Python数据分析实战:深入理解Pandas的GroupBy操作
在Python数据分析领域,Pandas库是当之无愧的“瑞士军刀”,而其中的 GroupBy 操作更是数据分析师手中的利器。通过 GroupBy ,我们可以轻松对数据进行分组聚合、转换和筛选,挖掘数据背后的规律。Pandas的 GroupBy 操作通过强大的分组聚合能力,让数据分析师能够高效处理复杂的数据逻辑。例如,在电商销售数据中,我们可以按“地区”拆分数据,计算每个地区的总销售额,最后合并结果
在Python数据分析领域,Pandas库是当之无愧的“瑞士军刀”,而其中的 GroupBy 操作更是数据分析师手中的利器。通过 GroupBy ,我们可以轻松对数据进行分组聚合、转换和筛选,挖掘数据背后的规律。接下来,我们将深入探讨 GroupBy 的原理、用法与实战案例。
一、GroupBy的核心概念:Split-Apply-Combine
GroupBy 的操作逻辑基于拆分(Split)、应用(Apply)、**合并(Combine)**三个步骤:
1. 拆分:根据指定的键(列名、函数或多个条件)将数据集划分为若干个组。
2. 应用:对每个分组独立应用函数(如求和、均值、自定义函数等)。
3. 合并:将应用函数后的结果整合为一个新的数据集。
例如,在电商销售数据中,我们可以按“地区”拆分数据,计算每个地区的总销售额,最后合并结果得到地区销售排名。
二、GroupBy的基础用法
假设我们有一份包含订单信息的数据集,包含 订单ID 、 地区 、 销售额 、 订单日期 四列数据,以下是使用 GroupBy 的常见场景:
1. 按单列分组聚合

输出结果将是一个以“地区”为索引、平均销售额为值的 Series 对象。
2. 按多列分组聚合 python
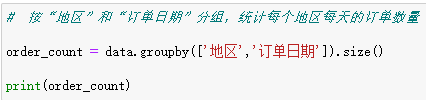
此时结果是一个 MultiIndex Series ,可以通过层级索引灵活查询数据。
3. 应用多个聚合函数 python
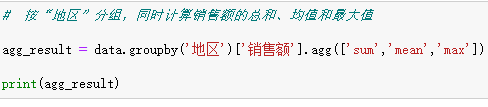
上述代码将返回一个包含三列( sum 、 mean 、 max )的 DataFrame ,方便对比不同聚合指标。
三、高级应用:自定义函数与Transform方法
1. 自定义聚合函数 当内置函数无法满足需求时,可以自定义函数进行分组计算。例如,计算每个地区销售额的变异系数(标准差/均值):

2. Transform方法:返回与原数据同形状的结果
Transform 方法常用于基于分组计算的结果填充回原数据。例如,为每个订单标记其所在地区的平均销售额:
这种操作在特征工程中极为实用,如计算标准化特征或异常值标记。
四、GroupBy的筛选与过滤
通过 Filter 方法,可以根据分组统计结果筛选数据。例如,筛选出平均销售额大于1000的地区:

Filter 会保留符合条件的分组内的所有行,而不是仅返回聚合结果。
五、实战案例:分析电商用户复购行为
假设我们有一份用户订单记录,包含 用户ID 、 订单日期 、 订单金额 等字段,目标是找出复购率最高的前10%用户。

通过 GroupBy 的灵活组合,我们可以快速完成复杂的业务分析需求。
六、总结
Pandas的 GroupBy 操作通过强大的分组聚合能力,让数据分析师能够高效处理复杂的数据逻辑。从基础的单列聚合到自定义函数、多步骤分析, GroupBy 在数据清洗、特征工程、业务洞察等场景中都发挥着关键作用。掌握这一工具,将大幅提升你的数据分析效率与深度。
无论是处理百万行的销售数据,还是挖掘用户行为模式, GroupBy 都是解锁数据价值的重要钥匙。建议读者通过实际数据集反复练习,体会其灵活性与强大之处!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)