强化学习: PPO模型
·
强化学习基础
一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。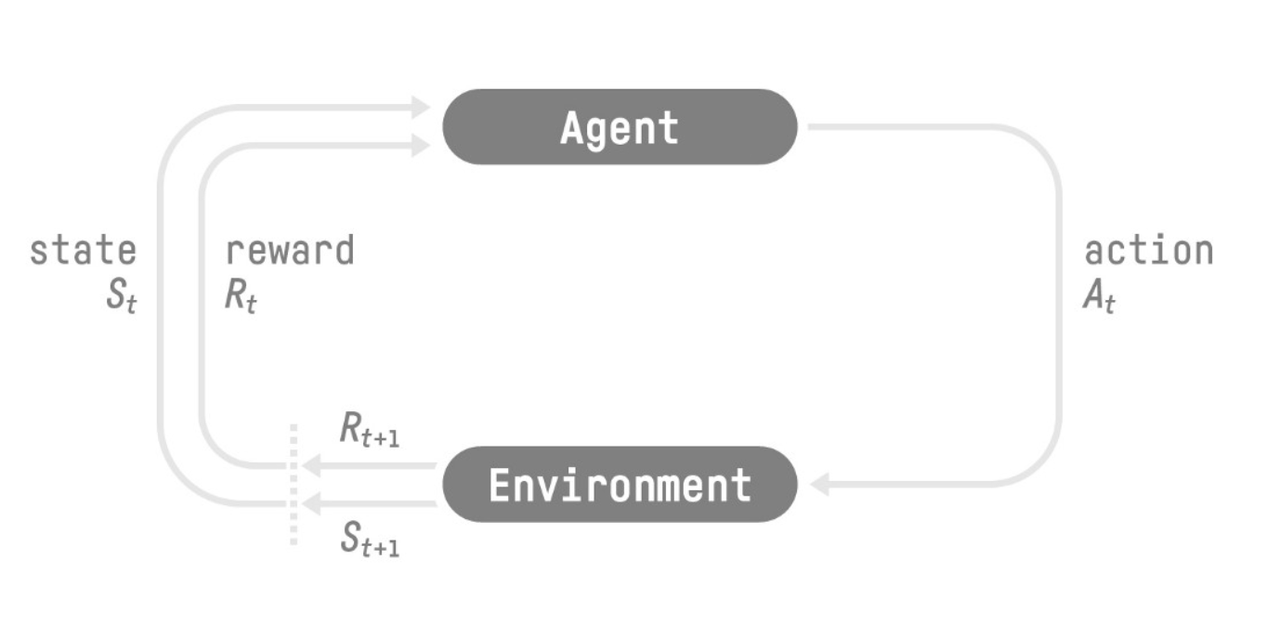
Policy Gradient 策略梯度算法
Agent又被称为Actor,Actor对于特定的任务,有自己的一个策略π,策略π用一个神经网络表示,其参数为θ。从一个特定的状态state出发,一直到任务的结束,被称为一个完整的eposide,在每一步,我们都能获得一个奖励r,一个完整的任务所获得的最终奖励被称为R。
一个有T个时刻的eposide,Actor不断与环境交互,形成如下的序列τ:
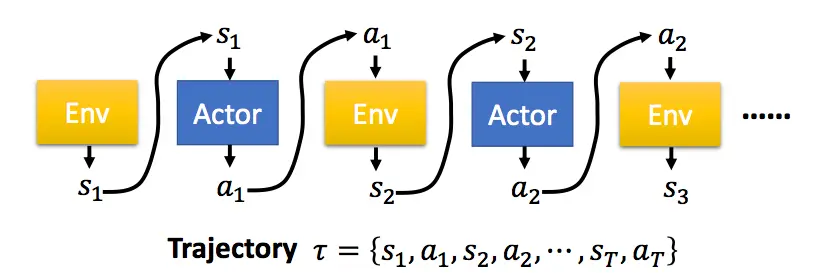
Actor在不同state下所采取的action可能是不同的,一个序列τ发生的概率为:(类似语言模型)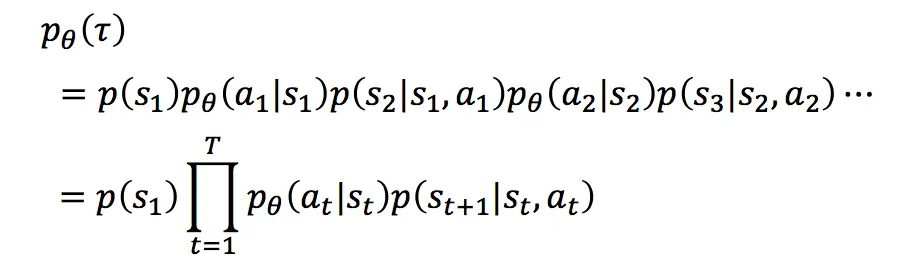
序列τ所获得的奖励为每个阶段所得到的奖励的和,称为R(τ)。因此,在Actor的策略为π的情况下,所能获得的期望奖励为:
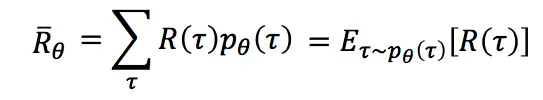
模型的学习过程就是调整Actor的策略π,使得期望奖励最大化,于是有了策略梯度的方法。既然奖励的期望函数如上,只要使用梯度提升的方法更新网络参数θ(即更新策略π)就好,所以问题的重点变为了求参数的梯度。梯度的求解过程如下:

其完整过程如下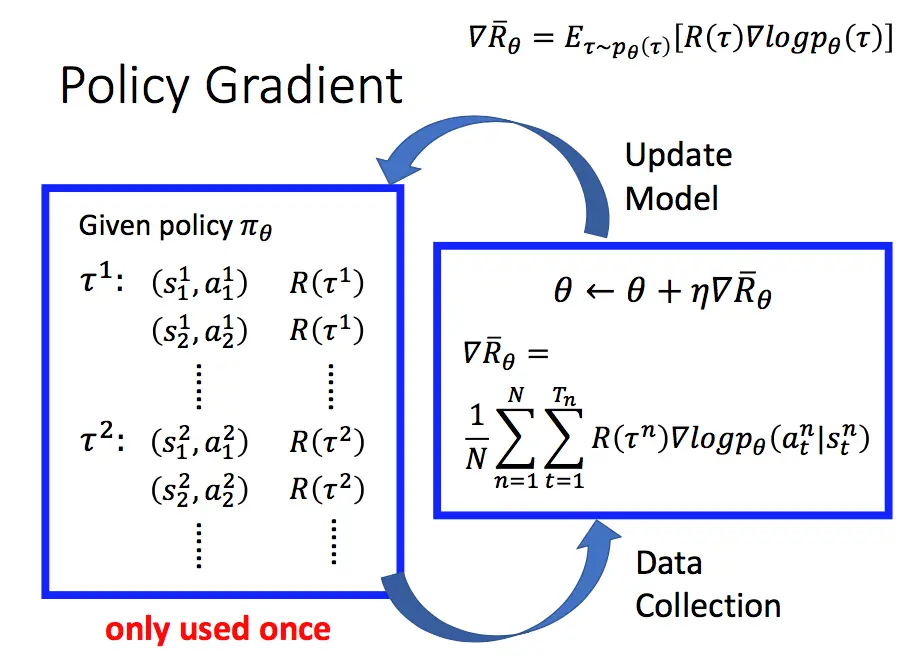
PPO

action_values = model.predict(state)
next_state, reward, done, _ = env.step(action_values)
target = model.predict(state)[0]
target[action] = reward + gamma * np.max(model.predict(next_state)[0])
model.fit(state, target.reshape(-1, num_actions), epochs=1, verbose=0)
GRPO
- GRPO 算法要求对每一个 prompt 都生成多个 response,后续才能根据组间对比得出相对于平均的优势(Advantage)
Reference
- https://www.jianshu.com/p/9f113adc0c50
- https://zhuanlan.zhihu.com/p/468828804
- https://zhuanlan.zhihu.com/p/20395188451

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)