计算机毕业设计之基于hadoop的社交媒体情感分析系统设计与实现
数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从微博网站上抓取海量社交媒体信息和评论数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入Hive数据库中以方便后续查询和检索,后端采用Django框架搭建We
本研究设计并实现了一个基于Hadoop的社交媒体情感分析系统,旨在高效处理和分析海量社交媒体数据。系统采用Hadoop分布式计算框架,结合自然语言处理技术,实现了数据采集、预处理、情感分析和结果展示等功能。通过情感分析算法,系统能准确识别用户情感倾向,为舆情监控、市场分析等提供数据支持。此外,系统还具备热门预测功能,可预测社交媒体内容的影响力。经测试,系统在处理大规模数据时表现出高效率和高准确性,展现了良好的应用前景。本研究为社交媒体情感分析领域提供了新的技术方案,推动了大数据技术在社交媒体分析中的应用与发展。
系统使用收集社交媒体信息的基本信息、转发数、点赞数、评论数、博主学习等行为数据的公开数据集,来构建社交媒体信息的数据分析。用户可以通过查询条件的方式,让系统实现对相关数据的筛选和查询,并将查询结果在前端以图表的可视化方式展示出来,进而帮助用户理解数据。系统通过对用户数据的分析与挖掘,实现了对于微博的解析和分类,系统提供了直观的社交媒体信息数据展示界面,查看到相应的分析结果。
数据采集功能实现对微博平台公共数据的采集,识别数据来源、区分数据类型,并进行数据完整性的验证,确保数据的准确性以及可靠性。分布式存储功能实现对已经处理过的数据进行分布式存储,采用MySQL、HDFS进行对数据的存储,以及支持异构端存储和具备高容错性,高可用性以及易扩展性。数据分析功能基于Spark分布式计算框架,实现对存储的数据进行了数据分析和挖掘。
数据可视化功能使用ECharts、Vue、BootStrap等前端技术,对数据分析结果进行了可视化展示,以图表等可视化方式将数据展示,方便了用户分析和观察。系统功能模块图如图3-1所示。
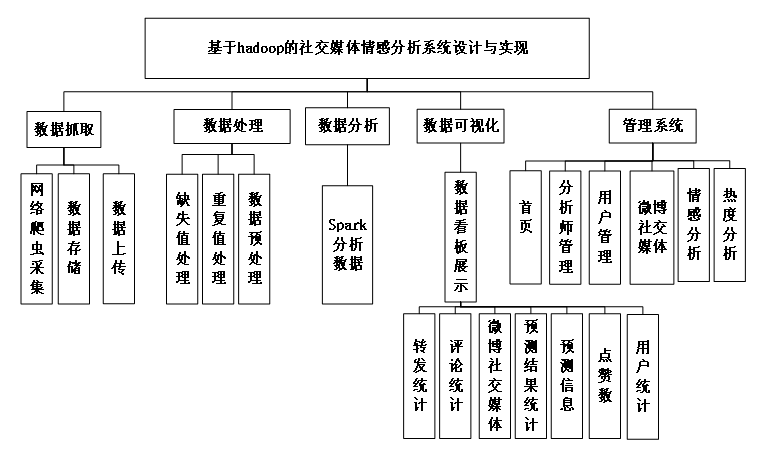
图3-1 系统功能模块图
在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从微博网站上抓取海量社交媒体信息和评论数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入Hive数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
基于Hadoop的社交媒体情感分析系统的数据可视化面板实现了多个功能模块,如图所示。左侧展示了转发统计和评论统计的柱状图,便于了解不同内容的传播情况和用户互动情况。中间部分则详细列出了微博社交媒体的热门预测总数、博主列表以及具体的发布计划和时间,帮助用户快速浏览和筛选热门话题和博主。右侧的用户统计和点赞统计的可视化图表,直观地反映了各个用户的活跃程度和经济指标。这些模块共同构成了一个全面的数据分析平台,助力系统高效运营和决策制定。可视化效果图如下所示:
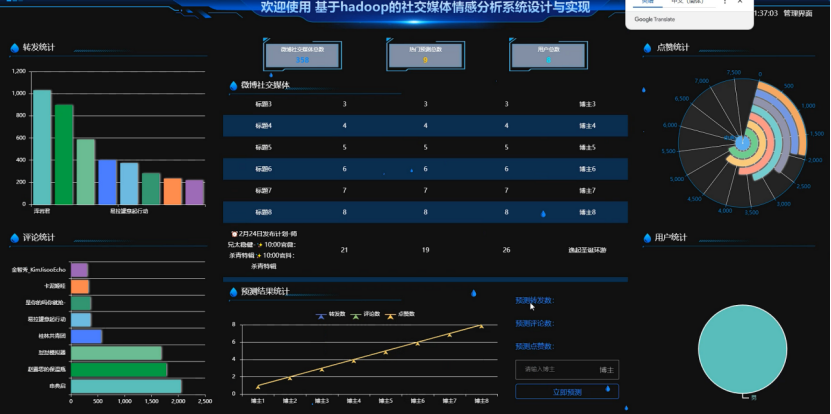
图5-1 数据可视化看板

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)