78、DEAP情感数据详解+神经网络项目实战[馒头老师,没有灵根就真的不能学BCI吗]
DEAP(Database for Emotion Analysis usingPhysiological Signals),该数据库是由来自英国伦敦玛丽皇后大学,荷兰特温特大学,瑞士日内瓦大学,瑞士联邦理工学院的Koelstra 等人通过实验采集到的,用来研究人类情感状态的多通道数据,可以公开免费获取。该数据库是基于音乐视频材料诱发刺激下产生的生理信号,采集了32名(16名男性和16名女性)健
我曾是那片故土的学生
如今
我是漂泊异乡的老师
—— 馒头
自己的学生有做情感分析的,无从下手,所以今天写一篇情感BCI的文章,介绍情感DEAP公开数据以及使用GCN处理该数据。
一、DEAP情感数据介绍
DEAP(Database for Emotion Analysis usingPhysiological Signals),该数据库是由来自英国伦敦玛丽皇后大学,荷兰特温特大学,瑞士日内瓦大学,瑞士联邦理工学院的Koelstra 等人通过实验采集到的,用来研究人类情感状态的多通道数据,可以公开免费获取。该数据库是基于音乐视频材料诱发刺激下产生的生理信号,采集了32名(16名男性和16名女性)健康被试者的数据。
获取官网:DEAP: A Dataset for Emotion Analysis using Physiological and Audiovisual Signals
在正式介绍数据之前,我想需要先说明一下[情绪定量模型的连续维度类型问题]。
1、区分情绪状态的边界是模糊的,状态的变化和演变是连续的,没有断点。将情绪状态划分为十二种离散类型只能显示情绪的主要方面,并在精确量化情绪状态下失败。此外,在各种文化和国籍之间,离散的情感标签并不一致。例如,我们无法找到波兰语中的相应翻译,以表达“厌恶”的情感。因此,提出了情绪定量方法的连续维度类型。这种量化方法使用了几个相互正交的基本轴来显示情绪的不同维度,这解决了离散量化方法与丰富的情感内涵之间的矛盾。 Russell提出了价值双相情感象限系统,该系统已在有效的计算中被广泛接受。如图1(a)所示,价值和唤醒的经典两个维度用于描述价水平和唤醒情绪水平。
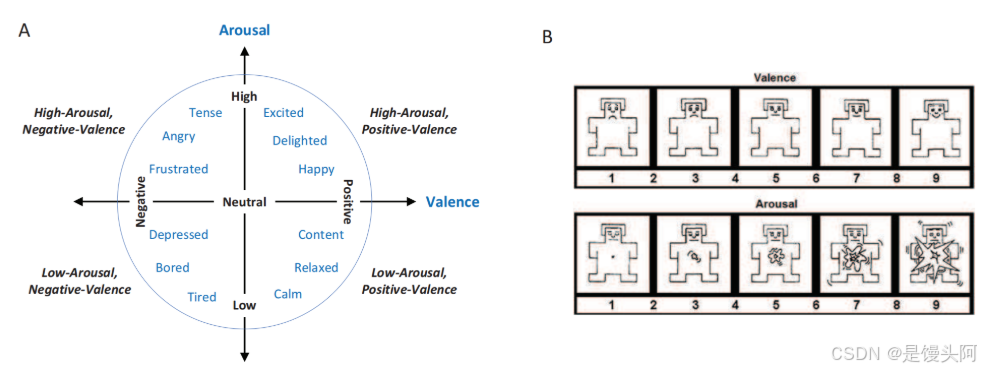
图1:(A)和相应的自我评估Manikin量表(B)提出的价值 - 正极双极坐标系。
2、从正到负的价值轴的值(或评级)是指个人快乐和悲伤的程度的测量。同样,唤醒的正值表示活化状态(兴奋),而负值表示未激活状态(平静)。除了两个标准的基本轴外,还可以添加更多的尺寸以进行全面的情绪测量。优势维度代表了情感过程中个人的主要控制程度。当外部环境控制用户时,情绪状态处于较低的优势水平(例如,惊喜,恐惧等)。相反,当用户可以掌握外部环境时,情绪状态处于较高的优势水平。应该指出的是,各种离散的情绪状态可以将其定位到具有一对一信件的连续维状态空间中的特定位置。例如,悲伤的情绪位于连续情感坐标系统中的低唤醒统治地位 -低价坐标空间中,而幸福情绪则位于高唤醒高的统治高价值坐标空间中。评估连续情绪状态的广泛采用的方法是基于量表的自我评估Manikins(SAM)方法。 SAM的设计是通过将Manikins引入问卷中以视觉评估价和唤醒的程度。
DEAP数据详解:
DEAP(Database for Emotion Analysis using Physiological Signals)是一个用于情绪分析的生理信号数据库。它包含了多个参与者在观看多个音乐视频片段时的生理数据和情绪评分。DEAP数据集是在实验室环境中收集的,旨在研究情绪与生理信号之间的关联。
1、数据采集过程:参与者戴上生理传感器设备,包括电极用于测量脑电图(EEG)信号、心电图(ECG)信号、皮肤电导(EDA)信号和肌电图(EMG)信号。参与者被要求观看40个5分钟的音乐视频片段,并在观看期间进行情绪评分。
2、生理信号:DEAP数据集包含32个通道的生理信号数据。其中包括14个脑电图信号(采样频率为128Hz)、1个心电图信号(采样频率为256Hz)、8个皮肤电导信号(采样频率为4Hz)、4个肌电图信号(采样频率为128Hz)和1个呼吸信号(采样频率为32Hz)。
3、情绪评分:参与者在每个音乐视频片段观看完毕后,根据离散的9点等级评分情绪体验。这些情绪包括愉快、兴奋、愤怒、压力、悲伤、害怕、惊讶、平静和无聊。
4、数据标注:除了生理信号和情绪评分外,DEAP数据集还提供了音频和视频特征。音频特征包括梅尔频率倒谱系数(MFCC)和音频能量。视频特征包括帧差分和颜色直方图等。
5、数据集规模:DEAP数据集包含来自32位参与者的数据,每位参与者观看完40个音乐视频片段,因此总共有1280个数据点。每个数据点包含用于情绪分析的生理信号数据、情绪评分以及音频和视频特征。
6、官方对于数据的预处理:
6.1、生理信号采用512Hz采样,128Hz复采样(官方提供了经过预处理的复采样数据)每个被试者的生理信号矩阵为40408064(40首实验音乐,40导生理信号通道,8064个采样点)其中40首音乐均为时长1分钟的不同种类音乐视频,40导生理信号包括10-20系统下32导脑电信号、2 导眼电信号(1导水平眼电信号,1导竖直眼电信号)[眼电信号EOG]、2导肌电信号(EMG)、1导GSR信号(皮电)、1导呼吸带信号、1导体积描记器、1导体温记录信号。8064则是128Hz采样率下63s的数据,每一段信号记录前,都有3s静默时间。据一般选取官网可下载的预处理( 降采样,去除眼电等噪声) 之后的数据(两个版本:data_preprocessed_matlab文件夹和data_pr
6.2、eprocessed_python文件夹,即matlab和python处理后的,格式分别为.mat和.dat),实验数据由32个文件组成。对应32个实验受试者每个参与者文件包含两个数组。

数据意义:
DEAP数据集的设计使得研究人员能够探索生理信号与情绪之间的关系。通过分析这些数据,可以提取特征、构建模型并进行情绪分类或回归任务,从而增进对情绪体验的理解以及与生理变化的联系。这对于情感计算、情绪识别和心理健康领域的研究非常有用。
二、GCN处理DEAP数据
图卷积神经网络(Graph Convolutional Network,GCN)是一种用于处理图结构数据的深度学习算法。它扩展了传统的卷积神经网络(CNN)到图领域,可以对节点在图上的特征进行学习和预测。GCN具有广泛的应用,包括社交网络分析、推荐系统、生物信息学等领域。
这个模型,我之前的博客写了不少,也介绍过其原理,做过一些实战以及讲解了几篇一二区的GCN的论文,同学请自行查阅:
51、CR-GCN:EEG通道拓扑结构+脑功能连接捕获EEG通道关系,用于情感识别[我处理的是原始EEG数据哦]_eeg功能连接网络-CSDN博客
50、东北大学、阿尔伯塔大学:Hi-GCN从2个层次角度进行图学习,用来诊断脑部疾病[你这和MVS-GCN套娃呢?]_higcn-CSDN博客
47、处理EEG数据的隐藏王者:手推图神经网络GCN[CNN宗主不过如此!]_eeg gcn-CSDN博客
下面我们使用GCN去处理这个数据并开源代码:
算法流程:
这里应该画一个流程图,但是馒头老师没时间画了,直接以文字代替
1、图卷积神经网络(GCN)输入数据为一个图数据,包括节点特征和节点之间的边信息
2、GCNConv()是对节点特征进行卷积操作,包括输入特征维度和输出特征维度两个参数
3、模型使用了两个GCNConv层,分别将输入特征从60维降到32维,再从32维降至输出类型维度(即分类数)
4、在每个GCNConv操作后,使用了ReLU激活函数和dropout正则化
5、最后,使用global_max_pool操作将每个节点的特征进行池化降维得到图的全局特征,再使用log_softmax作为输出,得到每个类别的概率分布。
实验过程:
1)获取数据集,提取数据并依据文档将其重整为mne格式,设定脑电通道;
2)提取频域特征,作为通道节点输入GCN的特征;
3)生成通道邻接矩阵,根据希尔伯特变换生成相位同步矩阵;
4)依据以上数据构造GCN能够接收的数据格式进行训练;
5)预测并输出结果。
实验结果:
epoch is 1000
loss is 0.013977153226733208
Accuracy of the network on the test images: 63 %模型代码:
import numpy as np
import mne
import scipy.io as scio
import warnings
import torch
import torch.nn as nn
from torch_geometric.data import DataLoader
import torch.nn.functional as F
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
import os
from sklearn.model_selection import train_test_split
import logging
from scipy.signal import hilbert
import scipy.sparse as sp
import torch_geometric.nn as pyg_nn
from sklearn.preprocessing import StandardScaler
# 引入tensorboard记录loss和正确率
from torch.utils.tensorboard import SummaryWriter
# 设置日志级别为ERROR或CRITICAL
warnings.filterwarnings("ignore", category=RuntimeWarning)
logging.getLogger('mne').setLevel(logging.ERROR) # 或者 logging.CRITICAL
# 超参数
num_epochs = 1000 # 训练轮数
num_sample = 60 # 时间轴上时间点数量,num_sample + t_max < 63(数据持续时间)
learing_rate = 0.001 # 学习率
t_max = 1 # 每一个mne.epoch的持续长度
output_types = 2 # LSTM输出种类数量
def compute_phase_sync_matrix(eeg_data):
num_channels = 32
eeg_data = np.transpose(eeg_data)
phase_sync_matrix = np.zeros((num_channels, num_channels))
# 计算每个电极的相位
phase_data = np.angle(hilbert(eeg_data))
# 计算相位差的余弦值
for i in range(num_channels):
for j in range(i+1, num_channels):
phase_diff = np.abs(phase_data[:, i] - phase_data[:, j])
cos_phase_diff = np.cos(phase_diff)
phase_sync = np.mean(cos_phase_diff)
phase_sync_matrix[i, j] = phase_sync
phase_sync_matrix[j, i] = phase_sync
# 将结果转化为list
# phase_sync_matrix = phase_sync_matrix.tolist()
# 将矩阵中元素数值大于0的设置为1,小于0的设置为0
phase_sync_matrix[phase_sync_matrix > 0] = 1
phase_sync_matrix[phase_sync_matrix < 0] = 0
return phase_sync_matrix
class Net(torch.nn.Module):
"""构造GCN模型网络"""
def __init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(60, 32)
self.conv2 = GCNConv(32, output_types)
def forward(self, data): # 前向传播
x, edge_index, batch = data.x, data.edge_index, data.batch # 赋值
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = pyg_nn.global_max_pool(x, batch) # 池化降维出
return F.log_softmax(x, dim=1) # softmax可以得到每张图片的概率分布,设置dim=1,可以看到每一行的加和为1,再取对数矩阵每个结果的值域变成负无穷到0
def pre_train():
# 定义通道列表
num_channels = 32
channels = ['Fp1', 'AF3', 'F7', 'F3', 'FC1', 'FC5', 'T7', 'C3', 'CP1', 'CP5', 'P7', 'P3', 'Pz', 'PO3', 'O1', 'Oz',
'O2', 'PO4', 'P4', 'P8', 'CP6', 'CP2', 'C4', 'T8', 'FC6', 'FC2', 'F4', 'F8', 'AF4', 'Fp2', 'Fz', 'Cz']
# 这里初始空值维度设置为第一个文件第一个视频中的维度,便于拼接,之后需要去掉
features = np.empty((0, 60)) # 创建一个空的 features 数组
labels = []
graph_dataset = []
matrix_dataset = []
# 要遍历的文件夹路径
folder_path = "data/data_preprocessed_matlab"
# 遍历文件夹下的文件名
file_names = [f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]
# print(file_names)
test_file = ['s01.mat', 's02.mat', 's03.mat', 's04.mat', 's05.mat', 's06.mat', 's07.mat', 's08.mat', 's09.mat']
for i in test_file:
path = folder_path + "/" + i
input_features, y, per_matrix = dataset(path)
# 取得每个文件的特征和标签
features = np.vstack((features, input_features))
labels = np.append(labels, y)
# 将每个文件的相位同步矩阵存入matrix_dataset
for m in per_matrix:
# 重复添加5次
for n in range(5):
matrix_dataset.append(m)
# print(features.shape)
# print(labels.shape)
print("the shape of features is:", features.shape)
scaler = StandardScaler()
features = scaler.fit_transform(features)
print("the shape of labels is:", labels.shape)
print("the shape of matrix_dataset is:", len(matrix_dataset))
# 构建可以输入图卷积神经网络中的相位同步矩阵,每32条数据(一个视频)构建一个矩阵(需修改)
no = 0
print(matrix_dataset)
# print("int(features.shape[0]/32):", int(features.shape[0]/32))
for i in range(int(features.shape[0]/32)):
graph_matrix = matrix_dataset[no]
edge_index_temp = sp.coo_matrix(graph_matrix)
indices = np.vstack((edge_index_temp.row, edge_index_temp.col))
edge_index = torch.LongTensor(indices)
x = torch.FloatTensor(features[32*i:32*(i+1), :])
y = torch.tensor(labels[i]).long()
data = Data(x=x, edge_index=edge_index, y=y)
graph_dataset.append(data)
no += 1
# 划分训练集和测试集
train_dataset, test_dataset = train_test_split(graph_dataset, test_size=0.2, random_state=42)
# 构建模型实例
model = Net() # 构建模型实例
optimizer = torch.optim.Adam(model.parameters(), lr=learing_rate) # 优化器,参数优化计算
train_loader = DataLoader(train_dataset, batch_size=40, shuffle=False) # 加载训练数据集,训练数据中分成每批次40个图片data数据
test_loader = DataLoader(test_dataset, batch_size=40, shuffle=False) # 读取测试数据集数据
# 定义测试函数
def evaluate(loader): # 构造测试函数
# model.eval() # 表示模型开始测试
with torch.no_grad():
for data in loader: # 读取测试数据集单个data数据
pred = model(data).numpy() # 将数据导入之前构造好的模型
label = data.y.numpy() # 获取测试集的图片标签
# 将preds转化为数组形式
pred = np.array(pred)
label = np.array(label)
return pred, label
# 训练模型
for epoch in range(num_epochs): # 训练所有训练数据集n次
loss_all = 0
# 一轮epoch优化的内容
for data in train_loader:
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播,把一批训练数据集导入模型并返回输出结果
label = data.y # 40张图片数据的标签集合
# print("label is", label)
# print("output is", output.shape)
loss = F.nll_loss(output, label)
loss.backward() # 反向传播
loss_all += loss.item() # 将最后的损失值汇总
optimizer.step() # 更新模型参数
if epoch % 10 == 0:
print("epoch is", epoch)
print("loss is", loss.item())
# 输出测试集准确率
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
labels = data.y
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the test images: %d %%' % (100 * correct / total))
writer.add_scalar('Train/Loss', loss, epoch)
writer.add_scalar('Test/Accuracy', 100 * correct / total, epoch)
def eeg_power_band(epochs):
"""
该函数根据epochs的特定频段中的相对功率来创建eeg特征
输入数据为被试观看一个视频中的raw
根据需求需要把该函数进行改动
psds_band之前的特征格式为(epoch数, 通道数)
新生成特征格式应当为(通道数, epoch数个某频段相对功率)
输入图卷积神经网络中的数据应当为(通道数, 特征)
与其相关的脑网络矩阵为(通道数, 通道数)
每一个视频数据对应一个label,故最后输入网络的数据应当为(通道数, 某频域相对功率特征)
因此下面部分的label区域(数量为视频数量)应当做出5(频域数量)的拓展
"""
# 特定频带
FREQ_BANDS = {"delta": [0.5, 4.5],
"theta": [4.5, 8.5],
"alpha": [8.5, 11.5],
"sigma": [11.5, 15.5],
"beta": [15.5, 30]}
spectrum = epochs.compute_psd(method='welch', picks='eeg', fmin=0.5, fmax=30., n_fft=128, n_overlap=16)
psds, freqs = spectrum.get_data(return_freqs=True)
# 归一化 PSDs
psds /= np.sum(psds, axis=-1, keepdims=True)
X = []
for fmin, fmax in FREQ_BANDS.values():
psds_band = psds[:, :, (freqs >= fmin) & (freqs < fmax)].mean(axis=-1)
# print("psd_band.shape is ", psds_band.shape)
"""
(60个epoch,(每一个epoch有32个通道,每一个通道的某个频段))
"""
X.append([list(item) for item in zip(*psds_band)])
# print("X.shape is ", np.array(X).shape)
return X
def label_trans(raw_label):
# 对值进行二进制编码(小于5.5为0, 大于为1)
# 该函数在调整分类类别的时候需要跟随目标类别进行调整
binary_arr = np.where(raw_label < 5.5, 0, 1) # 小于 5.5 的值设置为 0,大于等于 5.5 的值设置为 1
decimal_arr = binary_arr.dot([1, 0, 0, 0]) # 将二进制数组转化为十进制数组
# print(decimal_arr) # 输出生成的数组
repeated_arr = np.repeat(decimal_arr, 5)
return repeated_arr
def dataset(file):
"""
dataset key_word:
labels.shape (40, 4)
解释:
labels用于标记被试看到每一个视频时的状态
第二维度中的四个数据代表四个评价标准arousal(唤醒度), valence(愉悦度), dominance(支配度), like(喜爱度)
data.shape (40, 40, 8064)
解释:
第一个维度代表40段观看视频产生的脑电数据
第二个维度代表每段数据存在40个通道
第三个维度为采样点,长度在63s左右
根据官方网站得采样率为128hz
"""
real_feature = []
original_data = scio.loadmat(file)
# print(original_data.keys())
sample_data = original_data['data']
sample_labels = original_data['labels']
sample_data = sample_data[:, :32, :]
# 计算每一个视频中的相位同步矩阵
per_matrix = []
for i in range(sample_data.shape[0]):
matrix = compute_phase_sync_matrix(sample_data[i])
per_matrix.append(matrix)
k = sample_data.shape[0]
# 每个人观看40个视频,每个视频有40个通道(取前32个EEG通道),每个通道有8064个采样点
# print("sample_data.shape is ", sample_data.shape)
# print("sample_labels.shape is ", sample_labels.shape)
# 根据官方文档设置通道
channel_names = ['Fp1', 'AF3', 'F7', 'F3', 'FC1', 'FC5', 'T7', 'C3',
'CP1', 'CP5', 'P7', 'P3', 'Pz', 'PO3', 'O1', 'Oz',
'O2', 'PO4', 'P4', 'P8', 'CP6', 'CP2', 'C4', 'T8',
'FC6', 'FC2', 'F4', 'F8', 'AF4', 'Fp2', 'Fz', 'Cz']
# 设置采样率
sfreq = 128
info = mne.create_info(channel_names, sfreq)
# 设置所有通道种类为eeg
channel_types = {}
for i in channel_names:
channel_types[i] = 'eeg'
# 将观看者看第i个视频的感受提取出来创建raw
for i in range(0, k):
slice_data = sample_data[i, :, :]
raw = mne.io.RawArray(slice_data, info)
raw.set_channel_types(channel_types)
"""
查看EEG信号图
raw.plot(title="The "+str(i)+" raw", bgcolor='pink', color='steelblue', n_channels=10, duration=10)
plt.pause(0)
"""
# 构建事件数组
events = np.zeros((num_sample, 3))
for i in range(num_sample):
events[i][0] = i*sfreq
# print(events)
events = events.astype(int)
# 每一个epoch长度为从事件开始的采样点到 t_max 秒后的采样点,这里就不设置基线了
epochs = mne.Epochs(raw=raw, events=events, tmin=0, tmax=t_max, preload=True, baseline=None)
# print(epochs)
features = eeg_power_band(epochs)
features = np.array(features)
# print("features.shape is ", features.shape)
real_feature.append(features)
# print("real_feature.shape is ", np.array(real_feature).shape)
# print("real_feature.shape is ", np.array(real_feature).shape)
# print("real_feature is ", real_feature)
real_feature = np.array(real_feature).reshape(-1, 60)
# print("new real_feature is ", real_feature)
y = label_trans(sample_labels) # 重整labels
# print("y.shape is ", y.shape)
# print("y is ", y)
# 返回当前文件下的40个视频中的特征以及labels
return real_feature, y, per_matrix
def main():
pre_train()
if __name__ == '__main__':
writer = SummaryWriter('logs')
main()
writer.close()
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)