01.初入MMDetection之轻松掌握模型训练、跟踪及评估
根据搭建好的基础环境启动第一个模型训练,并对训练好的模型进行评估。通过本篇博客的学习,您将掌握mmdetection训练过程中:a. 数据集的准备;b. 配置文件内容的修改;c. 单卡/多卡训练;d. 训练过程中日志输出解析;e. 训练精度可视化。走通模型训练、验证、测试的整个流程
本专栏内容:本专栏主要针对MMDetection训练框架提供从入门到进阶的学习路线。主要分为三个阶段。三个阶段包括初入mmdetection、走进mmdetection和mmdetection进阶三大部分,并包含mmdeploy一站式部署。其中,
- 初入mmdetection系列主要通过基础环境的构建,跑通基于mmdetection的训练、推理流程,熟悉mmdetection的基本操作;
- 走进mmdetection系列主要介绍mmdetection的整体组成结构,帮助大家了解mmdetection框架训练的实现机制;
- mmdetection进阶系列主要通过AI缝合技术提升mmdetection框架训练模型指标的实战方案,也划分了初级和高级两个阶段,不仅帮助大家可以通过提供的实战方案提升模型指标,也能够自己掌握通过mmdetection进行AI缝合术。另外,也会引入一些训练过程中的常用技巧。
- mmdeploy一站式部署在模型训练之余,介绍使用mmdeploy进行TensorRT/ONNX等量化加速部署模型的转换及应用。

https://github.com/open-mmlab/mmdetection
MMDetection是OpenMMlab项目中用于实现目标检测的开源训练框架,基于Pytorch 1.8+。框架内提供了丰富的model和benchmark。
[00.初入MMDetection之轻松掌握运行环境安装,实现模型推理 ]
[01.初入MMDetection之轻松掌握模型训练、跟踪及评估]
本篇内容:根据00.初入MMDetection之轻松掌握运行环境安装,实现模型推理 搭建好的基础环境启动第一个模型训练,并对训练好的模型进行评估。
🌠🌠🌠通过本篇博客的学习,您将掌握mmdetection训练过程中:
a. 数据集的准备;
b. 配置文件内容的修改;
c. 单卡/多卡训练;
d. 训练过程中日志输出解析;
e. 训练精度可视化。
走通模型训练、验证、测试的整个流程!
本篇不会涉及到太多细节的内容,主要目的在于快速走通训练的流程,大家将精力关注于训练的过程即可。细节的内容,将在第二节 走进mmdetection系列和第三节mmdetection进阶系列篇章中介绍,敬请期待!
训练环境有问题的小伙伴可以留言或者私信噢~
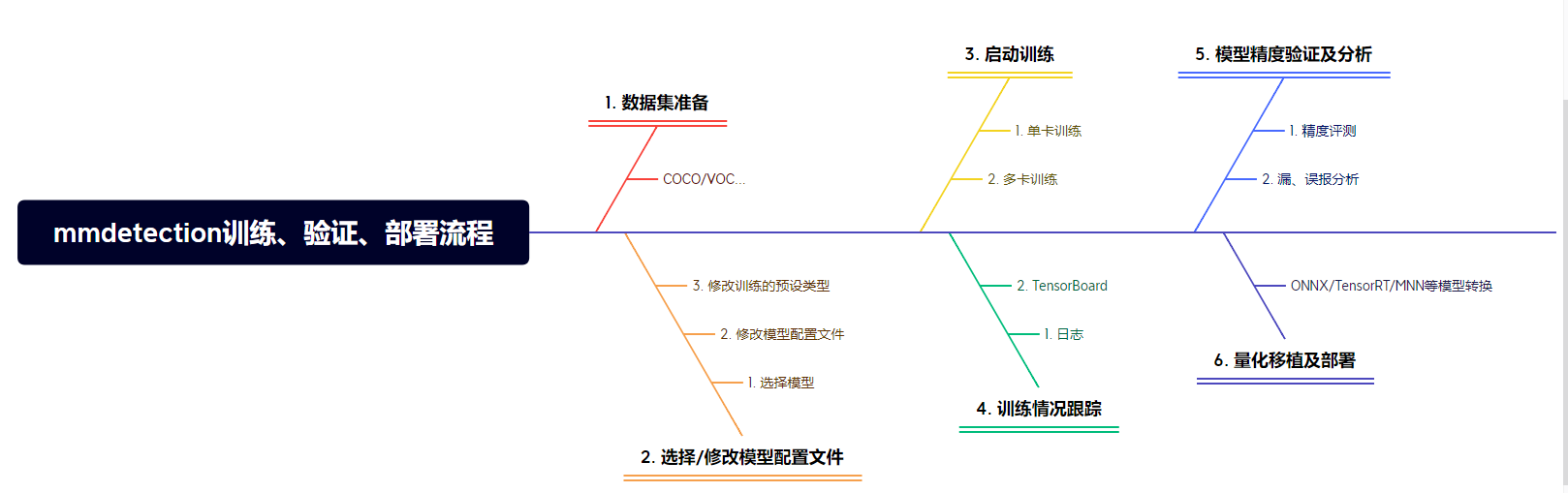
整体流程
一个模型从训练、验证到测试部署一般会包括如下流程(任何训练框架都大致相同)。主要包含:
- 数据集的准备: 包含COCO、VOC、YOLO等格式的准备;数据集情况的分析,例如图像分辨率的统计,数据标注类型及数量以及尺寸分布的统计等;
- 配置文件的选择&修改;
- 启动训练;
- 训练情况跟踪: 可以通过日志中验证集上的指标进行评估,以及TensorBoard可视化进行评估;
- 模型精度验证及分析: 模型训练完成后,对于mAP指标较高的模型进行其他数据集指标的验证,进一步评估模型的泛化性能;类似于深度学习中将数据划分为train / val / test。指标的验证训练框架会有一些基础的评测工具,也有很多不错的开源工具,另外,也可以根据业务需求,编写业务关注指标类型的评测工具。
- 模型量化及部署 当模型指标满足落地要求时,可以根据其部署的硬件设备进行量化移植部署,常见的有ONNX、TensorRT、MNN等。
启动第一个训练
在进行数据集准备之前,首先对mmdetection源码的整体组成结构进行一个初步了解。mmdetection项目的结构如下图所示,主要包括配置文件configs和具体实现mmdet,以及一些提供的常用工具tools,工具中包括数据格式转换、分析,模型转换,以及最常用的train.py和dist_train.sh。
也就是说,可以从configs中挑选一个模型配置文件通过train.py或者dist_train.sh启动单卡或者多卡训练。在启动训练之前,当然少不了数据集的准备。
A. 数据集准备
本篇和涉及到模型魔改实战的文章会尽可能使用同一个数据集,直观对比不同模型间指标的情况。
想要更换其他类型数据也可以留言~
数据选择天池大赛中的公开数据集:口罩佩戴数据集 该数据集包含7600张训练集,1000张验证集和1000张测试集,并且均包含标注。标注中共包含3个类别,正确佩戴口罩(R_mask)、未正确佩戴口罩(W_mask)和未佩戴口罩(N_mask)。
yololabels转voc
提供的标注文件为YOLO官方的txt格式,如下图所示。
每行代表一个目标的类别和位置信息。class_id, x_center, y_center, w, h
第1列代表目标的类别,例如,0代表R_mask, 2代表N_mask;后面4列代表目标的位置信息中心点信息和宽高信息 [x_center, y_center, w, h],可以看到这4列均为小于1的浮点数,表示的是相对于图像的比例,即x_center = x / W , x为目标的宽,W为图像的宽。
为了更好地实现不同数据格式之间的转换,通过下述代码,将yolo格式的txt文件,转换为voc格式的xml文件,目标位置信息为xmin, ymin, xmax, ymax。代码中所使用的imglist_dir可以通过下述指令获取
find `pwd` -name "*.jpg" > ../../imglist_train.txt
## yololabels 转 voc
import sys
import os
import os.path as osp
import cv2
import json
from tqdm import tqdm
import configparser
from xml.dom.minidom import parse
from xml.dom.minidom import Document
from collections import defaultdict
VERSION = "v1.0"
CLASSES = ("R_mask", "W_mask", "N_mask") # 类别及顺序
def parse_txt(txt_dir):
with open(txt_dir, "r") as fp:
imgdir_list = fp.readlines()
return imgdir_list
def parse_yololabel(yololabel_dir, label_dic, shape):
def xywh2xyxy(shape, label_info, label_dic):
h, w, c = shape
typ_id, _x, _y, _w, _h = label_info.split(" ")
xmin = int(float(_x) * w + 1 - (float(_w) * w * 0.5 )) # xmin
ymin = int(float(_y) * h + 1 - (float(_h) * h * 0.5 )) # ymin
xmax = int(float(_x) * w + 1 + (float(_w) * w * 0.5 )) # xmax
ymax = int(float(_y) * h + 1 + (float(_h) * h * 0.5 )) # ymax
xmin = 0 if xmin < 0 else xmin
ymin = 0 if ymin < 0 else ymin
xmax = int(w) - 1 if xmax > int(w) else xmax
ymax = int(h) - 1 if ymax > int(h) else ymax
label_dic["object"].append([CLASSES[int(float(typ_id))], '0', str(xmin), str(ymin), str(xmax), str(ymax)])
labels_info = parse_txt(yololabel_dir)
h, w, c = shape
label_dic["width"] = str(w)
label_dic["height"] = str(h)
label_dic["depth"] = str(c)
for label_info in labels_info:
label_info = label_info.strip()
xywh2xyxy(shape, label_info, label_dic)
def write_xml(img_name, label_data, output_label_path, need_score):
doc = Document()
annotation = doc.createElement("annotation")
doc.appendChild(annotation)
folder = doc.createElement("folder")
folder_text = doc.createTextNode("JPEGImages")
folder.appendChild(folder_text)
annotation.appendChild(folder)
filename = doc.createElement("filename")
filename_text = doc.createTextNode(img_name)
filename.appendChild(filename_text)
annotation.appendChild(filename)
path = doc.createElement("path")
path_text = doc.createTextNode(img_name)
path.appendChild(path_text)
annotation.appendChild(path)
source = doc.createElement("source")
database = doc.createElement("database")
database_text = doc.createTextNode("Unknown")
database.appendChild(database_text)
source.appendChild(database)
annotation.appendChild(source)
size = doc.createElement("size")
width = doc.createElement("width")
height = doc.createElement("height")
depth = doc.createElement("depth")
width_text = doc.createTextNode(label_data["width"])
width.appendChild(width_text)
height_text = doc.createTextNode(label_data["height"])
height.appendChild(height_text)
depth_text = doc.createTextNode(label_data["depth"])
depth.appendChild(depth_text)
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
annotation.appendChild(size)
segmented = doc.createElement("segmented")
segmented_text = doc.createTextNode("0")
segmented.appendChild(segmented_text)
annotation.appendChild(segmented)
for det in label_data["object"]:
obj = doc.createElement("object")
name = doc.createElement("name")
name_text = doc.createTextNode(det[0])
name.appendChild(name_text)
pose = doc.createElement("pose")
pose_text = doc.createTextNode("Unspecified")
pose.appendChild(pose_text)
truncated = doc.createElement("truncated")
truncated_text = doc.createTextNode("0")
truncated.appendChild(truncated_text)
difficult = doc.createElement("difficult")
difficult_text = doc.createTextNode(det[1])
difficult.appendChild(difficult_text)
if need_score:
score = doc.createElement("score")
score_text = doc.createTextNode(det[6])
score.appendChild(score_text)
bndbox = doc.createElement("bndbox")
xmin = doc.createElement("xmin")
xmin_text = doc.createTextNode(det[2])
xmin.appendChild(xmin_text)
ymin = doc.createElement("ymin")
ymin_text = doc.createTextNode(det[3])
ymin.appendChild(ymin_text)
xmax = doc.createElement("xmax")
xmax_text = doc.createTextNode(det[4])
xmax.appendChild(xmax_text)
ymax = doc.createElement("ymax")
ymax_text = doc.createTextNode(det[5])
ymax.appendChild(ymax_text)
bndbox.appendChild(xmin)
bndbox.appendChild(ymin)
bndbox.appendChild(xmax)
bndbox.appendChild(ymax)
obj.appendChild(name)
obj.appendChild(pose)
obj.appendChild(truncated)
obj.appendChild(difficult)
obj.appendChild(bndbox)
if need_score:
obj.appendChild(score)
annotation.appendChild(obj)
with open(output_label_path, "w") as file:
file.write(doc.toprettyxml(indent=" "))
if __name__ == "__main__":
print(f"欢迎使用yololabels 转 voc 工具: {VERSION}")
imglist_dir = r'/workspace/Dataset/OpenSourceDataset/MaskDetection/imglist_test.txt'
xml_save_pth = r'/workspace/Dataset/OpenSourceDataset/MaskDetection/Annotations/test'
os.makedirs(xml_save_pth, exist_ok=True)
if not osp.exists(imglist_dir):
print(f"no such file {imglist_dir}")
sys.exit(0)
imgdir_list = parse_txt(imglist_dir)
for img_dir in tqdm(imgdir_list):
img_dir = img_dir.strip()
yololabel_dir = img_dir.replace("images", "labels").replace(".jpg", ".txt")
if not osp.exists(yololabel_dir) or not osp.exists(img_dir):
print(f'no such file {yololabel_dir} or {img_dir}, please check')
sys.exit(0)
img = cv2.imread(img_dir)
if img is None:
continue
shape = img.shape
label_dic = {
"width": 0,
"height": 0,
"depth": 3,
"object": []
}
parse_yololabel(yololabel_dir, label_dic, shape)
save_xml_dir = osp.join(xml_save_pth, osp.split(img_dir)[-1].replace(".jpg", ".xml"))
write_xml(img_dir, label_dic, output_label_path=save_xml_dir, need_score=False)
经过上述操作,在数据集Annotations文件夹下,分别生成train / val/ test对应的xml格式的文件。
voc转coco
COCO数据集将所有的图像信息和标注信息集成汇总为一个json文件。其主要可以由如下结构组成。包括保存图像信息的images,保存标注信息的annotations,以及类别对应关系categories。json_dict = {"images":[], "annotations": [], "categories": [], "type": "instances", } 其中,images包含具有图像路径的filename、图像宽高信息、以及与标注annotations做链接的id。通过id,可以对应图像和标注之间的归属,如下图所示。
annotations主要包含bbox的位置信息[xmin, ymin, xmax, ymax],category_id类别索引,以及image_id对应到那张图像,以及id序号。
categories包含类别信息name及id信息,annotations中的category_id可以通过id对应到具体的类别名称。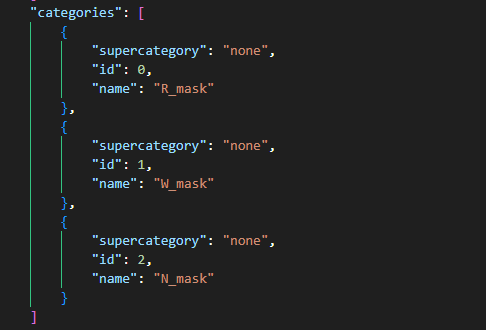
通过下述代码,可以将图像的imglist列表生成对应的COCO文件。
训练集、验证集、测试集对应的imglist文件,可以在对应的图像路径下通过下述指令获得。
find `pwd` -name "*.jpg" > ../../imglist_train.txt

# 实现imglist的txt文件转coco
# VOC2COCO
import sys
import os
import os.path as osp
import json
import xml.etree.ElementTree as ET
from tqdm import tqdm
VERSION = "v1.0"
START_BOUNDING_BOX_ID = 1
NAME_REFLECT_FLAG = 1
PRE_DEFINE_CATEGORIES = {"R_mask": 0, "W_mask": 1, "N_mask": 2}
NAME_REFLECT= {
"N_mask": "N_mask",
"W_mask": "W_mask",
"R_mask": "R_mask"
}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = os.path.splitext(filename)[0]
return str(filename)
except:
raise NotImplementedError('Filename %s is supposed to be an integer.'%(filename))
def convert(img_list, json_file):
img_list_fp = open(img_list, "r", encoding='utf-8-sig')
json_dict = {"images":[], "type": "instances", "annotations": [],
"categories": []}
categories = PRE_DEFINE_CATEGORIES # 设置了预定义的类别和id
bnd_id = START_BOUNDING_BOX_ID # 开始的id号 默认为1
with_out_xml_num = 0
for line in tqdm(img_list_fp.readlines()):
img_dir = line.strip()
xml_dir = img_dir.replace("images", "Annotations")
xml_dir = xml_dir.replace(".jpg", ".xml")
# print("Processing %s"%(xml_dir))
if not osp.exists(xml_dir):
print("xml not exist: {}".format(xml_dir))
with_out_xml_num+=1
continue
# xml_f = os.path.join(xml_dir, line+".xml")
tree = ET.parse(xml_dir)
root = tree.getroot()
path = get(root, 'path') # path 是包含路径的图像名称 filename是不包含路径的图像名称
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, 'filename', 1).text
else:
raise NotImplementedError('%d paths found in %s'%(len(path), line))
## The filename must be a number
image_id = get_filename_as_int(img_dir) # image_id用的是图像名称 带路径
size = get_and_check(root, 'size', 1)
try:
width = int(float(get_and_check(size, 'width', 1).text))
height = int(float(get_and_check(size, 'height', 1).text)) # 获取宽高
except Exception as e:
print(f"Error: {xml_dir}")
sys.exit(0)
image = {'file_name': img_dir, 'height': height, 'width': width,
'id':image_id} # 形成images中的一个
rm_num = 0
flag =False
for obj in get(root, 'object'): # 获取标注
category = get_and_check(obj, 'name', 1).text
category = category.encode("utf-8").decode("utf-8-sig")
if NAME_REFLECT_FLAG:
category = NAME_REFLECT.get(category, 0)
category_id = categories[category] # 获取当前的id
bndbox = get_and_check(obj, 'bndbox', 1) # 获取bndbox 包含异常报错
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text)) - 1
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text)) - 1
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
if xmin < xmax and ymin > ymax:
ymin, ymax = ymax, ymin
elif xmin > xmax and ymin < ymax:
xmin, ymin, xmax, ymax = xmax, ymin, xmin, ymax
elif xmin > xmax and ymin > ymax:
xmin, ymin, xmax, ymax = xmax, ymax, xmin, ymin
xmin = 0 if xmin < 0 else xmin
ymin = 0 if ymin < 0 else ymin
xmax = int(width) - 1 if xmax > int(width) else xmax
ymax = int(height) - 1 if ymax > int(height) else ymax
# 对于标注点 大于 标注中记录的图像宽高的
if xmax < xmin or ymax < ymin:
rm_num += 1
continue
try:
assert xmax > xmin, f"{xmax}, {xmin}, {ymin}, {ymax}, {xml_dir}"
assert(ymax > ymin) # 包含对于左上 右下角坐标的大小处理 可以用于判断标注文件中是否包含右上 左下的情况
except Exception as e:
print(f"{xml_dir}-{xmax}, {xmin}, {ymin}, {ymax}-{e}")
continue
flag = True
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin) # 获取目标的宽高 用于计算面积
area = o_width * o_height
ann = {'area': area, 'iscrowd': 0, 'image_id':
image_id, 'bbox':[xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []} # 进行填写
json_dict['annotations'].append(ann) # 添加
bnd_id = bnd_id + 1 # bnd_id+1
if flag:
json_dict['images'].append(image) # 添加进去
for cate, cid in categories.items(): # 循环完成后 使用categories进行 categories 的处理
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w', encoding="utf-8")
json.dump(json_dict, json_fp, indent=4, ensure_ascii=False)
json_fp.close()
img_list_fp.close()
print("with_out_xml_num:", with_out_xml_num)
if __name__ == '__main__':
img_list = '/workspace/Dataset/OpenSourceDataset/MaskDetection/imglist_val.txt'
jsonfile = '/workspace/Dataset/OpenSourceDataset/MaskDetection/imglist_val.json'
convert(img_list, jsonfile)
至此,启动模型训练的数据集构建完成。
B. 配置文件的选择&修改
选择一款经典的双阶段网络FasterRCNN-R50-FPN作为本次的训练模型。其中FasterRCNN为检测器,R50为特征提取网络backbone的名称resnet50,FPN为特征融合网络。模型配置文件路径及内容如下图所示。
可以看出,除了模型结构的配置文件faster_rcnn_r50_fpn.py,还包含一些其他的配置文件,如数据集的配置文件coco_detection.py,训练过程优化器,训练代数、学习率的配置文件schedule_1x.py,以及训练过程中一些runtime的设置default_runtime.py
模型训练整体配置文件的内容较多,为了方便修改与独立,建议先生成一个整合在一起的配置文件。可以直接启动单卡训练,自动生成一个完整的配置文件,即使由于没有更改数据集等相关信息会报错。
python tools/train.py /workspace/Code/mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --work-dir /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls
执行完成后,便会在指定的-work-dir下生成一个完成的配置文件,如下图所示。启动训练前将对这个配置文件进行修改。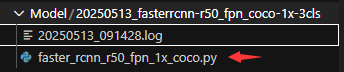
配置文件中,主要包含3大部分,如下图所示:
- 模型配置文件
model:包括特征提取网络backbone,特征融合网络neck,以及检测头head的相关设置和参数传递;- 需要修改类别数量
num_classes为数据集中的类别数量。此处将类别数量修改为num_classes=3,,共3个类。以及norm_cfg中关于BN的设置,单卡使用norm_cfg=dict(type='BN', requires_grad=True),,多卡使用norm_cfg=dict(type='SyncBN', requires_grad=True),。
- 需要修改类别数量
- 训练、验证、测试数据
data:包括数据类型,如CocoDataset;训练测试过程的pipeline,包含数据增强的相关设置;训练数据整合data:包括batchsize的设置,训练、验证、测试之间的dataloader设置,分辨率和相关CoCo文件。- 需要修改每张GPU样本的数量:
samples_per_gpu;训练、验证、测试使用的coco文件ann_file(voc转coco中生成的文件);训练、验证、测试图像的分辨率img_scale
- 需要修改每张GPU样本的数量:
- 训练过程的相关设置:包括优化器、学习率策略、最大训练代数等。
- 需要再
log_config中添加TensorBoard的Hookdict(type='TensorboardLoggerHook'),可以在work_dir下生成训练精度可视化的tensorboard文件。
完整的训练配置文件如下,可参考上述需要修改的内容进行调整。
- 需要再
# 1. 模型配置文件 包括类别数量num_class的设置
model = dict(
type='FasterRCNN',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='SyncBN', requires_grad=True), # 多卡用SyncBN 单卡用BN
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=3,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
train_cfg=dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
match_low_quality=True,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=-1,
pos_weight=-1,
debug=False),
rpn_proposal=dict(
nms_pre=2000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)),
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)))
# 2. 数据相关 数据类型 pipeline 等 data_root可置为空字符串
dataset_type = 'CocoDataset'
data_root = ''
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
## 2.1 训练 测试数据构成的pipeline
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(608, 608), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(608, 608),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]
## 2.2 整体训练 验证 测试过程中的数据构成 包括coco文件 batchsize 以及pipeline的设置
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='CocoDataset',
ann_file=
'/workspace/Dataset/OpenSourceDataset/MaskDetection/imglist_train.json',
img_prefix='',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(608, 608), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]),
val=dict(
type='CocoDataset',
ann_file=
'/workspace/Dataset/OpenSourceDataset/MaskDetection/imglist_val.json',
img_prefix='',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(608, 608),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
ann_file=
'/workspace/Dataset/OpenSourceDataset/MaskDetection/imglist_val.json',
img_prefix='',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(608, 608),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
])
]))
# 3. 训练过程的相关设置: 包括优化器 学习率策略 最大训练代数等
evaluation = dict(interval=1, metric='bbox') # 每轮都进行一次验证,验证评价标准为bbox
optimizer = dict(type='SGD', lr=0.0001, momentum=0.9, weight_decay=0.0001) # 优化器 学习率等相关设置
optimizer_config = dict(grad_clip=None)
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11]) # 在第8轮和11轮 降低学习率 线性warmup warmup持续迭代次数500
runner = dict(type='EpochBasedRunner', max_epochs=12) # 最大训练12个epoch 也就是1x
checkpoint_config = dict(interval=1) # 每代保存一个模型文件
log_config = dict(
interval=50,
hooks=[dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')]) # 添加TensorBoard记录
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None # 从头开始加载模型进行训练;
resume_from = None # 从上一次的位置加载模型文件,断点训练
workflow = [('train', 1)]
opencv_num_threads = 0
mp_start_method = 'fork'
auto_scale_lr = dict(enable=False, base_batch_size=16)
work_dir = '/workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls' # 工作路径:模型文件 / Tensorboard文件 保存路径
auto_resume = False
gpu_ids = [0]
C. 启动训练
启动训练之前,将./mmdetection/mmdet/datasets/coco.py中的训练类型由预设的COCO80类修改为训练的类别, 如下图所示。
在mmdetection目录下创建train.sh,根据显卡数量选择单卡训练或者多卡训练。
# 单卡训练
nohup python ./tools/train.py /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls/faster_rcnn_r50_fpn_1x_coco.py > /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls/train.log 2>&1 &
# 多卡训练
export CUDA_VISIBLE_DEVICES=0,1
nohup ./tools/dist_train.sh /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls/faster_rcnn_r50_fpn_1x_coco.py 2 > /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls/train.log 2>&1 &
多卡训练./tools/dist_train.sh主要涉及3个参数需要传递,模型配置文件CONFIG, GPU的数量GPUS;以及使用的端口PORT,该参数只需在一个环境内启动多个训练时需要才会因发生冲突需要修改,如果只启动一个训练,可直接使用默认,类似上述train.sh中,不传该参数。
并将train.sh添加可执行权限,chmod +x train.sh,便可以通过./train.sh启动训练。
D. 训练情况跟踪
日志跟踪
启动训练后,在指定的work_dir下会生成train.log记录训练过程中的相关信息。如下图所示,包含训练迭代过程中的损失和验证的精度bbox_mAP。
通过日志,通过每个epoch的mAP是否处于上升的状态,以及损失是否处于下降或者调整的状态进而判断模型训练是否有效。
对上述日志中相关字段的解析:
-
epoch: 第几轮训练 -
iter: 每轮训练中迭代的次数,一次迭代表示一个批次的图片处理 -
lr: 学习率 可以看出学习率先从很小的值到设定的1e-4,此处使用了warmup的策略,先进性热身 -
memory: 内存占用值, 之后单位是MB -
loss_cls: 分类损失 -
loss_bbox: boundingbox回归损失 -
loss: 整体损失 -
bbox_mAP: (默认)IoU=0.5 到 IoU=0.95, 每隔0.05个IoU计算一次AP,然后求平均值 -
bbox_mAP_50: IoU=0.5时的AP值 -
bbox_mAP_75: IoU=0.75时的AP值 IoU越大,对于目标检测的定位要求越高,mAP表现也会越低 -
bbox_mAP_s/m/l: 大中小三种不同尺度物体的AP值,此处大小的设定遵循COCO,即其中small是指物体面积小于32 x 32, medium是指面积在32 x 32 - 96 x 96 之间,large是指面积大于96 x 96
关于mmdetection验证过程中使用多少的IoU进行验证,以及验证的时候显示每个类别的AP,可以在./mmdetection/mmdet/datasets/coco.py中进行修改。 -
classwise: 设置为True,验证时会显示每个类别的AP,而不仅仅是mAP;
-
iou_thrs: 设置想要的阈值,默认为[0.50, 0.55,0.60, 0.65, 0.70, 0.75, 0.80, 0.85, 0.90, 0.95]这些阈值的AP取平均。

更改coco.py中evaluate的相关设置后,可以使用./tools/test.py对模型的精度进行复测。具体指令如下:
# config checkpoint work-dir eval
python tools/test.py /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls/faster_rcnn_r50_fpn_1x_coco.py /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls/epoch_12.pth --work-dir /workspace/Model/20250513_fasterrcnn-r50_fpn_coco-1x-3cls --eval bbox
由于修改classwise为True,在验证过程中增加了各类型的AP
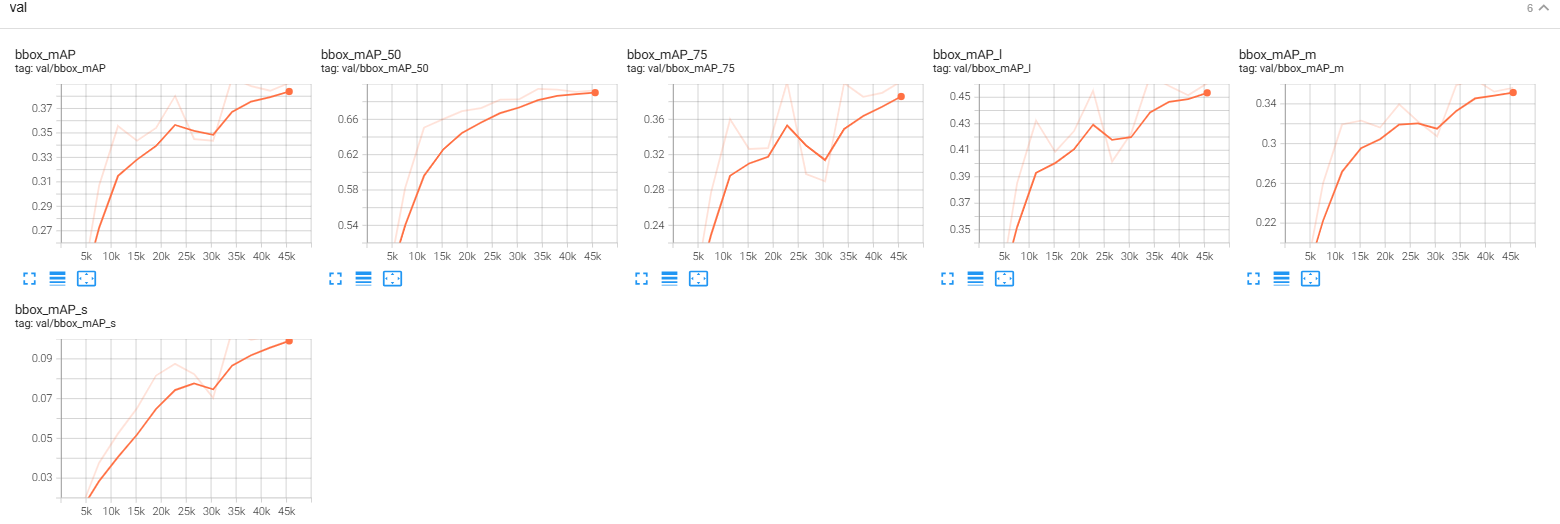
TensorBoard可视化跟踪
启动训练后,同时可以看到在work_dir下会生成一个tf_logs,其中会包含对应的事件文件,该文件在训练过程不断更新。
可以通过
tensorboard --logdir=./tf_logs --port 6006
对训练过程的情况进行可视化。
并在浏览器中输入http://localhost:6006,从中可以看出学习率的变化。
以及训练、验证过程中损失、精度的变化曲线。
批量测试
参考前文对图像进行推理,生成检测结果xml文件和检测结果图。从检测结果图中,可以看到对应的类别和得分。
[00.初入MMDetection之轻松掌握运行环境安装,实现模型推理 ]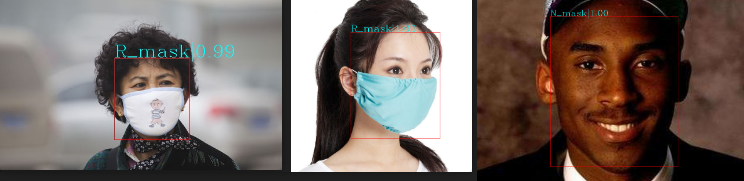


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)