LeNet - 5:卷积神经网络的起源、架构、应用及代码实现
文章目录
前言
在当今人工智能蓬勃发展的时代,卷积神经网络(CNN)已成为计算机视觉和深度学习领域的核心技术,广泛应用于图像分类、视频分析、语音识别等众多领域。而追溯CNN的发展历程,LeNet - 5作为其真正的开端,具有里程碑式的意义。1998年,Yann LeCun教授提出的LeNet - 5网络,尽管当时硬件条件有限,但为后续CNN的发展奠定了坚实基础。本文将深入探讨LeNet - 5的发展背景、网络架构、所使用的MNIST数据集以及具体的代码实现,带您全面了解这一经典卷积神经网络。
一、LeNet-5:卷积神经网络的开端与发展
1.1 卷积神经网络的发展背景与LeNet-5
卷积神经网络(CNN)是一种深度学习模型,其核心在于利用卷积运算处理图像、视频等数据,并在计算机视觉领域取得了广泛应用。
CNN 的发展可追溯至 1980 年代,当时 Yann LeCun (杨立昆) 及其团队开始探索如何利用神经网络识别手写数字。他们发现,通过卷积运算提取图像特征可显著提高神经网络的准确率。
1998 年,LeCun 训练的 LeNet-5 网络问世,标志着 CNN 的真正开端。 尽管当时硬件条件有限,但 LeNet-5 为后续 CNN 的发展奠定了基础。
2012 年,Hinton 的学生 Alex Krizhevsky 凭借 AlexNet 在 ILSVRC 2012 的 ImageNet 数据集上取得了突破。 AlexNet 将图像识别的准确率从传统的 70% 提升至 80% 以上。在此之前,图像识别主要依赖模式识别与机器学习结合的方法。AlexNet 的出现,标志着深度神经网络在图像识别领域的崛起,其核心在于对 LeNet 结构的强化和深度化。自 2012 年起,ImageNet 竞赛也主要转向采用深度学习方法。
随着计算机技术的飞速发展,CNN 在近年内持续演进。研究人员不断探索 CNN 的网络结构、训练方法及应用领域。如今,CNN 已成为计算机视觉和深度学习领域的核心模型。
CNN 在以下领域拥有广泛应用:
- 图像分类: 将图像归类至不同类别,如识别狗、猫等。
- 图像定位: 确定图像中物体的位置,例如识别狗、猫的具体位置。
- 视频分析: 分析视频内容,如检测运动目标、识别手势等。
- 语音识别: 识别语音中的单词或语句。
CNN 在这些任务中取得了显著进展,其准确率通常高于传统机器学习方法。随着技术的不断进步,CNN 的应用领域还将持续拓展。
LeNet-5 模型 由杨立昆(Yann LeCun)教授于 1998 年在论文《Gradient-Based Learning Applied to Document Recognition》中提出,是一种高效的手写体字符识别卷积神经网络。其实现过程如下图所示:
LeNet-5 神经网络架构图
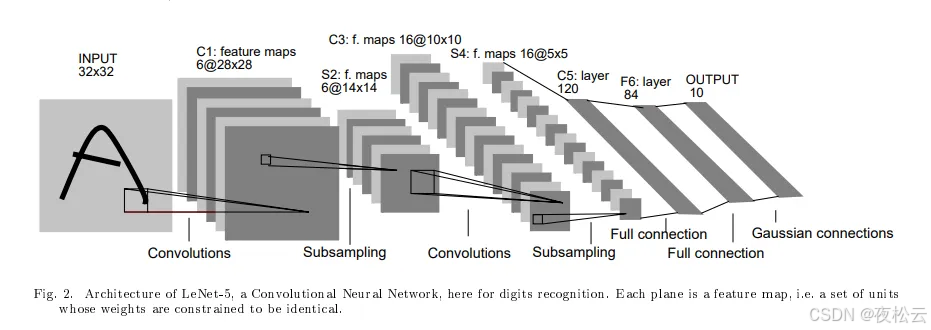
如上图所示,LeNet-5 结构简洁,其基本流程为:卷积层 -> 池化层 -> 卷积层 -> 池化层 -> 全连接层 -> 输出层。
降采样层(Subsampling Layer): 又称 池化层(Pooling Layer),主要用于减少特征图的空间尺寸,降低计算复杂度,并增强模型的平移不变性。
以下是整理后的内容:
二、网络架构
2.1 LeNet - 5 CNN 架构概述
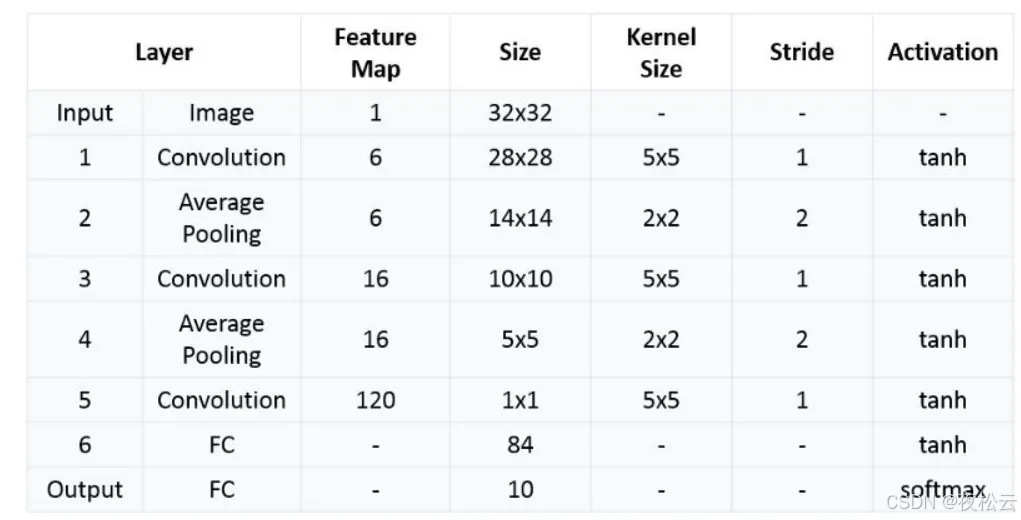
LeNet - 5 CNN 架构共有七层,由三个卷积层、两个子采样层(池化层)和两个全连接层组成。其基本流程为:卷积 -> 池化 -> 卷积 -> 池化 -> 全连接 -> 全连接 -> 输出。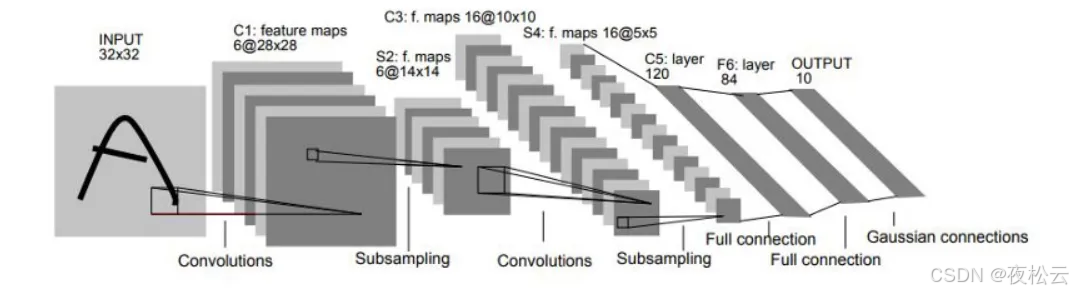
2.2 逐层分析
-
输入层
- 输入图片为单通道 32x32 的图像。若不符合要求,需要进行灰度化、重置大小以及图像参数归一化操作(将像素值从 0~255 变为 0~1)。
-
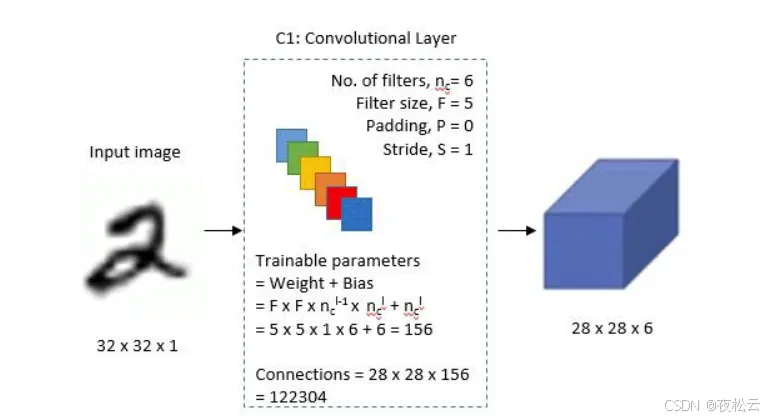
第一层:卷积层 1
-
输入:单通道 32x32 的图片。
-
卷积层参数:
- 滤波器(卷积核)个数 (n = 6)。
- 滤波器大小 (F = 5)。
- 填充 (P = 0)。
- 步幅 (S = 1)。
-
可训练参数计算:
- 权重数 = 卷积核大小×卷积核大小×输入通道数×输出通道数。
- 偏置数 = 输出通道数。
- 输出通道数 = 卷积核数。
- 总参数量 = F × F × C i × C o + C o = 5 × 5 × 1 × 6 + 6 = 156 = F\times F\times C_i\times C_o + C_o=5\times5\times1\times6 + 6 = 156 =F×F×Ci×Co+Co=5×5×1×6+6=156。
- 运算量计算:一次卷积运算的运算量为 156,卷积核水平和竖直滑动了 28 次,总运算量 C o n n e c t i o n s = 156 × 28 × 28 = 122304 Connections = 156\times28\times28 = 122304 Connections=156×28×28=122304。
-
输出:6 个 28x28 的特征图。
-
-
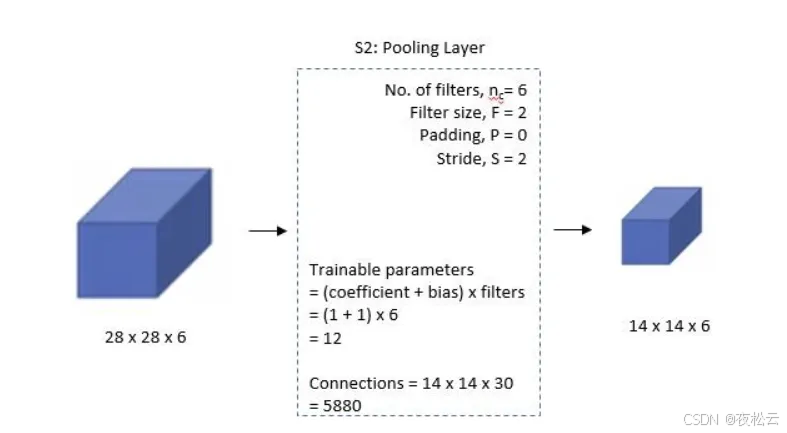
第二层:池化层 1
-
输入:上一层输出的 28x28x6 的特征图。
-
池化层参数:
- 池化核个数 (n = 6),输出 6 个通道。
- 池化核大小 (F = 2)。
- 不填充 (P = 0)。
- 步幅 (S = 2),与池化核大小相同。
-
说明:过去池化过程存在可训练参数,即把 2x2 区域的像素相加并乘以一个权重系数再加上一个偏置得到最终结果,但现在框架的池化层通常不包含训练参数。
-
输出:6 个 14x14 特征图。
-
-
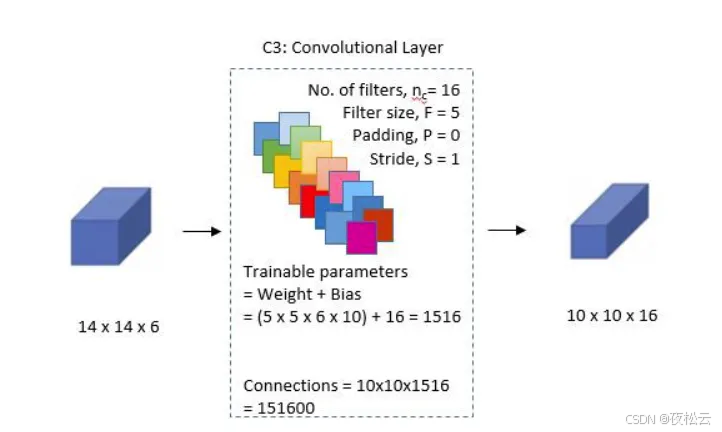
第三层:卷积层 2
-
卷积层参数:
- 卷积核个数 (n = 16),输出 16 个通道。
- 卷积核大小 (F = 5)。
- 不填充 (P = 0)。
- 步幅 (S = 1)。
-
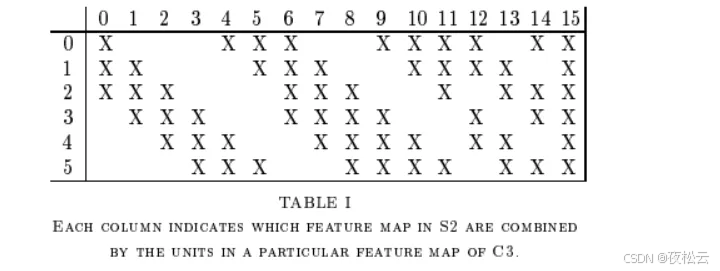
特殊之处:原作者制作该层时,卷积核和输入通道采用分组方式连接,每个卷积核使用部分输入通道做卷积。
-
输出:16 个 10 x 10 特征图。
-
-
第四层:池化层 2
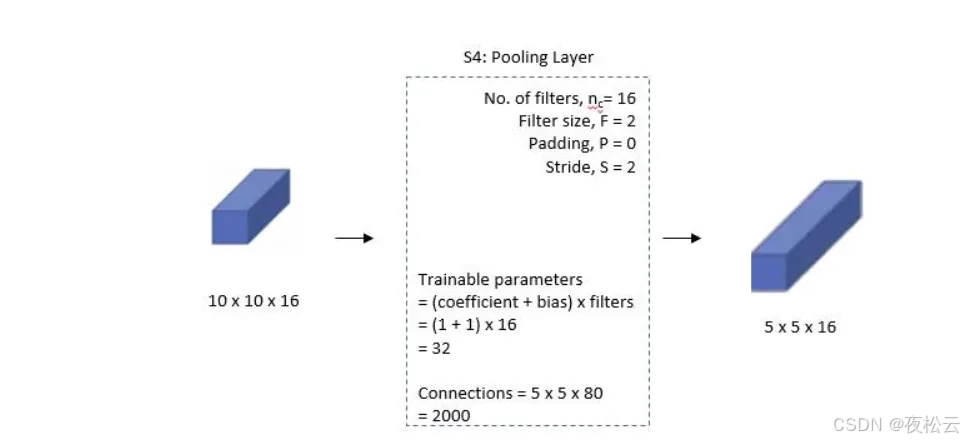
- 池化层参数:
- 池化核个数 (n = 16),输出 16 个通道。
- 池化核大小 (F = 2)。
- 不填充 (P = 0)。
- 步幅 (S = 2),与池化核大小相同。
- 输出:16 个 5x5 特征图。
- 池化层参数:
-
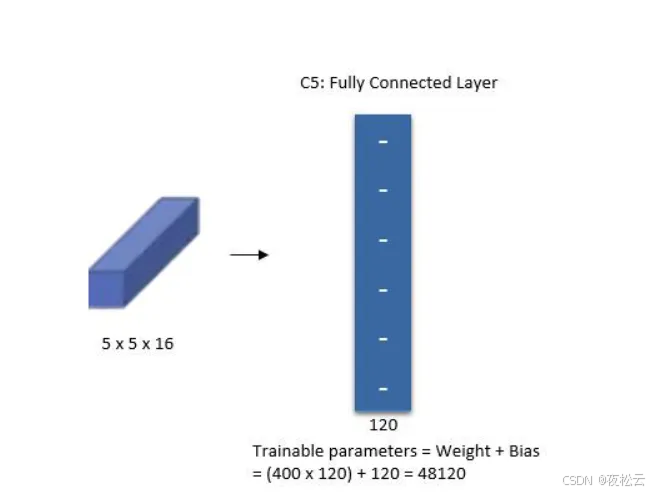
第五层:卷积层 3
-
实际情况:图中虽写全连接,但实际是卷积层(也可用展平方式,效果类似)。
-
输入:5x5x16。
-
卷积核:大小为 5。
-
输出:1x1x120。在使用 PyTorch 时,可通过展平(Flatten)再经过一个全连接层输出 120 个特征。
-
-
第六层:全连接层
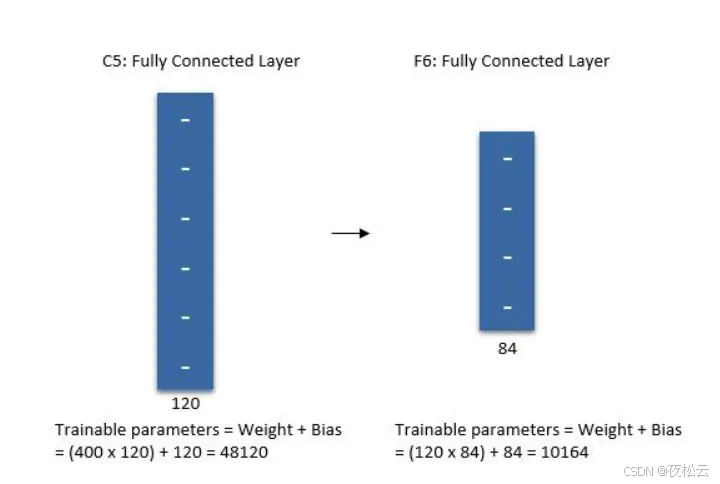
- 输入:上一层输出的 120 个特征点。
- 输出:84 个特征点。
-
第七层:输出层
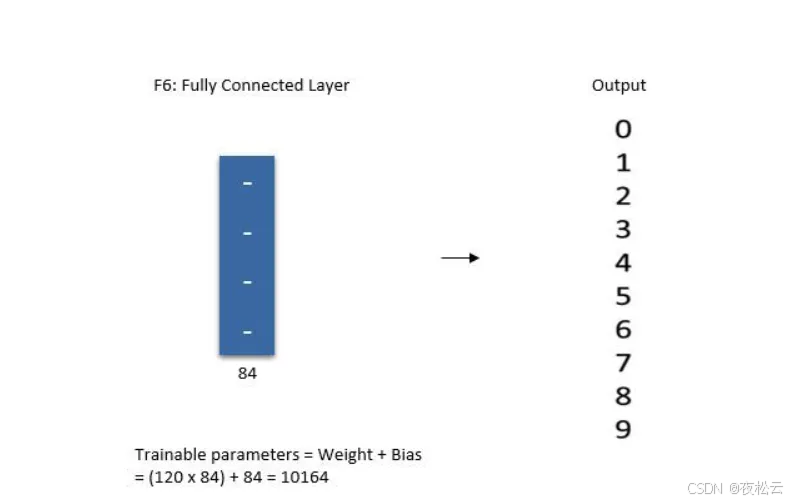
- 输出:0~9 这 10 个数字的分布概率。
-
完整架构
2.3 激活函数说明
每一层都有一个激活函数作为非线性激活,作者使用的是 tanh 和 softmax 函数:
- tanh 函数:形状类似 sigmoid,但结果分布在 -1 ~ 1 之间。
- softmax 函数:用于求概率分布,输出结果和为 1。
三、MNIST数据集
3.1 MNIST数据集概述
MNIST数据集(Modified National Institute of Standards and Technology database)是在机器学习和计算机视觉领域广泛使用的手写数字图像数据库,常被用于算法的测试和训练。该数据集涵盖了从0到9的手写数字的灰度图像,每张图像大小为28x28像素,数据集总共包含70000张图像,其中60000张用于训练,10000张用于测试。
3.2 数据集文件解析(以 train-images-idx3-ubyte 为例)
数据集下载:dataset
3.2.1 文件结构
train-images-idx3-ubyte 文件以特定的二进制格式存储训练图像数据,其结构如下:
| 位置 | 数据类型 | 描述 | 具体信息 |
|---|---|---|---|
| 前4字节 | 32位整数 | 魔数(图片类型的数) | 用于标识文件的类型和版本,可帮助程序正确解析文件内容 |
| 接着4字节 | 32位整数 | 图片的个数 | 对于训练集,该值为60000,表示文件中包含60000张手写数字图像 |
| 再接着4字节 | 32位整数 | 图片的行数 | 此值为28,表明每张图像的行数为28 |
| 再接着4字节 | 32位整数 | 图片的列数 | 此值为28,表明每张图像的列数为28 |
| 后续数据 | 单字节无符号整数 | 像素值 | 每个像素值的范围是0 - 255,0表示黑色,255表示白色,中间值表示不同程度的灰色。由于每张图像大小为28x28像素,所以每张图像对应28 * 28 = 784个像素值。对于60000张图像,后续共有60000 * 784个字节的数据 |
3.2.2 Python代码示例
以下是一个使用Python解析 train-images-idx3-ubyte 文件的示例代码:
import struct
import numpy as np
def read_mnist_images(file_path):
with open(file_path, 'rb') as f:
# 读取魔数
magic_number = struct.unpack('>I', f.read(4))[0]
# 读取图片数量
num_images = struct.unpack('>I', f.read(4))[0]
# 读取图片行数
num_rows = struct.unpack('>I', f.read(4))[0]
# 读取图片列数
num_cols = struct.unpack('>I', f.read(4))[0]
# 读取所有像素数据
image_data = f.read()
images = np.frombuffer(image_data, dtype=np.uint8)
images = images.reshape(num_images, num_rows, num_cols)
return images
# 替换为实际的文件路径
file_path = 'train-images-idx3-ubyte'
images = read_mnist_images(file_path)
print(f"图片数量: {images.shape[0]}")
print(f"图片大小: {images.shape[1]}x{images.shape[2]}")
在上述代码中,struct.unpack 函数用于从二进制文件中读取并解析32位整数,np.frombuffer 函数用于将二进制数据转换为NumPy数组,最后将数组重塑为合适的形状以表示图像数据。
通过上述解析,我们可以将MNIST数据集的图像数据加载到Python中,以便后续进行机器学习或计算机视觉的相关任务。
四、代码示例
# 1.实现LeNet5卷积神经网络
# 导入PyTorch库,用于构建和训练神经网络
import torch
# 导入NumPy库,用于进行数值计算
import numpy as np
# 导入PyTorch的神经网络模块
import torch.nn as nn
# 导入PyTorch的函数式接口,提供各种常用的函数
import torch.nn.functional as F
# 导入torchsummary库中的summary函数,用于打印模型结构
from torchsummary import summary
# 检查是否有可用的GPU,如果有则使用GPU,否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 打印当前使用的设备
print(device)
# 定义LeNet5卷积神经网络类,继承自nn.Module
class LetNet5(nn.Module):
def __init__(self):
# 调用父类的构造函数
super(LetNet5, self).__init__()
# 定义第一层卷积层
# in_channels:输入图像的通道数,这里是1(灰度图像)
# out_channels:经过卷积运算产生的通道数,这里是6
# kernel_size:卷积核大小,这里是5x5
# stride:卷积运算的步幅,这里是1
# padding:边界填充值,这里是2,因为输入的MNIST数据集图片是28x28的,填充后变为32x32
self.conv1 = torch.nn.Conv2d(in_channels=1, out_channels=6, kernel_size=(5, 5), stride=1, padding=2)
# 定义第一层平均池化层
# kernel_size:池化核大小,这里是2x2
# stride:池化运算的步幅,这里是2
self.pool1 = torch.nn.AvgPool2d(kernel_size=2, stride=2)
# 定义第二层卷积层
# in_channels:输入的通道数,这里是上一层输出的6个通道
# out_channels:经过卷积运算产生的通道数,这里是16
# kernel_size:卷积核大小,这里是5x5
# stride:卷积运算的步幅,这里是1
self.conv2 = torch.nn.Conv2d(in_channels=6, out_channels=16, kernel_size=(5, 5), stride=1)
# 定义第二层平均池化层
# kernel_size:池化核大小,这里是2x2
# stride:池化运算的步幅,这里是2
self.pool2 = torch.nn.AvgPool2d(kernel_size=2, stride=2)
# 定义第一个全连接层
# in_features:输入的特征数,这里是400
# out_features:输出的特征数,这里是120
self.fc1 = torch.nn.Linear(in_features=400, out_features=120)
# 定义第二个全连接层
# in_features:输入的特征数,这里是上一层输出的120
# out_features:输出的特征数,这里是84
self.fc2 = torch.nn.Linear(in_features=120, out_features=84)
# 定义第三个全连接层
# in_features:输入的特征数,这里是上一层输出的84
# out_features:输出的特征数,这里是10(对应10个类别)
self.fc3 = torch.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
# 进行第一次卷积运算
x = self.conv1(x)
# 对卷积结果使用tanh激活函数
# 然后进行第一次池化操作
x = self.pool1(F.tanh(x))
# 进行第二次卷积运算
# 对卷积结果使用tanh激活函数
# 然后进行第二次池化操作
x = self.pool2(F.tanh(self.conv2(x)))
# 在进行全连接前,需要将特征图展平为一维向量
# 使用view函数改变张量形状,-1表示自动计算该维度的大小,这里将每个样本展平为400个特征
x = x.view(-1, 400)
# 通过第一个全连接层,并使用tanh激活函数
x = F.tanh(self.fc1(x))
# 通过第二个全连接层,并使用tanh激活函数
x = F.tanh(self.fc2(x))
# 通过第三个全连接层
x = self.fc3(x)
return x
# 打印模型结构(这里注释掉了,可以取消注释查看模型结构)
# model = LetNet5()
# summary(model.to(device), input_size=(1, 28, 28))
# 创建LeNet5模型的实例
model = LetNet5()
# 生成一个随机输入张量,模拟5个样本的输入,每个样本是1通道、28x28的图像
x = torch.rand(5, 1, 28, 28)
# 将输入张量传入模型,得到输出
y = model(x)
# 对模型的输出使用softmax函数,将输出转换为概率分布
result = F.softmax(y, dim=1)
# 将结果从PyTorch张量转换为NumPy数组,并找出每个样本概率最大的类别索引
print(np.argmax(result.detach().numpy(), axis=1))
总结
本文围绕LeNet - 5卷积神经网络展开了全面而深入的介绍。首先阐述了CNN的发展背景,LeNet - 5作为CNN的开端,在手写数字识别领域开启了新的篇章,后续AlexNet的出现更是推动了深度神经网络在图像识别领域的崛起。接着详细剖析了LeNet - 5的网络架构,包括七层结构的逐层分析以及激活函数的说明。随后介绍了MNIST数据集,这是用于训练和测试LeNet - 5的常用数据集,并给出了数据集文件的解析代码。最后,提供了使用PyTorch实现LeNet - 5的完整代码示例。通过本文的学习,读者能够系统地了解LeNet - 5的原理、架构和实现方式,为进一步研究和应用卷积神经网络奠定基础。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)