翻译:CarPlanner:用于自动驾驶大规模强化学习的一致性自回归轨迹规划(二)
本文提出CarPlanner,一种基于强化学习的自回归轨迹规划框架。该方法通过模式选择器将驾驶行为分解为纵向速度与横向路线模式,使用Transformer解码器融合多模态特征,并采用规则增强选择器优化轨迹输出。实验表明,在nuPlan数据集上,该方法在非反应式环境中全面超越现有规则型、模仿学习和强化学习方法,闭环得分提升显著。消融研究验证了奖励设计和不变量视图模块的有效性。研究同时揭示了强化学习在
3.3.2. 模式选择器
该模块以 s_0 和纵向 - 横向分解模式信息作为输入,并输出每种模式的概率。模式数量 Nmode = NlatNlon 。
速度-路线分解模式。为了捕捉纵向行为,我们生成 N_{\text {lon}} 个模式,这些模式代表与每个模式相关联的轨迹的平均速度。每个纵向模式 c_{\text {lon},j} 定义为 \frac {j}{N_{\text {lon}}} 的标量值,并沿维度 D 重复。因此,纵向模式的维度为 N_{\text {lon}} \times D 。对于横向行为,我们使用图搜索算法从地图中识别出 N_{\text {lat}} 条可能的路线,这些路线对应于自动驾驶车辆可用的车道。这些路线的维度为 N_{\text {lat}} \times N_r \times D_m 。我们使用另一个 PointNet 来聚合每条路线上的 N_r 个点的特征,生成维度为 N_{\text {lat}} \times D 的横向模式。为了创建全面的模式表示 c,我们将横向和纵向模式相结合,得到的组合维度为 N_{\text {lat}} \times N_{\text {lon}} \times 2D 。为了将此模式信息与其它特征维度对齐,我们将其通过一个线性层,映射回 N_{\text {lat}} \times N_{\text {lon}} \times D 。
基于查询的 Transformer 解码器。此解码器用于融合模式特征与从 s_0 衍生出的地图和代理特征。在此框架中,模式充当查询,而地图和代理信息则作为键和值。通过多层感知机(MLP)对更新后的模式特征进行解码,以生成每个模式的得分,随后使用 softmax 操作进行归一化。
3.3.3. 轨迹生成器
此模块以自回归方式运行,根据当前状态 st 和一致的模式信息 c,反复解码出自动驾驶车辆 at 的下一个姿态。
不变视图模块(IVM)。在将模式和状态输入网络之前,我们对其进行预处理以消除时间信息。对于状态 st 中的地图和代理信息,我们选择距离当前自身位置最近的 K 个最近邻(KNN),并将这些信息输入策略中。K 分别设置为地图和代理元素数量的一半。对于捕捉横向行为的路线,我们过滤掉其中最近点为当前自身位置的路段,保留 Kr 个点。在这种情况下,Kr 设置为一条路线中 Nr 个点的四分之一。最后,我们将路线、代理和地图的位置转换为当前时间步 t 自身车辆的坐标系。我们从当前时间步 t 中减去历史时间步 t - H : t,得到时间步范围为 -H : 0。
基于查询的 Transformer 解码器。我们采用与模式选择器相同的骨干网络架构,但查询维度不同。由于 IVM 以及不同模式产生不同状态的事实,地图和智能体信息无法在模式之间共享。因此,我们为每个单独的模式融合信息。具体而言,查询维度为 1×D,而键和值的维度为 (N + N_{m})×D。输出特征维度仍为 1×D。需要注意的是,Transformer 解码器能够并行处理来自多个模式的信息,从而无需依次处理每个模式。
策略输出。模式特征由两个不同的头进行处理:策略头和价值头。每个头都包含自己的多层感知机(MLP),用于生成动作分布的参数和对应的价值估计。我们采用高斯分布来建模动作分布,在训练期间从该分布中采样动作。而在推理期间,我们则利用该分布的均值来确定动作。
3.3.4. 规则增强型选择器
此模块仅在推理阶段使用,其输入为初始状态 s_0 、多模态的自身规划轨迹以及各代理的预测未来轨迹。它会计算诸如安全性、进度、舒适度等驾驶相关指标。通过规则基础得分与模式选择器提供的模式得分的加权求和,得出一个综合得分。得分最高的自身规划轨迹将被选为规划器的输出。
3.4. 培训
我们首先训练非反应式转换模型,并在训练模式选择器和轨迹生成器期间冻结其权重。我们不将所有模式都输入生成器,而是采用赢家通吃的策略,即根据自身的真实轨迹分配一个正模式,并将其作为轨迹生成器的条件。
模式分配。对于横向模式,我们将最接近自身真实轨迹终点的路线分配为正向横向模式。对于纵向模式,我们将纵向空间划分为 N_{\text {lon}} 个区间,并将包含真实轨迹终点的区间分配为正向纵向模式。
奖励函数。为了应对各种场景,我们将自身未来姿态与真实值之间的负位移误差(DE)用作通用奖励。我们还引入了额外的项来提高轨迹质量:碰撞率和可行驶区域合规性。如果未来姿态发生碰撞或超出可行驶区域,则奖励设为 -1;否则设为 0。
模式丢弃。在某些情况下,自我(ego)没有可遵循的路径。然而,由于路径在 Transformer 中充当查询,路径的缺失可能会导致不稳定或危险的输出。为缓解这一问题,我们实施了一种
在训练期间采用模式丢弃模块,该模块会随机屏蔽路径,以防止过度依赖这些信息。
损失函数。对于选择器,我们使用交叉熵损失,即正模式的负对数似然以及一个回归自身真实轨迹的辅助任务。对于生成器,我们使用 PPO [31] 损失,它由三部分组成:策略改进、价值估计和熵。完整描述请参见补充材料。
4. Experiments
4.1. 实验设置
数据集与模拟器。我们使用 nuPlan [2],这是一个用于研究自动驾驶轨迹规划的大规模闭环平台,来评估我们方法的有效性。nuPlan 数据集包含由人类专家驾驶员在 4 个不同城市收集的超过 1500 小时的驾驶日志数据。它涵盖了诸如车道跟随与变更、左转与右转、穿越交叉路口和公交站、环岛、与行人互动等复杂多样的场景。作为一个闭环平台,nuPlan 提供了一个模拟器,该模拟器使用数据集中的场景作为初始化。在模拟过程中,交通参与者由日志回放(非反应式)或 IDM [37] 策略(反应式)控制。而自动驾驶车辆则由用户提供的规划器控制。模拟器持续 15 秒,以 10Hz 的频率运行。在每个时间戳,模拟器都会向规划器查询规划轨迹,该轨迹由 LQR 控制器跟踪,以生成控制指令来驱动自动驾驶车辆。
基准和指标。我们使用两个基准:由 PlanTF [4] 提供的 Test14-Random 和由 PDM [7] 提供的 Reduced-Val14,用于与其他方法进行比较以及分析我们方法中的设计选择。Test14-Random 包含 261 个场景,而 Reduced-Val14 包含 318 个场景。
我们使用官方 nuPlan 开发工具包† 提供的闭环得分(CLS)来评估所有方法的性能。CLS 得分涵盖了安全性(S-CR、S-TTC)、可行驶区域合规性(S-Area)、进度(S-PR)、舒适性等多个方面。根据交通参与者的不同行为类型,CLS 细分为 CLS-NR(非反应型)和 CLS-R(反应型)。
实现细节。我们遵循 PDM [7] 构建训练集和验证集。训练集大小为 176,218,涵盖了所有可用的场景类型,每种类型有 4,000 个场景。验证集大小为 1,118,包含 14 种类型的 100 个场景。我们在 2 块 NVIDIA 3090 GPU 上训练所有模型,每个 GPU 的批处理大小为 64。我们使用 AdamW 优化器,初始学习率为 1e-4,当验证集损失不再下降时降低学习率,耐心值为 0,降低因子为 0.3。对于强化学习训练
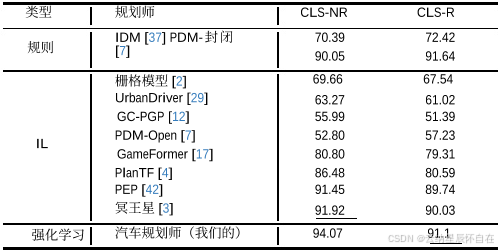
表 1.在 Test14-Random 中与最新技术的比较。根据轨迹生成器的类型,所有方法被分为规则型、强化学习型和模仿学习型。最佳结果以粗体显示,次佳结果以下划线显示。
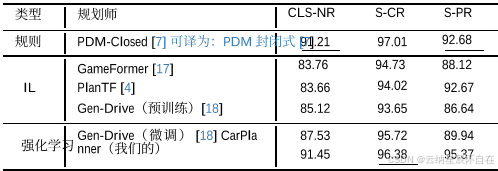
表 2. 在具有非反应性交通代理的 Reduced-Val14 中与最先进方法的比较。
我们将折扣因子 γ 设为 0.1,广义优势估计(GAE)参数 λ 设为 0.9。价值损失、策略损失和熵损失的权重分别设为 3、100 和 0.001。纵向模式的数量设为 12,横向模式的最大数量设为 5。
4.2. 与最先进方法的比较
最先进的方法。我们根据轨迹生成器的类型将这些方法分为规则、模仿学习(IL)和强化学习(RL)三类。(1)PDM [7] 在 nuPlan 挑战赛 2023 中胜出,其基于模仿学习和基于规则的变体分别被标记为 PDM-Open 和 PDM-Closed。PDM-Closed 遵循生成-选择框架,其中 IDM 用于生成多个候选轨迹,基于规则的选择器则根据安全性、进度和舒适性来选择最佳轨迹。(2)PLUTO [3] 同样遵循生成-选择框架,并使用对比模仿学习来整合各种数据增强技术,训练生成器。(3)Gen-Drive [18] 是一项同期工作,它采用预训练-微调流程,其中模仿学习用于预训练基于扩散的规划器,强化学习则基于由 AI 偏好训练的奖励模型来微调去噪过程。
结果。我们在 Tab. 1 和 Tab. 2 中展示了在 Test14-Random 和 Reduced-Val14 基准测试中,我们的方法与最先进方法的比较情况。总体而言,我们的 CarPlanner 表现更优,尤其是在非反应式环境中。
在非反应性环境中,我们的方法在所有指标上均取得了最高分,与 PDM-Closed 和 PLUTO 相比分别提高了 4.02 和 2.15,这证明了强化学习的潜力以及其优越的性能。
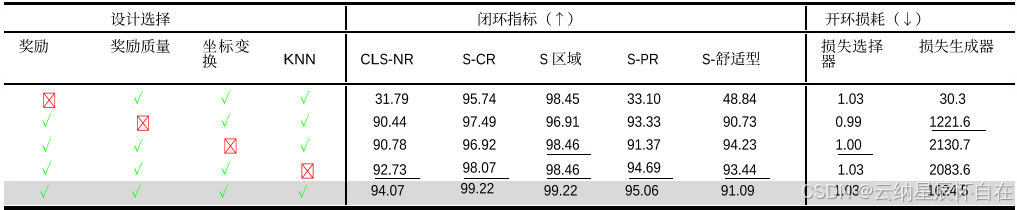
表 3.关于强化学习训练中设计选择的消融研究。结果来自 Test14 随机非反应性基准测试。
此外,在表 2 中,CarPlanner 在进度指标 S-PR 上相较于 PDM-Closed 有显著提升,并且碰撞指标 S-CR 相当,这表明我们的方法能够在提高驾驶效率的同时保持驾驶安全。重要的是,我们没有应用强化学习中常见的任何技术,如数据增强 [3, 4] 和自我历史掩码 [11],这突显了我们方法解决闭环任务的内在能力。
在反应式环境中,虽然我们的方法表现良好,但略逊于 PDM-Closed。这种差异的产生是因为我们的模型仅在非反应式环境中进行训练,并未与反应式环境中使用的 IDM 策略进行交互;因此,在测试期间,我们的模型对反应式智能体产生的干扰的适应性较差。
4.3. 消融研究
我们研究了强化学习训练中不同设计选择的影响。结果如表 3 所示。
奖励项的影响。仅使用质量奖励时,规划器倾向于生成静态轨迹,并且进度指标较低。这是因为自动驾驶车辆起始时处于安全、可行驶的状态,但向前行驶存在碰撞风险或驶离可行驶区域的风险。另一方面,当质量奖励与 DE 奖励结合使用时,与单独使用 DE 奖励相比,闭环指标有了显著提升。例如,S-CR 指标从 97.49 上升到 99.22,S-Area 指标从 96.91 上升到 99.22。这些改进表明质量奖励鼓励了安全且舒适的驾驶行为。
IVM 的有效性。结果表明,IVM 中的坐标变换和 KNN 技术显著改善了闭环指标和发电机损耗。例如,采用坐标变换技术后,整体闭环得分从 90.78 提升至 94.07,S-PR 从 91.37 升至 95.06。这些改进归因于强化学习中价值估计精度的提高,从而实现了闭环中的通用驾驶。
4.4. Extention to IL
除了为强化学习(RL)训练进行设计之外,我们还将 CarPlanner 扩展以纳入模仿学习(IL)。我们进行了严格的分析,以比较在 IL 和 RL
训练中各种设计选择的效果,总结见表 4。我们的研究结果表明,尽管模式丢弃和选择器辅助任务对 IL 和 RL 训练都有帮助,但通常在 IL 中有效的自我历史丢弃和骨干网络共享对于 RL 来说不太适用。
自我历史数据丢弃。先前的研究 [1, 3, 4, 11] 表明,通过模仿学习训练的规划器可能过度依赖过去的姿态,而忽视环境状态信息。为解决这一问题,我们将 ChauffeurNet [1] 和 PlanTF [4] 中的技术结合到一个自我历史数据丢弃模块中,随机遮蔽自我历史姿态和当前速度,以缓解因果混淆问题。
我们的实验证实,自我历史丢弃对模仿学习训练有益,因为它能提升诸如 S-CR 和 S-Area 等闭环指标的性能。然而,在强化学习训练中,我们观察到自我历史丢弃对优势估计产生了负面影响,这显著影响了生成器损失中的价值部分,导致闭环性能下降。这表明强化学习训练通过揭示与奖励信号一致的因果关系,自然地解决了模仿学习中固有的因果混淆问题,因为奖励信号明确编码了任务导向的偏好。这种能力凸显了强化学习在基于学习的规划方面突破局限的潜力。
骨干网络共享。这种选择在基于模仿学习(IL)的多模态规划器中经常被采用,它促进了跨任务的特征共享,从而提高泛化能力。虽然骨干网络共享有助于模仿学习,通过平衡轨迹生成器和选择器的损失,但我们发现它对强化学习(RL)的训练产生了不利影响。具体而言,在强化学习中,骨干网络共享导致轨迹生成器和选择器的损失都更高,这表明来自每个任务的梯度相互干扰。强化学习中轨迹生成和选择任务的目标不同,似乎存在冲突,从而降低了整体策略性能。因此,在我们的强化学习框架中避免使用骨干网络共享,以保持任务特定的梯度流并提高策略质量。
4.5. 定性结果
我们提供定性结果如图 3 所示。在此场景中,自动驾驶车辆需要在绕行行人时执行右转操作。在这种情况下,我们的方法表现出了平稳、高效的特点。从 tsim0 秒到 tsim9 秒,所有方法都在等待行人过马路。在 tsim10 秒时,一名意外的行人折返并准备再次过马路。PDM-Closed 是
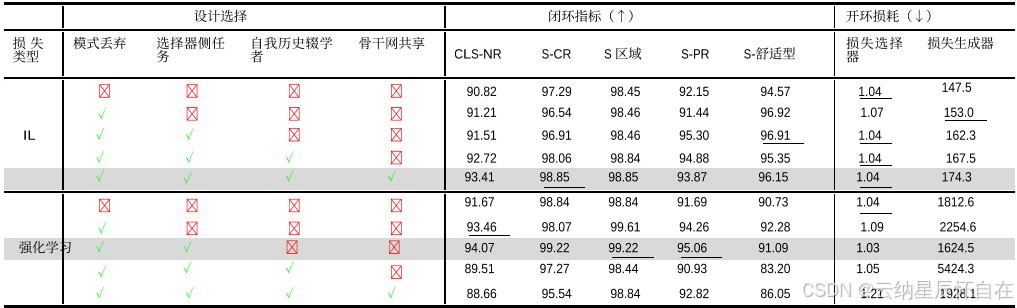
表 4. 使用我们的 CarPlanner 时不同组件对 IL 和 RL 损失的影响。结果来自 Test14 随机非反应性基准测试。
|
图 3.在非反应性环境中对 PDM-Closed 和我们的方法进行定性比较。该场景标注为 |
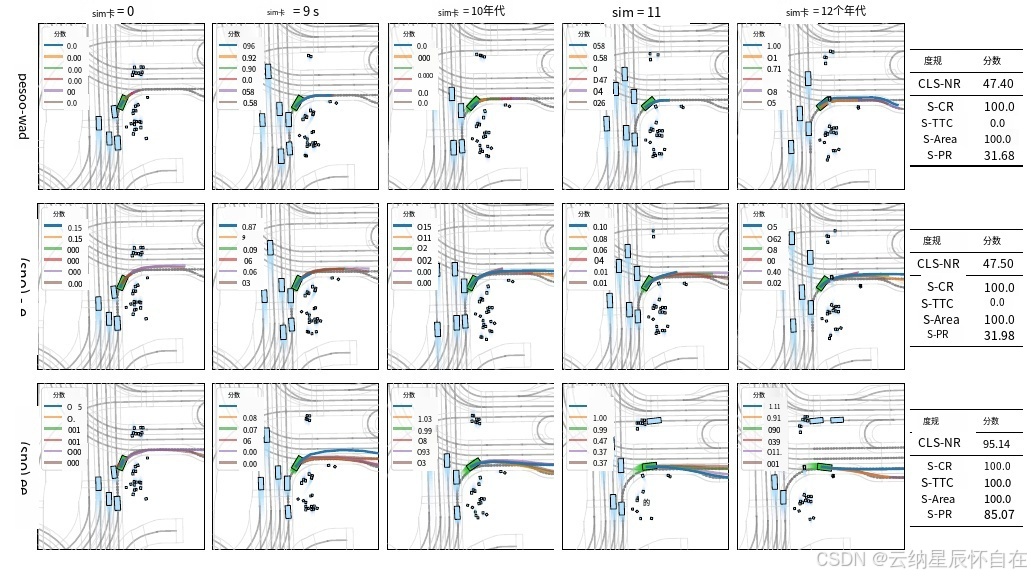
等待行人通过。在每张拍摄的图像中,主车被标记为绿色。交通参与者被标记为天蓝色。蓝色折线图表示主车规划的行驶轨迹。
在这种情况下,未意识到这一状况的车辆采取了紧急制动,但仍与行人发生了碰撞。相比之下,我们的 IL 变体能够感知行人的动作,从而实施了制动操作。不过,它仍然离行人很近。而我们的 RL 方法则通过提前至 tsim = 9 秒启动,成功避开了这一危险,并取得了最高的进度和安全指标。
5. Conclusion
在本文中,我们介绍了 CarPlanner,这是一种面向大规模强化学习训练的一致性自回归规划器。得益于所提出的框架,我们训练出了一种基于强化学习的规划器,其性能优于现有的基于强化学习、基于模仿学习和基于规则的最先进方法。此外,我们
还提供了分析,指出了模仿学习和强化学习的特点,突显了强化学习在基于学习的规划方面进一步发展的潜力。
局限性和未来工作。强化学习需要精心设计,并且容易受到输入表示的影响。强化学习可能会过度拟合其训练环境,并在未见过的环境中出现性能下降的情况[21]。我们的方法利用专家辅助的奖励设计来引导探索。然而,这种方法可能会限制强化学习的全部潜力,因为它本质上依赖于专家演示,并可能阻碍发现超越人类专业知识的解决方案。未来的工作旨在开发能够克服这些局限性的鲁棒强化学习算法,从而实现自主探索和在各种环境中进行泛化。
6. 致谢
非常感谢王景科的有益讨论以及所有审稿人对论文的改进。本研究得到了浙江省自然科学基金(项目编号:LD24F030001)和国家自然科学基金(项目编号:62373322)的支持。
参考文献
[1] Mayank Bansal, Alex Krizhevsky, and Abhijit Ogale. Chauf- feurnet: Learning to drive by imitating the best and synthe- sizing the worst. In Proc. of Robotics: Science and Systems, 2019. 3, 7
[2] Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based plan- ning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810, 2021. 2, 6, 12
[3] Jie Cheng, Yingbing Chen, and Qifeng Chen. Pluto: Push- ing the limit of imitation learning-based planning for au- tonomous driving. arXiv preprint arXiv:2404.14327, 2024. 3, 6, 7, 12, 13
[4] Jie Cheng, Yingbing Chen, Xiaodong Mei, Bowen Yang, Bo Li, and Ming Liu. Rethinking imitation-based planners for autonomous driving. In Proc. of the IEEE Intl. Conf. on Robotics & Automation, pages 14123–14130. IEEE, 2024. 3, 6, 7
[5] Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing. IEEE Trans. on Pattern Analysis and Machine Intelli- gence (TPAMI), 2022. 3
[6] Ignasi Clavera, Yao Fu, and Pieter Abbeel. Model- augmented actor-critic: Backpropagating through paths. In Proc. of the Int. Conf. on Learning Representations, 2020.15
[7] Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with misconceptions about learning- based vehicle motion planning. In Proc. of the Conf. on Robot Learning, 2023. 6
[8] Pim De Haan, Dinesh Jayaraman, and Sergey Levine. Causal confusion in imitation learning. Proc. of the Advances in Neural Information Processing Systems, 32, 2019. 1, 3
[9] Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R Qi, Yin Zhou, et al. Large scale interactive motion forecasting for autonomous driving: The waymo open mo- tion dataset. In Proc. of the IEEE/CVF Intl. Conf. on Com- puter Vision, pages 9710–9719, 2021. 2, 12
[10] Jiyang Gao, Chen Sun, Hang Zhao, Yi Shen, Dragomir Anguelov, Congcong Li, and Cordelia Schmid. Vectornet: Encoding hd maps and agent dynamics from vectorized rep- resentation. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pages 11525–11533, 2020.3
[11] Ke Guo, Wei Jing, Junbo Chen, and Jia Pan. CCIL: Context- conditioned imitation learning for urban driving. In Proc. of Robotics: Science and Systems, 2023. 1, 7
[12] Marcel Hallgarten, Martin Stoll, and Andreas Zell. From prediction to planning with goal conditioned lane graph traversals. arXiv preprint arXiv:2302.07753, 2023. 6
[13] Nicklas A Hansen, Hao Su, and Xiaolong Wang. Tem- poral difference learning for model predictive control. In Proc. of the Intl. Conf. on Machine Learning, pages 8387– 8406. PMLR, 2022. 15
[14] Xiangkun He, Haohan Yang, Zhongxu Hu, and Chen Lv. Robust lane change decision making for autonomous vehi- cles: An observation adversarial reinforcement learning ap- proach. IEEE Transactions on Intelligent Vehicles, 8(1):184– 193, 2022. 3
[15] John Houston, Guido Zuidhof, Luca Bergamini, Yawei Ye, Long Chen, Ashesh Jain, Sammy Omari, Vladimir Iglovikov, and Peter Ondruska. One thousand and one hours: Self-driving motion prediction dataset. In Proc. of the Conf. on Robot Learning, pages 409–418, 2021. 2
[16] Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pat- tern Recognition, pages 17853–17862, 2023. 1
[17] Zhiyu Huang, Haochen Liu, and Chen Lv. Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving. In Proc. of the IEEE/CVF Intl. Conf. on Computer Vision, pages 3903–3913, 2023. 2, 3, 6, 13
[18] Zhiyu Huang, Xinshuo Weng, Maximilian Igl, Yuxiao Chen, Yulong Cao, Boris Ivanovic, Marco Pavone, and Chen Lv. Gen-drive: Enhancing diffusion generative driving poli- cies with reward modeling and reinforcement learning fine- tuning. arXiv preprint arXiv:2410.05582, 2024. 2, 6, 12
[19] Julian Ibarz, Jie Tan, Chelsea Finn, Mrinal Kalakrishnan, Peter Pastor, and Sergey Levine. How to train your robot with deep reinforcement learning: lessons we have learned. Intl. Journal of Robotics Research, 40(4-5):698–721, 2021.1
[20] Chiyu Jiang, Andre Cornman, Cheolho Park, Benjamin Sapp, Yin Zhou, Dragomir Anguelov, et al. Motiondiffuser: Controllable multi-agent motion prediction using diffusion. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pat- tern Recognition, pages 9644–9653, 2023. 2
[21] Robert Kirk, Amy Zhang, Edward Grefenstette, and TimRockt¨aschel. A survey of zero-shot generalisation in deep reinforcement learning. Journal of Artificial Intelligence Re- search, 76:201–264, 2023. 8
[22] Edouard Leurent and Jean Mercat. Social attention for au- tonomous decision-making in dense traffic. arXiv preprint arXiv:1911.12250, 2019. 3
[23] Guofa Li, Yifan Yang, Shen Li, Xingda Qu, Nengchao Lyu, and Shengbo Eben Li. Decision making of autonomous ve- hicles in lane change scenarios: Deep reinforcement learn- ing approaches with risk awareness. Transportation research part C: emerging technologies, 134:103452, 2022. 3

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)