【三维重建】【3DGS系列】【深度学习】3DGS的代码讲解之COLMAP内容处理模块解析
【三维重建】【3DGS系列】【深度学习】3DGS的代码讲解之COLMAP内容处理模块解析
文章目录
前言
在详细解析3DGS代码之前,首要任务是成功运行3DGS代码【理论基础及代码运行(win11下)解析参考教程】,后续学习才有意义。本博文对COLMAP内容处理模块代码进行解析,colmap_loader是用于解析COLMAP三维重建输出文件内容Python处理模块。其他模块代码后续的博文将会陆续讲解。这里只做colmap_loader相关模块的代码解析。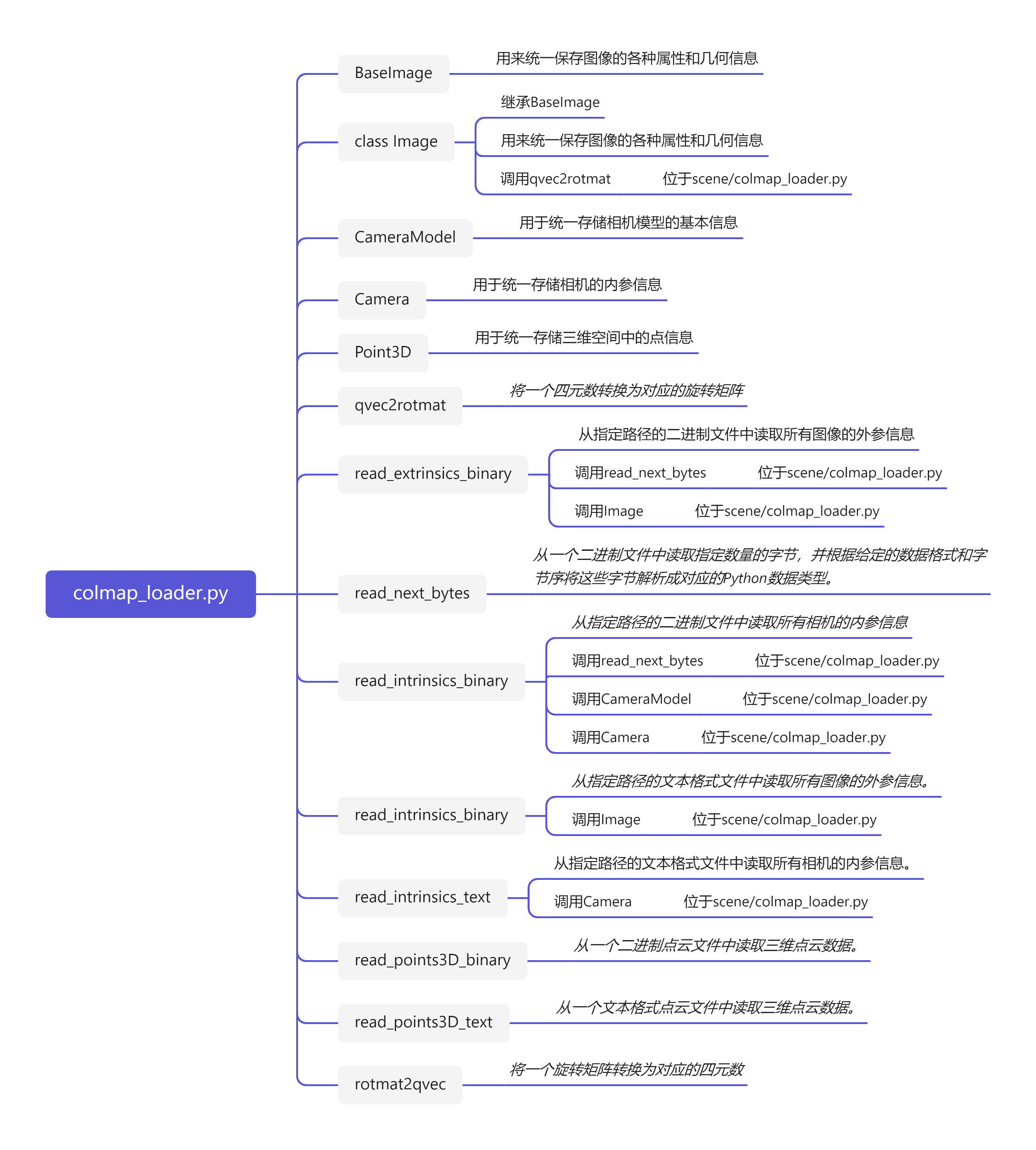
read_extrinsics_binary
从一个给定路径的二进制文件中读取多个图像的外参信息,并将这些信息存储在一个字典中返回。
外参信息包括每个图像的旋转四元数、平移向量、相机ID、图像名称、2D特征点坐标及对应的3D点ID。适用于处理COLMAP等三维重建系统生成的images.bin文件。
def read_extrinsics_binary(path_to_model_file):
"""
从指定路径的二进制文件中读取所有图像的外参信息
@param path_to_model_file:包含图像外参信息的二进制文件的路径
@return:返回包含每个图像唯一标识符与对应外参信息的对象的字典
"""
images = {} # 用于存储从文件中读取的所有图像的信息,便于后续通过image_id快速访问
with open(path_to_model_file, "rb") as fid: # 读取二进制文件
# Q代表8字节64位无符号长整型
num_reg_images = read_next_bytes(fid, 8, "Q")[0] # 获取图像的总数
for _ in range(num_reg_images): # 遍历读取每张图像的信息
# idddddddi i代表4字节32位有符号整数,d代表8字节64位双精度浮点数:4+8*7+4=64字节
binary_image_properties = read_next_bytes(
fid, num_bytes=64, format_char_sequence="idddddddi") # 读取图像的基本属性
image_id = binary_image_properties[0] # 图片ID,唯一标识符
qvec = np.array(binary_image_properties[1:5]) # 四元数:从世界坐标系到相机坐标系的旋转,长度为4
tvec = np.array(binary_image_properties[5:8]) # 平移向量:从世界坐标系到相机坐标系的平移,长度为3
camera_id = binary_image_properties[8] # 当前图像使用的相机模型ID
image_name = "" # 当前图像文件名
# c代表1字节8位字符
current_char = read_next_bytes(fid, 1, "c")[0] # 图像名起始字符
while current_char != b"\x00": # 图像名是可变长字符串,以\x00(空字符)结尾
image_name += current_char.decode("utf-8") # 将每个字符解码为UTF-8字符串并拼接成完整文件名
current_char = read_next_bytes(fid, 1, "c")[0] # 每次读取1字节字符,直到遇到空字符为止
# Q代表8字节64位无符号长整型
num_points2D = read_next_bytes(fid, num_bytes=8,
format_char_sequence="Q")[0] # 当前图像包含的2D特征点数量
# ddq d代表8字节64位双精度浮点数,q代表8字节64位有符号长整型:8*2+8=24字节,再乘2D点数量
x_y_id_s = read_next_bytes(fid, num_bytes=24*num_points2D,
format_char_sequence="ddq"*num_points2D) # 所有2D点的x,y坐标及对应的3D点ID
# 数据是xyzxyzxyz的重复格式,所以需每隔3个再取
xys = np.column_stack([tuple(map(float, x_y_id_s[0::3])),
tuple(map(float, x_y_id_s[1::3]))]) # 提取所有2D点的x和y值并合并为(N,2)的二维数组
point3D_ids = np.array(tuple(map(int, x_y_id_s[2::3]))) # 提取所有2D点对应3D点ID,转换为一维整数数组
# 当前图像的外参相关数据:包含图像ID,旋转四元数,平移矩阵,所属相机ID,图像名称,图像2D特征点xy坐标,2D特征点对应的3D点ID
images[image_id] = Image(
id=image_id, qvec=qvec, tvec=tvec,
camera_id=camera_id, name=image_name,
xys=xys, point3D_ids=point3D_ids)
return images
总结:各 format_char_sequence 的作用
| 格式字符串 | 含义 | 大小 |
|---|---|---|
| Q | unsigned long long 无符号长整型 | 8字节 64位 |
| i | int 有符号整数 | 4字节 32位 |
| d | double 双精度浮点数 | 8字节 64位 |
| c | char | 1字节 |
| q | long long | 8字节 |
read_next_bytes
用于从二进制文件中读取固定长度的字节,并根据给定的格式字符串和字节序将其解析为Python元组,是处理结构化二进制数据的关键工具函数。 主要用途:解析COLMAP的 .bin文件。
def read_next_bytes(fid, num_bytes, format_char_sequence, endian_character="<"):
"""
从一个二进制文件中读取指定数量的字节,并根据给定的数据格式和字节序将这些字节解析成对应的Python数据类型
@param fid:二进制文件对象
@param num_bytes:读取的字节数
@param format_char_sequence:字符串,表示每个字段的数据类型(由struct模块支持的格式字符组成,c, e, f, d, h, H, i, I, l, L, q, Q)
@param endian_character:字符串,表示字节序(@,=,<,>,!),默认为小端序 <(x86/x64架构使用)
@return:元祖类型
"""
data = fid.read(num_bytes) # 从文件对象中读取指定字节数的二进制字节数据(bytes类型)
# 将字节串按照格式字符串解码为Python原生数据类型组成的元组
# 参数一:完整的格式字符串(字节序字符和格式字符组成);参数二:要解包的原始字节数据
return struct.unpack(endian_character + format_char_sequence, data) # 解析字节数据
BaseImage
用于统一存储图像的各种属性和几何信息。
# 名为Image的类:用来统一保存图像的各种属性和几何信息
# id:图像的唯一标识序号;qvec:四元数旋转向量;tvec:平移向量;camera_id:图像所属相机的标识序号;name:图像的文件名;point3D_ids:关联每个2D特征点对应的三维空间点的ID
BaseImage = collections.namedtuple(
"Image", ["id", "qvec", "tvec", "camera_id", "name", "xys", "point3D_ids"])
具名元组类型(namedtuple):允许通过属性名和索引访问元素,功能上类似于简单的类,更轻量级且性能更高。结合了普通元组的高效性和对象属性访问的可读性,是一种非常实用的数据结构。
class Image
继承自BaseImage具名元组类型,用于统一保存图像的各种属性和几何信息,并提供了一个将四元数转换为对应的旋转矩阵的方法。
class Image(BaseImage):
# 用来统一保存图像的各种属性和几何信息
def qvec2rotmat(self):
# 将一个四元数转换为对应的旋转矩阵
return qvec2rotmat(self.qvec)
qvec2rotmat
接受一个四元数作为输入并返回相应的旋转矩阵。在计算机图形学和机器人学中,四元数常被用来表示旋转,因为它避免了万向节死锁的问题并且比旋转矩阵更紧凑。
def qvec2rotmat(qvec):
"""
将一个四元数转换为对应的旋转矩阵
@param qvec:单位四元数
@return:四元数对应的3×3旋转矩阵
"""
# 四元数到旋转矩阵的标准变换公式:
return np.array([
[1 - 2 * qvec[2]**2 - 2 * qvec[3]**2,
2 * qvec[1] * qvec[2] - 2 * qvec[0] * qvec[3],
2 * qvec[3] * qvec[1] + 2 * qvec[0] * qvec[2]],
[2 * qvec[1] * qvec[2] + 2 * qvec[0] * qvec[3],
1 - 2 * qvec[1]**2 - 2 * qvec[3]**2,
2 * qvec[2] * qvec[3] - 2 * qvec[0] * qvec[1]],
[2 * qvec[3] * qvec[1] - 2 * qvec[0] * qvec[2],
2 * qvec[2] * qvec[3] + 2 * qvec[0] * qvec[1],
1 - 2 * qvec[1]**2 - 2 * qvec[2]**2]])
read_intrinsics_binary
从一个给定路径的二进制文件中读取多个相机的内参信息,并将这些信息存储在一个字典中返回。
内参信息包括每个相机的旋转焦距、图像分辨率、畸变参数。适用于处理COLMAP等三维重建系统生成的cameras.bin文件。
def read_intrinsics_binary(path_to_model_file):
"""
从指定路径的二进制文件中读取所有相机的内参信息
@param path_to_model_file:包含图像内参信息的二进制文件的路径
@return:返回包含每个相机唯一标识符与对应内参信息的对象的字典
"""
cameras = {} # 用于存储从文件中读取的所有相机的信息,便于后续通过camera_id快速访问
with open(path_to_model_file, "rb") as fid: # 读取二进制文件
# Q代表8字节64位无符号长整型
num_cameras = read_next_bytes(fid, 8, "Q")[0] # 获取相机的总数
for _ in range(num_cameras): # 遍历读取每个相机的信息
# iiQQ i代表4字节32位有符号整数,Q代表8字节64位无符号长整型:4*2+8*2=24字节
camera_properties = read_next_bytes(
fid, num_bytes=24, format_char_sequence="iiQQ") # 读取相机的基本属性
# 同一场景可能使用多个相机拍摄,每个相机都有专属ID
camera_id = camera_properties[0] # 相机ID,唯一标识符
# 不同的相机模型(如针孔相机、广角相机、鱼眼相机等)有不同的内部参数和畸变模型
model_id = camera_properties[1] # 相机类型ID,唯一标识符
model_name = CAMERA_MODEL_IDS[camera_properties[1]].model_name # 获取对应的相机模型名称
width = camera_properties[2] # 相机图像的宽度
height = camera_properties[3] # 相机图像的高度
num_params = CAMERA_MODEL_IDS[model_id].num_params # 获取该相机模型对应的参数个数
# d代表8字节64位双精度浮点数:1*参数数量
params = read_next_bytes(fid, num_bytes=8*num_params,
format_char_sequence="d"*num_params) # 获取该相机模型参数
# 当前相机的内参相关数据:包含相机ID,相机模型名称,相机图像宽高,相机内参
cameras[camera_id] = Camera(id=camera_id,
model=model_name,
width=width,
height=height,
params=np.array(params))
assert len(cameras) == num_cameras # 确保读取到的相机数量与文件头记录的一致
return cameras
# 包含多个相机模型的集合
CAMERA_MODELS = {
# CameraModel类用于表示某种相机的投影模型
# model_id:整数,唯一标识该相机模型;model_name:字符串,描述相机模型的名称;num_params:整数,表示该相机模型需要的参数数量
CameraModel(model_id=0, model_name="SIMPLE_PINHOLE", num_params=3), # 标准相机且没有明显畸变,选择SIMPLE_PINHOLE或PINHOLE
CameraModel(model_id=1, model_name="PINHOLE", num_params=4),
CameraModel(model_id=2, model_name="SIMPLE_RADIAL", num_params=4), # 有轻微的径向畸变,使用SIMPLE_RADIAL或RADIAL
CameraModel(model_id=3, model_name="RADIAL", num_params=5),
CameraModel(model_id=4, model_name="OPENCV", num_params=8), # 复杂的广角镜头,选择OPENCV_FISHEYE或FOV
CameraModel(model_id=5, model_name="OPENCV_FISHEYE", num_params=8),
CameraModel(model_id=6, model_name="FULL_OPENCV", num_params=12), # 需要更高的精度,使用FULL_OPENCV或THIN_PRISM_FISHEYE
CameraModel(model_id=7, model_name="FOV", num_params=5),
CameraModel(model_id=8, model_name="SIMPLE_RADIAL_FISHEYE", num_params=4),
CameraModel(model_id=9, model_name="RADIAL_FISHEYE", num_params=5),
CameraModel(model_id=10, model_name="THIN_PRISM_FISHEYE", num_params=12)
}
# 将原始的相机模型集合(一组CameraModel对象)构造成两个字典,以方便后续通过模型ID或模型名称快速查找对应的相机模型
# 相机ID:相机
CAMERA_MODEL_IDS = dict([(camera_model.model_id, camera_model)
for camera_model in CAMERA_MODELS])
# 相机名字:相机
CAMERA_MODEL_NAMES = dict([(camera_model.model_name, camera_model)
for camera_model in CAMERA_MODELS])
CameraModel
用于统一存储相机模型的基本信息。
# 名为CameraModel的类:用于统一存储相机模型的基本信息
# model_id:相机模型的唯一编号;model_name:相机模型的名称;num_params:该相机模型所需的参数个数
CameraModel = collections.namedtuple(
"CameraModel", ["model_id", "model_name", "num_params"])
Camera
用于统一存储相机的内参信息。
# 名为Camera的类:用于统一存储相机的内参信息
# id:相机的唯一标识序号;model:相机的名称(型号);width:相机图像的宽度;height:相机图像的高度;params:相机的参数(内参矩阵)
Camera = collections.namedtuple(
"Camera", ["id", "model", "width", "height", "params"])
Point3D
用于统一存储三维空间中的点信息。
# 名为Point3D的类:用于统一存储三维空间中的点信息
# id:三维点的唯一标识符;xyz:三维坐标;rgb:点的颜色值;error:重投影误差;image_ids:与该三维点对应的图像ID列表;"point2D_idxs:每个图像中对应二维点的索引列表
Point3D = collections.namedtuple(
"Point3D", ["id", "xyz", "rgb", "error", "image_ids", "point2D_idxs"])
read_extrinsics_text
从一个给定路径的文本格式文件中读取多个图像的外参信息,并将这些信息存储在一个字典中返回。
外参信息包括每个图像的旋转四元数、平移向量、相机ID、图像名称、2D特征点坐标及对应的3D点ID。适用于处理COLMAP等三维重建系统生成的images.txt文件。
def read_extrinsics_text(path):
"""
从指定路径的文本格式文件中读取所有图像的外参信息
@param path:包含图像外参信息的文本格式文件的路径
@return:返回包含每个图像唯一标识符与对应外参信息的对象的字典
"""
images = {} # 用于存储从文件中读取的所有图像的信息,便于后续通过image_id快速访问
with open(path, "r") as fid: # 读取文本文件
while True: # 每次读取一行内容,直到读到文件末尾
line = fid.readline()
if not line:
break
line = line.strip() # 去除当前行首尾的空白字符,如换行符、空格等
if len(line) > 0 and line[0] != "#": # 当前行有内容且不是注释行
elems = line.split() # 按空白字符将当前行分割成多个元素存储为列表
image_id = int(elems[0]) # 图片ID,唯一标识符
qvec = np.array(tuple(map(float, elems[1:5]))) # 四元数:从世界坐标系到相机坐标系的旋转,长度为4
tvec = np.array(tuple(map(float, elems[5:8]))) # 平移向量:从世界坐标系到相机坐标系的平移,长度为3
camera_id = int(elems[8]) # 当前图像使用的相机模型ID
image_name = elems[9] # 前图像文件名
elems = fid.readline().split() # 再读取下一行,这行数据包含2D特征点坐标及其对应的3D点ID
# 数据是xyzxyzxyz的重复格式,所以需每隔3个再取
xys = np.column_stack([tuple(map(float, elems[0::3])),
tuple(map(float, elems[1::3]))]) # 提取所有2D点的x和y值并合并为(N,2)的二维数组
point3D_ids = np.array(tuple(map(int, elems[2::3]))) # 提取所有2D点对应3D点ID,转换为一维整数数组
# 当前图像的外参相关数据:包含图像ID,旋转四元数,平移矩阵,所属相机ID,图像名称,图像2D特征点xy坐标,2D特征点对应的3D点ID
images[image_id] = Image(
id=image_id, qvec=qvec, tvec=tvec,
camera_id=camera_id, name=image_name,
xys=xys, point3D_ids=point3D_ids)
return images
read_intrinsics_text
从一个给定路径的文本格式文件中读取多个相机的内参信息,并将这些信息存储在一个字典中返回。
内参信息包括每个相机的旋转焦距、图像分辨率、畸变参数。适用于处理COLMAP等三维重建系统生成的cameras.txt文件。
def read_intrinsics_text(path):
"""
从指定路径的文本格式文件中读取所有相机的内参信息
@param path_to_model_file:包含图像内参信息的文本格式文件的路径
@return:返回包含每个相机唯一标识符与对应内参信息的对象的字典
"""
cameras = {} # 用于存储后续读取到的所有相机对象
with open(path, "r") as fid: # 读取文本文件
while True: # 每次读取一行内容,直到读到文件末尾
line = fid.readline()
if not line:
break
line = line.strip() # 去除当前行首尾的空白字符,如换行符、空格等
if len(line) > 0 and line[0] != "#": # 当前行有内容且不是注释行
elems = line.split() # 按空白字符将当前行分割成多个元素存储为列表
# 同一场景可能使用多个相机拍摄,每个相机都有专属ID
camera_id = int(elems[0]) # 相机ID,唯一标识符
model = elems[1] # 获取相机模型名称
# 后续代码仅支持PINHOLE模型
assert model == "PINHOLE", "While the loader support other types, the rest of the code assumes PINHOLE"
width = int(elems[2]) # 相机图像的宽度
height = int(elems[3]) # 相机图像的高度
params = np.array(tuple(map(float, elems[4:]))) # 获取该相机模型参数
# 当前相机的内参相关数据:包含相机ID,相机模型名称,相机图像宽高,相机内参
cameras[camera_id] = Camera(id=camera_id, model=model,
width=width, height=height,
params=params)
return cameras
read_points3D_binary
用于从一个二进制文件中读取三维点云数据。
点云数据包括每个三维点的坐标、颜色及重投影误差等信息。适用于处理COLMAP等三维重建系统生成的points3D.bin文件。
def read_points3D_binary(path_to_model_file):
"""
从一个二进制点云文件中读取三维点云数据
@param path_to_model_file:二进制点云文件路径
@return:所有点的(x,y,z)坐标;对应点的颜色(r,g,b);每个点的重投影误差
"""
with open(path_to_model_file, "rb") as fid: # 打开二进制点云文件
# Q代表8字节64位无符号长整型
num_points = read_next_bytes(fid, 8, "Q")[0] # 点云数量
xyzs = np.empty((num_points, 3)) # 点云的坐标
rgbs = np.empty((num_points, 3)) # 点云的颜色
errors = np.empty((num_points, 1)) # 点云的误差信息
for p_id in range(num_points):
# Q代表8字节64位无符号长整型;d代表8字节64位双精度浮点数;B表示1字节8位无符号整数:8+8*4+1*3=43
binary_point_line_properties = read_next_bytes(
fid, num_bytes=43, format_char_sequence="QdddBBBd")
xyz = np.array(binary_point_line_properties[1:4]) # 提取三维坐标点
rgb = np.array(binary_point_line_properties[4:7]) # 提取坐标点颜色
error = np.array(binary_point_line_properties[7]) # 提取误差
# 未使用:读取跟踪长度和跟踪元素
track_length = read_next_bytes(
fid, num_bytes=8, format_char_sequence="Q")[0]
track_elems = read_next_bytes(
fid, num_bytes=8*track_length,
format_char_sequence="ii"*track_length)
# 存储到到对应数组中
xyzs[p_id] = xyz
rgbs[p_id] = rgb
errors[p_id] = error
return xyzs, rgbs, errors
read_points3D_text
用于从一个文本格式文件中读取三维点云数据。
点云数据包括每个三维点的坐标、颜色及重投影误差等信息。适用于处理COLMAP等三维重建系统生成的points3D.txt文件。
def read_points3D_text(path):
"""
从一个文本格式点云文件中读取三维点云数据
@param path:文本格式点云文件路径
@return:所有点的(x,y,z)坐标;对应点的颜色(r,g,b);每个点的重投影误差
"""
# 初始化变量
xyzs = None
rgbs = None
errors = None
# 第一遍遍历先计算点的个数
num_points = 0
# 统计点的数量
with open(path, "r") as fid: # 打开文本3D点云文件
while True: # 一行一行读取
line = fid.readline()
if not line:
break
line = line.strip() # 分割成多个字段
if len(line) > 0 and line[0] != "#": # 忽略空行和以#开头的注释行
num_points += 1 # 非注释行对应一个点
# 创建固定大小的NumPy数组
xyzs = np.empty((num_points, 3)) # 点云的坐标
rgbs = np.empty((num_points, 3)) # 点云的颜色
errors = np.empty((num_points, 1)) # 点云的误差信息
count = 0 # 用于记录当前写入的点数
# 第二遍遍历获取点的信息
with open(path, "r") as fid:
while True:
line = fid.readline() # 按行读取文件
if not line:
break
line = line.strip() # 分割成多个字段
if len(line) > 0 and line[0] != "#": # 同样跳过空行和注释行
elems = line.split()
# 解析每行的数据字段
xyz = np.array(tuple(map(float, elems[1:4]))) # 提取三维坐标点
rgb = np.array(tuple(map(int, elems[4:7]))) # 提取坐标点颜色
error = np.array(float(elems[7])) # 提取误差
# 存储到到对应数组中
xyzs[count] = xyz
rgbs[count] = rgb
errors[count] = error
count += 1
return xyzs, rgbs, errors
rotmat2qvec
接受一个旋转矩阵作为输入并返回相应的四元数。
输出的四元数格式是 [qw, qx, qy, qz],即标量部分在前,矢量部分在后,这种格式常见于 COLMAP 等三维重建系统。
def rotmat2qvec(R):
"""
将一个旋转矩阵转换为对应的四元数
@param R: 3×3旋转矩阵
@return: 旋转矩阵对应的单位四元数
"""
# 旋转矩阵到四元数的标准变换公式:
Rxx, Ryx, Rzx, Rxy, Ryy, Rzy, Rxz, Ryz, Rzz = R.flat
K = np.array([
[Rxx - Ryy - Rzz, 0, 0, 0],
[Ryx + Rxy, Ryy - Rxx - Rzz, 0, 0],
[Rzx + Rxz, Rzy + Ryz, Rzz - Rxx - Ryy, 0],
[Ryz - Rzy, Rzx - Rxz, Rxy - Ryx, Rxx + Ryy + Rzz]]) / 3.0
eigvals, eigvecs = np.linalg.eigh(K)
qvec = eigvecs[[3, 0, 1, 2], np.argmax(eigvals)]
if qvec[0] < 0:
qvec *= -1
return qvec
read_colmap_bin_array
从一个COLMAP二进制数组文件(通常是 .bin 文件)中读取图像数据,并将其转换为 NumPy 数组。
通常用于COLMAP输出的稠密重建结果,如深度图、法线图、置信图等。这些文件以二进制形式存储三维数组(width × height × channels),并使用特殊分隔符 “&” 来标记头部信息。
def read_colmap_bin_array(path):
"""
从指定路径的二进制文件中读取图像数据并将其转换为NumPy数组
@param path:指定二进制文件路径
@return: NumPy数组类型的图像数据
"""
with open(path, "rb") as fid: # 读取二进制文件
width, height, channels = np.genfromtxt(fid, delimiter="&", max_rows=1,
usecols=(0, 1, 2), dtype=int) # 读取头部,提取宽度,高度,通道数
# 定位数据
fid.seek(0) # 将文件指针重新定位到数据开始处
num_delimiter = 0
byte = fid.read(1)
while True: # 跳过前三个&字符,找到真正的二进制数据起始位置
if byte == b"&":
num_delimiter += 1
if num_delimiter >= 3:
break
byte = fid.read(1)
array = np.fromfile(fid, np.float32) # 读取数据,并转换为NumPy数组
# 按照Fortran顺序列优先重塑数组
array = array.reshape((width, height, channels), order="F") # 重塑数组
# 调整维度顺序并压缩维度去除冗余
return np.transpose(array, (1, 0, 2)).squeeze()
总结
尽可能简单、详细的介绍了COLMAP内容处理模块的功能和作用。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)