河南大学机器学习与数据挖掘——第二章 模型评估与选择
4、对于二分类问题,可将样本根据其真实类别与学习器预测类别的组合划分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)和假反例(false negative,FN)四种情形,请画出分类结果的混淆矩阵。1、以二分类任务为例,假定数据集D包含1000个样本,将其划分为训练集S和测试集T,其中S包含800个样本, T包含
第二章 模型评估与选择
2.1经验误差与过拟合
-
训练误差(经验误差)偏差:训练集上的误差;不是越小越好因为会出现过拟合
-
泛化误差(越小越好)方差:新样本上的误差
-
过拟合:指的是模型在训练数据上表现得过于优秀,但在未见数据上表现较差
-
原因:
-
训练数据量较少:当训练数据量较少时,模型容易过度拟合训练集中的样本。
-
模型过于复杂:过于复杂的模型具有更多的参数和灵活性,可以更好地拟合训练数据,但也更容易过拟合。
-
特征过多:如果特征过多,而与目标变量之间的关系又较弱,模型可能会过度拟合噪声或无关的特征。
-
-
措施:
-
数据扩充:通过增加更多的训练样本,可以减少模型对于训练数据的过拟合程度。
-
正则化(Regularization):通过在模型训练过程中引入正则化项,限制模型的复杂度,防止过拟合。
-
L1正则化:加上系数绝对值之和;使模型稀疏,使特征趋近于0,起特征选择作用
-
L2正则化:加上系数平方和;对特征系数按比例放缩,使模型变简单,防止过拟合,不会起到特征选择作用
-
-
特征选择:选择与目标变量相关性较高的特征,减少噪声和不相关的特征对模型的影响。
-
交叉验证(Cross-Validation):使用交叉验证来评估模型的泛化性能,选择最优的模型。
-
提前停止:可以通过监视损耗图,设置提前停止模型。
-
-
低偏差,高方差
-
-
欠拟合:指的是模型无法很好地拟合训练数据,无法捕捉到数据中的真实模式和关系
-
原因:
-
模型复杂度不足:如果模型过于简单,无法捕捉数据中的复杂关系和模式,就容易出现欠拟合问题。
-
数据特征不足:如果训练数据缺乏代表性的特征或者重要的特征被忽略,模型可能无法学习到足够的信息来进行准确预测。
-
-
措施:
-
增加模型复杂度:增加模型的复杂度,增加参数或层级,使其能够更好地拟合训练数据中的模式和关系。
-
特征工程:进行特征工程,提取更多有效的特征,以提高模型的表达能力。
-
模型集成(Ensemble Learning):使用多个模型组合的方法,如集成学习,可以提高模型的性能和泛化能力。
-
-
高偏差
-
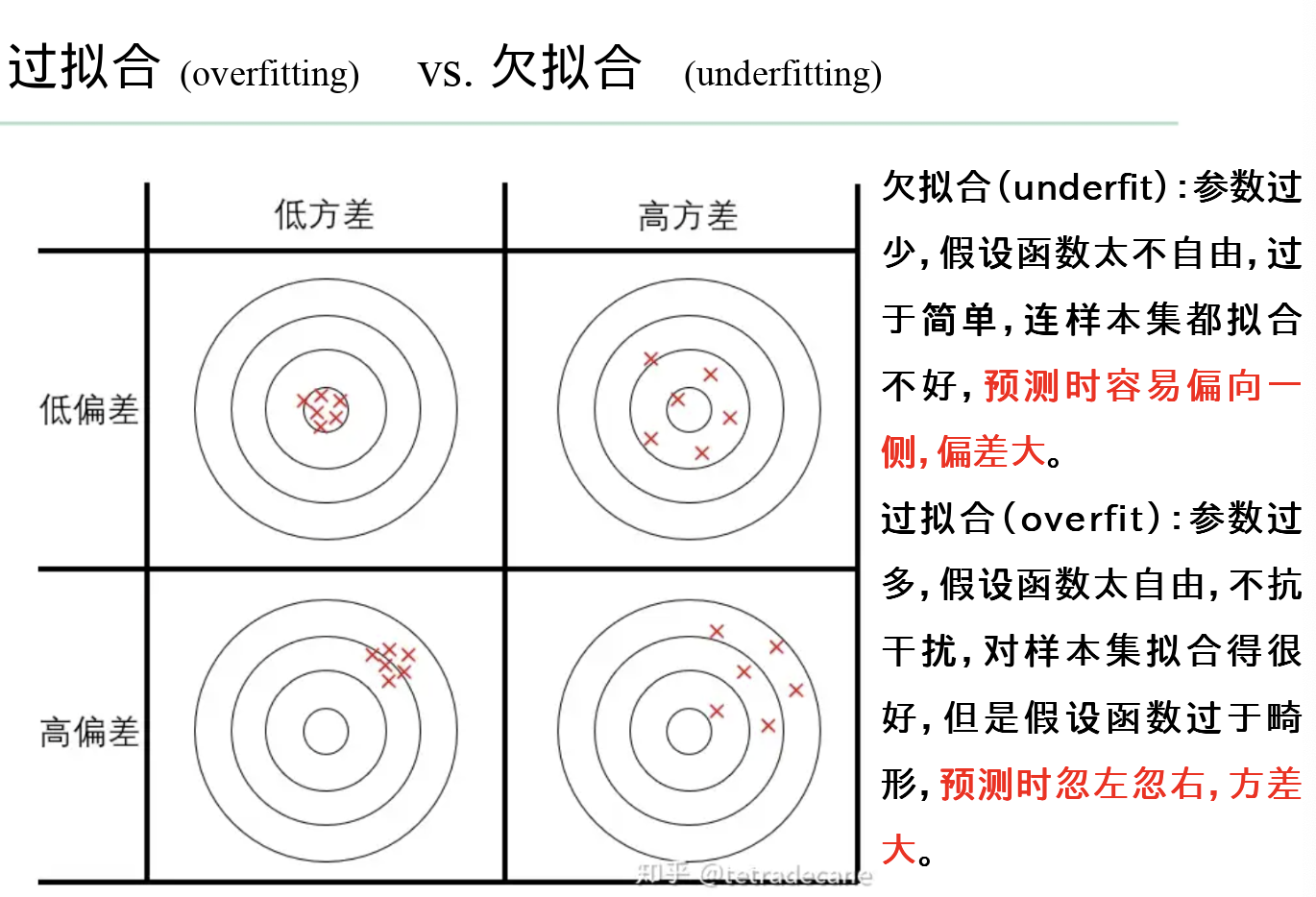
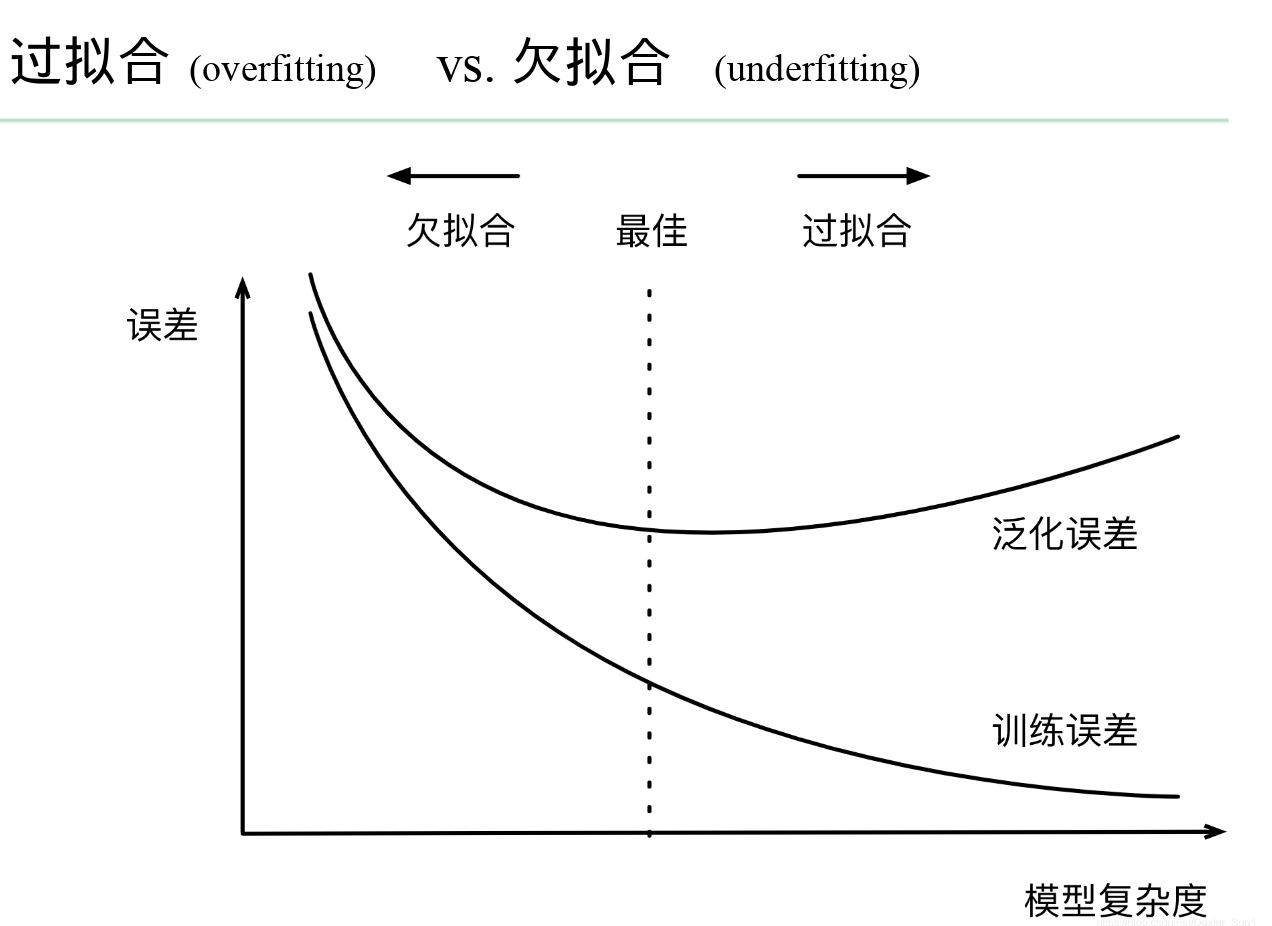
-
训练集:用于训练模型,让模型学习数据特征和规律的数据集
-
测试集:在模型训练完成后,用于评估模型最终性能表现的数据集
-
验证集:在模型训练过程中,用于调整模型超参数、防止过拟合的数据集
-
混淆矩阵(考计算)
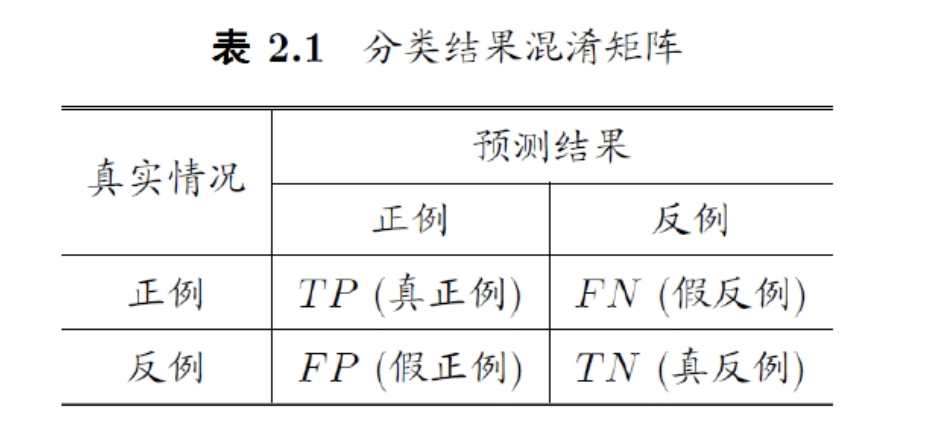
-
查准率(精确率)
-
查全率(召回率)
-
F1
-
偏差和方差(都小才好)
-
偏差:度量了学习算法的期望预测与真实结果的偏离程度,刻画了算法本身的拟合程度。
-
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动带来的影响。
-
模型在训练集上的误差来源主要来自于偏差,在测试集上误差来源主要来自于方差。
-
|
训练集 |
测试集 |
偏差 |
方差 |
|
|
欠拟合 |
80% |
79% |
20% |
1% |
|
过拟合 |
99% |
80% |
1% |
19% |
-
评估方法
-
留出法:打乱顺序按比例划分,或者分层抽样
-
测试集小的时候,评估结果的方差较大
-
训练集小的时候,评估结果的偏差较大
-
留出法需要对数据集进行多次切分并将结果取平均值
-
-
k-折交叉验证法:取平均;交叉验证能够增加模型泛化能力
-
自助法:对集成学习方法有很大的好处;在数据难以划分训练集测试集时,可以使用自助法
-
-
衡量回归的性能指标
-
MSE越小越好
-
RMSE越小越好
-
MAE对噪声数据不敏感(相比于MSE)
-
R<=1 模型不犯任何错误时取最大值1
-
测试题:
1、以二分类任务为例,假定数据集D包含1000个样本,将其划分为训练集S和测试集T,其中S包含800个样本, T包含200个样本,用S进行训练后,如果模型在T上有50个样本分类错误,那么模型的正确率为_____75%_______。
2、PR(Precision-Recall)曲线的横轴和纵轴分别是__查全率__和____查准率__。
3、ROC曲线的横轴和纵轴分别是___假正例率____和___真正例率_____。
4、对于二分类问题,可将样本根据其真实类别与学习器预测类别的组合划分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)和假反例(false negative,FN)四种情形,请画出分类结果的混淆矩阵。
|
真实情况 |
预测结果 |
|
|
正例 |
反例 |
|
|
正例 |
TP |
FN |
|
反例 |
FP |
TN |
5、F1度量是综合考虑了查准率和查全率的性能度量指标,请写出其公式。
F1=2⋅P⋅R/(P+R)
6、有多种因素可能导致过拟合,其中最常见的情况是由于_________学习器将训练样本学习过好_______,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由于________一般性质尚未学好__________而造成的。
7、查准率和查全率是分类任务中常用的性能度量指标,请写出其公式并对这两种指标进行分析。
P=TP/(TP+FP)查准率是预测的结果中有多少是对的
R=TP/(TP+FN)查全率是真正的情况中有多少是被预测准确的
8. 简述k折交叉验证法。
k折交叉验证法通过将数据集分割成多个子集来提高模型评估的稳定性和可靠性。该方法将整个数据集随机分成k个大小相等的子集,对于每一个子集,将其作为验证集,而其余的k-1个子集合并作为训练集。在这个训练集上训练模型,然后在验证集上评估模型的性能。重复上述步骤k次,每次都使用不同的子集作为验证集。最终,计算k次评估结果的平均值,以得到模型的整体性能估计。
9、分析偏差和方差的含义。
偏差衡量的是模型的预测值与真实值之间的差异。高偏差意味着模型过于简单,无法捕捉数据的基本结构,导致欠拟合。
方差衡量的是模型在不同数据集上的预测结果的变化程度。高方差意味着模型对训练数据中的噪声和细节过于敏感。在这种情况下,模型在训练数据上的误差可能很低,但在新的、未见过的数据上的误差很高。
10、对于一个三分类问题,数据集的真实标签和模型预测标签如下:
|
真实标签 |
1 |
1 |
2 |
2 |
2 |
3 |
3 |
3 |
3 |
|
预测标签 |
1 |
2 |
2 |
2 |
3 |
3 |
3 |
1 |
2 |
分别计算模型的精确率、召回率、F1值以及它们的宏平均和微平均。
(后面补上)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)