大模型训练 优化参数设置 4个技术
还在为“炼丹”参数发愁吗?这篇文章将带你彻底搞懂批次大小、学习率、优化器这些核心参数背后的深层逻辑。
1. 动态批次大小:从“小步快跑”到“稳步前进”的艺术
大模型训练的第一道坎,就是如何设置批次大小(Batch Size)。一个常见的误区是越大越好,但顶级玩家的策略其实是“动态调整”,这背后蕴含着对训练效率和稳定性的精妙平衡。
| 策略 (Strategy) | 目的 (Purpose) | 典型值 (Typical Value) |
|---|---|---|
| 动态批次大小 | 兼顾速度与稳定性 | 从数万增至数百万词元 |
| 早期小批次 | 梯度更新频繁,损失下降快 | GPT-3: 从 32K 开始 |
| 后期大批次 | 梯度更准,收敛更稳定 | PaLM: 增至 4M |
| 业界趋势 | 批次越来越大 | DeepSeek: 18M 词元 🔥 |
📊 表格展示了大模型训练中动态批次大小的核心策略与价值。这种“先小后大”的策略非常巧妙。训练初期,模型参数处于随机状态,用较小的批次可以让模型更快地进行梯度更新,好比“小步快跑”,迅速让损失下降到一个合理的范围。而到了训练后期,模型逐渐收敛,此时需要更大的批次来获得更准确的梯度方向,减少震荡,实现“稳步前进”,最终平稳地收敛到最优解。
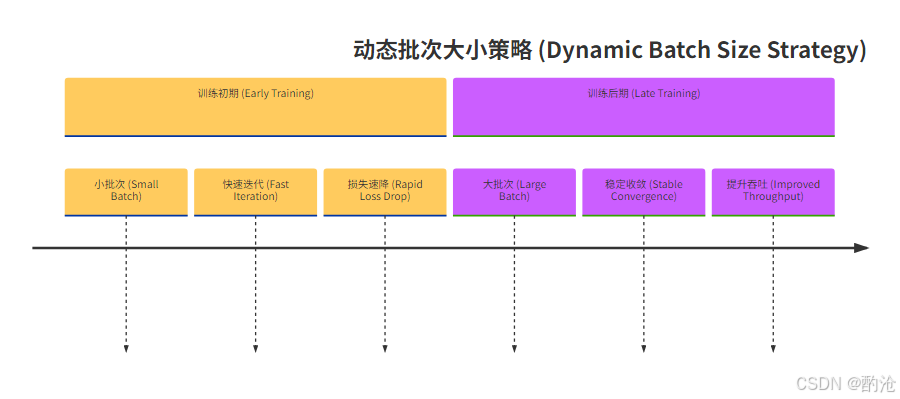
📊 这个时间线清晰地展示了动态批次大小策略在不同训练阶段的目标和作用。简单来说,这就是一个先追求速度、后追求质量的过程。没有足够的GPU资源支撑起百万级的批次大小,就很难在训练后期让模型稳定地达到最佳性能。而要实现如此大的批次,通常需要借助数据并行等分布式训练技术。
2. 学习率的“过山车”:预热、峰值与衰减的黄金法则
如果说批次大小是步子的大小,那学习率(Learning Rate, LR)就是走路的速度。设得太高容易“扯着蛋”导致模型崩溃,设得太低又像“蜗牛爬”,收敛遥遥无期。所有成功的大模型都采用了一套极其相似的“预热-衰减”调度策略。
| 阶段 (Phase) | 策略 (Strategy) | 目的 (Purpose) |
|---|---|---|
| 预热 (Warmup) | 线性增加 | 避免初始梯度过大,稳定启动 |
| 峰值 (Peak) | 达到最大值 | 加快模型收敛速度 |
| 衰减 (Decay) | 余弦衰减 (最常用) | 避免在最优点附近震荡 |
| 典型峰值 | ~1e-4 到 ~3e-4 | LLaMA-2: 1.5e-4 |
| 衰减终点 | 峰值的 10% | 实现精细调优 |
📊 表格概括了学习率调度三段式的核心作用和典型设置。这套策略就像开赛车。预热阶段是缓慢起步,让引擎(模型参数)适应赛道(数据),避免一开始就猛踩油门导致熄火。达到峰值学习率后,就是全力冲刺,快速逼近终点。最后进入衰减阶段,在接近最优解时逐渐减速,进行精细微调,确保精准“刹车”在最佳位置,而不会因速度过快而错过。余弦衰减因其平滑的特性,成为最受欢迎的衰减策略。
📊 上图描绘了学习率从预热到衰减的完整生命周期。这个工作流是大模型训练的标配。几乎所有你听过的大模型,从GPT-3到Qwen-1.5,都遵循着这个模式。它完美解决了训练初期不稳和后期收敛难两大核心矛盾,是“炼丹”成功的关键保障。
3. 优化器之争:为什么 AdamW 成了大模型标配?
优化器(Optimizer)是根据损失函数的梯度来更新模型权重的算法,它决定了模型学习的效率和效果。在众多优化器中,AdamW 几乎一统江湖,成为了大模型预训练的“钦定”之选。
| 优化器 (Optimizer) | 核心特点 (Core Feature) | 典型使用者 |
|---|---|---|
| Adam | 动量 + 自适应学习率 | GPT-3, BLOOM |
| AdamW ✅ | Adam + 权重衰减解耦 | LLaMA-2, Qwen-1.5, DeepSeek |
| Adafactor | 内存优化,节省显存 | PaLM, T5 |
| 常用 β1, β2 | 0.9, 0.95 | Adam/AdamW 的黄金搭档 |
| 常用 ϵ | 10⁻⁸ | 防止除零错误 |
📊 表格对比了三种主流优化器,并点明了AdamW成为事实标准的原因。Adam 本身结合了动量(让更新方向更稳定)和自适应学习率(为不同参数设置不同学习率),已经非常强大。但它的权重衰减方式存在缺陷,会导致正则化效果不佳。AdamW 通过将权重衰减与梯度更新解耦,修正了这个问题,提供了更好的泛化能力和训练稳定性,因此迅速成为大厂新宠。而谷歌的 Adafactor 则通过一些数学技巧减少了优化器状态的显存占用,在训练PaLM、T5这种巨无霸模型时优势明显。
📊 这张图清晰地展示了 Adam、AdamW 和 Adafactor 之间的演进关系,以及现代大模型训练依赖的核心优化技术。选择 AdamW 几乎不会错。它的超参数(如 β1=0.9, β2=0.95)也已经成为业界共识,你甚至不需要调整它们。这种标准化大大降低了训练的门槛。
4. 训练稳定三板斧:梯度裁剪、权重衰减
即使有了最好的参数策略,大模型训练过程依然像是在走钢丝,随时可能因为“损失爆炸”而前功尽弃。为此,工程师们准备了“三板斧”来保驾护航。
| 技术 (Technique) | 目的 (Purpose) | 典型设置 (Typical Setting) |
|---|---|---|
| 梯度裁剪 | 防止损失突增 (梯度爆炸) | 阈值通常设为 1.0 |
| 权重衰减 | 正则化,提高模型泛化能力 | 系数通常设为 0.1 |
| 训练恢复 | 从存档点恢复训练 | 应对异常的“后悔药” 💊 |
| Dropout | 避免过拟合 | 大模型中较少使用 |
📊 表格总结了保障大模型训练稳定性的三大核心技术及其作用。梯度裁剪(Gradient Clipping) 是最直接的保险丝。一旦梯度的模长超过一个阈值(通常是1.0),就强行把它拉回来,防止过大的梯度更新摧毁模型。权重衰减(Weight Decay) 是一种正则化技术,它在更新权重时施加一个惩罚,防止权重变得过大,从而提高模型的泛化能力,AdamW优化器已经内置了这一功能。而训练恢复则是一种工程实践:定期保存模型状态(Checkpoint),一旦训练崩溃,可以从上一个正常的存档点重启,避免从头再来。
📊 上图描绘了一个包含梯度裁剪和异常恢复的、鲁棒的训练步骤。有趣的是,曾经在深度学习中广受欢迎的 Dropout 技术,在现代大模型预训练中反而用得很少。这可能是因为当模型和数据量都足够大时,模型本身的容量和归一化层(Normalization Layers)已经起到了很好的正则化作用,过拟合的风险相对较小。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)