Sharding-JDBC 从入门到实战:分布式数据库分库分表核心指南
本文介绍 **Sharding-JDBC 的核心原理与实践应用**,通过从零开始的渐进式讲解,帮助读者掌握分布式数据库分库分表的核心技术。内容涵盖配置管理、SQL路由、数据分片、读写分离等关键模块,结合电商、物联网等真实场景案例,提供可落地的解决方案。
·

肖哥弹架构 跟大家“弹弹” mycat设计与实战应用,需要代码关注
欢迎 点赞,点赞,点赞。
关注公号Solomon肖哥弹架构获取更多精彩内容
历史热点文章
- MyCat应用实战:分布式数据库中间件的实践与优化(篇幅一)
- 图解深度剖析:MyCat 架构设计与组件协同 (篇幅二)
- 一个项目代码讲清楚DO/PO/BO/AO/E/DTO/DAO/ POJO/VO
- 写代码总被Dis:5个项目案例带你掌握SOLID技巧,代码有架构风格
- 里氏替换原则在金融交易系统中的实践,再不懂你咬我
本文介绍 Sharding-JDBC 的核心原理与实践应用,通过从零开始的渐进式讲解,帮助读者掌握分布式数据库分库分表的核心技术。内容涵盖配置管理、SQL路由、数据分片、读写分离等关键模块,结合电商、物联网等真实场景案例,提供可落地的解决方案。
一、Sharding-JDBC框架图
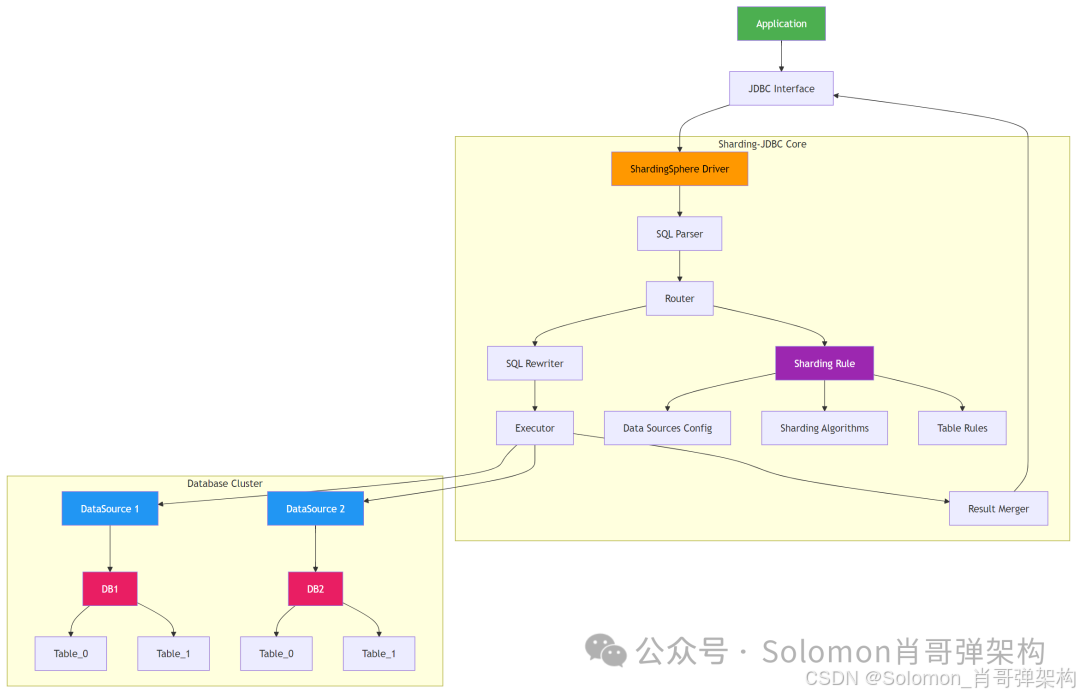
1. 应用层 (Application)
- 使用标准 JDBC 接口访问数据库
- 无需修改业务代码即可接入 Sharding-JDBC
- 操作逻辑表(如
t_order)而非物理表
2. Sharding-JDBC 核心层
核心组件:
- SQL Parser:解析 SQL 语句,提取分片键
- Router:根据分片规则路由到目标数据源和表
- SQL Rewriter:将逻辑 SQL 改写为物理 SQL
- Executor:执行物理 SQL(支持并行执行)
- Result Merger:合并多个分片的查询结果
配置模块:
- Sharding Rule:分片规则配置中心
- Data Sources:数据源配置(支持多库)
- Sharding Algorithms:分片算法(取模、范围等)
- Table Rules:表分片规则(分片键、分片策略)
3. 数据层 (Database Cluster)
- 物理数据源:多个数据库实例(如 DB1、DB2)
- 物理表:实际存储数据的表(如 table_0、table_1)
- 支持 MySQL、PostgreSQL、Oracle 等主流数据库
关键流程说明
-
SQL 解析:
- 应用发送逻辑 SQL(如
SELECT * FROM t_order) - SQL Parser 解析 SQL 结构,识别操作类型
- 应用发送逻辑 SQL(如
-
路由决策:
- Router 根据分片规则和 SQL 中的分片键值
- 确定需要访问的物理数据源和物理表
-
SQL 改写:
- 将逻辑表名替换为物理表名
- 优化 SQL 结构(如分页改写)
-
执行引擎:
- 并行执行多个物理 SQL
- 支持跨数据源的事务管理(XA/SAGA)
-
结果归并:
- 合并多个分片的查询结果
- 处理排序、分组、分页等逻辑
二、Sharding-JDBC 入门案例执行流程图
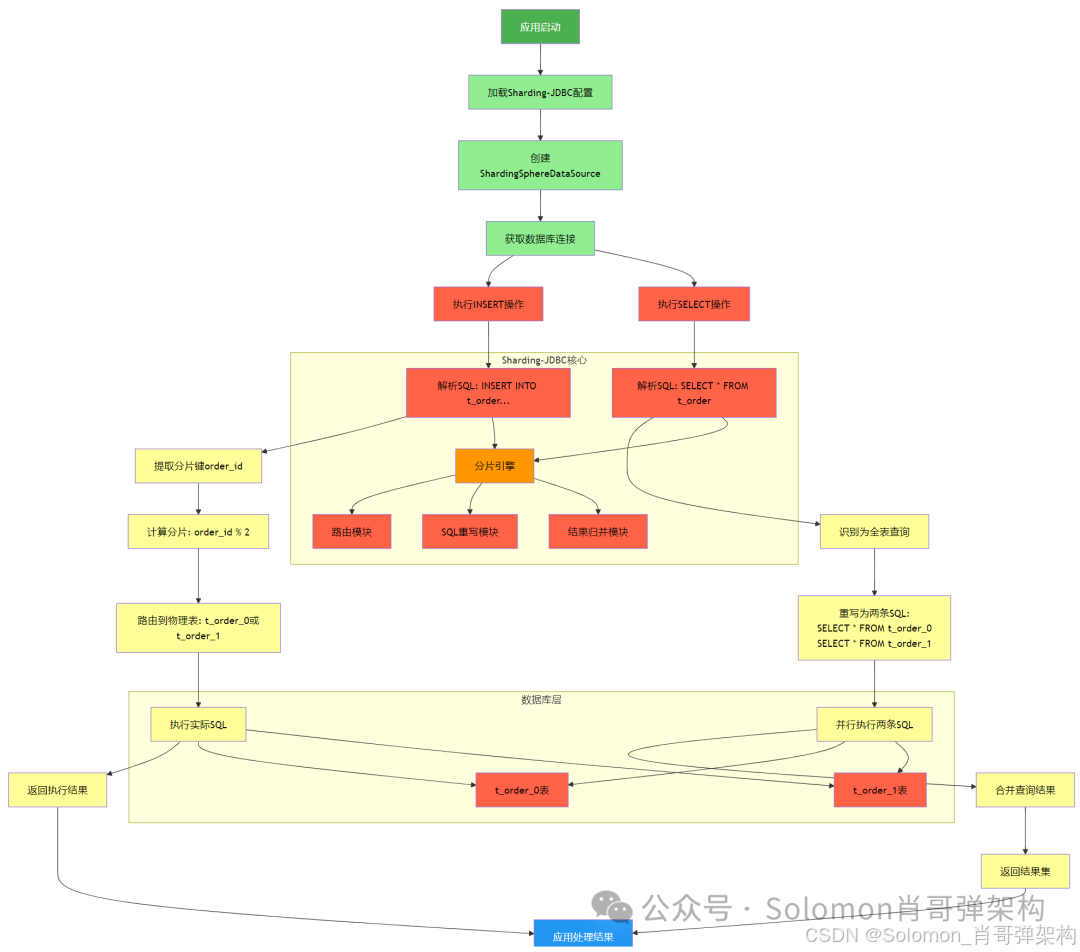
-
应用启动阶段:
- 加载 Sharding-JDBC 配置文件
- 创建 ShardingSphereDataSource 数据源对象
-
INSERT 操作流程:
- 解析逻辑 SQL(
INSERT INTO t_order...) - 提取分片键
order_id - 根据分片算法计算目标物理表(
order_id % 2) - 路由到具体物理表(
t_order_0或t_order_1) - 执行改写后的实际 SQL
- 解析逻辑 SQL(
-
SELECT 操作流程:
- 解析逻辑 SQL(
SELECT * FROM t_order) - 识别为全表查询需要扫描所有分片
- 重写为两条物理 SQL(查询
t_order_0和t_order_1) - 并行执行两条物理 SQL
- 合并两个结果集返回给应用
- 解析逻辑 SQL(
-
Sharding-JDBC 核心模块:
- 分片引擎:协调整个分片过程
- 路由模块:确定数据操作的目标分片
- SQL 重写模块:将逻辑SQL改写为物理SQL
- 结果归并模块:合并多个分片的查询结果
-
数据库层:
- 实际存储数据的物理表(
t_order_0和t_order_1) - 所有操作最终都会落实到具体的物理表上
- 实际存储数据的物理表(
关键过程说明
- 分片路由:当执行 DML 操作时,Sharding-JDBC 根据分片键的值计算目标分片
- 全表查询:当执行全表查询时,Sharding-JDBC 会自动查询所有分片并合并结果
- SQL 改写:Sharding-JDBC 会将逻辑表名改写为物理表名
- 结果归并:对于跨分片的查询,会将多个结果集合并为一个结果集返回
步骤 1:环境准备
1.1 创建数据库和表
-- 创建数据库(单库)
CREATE DATABASE demo_ds;
-- 创建两个物理表(分表)
USE demo_ds;
CREATE TABLE t_order_0 (order_id BIGINT PRIMARY KEY, user_id INT, status VARCHAR(50));
CREATE TABLE t_order_1 (order_id BIGINT PRIMARY KEY, user_id INT, status VARCHAR(50));
1.2 Maven 依赖
<dependencies>
<!-- Sharding-JDBC 核心 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.3.2</version> <!-- 使用最新版本 -->
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
步骤 2:Sharding-JDBC 配置
创建 sharding-config.yaml 配置文件(放在 resources 目录下):
dataSources:
ds_0: # 数据源名称(单库)
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
jdbcUrl: jdbc:mysql://localhost:3306/demo_ds?useSSL=false
username: root
password: 123456
rules:
- !SHARDING
tables:
t_order: # 逻辑表名
actualDataNodes: ds_0.t_order_${0..1} # 物理表表达式
tableStrategy: # 分表策略
standard:
shardingColumn: order_id # 分片键
shardingAlgorithmName: t_order_inline # 分片算法名称
shardingAlgorithms:
t_order_inline: # 行表达式分片算法
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2} # 按 order_id 奇偶分表
props:
sql-show: true # 打印SQL日志(调试用)
步骤 3:Java 代码实现
import org.apache.shardingsphere.driver.api.yaml.YamlShardingSphereDataSourceFactory;
import javax.sql.DataSource;
import java.io.File;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class ShardingJdbcDemo {
public static void main(String[] args) throws Exception {
// 1. 加载配置文件
File configFile = new File(ShardingJdbcDemo.class.getResource("/sharding-config.yaml").toURI());
DataSource dataSource = YamlShardingSphereDataSourceFactory.createDataSource(configFile);
// 2. 插入数据(自动路由到分表)
try (Connection conn = dataSource.getConnection()) {
String sql = "INSERT INTO t_order (order_id, user_id, status) VALUES (?, ?, ?)";
// 插入偶数订单(order_id=100)
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setLong(1, 100L);
ps.setInt(2, 1);
ps.setString(3, "SUCCESS");
ps.executeUpdate(); // 插入 t_order_0
}
// 插入奇数订单(order_id=101)
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setLong(1, 101L);
ps.setInt(2, 2);
ps.setString(3, "FAILED");
ps.executeUpdate(); // 插入 t_order_1
}
}
// 3. 查询所有数据(跨表查询)
try (Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement("SELECT * FROM t_order");
ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
System.out.printf(
"order_id: %d, user_id: %d, status: %s\n",
rs.getLong("order_id"),
rs.getInt("user_id"),
rs.getString("status")
);
}
}
}
}
步骤 4:运行结果
控制台输出
-- 插入日志(自动路由)
LogicSQL: INSERT INTO t_order ...
ActualSQL: ds_0 ::: INSERT INTO t_order_0 ... # order_id=100 进入 t_order_0
ActualSQL: ds_0 ::: INSERT INTO t_order_1 ... # order_id=101 进入 t_order_1
-- 查询日志(合并结果)
LogicSQL: SELECT * FROM t_order
ActualSQL: ds_0 ::: SELECT * FROM t_order_0
ActualSQL: ds_0 ::: SELECT * FROM t_order_1
-- 程序输出
order_id: 100, user_id: 1, status: SUCCESS
order_id: 101, user_id: 2, status: FAILED
数据库验证
SELECT * FROM t_order_0; -- 包含 order_id=100
SELECT * FROM t_order_1; -- 包含 order_id=101
关键概念解析
| 术语 | 说明 |
|---|---|
| 逻辑表 | 应用程序使用的表名(如 t_order),是分片规则的抽象 |
| 物理表 | 真实存储数据的表(如 t_order_0、t_order_1) |
| 分片键 | 路由字段(如 order_id),Sharding-JDBC 根据它决定数据写入哪个物理表 |
| 行表达式 | 简化配置的语法(t_order_${order_id % 2}) |
| actualDataNodes | 物理表与数据源的映射关系(ds_0.t_order_${0..1}) |
扩展:分库分表配置
若需分库(如拆分为两个库),只需修改配置:
dataSources:
ds_0: # 第一个库
url: jdbc:mysql://localhost:3306/db0
ds_1: # 第二个库
url: jdbc:mysql://localhost:3306/db1
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1} # 两库两表
databaseStrategy: ... # 分库策略
tableStrategy: ... # 分表策略

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)