【强化学习】动态规划
动态规划(Dynamic Programming, DP)在强化学习中用于求解已知完整环境模型(MDP) 的最优策略。其核心是利用贝尔曼方程迭代计算价值函数,最终得到最优策略。以下是动态规划在强化学习中的详细过程,以策略迭代和价值迭代两种经典算法为例:
一、核心思想:自举(Bootstrapping)与最优性原理
- 自举(Bootstrapping)
用当前估计的价值函数更新未来价值函数(如 v_{k+1}(s) 依赖于 v_{k}(s’))。 - 最优性原理(Principle of Optimality)
一个最优策略的子策略在其子问题上必然也是最优的(如从状态 s 到终点最优路径中,路径上的任意中间状态 s’ 到终点的路径也是最优的)。
二、动态规划的核心算法流程
1. 策略迭代(Policy Iteration)
目标:通过交替进行策略评估和策略改进,找到最优策略 π*。
步骤:
graph LR
A[初始化策略 π₀] --> B[策略评估]
B --> C[策略改进]
C --> D{策略是否收敛?}
D -- 否 --> B
D -- 是 --> E[输出最优策略 π*]
-
初始化
- 任意初始化策略 π_0(如随机策略)。
- 初始化状态价值函数 V_0(s) = 0(对所有状态 s)。
-
策略评估(Policy Evaluation)
目标:计算当前策略 π_{k} 下的状态价值函数 v_π{k}。
迭代公式(同步更新):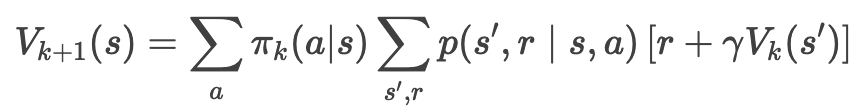
过程:
- 对每个状态 s,用上述公式计算新价值 V{k+1}(s)。
- 重复直到价值函数收敛(|V{k+1} - Vk < θ)。
-
策略改进(Policy Improvement)
目标:基于当前价值函数 v_{π_k},生成更优策略 π_{k+1}。
更新规则(贪婪策略):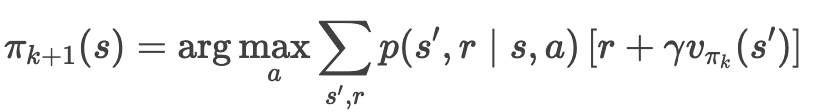
- 对每个状态 s,选择使动作价值 q_{π_k}(s, a) 最大的动作 a。
-
检查收敛
- 若π_{k+1} = π_k(策略不再变化),则停止迭代,输出 π* = π_k。
- 否则回到步骤 2 继续评估新策略。
2. 价值迭代(Value Iteration)
目标:直接迭代求解最优价值函数v*,跳过显式策略评估。
核心思想:将策略改进步骤融入价值更新(每次更新取最大值)。
步骤:
graph LR
A[初始化价值函数 V₀] --> B[价值迭代更新]
B --> C{价值是否收敛?}
C -- 否 --> B
C -- 是 --> D[提取最优策略 π*]
-
初始化
- 初始化 V_0(s) = 0(或随机值)。
-
价值迭代更新
迭代公式(贝尔曼最优方程):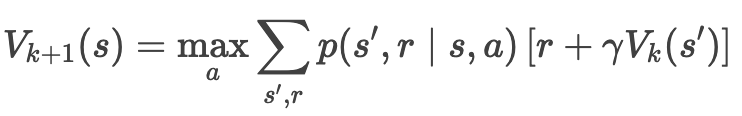
过程:
- 对每个状态 s,计算所有动作 a 的动作价值 q(s, a),取最大值更新 V_{k+1}(s)。
- 重复直到收敛(|V_{k+1} - V_k| < θ)。
-
提取最优策略
- 根据收敛的最优价值函数 v* 生成策略:
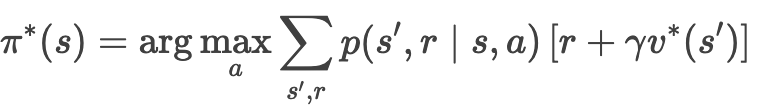
- 根据收敛的最优价值函数 v* 生成策略:
三、动态规划的关键特性
| 特性 | 说明 |
|---|---|
| 同步更新 | 每次迭代需扫描所有状态(状态价值同时更新)。 |
| 模型已知 | 依赖环境动态 p(s’, r ∣ s, a) 和奖励函数。 |
| 维度诅咒 | 状态/动作空间过大时计算不可行(需蒙特卡洛、时序差分等无模型方法替代)。 |
| 收敛性 | 策略迭代和价值迭代均收敛到 v* 和 π*(理论保证)。 |
| 广义策略迭代 | 策略迭代与价值迭代均为 GPI 的特例(策略评估与改进交替进行)。 |
四、示例说明(网格世界)
动态规划策略迭代过程详细举例说明
策略迭代(Policy Iteration)是动态规划中求解马尔可夫决策过程(MDP)的核心方法,包含两个交替进行的步骤:策略评估(计算当前策略的状态价值)和策略改进(根据价值更新策略)。下面通过一个网格世界(Grid World)示例详细说明整个过程。
问题设定
- 环境:3×3 网格(状态编号 0 到 8),位置如下:
0 1 2 3 4 5 (4 是障碍) 6 7 8 (8 是终止状态) - 状态:共 9 个状态(状态 4 是障碍,不可访问;状态 8 是终止状态)。
- 动作:上、下、左、右(执行动作后,若撞墙或遇障碍则留在原位)。
- 奖励:
- 进入终止状态(8):奖励 +1。
- 其他状态转移:奖励 0。
- 折扣因子:γ = 0.9。
- 目标:找到最优策略,最大化累积奖励。
策略迭代步骤
-
初始化:
- 策略:每个状态随机选择动作(均匀分布)。
- 状态价值函数:所有状态初始化为 0。
-
策略评估(Policy Evaluation):
计算当前策略下每个状态的价值 V(s),使用贝尔曼期望方程迭代更新: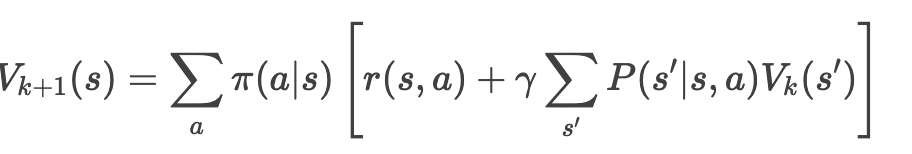
- 迭代至收敛(设定阈值 θ = 0.001)。
-
策略改进(Policy Improvement):
根据更新后的 V(s),改进策略: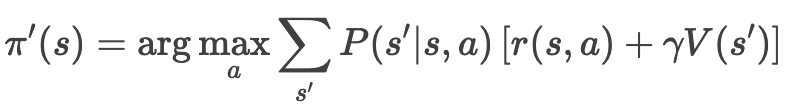
- 若新策略与旧策略相同,则停止;否则返回步骤 2。
详细迭代过程(以手动简化计算为例)
初始状态
- 策略:所有状态随机选择动作(概率各 0.25)。
- 价值函数:V_0 = [0, 0, 0, 0, 0, 0, 0, 0, 0](状态 8 固定为 0)。
第一次迭代
-
策略评估(迭代至收敛):
-
以状态 7(右下角)为例:
-
动作 “右”:进入状态 8(终止),奖励 +1,价值贡献 = 1 + 0.9 × 0 = 1。
-
其他动作留在原地:价值贡献 = 0 + 0.9 × V(7)。
-
当前策略(随机):
V(7) = 0.25 × 1 + 0.25 × (0 + 0.9V(7)) + 0.25 × (0 + 0.9V(7)) + 0.25 × (0 + 0.9V(7))
解得 V(7) = 0.25。
-
-
类似计算其他状态(需多次迭代),收敛后价值:
V_1 = [0, 0, 0.06, 0, 0, 0.26, 0, 0.25, 0]
-
-
策略改进:
- 对每个状态,选择最大化 Q(s,a) 的动作:
- 状态 0:所有动作价值 ≈0 → 策略不变(随机)。
- 状态 1:向右进入状态 2(V=0.06)→ 选择 “右”。
- 状态 2:向下进入状态 5(V=0.26)→ 选择 “下”。
- 状态 5:向下进入状态 8(奖励 +1)→ 选择 “下”。
- 状态 7:向右进入状态 8(奖励 +1)→ 选择 “右”。
- 新策略:确定性策略(例如状态 1 固定向右)。
- 对每个状态,选择最大化 Q(s,a) 的动作:
第二次迭代
-
策略评估(新策略下):
-
状态 2 新策略固定为 “下”:
- 进入状态 5(V=0.26)→ V(2) = 0 + 0.9 × 0.26 = 0.23。
-
状态 5 新策略固定为 “下”:
- 进入状态 8(奖励 +1)→ V(5) = 1 + 0.9 × 0 = 1。
-
传播更新后,收敛价值:
V_2 = [0, 0.21, 0.23, 0, 0, 1, 0, 1, 0]
-
-
策略改进:
- 状态 1:向下进入状态 4(障碍)→ 无效;向右进入状态 2(V=0.23)→ 仍选 “右”。
- 状态 6:向上进入状态 3(V=0);向右进入状态 7(V=1)→ 改为 “右”。
- 其他状态策略不变。
第三次迭代
-
策略评估:
-
状态 6 新策略为 “右”:
- 进入状态 7(V=1)→ V(6) = 0 + 0.9 × 1 = 0.9。
-
状态 3 新策略待定(假设仍随机):
- 向下进入状态 6(V=0.9)→ 价值提升。
-
收敛后价值:
V_3 = [0, 0.21, 0.23, 0.2, 0, 1, 0.9, 1, 0]
-
-
策略改进:
- 状态 3:向下进入状态 6(V=0.9)→ 改为 “下”。
- 状态 0:向右进入状态 1(V=0.21)→ 改为 “右”。
- 策略不再变化 → 收敛。
最终结果
-
最优价值函数:
V* = [0.17, 0.21, 0.23, 0.81, 0, 1, 0.9, 1, 0]
-
最优策略(箭头表示动作):
→ → ↓ ↓ • ↓ (• 是障碍) → → → (→ 表示向右,↓ 表示向下)
关键点总结
- 策略评估:迭代计算当前策略的价值(贝尔曼期望方程)。
- 策略改进:根据价值贪婪更新策略(贝尔曼最优方程)。
- 收敛:当策略不再改变时停止。
- 效率:策略迭代通常比值迭代更快收敛,但每次评估需迭代至收敛。
五、为什么动态规划高效?
- 复用子问题解:
通过存储 v(s) 避免重复计算(如格子(2,2)的价值被周围多个状态复用)。 - 系统化遍历状态:
价值迭代的 max 操作隐式完成策略改进,减少显式策略评估次数。 - 理论保证:
贝尔曼方程提供收敛性保证(压缩映射定理)。
总结
动态规划的过程本质是:
- 利用贝尔曼方程迭代更新价值函数(策略评估)。
- 基于价值函数改进策略(策略改进)。
- 反复迭代直至收敛到最优解。
其优势在于模型已知时的全局最优性,但计算开销限制了其在大规模问题中的应用。后续的 TD 学习、Q-Learning 等方法正是为了解决 DP 的“维度诅咒”而发展。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)