基于 Docker 的 Apache Spark 4.0.0 环境搭建与sparksql的使用教程
·
目录
一、前言
本教程将详细指导你如何使用 Docker 搭建 Apache Spark 4.0.0 环境,并进行spark-sql基础操作。
二、环境准备
1 安装 Docker
确保你的系统已安装 Docker。若未安装,请根据操作系统类型参考官方文档进行安装:
- Ubuntu:
sudo apt-get update && sudo apt-get install docker.io - CentOS:
sudo yum install docker-ce docker-ce-cli containerd.io - Windows/macOS: 下载 Docker Desktop 并安装
2 配置镜像加速器
sudo nano /etc/docker/daemon.json 
可以用我的配置文件,这些是还没挂的镜像源
{"registry-mirrors": [
"https://docker.1ms.run",
"https://docker.anyhub.us.kg",
"https://dockerhub.jobcher.com",
"https://dockerhub.icu"
]
}保存并重启Docker服务,查看Docker的状态
sudo systemctl restart docker
systemctl status docker.service
三、获取与构建 Spark 镜像
1.下载Spark Docker仓库
从GitHub下载官方仓库,然后进入目标地址,选择别的版本也可以,文件名都清楚的标记了是什么版本,进入的时候按照文件夹名称来就好。
git clone https://github.com/apache/spark-docker.git
cd spark-docker/4.0.0/scala2.13-java17-python3-ubuntu2.构建镜像
执行构建命令,如果是别的版本直接更换版本号就行.
docker build -t my-spark:4.0.0 .
3.常见问题
构建失败可能是网络问题,或者权限问题,要给用户设置Docker操作权限,还可能使daemon.json的语法问题,可以好好检查以下这个文件的语法。
四、启动与验证 spark-sql 环境
1 启动 Sparksql
如果用的是别的版本,进入容器的时候需要修改容器名称,建议和我用一样的版本
#进入容器
docker run -it my-spark:4.0.0 bash
#启动spark-sql
/opt/spark/bin/spark-sql
#也可以直接启动
docker run -it my-spark:4.0.0 /opt/spark/bin/spark-sql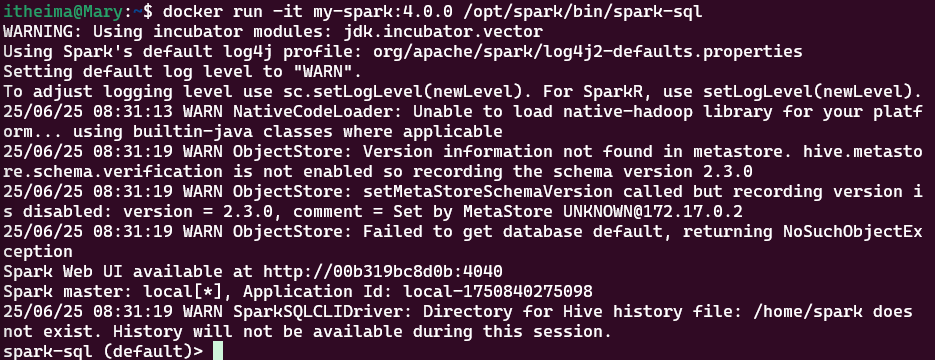
2. 执行示例查询
Spark 自带示例数据,可以直接用于测试,创建临时表
CREATE TEMPORARY VIEW people
USING json
OPTIONS (path "/opt/spark/examples/src/main/resources/people.json");查询数据
-- 查询数据
SELECT * FROM people;
-- 筛选年龄大于20的记录
SELECT name, age FROM people WHERE age > 20;
-- 分组统计(假设数据有更多记录)
SELECT COUNT(*) FROM people;
-- 使用 Spark 函数(如字符串处理)
SELECT UPPER(name) FROM people; 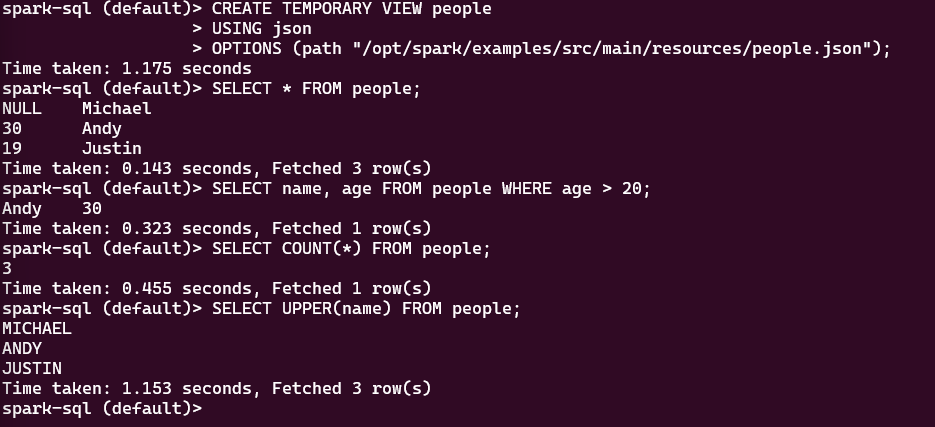
3.手动创建实例数据
在容器中创建文件
再开个终端进入容器
docker run -it my-spark:4.0.0 bash![]()
这个镜像非常精简,没下载vi之类的文件编辑器,我们直接用cat创建test.json文件
cat > /tmp/test.json << EOF
{"name":"Bob","age":30,"hobbies":["reading","coding"]}
{"name":"Charlie","age":35,"city":"Chicago"}
EOF验证文件内容
cat /tmp/test.json 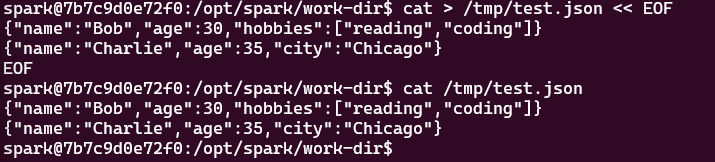
启动spark-sql,使用新路径创建临时表
/opt/spark/bin/spark-sql
CREATE TEMPORARY VIEW test_people
USING json
OPTIONS (path "/tmp/test.json");
其他查看表的操作都和前面的一样,改个表名就行。
五、常见问题
1.数据量可能对从查询结果造成影响。
2.找不到文件之类的报错,可能是路径错误,排bug可以关注一下。
3.这个容器默认以非root用户(spark)运行,若需安装工具,要进入root环境运行:
在宿主机执行:docker exec -it -u root <容器ID> bash![]()
![]() 这个@后面的东西是容器id
这个@后面的东西是容器id

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)