计算机毕业设计之基于Hadoop的共享自行车数据分析系统设计与实现-
本文设计实现了一个基于Hadoop的共享自行车数据分析系统,利用HDFS、MapReduce、Spark等技术处理海量运营数据。系统通过随机森林回归模型分析车辆使用量、用户行为等,为运营商提供决策支持。采用Python爬虫采集数据,Hadoop存储,Spark计算分析,MySQL存储结果,Django+Vue.js搭建Web应用,Echarts可视化展示。系统包含数据采集、处理、分析、可视化和管理
本文设计并实现了一个基于Hadoop的共享自行车数据分析系统,旨在解决共享自行车运营过程中产生的海量数据存储、处理和分析问题。系统利用Hadoop生态系统中的HDFS、MapReduce、Spark等组件,实现了对共享自行车数据的采集、清洗、转换、存储和分析。通过构建随机森林回归模型,系统实现了对车辆使用量、用户行为、需求预测等方面的精准分析,为共享自行车运营商提供了重要的决策支持。同时,系统还提供了丰富的数据可视化功能,通过地图、图表等方式直观展示了分析结果,帮助运营商更好地理解用户需求,优化运营策略,提升服务质量。
研究结果表明,该系统能够显著提高共享自行车运营效率,降低运营成本,提升用户体验,推动共享自行车行业的健康发展。此外,本研究还具有重要的理论意义和实践价值,丰富了大数据技术在交通出行领域的应用,为智慧交通的建设提供了新的思路和方法。未来,随着大数据、人工智能等技术的不断发展,共享自行车数据分析系统将朝着更加智能化、精准化、实时化的方向发展,为共享自行车行业的可持续发展提供更加有力的支持。
功能模块设计
基于Hadoop的共享自行车数据分析系统设计与实现,涵盖了从数据抓取到最终呈现的全过程管理。首先,数据抓取模块利用网络爬虫技术,高效地从共享自行车系统中收集大量数据,并将其存储到数据库中。其次,数据处理模块对原始数据进行清洗、转换、集成等操作,确保数据的准确性和完整性。接着,数据分析模块利用随机森林回归算法对处理后的数据进行建模和预测,挖掘出有价值的信息和规律。然后,数据可视化模块将分析结果以图表的形式展现出来,使数据更加直观易懂。最后,管理系统模块提供了丰富的功能,如首页展示、个人中心、自行车数据、使用量预测、用户管理、系统日志等,方便用户管理和查询数据。整个平台的功能模块相互配合,共同构成了一个高效、可靠的共享自行车数据分析系统,为共享自行车运营商提供了有力的决策支持。
具体来说,该系统包括以下几个主要功能模块:
数据抓取:通过网络爬虫采集共享自行车的相关数据,并进行数据存储和数据上传。
数据处理:对采集到的数据进行缺失值处理、重复值处理以及数据预处理,以确保数据的准确性和可靠性。
数据分析:选择合适的模型进行模型训练和模型部署,利用随机森林回归算法对共享自行车的使用情况进行预测和分析。
数据可视化:将分析结果以数据看板的形式展示出来,包括季节使用量、节假日使用量、非注册用户、自行车数量、预测总使用量、工作日使用量和天气使用量等信息。
管理系统:提供首页展示、个人中心、自行车数据、使用量预测、用户管理和系统日志等功能,方便用户对共享自行车系统进行管理和维护。系统总体功能如图4-6所示。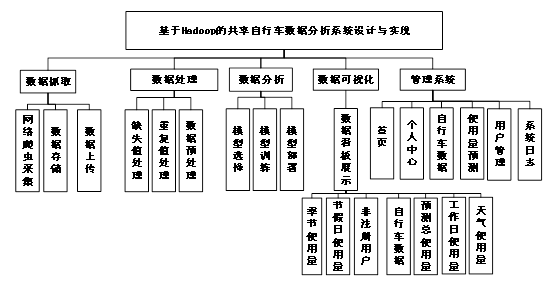
图4-6 系统总体结构图
数据可视化实现
在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从网站上抓取自行车数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,sklearn机器学习搭建模型与预测,将处理后的结果存入MySQL数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
基于Hadoop的共享自行车数据分析系统的数据可视化大屏,通过丰富的图表和图形元素,直观地展示了共享自行车的自行车数据和相关信息。大屏左侧展示了季节使用量、节假日使用量、非注册用户、注册用户量等关键指标,通过柱状图、饼状图等方式进行展示,便于用户快速了解共享自行车的使用情况。中间部分则详细列出了每日的自行车数据,包括日期、星期、天气状况等信息,让用户能够清晰地看到每天的使用情况。右侧则重点展示了星期的使用量和工作日的使用量,通过横向柱状图和环形图的方式进行展示,使得用户能够一目了然地比较不同时间段的使用情况。此外,大屏还提供了天气使用量的展示,通过环形图的方式,将不同天气条件下的使用量进行分类展示,帮助用户更好地理解天气对共享自行车使用的影响。数据可视化大屏不仅美观大方,而且功能强大,能够帮助用户快速了解共享自行车的使用情况和产品信息,为决策提供有力的支持。数据可视化面板界面如下图所示。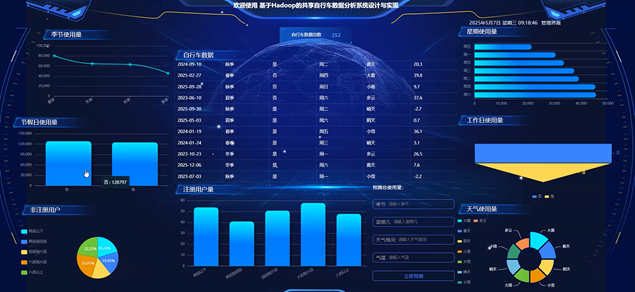
图5-1数据可视化分析面板界面

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)