计算机毕业设计之基于Python的京东销售数据分析与可视化平台的设计与实现
摘要:本文构建了一个基于Python和Hadoop的京东销售数据分析与可视化平台,实现了从数据采集到预测分析的完整流程。系统通过爬虫获取京东商品数据,利用Spark进行分布式计算,结合随机森林回归算法进行销售预测,并采用Vue+Django框架实现可视化展示。平台整合了ECharts、MySQL等技术,提供包括商品特性、用户偏好、价格分布等多维度分析,为商家营销决策和库存管理提供数据支持。可视化大
随着互联网技术的飞速发展和电子商务平台的普及,在线购物已成为人们日常生活中不可或缺的一部分。京东作为中国领先的电子商务平台,其销售数据包含了丰富的市场信息,对于商家和消费者都具有极高的分析价值。特别是在商品销售领域,消费者对于产品的选择越来越多样化,需求也更加个性化。
系统利用Python和Hadoop的分布式存储和计算能力,高效处理海量销售数据,实现数据采集、存储、处理和分析的自动化。通过引入ECharts、Spark、Vue和Django等先进技术,系统提供了直观、动态的数据可视化展示,通过高效的数据挖掘和随机森林回归算法,实现了对京东平台商品销售市场动态的深入洞察与未来销售趋势的精准预测。系统不仅对海量销售数据进行了详细的分析,包括产品特性、用户偏好、价格分布等关键因素,还构建了预测模型,为商家提供了战略规划与库存管理的科学依据,从而优化营销策略,提高市场竞争力。该系统的应用极大地提升了数据分析的效率和预测的准确性,对于电商平台的销售决策具有重要的实践价值。
系统总体流程
系统实现了一个完整的数据处理与分析流程,涵盖了数据来源、数据处理与分析、数据存储和数据可视化四个主要阶段。系统使用爬虫获取京东商品数据集,通过Python中的request库获取数据,使用Pandas库对数据进行清洗和处理,以确保数据的准确性和一致性。之后,采用Spark库分析数据,sklearn机器学习搭建模型与预测,以便更好地理解和展示商品。最后,将处理和分析后的数据存储到MySQL数据库、Hadoop分布式文件系统中,并提供Vue可视化界面供用户查看和分析结果。整个流程实现了对京东商品信息数据的自动化管理和分析,为相关部门提供了有力的决策支持。系统总体流程图如图4-1所示。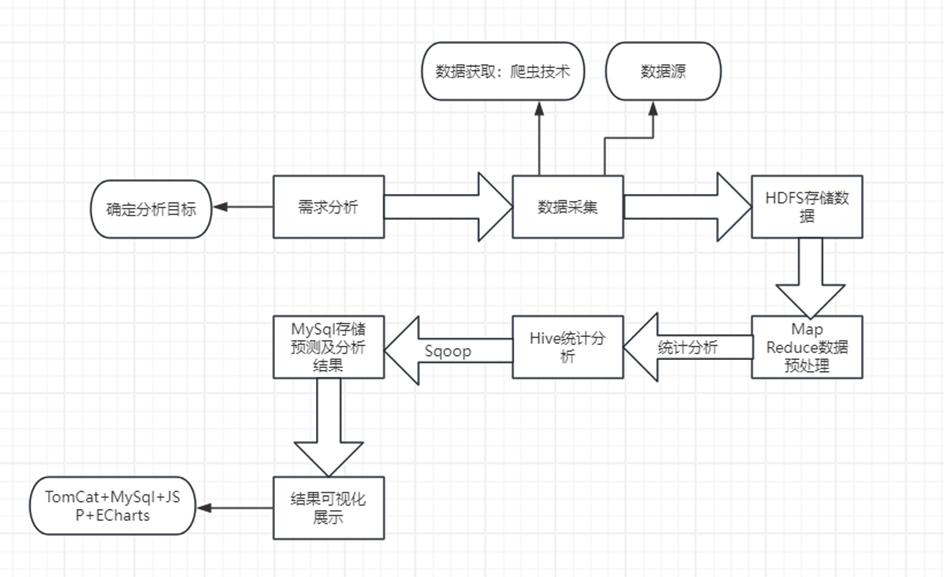
图4-1 系统数据总体流程图
数据可视化实现
在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从京东网站上抓取海量数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,sklearn机器学习搭建模型与预测,将处理后的结果存入MySQL数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
基于Python的京东销售数据分析与可视化平台的数据可视化大屏,通过丰富的图表和图形元素,直观地展示了京东的销售数据和产品信息。大屏左侧展示了商品名称、商品产地和品牌统计,其中商品名称部分显示了苹果平板电脑的相关信息,商品产地部分通过饼图展示了不同产地的分布情况,品牌统计部分则通过环形图展示了各大品牌的占比情况。中间部分是销售数据总览,显示了销售数据总数,下方列出了不同类别商品的销量、评分等信息。右侧部分则是商品价格、月销量和商品评分类别,分别通过柱状图、折线图和堆叠条形图进行了展示。整体来看,这个数据可视化大屏不仅美观大方,而且功能强大,能够帮助用户快速了解京东的销售情况和产品信息,为决策提供有力的支持。数据可视化面板界面如下图所示。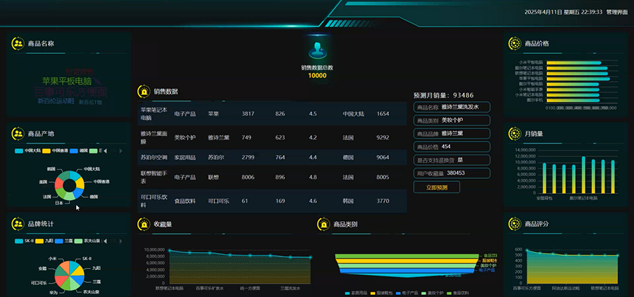
图5-1数据可视化分析面板界面

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)