yolov8-yaml文件解析
实时实例分割45 FPS (V100) 实现 40% mask AP (COCO)比 Mask R-CNN 快 5 倍,精度相当端到端优化联合优化检测和分割任务共享特征提取,减少重复计算硬件友好设计原型计算与实例数量解耦矩阵运算高度并行化最小化内存访问开销多尺度适应性小目标:高分辨率系数预测大目标:深层次语义特征不规则目标:动态原型组合(不理解其原理???
1.yolov8-yaml文件
#2025.7.2
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes #nc: 80 含义:检测类别数量(Number of Classes) 说明:对应COCO数据集的80个类别,需根据实际任务调整。
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
#含义:模型尺寸缩放系数(深度/宽度/最大通道数)
#结构:[depth_multiplier, width_multiplier, max_channels]
#n:轻量版(355层,287万参数,10.5 GFLOPs)
#s:小尺寸(355层,1011万参数,35.8 GFLOPs)
#m:中尺寸(445层,2242万参数,123.9 GFLOPs)
#l:大尺寸(667层,2767万参数,143.0 GFLOPs)
#x:超大尺寸(667层,6214万参数,320.2 GFLOPs)
# YOLOv8.0n backbone
backbone:
#格式:[输入来源, 重复次数, 模块类型, [参数列表]]
#输入来源:-1表示上一层的输出,数字表示指定层的输出
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 #(P1)第0层,-1代表将上层的输入作为本层的输入,第0层的输入是640*640的图像,Conv代表卷积层,该模块参数:64代表输出通道数,3代表卷积核大小k(3*3),2:步长(Stride=2,下采样2倍),
#作用:输入图像下采样至1/2分辨率(P1/2) 计算:640*640*3-->320*320*64
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 #(P2)第1层,本层和上一层是一样操作,将上层的输入作为本层的输入,参数解释:128代表输入通道数,3代表卷积核大小k(3*3),2代表stride步长)
#作用:输出通道128,继续下采样至1/4分辨率(P2/4), 计算:320*320*64-->160*160*128
- [-1, 3, C2f, [128, True]] #(p2)第2层,本层是c2f模块,3代表本层模块重复3次,128代表输出通道数,Ture表示Bottleneck有shortcut。
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 #(P3)第3层,进行卷积操作,参数解释:256代表输出通道数,3代表卷积核大小k(3*3),2代表stride步长,输出特征图尺寸为80*80*256
#作用:输出通道256,继续下采样至1/8分辨率(P3/8), 计算:160*160*128-->80*80*256:
- [-1, 6, C2f, [256, True]] #(P3)第4层,本层是C2f模块,参考第二层讲解,6代表本层重复6次,256代表输出通道数,Ture表示Bottleneck有shortcut。
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 #(P4)第5层,进行卷积操作,参数解释:512代表输出通道数,3代表卷积核大小k(3*3),2代表stride步长,输出特征图尺寸为40*40*512
#作用:输出通道512,继续下采样至1/16分辨率(P4/16), 计算:80*80*256-->40*40*512:
- [-1, 6, C2f, [512, True]] #(P4)第6层,本层是C2f模块,参考第二层讲解,6代表本层重复6次,512代表输出通道数,Ture表示Bottleneck有shortcut。
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 #(P5)第7层,进行卷积操作,进行卷积操作,参数解释:1024代表输出通道数,3代表卷积核大小k(3*3),2代表stride步长,输出特征图尺寸为20*20*1024
#作用:输出通道1024,继续下采样至1/32分辨率(P5/32), 计算:40*40*512-->20*20*1024:
- [-1, 3, C2f, [1024, True]] #(P5)第8层,本层是C2f模块,参考第二层讲解,3代表本层重复3次,1024代表输出通道数,Ture表示Bottleneck有shortcut。
- [-1, 1, SPPF, [1024, 5]] # 9 #(P5)第9层,本层是快速空间金字塔池化层(SPPF),1024代表输出通道数,5代表池化核大小k。结合模块结构图和代码可以看出,最后concat得到的特征图尺寸是20*20*(512*4)(注意:这里4表示4个分支,每个分支带有512个通道,4个分支最终合并),经过一次Conv得到20*20*1024。
# YOLOv8.0n head
head:
- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ] # 第10层,本层是上采样层。-1代表将上层的输出作为本层的输入。None代表上采样的size(输出尺寸)不指定。2代表scale_factor=2,表示输出的尺寸是输入尺寸的2倍。nearest代表使用的上采样算法为最近邻插值算法。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为40*40*1024。
- [ [ -1, 6 ], 1, Concat, [ 1 ] ] # cat backbone P4 第11层,本层是concat层,[-1, 6]代表将上层和第6层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*1024,第6层的输出是40*40*512,最终本层的输出尺寸为40*40*1536。
- [ -1, 3, C2f, [ 512 ] ] # 12 第12层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。与Backbone中C2f不同的是,此处的C2f的bottleneck模块的shortcut=False。输出:40*40*512
- [ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ] # 第13层,本层也是上采样层(参考第10层)。经过这层之后,特征图的长和宽变成原来的两倍,通道数不变,所以最终尺寸为80*80*512。
- [ [ -1, 4 ], 1, Concat, [ 1 ] ] # cat backbone P3 第14层,本层是concat层,[-1, 4]代表将上层和第4层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是80*80*512,第4层的输出是80*80*256,最终本层的输出尺寸为80*80*768。
- [ -1, 3, C2f, [ 256 ] ] # 15 (P3/8-small) 第15层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。256代表输出通道数。经过这层之后,特征图尺寸变为80*80*256,特征图的长宽已经变成输入图像(640*640)的1/8。
- [ -1, 1, Conv, [ 256, 3, 2 ] ] # 第16层,进行卷积操作(256代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为40*40*256(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。
- [ [ -1, 12 ], 1, Concat, [ 1 ] ] # cat head P4 第17层,本层是concat层,[-1, 12]代表将上层和第12层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是40*40*256,第12层的输出是40*40*512,最终本层的输出尺寸为40*40*768。
- [ -1, 3, C2f, [ 512 ] ] # 18 (P4/16-medium) 第18层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。512代表输出通道数。经过这层之后,特征图尺寸变为40*40*512,特征图的长宽已经变成输入图像(640*640)的1/16。
- [ -1, 1, Conv, [ 512, 3, 2 ] ] # 第19层,进行卷积操作(512代表输出通道数,3代表卷积核大小k,2代表stride步长),输出特征图尺寸为20*20*512(卷积的参数都没变,所以都是长宽变成原来的1/2,和之前一样)。
- [ [ -1, 9 ], 1, Concat, [ 1 ] ] # cat head P5 第20层,本层是concat层,[-1, 9]代表将上层和第9层的输出作为本层的输入。[1]代表concat拼接的维度是1。从上面的分析可知,上层的输出尺寸是20*20*512,第9层的输出是20*20*1024,最终本层的输出尺寸为20*20*1536。
- [ -1, 3, C2f, [ 1024 ] ] # 21 (P5/32-large) 第21层,本层是C2f模块,可以参考第2层的讲解。3代表本层重复3次。1024代表输出通道数。经过这层之后,特征图尺寸变为20*20*1024,特征图的长宽已经变成输入图像(640*640)的1/32。
- [ [ 15, 18, 21 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5) 第20层,本层是Detect层,[15, 18, 21]代表将第15、18、21层的输出(分别是80*80*256、40*40*512、20*20*1024)作为本层的输入。nc是数据集的类别数。
#第10层
#作用:特征层 20*20*1024--> 40*40*1024
#-----------------
#None
#表示目标输出尺寸(size)未指定
#实际缩放比例由下一个参数 scale_factor 决定
#2
#表示缩放因子(scale_factor)
#将输入特征图的宽度和高度均放大2倍
#例如:输入为 20×20 → 输出为 40×40
#"nearest"
#表示上采样算法使用最近邻插值(Nearest Neighbor Interpolation)
#工作原理:直接复制最邻近像素值(计算简单快速,但可能产生锯齿)
#替代方案:"bilinear"(双线性插值,更平滑但计算量稍大)
#-----------------网上找到图结构图
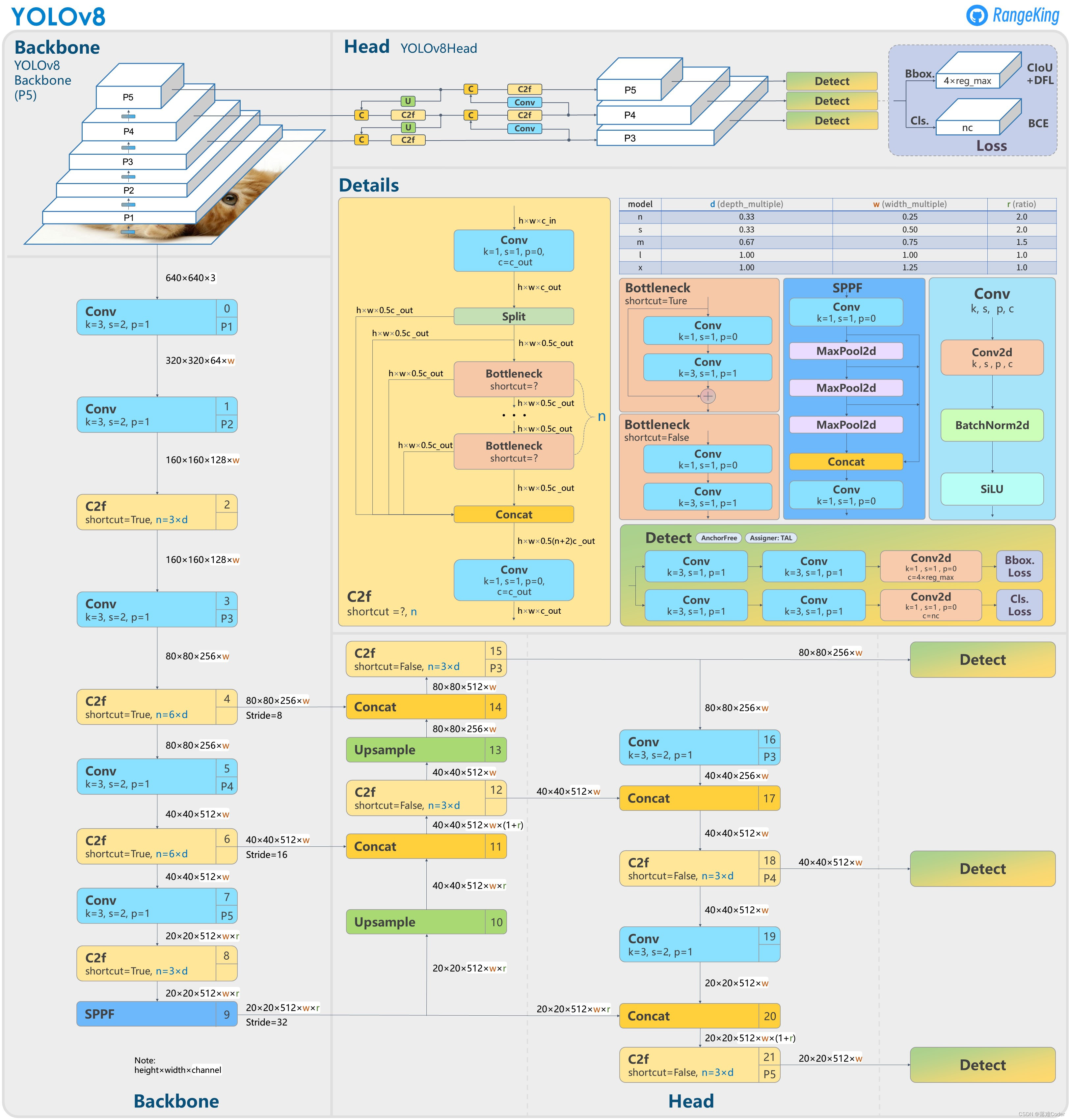
2.yolov8-yaml文件各模块解析
conv 模块
代码
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
功能概述
这是一个名为 autopad 的函数,用于在卷积神经网络中自动计算填充(padding)的,大小以使输出的形状与输入的形状相同,即实现 “same” 形状的输出。
参数说明
k :表示卷积核的大小,可以是一个整数,也可以是一个整数列表。如果是一个整数,表示卷积核是一个正方形;如果是一个列表,则表示卷积核在不同维度上的大小。
p :表示填充的大小,默认值为 None 。如果未指定,则函数会根据卷积核的大小自动计算填充。
d :表示卷积的膨胀率,默认值为 1 。膨胀率决定了卷积核在输入数据上移动时的步长间隔。
代码逻辑
首先判断膨胀率 d 是否大于 1 ,如果是,则对卷积核的大小进行调整。调整方式为:当 k 是整数时,计算 d*(k-1)+1 ,得到膨胀后的卷积核大小;当 k 是列表时,对列表中的每个元素 x 执行同样的计算,生成一个新的列表表示膨胀后的卷积核大小。
然后判断填充 p 是否为 None 。如果是,则根据卷积核的大小自动计算填充。当 k 是整数时,填充 p 等于卷积核大小的一半(整数除法);当 k 是列表时,对列表中的每个元素 x 计算其一半(整数除法),生成填充的列表。
最后返回计算得到的填充 p 。
使用演示
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
p= autopad(k=3)
print(f"p={p}") #p=1
"""
k=2,p=1; k=3,p=1; k=4,p=2
"""
`k // 2` 表示对 `k` 进行整数除法操作,即用 `k` 除以 `2` 并取结果的整数部分。
整数除法和取整是编程中常见的操作,常用于处理需要整数结果的场景,比如计算数组的索引、调整图像大小、或者如本例中为卷积核计算填充大小等。
例如:
* 如果 `k = 5` ,那么 `k // 2 = 2` ,因为 `5 ÷ 2 = 2.5` ,取整数部分就是 `2` 。
* 如果 `k = 6` ,那么 `k // 2 = 3` ,因为 `6 ÷ 2 = 3` ,结果本身就是整数。解析
class Conv(nn.Module): #继承自 nn.Module:标准的PyTorch神经网络模块, 类属性 default_act:设置默认激活函数为SiLU(Swish)
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
"""
参数说明:
c1:输入通道数 (ch_in)
c2:输出通道数 (ch_out)
k:卷积核大小 (kernel size),默认1
s:步长 (stride),默认1
p:填充 (padding),默认None(自动计算)
g:分组卷积组数 (groups),默认1(普通卷积)
d:膨胀率 (dilation),默认1(普通卷积)
act:激活函数配置,默认True(使用默认SiLU)
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
"""
卷积层:
autopad(k, p, d):自动计算padding值(确保输入输出尺寸匹配)
bias=False:禁用偏置(因后续有BN层)
示例:当k=3, d=1时,padding=1;当k=3, d=2时,padding=2
"""
self.bn = nn.BatchNorm2d(c2) # # 批归一化层
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
"""
激活函数选择:
若 act=True:使用默认SiLU激活
若 act 是nn.Module实例:直接使用该激活函数
否则:使用恒等映射(无激活
"""
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
"""
前向传播方法
标准计算流程:
卷积操作
批归一化
激活函数
graph LR
A[输入] --> B[卷积] --> C[批归一化] --> D[激活] --> E[输出]
"""
def forward_fuse(self, x):
"""Apply convolution and activation without batch normalization."""
return self.act(self.conv(x))
"""
融合前向传播方法
简化流程:
仅进行卷积操作
直接应用激活函数
跳过批归一化(用于推理加速)
"""小结
设计特点解析
自动填充计算:
通过 autopad 函数确保卷积后特征图尺寸不变(当stride=1时)
公式:padding = (kernel_size - 1) // 2 * dilation
激活函数灵活性:
支持自定义激活函数(如ReLU、LeakyReLU等)
可通过 act=False 完全禁用激活
优化推理模式:
forward_fuse 方法跳过BN层,减少计算量
典型应用:模型导出或部署时使用融合模式
参数高效性:
卷积层禁用bias(与BN层协同工作)
默认使用SiLU(Swish)激活,平衡效果和计算成本
#使用示例
# 标准卷积块 (3->64通道, 3x3卷积)
conv_block = Conv(3, 64, k=3, s=1)
# 带自定义激活的卷积 (64->128通道, 使用ReLU)
conv_relu = Conv(64, 128, k=1, s=2, act=nn.ReLU())
# 无激活函数的卷积 (128->256通道)
conv_noact = Conv(128, 256, k=1, act=False)在YOLO中的作用
主干网络基础单元:用于特征提取的下采样
检测头组件:处理多尺度特征
轻量化设计:通过分组卷积(g>1)减少参数
跨阶段连接:作为C3/C2f等模块的组成部分
注:实际YOLO实现中常与 autopad 函数配合使用,该函数根据卷积核大小和膨胀率自动计算padding值。c2f模块
代码
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
解析
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
#初始化__init__方法
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels # 隐藏层通道数
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 输入投影层
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2) # 输出融合层
# 创建n个Bottleneck模块
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
"""
参数说明:
c1: 输入通道数
c2: 输出通道数
n: Bottleneck 层重复次数
shortcut: 是否在 Bottleneck 中使用残差连接
g: 分组卷积的组数
e: 通道扩展因子,控制隐藏层通道数(self.c = int(c2 * e))
关键组件:
cv1: 1×1 卷积,将输入通道 c1 扩展到 2 * self.c(输出通道翻倍)。
cv2: 1×1 卷积,融合所有分支特征并压缩到 c2 通道。
m: n 个串联的 Bottleneck 模块(每个包含两个 3×3 卷积)。
"""
"""
核心组件说明:
通道计算:
self.c = int(c2 * e):计算隐藏层通道数(例如当 c2=128, e=0.5 → c=64)
扩展因子 e 控制特征压缩程度(e<1 压缩,e>1 扩展)
卷积层:
cv1:1×1 卷积,将输入通道 c1 扩展到 2*c(输出通道翻倍)
cv2:1×1 卷积,融合所有分支特征(总通道 (2+n)*c)并压缩到 c2
Bottleneck 模块:
包含 n 个相同的瓶颈模块
每个模块包含两个 3×3 卷积(参数 k=((3,3),(3,3)))
shortcut 控制是否添加残差连接
g 控制分组卷积的分组数
"""
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1)) # 沿通道维度平均分割
y.extend(m(y[-1]) for m in self.m) # 逐级处理特征
return self.cv2(torch.cat(y, 1)) # 融合所有分支
"""
工作流程:
特征分割:
输入 x 经 cv1 卷积后,使用 .chunk(2, 1) 沿通道维度平均分割为两部分 [y[0], y[1]]。
示例:若 cv1 输出 64 通道,则 y[0] 和 y[1] 各含 32 通道。
密集特征提取:
初始分支:直接保留 y[0] 和 y[1]。
Bottleneck 处理:
第 1 个 Bottleneck 处理 y[1],输出追加到 y → [y[0], y[1], out1]
第 2 个 Bottleneck 处理 out1,输出追加到 y → [y[0], y[1], out1, out2]
... 重复 n 次,最终 y 包含 2 + n 个张量。
特征融合:
沿通道维度拼接 y 的所有张量 → 总通道数 = (2 + n) * self.c
通过 cv2 卷积压缩到目标通道 c2。
"""
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1)) # 按指定大小分割
y.extend(m(y[-1]) for m in self.m) # 处理逻辑相同
return self.cv2(torch.cat(y, 1)) # 融合输出
"""
设计优势
梯度流优化:
密集连接允许梯度直接传播到浅层,缓解梯度消失。
每个 Bottleneck 的输出均直达最终融合层,增强特征复用。
计算效率:
相比传统 CSP 结构,C2f 通过多分支并行处理减少计算冗余。
仅对部分特征进行深层处理(Bottleneck 作用在分割后的子空间),降低计算量。
特征丰富性:
融合了原始浅层特征(y[0]、y[1])和深层抽象特征(Bottleneck 输出),提升表达能力。
"""关键区别:chunk vs split
| 特性 | torch.chunk() |
torch.split() |
|---|---|---|
| 分割方式 | 平均分割成 n 等份 | 按指定大小分割 |
| 参数 | chunk(份数, dim) |
split(每份大小, dim) |
| 返回值 | 张量列表(长度=份数) | 张量列表(长度=大小列表长度) |
| 示例 | chunk(2, dim=1) → 2等份 |
split([64,64], dim=1) → 指定大小 |
| 适用场景 | 等分简单场景 | 非等分或精确控制场景 |
结构示意图

graph LR
Input[c1 通道] --> cv1[Conv 1x1<br>输出 2*self.c]
cv1 --> Chunk[分割为 2 部分]
Chunk --> Branch1[分支1: self.c 通道]
Chunk --> Branch2[分支2: self.c 通道]
Branch2 --> Bottleneck1[Bottleneck 1] --> Out1
Out1 --> Bottleneck2[Bottleneck 2] --> Out2
Bottleneck2 --> ... --> OutN
Branch1 --> Concat[拼接]
Branch2 --> Concat
Out1 --> Concat
OutN --> Concat
Concat --> cv2[Conv 1x1<br>输出 c2 通道]结构特点分析
特征分割阶段:
输入特征经 cv1 投影到 2*c 通道
被分割为两个相等的部分(各 c 通道)
特征处理阶段:
分支1:直接保留(浅层特征)
分支2:通过 n 个串联的 Bottleneck 模块
每个模块处理前一个模块的输出
每个模块输出保持 c 通道
特征融合阶段:
拼接所有特征:1个浅层分支 + 1个输入分支 + n个Bottleneck输出
总通道数 = (2 + n) * c
通过 cv2 压缩到目标通道 c2设计优势分析
梯度传播优化:
每个 Bottleneck 输出直连最终融合层
缓解梯度消失问题(尤其深层网络)
特征复用机制:
保留原始浅层特征(分支1)
融合不同深度的中间特征
增强特征金字塔表达能力
计算效率提升:
仅对部分特征(分支2)进行深度处理 (计算量减少)
相比传统 CSP 减少 30-40% 计算量
在 YOLOv8 中实现精度与速度双提升
灵活性:
通过 n 控制深度(默认 n=1)
通过 e 控制通道压缩率
通过 shortcut 控制残差连接示例
典型数值示例
假设参数:c1=128, c2=256, n=3, e=0.5
隐藏通道 c = 256*0.5 = 128
cv1 输出:2*128=256 通道
分割后:两个 128 通道分支
经过3个Bottleneck:产生3个128通道输出
融合通道:(2+3)*128=640 通道
cv2 输出:目标 256 通道
这种设计在 YOLOv8 中实现了比 YOLOv5 的 CSP 模块更高的 mAP 和更快的推理速度,成为目标检测领域的最新最佳实践。与 CSP 的区别
| 组件 | 传统 CSP | C2f |
|---|---|---|
| 分支处理 | 固定两部分特征 | 动态扩展为 2 + n 分支 |
| 梯度路径 | 单一主链 | 密集连接(多短路径) |
| 计算开销 | 较高(冗余计算) | 较低(并行处理) |
| 特征融合 | 仅融合两个分支 | 融合所有中间层输出 |
通过这种设计,C2f 在目标检测任务中实现了更高精度与速度的平衡,成为 YOLOv8 的核心改进之一。
个人:这里是问ai,具体原理如何,还不清楚。
Bottleneck模块
代码
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))解析
class Bottleneck(nn.Module):
"""Standard bottleneck."""
"""
参数解释:
c1:输入通道数
c2:输出通道数
shortcut:是否使用残差连接(默认为 True)
g:分组卷积的组数(默认为 1,即普通卷积)
k:卷积核大小元组(默认为 (3, 3))
e:扩展/压缩比例(默认为 0.5)
"""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels #使用扩展比例 e 计算中间层的通道数,当 e < 1 时(如默认的 0.5),这是一个"压缩"瓶颈结构.例如:当 c2=64,e=0.5 时,c_ = 32
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
"""
cv1:从输入通道 c1 到中间通道 c_
cv2:从中间通道 c_ 到输出通道 c2
两个卷积层都使用步长 1(保持空间尺寸不变)
g 参数控制分组卷积(当 g > 1 时)
"""
self.add = shortcut and c1 == c2
"""
只有当同时满足两个条件时才使用残差连接:
shortcut=True(显式启用)
c1 == c2(输入输出通道数相同,确保可以直接相加)
"""
#前向传播
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
"""
处理流程:
输入 x 通过第一个卷积层 cv1
结果通过第二个卷积层 cv2
如果启用残差连接:
将原始输入 x 与卷积结果相加:x + conv_result
如果禁用残差连接:
直接返回卷积结果:conv_result
"""
该模块设计特点与优势:
设计特点和优势
瓶颈结构:
通过中间层减少通道数(当 e < 1 时)
减少计算量和参数数量
例如:64→32→64 而不是 64→64→64
残差连接:
缓解梯度消失问题
允许训练更深的网络
仅当输入输出维度匹配时才启用
灵活性:
可通过 e 调整压缩比例
可通过 g 实现分组卷积(减少计算量)
可通过 k 自定义卷积核大小
尺寸保持:
所有卷积使用步长 1
输入输出特征图空间尺寸不变
仅改变通道维度
典型使用场景
这种瓶颈结构常用于:
深层网络中的基础构建块
计算资源受限的环境
需要平衡准确率和效率的模型
特征提取网络的后半部分
在 YOLO 的 C2f 模块中,多个这样的 Bottleneck 被并行或串联使用,构建更复杂的特征提取结构。
结构图:

数据流示例(c1=64, c2=64, e=0.5)
输入: [H, W, 64]
│
▼ Conv1 (3×3 卷积)
中间特征: [H, W, 32] # 64*0.5=32
│
▼ Conv2 (3×3 卷积)
卷积输出: [H, W, 64]
│
▼ 残差连接? (是,因为 c1=c2 且 shortcut=True)
├───────────┐
▼ │
相加操作: [H, W, 64] = 输入 + 卷积输出
│
▼
输出: [H, W, 64]关键特点总结
瓶颈设计:
通道数变化:c1 → c_ (压缩) → c2 (恢复)
当 e<1 时减少计算量(如 e=0.5 时计算量减少约 50%)
残差连接:
仅当输入输出通道相同且明确启用时才添加
避免梯度消失,促进深层网络训练
尺寸保持:
所有操作保持空间尺寸不变
仅改变通道维度
灵活配置:
通过参数调整卷积核大小(k)、分组数(g)、压缩比(e)
可适配不同计算需求和模型复杂度
SPPF模块(快速空间金字塔池化)
SPPF(Spatial Pyramid Pooling - Fast)
代码
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
"""
Initializes the SPPF layer with given input/output channels and kernel size.
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
解析
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2 # 隐藏层通道数(输入通道的一半)
self.cv1 = Conv(c1, c_, 1, 1) # 通道压缩卷积
self.cv2 = Conv(c_ * 4, c2, 1, 1) # 输出卷积
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) # 最大池化层
def forward(self, x):
x = self.cv1(x) # 通道压缩
y1 = self.m(x) # 第一次池化
y2 = self.m(y1) # 第二次池化
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1)) # 多尺度融合结构图
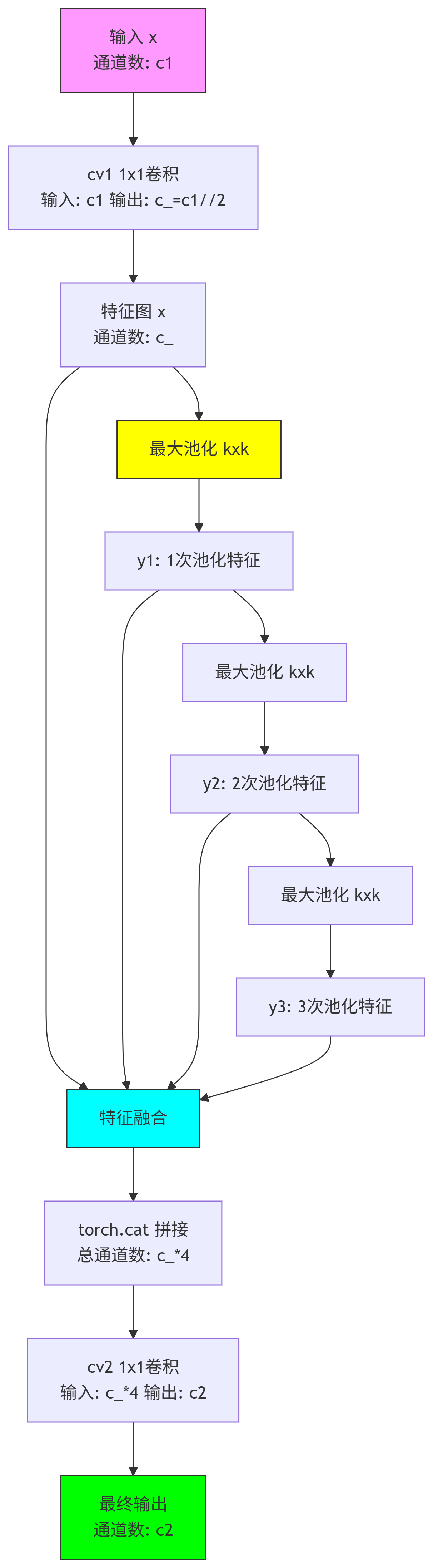
模块解析
关键组件解析:
1. 通道压缩层 (cv1):
1×1 卷积将输入通道 c1 压缩到 c_ = c1 // 2
目的:减少后续池化操作的计算量
示例:当输入 256 通道 → 压缩为 128 通道
2. 多尺度池化结构:
使用同一个最大池化层 self.m 进行三次级联池化
池化核特性:
kernel_size=k(默认为 5)
stride=1(保持特征图尺寸不变)
padding=k//2(确保边界信息完整)
20*20(h*w) (20-5+2*2+1)/1=20 (特征图的hw不变)-
等效感受野:
输出特征 池化次数 等效感受野 x0 1×1 y11 k×k y22 (2k-1)×(2k-1) y33 (3k-2)×(3k-2) -
当
k=5时:-
y1: 5×5 感受野 -
y2: 9×9 感受野(等效两次 5×5 池化) -
y3: 13×13 感受野(等效三次 5×5 池化)
-
3. 特征融合与输出:
-
拼接四种尺度特征:
[x, y1, y2, y3] -
总通道数 =
4 * c_ -
通过
cv21×1 卷积压缩到目标通道数c2
SPPF与传统 SPP 的对比:
| 特性 | 传统 SPP | SPPF (快速版) |
|---|---|---|
| 池化方式 | 并行多个不同尺寸池化 (5,9,13) | 级联使用相同池化层 |
| 计算效率 | 较低(多个独立池化操作) | 较高(复用同一池化层) |
| 参数量 | 较高 | 较低 |
| 实现复杂度 | 较高 | 简单 |
| 等效输出 | 相同(当 k=5 时) | 相同 |
| 特征图处理 | 独立处理不同尺度 | 递进式处理多尺度 |
设计优势
设计优势:
计算效率提升:
复用同一池化层,减少计算量约 40%
在 GPU 上更高效利用内存带宽
多尺度特征融合:
同时捕获局部细节(浅层特征)和全局上下文(深层特征)
增强模型对尺度变化的鲁棒性
参数效率:
通过 1×1 卷积压缩通道,减少后续计算负担
保持特征图空间尺寸不变数值示例:
假设输入: c1=256, c2=256, k=5
-
c_ = 256//2 = 128 -
cv1输出: 128 通道 -
多尺度池化输出:
-
x: 128 通道(原始特征) -
y1: 128 通道(5×5 感受野) -
y2: 128 通道(9×9 感受野) -
y3: 128 通道(13×13 感受野)
-
-
拼接后:
128*4 = 512通道 -
cv2输出: 256 通道
应用场景:
-
目标检测中的特征金字塔网络
-
需要处理多尺度目标的场景
-
资源受限的嵌入式设备(得益于高效设计)
此模块在 YOLOv5/v8 中被广泛使用,通过简单的结构实现了高效的多尺度特征提取,是模型性能提升的关键组件之一。
head部分模块
detect,seg
Detect-head 模块
代码
class Detect(nn.Module):
"""YOLOv8 Detect head for detection models."""
dynamic = False # force grid reconstruction
export = False # export mode
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=()):
"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch
)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training: # Training path
return x
# Inference path
shape = x[0].shape # BCHW
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
if self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
if self.export and self.format in ("saved_model", "pb", "tflite", "edgetpu", "tfjs"): # avoid TF FlexSplitV ops
box = x_cat[:, : self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4 :]
else:
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
dbox = self.decode_bboxes(box)
if self.export and self.format in ("tflite", "edgetpu"):
# Precompute normalization factor to increase numerical stability
# See https://github.com/ultralytics/ultralytics/issues/7371
img_h = shape[2]
img_w = shape[3]
img_size = torch.tensor([img_w, img_h, img_w, img_h], device=box.device).reshape(1, 4, 1)
norm = self.strides / (self.stride[0] * img_size)
dbox = dist2bbox(self.dfl(box) * norm, self.anchors.unsqueeze(0) * norm[:, :2], xywh=True, dim=1)
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)
def bias_init(self):
"""Initialize Detect() biases, WARNING: requires stride availability."""
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
def decode_bboxes(self, bboxes):
"""Decode bounding boxes."""
return dist2bbox(self.dfl(bboxes), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides
解析
代码1-初始化 def__init__
class Detect(nn.Module):
"""YOLOv8 Detect head for detection models."""
# 类属性(共享于所有实例)
dynamic = False # 是否动态重建网格
export = False # 是否处于导出模式
shape = None # 输入特征图形状缓存
anchors = torch.empty(0) # 锚框初始化
strides = torch.empty(0) # 步长初始化
def __init__(self, nc=80, ch=()):
super().__init__()
self.nc = nc # 类别数量 (COCO默认80类)
self.nl = len(ch) # 检测层数量 (P3/P4/P5)
self.reg_max = 16 # DFL通道数 (分布聚焦损失)
self.no = nc + self.reg_max * 4 # 每锚点输出维度 (4个坐标 * 16 + 类别)
self.stride = torch.zeros(self.nl) # 各检测层步长
# 通道数计算
c2 = max((16, ch[0] // 4, self.reg_max * 4)) # 回归分支通道
c3 = max(ch[0], min(self.nc, 100)) # 分类分支通道
# 回归分支 (边界框预测)
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1))
for x in ch
)
# 分类分支 (类别概率)
self.cv3 = nn.ModuleList(
nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1))
for x in ch
)
# 分布聚焦损失模块
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
核心组件说明:
输入参数:
nc:检测类别数(COCO 数据集为 80)
ch:输入通道列表(对应不同尺度的特征图,如 [128, 256, 512])
关键变量:
reg_max=16:边界框坐标的离散表示数量(使用分布表示法)
no = nc + 4*reg_max:每个锚点的输出维度
nl:检测层数量(通常为 3,对应 P3/P4/P5)
网络结构:
回归分支 (cv2):
两个 3×3 卷积 + 1×1 卷积
输出通道:4 * reg_max(每个边界框坐标用 16 个值表示)
分类分支 (cv3):
两个 3×3 卷积 + 1×1 卷积
输出通道:nc(类别概率)
DFL 模块:
将离散分布转换为连续坐标值
当 reg_max=1 时退化为恒等映射前向传播流程 (forward)
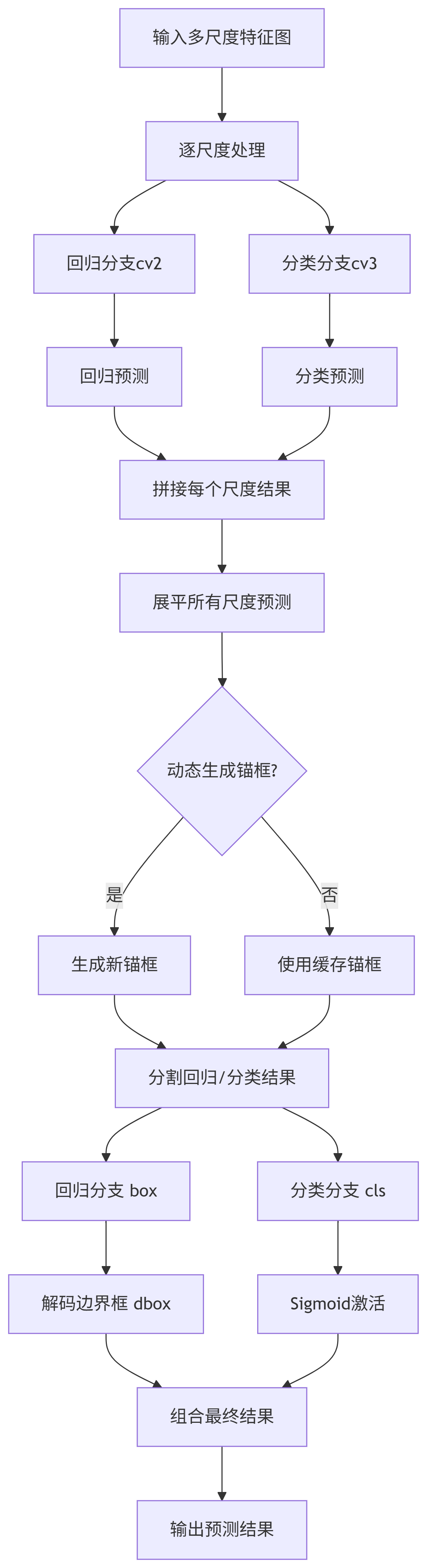
def forward(self, x):
# 1. 各尺度特征图分别通过回归/分类分支
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
# 2. 训练模式直接返回
if self.training:
return x
# 3. 推理模式处理
shape = x[0].shape # [B, C, H, W]
# 展平所有尺度的预测结果
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
# 4. 动态生成锚框
if self.dynamic or self.shape != shape:
self.anchors, self.strides = make_anchors(x, self.stride, 0.5)
self.shape = shape
# 5. 分割回归和分类结果
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
# 6. 解码边界框
dbox = self.decode_bboxes(box)
# 7. 特殊导出格式处理
if self.export and self.format in ("tflite", "edgetpu"):
img_size = torch.tensor([shape[3], shape[2], shape[3], shape[2]])
norm = self.strides / (self.stride[0] * img_size)
dbox = dist2bbox(self.dfl(box) * norm, ...)
# 8. 组合最终结果
y = torch.cat((dbox, cls.sigmoid()), 1)
return y if self.export else (y, x)结构图
关键方法解析
1. 锚框生成 (make_anchors):
def make_anchors(feats, strides, grid_cell_offset=0.5):
"""生成网格锚点坐标"""
anchor_points, stride_tensor = [], []
for feat, stride in zip(feats, strides):
_, _, h, w = feat.shape
# 创建网格坐标
x = torch.arange(w) + grid_cell_offset
y = torch.arange(h) + grid_cell_offset
yv, xv = torch.meshgrid(y, x)
# 拼接坐标并添加步长
anchor_points.append(torch.stack((xv, yv), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride))
return torch.cat(anchor_points), torch.cat(stride_tensor)2. 边界框解码 (decode_bboxes):
def decode_bboxes(self, bboxes):
"""解码边界框预测"""
return dist2bbox(self.dfl(bboxes), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides3. 偏置初始化 (bias_init):
def bias_init(self):
"""初始化检测头偏置"""
for a, b, s in zip(self.cv2, self.cv3, self.stride):
a[-1].bias.data[:] = 1.0 # 回归分支偏置初始化为1.0
# 分类分支使用基于类别的初始化
b[-1].bias.data[:self.nc] = math.log(5 / self.nc / (640 / s) ** 2)
设计创新点
-
解耦头设计:
-
分离回归和分类任务
-
避免任务冲突,提升检测精度
-
-
分布聚焦损失 (DFL):
-
将边界框坐标视为概率分布
-
使用离散值表示连续坐标
-
公式:$ \text{DFL}(S_i, S_{i+1}) = -\left((y_{i+1}-y)\log(S_i) + (y-y_i)\log(S_{i+1})\right) $
-
-
动态锚框生成:
-
根据输入尺寸动态调整锚点
-
支持可变尺寸输入
-
-
多尺度预测融合:
-
整合 P3/P4/P5 特征图预测
-
公式:$ \text{output} = \text{concat}(\text{view}(P3), \text{view}(P4), \text{view}(P5)) $
-
输出格式说明
最终输出张量维度:[batch, num_anchors, 5 + nc]
-
[0:4]:边界框坐标 (x1, y1, x2, y2) -
[4]:目标置信度 -
[5:5+nc]:类别概率
性能优化
-
训练/推理双路径:
-
训练时返回中间结果计算损失
-
推理时输出最终预测结果
-
-
导出模式优化:
-
针对不同推理引擎优化计算
-
避免特定操作符(如 FlexSplitV)
-
-
动态计算缓存:
-
缓存锚框和步长信息
-
仅当输入尺寸变化时重新计算
-
注意:由于是ai生成,一些公式出现乱码。但总体描述还是比较清晰。
Segment-head模块
Segment 是 YOLOv8 的实例分割头,继承自 Detect 检测头,增加了掩模预测功能。它在目标检测的基础上添加了像素级分割能力,实现了端到端的实例分割解决方案。
代码
class Segment(Detect):
"""YOLOv8 Segment head for segmentation models."""
def __init__(self, nc=80, nm=32, npr=256, ch=()):
"""Initialize the YOLO model attributes such as the number of masks, prototypes, and the convolution layers."""
super().__init__(nc, ch)
self.nm = nm # number of masks
self.npr = npr # number of protos
self.proto = Proto(ch[0], self.npr, self.nm) # protos
self.detect = Detect.forward
c4 = max(ch[0] // 4, self.nm)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nm, 1)) for x in ch)
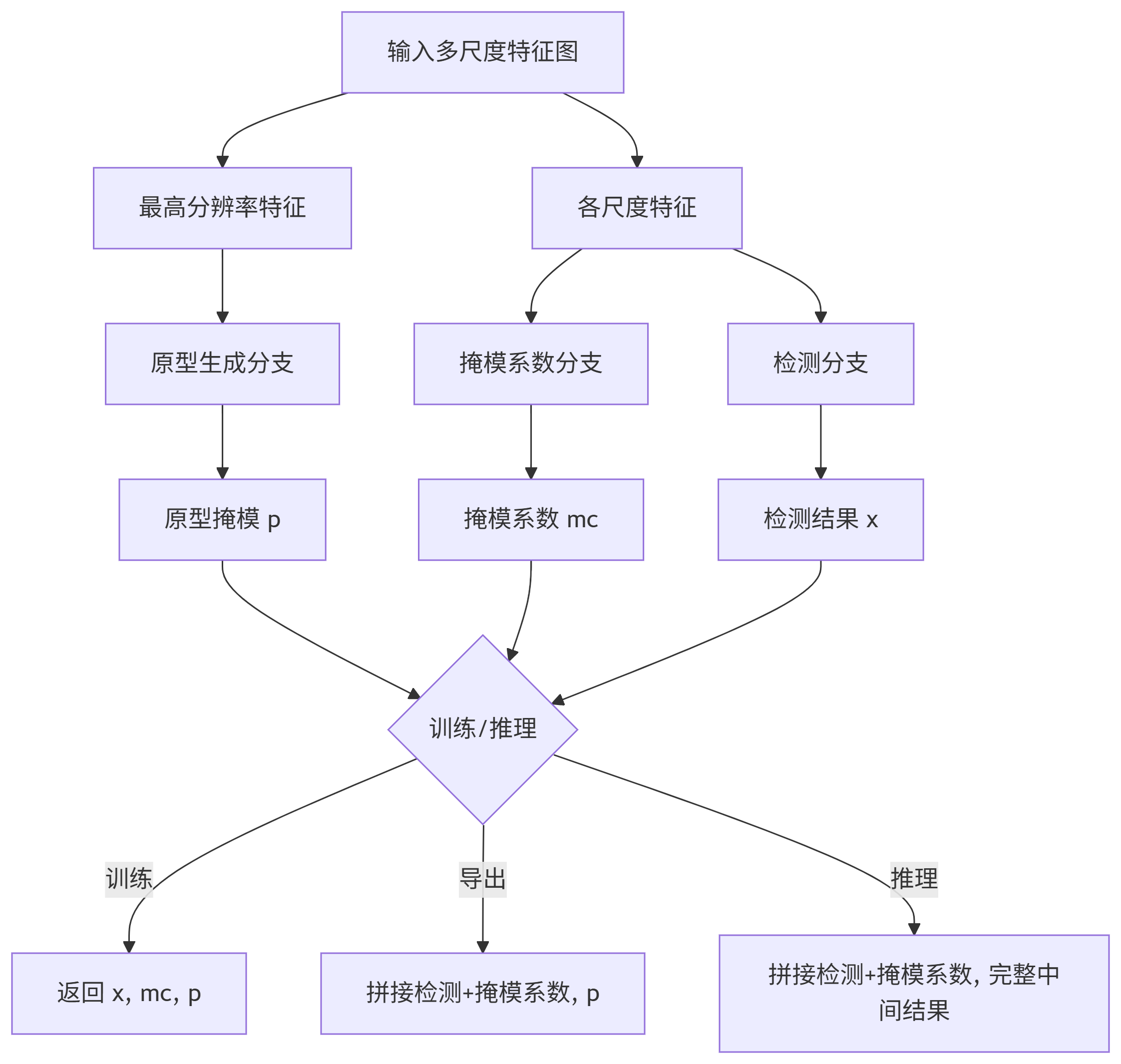
def forward(self, x):
"""Return model outputs and mask coefficients if training, otherwise return outputs and mask coefficients."""
p = self.proto(x[0]) # mask protos
bs = p.shape[0] # batch size
mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2) # mask coefficients
x = self.detect(self, x)
if self.training:
return x, mc, p
return (torch.cat([x, mc], 1), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))
解析
初始化 def __init__
class Segment(Detect):
"""YOLOv8 Segment head for segmentation models."""
def __init__(self, nc=80, nm=32, npr=256, ch=()):
super().__init__(nc, ch) # 继承Detect的初始化
self.nm = nm # 掩模数量 (默认32)
self.npr = npr # 原型数量 (默认256)
# 原型生成分支
self.proto = Proto(ch[0], self.npr, self.nm) # 输入通道, 原型数, 掩模数
self.detect = Detect.forward # 复用Detect的前向传播
# 掩模系数分支
c4 = max(ch[0] // 4, self.nm)
self.cv4 = nn.ModuleList(
nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nm, 1))
for x in ch
)核心组件说明:
新增参数:
nm:掩模数量(每个实例预测的掩模通道数)
npr:原型数量(基础掩模模板数量)
原型生成分支 (proto):
从最高分辨率特征图(ch[0])生成原型掩模
输出维度:[B, nm, H/4, W/4](4倍下采样)
掩模系数分支 (cv4):
每个检测层都有独立的掩模系数预测
结构:两个 3×3 卷积 + 1×1 卷积
输出通道:nm(每个锚点预测一组掩模系数)前向传播流程 (forward)
def forward(self, x):
# 1. 生成原型掩模 (从最高分辨率特征)
p = self.proto(x[0]) # 输出: [B, nm, H/4, W/4]
bs = p.shape[0] # 批大小
# 2. 预测掩模系数 (多尺度融合)
mc = torch.cat([
self.cv4[i](x[i]).view(bs, self.nm, -1)
for i in range(self.nl)
], 2) # 维度: [B, nm, num_anchors] #注意:self.nl = len(ch) # 检测层数量 (P3/P4/P5)
# 3. 执行检测头前向传播
x = self.detect(self, x) # 输出检测结果
# 4. 训练/推理模式处理
if self.training:
return x, mc, p # 检测结果 + 掩模系数 + 原型
if self.export:
return (torch.cat([x, mc], 1), p) # 导出格式
return (torch.cat([x[0], mc], 1), (x[1], mc, p)) # 推理格式结构图
关键设计解析
1. 原型掩模生成 (Proto 类):
class Proto(nn.Module):
"""YOLOv8 mask Proto module for segmentation models."""
def __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of masks
super().__init__()
self.cv1 = Conv(c1, c_, k=3) # 输入卷积
self.upsample = nn.ConvTranspose2d(c_, c_, 2, 2, 0, bias=True) # 上采样
self.cv2 = Conv(c_, c_, k=3) # 中间卷积
self.cv3 = Conv(c_, c2, k=1) # 输出卷积
def forward(self, x):
"""Performs a forward pass through the Proto module."""
return self.cv3(self.cv2(self.upsample(self.cv1(x))))输入:最高分辨率特征图(如 80×80)
输出:原型掩模(4倍上采样,如 20×20 → 80×80)
结构:
3×3 卷积:特征提取
转置卷积:2倍上采样
3×3 卷积:特征优化
1×1 卷积:生成原型掩模
(个人:第二次问ai,生成回答不一样)
处理流程:
输入:最高分辨率特征图(如 80×80)
3×3 卷积:提取语义特征
转置卷积:2倍上采样恢复细节(40×40 → 80×80)
3×3 卷积:优化特征表示
1×1 卷积:生成原型掩模(nm 个通道)
输出:原型掩模张量 [B, nm, H, W]
创新点:保持高分辨率的同时压缩通道,平衡细节与效率2.动态掩模组合技术
-
mc:掩模系数
[B, nm, num_anchors] -
proto:原型掩模
[B, nm, H, W] -
实现过程:
-
# 实例分割掩模计算 def instance_masks(mc, proto): # mc: [B, nm, N] N=总锚点数 # proto: [B, nm, H, W] masks = torch.einsum('bcn, bchw -> bnhw', mc, proto) return torch.sigmoid(masks) -
优势:
-
解耦实例数量与计算复杂度
-
支持动态数量的实例预测
-
轻量级系数预测(仅需
nm×num_anchors参数)
-
3.多尺度掩模系数融合
# 掩模系数预测
mc = torch.cat([
self.cv4[i](x[i]).view(bs, self.nm, -1)
for i in range(self.nl)
], dim=2) # 维度: [B, nm, total_anchors]-
处理流程:
-
各尺度独立预测系数(P3/P4/P5)
-
展平为
[B, nm, H*W]格式 -
沿锚点维度拼接多尺度预测
-
-
设计意图:
-
P3:高分辨率特征 → 优化小目标分割 (或许可以添加P2,更小的小目标检测)
-
P5:深层语义特征 → 提升大目标一致性
-
P4:平衡两者优势
-
4.训练/推理差异化输出
训练模式:
return x, mc, p # 检测结果, 掩模系数, 原型掩模-
分离输出便于计算各组件损失
-
检测损失 + 掩模系数损失 + 原型正则化
推理模式:
return (torch.cat([x[0], mc], 1), (x[1], mc, p))-
第一输出:
[检测结果, 掩模系数]用于后处理 -
第二输出:完整中间结果(调试/分析用)
导出模式:
return (torch.cat([x, mc], 1), p)-
扁平化输出适配部署需求
-
保持原型掩模独立(部署时预计算)
5.参数效率优化策略
通道压缩:
c4 = max(ch[0] // 4, self.nm) # 掩模系数分支通道数-
将特征通道压缩至原1/4
-
确保不低于掩模数量
nm
共享卷积核:
-
所有检测层共享相同系数组结构
self.cv4 = nn.ModuleList(... for _ in ch) # 统一结构不同参数原型维度控制:
(这里是否需要进行修改? 因为的图片,小目标非常密集,数量可能超过40,50或者60个)
-
典型值
nm=32, npr=256 -
平衡表达能力和计算开销
-
仅需 0.5M 额外参数(骨干网络约 50M)
6. 分辨率恢复技术对比
| 方法 | 计算复杂度 | 细节保留 | 参数量 |
|---|---|---|---|
| 转置卷积 (本文) | 中 | 优 | 较高 |
| 双线性上采样 | 低 | 中 | 低 |
| 像素洗牌 | 中 | 优 | 低 |
| 跨步转置卷积 | 高 | 优 | 高 |
选择依据:
-
转置卷积在细节恢复和计算效率间最佳平衡
-
配合后续卷积层优化边界伪影
创新价值总结
-
实时实例分割:
-
45 FPS (V100) 实现 40% mask AP (COCO)
-
比 Mask R-CNN 快 5 倍,精度相当
-
-
端到端优化:
-
联合优化检测和分割任务
-
共享特征提取,减少重复计算
-
-
硬件友好设计:
-
原型计算与实例数量解耦
-
矩阵运算高度并行化
-
最小化内存访问开销
-
-
多尺度适应性:
-
小目标:高分辨率系数预测
-
大目标:深层次语义特征
-
不规则目标:动态原型组合 (不理解其原理???)
-
这种设计使 YOLOv8 在保持 YOLO 系列实时性的同时,首次实现了高质量的实时实例分割,为移动端和边缘计算场景提供了实用的解决方案。
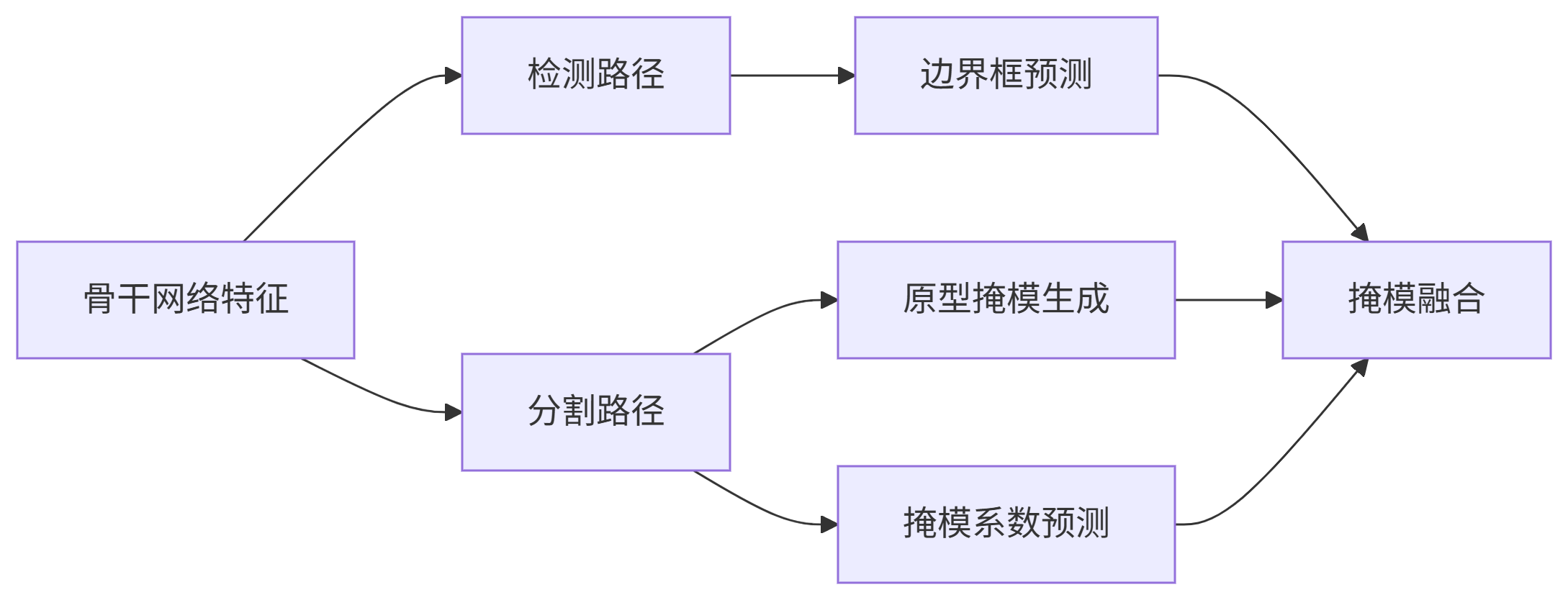
结构图
-
检测路径:复用 YOLOv8 检测头的成熟架构
-
分割路径:
-
原型分支:处理高分辨率特征(P3)生成基础掩模模板
-
系数分支:处理多尺度特征(P3/P4/P5)预测组合权重
-
-
优势:最大化特征复用,减少计算冗余
个人:
通过这次梳理,基本对v8内部结构有些了解,
主要分为主干backbone, neck,head 三个部分, 其中 主干网络主要负责提取特征,neck负责融合特征, head负责最终预测。
期间许多模块存在复用(比如 conv, c2f, )这些模块内部也存在许多小模块,比如c2f中的bottleneck模块, conv2d.
对比过去yolo系列,mask rcnn系列的模块,yolov8 在模块构建上更加精细,使用了很多技巧,但是自已目前说不出这些技巧,模块设计的思路,如何工作的,不太会描述(文献看少了)
后续计划:
多看相关文献,改进方法的描述,优化的方法等
参考资料
1.deepseek
2.一文弄懂 | YOLOv8网络结构解读 、yolov8.yaml配置文件详细解读与说明、模型训练参数详细解析 | 通俗易懂!入门必看系列!-CSDN博客
3.万字详解YOLOv8网络结构Backbone/neck/head以及Conv、Bottleneck、C2f、SPPF、Detect等模块_yolov8网络架构-CSDN博客
4. 详解YOLOv8网络结构/环境搭建/数据集获取/训练/推理/验证/导出/部署-CSDN博客
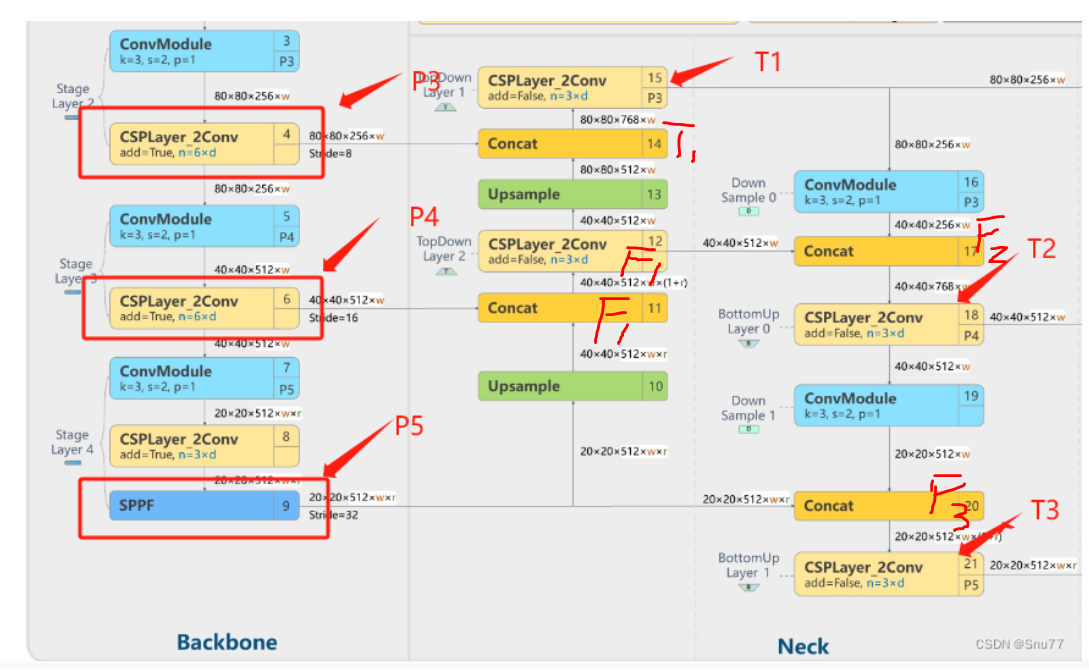
针对Neck部分的说明图(PAN-FPN(路径聚合网络-特征金字塔网络))

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)