(完全解决)Resource punkt_tab not found. Please use the NLTK Downloader to obtain the resource
关键就是,根据我们之前写的分析,你要得到tokenizers/punkt_tab/english这个文件夹,并且要将其放置在任意一个之前提到过的目录下,比如我将其放置在第一个目录。然后会发现当前目录下有一个nltk_data文件夹,这个文件和github目录保持了一致。使用nltk的时候报错(吐槽一句,nltk这玩意经常报错,为啥还这么多人用,无语),我们要的就是那两个zip文件夹,需要解压缩,然
报错
使用nltk的时候报错(吐槽一句,nltk这玩意经常报错,为啥还这么多人用,无语),
tokens = nltk.word_tokenize(sentence)
报错如下:
Resource punkt_tab not found. Please use the NLTK Downloader to
obtain the resource:
import nltk
nltk.download(‘punkt_tab’)
分析
看下面,说白了这玩意就是想要找一个tokenizers/punkt_tab/english的文件夹,在哪里找呢?报错信息那里写了。
Attempted to load tokenizers/punkt_tab/english/
Searched in:
- ‘/home/liubingqing/nltk_data’
- ‘/home/liubingqing/anaconda3/nltk_data’
- ‘/home/liubingqing/anaconda3/share/nltk_data’
- ‘/home/liubingqing/anaconda3/lib/nltk_data’
- ‘/usr/share/nltk_data’
- ‘/usr/local/share/nltk_data’
- ‘/usr/lib/nltk_data’
- ‘/usr/local/lib/nltk_data’
结果呢,这些目录下面都没有这个文件夹,所以就报错了。
我按照上述做法做了,但是不知道为什么没有用。
import nltk
nltk.download('punkt_tab')
解决办法
我直接在github上把它的整个项目下载了下来。在linux命令行中输入(你是windows怎么办?先看到最后)
git clone https://github.com/nltk/nltk_data.git
然后会发现当前目录下有一个nltk_data文件夹,这个文件和github目录保持了一致。
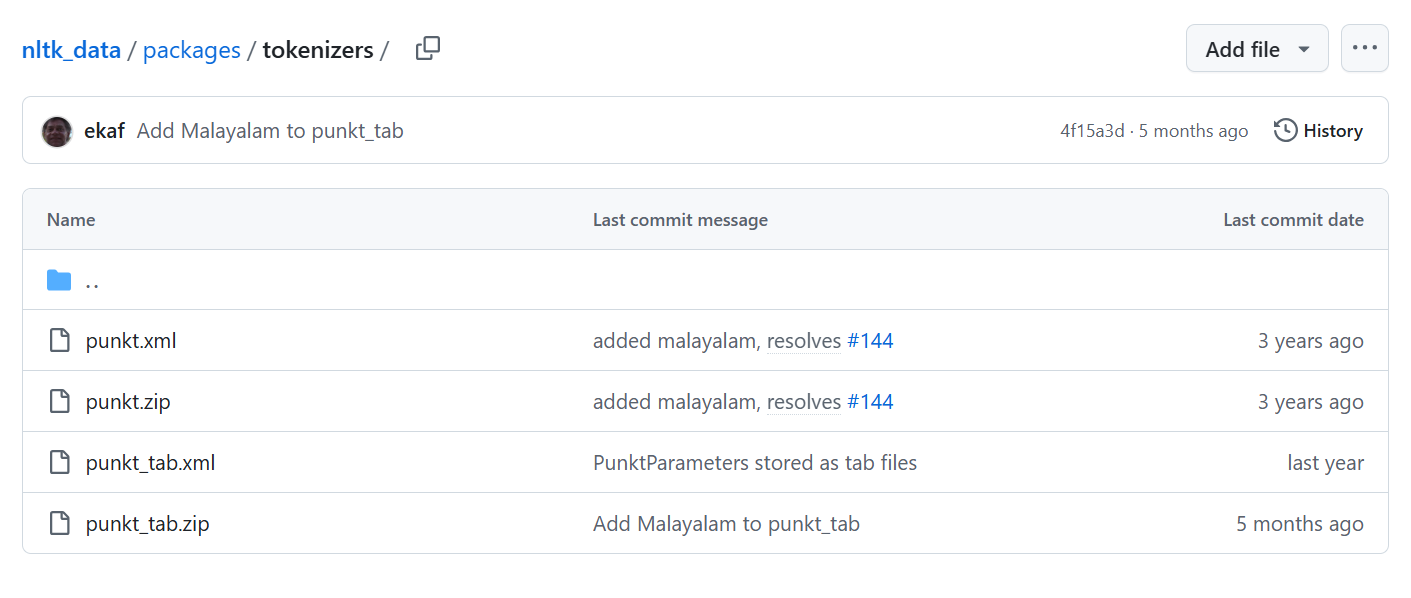
我们要的就是那两个zip文件夹punkt.zip和punkt_tab.zip,需要解压缩,解完压缩之后,punkt_tab文件夹下面就有一个english文件夹。然后接下来怎么做你应该知道了吧。
关键就是,根据我们之前写的分析,你要得到tokenizers/punkt_tab/english这个文件夹,并且要将其放置在任意一个之前提到过的目录下,比如我将其放置在第一个目录
/home/liubingqing/nltk_data#见上面写的分析
从而组成了目录:
/home/liubingqing/nltk_data/tokenizers/punkt_tab/english
这下你懂了吧,反复看我们的“分析”和“解决办法”,你会明白的。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)