python数据分析-期末大作业《电商用户消费行为分析与可视化》
·
python数据分析期末大作业任务目标:

确定项目主题:电商用户消费行为分析与可视化
完整代码
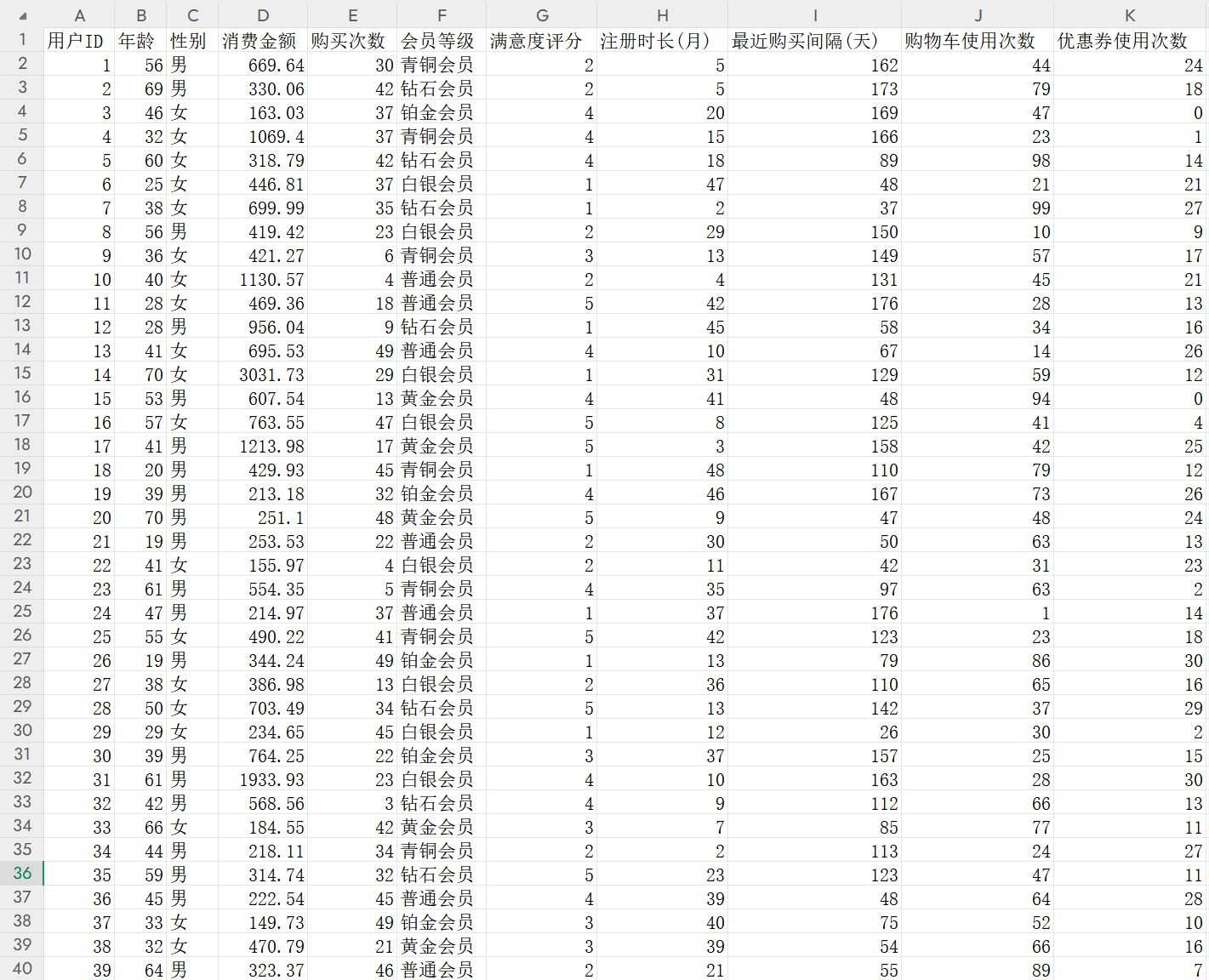
数据示例
代码
查看数据的基本信息
import pandas as pd
print("先读取电商用户消费行为数据集")
# 读取数据
df = pd.read_csv('电商用户消费行为数据集_改进版.csv')
df.info()
print("\n数据前5行:")
print(df.head())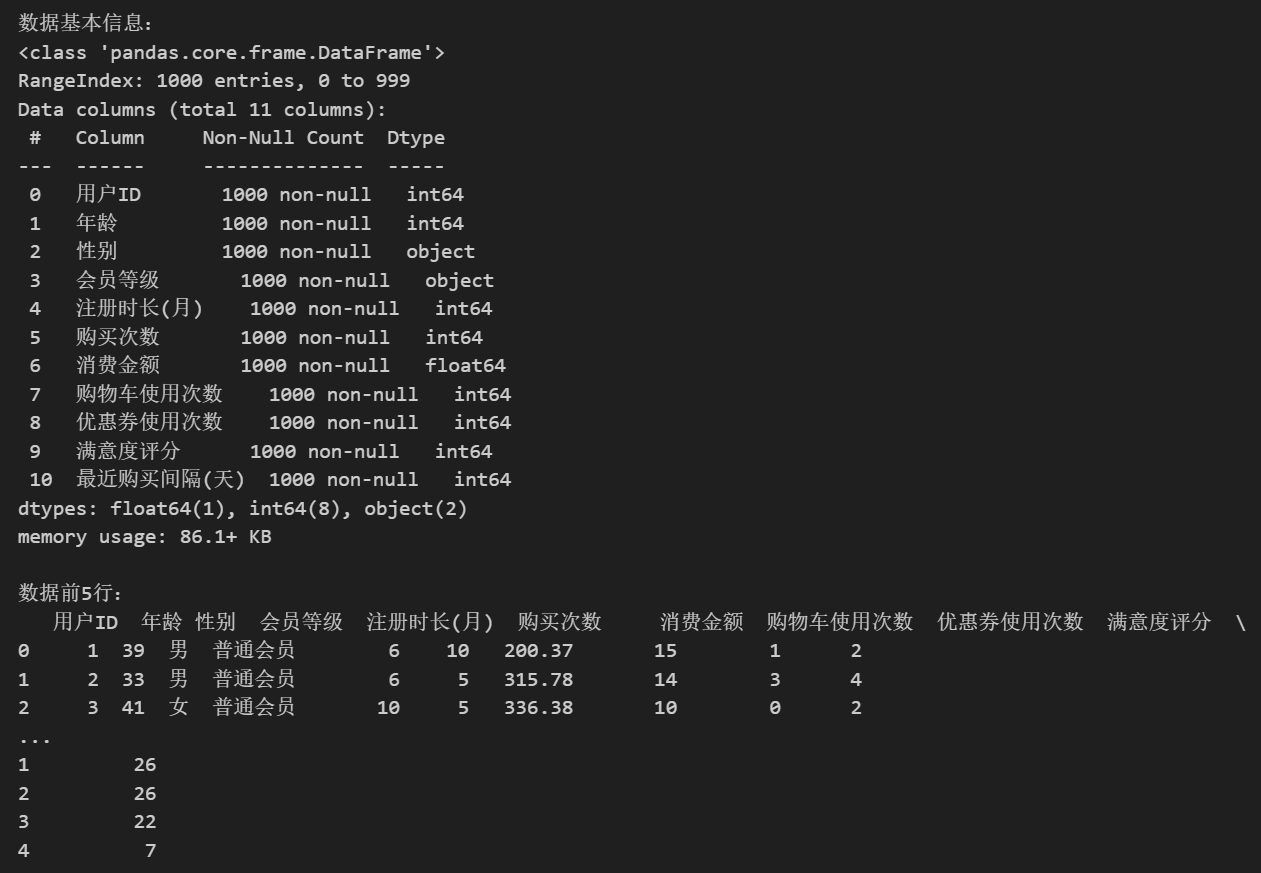
数据处理
# 1. 条件查询:高价值用户(消费金额>800且购买次数>10)
# 1. 条件查询:高价值用户(消费金额>800且购买次数>10)
high_value_users = df[(df['消费金额'] > 800) & (df['购买次数'] > 10)]
high_value_users.to_csv('高价值用户.csv', index=False, encoding='utf-8-sig')
print(f"\n高价值用户数量:{len(high_value_users)}")高价值用户数量:319
# 2. 数据分箱:年龄分箱
# 2. 数据分箱:年龄分箱
age_bins = [18, 25, 35, 45, 55, 70]
age_labels = ['18-25岁', '26-35岁', '36-45岁', '46-55岁', '56-70岁']
df['年龄区间'] = pd.cut(df['年龄'], bins=age_bins, labels=age_labels, right=False)
# 消费金额分箱
spend_bins = [0, 200, 500, 800, 1500]
spend_labels = ['低消费', '中低消费', '中高消费', '高消费']
df['消费等级'] = pd.cut(df['消费金额'], bins=spend_bins, labels=spend_labels, right=False)
# 保存带分箱的数据集
df.to_csv('带分箱的电商用户消费行为数据集.csv', index=False, encoding='utf-8-sig')
print("带分箱的数据集已保存")
print(df.head())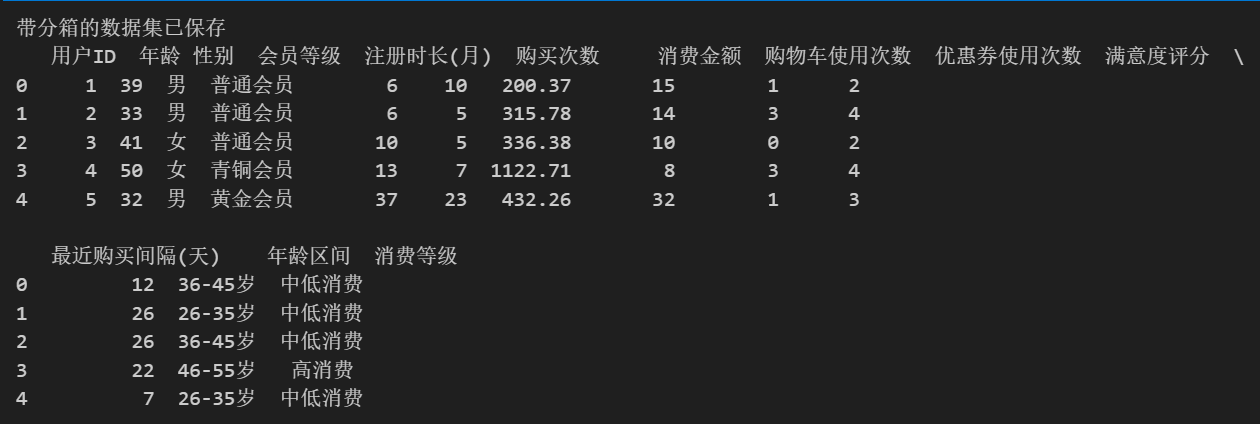
# 3. 分组聚合:按会员等级分析消费特征
# 3. 分组聚合:按会员等级分析消费特征
grouped_member = df.groupby('会员等级').agg(
平均消费金额=('消费金额', 'mean'),
平均购买次数=('购买次数', 'mean'),
平均满意度评分=('满意度评分', 'mean'),
最大消费金额=('消费金额', 'max'),
最小消费金额=('消费金额', 'min')
).round(2).reset_index()
grouped_member.to_csv('会员等级消费特征.csv', index=False, encoding='utf-8-sig')
print("\n会员等级消费特征分析结果已保存")
print(grouped_member)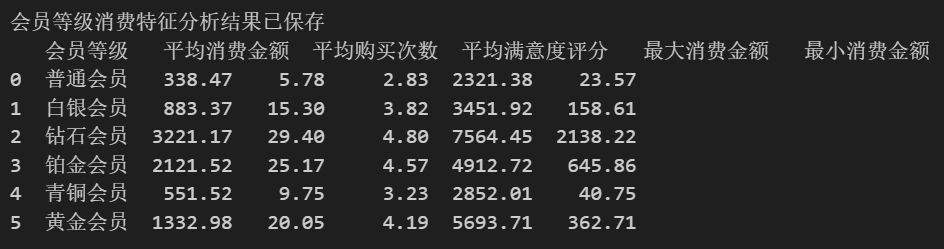
# 4. 多条件分组:按性别和年龄区间分析
# 4. 多条件分组:按性别和年龄区间分析
multi_grouped = df.groupby(['性别', '年龄区间']).agg(
平均消费金额=('消费金额', 'mean'),
总购买次数=('购买次数', 'sum'),
平均满意度评分=('满意度评分', 'mean'),
高价值用户占比=('用户ID', lambda x: (x.isin(high_value_users['用户ID']).sum() / len(x)) * 100)
).round(2).reset_index()
multi_grouped.to_csv('性别年龄消费特征.csv', index=False, encoding='utf-8-sig')
print("性别年龄消费特征分析结果已保存")
print(multi_grouped)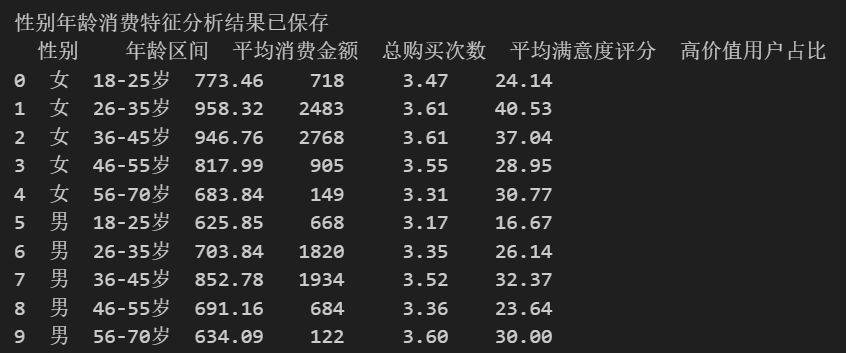
# 5. 相关分析:计算消费相关指标的相关性
# 5. 相关分析:计算消费相关指标的相关性
correlation = df[['消费金额', '购买次数', '注册时长(月)', '购物车使用次数', '优惠券使用次数']].corr().round(2)
correlation.to_csv('消费指标相关性.csv', encoding='utf-8-sig',index=False)
print("\n消费指标相关性分析结果已保存")
print(correlation)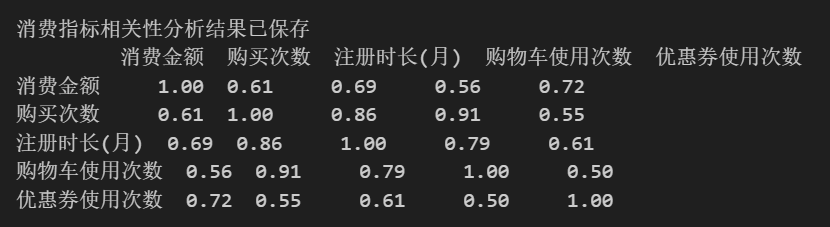
数据可视化
from pyecharts import options as opts
from pyecharts.charts import Bar, Pie, Line, Scatter, Boxplot
import pandas as pd
# 定义全局配色方案
COLORS = ["#5793f3", "#d14a61", "#675bba", "#00a578", "#ff9f1c", "#8dc63f", "#f8ba00", "#ff2501"]# 1. 柱状图:不同会员等级的平均消费金额
# 1. 柱状图:不同会员等级的平均消费金额
df_level = pd.read_csv('会员等级消费特征.csv')
bar = (
Bar(init_opts=opts.InitOpts(theme="light", bg_color="#f5f5f5"))
.add_xaxis(df_level["会员等级"].tolist())
.add_yaxis("平均消费金额", df_level["平均消费金额"].tolist(), color=COLORS[0])
.set_global_opts(
title_opts=opts.TitleOpts(title="不同会员等级的平均消费金额"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
yaxis_opts=opts.AxisOpts(name="平均消费金额(元)"),
xaxis_opts=opts.AxisOpts(name="会员等级")
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top"))
)
bar.render_notebook() 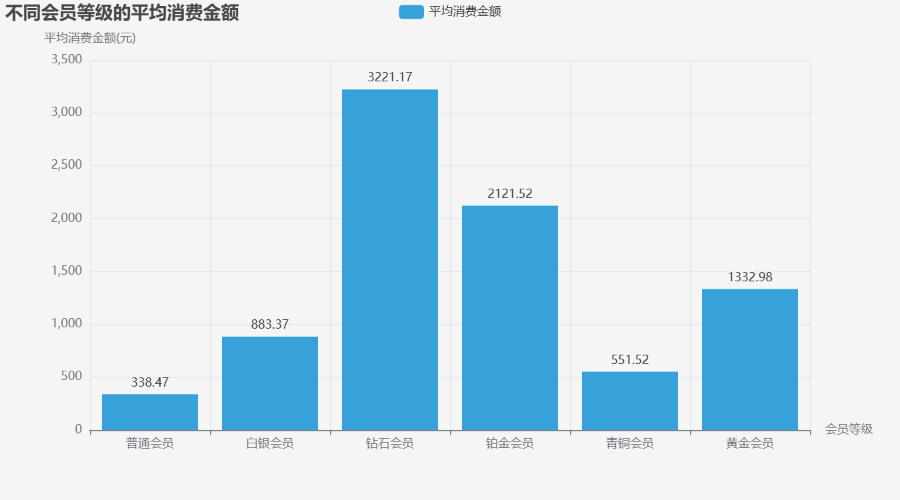
# 2. 饼图:用户性别分布
# 2. 饼图:用户性别分布
df_gender = pd.read_csv('电商用户消费行为数据集_改进版.csv')
gender_counts = df_gender["性别"].value_counts()
pie = (
Pie(init_opts=opts.InitOpts(theme="light", bg_color="#f5f5f5"))
.add("", list(zip(gender_counts.index.tolist(), gender_counts.tolist())),
radius=["40%", "75%"], label_opts=opts.LabelOpts(formatter="{b}: {c}人 ({d}%)"))
.set_global_opts(
# title_opts=opts.TitleOpts(title="用户性别分布"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
legend_opts=opts.LegendOpts(pos_left="left", orient="vertical")
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}人 ({d}%)", color="#333"))
)
pie.render_notebook()
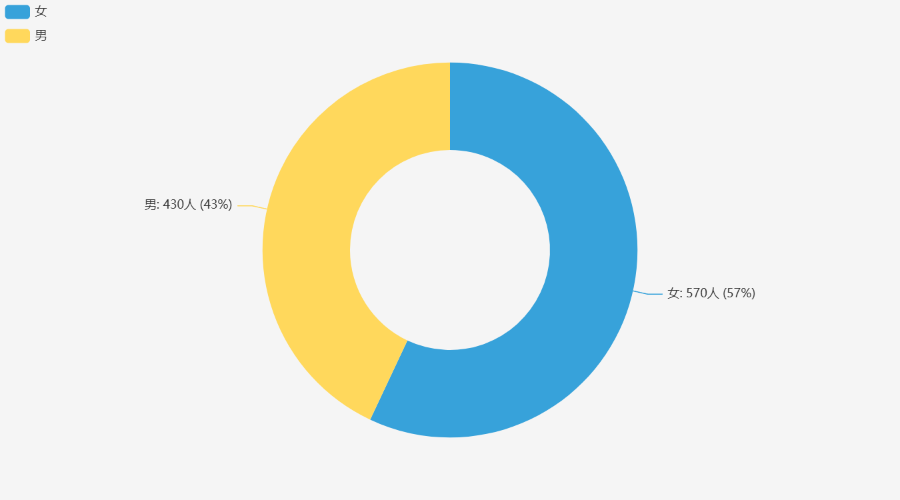
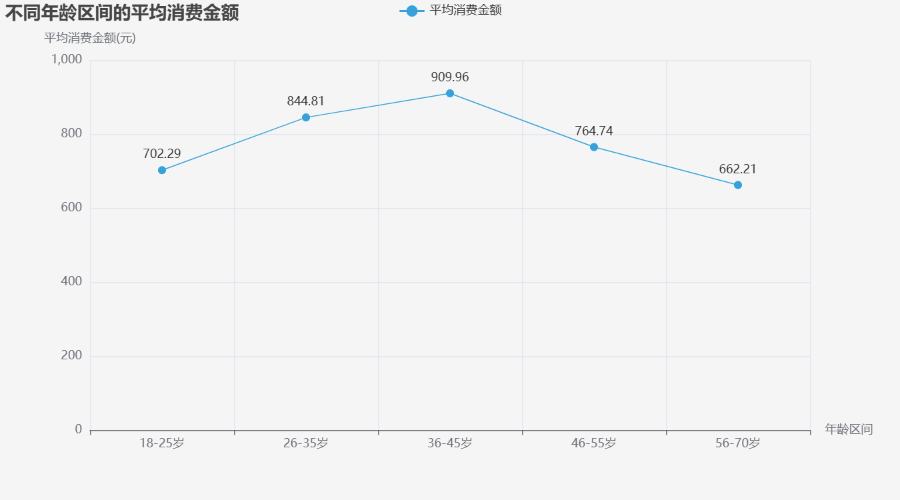
# 3. 折线图:不同年龄区间的平均消费金额
# 3. 折线图:不同年龄区间的平均消费金额
df_age = pd.read_csv('带分箱的电商用户消费行为数据集.csv')
age_group = df_age.groupby("年龄区间")["消费金额"].mean().reset_index()
line = (
Line(init_opts=opts.InitOpts(theme="light", bg_color="#f5f5f5"))
.add_xaxis(age_group["年龄区间"].tolist())
.add_yaxis("平均消费金额", age_group["消费金额"].round(2).tolist(),
color=COLORS[2], symbol="circle", symbol_size=8)
.set_global_opts(
title_opts=opts.TitleOpts(title="不同年龄区间的平均消费金额"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
yaxis_opts=opts.AxisOpts(name="平均消费金额(元)"),
xaxis_opts=opts.AxisOpts(name="年龄区间")
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top"))
)
line.render_notebook()
# 4. 散点图:消费金额与购买次数的关系
# 4. 散点图:消费金额与购买次数的关系
df_scatter = df_age.sort_values(by="购买次数")
scatter = (
Scatter(init_opts=opts.InitOpts(theme="light", bg_color="#f5f5f5"))
.add_xaxis(df_scatter["购买次数"].tolist())
.add_yaxis("消费金额",
df_scatter["消费金额"].tolist(),
color=COLORS[3],
# symbol_size=10,
label_opts=opts.LabelOpts(is_show=False)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="消费金额与购买次数的关系"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
yaxis_opts=opts.AxisOpts(name="消费金额(元)"),
xaxis_opts=opts.AxisOpts(
name="购买次数",
type_="value",
)
)
)
scatter.render_notebook()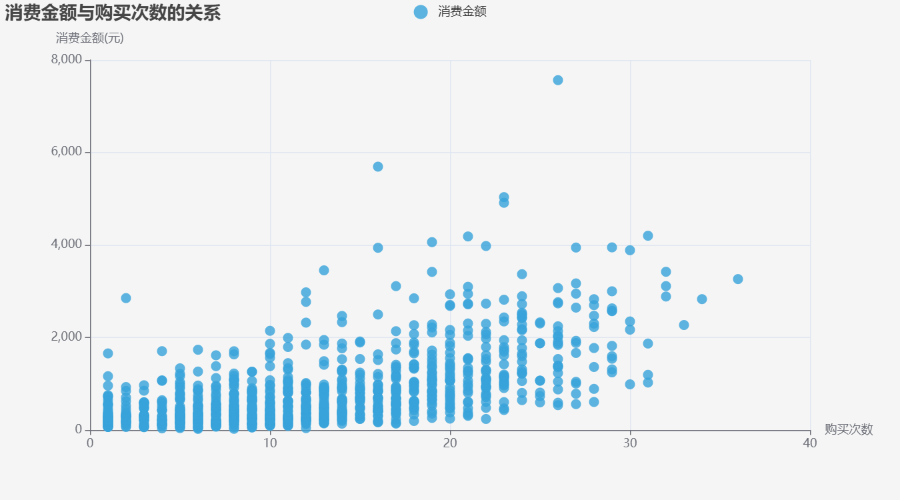
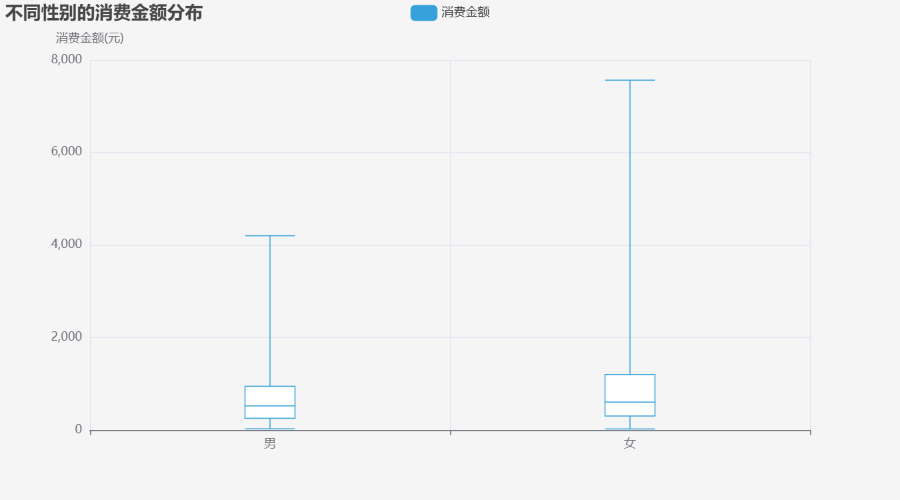
# 5. 箱线图:不同性别的消费金额分布
# 5. 箱线图:不同性别的消费金额分布
prepared_data = Boxplot.prepare_data([
df_gender[df_gender["性别"] == "男"]["消费金额"].tolist(),
df_gender[df_gender["性别"] == "女"]["消费金额"].tolist()
])
boxplot = (
Boxplot(init_opts=opts.InitOpts(theme="light", bg_color="#f5f5f5"))
.add_xaxis(["男", "女"])
.add_yaxis("消费金额", prepared_data)
.set_global_opts(
title_opts=opts.TitleOpts(title="不同性别的消费金额分布"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
yaxis_opts=opts.AxisOpts(name="消费金额(元)")
)
)
boxplot.render_notebook()
# 6. 热力图:用户行为特征相关系数热力图
# 6. 热力图:用户行为特征相关系数热力图
import seaborn as sns
import matplotlib.pyplot as plt
df_rlt = pd.read_csv('消费指标相关性.csv')
# 绘制热力图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(10, 8))
sns.heatmap(df_rlt, annot=True, cmap='coolwarm', center=0, vmin=-0.1, vmax=1.0)
plt.title('用户行为特征相关系数热力图')
plt.tight_layout()
plt.show() 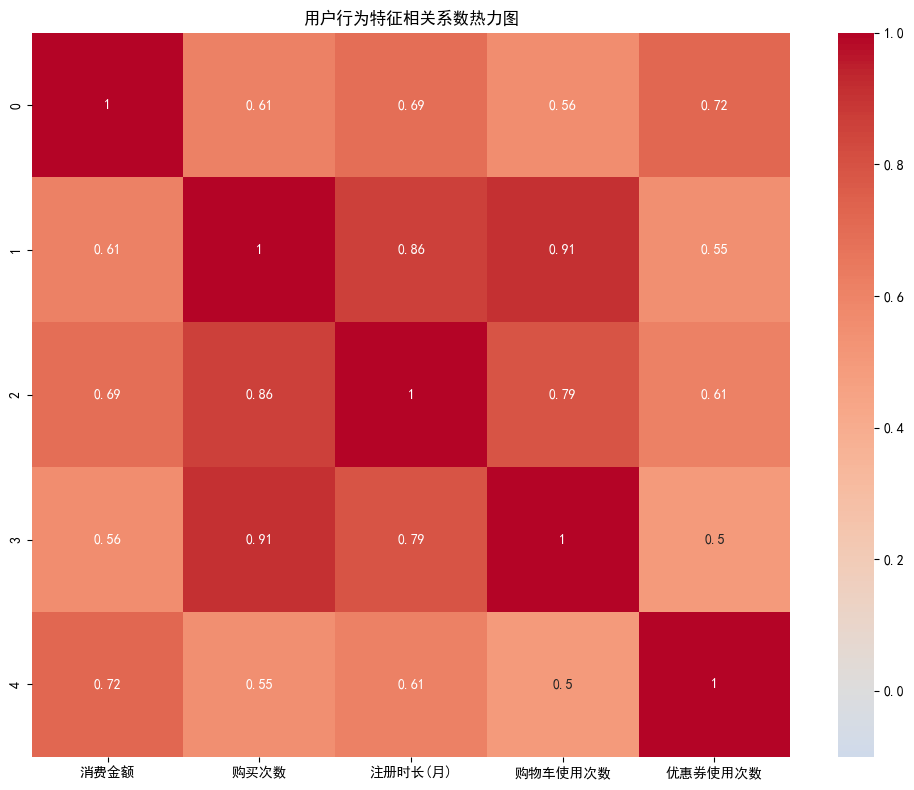
PPT制作

想要源码和PPT加我

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)