【读点论文】RAW-Adapter:Adapting Pre-trained Visual Model to Camera RAW Images优化ISP成像流程,两阶段适配深度学习任务的成像规则
RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images and A Benchmark
Abstract
-
在计算机视觉社区中,对预训练视觉模型的偏好已经很大程度上转向sRGB图像,因为它们易于获取和紧凑存储。然而,相机原始图像保留了各种真实世界场景中丰富的物理细节。尽管如此,大多数利用原始数据的现有视觉感知方法直接将图像信号处理(ISP)阶段与后续网络模块集成,通常忽略了模型级别的潜在协同作用。基于NLP和计算机视觉中基于适配器方法的最新进展,我们提出了RAW-Adapter,这是一个新的框架,它将可学习的ISP模块作为输入级适配器来调整原始输入。同时,它采用模型级适配器无缝连接ISP处理和高级下游架构。此外,RAW-Adapter作为一个通用框架适用于各种计算机视觉框架。
-
此外,我们介绍了RAW-Bench,它包含17种基于RAW的常见损坏,包括亮度退化、天气影响、模糊、相机成像退化和相机颜色响应变化。使用该基准,我们系统地比较了RAW-Adapter与最先进的(SOTA) ISP方法和其他基于RAW的高级视觉算法的性能。此外,我们还提出了一种基于RAW的数据扩充策略,以进一步提高RAW-Adapter的性能和域外泛化能力。大量实验证实了RAW-Adapter的有效性和效率,突出了其在不同场景中的稳健性能。
-
ISP 本身的设计和design是为了满足人眼视觉更好的感知,传统的ISP算法每一个step往往都需要prior knowledge,比如白平衡前需要估计光源。每一家厂商的ISP也都有自己的特点,比如Sony和华为他们的自家ISP流程的CCM以及LUT参数肯定不同,同时每家的ISP基本都是黑盒,我们很难获取里面具体的step。ISP针对人眼设计的特性也导致了,这些ISP算法并不一定能很好的满足machine vision,尤其是在对于一些下游计算机视觉任务检测,分割的时候,针对人眼设计的ISP并不一定能够符合mAP,IOU等指标,这一表现在低光场景尤为明显。本文方法设计了两组Adapters,一组是用来把RAW图像处理到网络输入阶段的Input-level Adapter, 另一组是链接ISP阶段特征和后续网络的Model-level Adapter。Input-level Adapter这里大致包括四个步骤: (1). 预处理 + denoise/ gain/ sharpen (2). 白平衡 (3). CCM矩阵以及(4) Implicit 3D LUT。每一个步骤的初心目的就是把ISP参数变成可学习的,动态参与到模型的反向传播过程,同时让这些ISP参数可以自适应的配合到不同图像&光照&数据集。Model-level Adapter这里则是更多借鉴了ViT-Adapter的设计,希望能把ISP阶段的中间特征作为Guidance融合的后续的网络backbone中。
-
传统视觉模型依赖sRGB预训练,与RAW图像存在域差距,RAW图像保留物理细节,但现有方法未充分利用模型级协同。RAW-Adapter框架,输入级适配器:优化ISP参数(QAL、INR),模型级适配器:融合ISP阶段特征。输入级适配器设计,增益与去噪、白平衡与CCM矩阵、3D LUT色彩操作;模型级适配器集成,特征提取与残差块融合,参数轻量级(0.2M-0.8M)。
-
RAW 图像的价值与挑战:RAW 图像保留线性辐射数据、全动态范围和噪声特性,适用于图像去噪、新视图合成等任务,但主流模型基于 sRGB 预训练,存在域差距。传统 ISP 为人类感知设计,丢弃物理线索;联合优化方法将 ISP 与网络独立处理,未充分整合 RAW 与 sRGB 模型。
-
输入级适配器,将 RAW 转换为适合机器视觉的格式,包含增益与去噪、白平衡调整、色彩矩阵转换等步骤。Query Adaptive Learning(QAL)预测 ISP 参数,如增益比 g、高斯核参数。隐式神经表示(INR)驱动的 3D LUT 进行色彩操作。模型级适配器,提取 ISP 阶段特征(I1-I4),通过卷积层和残差块与下游网络融合。
-
通过输入级适配器预测 ISP 关键参数(如增益、白平衡),将 RAW 转换为机器视觉友好格式;模型级适配器提取 ISP 阶段特征并与下游网络融合,桥接 RAW 输入与 sRGB 预训练模型的知识,同时保持参数轻量级(0.2M-0.8M)。通过亮度变化(随机缩放亮度)、色度增强(随机通道权重)和质量退化(添加模糊与噪声),模拟多样化 RAW 损坏场景,扩大训练数据分布。实验表明,该策略使 RAW-Adapter 在 OOD 场景中 mAP/mIOU 提升最高达 20.6%,且对跨传感器任务效果显著。
INTRODUCTION
-
近年来,相机传感器技术和计算摄影的快速发展重新引起了人们对利用未经处理的相机原始图像执行计算机视觉任务的兴趣。与sRGB图像(其质量受复杂的有损图像信号处理器(ISP)管道的影响)不同,原始图像保留了场景的线性辐射数据、全动态范围和内在噪声特征。这种纯粹的数据格式提供了一个忠实的场景表示和各种分区的可靠基础。例如,图像去噪技术利用RAW中固有的噪声分布来降低传感器噪声,同时保留精细的纹理和边缘。
-
此外,新的视图合成(NVS)框架利用来自RAW的丰富信息来生成更准确和一致的3D场景表示。此外,高级视觉算法(例如,对象检测和语义分割)也受益于原始数据,从而在各种具有挑战性的光照条件下实现更高的准确性。这些进步强调了相机原始数据在各种应用中的巨大潜力。在自动驾驶中,原始图像为精确的场景解读提供了未经处理的丰富数据;在野生动物监测中,即使在极其黑暗的条件下,它们也能揭示微妙的细节;在智能安全方面,它们确保在充满挑战的环境中保持一致的可靠性。因此,利用原始图像推动了技术创新和强大、高性能的真实世界系统的开发。
-
尽管前景光明,但重大挑战依然存在。大多数最先进的(SOTA)视觉模型都是在大规模sRGB数据集上进行预训练的(例如,ImageNet ,MSCOCO ),这与相机原始输入产生了明显的域差距。没有这些sRGB预训练重量的从头训练会严重降低成绩(见图1的例子)。此外,传统的 ISP 管道针对人类感知而非机器解释优化原始输入,通常会丢弃或扭曲原始数据中微妙的物理线索 。如图2(a)所示,每个ISP模块以特定的感知目标为目标,而不是解决随后的任务需求(见图2(b)),并且商业ISP(例如Adobe Camera RAW)的不透明性质进一步使其处理重新用于下游算法任务变得复杂。
-
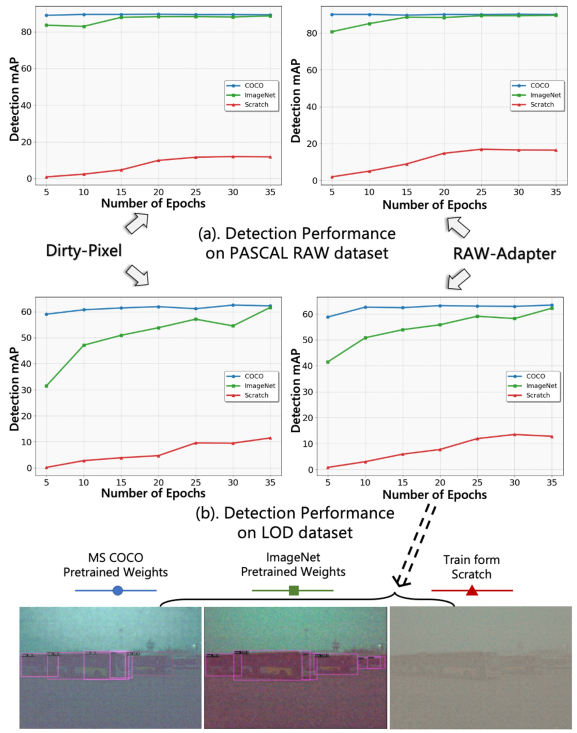
-
图一。使用和不使用sRGB预训练权重的基于RAW的对象检测任务的性能。我们分析两种方法:脏像素和我们的原始适配器。蓝线代表使用MS COCO 训练前重量训练,绿线表示ImageNet 训练前重量,红线表示从头开始训练。我们分别介绍了PASCAL RAW 和LOD 数据集上的检测性能。
-
-
为了应对这些挑战,研究人员探索了联合优化可调ISP和后续计算机视觉网络的策略(见图2©)。概括地说,这些方法分为两类。第一种方法通过设计不同的模块,通常利用CMA-ES 等优化技术,保留了传统ISP的模块化结构。第二种方法是用神经网络模块(如UNet ) 完全取代ISP,这通常会给高分辨率输入带来巨大的计算负担。然而,这两种范式在很大程度上都将ISP和vision network视为独立的组件,因此忽略了原始输入和sRGB预训练模型之间更协同集成的潜力。
-

-
图二。(一)。基本图像信号处理器(ISP)流水线概述。(顺序或配置可能因不同制造商的特定ISP设置而异)(b)。ISP和当前的高级视觉模型有不同的目标。©以前的方法使用下游高级视觉模型来优化ISP。(d)我们提议的原始适配器。
-
-
为了更好地弥合信息丰富的原始数据和知识丰富的sRGB预训练模型之间的差距,我们提出了RAW-Adapter,这是一个重新定义相机原始输入和sRGB模型之间关系的框架。我们的方法不依赖于复杂的ISP模块或深度神经网络编码器,而是简化了输入阶段,同时在模型级别促进了与sRGB预训练模型的更紧密集成。受即时学习和适配器调整最新进展的启发,我们开发了两种新颖的适配器方法(输入级和模型级适配器)来增强两者之间的联系。
-
如图2(d)所示。输入级适配器将原始数据转换成适合后端网络的格式。按照传统的ISP设计,我们预测关键的ISP阶段参数,以转换目标下游视觉任务的输入原始图像。为了在保持轻量级设计的同时确保可区分性,我们将查询自适应学习(QAL)和隐式神经表示(INR)整合到核心ISP流程中。模型级适配器通过提取中间ISP阶段特征来利用来自输入级适配器的先验知识。这些功能随后被嵌入到下游网络中,使模型能够整合ISP的先验知识,共同为最终的机器视觉感知任务做出贡献。
-
除了架构上的改进,实际应用还需要考虑模型在不同的真实世界环境下的性能(例如,照明、天气)。尤其是在基于相机原始数据的任务中,通常会遇到用于训练数据的传感器和用于测试数据的传感器之间的不一致(例如,用尼康D3200 DSLR原始数据进行训练,用iPhone X原始数据进行测试)。为此,我们提出RAW-Bench,这是一个综合的基准测试,包含17种基于RAW的常见损坏,全面考虑了各种照明退化、天气影响、模糊、相机成像退化和相机颜色响应的变化(见图3和图6)。为了更好地评估RAW-Adapter的真实世界泛化能力,我们使用不同的输入图像类型(例如,RAW、log-RGB)、主流ISP算法和其他联合训练解决方案在RAW-Bench上进行比较,以验证我们的性能。此外,我们设计实验来分别评估上述方法的域内(ID)和域外(OOD)性能。我们的贡献可以总结如下:
- 我们引入了RAW-Adapter,这是一个轻量级框架,通过适配器调整增强了sRGB预训练模型与camera RAW的集成。它解决了输入级和模型级的差异:输入级适配器有效优化关键ISP参数,而模型级适配器利用此输入级信息来进一步改善下游性能。RAW-Adapter旨在提高有效性和效率,最大限度地减少计算开销,同时增强各种下游视觉模型的性能。
- 我们引入RAW-Bench,这是一个包含17种影响基于RAW的视觉性能的常见错误的基准。我们分析了它们对各种因素的现有方法的影响,包括亮度、天气条件、模糊度、成像退化和交叉传感器性能,为未来的研究提供了有价值的见解。此外,我们提出了一个简单而有效的基于RAW的数据增强策略,以提高RAW-Adapter的性能和OOD鲁棒性。
- 通过对不同输入数据类型、主流ISP解决方案以及对象检测和语义分割任务中的联合训练策略的综合比较(在不同的损坏场景下进行评估),我们证明RAW-Adapter实现了最先进的(SOTA)性能,同时展现出对真实世界损坏的卓越鲁棒性。
-
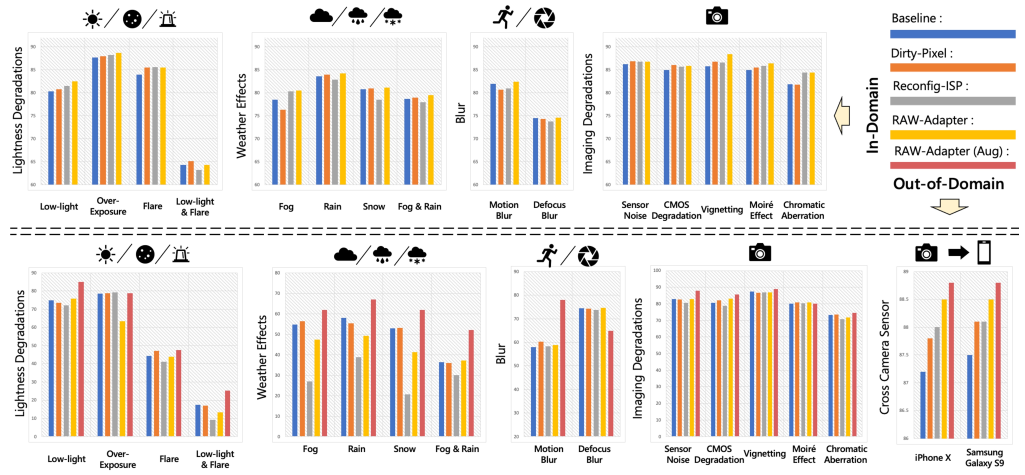
-
图3。我们提出RAW-Bench来评估当前基于RAW的视觉框架对常见破坏的性能,包括照明、天气、模糊、相机成像退化和相机颜色响应的变化。在这里,我们展示了PASCAL RAW-D数据集上的结果。
-
本文提出 RAW-Adapter 框架,通过输入级适配器(含可学习 ISP 模块)和模型级适配器(桥接 ISP 与下游架构),实现预训练视觉模型对 RAW 图像的适配,同时引入 RAW-Bench 基准(包含 17 种 RAW 常见损坏,如亮度退化、天气影响等)及 RAW 数据增强策略,实验表明其在目标检测和语义分割任务中性能优于现有方法,且具备高效性和强鲁棒性。
-
RAW-Adapter 的核心是输入级适配器(物理 ISP 参数学习)+ 模型级适配器(特征融合)的双模块设计,理论基础融合相机成像物理模型与深度适配器调优,专门解决不良光照下 RAW 图像的光照色彩矫正与视觉任务适配。
- 输入级适配器:可学习的 ISP 参数建模(对应图像处理理论),增益与去噪模块(对应成像物理噪声模型)。基于传感器噪声模型 shot noise:δs=S,read noise:δrshot ~noise: \delta_s = \sqrt{S}, read~ noise: \delta_rshot noise:δs=S,read noise:δr,结合高斯核各向异性去噪。增益比g(2-6)、高斯核主 / 次轴 r1/r2r_1/r_2r1/r2、锐化参数 σ∈(0,1)\sigma \in (0,1)σ∈(0,1)。低光场景增大g提升亮度,但需通过\ r1/r2r_1/r_2r1/r2控制噪声抑制强度(过大导致细节丢失),σ\sigmaσ 平衡模糊与锐化。白平衡与 CCM 矩阵(对应颜色恒常性理论),改进的 Shades of Gray(SoG)算法,引入 Minkowski 距离参数 ρ\rhoρ,替代传统灰世界假设。ρ∈(1,+∞)\rho \in (1, +\infty)ρ∈(1,+∞)(1 为平均,∞为 Max-RGB),3×3 可学习 CCM 矩阵(初始单位矩阵)。ρ=1.5\rho=1.5ρ=1.5 时在混合光源下颜色更准确(消融实验显示白平衡模块贡献 + 1.6 mAP),CCM 矩阵优化跨传感器色彩一致性。隐式 3D LUT 色彩变换(对应非线性色彩映射),经隐式表示(INR)驱动的 3D LUT(NILUT),替代传统查表法,支持端到端优化。将 ISP 的物理参数(增益、噪声、白平衡)转化为可学习的动态变量,通过 QAL(查询自适应学习)实现图像级个性化 ISP,区别于固定 ISP 流程(如 Adobe Camera RAW),专为机器视觉任务(检测 / 分割)优化。
- 模型级适配器:ISP 特征与视觉网络的跨阶段融合,ISP 阶段特征提取,对 RAW 预处理后四阶段图像(增益后 I2、白平衡后 I3、CCM 后 I4)提取卷积特征,通过残差块生成适配器特征(f_1)。类似特征金字塔(FPN)的跨阶段连接,保留 ISP 各步骤的中间信息(如噪声分布、色彩校正过程)。特征融合策略(合并块设计),通过拼接(Concat)+ 残差连接,将 ISP 特征与主干网络特征融合。适配器调优(Adapter Tuning)的轻量级扩展,冻结主干参数,仅更新适配器(总参量 0.2M-0.8M,比 Dirty-Pixel 轻 80%)。
-
模块 参数范围 目标任务影响(PASCAL RAW-D) 理论依据 增益g 0.1-5.0(动态) 低光 + 1.8% mAP,过曝 - 0.3% mAP 线性增益符合 RAW 辐射特性(公式 7) 高斯核(r_1) 2-8(动态) 噪声场景 + 0.9% mAP,过曝 - 0.5% mAP 各向异性核适应不同噪声方向 白平衡(\rho) 1-5(动态) 混合光源 + 2.1% mAP,单一光源 + 0.7% Minkowski 距离扩展灰世界假设 模型级参数 114K-687K 全场景平均 + 3.2% mAP,OOD+5.1% 特征融合避免 ISP 信息丢失
RELATED WORKS
Image Signal Processor (ISP)
-
传统的ISP方法:通常,相机的图像信号处理器(ISP)流水线对于将捕获的图像从相机的内部原始空间渲染到标准显示色彩空间(例如,sRGB)是必不可少的。传统的ISP管道被公式化为一系列手工制作的模块,按顺序执行。这些模块包括代表性的步骤,例如去马赛克、白平衡、降噪、色调映射和色彩空间转换。许多这些步骤依赖于现实世界的物理先验和基于人类经验的设计方法。例如,ISP中的白平衡通常取决于作为先验信息的光源估计或采用统计假设,如 gray-world 和 white-patch。也存在ISP工艺的替代设计,例如Heide等人设计的FlexISP将多个ISP模块组合成一个统一的优化模块,Hasinoff等人修改了一些传统的ISP步骤,用于极端弱光条件下的连拍摄影。传统的ISP方法具有高度的可解释性,支持高效的故障排除和优化,并且不需要大规模的训练数据集。然而,它们本质上也依赖于特定的硬件,需要专家手动调整,并且始终缺乏从原始到sRGB的端到端翻译能力。
-
基于深度学习的ISP方法:随着深度学习时代的到来,许多研究人员的目标是开发端到端的管道,用于RAW到sRGB映射。例如,Chen等人提出了SID,用UNet 代替传统的ISP步骤,将低照度原始数据转换成正常照度的sRGB图像。同样,Hu等人引入了一种具有8个可微分滤波器的可学习白盒解决方案,允许检查白盒过程中的每个步骤。Zhang等人提出了LiteISP,它还解决了颜色不一致对图像对齐的影响。Tseng等人介绍了神经照片整理,它不仅完成ISP管道,而且支持风格转换和对抗性照片编辑。然而,基于深度网络的ISP模型的一个主要缺点是它们固有的对训练数据集的依赖,这通常限制了它们的泛化性能。
-
sRGB到原始数据的去渲染:另一条研究路线专注于将sRGB图像转换回原始域,缓解许多成像应用中的大存储需求和有限支持等挑战。将RGB转换为RAW的方法包括记录相机元数据、手动设计的解处理管道,以及基于神经网络的方法。其中许多方法支持sRGB和原始数据之间的双向转换。例如,CycleISP 采用sRGB到原始数据和原始数据到sRGB的级联网络,InvISP 使用基于流的架构进行双向映射,ParamISP 利用ParamNet中的参数来控制转换方向。除了RAW和sRGB之间的转换,正在进行的研究重点是利用RAW图像进行下游高级计算机视觉任务。
RAW-based High-level Vision Tasks
-
1)架构改进:为了有效地利用原始数据中的丰富信息来完成下游的高级视觉任务,早期的方法建议绕过ISP过程,直接在原始数据上执行视觉算法。然而,这些方法未能解决从光子到RAW转换过程中引入的相机噪声,尤其是在弱光条件下。此外,在原始数据上从零开始的训练失去了在sRGB数据上的大规模预训练视觉模型的好处(见图1)。数据集大小的显著差异进一步加剧了这一挑战:原始图像数据集,如PASCAL RAW (4,259幅图像)和LOD (2,230幅图像),比当前的RGB数据集小得多。例如,ImageNet 包含超过100万张图像,而SAM 则针对1100万张图像进行训练。
- 大多数后续研究都集中在将ISP与后端计算机视觉模型集成 。例如,Wu等人首先提出了VisionISP,并强调了人类和机器视觉之间的差异,在ISP中引入了几个可训练的模块来增强后端对象检测性能。此后,有几种方法试图用可区分的ISP网络来取代传统的不可区分的ISP。例如,ReconfigISP采用神经架构搜索(NAS)方法来确定最佳ISP配置。或者,一些方法直接用编码器网络代替ISP过程。例如,Dirty-Pixel 利用一堆UNets作为预编码器。然而,同时训练两个连续的网络强加了大量的计算负担,并且先前的研究很少探索如何针对相机原始数据有效地微调当前主流的基于sRGB的视觉模型。
-
2)退化情况下的基于原始数据的视觉:同时,诸如 Rawgment 的研究侧重于直接在原始图像上实现逼真的数据增强,以实现稳健的感知。一些研究解决了由incamera处理管道或ISP中的特定步骤导致的计算机视觉性能下降,如白平衡错误、自动曝光错误、相机运动模糊和不良相机噪声。此外,已经提出了几个基于原始数据的数据集来说明特定的真实世界场景。例如,LOD 和ROD 考虑弱光条件。最近,引入了AODRaw ,进一步整合了各种不利天气条件下的相机原始数据。
-
在这项工作中,我们提出了RAW-Bench,它通过额外纳入耀斑、雪、各种类型的模糊、相机成像退化和交叉传感器变化,扩展了先前对照明和天气条件的考虑。我们将这些因素统一到一个由17种常见损坏组成的综合基准中,旨在评估模型的域内(ID)和域外(OOD)性能。
Adapter Tuning in Computer Vision
-
适配器在自然语言处理(NLP)领域已经变得普遍,它在大型语言模型(LLM)中引入了新的模块。这些模块支持特定任务的微调,允许预先训练的模型快速适应下游NLP任务。
-
在计算机视觉领域,适配器已被应用于各种领域,如增量学习和领域适应。近年来,已经提出了一系列适配器来研究如何更好地利用预训练的视觉模型 或预训练的视觉语言模型 。这些方法侧重于利用先验知识,使预先训练的模型快速适应下游任务。像ViT-Adapter 利用特征注入器和特征提取器来使预训练的ViT 模型适应下游检测和分割任务一样,DAPT 提出使ViT模型适应点云分析。与以前的适配器研究主要集中在RGB域不同,我们的RAW-Adapter进一步改善了相机原始输入和sRGB预训练视觉模型之间的对齐。
RAW-ADAPTER
- 在本节中,我们将介绍我们提出的 RAW-Adapter。我们的补充材料中提供了传统图像信号处理器(ISP)的简要概述。对于适配器设计,我们有选择地省略某些步骤,以专注于相机ISP的关键方面。第III-A节详细描述了输入级适配器,第III-B节解释了模型级适配器。
Input-level Adapters
-
图4提供了原始适配器的概述。图4(a)左侧的实线代表输入级适配器。输入级适配器被设计成将原始图像 I1 转换成面向机器视觉的图像I5。这个过程包括数字增益和去噪、去马赛克、白平衡调整、相机颜色矩阵和颜色处理。
-
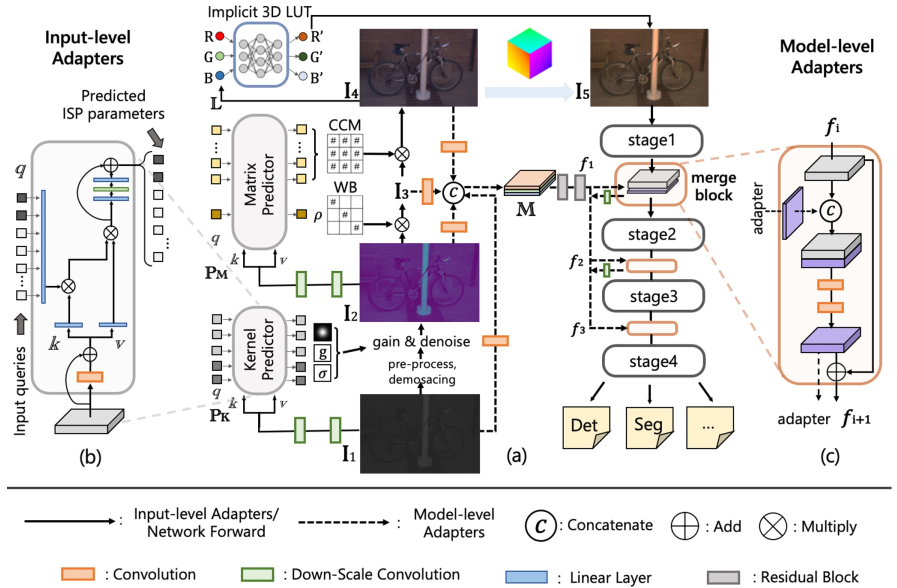
-
图4。(一)。原始适配器的整体结构。左边的实线表示输入级适配器的工作流程(从输入原始数据I1 → I2 → I3 → I4 → I5 ),虚线表示模型级适配器的工作流程,阶段1∞4表示可视化模型主干的不同阶段。(二)。内核和矩阵预测器的详细结构。(三)。模型级适配器M的合并块的详细结构。
-
-
我们保持ISP设计,同时使用查询自适应学习(QAL)来估计ISP阶段的关键参数。QAL策略是由以前的 Transformer 模型 激发的,详细结构如图4(b)所示,输入图像 Ii∈(1,2) 将经过2个下尺度卷积块以生成特征,然后特征经过2个线性层以生成注意块的密钥k和值v,而查询q是一组可学习的动态参数,ISP参数将通过自注意计算来预测:
-
parameters=FFN(softmax(q⋅kTdk)⋅v),(1) parameters = F F N(sof tmax(\frac {q · k ^T} {\sqrt {d_k}} ) · v), (1) parameters=FFN(softmax(dkq⋅kT)⋅v),(1)
-
其中FFN表示前馈网络,包括2个线性层和1个激活层,预测的参数将保持与查询q相同的长度。我们定义了2个 QAL 块 PK 和 PM 来预测不同的零件参数。
-
-
输入原始图像 I1 将首先经过预处理操作和去马赛克阶段 ,随后是后续的ISP处理:
-
1)增益和去噪:去噪算法总是考虑各种因素,例如输入光子数、ISO增益水平、曝光设置。这里,我们首先使用QAL块PK来预测增益比g ,以适应不同照明场景中的 I1I_1I1,随后使用自适应各向异性高斯核来抑制各种噪声条件下的噪声,PK将预测适当的高斯核k来进行去噪,以提高下游视觉任务的性能,预测的关键参数是高斯核的长轴r1、短轴r2(见图5左侧),这里我们将核角度θ设置为0°以进行简化。像素(x,y)处的高斯核k将是:
-
k(x,y)=exp(−(b0x2+2b1xy+b2y2)),(2)其中:b0=cos(θ)22r12+sin(θ)22r22,b1=sin(2θ)4r12((r1r2)2−1),(3)b2=sin(θ)22r12+cos(θ)22r22. k(x, y) = exp(−(b_0x^2 + 2b_1xy + b_2y^2 )), (2)\\ 其中:\\ b_{0}=\frac{cos(\theta)^{2}}{2{r_{1}}^{2}}+\frac{sin(\theta)^{2}}{2{r_{2}}^{2}},\\ b_{1}=\frac{sin(2\theta)}{4{r_{1}}^{2}}((\frac{r_{1}}{r_{2}})^{2}-1), \\ \mathrm{(3)} \\ b_{2}=\frac{sin(\theta)^{2}}{2{r_{1}}^{2}}+\frac{cos(\theta)^{2}}{2{r_{2}}^{2}}. k(x,y)=exp(−(b0x2+2b1xy+b2y2)),(2)其中:b0=2r12cos(θ)2+2r22sin(θ)2,b1=4r12sin(2θ)((r2r1)2−1),(3)b2=2r12sin(θ)2+2r22cos(θ)2.
-
在对图像I1进行增益比g和核k处理之后,PK还预测滤波器参数σ(初始为0 ),以保持生成的图像I2的锐度并恢复其细节。情商。图4示出了从I1到I2的转换,其中⊛表示核卷积,并且滤波器参数σ被Sigmoid激活限制在(0,1)的范围内。更多详情请参阅我们的补充部分。
-
PK(I1,q)→k{r1,r2,θ},g,σ,I2′=(g⋅I1)⊗k,(4)I2=I2′+(g⋅I1−I2′)⋅σ. \begin{aligned} & \mathbb{P}_{\mathrm{K}}(\mathbf{I}_{1},\mathrm{q})\to k\left\{r_{1},r_{2},\theta\right\},g,\sigma, \\ & \mathbf{I}_{2}^{\prime}=(g\cdot\mathbf{I}_{1})\otimes k, & \mathrm{(4)} \\ & \mathbf{I}_{2}=\mathbf{I}_{2}^{\prime}+(g\cdot\mathbf{I}_{1}-\mathbf{I}_{2}^{\prime})\cdot\sigma. \end{aligned} PK(I1,q)→k{r1,r2,θ},g,σ,I2′=(g⋅I1)⊗k,I2=I2′+(g⋅I1−I2′)⋅σ.(4)
-
2)白平衡& CCM矩阵:白平衡(WB)通过将“白色”与白色物体对齐来模拟人类视觉系统(HVS)的颜色恒常性,从而使捕获的图像反映光色和材料反射率的组合 。在我们的工作中,我们希望找到一种自适应的白平衡,用于各种照明场景下的不同图像。受灰色阴影(SoG) WB算法设计的启发,其中灰色世界WB和Max-RGB WB可以被视为子情况,我们采用了一个可学习的参数ρ,以自适应Minkowski距离平均值代替灰色世界的L-1平均值(参见等式5),QAL板块PM预测闵可夫斯基距离的超参数ρ,各种ρ的演示如图5所示。在找到合适的ρ后,I2将乘以白平衡矩阵以产生I3。
-
ISP中的颜色转换矩阵(CCM)受特定相机型号的限制。这里,我们将CCM标准化为单个可学习的3×3矩阵,初始化为单位对角矩阵e 3。QAL块PM在这里预测9个参数,然后将这些参数添加到E3以形成最终的3×3矩阵Eccm。那么I3将乘以CCM Eccm以产生I4,等式如下:
-
PM(I2,q)→ρ,Eccm,mi∈{r,g,b}=avg(I2(i)ρ)ρ/avg((I2)ρ)ρ,I3=I2∗[mrmgmb],I4=I3∗Eccm. \begin{aligned} & \mathbf{P}_{\mathbf{M}}\left(\mathbf{I}_{2},q\right)\rightarrow\rho,\mathbf{E}_{ccm}, \\ & m_{i\in\{r,g,b\}}=\sqrt[\rho]{\operatorname{avg}\left(\mathbf{I}_{2}(i)^{\rho}\right)}/\sqrt[\rho]{\operatorname{avg}\left(\left(\mathbf{I}_{2}\right)^{\rho}\right)}, \\ & \mathbf{I}_{3}=\mathbf{I}_{2}* \begin{bmatrix} m_{r} \\ m_{g} \\ m_{b} \end{bmatrix}, \quad\mathbf{I}_{4}=\mathbf{I}_{3}*\mathbf{E}_{ccm}. \end{aligned} PM(I2,q)→ρ,Eccm,mi∈{r,g,b}=ρavg(I2(i)ρ)/ρavg((I2)ρ),I3=I2∗ mrmgmb ,I4=I3∗Eccm.
-
3)色彩操纵过程:在ISP中,色彩操纵过程通常通过查找表(LUT)来实现,如1D和3D LUTs 。这里,我们将颜色处理操作合并到单个3D LUT中,调整图像I4的颜色以产生输出图像I5。利用LUT技术的进步,我们选择了最新的神经隐式三维LUT (NILUT) ,因为它的速度效率和促进我们管道中端到端学习的能力。我们将NILUT 表示为L,L将输入像素强度R,G,B映射到连续的坐标空间,随后利用隐式神经表示(INR) ,这涉及使用多层感知器(MLP)网络将输出像素强度映射到R′,G′,B′:
-
I5(R′,G′,B′)=L(I4(R,G,B)).(6) I_5(R^ ′ , G^′ , B^′ ) = L(I_4(R, G, B)). (6) I5(R′,G′,B′)=L(I4(R,G,B)).(6)
-
通过图像级适配器获得的图像I5将被转发到下游网络的中枢。此外,在主干中获得的I5特性将与模型级适配器融合,我们将详细讨论这一点。
-

-
图5。(一)。我们采用查询自适应学习(QAL)来预测ISP过程中的关键参数。(二)。神经隐式3DLUT (NILUT ) ©的一个图解。我们显示原始适配器不同块的参数。
-
Model-level Adapters
-
输入级适配器保证为高级模型生成面向机器视觉的图像I5。然而,ISP阶段的信息(I1 I4)几乎被忽略了。受当前NLP和CV区域 中适配器设计的启发,我们采用ISP阶段的先验信息作为模型级适配器来指导后续模型的感知。此外,模型级适配器促进了下游任务和ISP阶段之间更紧密的集成。图4(a)中的虚线表示模型级适配器。
-
模型级适配器M将来自ISP阶段的信息集成到网络主干中。如图4(a)所示,我们将阶段1~4表示为网络主干中的不同阶段,图像I5将经过主干阶段1~4,然后跟随检测或分割头。我们利用卷积层ci从I1到I4提取特征,这些提取的特征被连接为 C(I1~4)=C(C1(I1),c2(I2),c3(I3),c4(I4))C(I_{1~4)}= C(C_1(I_1),c_2(I_2),c_3(I_3),c_4(I_4))C(I1~4)=C(C1(I1),c2(I2),c3(I3),c4(I4))。随后,C(I1 4I_{1~4}I1 4)通过两个残差块并生成适配器f1,f1将通过合并块与阶段1的特征合并,合并块的详细结构在图4©中示出,其大致包括连接过程和残差连接,最后合并块将输出阶段2的网络特征和附加适配器f2。则该过程将在网络主干的阶段2和阶段3中重复。我们将所有与模型级适配器相关的结构统称为M
-
我们在图5©中显示了原始适配器的不同部分参数编号,包括输入级适配器{PK (37.57K),PM (37.96K),L (1.97K)}和模型级适配器M(114.87k 687.59k),模型级适配器的参数编号取决于以下主干网络。RAW-Adapter的总参数数量约为0.2M至0.8M,远小于以下主干(ResNet-50 中的25.6M,Swin-L 中的197M),也小于以前的SOTA方法,如SID (11.99M)和Dirty-Pixel (4.28M)。
-
在介绍了我们的RAW-Adapter模型之后,在第四节中,我们将介绍建议的RAW-Bench,它包括17种常见退化,并将用于评估RAW-Adapter和其他方法的鲁棒性 。在第五节中,我们将介绍基于RAW的数据扩充,它旨在进一步增强RAW-Adapter的性能并提高其域外(OOD)泛化能力。
RAW-BENCH WITH RAW-BASED COMMON CORRUPTIONS
-
在这一节中,我们提出了RAW-Bench,它包括相机原始空间中的各种常见损坏。我们选择了两个数据集,PASCAL RAW 和iPhone XS Max ,这两个数据集都是在相对正常的条件下捕获的,以合成讹误。PASCAL RAW数据集被转换为PASCAL RAW-D,作为对象检测的鲁棒性基准,而iPhone XS Max数据集被转换为iPhone XS Max-D,用于语义分割。我们没有使用像 这样的数据集,因为它们已经是在不同的光照和天气条件下拍摄的。接下来,我们介绍相机原始空间中可能发生的常见破坏,如亮度退化、天气影响、模糊、成像退化和相机颜色响应函数的变化,并描述相应的退化合成管道(可视化见图6)。
-
值得注意的是,以前的视觉鲁棒性基准 ,大多是基于渲染的sRGB数据,而我们的工作重点是发生在相机原始空间的退化。因此,我们只考虑可能发生在RAW中的损坏,而不解决与ISP阶段相关的退化,例如由不正确的白平衡设置或色度去噪引入的重影伪像引起的退化。
Lightness Degradations
-
弱光:自然黑暗环境和相机曝光设置(ISO, f-number, exposure time)都会影响拍摄的原始数据的亮度。由于光强度和环境辐照度与原始数据具有线性关系,我们采用了我们的会议版本和先前工作中的合成方法来生成低照度原始数据,如下所示:
-
xn∼N(µ=lx,σ2=δr2+δslx)y=lx+xn,(7) x_n ∼ N(µ = lx, σ^2 = δ^ 2_r + δ_slx)\\ y = lx + x_n, (7) xn∼N(µ=lx,σ2=δr2+δslx)y=lx+xn,(7)
-
其中 x 表示输入原始数据,y表示退化的原始数据,δs = √ S表示散粒噪声,而√ S是传感器的信号,δr表示读取噪声,l 表示从[0.05,0.4]中随机选择的光强度参数,以合成弱光破坏。图6(b)中示出了一个例子。
-

-
图6。PASCAL原始数据集中的“汽车”照片示例,通过平均绿色通道并应用编码gamma为1/1.4的gamma校正,可以更好地进行可视化。我们综合了可能在相机成像的不同阶段出现的各种破坏,例如照明、天气、模糊和固有的相机成像退化(例如,传感器噪声、CMOS传感器损坏),以及不同的相机颜色响应函数(交叉传感器)。
-
-
过度曝光:相机曝光误差和强烈的自然光也会显著影响视觉任务。对于过度曝光的原始合成,我们应用了用于低光图像的相同合成公式(等式7),其中光强度参数l从范围[3.5,5.0]中随机选择。图6©中示出了一个例子。
-
眩光:强光源场景的照片通常会出现镜头眩光,其图案受镜头光学、光源位置、制造缺陷以及累积的划痕或灰尘的影响。镜头眩光引起的局部过度曝光和伪像会对下游任务产生负面影响。在之后,我们合成耀斑破坏的图像如下:
-
y=x+F+N(0,σ2).(8) y = x + F + N(0, σ^2 ). (8) y=x+F+N(0,σ2).(8)
-
这里,X表示无耀斑的输入原始数据,F表示仅有耀斑的图像,其中我们从作品中随机选择10个模式,N(0,σ^2)表示高斯噪声,每个图像采样的方差来自缩放的卡方分布σ2∾X 2。图6(d)示出了一个例子。
-
-
低光和闪光(Low & Flare):夜间环境中的人造光(如汽车前灯和霓虹灯)会产生更大的负面影响 。因此,我们进一步将耀斑退化纳入弱光条件(等式 7),如下所示:
-
y=lx+F+xn,(9) y = lx + F + x_n, (9) y=lx+F+xn,(9)
-
光强度参数 l 和噪声 xn 与等式相同。如图7所示,图6(e)示出了一个例子。
-
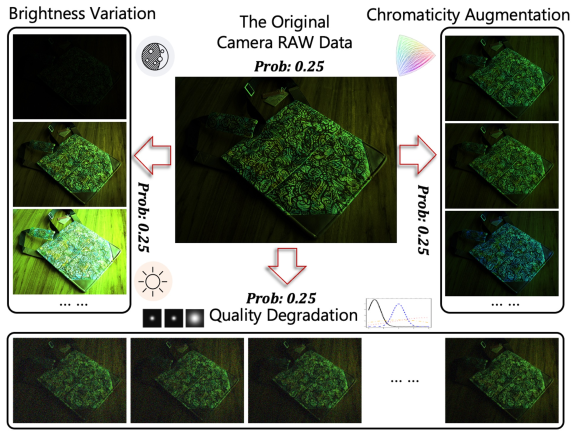
-
图7。基于RAW的数据增强概述,包括亮度变化、色度增强和质量下降。
-
Weather Effects
-
雾:有雾或朦胧的环境对计算机视觉任务有重大影响。遵循Koschmieder定律,我们合成相机原始数据上的模糊效果如下:
-
y=x⋅t(x)+A⋅(1−t(x)),(10) y = x · t(x) + A · (1 − t(x)), (10) y=x⋅t(x)+A⋅(1−t(x)),(10)
-
其中x表示原始原始数据,y表示有雾的退化原始数据,A表示全局大气光,t(x)=e−βd(x)t(x)= e^{-βd(x)}t(x)=e−βd(x) 是介质透射图。这里,β表示大气散射参数,d(x)表示场景深度x。我们使用离线深度估计方法Depth anythings model 来预测深度d(x),然后将超参数A和β设置为与work 相同。图6(f)示出了一个例子。
-
-
雨:雨环境对人类和机器视觉系统也有重大影响。在这里,我们采用imgaug工具箱在相机原始数据上添加雨条纹效果,以如下方式合成雨原始数据y:
-
y=x+∑i=1NRi,(11) y = x + \sum^N_{i=1} R_i , (11) y=x+i=1∑NRi,(11)
-
其中x是无雨输入原始数据,Ri表示添加的雨层。图6(g)示出了一个例子。
-
-
雨和雾:当考虑大雨时,必须考虑雨条纹和雾的综合影响。在之后,我们将雨和雾的效果合成如下:
-
y=(x+∑i=1NRi)⋅t(x)+A⋅(1−t(x)),(12) y = (x +\sum^N_{i=1} R_i) · t(x) + A · (1 − t(x)), (12) y=(x+i=1∑NRi)⋅t(x)+A⋅(1−t(x)),(12)
-
这个方程式是方程式10和Eq11的组合。,图6(h)中示出了一个例子。
-
-
雪:雪也是不利天气条件下的一个重要因素,我们按照前人的工作[Transweather: Transformer-based restoration of images degraded by adverse weather conditions]来完成雪的合成,方程如下:
-
y=x⋅(1−z)+z⋅S,(13) y = x · (1 − z) + z · S ,(13) y=x⋅(1−z)+z⋅S,(13)
-
其中z表示雪遮罩区域,S表示雪花(S图案取自imgaug工具箱)。图6(i)中示出了一个例子。
-
Blurriness
-
运动模糊:运动模糊是由于曝光期间相机和场景之间的相对运动而发生的,导致锐度损失,其中对象沿着运动方向出现模糊或拉伸。为了在去马赛克的camera RAW上合成运动模糊,我们使用imgaug工具箱中的点扩散函数(PSF)。图6(j)中示出了一个例子。
-
散焦模糊:当宽光圈阻止光线正确会聚,导致相机焦距之外的场景点看起来模糊时,就会出现散焦模糊。为了在去马赛克的相机RAW上合成散焦模糊,我们使用imgaug工具箱中的点扩散函数(PSF)。图6(k)中示出了一个例子。
Camera Imaging Degradations
-
传感器噪声:相机原始图像中的噪声来源于成像管道中的各个阶段,跨越了从光子到电子,然后到电压,最后到数字的转换过程 。在本文中,我们遵循 中的建模方法,将散粒噪声(一种与光子相关的随机过程)和读取噪声(在电子读出过程中引入)结合成一个统一的表示,此外还考虑模数转换器(ADC)量化噪声,公式如下:
-
xn∼N(µ=x,σ2=δ2r+δsx)xquan∼U(−12B,12B)y=x+xn+xquan,(14) x_n ∼ N(µ = x, σ^2 = δ^ 2 r + δ_sx) \\ x_{quan} ∼ U(\frac{− 1 }{2B} ,\frac 1{2B} ) \\ y = x + x_n + x_{quan}, (14) xn∼N(µ=x,σ2=δ2r+δsx)xquan∼U(2B−1,2B1)y=x+xn+xquan,(14)
-
这里,镜头读取噪声设置xn与Eq7相同。其中xquan表示与B位相关的量化噪声,遵循均匀分布,并且B在帕斯卡原始数据集和iPhone XS Max-D数据集中的位数之后被设置为12。图6(l)中示出了一个例子。
-
-
CMOS传感器损坏(CMOS-SD):由于像素行故障或读出电路问题,老化的CMOS传感器可能会导致黑线,以及来自热像素、增加的热噪声或固定模式噪声的白点。我们通过在数字信号中引入黑线和白点损伤来模拟这种损坏,基于激光光斑模型进行模拟。图6(m)中示出了一个例子。
-
莫尔效应:当相机的采样频率不足以捕捉高频细节时,会出现莫尔图案,导致如奈奎斯特采样定理所述的混叠。为了在相机的RAW图像上合成莫尔图案,我们创建条纹图案并将其叠加到RAW图像上,调整图案的频率,角度和透明度,然后混合各层以产生莫尔效应。图6(n)中显示了一个例子。
-
暗角:暗角是指与中心相比,图像边缘的亮度或饱和度降低。有几个因素会导致渐晕,如使用厚或堆叠的滤光片和不合适的透镜罩。在这里,我们遵循工作,使用2D高斯渐晕滤波器对相机原始图像执行渐晕效果,示例如图6(o)所示。
-
色差(CA):当相机透镜未能将所有波长的光聚焦在同一点时,就会发生色差,导致沿着图像的暗区和亮区之间的边界出现颜色“条纹”。下面我们使用径向失真合成色差效应(k1,二阶),其被实现为k1径向失真的每通道(红、绿色、蓝)变化,示例在图6(p)中示出。
Camera Color Response Functions (Cross Sensor)
-
除了相机RAW空间中的常见损坏之外,原始RGB颜色由于传感器之间的光谱灵敏度差异而变化 。数学上,原始RGB颜色x可以描述如下 :
-
x=∫ωρ(λ)⋅R(λ)⋅L(λ)dλ.(15) x = \int_ω ρ(λ) · R(λ) · L(λ) dλ. (15) x=∫ωρ(λ)⋅R(λ)⋅L(λ)dλ.(15)
-
其中λ表示波长,ω表示可见光谱(380 - 720 nm),ρ表示光谱功率分布,R表示捕获的对象光谱反射特性,而L表示相机传感器灵敏度。相机传感器灵敏度的差异可能导致最终捕获的RAW数据的变化。在我们的RAW Bench中,我们还将不同的相机颜色响应函数L视为一种常见的腐败,以评估模型在不同传感器上的OOD性能。利用当前的SOTA无监督RAW到RAW转换模型,可以将输入RAW数据x(由摄像机A捕获)转换成目标RAW数据y(由摄像机B捕获的相同场景),而不需要配对训练。
-
y=f(x),(16) y = f(x), (16) y=f(x),(16)
-
这里f(·)表示传感器到传感器的映射。我们使用中的转换方法将源传感器(例如尼康D3200 DSLR )捕获的RAW数据转换为与目标传感器(例如iPhone X和三星Galaxy S9 )捕获的RAW数据非常相似。示例如图6(q)和图6(r)所示。
-
RAW-BASED DATA AUGMENTATION
-
在本节中,我们将介绍我们基于RAW的数据增强解决方案,以进一步提高RAWAdapter的性能,并增强其在各种损坏情况下的域外(OOD)鲁棒性。以前的研究也表明了数据增强对提高模型鲁棒性的积极影响。我们的增强方法直接在相机RAW域中操作,并包含三个关键组件:亮度变化、色度增强和质量下降。所提出的方法的概述如图7所示。每个增强组件的详细设计描述如下:
-
(a).亮度变化:对于亮度变化,我们在训练过程中将输入RAW映射到随机亮度水平。具体来说,输入RAW图像通过照明系数ω进行缩放,其中ω遵循以下分布:
-
ω∈{TN(0.2,0.08;0.01,1.0),prob=0.5TN(3.5,1.0;1.0,5.0),prob=0.5(17) \omega\in\left\{ \begin{array} {ll}\mathcal{TN}(0.2,0.08;0.01,1.0),\quad prob=0.5 \\ \mathcal{TN}(3.5,1.0;1.0,5.0),\quad prob=0.5 \end{array}\right.\quad(17) ω∈{TN(0.2,0.08;0.01,1.0),prob=0.5TN(3.5,1.0;1.0,5.0),prob=0.5(17)
-
其中T N(µ,σ; min,max)表示截断的高斯分布,µ是平均值,σ是标准差,min和max分别表示范围的下限和上限。这确保了RAW图像在训练期间覆盖不同的亮度水平范围。
-
(b).色度增强:除了亮度变化之外,我们还通过将每个通道乘以随机值,同时确保三个随机值之和等于3,来在去马赛克的3通道线性Raw-RGB数据上加入色度增强。
-
R′=ωr⋅R,G′=ωg⋅G,B′=ωb⋅B(18)ωr+ωg+ωb=3,ωr∈U(0.9,1.1),ωb∈U(0.9,1.1) \begin{aligned} & R^{\prime}=\omega_{r}\cdot R,G^{\prime}=\omega_{g}\cdot G,B^{\prime}=\omega_{b}\cdot B & & \mathrm{(18)} \\ & \omega_{r}+\omega_{g}+\omega_{b}=3,\omega_{r}\in U(0.9,1.1),\omega_{b}\in U(0.9,1.1) \end{aligned} R′=ωr⋅R,G′=ωg⋅G,B′=ωb⋅Bωr+ωg+ωb=3,ωr∈U(0.9,1.1),ωb∈U(0.9,1.1)(18)
-
增强的RAW数据的可视化在图7的右边。我们的目标是最大限度地提高色度色彩抖动,同时最大限度地减少整体亮度的变化。
-
-
©.质量下降:受以前的工作 的启发,在这里我们进一步将噪声和模糊作为 RAW 数据的数据增强。具体来说,我们采用中的退化合成方法。对于模糊,我们使用各向同性kiso和各向异性kaniso高斯核;核大小从 {7×7,9×9,...,21×21}\{7 × 7,9 × 9,...,21 × 21\}{7×7,9×9,...,21×21} 均匀采样。对于 kisok_{iso}kiso,核宽度是从(0.1,2.4)均匀得出的。对于kaniso,内核角度从(0,π)均匀采样,而长轴宽度从(0.5,6).对于噪声,我们采用零均值加性高斯白噪声(AWGN)模型 n~N(0,σ)n~ N(0,σ)n~N(0,σ),方差σ从均匀分布U中随机选取(0,(0.1⋅2B)/2B0,(0.1·2^ B)/2^ B0,(0.1⋅2B)/2B)和B表示RAW的位数。噪声和模糊的混叠遵循与相同的方法。
-
增强(a),(b)和(c)与原始RAW图像一起应用,每个都是在训练过程中随机选择的,概率为0.25。实验表明,我们简单的基于RAW的数据增强方法显着增强了RAW适配器和其他算法的性能,同时也大大提高了OOD鲁棒性(见图3)。
EXPERIMENTS
- 在本节中,我们将展示我们的实验。我们开始于数据集和实验设置(第VI-A节),然后是在域内(ID)训练设置下的对象检测(第VI-B节)和语义分割(第VI-C节)结果。最后,我们报告了域外(OOD)推广结果(第六至第四节)。补充材料中提供了其他消融研究和可视化结果。
Dataset and Experimental Setting
-
1)数据集:在RAW-Bench上进行了目标检测和语义分割实验(PASCAL RAWD,iPhone XS Max-D)和低光RAW检测数据集LOD 。表I中提供了数据集的概述。对于对象检测,我们使用PASCAL RAW-D和LOD 。这里PASCAL RAW 是一个正常条件RAW数据集,包含4,使用Nikon D3200 DSLR捕获的3个对象类的259张图像。在[Pascalraw: raw image database for object detection]之后,我们使用2,129张图像进行训练,2,130张用于测试。为了评估RAW适配器和其他方法的鲁棒性,我们通过引入各种基于RAW的损坏来合成PASCAL RAW-D(第四节,图6)。LOD 是一个真实世界的低光数据集,包含使用Canon EOS 5D Mark IV捕获的8个对象类别的2,230张RAW图像。我们使用1,800张图像进行训练,430张用于测试。
-
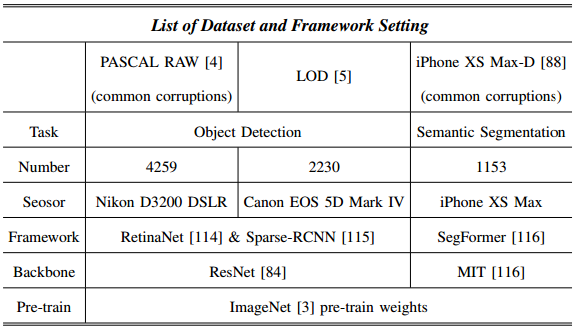
-
表1列出了我们实验中的数据集和框架设置。
-
-
对于语义分割,我们使用了iPhone XS Max数据集,这是一个真实的RAW数据集,包含1,153张图像和相应的语义标签。该数据集分为806张图像用于训练,347张用于评估。与PASCAL RAW-D类似,我们通过引入各种基于RAW的损坏来合成iPhone XS Max-D(第四节)。
-
2)实作详细数据:我们使用开源计算机视觉工具箱mmdetection 和mmsegmentation 构建RAW适配器。对象检测任务和语义分割任务都使用ImageNet预训练权重进行初始化(见表一),而我们在默认设置下应用数据增强流水线,主要包括随机裁剪、随机翻转、多尺度测试等,对于目标检测任务,我们采用了两种主流的对象检测器:RetinaNet 和Sparse-RCNN 以及ResNet 主干。对于语义分割任务,我们选择使用主流分割框架Segformer 以及他们提出的MIT 主干。
-
3)比较方法:我们工作中的比较方法分为三类:(a)sRGB之外的不同输入图像类型,(B)用于将RAW转换为sRGB的不同ISP技术,以及(c)最先进的(SOTA)联合训练方法。这些方法的详细列表在表II中提供。对于组(a),我们将原始去马赛克相机RAW数据,从RAW生成的log-RGB数据,对于组(B),我们比较了不同的ISP解决方案,包括相机默认ISP,传统的人工ISP方法Karaimer等人,以及最近的SOTA深度学习ISP方法Lite-ISP ,InvISP ,SID 和DNF ,其中SID 和DNF 是专门为低光照条件RAW数据设计的。对于组(c),我们比较了两种SOTA联合训练方法,Dirty-Pixel 和Reconfig-ISP 。同时,为了确保公平性,所有竞争方法都使用与RAW-Adapter相同的策略和epoch数进行训练。
Object Detection Evaluation
-
表III列出了PASCAL RAW(-D)数据集上的对象检测结果。我们采用RetinaNet检测器与ResNet-18和ResNet-50主干。我们的比较包括不同的数据输入类型(RAW,log-RGB 和色度空间),ISP解决方案(Karaimer等人、Lite-ISP 和InvISP )以及联合训练方法(Dirty-Pixel 、Reconfig-ISP )。
-

-
表二列出了我们实验中的比较方法。
-
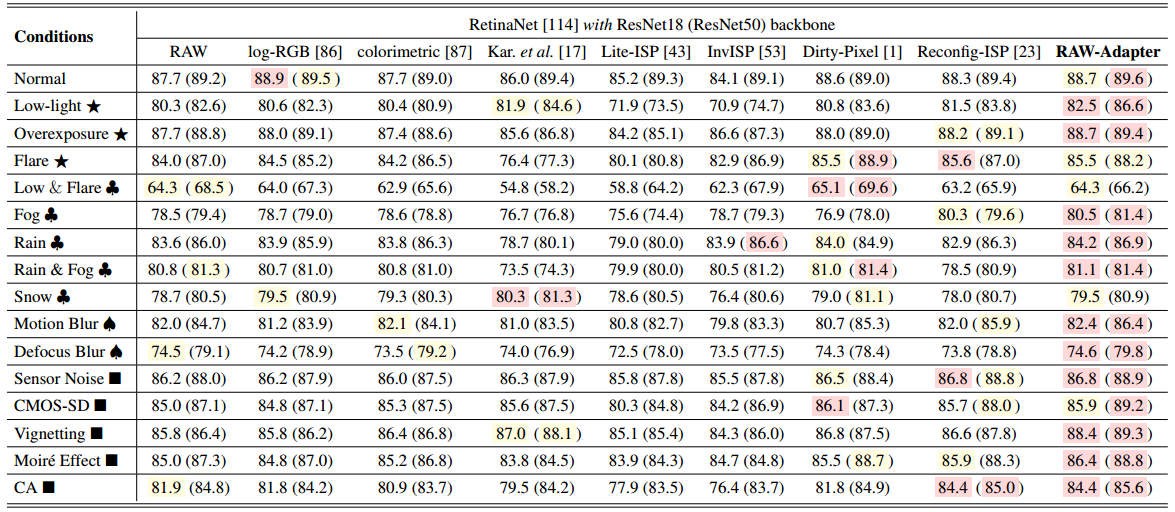
-
表III PASCAL RAW-D数据集的比较结果(MAP%)。红色背景色显示最佳地图结果,而黄色显示第二最佳地图结果。括号外的结果代表具有RESNET-18骨架的RETINANET,而括号内的结果代表具有RESNET-50骨架的RETINANET。
-
-
如表三所示,(Dirty-Pixel, Reconfig-ISP, and RAW-Adapter)显著优于其他方法,在大多数情况下实现了最佳性能。而log-RGB在正常条件下表现良好,基于深度学习的ISP方法(LiteISP,InvISP)与RAW图像和传统ISP算法相比通常表现不佳。Dirty-Pixel 在极端条件下表现出色,例如“低光和眩光”。
-
总的来说,无论是在正常情况下还是在损坏的情况下,RAW-Adapter都能始终保持顶级性能。值得注意的是,使用ResNet-18的RAW-Adapter甚至优于使用ResNet-50的许多方法,尤其是在“弱光⋆”和“下雨♣”的情况下。图8中的效率比较进一步强调了RAW-Adapter在训练时间和内存方面的优势。相比之下,脏像素受到堆叠残差U-Net 编码器的沉重计算成本的阻碍,而 ReconfigISP 由于神经架构搜索(NAS)的复杂性而遭受长时间的训练。
-

-
图8。与Dirty-Pixel和Reconfig-ISP的效率比较(检测:RetinaNet与ResNet-18,分割:SegFormer与MIT-B0).
-
-
表V给出了LOD 数据集上的对象检测结果。我们评估了RetinaNet 和Sparse-RCNN ,两者都使用ResNet-50主干,并将我们的结果与各种ISP方法和联合训练方法进行了比较。如表五所示,在弱光场景中,直接使用原始图像优于默认ISP和其他ISP方法,包括像SID 和DNF 这样的夜间特定算法。值得注意的是,RAW-Adapter在所有测试方法中获得了最佳的整体性能。
-
图9显示了可视化结果,其中背景图像是由Dirty-Pixel的前置编码器 和RAW-Adapter的输入级适配器处理的原始数据。在表V中,蓝色背景表示我们的原始数据扩充(秒)的结果。这增强了所有的联合训练方法,其中RAW-Adapter受益最大。
-

-
图9。使用具有ResNet-50 主干的RetinaNet 检测器在LOD数据集上的对象检测结果(请放大以了解详细信息)。
-
Semantic Segmentation Evaluation
-
iPhone XSmax (-D)数据集上的语义切分结果如表四所示。这里我们采用不同大小的主链麻省理工学院-B0和麻省理工学院-B3,segformer。同样,这里我们采用与PASCAL RAW-D中相同的比较方法(表III)。
-
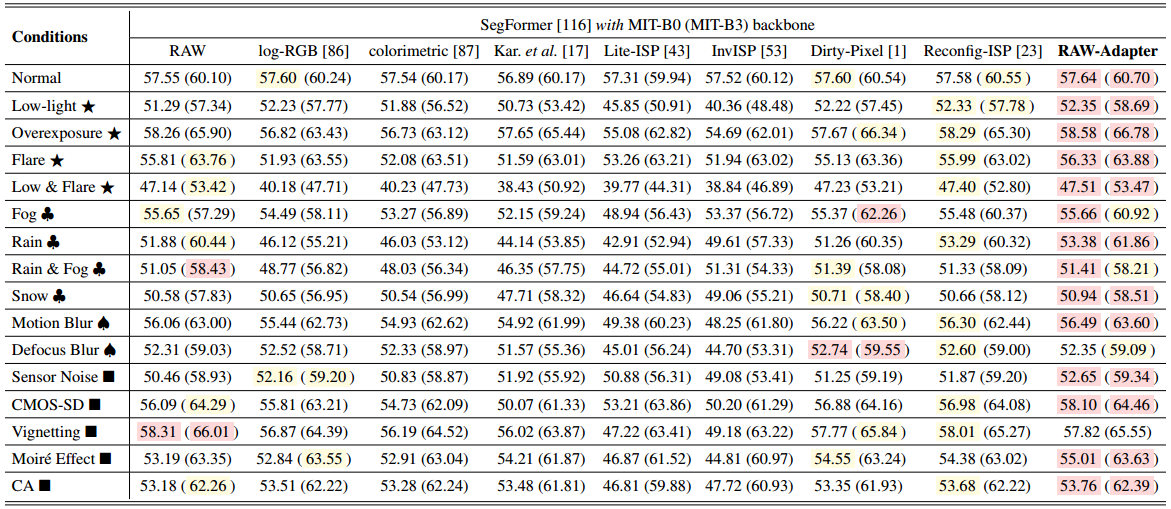
-
表四,IPHONE XS MAX-D数据集上的比较结果(MIOU%)。红色背景色显示最佳MIOU结果,而黄色显示第二好MIOU结果。括号外的结果代表具有MIT-B0骨架的SEGFORMER,而括号内的结果代表具有MIT-B3骨架的SEGFORMER。
-
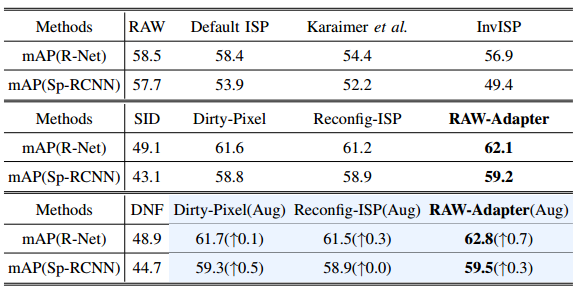
-
表V LOD数据集的比较结果。我们展示了RETINANET (R-NET) 和SPARSE-RCNN (SP-RCNN) 的检测性能图(↑),粗体表示最佳结果。
-
-
从表IV中,我们观察到,在语义分割任务中,直接使用camera RAW作为输入产生了有希望的结果(即在“晕映”中最好)。此外,无论是传统的手工ISP方法还是当代基于深度学习的ISP方法都无法获得可比的结果,这可能是因为现有的ISP算法可能会在降级条件下无意中抑制关键的语义特征。总体而言,RAW-Adapter在标准和降级条件下始终优于竞争方法,在MIT-B0主干网上获得了16个最佳结果中的14个,在MIT-B3主干网上获得了16个最佳结果中的12个,从而强调了其强大的域内性能。图8进一步展示了RAW-Adapter的计算优势。
Out-of-domain (OOD) Robustness Evaluation
-
除了上述域内(ID)实验,我们还检验了当前基于原始数据的感知方法的域外(OOD)鲁棒性,包括直接原始输入(表VI和表VII中的“基线”)。DirtyPixel 、Reconfig-ISP 和我们的RAW-Adapter。具体来说,我们在正常条件数据集上训练模型,并在推理阶段评估它们在各种常见的基于raw的破坏下的OOD性能(图3)。
-
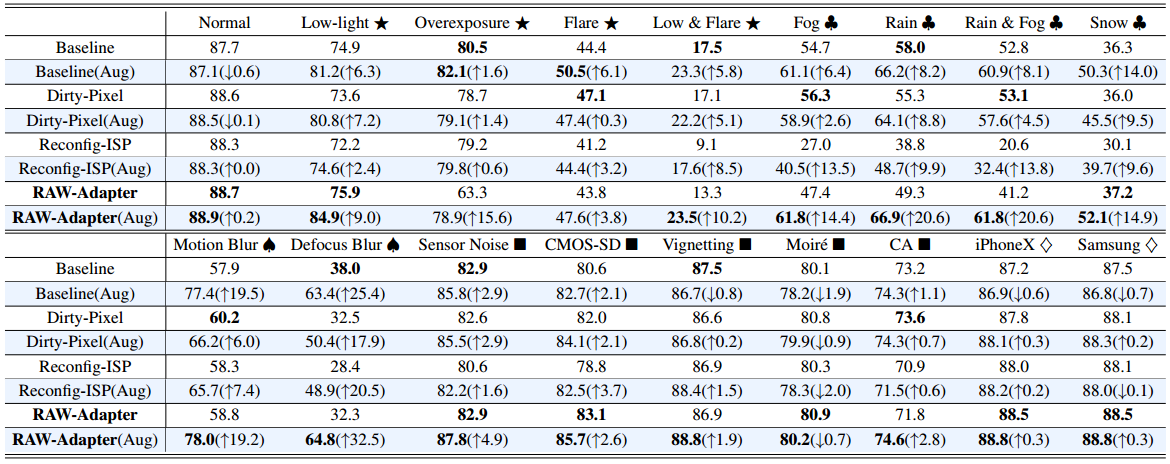
-
表VI PASCAL RAW-D数据集上的域外(OOD)检测结果(MAP %)。我们采用RETINANET 和RESNET-18 主干。(⋆:亮度退化、♣:天气影响、♠:模糊、■:成像退化、♢:十字传感器)。蓝色背景突出显示通过基于原始数据的数据扩充获得的结果。粗体表示最佳结果。
-
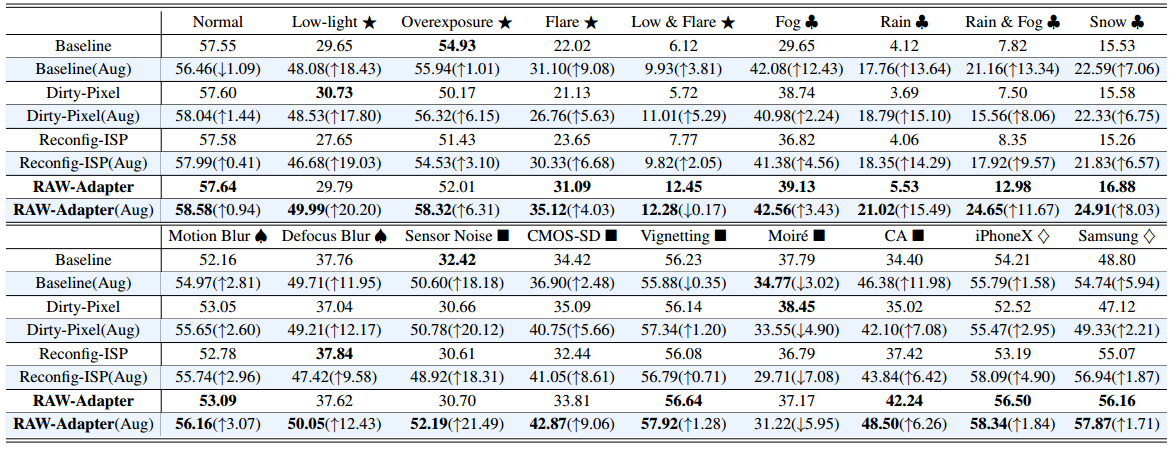
-
表VII IPHONE XS MAX-D数据集上的域外(OOD)分割结果(MIOU %)。我们采用带MIT-B0 主干的SEGFORMER 。(⋆:亮度退化、♣:天气影响、♠:模糊、■:成像退化、♢:十字传感器)。蓝色背景突出显示通过基于原始数据的数据扩充获得的结果。粗体表示最佳结果。
-
-
对于PASCAL RAW-D上的OOD鲁棒性评估,我们使用RetinaNet 和ResNet-18 主干。表VI呈现地图比较结果。在表VI中,具有白色背景的单元指示模型在正常条件下被训练,而具有蓝色背景的单元对应于使用我们的基于原始数据的数据扩充(Sec v)在正常情况下。相应的可视化结果如图10所示。对于iPhone XS Max-D的OOD评估,我们采用了带MIT-B0主干的SegFormer 。mIOU比较结果如表VII所示。并且相应的可视化结果在图11-2中提供。除了mAP和mIOU评估指标,我们还遵循并引入了腐败降级(CD)和相对腐败降级(rCD)指标,定义如下:
-
CDcf=Dcf/DcrefrCDcf=(Dcf−Dnormalf)/(Dcref−Dnormalref)(19) \mathrm{CD}_c^f = D_c^f / D_c^{\mathrm{ref}} \\ \mathrm{rCD}_c^f = (D_c^f - D_{\mathrm{normal}}^f) / (D_c^{\mathrm{ref}} - D_{\mathrm{normal}}^{\mathrm{ref}}) \tag{19} CDcf=Dcf/DcrefrCDcf=(Dcf−Dnormalf)/(Dcref−Dnormalref)(19)
-
其中D表示模型误差,定义为对象检测任务的D = 1 - mAP,语义分割任务的D = 1- mIOU。此外,c表示损坏类型(即“弱光⋆”),f表示评估方法(DirtyPixel 、Reconfig-ISP 和RAW-Adapter),ref表示参考基线(直接原始输入)。CD结果如图13 (PASCAL RAW-D)和图14 (iPhone XS Max-D)所示,其中我们分析了不同退化条件下每个联合训练方法的得分,我们主要使用CD来比较不同方法的鲁棒性。同时,图12中示出了不同恶化条件下的平均rCD结果。低于100%的CD和rCD值表明,与基线(直接原始输入)相比,稳健性能更好。随后的分析提供了对不同类型的损坏的健壮性的详细检查。
-

-
图10。PASCAL RAW-D数据集上RAW-Adapter的OOD检测结果(在每个子图的右下角输入RAW)。(b)基本事实。
-
-
性能w.r.t正常条件:表VI显示基于RAW的数据增强将RAW-Adapter在PASCAL RAW检测上的性能提高了0.2个点。它对其他两种联合训练方法没有好处,并且降低了基线的表现。表七表明,增强改善了所有三种联合训练方法的iPhone XS Max-D分割结果,而基线下降,可能是因为缺乏增强的自适应参数。
-
亮度退化下的性能:在表六和表七中,⋆ 符号表示在各种亮度退化下的性能。在表六(白色背景)中,“弱光&眩光⋆”对探测性能的负面影响最大。耀斑和弱光的综合效应创造了具有挑战性的条件(见图10)。基线方法对光照变化保持稳健;原始适配器与“过度曝光⋆”作斗争,但在“低光 ⋆".”下表现良好有了数据增强(蓝色背景),所有模型都有所改善;图13显示RAW-Adapter的CD值降低(表明鲁棒性更好),而 Dirty-Pixel 和 Reconfig-ISP 的 CD 值增加。
-
在用于语义分割的表VII(白色背景)中,“低光&闪光⋆”也具有最严重的影响,而“过度曝光⋆”具有最小的影响(见图11)。数据增强(蓝色背景)增强了所有模型的性能,RAW-Adapter (Aug)实现了所有最佳结果。
-
天气影响下的性能:♣符号表示模型在各种恶劣天气下的性能。在表VI(白色背景)中,“雪♣”和“雨和雾♣”导致检测性能的最大下降,可能是由于物体遮挡导致误预测(见图10)。在数据增强(蓝色背景)后,所有方法都得到了改进,其中RAW-Adapter获得了最好的结果。
-
同时,在用于语义分割的表VII(白色背景)中,“雨♣”和“雨和雾♣”导致最显著的下降,主要是因为雨条纹扰乱了原始数据中的语义信息(见图11)。数据扩充后,所有方法的性能都有所提高。值得注意的是,RAW-Adapter始终如一地提供最佳性能,而不管扩增情况如何,其CD %保持在100 %以下(见图14)。
-
性能w.r.t模糊度:♠符号表示模糊损坏下的性能。在表VI(白色背景)中,“散焦模糊♠”严重影响所有方法(例如,RAW-Adapter从88.7下降到32.3)。在应用数据扩充(蓝色背景)后,所有方法都得到了改进,部分原因是基于原始数据的数据扩充模拟了不同的退化条件,并在训练过程中增加了退化样本的数量。
-
在用于语义分割的表VII(白色背景)中,与检测结果一致,“散焦模糊♠”继续具有比“运动Blur ♠".”更严重的影响这部分是因为散焦模糊导致精细纹理细节的更大损失,这对于精确分割是至关重要的(参见图11)。
-
相机成像退化下的性能:■符号表示各种相机成像退化下的模型性能。在表VI(白色背景)中,“色差(CA) ■”导致检测性能显著下降。同时,RAW-Adapter在“噪声”、“CMOS-SD”和“莫尔效应”下保持强大的域外鲁棒性。有趣的是,在数据增强(蓝色背景)后,所有模型在相机成像退化下都表现出改进的性能,除了“莫尔效应■”,它在基于RAW的数据增强后表现得更差。此外,RAW-Adapter的CD%值保持在100%以下,表明它比其他两种方法表现出更好的稳健性(见图13)。
-
同时,在用于语义分割的表VII(白色背景)中,“噪声”和“CMOS-SD”导致显著的性能下降。图11示出了这两种类型的退化严重影响语义信息。类似于检测中的结论,在数据增强(蓝色背景)后,只有“莫尔效应■”表现出性能下降。
-
性能w.r.t交叉传感器能力:♢符号表示不同相机颜色响应功能下的模型性能(交叉传感器场景)。具体来说,它代表了模型根据来自相机传感器a的原始数据进行训练并根据来自相机传感器b的原始数据进行测试的情况。在对象检测任务(表VI)中,PASCAL原始数据集是使用尼康D3200 DSLR相机收集的,在“尼康D3200 → iPhoneX ♢”和“尼康D3200 →三星S9 ♢”设置下观察到轻微的性能下降。有趣的是,在基于原始数据的数据增强(表VI中的蓝色背景)之后,只有基线方法的性能总体下降,而其他联合训练方法的性能总体上有所提高。
-
对于语义分割任务(表VII),iPhone XS Max数据集是使用iPhone XS Max手机摄像头收集的。因为iPhone XS Max和iPhone X具有非常相似的相机型号和传感器类型,所以在“iPhone XS Max → iPhoneX ♢”设置中观察到的OOD性能下降很少(例如,基线从57.55到54.21)。然而,在“iPhone XS Max →三星S9 ♢”设置中,由于传感器特性和ISP的显著差异,性能下降更加显著(例如,从57.55到48.80的基线)。总体而言,基于原始数据的数据扩充(表VII中的蓝色背景)可以有效地增强所有方法的分割性能。
-
总体讨论:从图13和图14中,我们可以观察到RAW-Adapter的CD值通常较低,表明与其他方法相比具有更好的鲁棒性。值得注意的是,在数据扩充之后,尽管大多数方法显示出性能改进,但是脏像素和重新配置ISP的鲁棒性相对于基线(大于100 %的CD值)趋于下降。同时,RAW-Adapter显示出稳健性提高的趋势(CD值降低)。图12中的rCD比较结果也表明RAWAdapter的总体鲁棒性更好。
-

-
图11。iPhone XS MaxD数据集上RAW-Adapter的OOD分割结果(在每个子图的右下角输入RAW)。(b)基本事实。
-

-
图12。PASCAL RAW-D检测和iPhone XS Max-D分段任务的相对损坏率(rCD %)。蓝色条代表原始结果。黄条代表基于原始数据的数据扩充所获得的结果。rCD值计算为17种损坏类型的截断平均值(不包括最高和最低值)。
-
-
RAW-Adapter在某些情况下表现不佳,如对象检测中的“过度曝光⋆”和“耀斑⋆”以及语义分割中的“莫尔效应”。然而,总的来说,RAW-Adapter在大多数场景中都取得了很好的效果。值得注意的是,在数据扩充后,RAW-Adapter在18个OOD检测案例中的12个和18个OOD分割案例中的17个中实现了最佳性能。
CONCLUSION
-
在这项工作中,我们介绍了RAW-Adapter,它使用输入和模型级适配器来连接预训练的sRGB模型和原始图像。我们的方法在现有的ISP和联合训练方法上实现了最先进的(SOTA)性能,并进一步受益于基于原始数据的增强。此外,我们提出了RAW-Bench,它建立了一个强大的基准,涵盖照明、天气、模糊和成像退化以及跨传感器性能。
-
对于未来的研究方向,我们认为探索基于相机原始图像的多任务架构是一个非常有意义的方向。一个有效的多任务系统可以促进大规模模型中原始图像上各种视觉任务的无缝集成。此外,将RAW-Adapter整合到现有的端到端自动驾驶系统中,以充分利用其在现实世界场景中的优势,是另一个有前途和有影响力的方向。通过利用原始图像的优势来抵消自动驾驶汽车中遇到的各种亮度和天气退化,这种方法可能会导致未来自动驾驶系统的变革性进步。
-
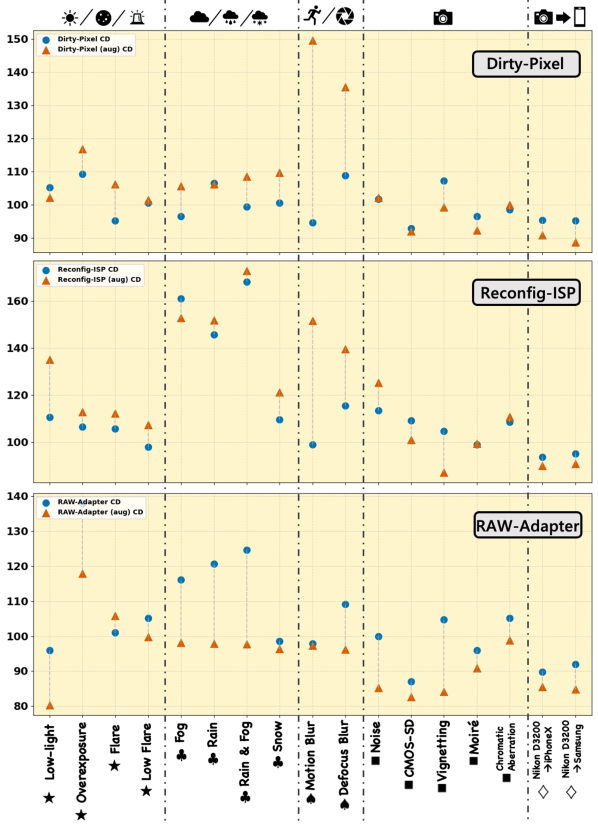
-
图13。PASCAL RAWD检测任务的损坏降级(CD %)结果。蓝色圆圈显示原始结果,黄色三角形显示基于原始数据增强的结果。
-
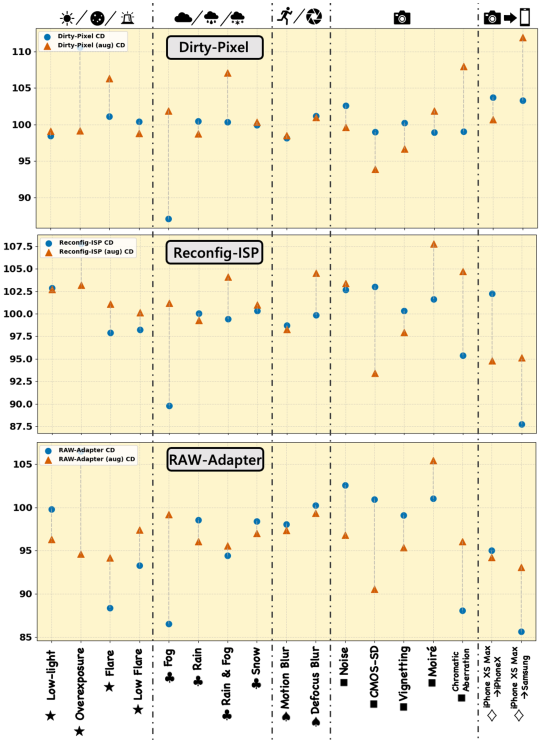
-
图14。iPhone XS Max-D分段任务的损坏降级(CD %)结果。蓝色圆圈显示原始结果,黄色三角形显示基于原始数据增强的结果。
-
ISP REVISITED
-
这里我们简要回顾一下数码相机成像过程,从相机传感器原始数据到输出渲染sRGB。请参考主文件中的图2 (a)作为示意图,ISP的基本步骤主要包括:
- (a)。预处理包括一些预处理操作,如黑电平调整、白电平调整和镜头阴影校正。
- (b)。降噪消除了噪声,保持了图像的视觉质量,这一步与曝光时间和相机ISO设置密切相关 。
- ©。去马赛克用于从单通道RAW重建3通道彩色图像,通过对Bayer模式中缺少的值进行插值来执行,依赖于CFA中的相邻值
- (d)。白平衡模拟人类视觉系统的色彩恒常性(HVS)。自动白平衡(AWB)算法估计传感器对场景照明的响应,并校正原始数据。
- (e)。颜色空间转换主要包括两个步骤,第一步是将白平衡像素映射到非渲染颜色空间(即CIEXYZ),第二步是将非渲染颜色空间映射到显示器参考颜色空间(即sRGB),通常每个步骤都使用基于特定相机的3×3矩阵。
- (f)。颜色和色调校正通常使用3D和1D查找表(lut)来实现,而色调映射也压缩像素值。
- (g)。锐化通过反锐化掩模或反卷积来增强图像细节。
-
我们参考了以前作品 中的其他步骤,如数字变焦和伽马校正。同时,在ISP管道中,许多其他操作优先考虑生成图像的质量,而不是它在机器视觉任务中的性能。因此,对于RAWAdapter中的特定适配器设计,我们有选择地省略某些步骤,而专注于包括上面提到的步骤。我们在第 III-A和Sec III-B提供了详细的解释。(主文件)。
ABLATION ANALYZE
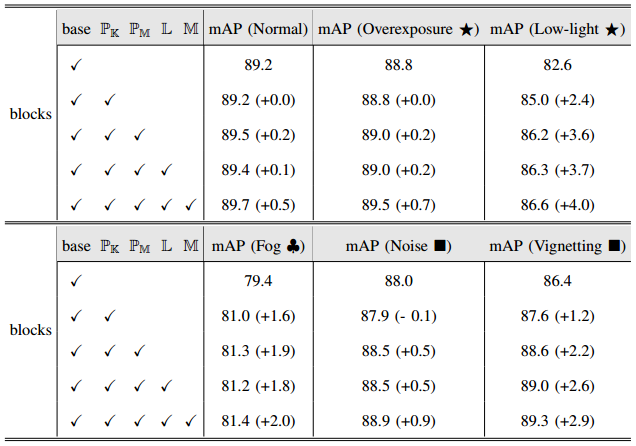
Impact of Different Blocks
- 我们进行了消融实验,以评估RAW-Adapter中各种组件的有效性。实验在PASCAL(-D)数据集上进行,使用RetinaNet 和ResNet-50主干,它们涵盖了正常和各种损坏的条件。表H8中给出的结果表明,内核预测器PK在“低光⋆”(+2.4)和“雾♣”(+1.6)场景中提供了显著的改进。这些增益主要归因于由增益比g和去噪过程提供的增强。
-
-
表H8,基于RAW-ADAPTER模型结构的消融分析。
-
- 然而,PK在“正常”、“过度曝光⋆”和“噪声■”场景中似乎不太有效,可能是因为当前基于核的去噪方法过于简单,可能会移除一些精细细节。同时,隐式LUT L在“过度曝光⋆”和“低光⋆”条件下不会产生改善,但在“渐晕”条件下证明是有效的。最后,模型级适配器M和矩阵预测器PM有助于所有场景的性能改进。总的来说,RAW-Adapter中的每个组件在应对不同条件时都扮演着独特的角色,它们共同确保了稳健的性能。
Different Parts in RAW-based Data Augmentation
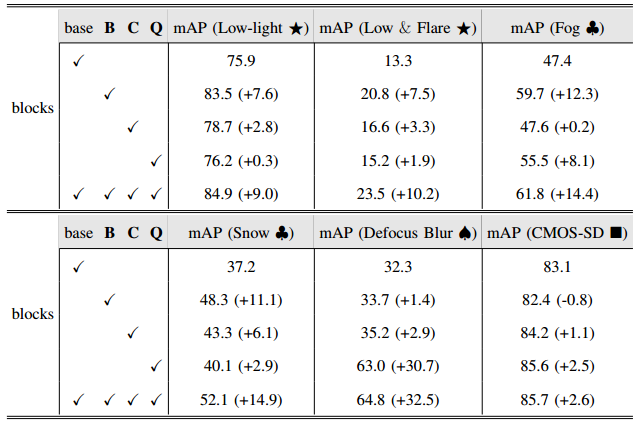
- 除了分析RAWAdapter设计中的不同模块之外,我们还进一步研究了基于RAW的数据增强的各种组件(主要论文的第五部分)如何影响RAW Adapter的OOD性能。我们在PASCAL RAW-D数据集上展示了RAW-Adapter的结果。如表I9 所示,其中B表示亮度变化,C表示色度增加,Q表示质量下降。我们观察到,b在处理亮度退化(“低光⋆”和“低光&耀斑⋆”)和天气影响(“雾♣”和“雪♣”)方面起着至关重要的作用,但也会导致“CMOS-SD”的性能下降。同时,c在大多数情况下都可以提高性能,尽管与b和q相比,提高的幅度仍然相对有限。此外,q在模糊场景(“散焦模糊♠”)和“CMOS-SD”中都非常有效。
-
-
表I9, 基于原始数据增强的消融分析。
-
DETAILED DESIGN OF INPUT-LEVEL ADAPTERS
-
在我们的主要论文中,我们概述了RAW-Adapter的输入级适配器包括三个组件:内核预测器PK、矩阵预测器PM和神经隐式3D LUT L。在这一节中,我们将详细说明如何设置输入级适配器的参数范围,并进行一些结果分析。
-
核预测器PK负责预测五个ISP相关的参数,包括①增益比g、高斯核② k的长轴半径r1、③ k的短轴半径r2、④锐度滤波器参数σ。
- ①增益比g用于调整图像I1的整体强度。这里g在正常光照和过度曝光条件下初始化为1。在弱光场景下,g被初始化为5。
- ②长轴半径r1初始化为3,我们预测r1变化的偏差,然后加到r1上。
- ③短轴半径r2初始化为2,我们预测r2变化的偏差,然后加到r2上。
- ④锐度滤波器参数σ受到Sigmoid激活函数的约束,以确保其范围在(0,1)内。
-
矩阵预测器PM负责预测⑤白平衡相关参数ρ和⑥白平衡矩阵Eccm (9个参数)。总共需要预测10个参数。
- ⑤ ρ是SOG 白平衡算法中闵可夫斯基距离的超参数。我们将它的最小值设置为1,然后使用一个ReLU激活函数,再加上1,将其范围限制为(1,+∞)。
- ⑥矩阵Eccm由PM预测的9个参数组成,形成一个3x3矩阵。不需要添加激活函数,它将被直接添加到单位矩阵E3以形成最终的Eccm。
-
在正文中,我们将神经隐式3D LUT (NILUT) 的MLP维数设置为32,以平衡性能和计算成本。展望未来,我们计划探索更先进的架构,以进一步提高LUT在基于RAW的视觉任务中的效率。
SEGMENTATION ON ADE20K-RAW (SYNTHESIZED)
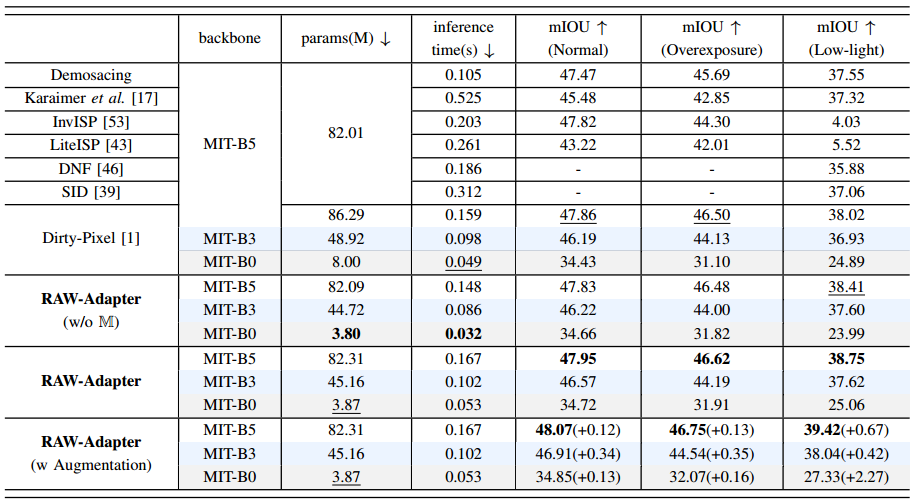
- 在我们的会议版本中,我们在ADE20K数据集上使用InvISP合成了ADE20K-RAW数据集,并设置了三种条件:正常、弱光和过度曝光。我们将我们的方法与以前的ISP算法 以及联合训练方法进行了比较。使用具有三个主链权重(麻省理工学院-B0、麻省理工学院-B3和麻省理工学院-B5)的SegFormer 框架,结果如表K10所示。此外,我们整合了基于RAW的数据增强,发现它显著提高了ADE20K-RAW的性能,进一步验证了我们增强策略的有效性。可视化结果显示在图K15中。
-
-
表K10,与ADE 20K原始数据集上的其他方法的比较(正常/过度曝光/低光)。
-

-
图K15。ADE20K-RAW 数据集上的可视化结果。
-
-
图L16。(a)PASCAL RAW-D数据集上的域外(OOD)物体检测结果,与原始基线(直接原始输入)、DirtyPixel 和Reconfig-ISP 进行比较。(b) GT 和平均OOD图(%)结果。
-

-
图L17。(a)iPhone XS Max-D数据集上的域外(OOD)语义分割结果,与原始基线(直接原始输入)、脏像素和Reconfig-ISP 进行比较。(b)基本事实和平均mIOU (%)结果。
-
MORE VISUALIZATION RESULTS
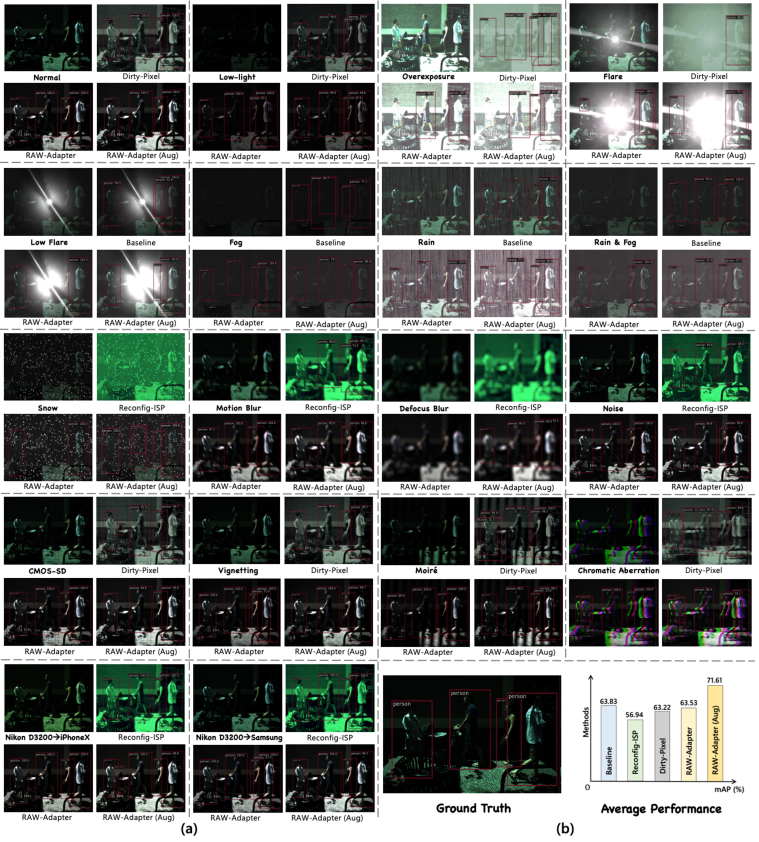
- 我们在图L16中呈现了附加的对象检测可视化结果(对应于表。VI)和图L17中的更多语义分割可视化结果(对应于表。主文中的VII)。由不同方法产生的背景图像代表编码器增强后的结果。值得注意的是,RAW-Adapter增强的图像中的背景呈现出最和谐的颜色,而Reconfig-ISP在处理食品案件时倾向于将背景向绿色色调转移。此外,基于原始数据的增强显著提高了良好的感知性能。例如,图L16中用于对象检测的“雨&雾♣”和“低&耀斑⋆”条件,以及图L17中用于语义分割的“雾♣”和“噪声■”条件,清楚地说明了这些改进。
语义分割部分(mmsegmentation_github)
-
数据处理流转过程:从文件中加载图像和标注,然后依次进行调整大小、裁剪、翻转、光度畸变等操作,最后封装成适合模型输入的数据格式。
-
# dataset settings dataset_type = 'iSAIDDataset' data_root = 'data/iSAID' crop_size = (896, 896) # 训练数据处理流程 train_pipeline = [ dict(type='LoadImageFromFile'), # 输入:文件路径,输出:加载的图像 dict(type='LoadAnnotations'), # 输入:文件路径,输出:加载的标注 dict( type='RandomResize', scale=(896, 896), ratio_range=(0.5, 2.0), keep_ratio=True), # 输入:图像和标注,输出:调整大小后的图像和标注 dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75), # 输入:图像和标注,输出:裁剪后的图像和标注 dict(type='RandomFlip', prob=0.5), # 输入:图像和标注,输出:翻转后的图像和标注 dict(type='PhotoMetricDistortion'), # 输入:图像和标注,输出:经过光度畸变处理后的图像和标注 dict(type='PackSegInputs') # 输入:图像和标注,输出:封装好用于分割任务的输入数据 ] # 测试数据处理流程 test_pipeline = [ dict(type='LoadImageFromFile'), # 输入:文件路径,输出:加载的图像 dict(type='Resize', scale=(896, 896), keep_ratio=True), # 输入:图像,输出:调整大小后的图像 # add loading annotation after ``Resize`` because ground truth # does not need to do resize data transform dict(type='LoadAnnotations'), # 输入:文件路径,输出:加载的标注 dict(type='PackSegInputs') # 输入:图像和标注,输出:封装好用于分割任务的输入数据 ] -
输入级适配器(Input - level Adapter),文件路径:ECCV_RAW_Adapter/mmdetection_github/mmdet/models/backbones/RAW_Adapter/input_adapter.py
-
# Input-level Adapter class Input_level_Adapeter(nn.Module): def __init__(self, mode='normal', lut_dim=32, out='all', k_size=3, w_lut=True): super(Input_level_Adapeter, self).__init__() ''' mode: normal (for normal & over-exposure conditions) or low (for low-light conditions) lut_dim: implicit neural look-up table dim number out: if all, return I1, I2, I3, I4, I5, if not all, only return I5 k_size: denosing kernel size, must be odd number, we set it to 9 in LOD dataset and 3 in other dataset w_lut: with or without implicit 3D Look-up Table ''' self.Predictor_K = Kernel_Predictor(dim=64, mode=mode) self.Predictor_M = Matrix_Predictor(dim=64) self.w_lut = w_lut if self.w_lut: self.LUT = NILUT(hidden_features=lut_dim) self.out = out self.k_size = k_size def forward(self, I1): # (1). I1 --> I2: Denoise & Enhancement & Sharpen r1, r2, gain, sigma = self.Predictor_K(I1) I2 = Gain_Denoise(I1, r1, r2, gain, sigma, k_size=self.k_size) # (B,C,H,W) I2 = torch.clamp(I2, 1e-5, 1.0) # normal & over-exposure ccm_matrix, distance = self.Predictor_M(I2) # (2). I2 --> I3: White Balance, Shade of Gray # (3). I3 --> I4: Camera Colour Matrix Transformation I3, I4 = WB_CCM(I2, ccm_matrix, distance) # (B,H,W,C) if self.w_lut: # (4). I4 --> I5: Implicit Neural LUT I5 = self.LUT(I4).permute(0,3,1,2) if self.out == 'all': # return all features return [I1, I2, I3.permute(0,3,1,2), I4.permute(0,3,1,2), I5] else: # only return I5 return [I5] else: if self.out == 'all': return [I1, I2, I3.permute(0,3,1,2), I4.permute(0,3,1,2)] else: return [I4.permute(0,3,1,2)] -
对输入的 RAW 图像进行预处理,包括去噪、增强、白平衡和颜色校正等操作,以改善图像的光照和色彩。
I1:形状为(B, C, H, W)的 RAW 图像张量,其中B是批量大小,C是通道数,H是高度,W是宽度。如果out == 'all':返回[I1, I2, I3, I4, I5]列表,其中每个元素都是形状为(B, C, H, W)的张量。mode:决定处理模式,'normal'用于正常和过曝条件,'low'用于低光照条件。w_lut:是否使用隐式 3D 查找表。在处理过程中,中间特征的形状可能会发生变化,但最终输出的形状仍然是(B, C, H, W)。
-
-
模型级适配器(Model - level Adapter)ECCV_RAW_Adapter/mmdetection_github/mmdet/models/backbones/RAW_Adapter/model_adapter.py
-
# Model-level Adapter Generation class Model_level_Adapeter(BaseModule): def __init__(self, in_c=3, in_dim=8, w_lut=True): super(Model_level_Adapeter, self).__init__() self.conv_1 = conv3x3(in_c, in_c, 2) self.conv_2 = conv3x3(in_c, in_c, 2) self.conv_3 = conv3x3(in_c, in_c, 2) self.w_lut = w_lut if self.w_lut: # With LUT: I1, I2, I3, I4 self.conv_4 = conv3x3(in_c, in_c, 2) self.uni_conv = conv7x7(4*in_c, in_dim, 2, padding=3) else: # Without LUT: I1, I2, I3 self.uni_conv = conv7x7(3*in_c, in_dim, 2, padding=3) self.res_1 = BasicBlock(inplanes=in_dim, planes=in_dim) self.res_2 = BasicBlock(inplanes=in_dim, planes=in_dim) def forward(self, IMGS): if self.w_lut: adapter = torch.cat([self.conv_1(IMGS[0]), self.conv_2(IMGS[1]), self.conv_3(IMGS[2]), self.conv_4(IMGS[3])], dim=1) else: adapter = torch.cat([self.conv_1(IMGS[0]), self.conv_2(IMGS[1]), self.conv_3(IMGS[2])], dim=1) adapter = self.uni_conv(adapter) adapter = self.res_1(adapter) adapter = self.res_2(adapter) return adapter -
生成模型级适配器,将输入级适配器的输出特征进行融合和转换,以更好地适配预训练模型。
IMGS:一个包含多个图像张量的列表,根据w_lut的值,列表长度可能为 3 或 4。每个张量的形状为(B, C, H, W)。adapter:形状为(B, in_dim, H', W')的适配器张量,其中H'和W'是经过卷积操作后的高度和宽度。 -
特征融合块(Feature Merge Block),ECCV_RAW_Adapter/mmdetection_github/mmdet/models/backbones/RAW_Adapter/model_adapter.py
-
# Feature Merge Block class Merge_block(BaseModule): def __init__(self, fea_c, ada_c, mid_c, return_ada=True): super(Merge_block, self).__init__() self.conv_1 = conv1x1(fea_c+ada_c, mid_c, 1) self.conv_2 = conv1x1(mid_c, fea_c, 1) self.return_ada = return_ada if self.return_ada: self.conv_3 = conv3x3(mid_c, ada_c*2, stride=2) def forward(self, fea, adapter, ratio=1.0): res = fea fea = torch.cat([fea, adapter], dim=1) fea = self.conv_1(fea) ada = self.conv_2(fea) fea_out = ratio*ada + res if self.return_ada: # return adapter for next level ada = self.conv_3(fea) return fea_out, ada else: return fea_out, None -
将适配器特征和原始特征进行融合,以增强原始特征的表达能力。输入:
fea:形状为(B, fea_c, H, W)的原始特征张量。adapter:形状为(B, ada_c, H, W)的适配器特征张量。ratio:融合比例,默认为 1.0。输出:fea_out:形状为(B, fea_c, H, W)的融合后特征张量。ada:形状为(B, ada_c*2, H', W')的适配器特征张量,仅当return_ada为True时返回。 -
维度变化:输入的
fea和adapter形状为(B, fea_c, H, W)和(B, ada_c, H, W),经过卷积操作后,fea_out的形状保持不变,而ada的形状可能会发生变化,具体取决于return_ada和conv_3的参数。
-
-
通过输入级适配器对 RAW 图像进行预处理,包括去噪、增强、白平衡和颜色校正等操作,可以改善图像的光照和色彩,减少光照和色彩变化对下游任务的影响。模型级适配器将输入级适配器的输出特征进行融合和转换,生成适配器特征,以更好地适配预训练模型。特征融合块将适配器特征和原始特征进行融合,增强原始特征的表达能力,从而提高下游任务(如目标检测和语义分割)的性能。
-
将本文的RAW-Adapter方法融入到自己的计算机视觉任务中,你可以按照以下步骤进行适配和代码调整:
-
RAW-Adapter主要包含三个关键模块:输入级适配器(Input-level Adapter):对输入的 RAW 图像进行预处理,包括去噪、增强、白平衡和颜色校正等操作。模型级适配器(Model-level Adapter):将输入级适配器的输出特征进行融合和转换,生成适配器特征。特征融合块(Feature Merge Block):将适配器特征和原始特征进行融合,增强原始特征的表达能力。
-
确保输入的图像是 RAW 格式,如果不是,需要进行相应的转换。将
RAW-Adapter的模块集成到自己的模型中,通常在特征提取阶段之前或之后。调整RAW-Adapter的参数,如mode、lut_dim、k_size等。在自己的模型类中初始化RAW-Adapter的模块: -
class CustomModel(nn.Module): def __init__(self, ..., light_mode='normal', w_lut=False, lut_dim=32, k_size=3, fea_c_s=[256, 512, 1024], ada_c_s=[24, 48, 96], mid_c_s=[64, 64, 128], merge_ratio=1.0, ...): super(YourModel, self).__init__() # 初始化输入级适配器 self.pre_encoder = Input_level_Adapeter(mode=light_mode, lut_dim=lut_dim, k_size=k_size, w_lut=w_lut) # 初始化模型级适配器 self.model_adapter = Model_level_Adapeter(in_c=3, in_dim=ada_c_s[0], w_lut=w_lut) # 初始化特征融合块 self.merge_1 = Merge_block(fea_c=fea_c_s[0], ada_c=ada_c_s[0], mid_c=mid_c_s[0], return_ada=True) self.merge_2 = Merge_block(fea_c=fea_c_s[1], ada_c=ada_c_s[1], mid_c=mid_c_s[1], return_ada=True) self.merge_3 = Merge_block(fea_c=fea_c_s[2], ada_c=ada_c_s[2], mid_c=mid_c_s[2], return_ada=False) self.merge_blocks = [self.merge_1, self.merge_2, self.merge_3] self.merge_ratio = merge_ratio # Feature Merge Ratio # 初始化自己的模型结构 ... -
在自己的模型的前向传播函数中添加
RAW-Adapter的处理流程: -
def forward(self, x): # 输入级适配器处理 x = self.pre_encoder(x) if self.w_lut: # I1, I2, I3, I4 ada = self.model_adapter([x[0], x[1], x[2], x[3]]) else: # I1, I2, I3 ada = self.model_adapter([x[0], x[1], x[2]]) x = x[-1] # 自己的模型前向传播 x = self.custom_model_layer_1(x) # 特征融合 for i, layer_name in enumerate(self.res_layers): if i <= 2: x, ada = self.merge_blocks[i](x, ada, ratio=self.merge_ratio) x = self.custom_model_layer_i(x) # 自己的模型层 if i in self.out_indices: outs.append(x) return tuple(outs) -
根据自己的任务需求,调整RAW-Adapter的参数:
mode:'normal'用于正常和过曝条件,'low'用于低光照条件。lut_dim:隐式神经查找表的维度,较大的值可以学习更复杂的颜色映射。k_size:去噪内核的大小,在LOD数据集上设置为 9,其他数据集设置为 3。w_lut:是否使用隐式 3D 查找表。fea_c_s、ada_c_s、mid_c_s:分别表示原始特征通道数、适配器特征通道数和中间特征通道数,根据自己的模型结构进行调整。merge_ratio:特征融合比例,控制适配器特征和原始特征的融合权重。 -
在训练和验证过程中,使用调整后的模型进行训练和验证:
-
# 初始化模型 model = CustomModel(...) # 定义损失函数和优化器 criterion = ... optimizer = ... # 训练循环 for epoch in range(num_epochs): for inputs, labels in dataloader: optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 验证 model.eval() with torch.no_grad(): for inputs, labels in val_dataloader: outputs = model(inputs) ...
-
-
RAW文件记录了数码相机传感器的原始信息,同时记录了由相机拍摄所产生的一些原数据如ISO的设置、快门速度、光圈值、白平衡等。RAW是未经处理、也未经压缩的格式,可以把RAW概念化为“原始图像编码数据”或更形象的称为“数字底片”。RAW的文件体积大,传输慢。需要的存储空间更大。同时软件打开RAW的时间较长。RAW的画质很精细,拍出来的照片效果非常的好。在修改照片的时候,能够很好的还原相片图像。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)