Skywork-R1V3-38B论文速读:一种先进的开源视觉 - 语言强化学习模型(VLM、RL)
Skywork-R1V3 技术报告解析
一、引言
Skywork-R1V3 是由 Multimodal Team Skywork AI 开发的一种先进的开源视觉 - 语言模型(VLM),旨在通过强化学习(RL)框架将文本语言模型(LLM)的推理能力迁移到视觉任务中。该模型通过独特的后训练方法,在不需要额外预训练的情况下,显著提升了视觉推理能力,并在多个基准测试中达到了与封闭源代码模型相媲美的性能。
二、数据准备
Skywork-R1V3 的训练数据分为三个阶段:
-
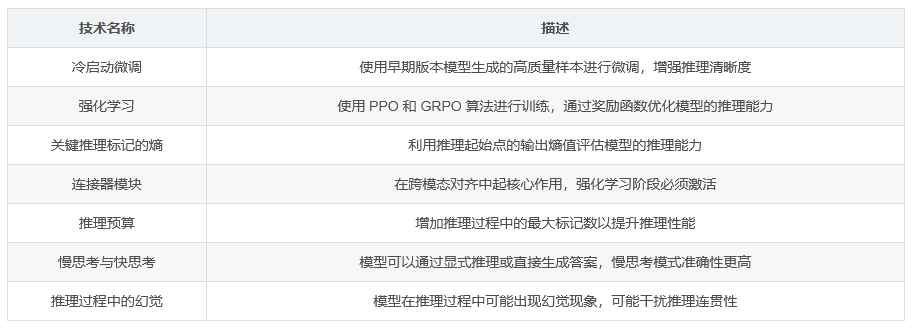
冷启动微调(Cold Start Finetuning):使用约 20K 个来自中国高中难度的科学实践问题实例构建冷启动数据集,涵盖物理、化学、生物和数学四个学科。通过 Skywork-R1V2 模型生成逐步思考过程,并筛选出最终答案与真实答案一致的实例,最终得到约 12K 高质量样本。
-
强化学习(Reinforcement Learning, RL):为 RL 阶段准备了 15K 高质量的 K12 难度的多模态数学数据,包含选择题和填空题,但不包含显式的推理步骤。
-
连接器唯一微调(Connector-Only Tuning):从 20 个不同领域中选取 10K 示例,包括自然科学、工程与应用科学、健康科学、艺术与人文、社会科学等,以确保领域多样性。
三、后训练方法
Skywork-R1V3 的后训练方法主要包括以下几个方面:
-
奖励函数设计(Reward Function Design):奖励函数由格式奖励和准确率奖励组成。格式奖励确保生成的响应符合指定的聊天模板,而准确率奖励是强化学习的主要目标。最终奖励函数为:
R=ϵRaccuracy+(1−ϵ)Rformat
其中,ϵ 设为 0.8,强调准确率的重要性。
-
冷启动微调(Cold Start Finetuning):使用早期版本的 Skywork-R1V2 模型生成的高质量样本进行微调,以增强模型的推理清晰度。Skywork-R1V2 通过直接拼接 InternViT-6B-448px-V2.5 和 QwQ-32B 实现了从文本推理到视觉推理的能力迁移。
-
强化微调(Reinforcement Finetuning):使用近端策略优化(PPO)和分组归一化奖励策略优化(GRPO)算法进行训练。GRPO 通过归一化优势估计,将稀疏的二元奖励信号转换为密集的连续优势估计,为策略学习提供了更丰富的信号。
-
连接器唯一微调(Connector-Only Tuning):在强化学习阶段之后,针对连接器模块进行微调,以重新平衡模型的知识分布,提升跨学科推理能力。
四、评估
Skywork-R1V3 在多个公开的多模态基准测试中进行了评估,涵盖通用视觉 - 语言理解任务和高级多模态推理任务。评估结果显示,Skywork-R1V3 在多个基准测试中达到了开源模型的最高水平,特别是在数学、逻辑和物理推理任务中表现出色。例如,在 MMMU 基准测试中达到了 76.0% 的准确率,在 MathVista 数学推理基准测试中达到了 77.1% 的准确率。
五、实验分析
Skywork-R1V3 的实验分析揭示了强化学习在提升多模态推理能力中的关键作用。主要发现包括:
-
关键推理标记的熵(Critical Token Entropy):在强化学习过程中,模型在推理起始点(如生成 “Wait…” 或 “Alternatively…” 等标记)的输出熵值与实际推理性能高度相关。具有真正推理能力的模型在这些位置通常表现出高熵值,而仅模仿推理模式的模型则表现出低熵值。
-
连接器模块的作用(The Role of Connector Module):连接器模块在跨模态对齐中起着核心作用。在强化学习阶段,连接器的激活是模型稳定学习的必要条件,而视觉编码器的激活则为模型提供了额外的性能提升。
-
课程学习的分布偏移(Curriculum Learning and Distribution Shift):尝试通过从简单到复杂的任务逐步训练模型,但实验表明,这种基于难度的数据切换可能导致分布偏移,反而削弱了模型的泛化能力。
-
学习率策略(Learning Rate Strategy):较高的学习率虽然可以加速早期奖励积累,但可能导致后期训练不稳定,甚至出现模型崩溃。较低的学习率则有助于保持训练的稳定性。
六、讨论
Skywork-R1V3 的研究还探讨了多模态推理模型在推理过程中的行为特点,包括:
-
推理能力的泛化与记忆(Generalization vs. Memorization):强化学习能够激活模型的泛化推理能力,而监督微调(SFT)则可能导致模型仅模仿推理风格,而无法泛化到新的任务。
-
推理速度与准确性(Slow Thinking vs. Fast Thinking):模型在推理过程中可以通过显式的逐步推理(慢思考)或直接生成答案(快思考)。慢思考模式虽然生成较长的输出,但推理准确性更高。
-
推理预算(Thinking Budget):增加推理过程中的最大标记数(推理预算)可以显著提升模型的推理性能,表明足够的推理空间对于模型的推理能力至关重要。
-
推理过程中的幻觉(Hallucination in Reasoning):模型在推理过程中可能会出现幻觉现象(如 “我看不到图像”),这可能会干扰推理过程的连贯性,从而影响模型的性能。
七、结论
Skywork-R1V3 通过强化学习驱动的后训练方法,显著提升了开源多模态推理模型的性能,特别是在数学、逻辑和物理推理任务中表现出色。该模型的成功展示了强化学习在提升视觉 - 语言对齐和推理能力中的巨大潜力,并为未来多模态人工智能系统的发展奠定了基础。
八、核心技术总结

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)