56、使用scikit-learn实现K-Means聚类【用Python进行AI数据分析进阶教程】
用Python进行AI数据分析进阶教程56:
使用scikit-learn实现K-Means聚类
关键词:K-Means聚类、scikit-learn、数据预处理、肘部法则、轮廓系数法
摘要:本文介绍了如何使用scikit-learn库实现K-Means聚类算法。文章首先概述了K-Means聚类的基本概念,随后详细讲解了其关键点,包括聚类数K的选择方法(如肘部法则、轮廓系数法)、初始质心选择(默认为k-means++算法)、距离度量方式(默认为欧几里得距离)以及收敛条件。同时,文章强调了数据预处理(标准化或归一化)、局部最优解的规避(多次运行算法)和异常值处理等注意事项。最后,通过Python示例代码演示了数据生成、标准化、聚类执行及可视化过程,并对重点语句进行了详细解读,帮助读者更好地理解和应用K-Means聚类方法。
👉 欢迎订阅🔗
《用Python进行AI数据分析进阶教程》专栏
《AI大模型应用实践进阶教程》专栏
《Python编程知识集锦》专栏
《字节跳动旗下AI制作抖音视频》专栏
《智能辅助驾驶》专栏
《工具软件及IT技术集锦》专栏
一、概述
K-Means 聚类是一种广泛使用的无监督学习算法,用于将数据点划分为不同的簇(cluster)。在 Python 中,scikit-learn 库提供了方便的 K-Means 类来实现 K-Means 聚类。以下将详细介绍使用 scikit-learn 实现K-Means聚类的关键点、注意点、示例代码及重点语句解读。
二、关键点
- 聚类数 K 的选择:K 值决定了最终聚类的数量,需要根据数据特点和业务需求来选择。常见的方法有肘部法则、轮廓系数法和间隙统计量法等。
- 初始质心的选择:scikit-learn 中的 K-Means 类默认使用 k-means++ 算法来初始化质心,该算法可以使初始质心尽可能地分散,减少陷入局部最优解的可能性。
- 距离度量:K-Means 类默认使用欧几里得距离来计算数据点之间的距离,也可以根据具体需求选择其他距离度量方法。
- 收敛条件:K-Means 算法通过迭代更新质心,直到满足收敛条件(如质心不再变化或达到最大迭代次数)为止。
三、注意点
- 数据预处理:在进行K-Means聚类之前,需要对数据进行预处理,如标准化或归一化,以确保不同特征具有相同的尺度,避免某些特征对聚类结果产生过大影响。
- 局部最优解:K-Means算法容易陷入局部最优解,因此可以多次运行算法,选择最优的聚类结果。
- 异常值处理:异常值可能会对聚类结果产生较大影响,在进行聚类之前,需要对异常值进行处理。
四、示例代码
Python脚本
# 导入 numpy 库,它是 Python 中用于科学计算的基础库,
# 提供了高效的多维数组对象和处理这些数组的工具
import numpy as np
# 导入 matplotlib 库中的 pyplot 模块,用于创建各种静态、交互式的可视化图表
import matplotlib.pyplot as plt
# 从 sklearn 库的 cluster 模块中导入 KMeans 类,
# KMeans 是一种常用的聚类算法,用于将数据点划分为不同的簇
from sklearn.cluster import KMeans
# 从 sklearn 库的 datasets 模块中导入 make_blobs 函数,
# 该函数用于生成聚类分析所需的样本数据
from sklearn.datasets import make_blobs
# 从 sklearn 库的 preprocessing 模块中导入 StandardScaler 类,
# 用于对数据进行标准化处理,使数据具有零均值和单位方差
from sklearn.preprocessing import StandardScaler
def generate_sample_data():
"""
生成示例数据
"""
# 调用 make_blobs 函数生成样本数据
# n_samples=300 表示生成 300 个样本点
# centers=4 表示生成 4 个聚类中心
# cluster_std=0.60 表示每个簇的标准差为 0.60
# random_state=0 是随机数种子,保证每次运行代码生成的数据相同
# [0] 表示只取生成数据的特征矩阵,忽略标签信息
return make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)[0]
def preprocess_data(X):
"""
对数据进行标准化预处理
:param X: 原始数据集
:return: 标准化后的数据集
"""
# 创建一个 StandardScaler 对象,用于对数据进行标准化处理
scaler = StandardScaler()
# 使用 fit_transform 方法对数据集 X 进行拟合和转换
# 拟合过程计算数据集的均值和标准差,
# 转换过程使用这些统计量将数据转换为具有零均值和单位方差的形式
return scaler.fit_transform(X)
def perform_kmeans_clustering(X, n_clusters=4):
"""
执行 K-Means 聚类
:param X: 数据集
:param n_clusters: 聚类数量
:return: 聚类标签和簇质心
"""
try:
# 创建一个 KMeans 聚类模型,n_clusters 参数指定要划分的簇的数量,这里默认为 4
# random_state=0 保证每次运行 KMeans 算法的初始状态相同,结果可复现
kmeans = KMeans(n_clusters=n_clusters, random_state=0)
# 使用 fit 方法对数据集 X 进行拟合,即让 KMeans 算法学习数据的分布并进行聚类
kmeans.fit(X)
# 获取每个样本所属的簇的标签,labels_ 是 KMeans 模型的属性,
# 存储了每个样本的聚类结果
labels = kmeans.labels_
# 获取每个簇的质心坐标,cluster_centers_ 是 KMeans 模型的属性,
# 存储了每个簇的中心点
centroids = kmeans.cluster_centers_
# 返回聚类标签和簇质心
return labels, centroids
except Exception as e:
# 如果在聚类过程中出现异常,打印错误信息,提示在 K-Means 聚类过程中出现了问题
print(f"K-Means 聚类过程中出现错误: {e}")
# 返回 None 表示聚类失败
return None, None
def visualize_clustering(X, labels, centroids):
"""
可视化聚类结果
:param X: 数据集
:param labels: 聚类标签
:param centroids: 簇质心
"""
# 检查聚类标签和簇质心是否为 None,如果为 None 说明聚类失败,直接返回,不进行可视化
if labels is None or centroids is None:
return
# 使用 scatter 函数绘制数据集的散点图,
# X[:, 0] 表示数据集的第一个特征,X[:, 1] 表示第二个特征
# c=labels 表示根据聚类标签对数据点进行颜色编码,不同的簇用不同的颜色表示
# s=50 表示散点的大小,cmap='viridis' 是颜色映射,用于指定不同标签对应的颜色
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
# 绘制每个簇的质心,同样使用 scatter 函数,
# centroids[:, 0] 和 centroids[:, 1] 分别表示质心的 x 和 y 坐标
# c='red' 表示质心用红色表示,s=200 表示质心的散点大小,alpha=0.5 表示质心散点的透明度
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=200, alpha=0.5)
# 设置图表的标题为 'K-Means Clustering'
plt.title('K-Means Clustering')
# 设置 x 轴的标签为 'Feature 1',表示第一个特征
plt.xlabel('Feature 1')
# 设置 y 轴的标签为 'Feature 2',表示第二个特征
plt.ylabel('Feature 2')
# 在图表中添加网格线,方便观察数据点的分布
plt.grid(True)
# 自动调整图表的布局,确保标签、标题等元素不会相互重叠
plt.tight_layout()
# 显示绘制好的图表
plt.show()
if __name__ == "__main__":
# 调用 generate_sample_data 函数生成示例数据集
X = generate_sample_data()
# 调用 preprocess_data 函数对生成的数据集进行标准化预处理
X_scaled = preprocess_data(X)
# 调用 perform_kmeans_clustering 函数对标准化后的
# 数据集进行 K-Means 聚类,得到聚类标签和簇质心
labels, centroids = perform_kmeans_clustering(X_scaled)
# 调用 visualize_clustering 函数将聚类结果进行可视化展示
visualize_clustering(X_scaled, labels, centroids)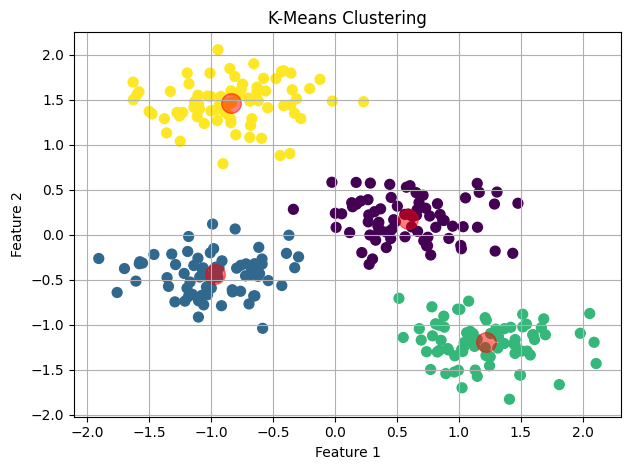
输出 / 打印结果注释
- 正常情况:若代码运行过程中没有出现异常,不会有控制台打印输出。程序会弹出一个窗口,显示一个散点图。在这个散点图里,不同颜色的点代表不同的簇,红色的半透明大点代表每个簇的质心。从图中可以直观地看到数据被划分成了 4 个簇,并且能看到每个簇的大致位置和分布情况。
- 异常情况:如果在 perform_kmeans_clustering 函数执行期间出现异常(例如数据格式有误、内存不足等),控制台会打印出错误信息,格式为 K-Means 聚类过程中出现错误: {e},其中 {e} 是具体的错误信息。此时不会弹出可视化窗口,因为聚类失败没有有效的聚类标签和质心数据用于可视化。
重点语句解读
1、数据生成:
Python脚本
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)- make_blobs 函数用于生成聚类分析所需的示例数据。
- n_samples=300 表示生成 300 个样本。
- centers=4 表示生成 4 个聚类中心。
- cluster_std=0.60 表示每个聚类的标准差为 0.60。
- random_state=0 用于固定随机种子,保证结果可复现。
2、数据标准化:
Python脚本
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)- StandardScaler 类用于对数据进行标准化处理,使数据的均值为 0,标准差为 1。
- fit_transform 方法用于拟合数据并进行转换。
3、创建 KMeans 模型:
Python脚本
kmeans = KMeans(n_clusters=4, random_state=0)- n_clusters=4 表示指定聚类的数量为 4。
- random_state=0 用于固定随机种子,保证结果可复现。
4、拟合模型:
Python脚本
kmeans.fit(X_scaled)- fit 方法用于使用标准化后的数据 X_scaled 来训练 KMeans 模型。
5、获取聚类标签和簇质心:
Python脚本
labels = kmeans.labels_
centroids = kmeans.cluster_centers_- labels_ 属性用于获取每个样本的聚类标签。
- cluster_centers_ 属性用于获取每个聚类的质心坐标。
6、可视化聚类结果:
Python脚本
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=labels, s=50, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=200, alpha=0.5)- 第一个 scatter 函数用于绘制标准化后的数据点,c=labels 表示根据聚类标签进行颜色编码。
- 第二个 scatter 函数用于绘制聚类的质心,c='red' 表示质心的颜色为红色。
通过以上步骤,你可以使用 scikit-learn 实现K-Means聚类,并可视化聚类结果。
——The END——
🔗 欢迎订阅专栏
| 序号 | 专栏名称 | 说明 |
|---|---|---|
| 1 | 用Python进行AI数据分析进阶教程 | 《用Python进行AI数据分析进阶教程》专栏 |
| 2 | AI大模型应用实践进阶教程 | 《AI大模型应用实践进阶教程》专栏 |
| 3 | Python编程知识集锦 | 《Python编程知识集锦》专栏 |
| 4 | 字节跳动旗下AI制作抖音视频 | 《字节跳动旗下AI制作抖音视频》专栏 |
| 5 | 智能辅助驾驶 | 《智能辅助驾驶》专栏 |
| 6 | 工具软件及IT技术集锦 | 《工具软件及IT技术集锦》专栏 |
👉 关注我 @理工男大辉郎 获取实时更新
欢迎关注、收藏或转发。
敬请关注 我的
微信搜索公众号:cnFuJH
CSDN博客:理工男大辉郎
抖音号:31580422589

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 40
40 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)