深度学习中评估指标:准确率Accuracy、召回率Recall、精确率Precision
欠拟合是指模型的复杂度小于真实的复杂度,模型不能够表达真实的情况,这可以通过增加模型的复杂度或增加训练数据来解决。过拟合则是指模型的复杂度大于真实的复杂度,模型在训练数据上表现很好,但在测试数据上表现很差,这可以通过使用更简单的模型、增加数据量、使用正则化技术等方法来解决。TP (True Positive):表示实际为正例,判定也为正例的次数,即表示判定为正例且判定正确的次数。在所有正类样本中,
1 问题
(1)准确率(Accuracy)指标以及如何提升Accuracy
(2)召回率(Recall=TPR)的介绍
(3)精确率(Precision,查准率)的介绍
2 方法
2.1 准确率(Accuracy)
Accuracy(准确率)是一个用于评估分类模型的指标。通俗来说,准确率是指我们的模型预测正确的结果(包括正例和负例)所占的比例。
我们可以用一个公式对其表达:
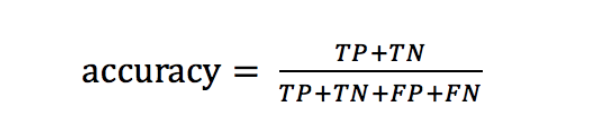
公式中各个参数含义如下:
TP (True Positive):表示实际为正例,判定也为正例的次数,即表示判定为正例且判定正确的次数。
FP (False Positive): 表示实际为负例,却判定为正例的次数,即表示判定为正例但判断错误的次数。
TN (True Negative):表示实际为负例,判定也为负例的次数,即表示判定为负例且判定正确的次数。
FN (False Negative): 表示实际为正例,却判定为负例的次数,即表示判定为负例但判断错误的次数。
判定正确的次数是(TP+TN),所有判定的次数是(TP + TN + FP +FN)
2.1.1 提升Accuracy的方法
主要从算法和数据两个方面提升Accuracy
算法方面:
欠拟合与过拟合检测与处理:首先,需要检测模型是否出现了欠拟合或过拟合。欠拟合是指模型的复杂度小于真实的复杂度,模型不能够表达真实的情况,这可以通过增加模型的复杂度或增加训练数据来解决。过拟合则是指模型的复杂度大于真实的复杂度,模型在训练数据上表现很好,但在测试数据上表现很差,这可以通过使用更简单的模型、增加数据量、使用正则化技术等方法来解决。
集成学习方法:使用集成学习方法,如bagging、boosting或stacking,可以将多个模型的预测结果组合起来,从而获得更好的预测效果。
深度学习模型优化:对于深度学习模型,可以使用一些优化算法,如梯度下降、随机梯度下降、动量梯度下降等来优化模型参数,以提高模型的预测准确率。
使用激活函数:在神经网络中,激活函数用于增加模型的非线性,以提高模型的表达能力。常用的激活函数包括sigmoid、tanh、ReLU等。
正则化和dropout:正则化可以通过在损失函数中增加一个正则项来惩罚模型的复杂度,从而防止过拟合。dropout则是在训练过程中随机地暂时关闭一部分神经元,以增加模型的泛化能力。
数据方面:
数据清洗:清理和预处理数据是提高模型准确率的非常重要的步骤。需要处理缺失值、异常值、删除重复数据等。
数据扩增:对于小样本数据集,可以使用数据扩增方法来增加数据量。例如在图像分类任务中,可以通过旋转、平移、缩放等方式来增加图片的多样性。
数据增强:通过一些方式改变输入数据,以产生更多的训练样本。例如在音频识别任务中,可以通过改变音频的音调、音量等来产生更多的训练样本。
领域适应:如果目标领域与源领域分布差异较大,可以采用领域适应方法来提高模型在目标领域的表现。例如,可以使用自适应学习率、原型迁移等方法。
2.2召回率(Recall=TPR)
在所有正类样本中,被正确识别为正类别的比例是多少,通俗讲,识别出来的正类(预测的)占实际正类中的比例。
在信息检索领域,召回率又被查全率。
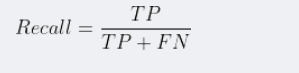
2.3精确率(Precision,查准率)
在预测为正类的样本中,实际上属于正类的样本所占的比例。 在信息检索领域,精确率又被称为查准率。
注意:精确率和准确率不是一个东西,请大家注意不要搞混了!
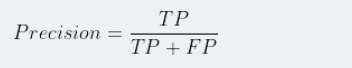
3 结语
深度学习中的评估指标是用来衡量模型性能的指标,它们可以帮助我们了解模型在不同任务上的表现。常见的评估指标包括准确率、精确率、召回率、F1值等。除了这些常见的评估指标,还有一些针对特定任务的评估指标,比如在目标检测任务中常用的AP(Average Precision)和mAP(mean Average Precision)等。
在深度学习中,评估指标的选择应该根据具体任务和数据集来确定。同时,评估指标的选择也会影响到模型的训练和优化策略。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)