【RL强化学习】Actor-Critic Methods
·
核心要领
- 状态价值函数取决于两部分π(a∣s)\pi(a|s)π(a∣s)和Qπ(s,a)Q_{\pi}(s,a)Qπ(s,a)
- 故训练两个网络,Policy Network(actor)用于决策,Value Network(critic)用于判断这个决策的好坏
- critic网络用梯度下降最小化与real Qπreal\ Q_{\pi}real Qπ之间的Loss,actor网络用梯度上升最大化VπV_{\pi}Vπ
- 计算VπV_{\pi}Vπ离不开QπQ_{\pi}Qπ,因此通常先算critic网络,再算actor网络,且critic网络的学习率通常来说会更大一些
Value Network(Critic)的内部结构
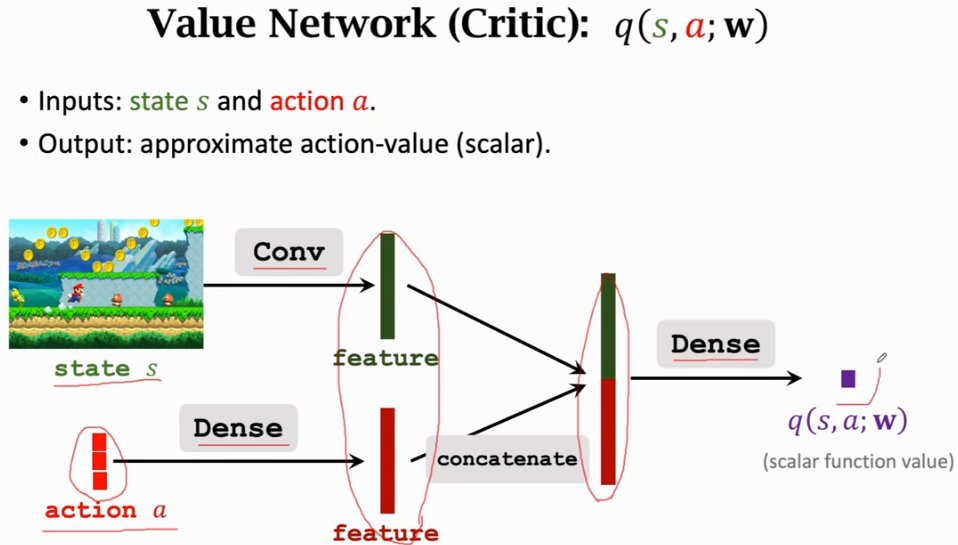
需要注意的是
Critic network和DQN完全不同
- 前者学的是当前策略 π 下的VπV_{\pi}Vπ或QπQ_{\pi}Qπ,Bootstrap时用的是策略生成的下一个动作。
- 后者学的是最优Q⋆Q_{\star}Q⋆,使用“最大化下步 Q 值”的贝尔曼最优方程
但是二者训练方法类似,都可以用n-step TD算法来更新网络参数
- 当前状态为sts_tst,并执行决策ata_tat,得到新状态st+1s_{t+1}st+1,根据新状态再决策at+1a_{t+1}at+1但不执行
- 根据qt=q(st,at;w)q_t=q(s_t,a_t;w)qt=q(st,at;w)计算得到当前时刻和下一时刻的qt qt+1q_t\ \ q_{t+1}qt qt+1
- 计算TD target:yt=rt+γ⋅qt+1y_t=r_t+\gamma \cdot q_{t+1}yt=rt+γ⋅qt+1,我们可以认为yty_tyt是一个常量,它类似于监督学习中qtq_tqt的标签
- 计算Loss:L(w)=12[qt−yt]2L(w)=\frac{1}{2}[q_t-y_t]^2L(w)=21[qt−yt]2(用其他loss function也可以)
- 梯度下降:wt+1=wt−α⋅∂L(w)∂w∣w=wtw_{t+1}=w_t-\alpha \cdot \frac{\partial L(w)}{\partial w}\mid_{w=w_t}wt+1=wt−α⋅∂w∂L(w)∣w=wt
其中∂L(w)∂w=(qt−yt)⋅∇wqt\frac{\partial L(w)}{\partial w}=(q_t-y_t)\cdot \nabla_w q_t∂w∂L(w)=(qt−yt)⋅∇wqt
实际训练流程
具体流程:
1. 收集当前状态
2. 根据现有策略做决策的随机采样,得决策a^\hat{a}a^
3. 执行决策a^\hat{a}a^,得到新状态和奖励
4. 用奖励执行TD算法更新Critic network的参数
5. 将Critic network的输出qπq_{\pi}qπ,代入公式g(a^,θ)=∇logπ(a^∣St)⋅qπ(St,a^)g(\hat{a},\theta)=\nabla log \pi(\hat{a}|S_t)\cdot q_{\pi}(S_t,\hat{a})g(a^,θ)=∇logπ(a^∣St)⋅qπ(St,a^),用梯度上升θt+1=θt+β⋅g(a^,θt)\theta_{t+1}=\theta_t+\beta \cdot g(\hat{a},\theta_t)θt+1=θt+β⋅g(a^,θt)更新actor network的参数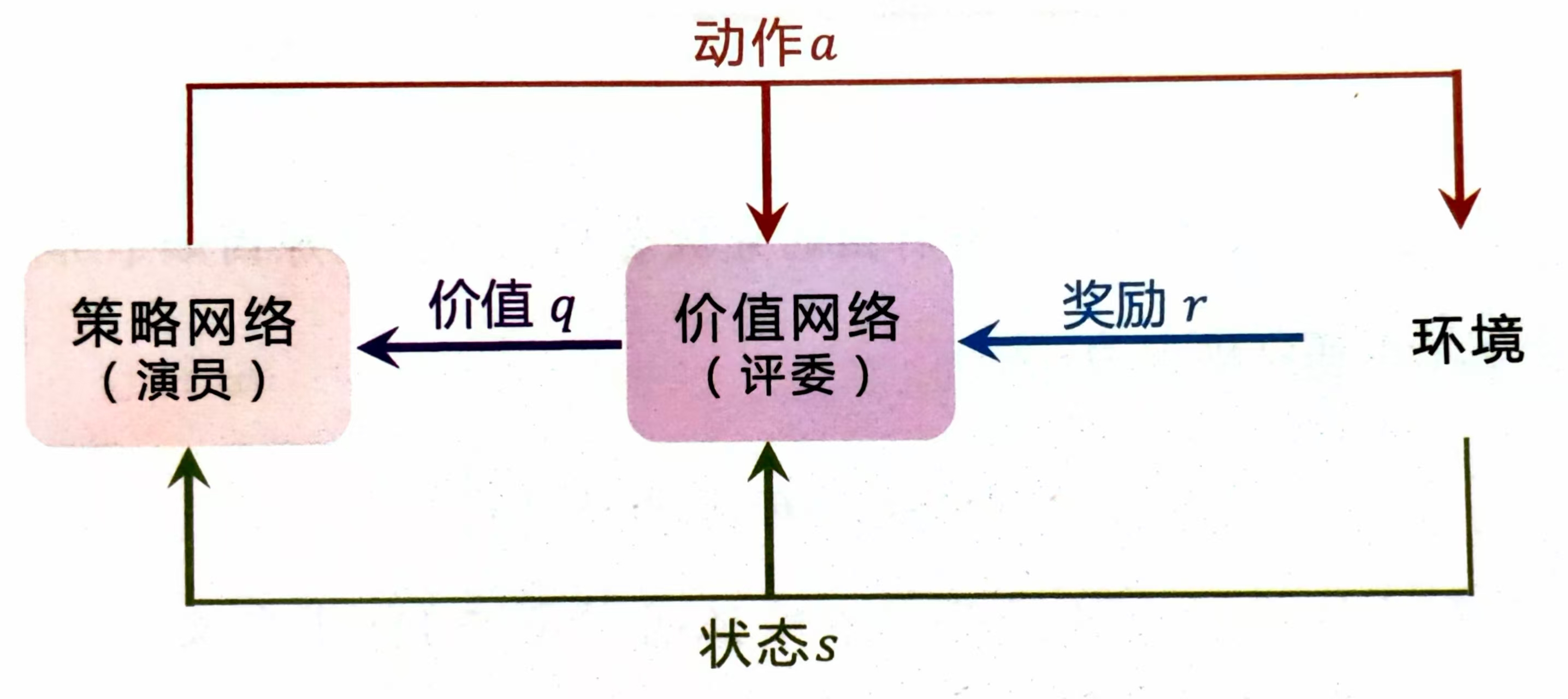

上图来自王树森老师的《深度强化学习》

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)