模型训练可视化、验证、评估
但因为wandb.ai需要收费,所以推荐使用Pytorch官网提供的Tensor Boadr。2.获取数据,得到预测值:out ,大小为[64,10],类型为tensor表示 每次取出64条数据,共10种类型。通过生成csv文件,直观的感受预测值与真实值是否都匹配,从而验证模型建立的好快。1.创建一个空的二维numpy(),列表与预期想要的csv列数相同,行数为0。将预测值和真实值通过混淆矩阵的方
一、模型训练可视化
模型训练可视化可以通过wandb.ai或Tensor Board完成。但因为wandb.ai需要收费,所以推荐使用Pytorch官网提供的Tensor Boadr。
1.1准备工作
导入tensorboard操作模块
from torch.utils.tensorboard import SummaryWriter
指定tensorboard日志保存路径:可以指定多个实例对象
dir = os.path.dirname(__file__)
tbpath = os.path.join(dir, "tensorboard")
# 指定tensorboard日志保存路径
writer = SummaryWriter(log_dir=tbpath)
1.2 保存训练过程曲线
记录训练数据
# 记录训练数据到可视化面板
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", acc, epoch)
模型训练后关闭
writer.close()
1.3 查看保存的曲线图
安装:pip install tensorboard
在训练完成后,查看训练结果,在当前目录下,打开控制台窗口:
tensorboard --logdir=runs
控制台会提示一个访问地址,用浏览器直接访问即可。

点击http://localhost:6006/后进入可视化界面
具体使用案例:
writer = SummaryWriter()
for epoch in range(epochs):
acc_total = 0
total_loss = 0
for i,(x,y) in enumerate(data_loader):
x, y = x.to(device), y.to(device)
out = model(x)
out1 = torch.argmax(out, dim=1)
acc_total += (out1 == y).sum().item()
loss = loss_fn(out, y)
total_loss += loss.item()
opt.zero_grad()
loss.backward()
opt.step()
torch.save(model.state_dict(),model_dir)
print("epoch:",epoch,"loss:",total_loss/len(data_loader.dataset),'acc:',acc_total/len(data_loader.dataset))
#将平均每个样本的损失值变化可视化
writer.add_scalar("loss/train",total_loss/len(data_loader.dataset),epoch)
#将平均每个样本的准确率变化可视化
writer.add_scalar("acc/train",acc_total/len(data_loader.dataset),epoch)效果如下:
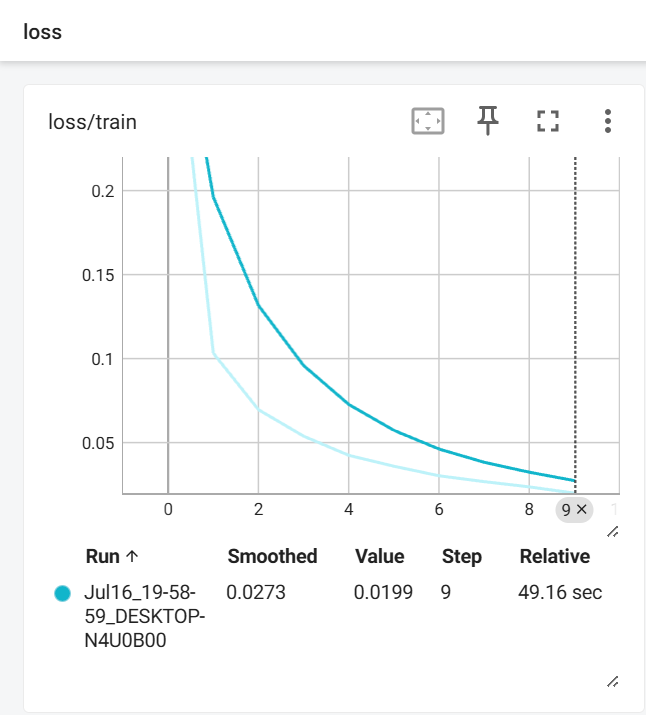
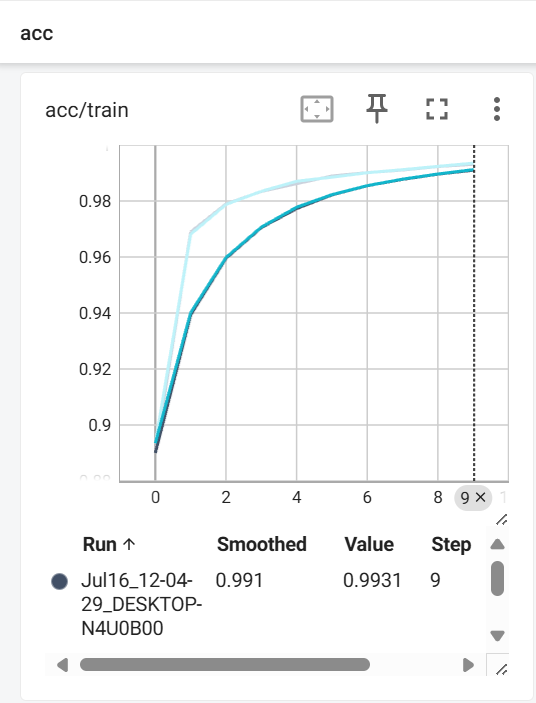
二、模型的验证
通过生成csv文件,直观的感受预测值与真实值是否都匹配,从而验证模型建立的好快。
创建csv文件的步骤:
1.创建一个空的二维numpy(),列表与预期想要的csv列数相同,行数为0

2.获取数据,得到预测值:out ,大小为[64,10],类型为tensor表示 每次取出64条数据,共10种类型
for x ,y in val_dataloader:
x = x.to(device)
y = y.to(device)
out = model(x)3.类型转换, 因为:创建csv文件一般使用numpy类型
'''
类型转换
预测值数据[64,10]
pred = torch.detach(out).cpu().numpy() ->numpy类型
detach->返回一个不需要计算梯度的张量
.cpu()-> 将张量从GPU转到CPU上,因为NumPy数组只能在CPU上处理
.numpy()转换为numpy类型
[64]
p1 = torch.argmax(out,dim=1) ->torch类型
p2 =p1.unsqueeze(1).detach().cpu().numpy()
真实值:
label = y.unsqueeze(1).detach().cpu().numpy()
'''
pred = torch.detach(out).cpu().numpy()
#[64]
p1 = torch.argmax(out, dim=1)
#
p2 = p1.unsqueeze(axis=1).detach().cpu().numpy()
label = y.unsqueeze(axis=1).detach().cpu().numpy()4.拼接
batch_data = np.concatenate((pred,p2,label), axis=1)
total_data = np.concatenate((total_data,batch_data),axis=0)5.创建csv文件
#将数据集的类别存入class_names中
class_names = env_dataset.classes
#构建csv的第一行,即列名
pd_column =[*class_names,'pred','label']
#选择文件生成的路径
csv_path = os.path.relpath(os.path.join(os.path.dirname(__file__),'results','results.csv'))
#生成csv文件
pd.DataFrame(total_data,columns=pd_column).to_csv(csv_path,index=False)
完整代码如下:
env_dataset = MNIST(
root=data_dir,
train=False,
transform=transforms,
download=False,
)
total_data = np.empty((0,12))
with torch.no_grad():
for x ,y in val_dataloader:
x = x.to(device)
y = y.to(device)
#预测值数据[64,10]
out = model(x)
#[64,10]
pred = torch.detach(out).cpu().numpy()
#[64]
p1 = torch.argmax(out, dim=1)
#
p2 = p1.unsqueeze(axis=1).detach().cpu().numpy()
label = y.unsqueeze(axis=1).detach().cpu().numpy()
batch_data = np.concatenate((pred,p2,label), axis=1)
total_data = np.concatenate((total_data,batch_data),axis=0)
class_names = env_dataset.classes
#构建csv的第一行,即列名
pd_column =[*class_names,'pred','label']
csv_path = os.path.relpath(os.path.join(os.path.dirname(__file__),'results','results.csv'))
pd.DataFrame(total_data,columns=pd_column).to_csv(csv_path,index=False)三、模型评估
知识点:混淆矩阵
将预测值和真实值通过混淆矩阵的方式进行展示,并由此评估模型的好坏
相关代码:
import pandas as pd
import os
from sklearn.metrics import classification_report
csv_path = os.path.relpath(os.path.join(os.path.dirname(__file__),'results','result.csv'))
# 读取csv
csvdata = pd.read_csv(csv_path,index_col=0)
#拿到真实值
true_labe = csvdata['label'].values
#拿到预测标签
true_pred = csvdata['pred'].values
#根据预测值和真实值生成分类报告
report = classification_report(y_true=true_labe,y_pred=true_pred)
print(report)运行效果:
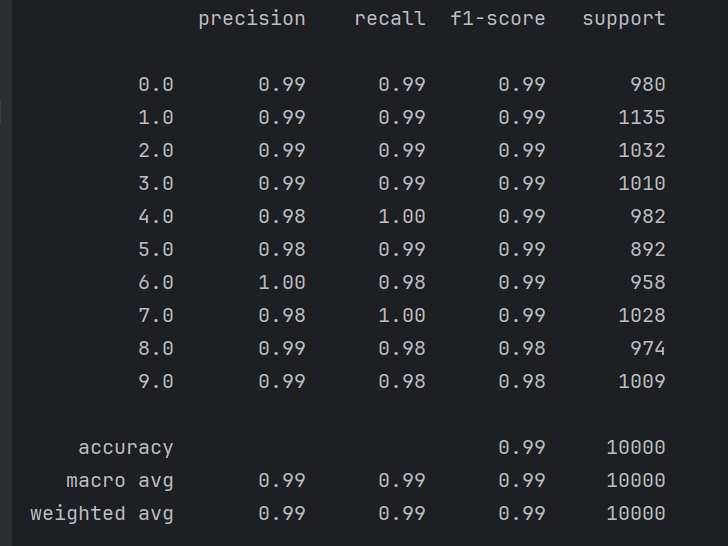
从混淆矩阵可以计算多种评估指标:
准确率(Accuracy) = (TP+TN)/(TP+TN+FP+FN)
精确率/查准率(Precision) = TP/(TP+FP)
召回率/查全率(Recall/Sensitivity) = TP/(TP+FN)
特异度(Specificity) = TN/(TN+FP)
F1分数 = 2×(Precision×Recall)/(Precision+Recall)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)