深度学习中的性能加速利器:深入浅出学习算子融合(Operator Fusion)
算子融合(Operator Fusion)就是将这些连续的、可以合并的算子(BN,RELU)在计算层面上融合成一个“超级算子”。在这个融合的Kernel中,conv_result 和 bn_result 都是存在于GPU核心旁边的极快存储中的临时变量,它们未被写入到位于显卡PCB板上的全局显存颗粒中。:指的是一个基本的操作,比如卷积(Conv2d)、批归一化(BatchNorm2d)、激活函数(R
在深度学习模型日益复杂的今天,模型性能优化变得至关重要。除了算法层面的改进,从计算底层寻找优化空间是提升模型推理速度、降低延迟的关键。算子融合(Operator Fusion)正是这样一种强大而有效的技术。本教程将从基本概念入手,深入剖析其工作原理,并结合 PyTorch 实例讲解。
1.基本概念:
本部分将介绍算子融合的基础知识,如果已具备相关背景,可直接跳至后续章节。
算子(Operator):指的是一个基本的操作,比如卷积(Conv2d)、批归一化(BatchNorm2d)、激活函数(ReLU)等。
内存(Memory):通常指 GPU 的显存(DRAM)。
计算单元(Compute Unit):指 GPU 上的 CUDA核心。
性能瓶颈:现代 GPU 的计算速度极快,但从显存中读取和写入数据的速度相对较慢。对于 Conv -> BN -> ReLU 这样的连续操作,标准流程是:
- 读:从显存读取输入数据。
- 算:执行 Conv 运算。
- 写:将 Conv 的结果写回显存。(conv结束)
- 读:从显存读取 Conv 的结果。
- 算:执行 BatchNorm 运算。
- 写:将 BatchNorm 的结果写回显存。(BN结束)
- 读:从显存读取 BatchNorm 的结果。
- 算:执行 ReLU 运算。
- 写:将最终结果写回显存。(RELU结束)
我们发现发现,这样计算有着大量的“读/写”操作(内存访问)浪费。
算子融合(Operator Fusion)就是将这些连续的、可以合并的算子(BN,RELU)在计算层面上融合成一个“超级算子”。这个超级算子在一次内核启动(Kernel Launch)中,连续执行多个操作,而不需要将中间结果写回全局显存。
于是:Conv -> BN -> ReLU 融合后就变成了 ConvBNReLU:
- 读:从显存读取输入数据。
- 算:在计算单元内部,依次完成 Conv、BN、ReLU 的所有计算。
- 写:将最终结果一次性写回显存。
2.算子融合的优势:
- 减少内存访问:这是最核心的优势,显著降低数据搬运延迟。
- 减少计算内核启动开销:每次调用一个独立的算子都需要一次 GPU 内核启动,这本身也有开销。融合后,多次启动变为一次。
- 提升缓存利用率:数据在计算单元的缓存(SRAM)中被连续使用,效率更高。
3. 融合的原理:
这部分内容会稍微硬核一些,涉及计算机体系结构和编译器的一些基本概念。如果不是想要特别深入的了解,可以跳过。要理解融合为何有效,首先必须理解现代计算硬件(尤其是GPU)的性能瓶颈。
GPU的两个核心指标:
1.计算能力 (Compute Power / FLOPS):指GPU每秒能执行的浮点运算次数。这个指标增长得非常快,得益于更多的计算核心和更高的时钟频率。
2.显存带宽 (Memory Bandwidth):指GPU每秒能从其全局显存(VRAM)中读取或写入数据的总量。这个指标的增长速度远远落后于计算能力的增长。
这种不平衡导致了所谓的 “内存墙” (Memory Wall) 问题:GPU的计算核心常常因为等待数据从缓慢的显存中传来而处于空闲状态。 换句话说,计算核心再大,显存带宽太小,也跑不快。
我们将深度学习中的算子(Operator)分为两类:
1.计算密集型 (Compute-Bound):算子的计算量远大于其数据读写量。例如,大型矩阵乘法或大通道数的卷积。对于这类算子,性能主要取决于GPU的计算能力。
2.访存密集型 (Memory-Bound):算子的数据读写量远大于其计算量。例如,ReLU, Add, BatchNorm, Dropout 等元素级(Element-wise)操作。对于这类算子,性能主要受限于显存带宽。
残差模块中的 BatchNorm 和 ReLU 就是典型的访存密集型算子。它们本身的计算非常简单,但它们需要将整个特征图(Feature Map)从显存读入,计算完后再写回显存。这个过程的耗时主要花在了数据搬运上,而不是计算上。
算子融合的根本目标就是最小化与全局显存(Global Memory)的交互次数。它通过将多个连续的算子合并成一个单一的、更大的GPU计算任务(称为一个 Kernel)来实现这一点。
我们用一个生动的“工厂流水线”比喻来解释:
场景一:未融合的流水线(Eager Mode)
一条流水线,有三个工人(Kernel):
1.工人A (Conv2d):从一个巨大的仓库(全局显存)里取来原材料(输入Tensor),进行卷积加工,然后将半成品放入仓库的另一个货架上。
2.工人B (BatchNorm2d):等工人A完成后,他再去仓库的那个货架上,把半成品取出来,进行标准化处理,处理完再放回仓库的新货架。
3.工人C (ReLU):等工人B完成后,他再去仓库把处理过的半成品取出来,进行激活操作,最后把成品放回仓库。
问题:
- 往返仓库的耗时 (Memory Access Latency):每次去仓库取货、放货都非常耗时。这是主要的性能瓶瓶颈。
- 任务启动的开销 (Kernel Launch Overhead):每次调度一个工人开始工作,都需要一套启动指令和准备工作。当任务本身很简单时(比如ReLU),这个启动开销就显得很浪费。
这就是PyTorch默认的Eager模式的执行方式。每个nn.Module的forward调用都是一次独立的Kernel启动和一次完整的数据读写循环。
现在,我们把这三个工人换成一个连接在一条流水线上变成一组工人(Fused Kernel)。
一组工人(Fused Conv-BN-ReLU Kernel):
1.一次性从仓库(全局显存)里取来原材料(输入Tensor)。
2.工作台上(GPU片上高速缓存,如寄存器/L1 Cache),连续完成三道工序:卷积 -> 标准化 -> 激活。
关键:卷积产生的中间结果,没有放回仓库,而是直接递给了下一步的标准化处理。标准化的结果也没有放回仓库,而是立即用于激活。这些中间数据一直在高速工作台上流转。
所有工序完成后,才将最终的成品一次性放回仓库(全局显存)。
优化后:
数据局部性 (Data Locality):中间数据在GPU芯片内部极高速的缓存中,避免了与缓慢的全局显存进行的往返交互。这是性能提升的最主要来源。
减少启动开销:从三次任务启动减少到一次,降低了CPU与GPU之间的通信开销。
4.融合的方法:
以卷积残差模块为例:
我们来看一个标准的残差模块,它包含一个卷积分支和一个恒等映射identity(或1x1卷积)分支。我们主要关注其核心的卷积分支: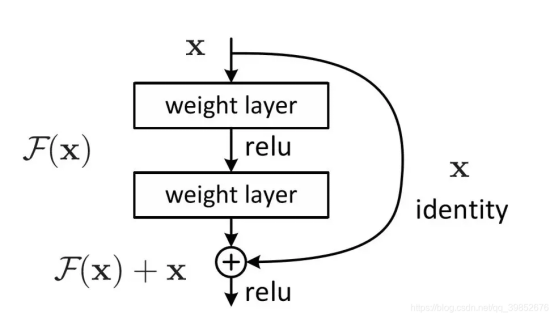
代码如下:
import torch
import torch.nn as nn
# 一个典型的卷积 -> BN -> ReLU 序列
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
super().__init__(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 残差模块
class ResidualBlock(nn.Module):
def __init__(self, channels):
super().__init__()
self.conv_branch = ConvBNReLU(channels, channels)
# 加上残差连接
# self.shortcut = nn.Identity() # 恒等映射
def forward(self, x):
out = self.conv_branch(x)
residual = x
out += residual
return out在forward函数中,计算流是: Input -> Conv2d -> BatchNorm2d -> ReLU -> Add -> Output
未经优化的执行流程:
- Kernel 1 (Conv2d): 读取Input,计算卷积,结果Conv_Out写入显存。
- Kernel 2 (BatchNorm2d): 读取Conv_Out,计算BN,结果BN_Out写入显存。
- Kernel 3 (ReLU): 读取BN_Out,计算ReLU,结果ReLU_Out写入显存。
- Kernel 4 (Add): 读取ReLU_Out和residual,计算相加,最终结果Output写入显存。
可以看到,中间结果 Conv_Out, BN_Out, ReLU_Out 都被完整地写入和读出了一遍,造成了大量的显存带宽浪费。
在现代PyTorch (2.0及以后版本) 中,实现算子融合最简单、最强大的方式是使用 torch.compile。
torch.compile 是一个即时编译器(Just-In-Time, JIT),它的工作流程大致如下:
- Graph Acquisition (图捕获):torch.compile 使用一个名为 TorchDynamo 的技术来安全地捕获Python代码执行的计算图
- Graph Lowering (图降级):将捕获到的计算图转换成一种更底层的、与硬件无关的中间表示(IR)。
- Graph Compilation (图编译):由后端编译器(如 TorchInductor)接管。TorchInductor会分析这个IR,进行各种优化,其中就包括算子融合。它会智能地识别出像 Conv->BN->ReLU 这样的可融合模式,并将它们合并成一个优化的Kernel。TorchInductor通常会将这些融合后的算子编译成高效的Triton或C++代码。
只需要一行代码,就可以让PyTorch自动完成优化工作。
# 原始模型
model = ResidualBlock(channels=128)
# 使用torch.compile进行优化
optimized_model = torch.compile(model)伪代码逻辑如下:
// Fused Kernel伪代码
__global__ void fused_conv_bn_relu(float* input, float* output, /* other params */) {
// 1. 从全局显存加载一小块输入数据到共享内存(Shared Memory)或寄存器(Registers)
// ... load data ...
// 2. 在片上执行卷积计算
float conv_result = perform_convolution(...);
// 3. 立即用卷积结果进行BN计算,参数(gamma, beta, mean, var)已预先加载
float bn_result = (conv_result - mean) / sqrt(var + epsilon) * gamma + beta;
// 4. 立即用BN结果进行ReLU计算
float relu_result = max(0.0f, bn_result);
// 5. 将最终结果写回全局显存
output[...] = relu_result;
}在这个融合的Kernel中,conv_result 和 bn_result 都是存在于GPU核心旁边的极快存储中的临时变量,它们未被写入到位于显卡PCB板上的全局显存颗粒中。
在推理(Inference/Eval模式) 阶段,融合可以做得更彻底。
BatchNorm层的均值(running_mean)和方差(running_var)是固定的。因此,它的线性运算可以被数学上折叠(Fold) 到前面的卷积层中。
假设我们有一个输入 x,它先经过一个卷积层,再经过一个批标准化(BN)层。
我们来看数学公式:
卷积层 (Conv2d)的计算是:
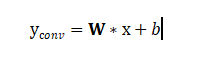
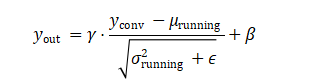
批标准化层 (BatchNorm2d):

第1步:代入
将第一个公式(卷积层输出)代入第二个公式(BN层)中的 y_conv:
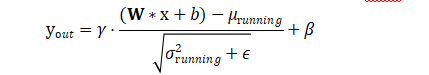
第2步:展开与重新组合
现在,我们对这个公式进行代数变换,把与输入 x 相关和不相关的项分开。
首先,把分母提出来,整理括号里的项:
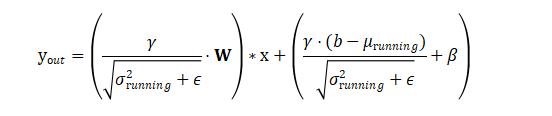
第3步:定义新的权重和偏置
观察上面的公式,它已经变回了 (新权重 * x) + 新偏置 的形式!我们只需要定义:
融合后的新权重 W_fused:
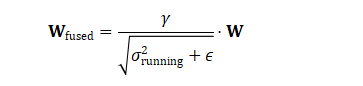
融合后的新偏置 b_fused:
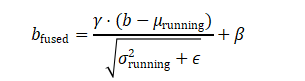
注意:如果原始卷积层没有偏置(bias=False),那么上式中的 b 就当作 0 来计算。
经过融合,原来的 Conv -> BN 两步计算,现在可以被一个单一的、带有新权重和新偏置的卷积层完全等效替代:
yout=Wfused∗x+bfused
在推理时,编译器或部署工具会预先计算好 W_fused 和 b_fused。这样一来,原始的BN层就彻底消失了,它的所有数学作用都被完美地吸收进了卷积层。这不仅减少了一次内存读写和一次Kernel启动,还消除了BN层本身的计算,从而带来显著的加速效果。
5.总结
算子融合是深度学习性能优化的良好方法,它通过将多个操作合并为单一内核,从根本上解决了由内存访问延迟引起的性能瓶颈。
对于日常训练和开发,torch.compile 提供了最便捷、最智能的自动化融合方案。
对于追求极致推理性能的部署场景,手动折叠(如 Conv+BN Folding) 等技术能提供更进一步的优化。
希望本教程能帮助大家更好地理解并应用算子融合技术。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 47
47 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)