计算机毕业设计之基于ECharts的Bilibili排行榜数据可视化平台设计与实现
摘要:本研究设计了一个基于ECharts的Bilibili排行榜数据可视化平台,通过Scrapy爬虫框架采集视频数据,经Pandas数据清洗后实现多维统计。系统包含Up主分析、分类统计等模块,采用模块化设计支持管理员对视频信息进行增删改查操作。平台利用ECharts可视化技术将播放量、弹幕数等数据转化为直观图表,为内容创作者和平台运营提供决策支持。该方案实现了从数据采集、处理到分析展示的全流程,具
本研究设计并实现了一个基于ECharts的Bilibili排行榜数据可视化平台,旨在通过直观、动态的图表展示,深入分析和挖掘Bilibili排行榜数据的价值。平台利用ECharts强大的数据可视化能力,结合数据爬取、存储、处理等技术,实现了播放量、收藏量、分享量、评论数等多维度的数据统计和分析。通过模块化设计,平台提供了Up主分析、时长分析、发布地统计、分类统计、点赞数分析、播放量分析和弹幕数分析等功能模块,满足了不同用户群体的数据需求。
该平台不仅提升了Bilibili数据的可理解性和利用价值,还为内容创作者、平台运营者和普通用户提供了强大的数据支持和决策依据。未来,平台将继续优化数据分析和可视化技术,引入更多数据维度和智能分析功能,拓展应用范围,助力视频行业的数据驱动发展。
系统功能建模
基于ECharts的Bilibili排行榜数据可视化平台设计与实现分为四个主要部分:数据采集、数据处理、数据分析和后台管理。每个部分都有具体的功能模块,如网络爬虫采集通过爬取Bilibili网站的视频数据,数据存储和数据上传属于数据采集阶段;缺失值处理、重复值处理和数据预处理则是数据处理阶段的任务。这些模块协同工作,实现了视频信息的自动化采集、清洗、分析和管理,为视频者提供了个性化和实时的排行榜建议。实现了以下功能模块: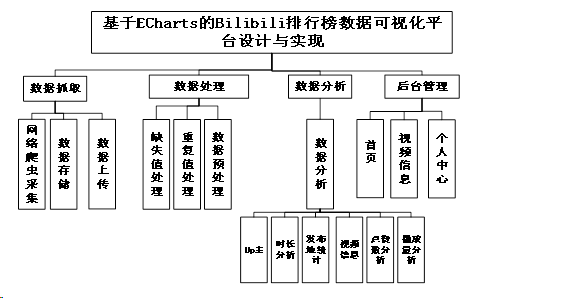
图3-2 系统功能图
管理员在视频信息管理模块中,可以对信息进行查看、修改、删除、新增的操作。
通过数据爬虫技术自动抓取Bilibili网站视频信息,并进行数据清洗以保障信息准确性。模块允许管理员查看视频详情、修改信息、删除记录以及查询。系统提供了友好的操作界面,管理员可轻松编辑信息,而爬虫功能则后台自动运行,确保数据的实时更新和高质量,从而有效支持管理员的日常信息管理工作。
数据爬取采用Python的爬虫框架,Scrapy结合HTTP请求库如Requests,从网站等目标源获取数据。爬取过程中,通过设置合理的爬取频率和遵守robots.txt规则,确保数据获取的合法性和效率。获取原始数据后,进入数据清洗阶段,利用Python的Pandas库对数据进行预处理,包括去除空值、异常值,格式统一,以及处理重复数据。此外,通过正则表达式对文本数据进行清洗,提取有用信息。数据清洗还涉及数据类型转换、缺失值填充等操作,确保数据的质量和一致性。最终,清洗后的数据存储于数据库,为后续的数据分析和业务应用提供准确、可靠的数据基础。如图5-3所示: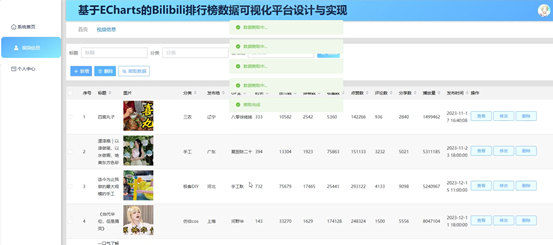
图5-3视频信息管理界面

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)