一文读懂 PPO 算法:强化学习中的 “实用派” 明星—强化学习(11)
目录
如果你想找一个简单、稳定又高效的强化学习算法,PPO(Proximal Policy Optimization)绝对是绕不开的选择。作为 TRPO 的 “简化版”,PPO 保留了核心的 “信任区域” 思想,却用更简单的方式实现了策略的稳定更新,成为学术界和工业界的 “宠儿”。今天我们就来拆解 PPO 的核心逻辑,看看它为何能脱颖而出。
1、PPO 诞生:为了解决 TRPO 的 “复杂病”
1.1、TRPO 的痛点在哪里?
TRPO 通过 “信任区域” 约束策略更新,确实实现了稳定学习,但它有个致命问题:太复杂。TRPO 需要求解带约束的二次规划问题,还得用共轭梯度法计算搜索方向,工程实现难度大,而且计算成本高,很难在大规模场景(如机器人控制、复杂游戏)中落地。
1.2、PPO 的核心思路:用 “惩罚” 代替 “约束”
PPO 的核心创新在于:把 TRPO 的约束条件,转化为目标函数中的惩罚项。简单说,就是不再严格限制 “新旧策略的 KL 散度≤阈值”,而是在目标函数里加入一个 “KL 散度惩罚”—— 如果新旧策略差异太大,就扣减奖励,以此间接约束策略更新幅度。
这种 “化约束为惩罚” 的思路,让 PPO 的实现难度大幅降低,同时保留了 TRPO 的稳定性。
强化学习的核心是让智能体(比如游戏里的角色)通过试错找到最优策略(也就是怎么做能拿高分)。但策略更新是个技术活:步子迈大了,可能直接从 “还行” 变成 “菜鸡”;步子迈小了,学半天没进步。
之前的 TRPO 算法想了个办法:给策略更新加个 “紧箍咒”(叫 “信任区域”),规定新策略不能和旧策略差太远。这招确实稳,但问题是太复杂—— 得用高级数学方法求解,普通程序员根本玩不转。
PPO 的思路就很 “接地气”:把 “紧箍咒” 简化成一个简单的规则,既能稳住策略,又好实现。就像把复杂的密码锁换成了一把简单的挂锁,效果差不多,却方便多了。
2、PPO 的核心:Clip 目标函数
PPO 有两种主流形式:PPO-Penalty(带 KL 惩罚的目标函数)和PPO-Clip(带截断的目标函数)。其中,PPO-Clip因为实现更简单、效果更稳定,成为最常用的版本。
2.1、PPO-Clip 的目标函数长什么样?
这里的关键变量:
:重要性权重(和 TRPO 一样,用旧策略数据评估新策略)。
:优势函数(和 TRPO 相同,衡量动作
的好坏)。
:截断系数(通常取 0.1 或 0.2),用来限制
的范围。
2.2、“截断” 的魔力:既约束又灵活
Clip 函数的作用是把“夹在”
之间。具体来说:
- 当
时,强制取
—— 避免新策略和旧策略差异太大(类似信任区域约束)。
- 当
时,强制取
—— 防止新策略变得比旧策略差太多。
- 当
然后,目标函数取 “原始” 和 “截断后的值” 中的较小者(
),这相当于告诉算法:可以更新策略,但别太 “激进”,也别太 “摆烂”。这种设计既实现了对策略更新的约束,又避免了 TRPO 复杂的二次规划,堪称 “化繁为简” 的典范。
PPO 的关键是那个叫 “Clip”(截断)的小技巧。咱们用个例子理解:
假设智能体之前的策略(旧策略)在某个状态下,有 70% 的概率向左走,30% 向右走。现在要更新策略(新策略),PPO 会说:新策略的概率不能和旧策略差太远。比如规定 “最多差 20%”,那新策略向左的概率就得在 56% 到 84% 之间(70%±20%)。
这个 “划线” 的规则,体现在 PPO 的目标函数里。简单说就是:
新策略可以改,但不能改得太离谱。如果改得太夸张,就 “拉回来” 按上限算;如果改得不如原来,也得有个底线。这么做的好处很明显:既鼓励智能体尝试更好的策略,又防止它一下子 “学废了”,完美平衡了 “探索” 和 “稳定”。
3、PPO 的迭代流程:简单到可以 “暴力更新”
PPO 的流程比 TRPO 简单得多,核心可以概括为 “收集数据→多次更新→重复迭代”,具体步骤如下:
-
用当前策略收集数据 让智能体在环境中执行当前策略
,收集状态、动作、奖励等数据,计算优势函数
-
固定数据,多次更新策略 保持旧策略
对新策略
进行多轮梯度下降(比如 3-10 轮)。 这一步是 PPO 的 “灵魂”:TRPO 每次只能更新一次策略,而 PPO 可以用同一批数据反复更新,大大提高了数据利用率,减少了与环境交互的次数。
-
更新旧策略,重复迭代 当多轮更新完成后,把新策略
PPO 的流程特别好记,就三步,循环往复:
先攒点 “经验”
让智能体用当前的策略去跟环境互动(比如玩几局游戏),记录下每一步的状态(比如游戏画面)、动作(比如按哪个键)、奖励(比如得了多少分),再算出 “优势”—— 也就是这个动作比平均水平好多少。用这些经验 “反复学”
拿到一批经验后,PPO 不着急换新策略,而是用这批经验反复更新很多次(比如 3-10 次)。这就好比做习题:普通算法做一遍就扔,PPO 会把同一套题反复做,直到吃透,大大节省了 “刷题”(和环境互动)的时间。换套 “旧策略”,再来一轮
等这批经验学透了,就把新策略当成下一轮的 “旧策略”,再去攒新经验,重复上面的步骤。直到智能体越来越厉害,比如游戏能通关了,就可以停了。
4、PPO vs TRPO:为什么 PPO 更受欢迎?
| 特性 | TRPO | PPO-Clip |
|---|---|---|
| 核心约束方式 | 严格的 KL 散度约束(约束优化) | 目标函数中加入截断(惩罚机制) |
| 实现难度 | 高(需二次规划、共轭梯度) | 低(普通梯度下降即可) |
| 数据利用率 | 低(一次更新用一批数据) | 高(一批数据可多次更新) |
| 计算成本 | 高 | 低 |
| 稳定性 | 高 | 接近 TRPO |
| 调参难度 | 高(需调整 KL 阈值) | 低(主要调\(\epsilon\)和迭代次数) |
从表格可以看出,PPO 几乎在所有 “实用性” 指标上都优于 TRPO,同时保持了相近的稳定性。这也是为什么 PPO 成为深度强化学习的 “入门首选”—— 无论是训练机器人走路,还是玩 Atari 游戏,PPO 都能快速上手且效果不俗。
和之前的算法(比如 TRPO)比,PPO 的优势简直碾压:
- 简单到能随便实现:不用懂复杂的数学,普通的梯度下降就够用,新手也能上手。
- 省时间又省资源:同一批数据能反复用,不用频繁跟环境互动,训练速度快很多。
- 稳得一批:不管是玩 Atari 游戏还是控制机器人走路,PPO 很少会出现 “越学越差” 的情况,效果还和复杂的 TRPO 差不多。
就像工具里的瑞士军刀,PPO 不一定是某个领域最顶尖的,但啥场景都能应付,还特别顺手,这就是它能火遍学术界和工业界的原因。
5、PPO 的变种:针对不同场景的优化
PPO 并非只有一个版本,研究者在实践中衍生出了几个常用变种:
- PPO-Penalty:直接在目标函数中加入 KL 散度的惩罚项(类似 “
”),通过调整惩罚系数\(\beta\)控制策略更新幅度。但实际中不如 Clip 版本稳定。
- PPO-Clip+Value Function Clipping:在更新价值函数时也加入截断,防止价值函数更新过快,进一步提升稳定性。这是很多开源实现的默认选择。
6、PPO 的调参技巧:让你的模型更快收敛
PPO 虽然简单,但调参仍有讲究,几个关键参数直接影响性能:
- 一批数据的更新次数:推荐 3-10 次。次数太少浪费数据,太多则可能过拟合当前批次数据。
- GAE 的
:一般取 0.95,平衡优势函数的偏差和方差。
- 学习率:建议用衰减学习率(比如从3e-4开始,随迭代减小),避免后期更新震荡。
PPO 虽然简单,但想用好也得注意几个关键参数:
- “划线” 的幅度(ε):一般设 0.1 或 0.2。太小了学太慢,太大了容易乱。
- 同一批数据更几次:3-10 次最合适。太少浪费数据,太多容易 “学傻”(比如只会用这批数据里的套路)。
- 学习率:别太大,一般从 0.0003 开始试,慢慢调小。
7、总结:PPO 为何成为 “顶流”?
PPO 的成功,在于它完美平衡了简单性、稳定性和效率:
- 用 “截断目标函数” 替代 TRPO 的复杂约束,实现了策略的稳定更新;
- 允许同一批数据多次更新,大幅提高了数据利用率;
- 仅需普通梯度下降即可实现,工程落地门槛极低。
理解 PPO 的核心 ——“在保证策略不突变的前提下,用数据高效地更新”,不仅能掌握一个强大的工具,更能体会到强化学习中 “实用主义” 的设计哲学。
说到底,PPO 的核心就是:用最简单的办法,让策略更新既稳又快。它不追求数学上的完美,而是把 “好用” 做到了极致 —— 普通人能实现,效果还顶尖。
8.完整代码
"""
文件名: 12.1
作者: 墨尘
日期: 2025/7/23
项目名: d2l_learning
备注: 这是一个完整的PPO(Proximal Policy Optimization)算法实现,用于训练CartPole环境中的智能体
"""
# 导入必要的库
import gym # 用于创建强化学习环境
import torch # 深度学习框架,用于构建神经网络
import torch.nn.functional as F # 包含各种神经网络函数
import numpy as np # 用于数值计算
import matplotlib.pyplot as plt # 用于绘制训练结果曲线
import rl_utils_1 # 自定义的强化学习工具函数(包含优势函数计算、移动平均等)
# 定义策略网络:用于输出动作的概率分布
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 第一层全连接层
self.fc2 = torch.nn.Linear(hidden_dim, action_dim) # 第二层全连接层,输出动作维度
def forward(self, x):
x = F.relu(self.fc1(x)) # 第一层输出经过ReLU激活
return F.softmax(self.fc2(x), dim=1) # 第二层输出经过softmax,得到动作概率分布
# 定义价值网络:用于估计状态的价值
class ValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim) # 第一层全连接层
self.fc2 = torch.nn.Linear(hidden_dim, 1) # 第二层全连接层,输出状态价值(标量)
def forward(self, x):
x = F.relu(self.fc1(x)) # 第一层输出经过ReLU激活
return self.fc2(x) # 输出状态价值
# 定义PPO算法类,采用截断方式(PPO-Clip)
class PPO:
''' PPO算法,采用截断方式 '''
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
lmbda, epochs, eps, gamma, device):
# 初始化策略网络和价值网络,并移动到指定计算设备(GPU/CPU)
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device)
# 定义优化器,用于更新两个网络的参数
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
# 算法超参数
self.gamma = gamma # 折扣因子,用于计算未来奖励的现值
self.lmbda = lmbda # GAE(广义优势估计)参数,平衡偏差和方差
self.epochs = epochs # 每批数据用于训练的轮数,提高数据利用率
self.eps = eps # 截断参数,控制新旧策略的差异范围(通常取0.1或0.2)
self.device = device # 计算设备(GPU或CPU)
def take_action(self, state):
# 处理状态格式,确保兼容不同环境的返回格式
if isinstance(state, tuple):
state = state[0] # 处理gymnasium环境返回的元组(状态+信息)
if not isinstance(state, np.ndarray):
state = np.array(state) # 确保状态是numpy数组
# 将状态转换为张量并增加批量维度(因为网络期望输入是批量数据)
state_tensor = torch.tensor(state, dtype=torch.float).unsqueeze(0).to(self.device)
# 通过策略网络得到动作概率分布
probs = self.actor(state_tensor)
# 创建分类分布并从中采样动作
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item() # 返回动作的标量值
def update(self, transition_dict):
# 从经验字典中提取数据,并转换为张量格式(适应PyTorch计算)
# 转换前先转为numpy数组,提高效率并避免警告
states = torch.tensor(np.array(transition_dict['states']), dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'], dtype=torch.long).view(-1, 1).to(self.device) # 动作需为长整型
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device) # 奖励
next_states = torch.tensor(np.array(transition_dict['next_states']), dtype=torch.float).to(self.device) # 下一状态
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device) # 终止标志
# 计算TD目标(时序差分目标):当前奖励 + 折扣后的下一状态价值(非终止状态)
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
# 计算TD误差:TD目标与当前状态价值的差
td_delta = td_target - self.critic(states)
# 计算优势函数(使用GAE方法),并移动到计算设备
advantage = rl_utils_1.compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)
# 计算旧策略的对数概率(detach()表示不参与梯度计算,固定旧策略)
old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()
# 多轮训练,充分利用收集到的经验
for _ in range(self.epochs):
# 计算新策略的对数概率
log_probs = torch.log(self.actor(states).gather(1, actions))
# 计算新旧策略的概率比值(指数形式,避免数值问题)
ratio = torch.exp(log_probs - old_log_probs)
# 计算两个损失项:未截断的损失和截断后的损失
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantage # 截断操作,限制策略变化幅度
# 策略损失取两个损失项的最小值的负平均(因为要最大化奖励,所以用负号转为最小化问题)
actor_loss = torch.mean(-torch.min(surr1, surr2))
# 价值损失为均方误差(预测值与TD目标的差)
critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach())) # detach()固定TD目标
# 梯度清零,避免累积
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
# 反向传播计算梯度
actor_loss.backward()
critic_loss.backward()
# 更新网络参数
self.actor_optimizer.step()
self.critic_optimizer.step()
# 主程序:创建环境、初始化智能体并进行训练
if __name__ == '__main__':
# 算法超参数设置
actor_lr = 1e-3 # 策略网络学习率
critic_lr = 1e-2 # 价值网络学习率(通常比策略网络大)
num_episodes = 500 # 训练的总回合数
hidden_dim = 128 # 神经网络隐藏层维度
gamma = 0.98 # 折扣因子
lmbda = 0.95 # GAE参数
epochs = 10 # 每批数据训练轮数
eps = 0.2 # 截断参数
# 选择计算设备(优先使用GPU,没有则用CPU)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
# 处理gym和gymnasium的兼容性问题,自动适应不同版本的环境
try:
# 尝试导入并使用gymnasium(较新的版本)
import gymnasium as gym
env_name = 'CartPole-v1' # gymnasium对应CartPole-v1
env = gym.make(env_name, render_mode=None) # 创建环境,不渲染画面
state, _ = env.reset(seed=0) # 重置环境,固定种子保证实验可复现
except ImportError:
# 如果gymnasium不可用,回退到旧版gym
env_name = 'CartPole-v0' # 旧版gym对应CartPole-v0
env = gym.make(env_name)
state = env.reset(seed=0) # 旧版环境reset只返回状态
# 设置随机种子,确保实验结果可复现
torch.manual_seed(0)
np.random.seed(0)
# 动态获取状态维度和动作维度(适配不同环境)
if isinstance(state, tuple):
state_dim = state[0].shape[0] # 处理gymnasium返回的元组
else:
state_dim = state.shape[0] # 旧版环境返回的状态数组
action_dim = env.action_space.n # 动作空间大小(CartPole为2:左/右)
# 创建PPO智能体
agent = PPO(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda,
epochs, eps, gamma, device)
# 调用工具函数训练智能体,返回每回合的总奖励
return_list = rl_utils_1.train_on_policy_agent(env, agent, num_episodes)
# 绘制学习曲线:每回合的总奖励
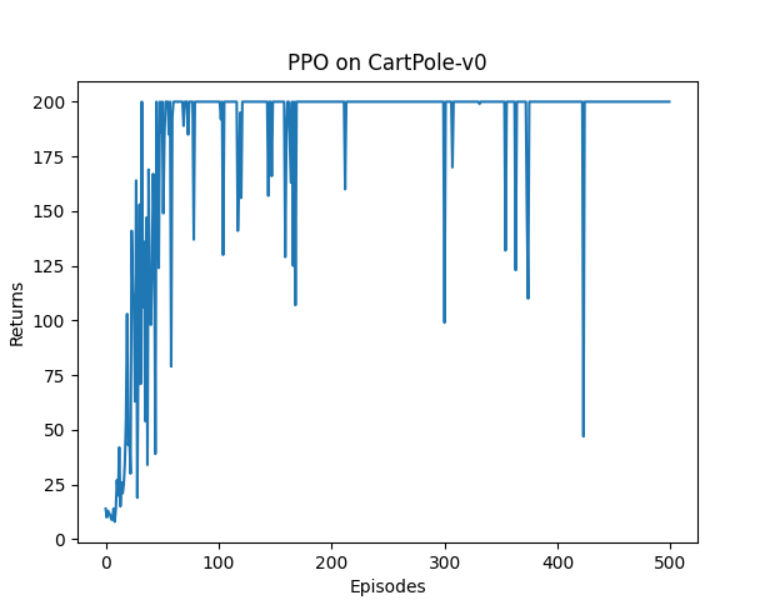
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes') # 横轴:回合数
plt.ylabel('Returns') # 纵轴:总奖励
plt.title('PPO on {}'.format(env_name)) # 标题:算法在特定环境上的表现
plt.show() # 显示图像
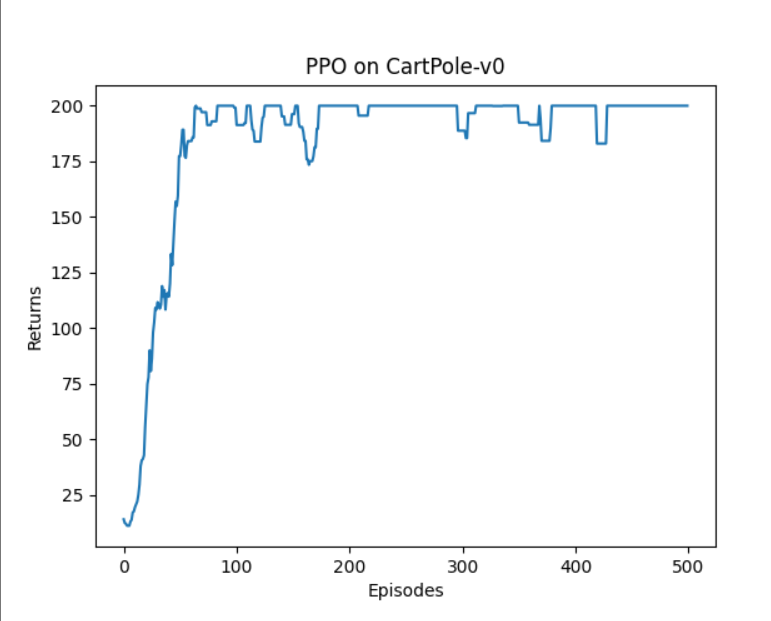
# 绘制移动平均曲线,平滑波动,更清晰展示学习趋势
mv_return = rl_utils_1.moving_average(return_list, 9) # 窗口大小为9的移动平均
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('PPO on {}'.format(env_name))
plt.show()补充代码
"""
文件名: rl_utils
作者: 墨尘
日期: 2025/7/22
项目名: d2l_learning
备注:
"""
from tqdm import tqdm
import numpy as np
import torch
import collections
import random
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self):
return len(self.buffer)
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size - 1, 2)
begin = np.cumsum(a[:window_size - 1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
# 修复后的rl_utils_1.train_on_policy_agent函数(核心部分)
def train_on_policy_agent(env, agent, num_episodes, max_steps=200): # 添加max_steps
return_list = []
for i_episode in range(num_episodes):
episode_return = 0
transition_dict = {
'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []
}
state, _ = env.reset() # 兼容Gymnasium的reset返回值
done = False
step = 0 # 记录当前步数
while not done and step < max_steps: # 增加步数限制
action = agent.take_action(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated # 环境终止标志
step += 1 # 步数+1
# 收集数据
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict) # 进入网络更新
print(f"Episode {i_episode + 1}/{num_episodes}, Return: {episode_return}")
return return_list
def train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
# 修复:提取观测值
state, _ = env.reset() # 新增:解包获取观测值
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, truncated, _ = env.step(action) # 注意:step也可能返回5个值
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {'states': b_s, 'actions': b_a, 'next_states': b_ns, 'rewards': b_r,
'dones': b_d}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
9.实验结果

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)