【Hadoop+Spark+Hive】-基于大数据的音乐推荐与数据分析系统 音乐网站系统 网易云音乐数据分析
本文介绍了一个基于大数据技术的音乐推荐系统,采用Python+Flask框架开发,整合Hadoop+Spark处理海量数据,实现协同过滤推荐算法。系统包含用户和管理员双角色功能:用户可获取个性化音乐推荐、参与社区交流;管理员能进行用户管理、音乐审核及可视化数据分析。核心亮点包括爬虫自动采集音乐数据、大屏可视化展示用户行为分析,以及解决数据稀疏性问题的推荐算法优化。系统显著提升了音乐推荐的精准度和用
🔥作者:it毕设实战小研🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java实战项目
Python实战项目
微信小程序实战项目
大数据实战项目
PHP实战项目
💕💕文末获取源码
文章目录
本次文章主要是介绍基于大数据、协同过滤 、Python 、Hadoop+Spark 、可视化大屏的音乐推荐系统的功能,
1、音乐推荐系统-前言介绍
1.1背景
数字音乐产业发展迅猛,全球音乐流媒体平台用户数量呈指数级增长,用户面临海量音乐资源却难以快速找到符合个人喜好的内容这一矛盾日益突出。传统音乐平台的推荐机制往往依赖简单的分类标签和热门排行,无法深度挖掘用户行为数据中蕴含的复杂偏好模式,导致推荐准确性不足且用户体验欠佳;同时缺乏对音乐数据的深层次分析能力,难以为平台运营提供有效的决策支持。音乐数据的爆炸式增长与个性化需求之间的不匹配问题,以及传统推荐算法在处理稀疏数据和冷启动问题上的局限性,亟需通过智能化技术手段加以解决,这促使开发一套基于大数据技术的音乐推荐与分析系统变得十分必要。
1.2课题功能、技术
本系统采用Python+Flask轻量级框架构建Web应用后端,结合网络爬虫技术自动化获取丰富的音乐资源数据,运用Hadoop分布式存储与Spark内存计算相结合的大数据处理架构对海量音乐信息进行高效存储与实时计算分析。系统核心实现了基于用户-物品协同过滤算法的个性化推荐引擎,通过分析用户历史听歌行为和相似用户群体的偏好模式,能够精准预测并推荐符合用户口味的音乐内容;构建了用户与管理员双角色权限管理体系,为普通用户提供音乐推荐、社区交流、公告资讯浏览等服务功能,为管理员配备用户管理、音乐资源管理、交流内容审核等后台管理工具。系统集成了先进的大屏可视化技术,实时展示用户年龄分布、性别比例、音乐作者作品统计、平台数据增长趋势等多维度数据洞察,为音乐平台的运营决策和商业分析提供直观的数据支撑。
1.3 意义
该系统的成功设计与实现为音乐推荐领域提供了大数据技术深度应用的典型范例,显著提升了用户获取个性化音乐内容的效率与满意度,有效解决了传统推荐系统面临的数据稀疏性和推荐精度不足等关键问题。研究成果对推动音乐产业数字化智能化转型具有重要的现实意义和应用价值,同时为电商推荐、视频推荐等相关领域的推荐系统设计与优化、大数据分析技术应用提供了宝贵的技术参考与实践经验,具备良好的推广应用前景。
2、音乐推荐系统-研究内容
1、音乐数据采集与清洗:运用Python环境下的网络爬虫框架(如Scrapy、Requests结合BeautifulSoup)从各大音乐平台自动化抓取音乐基础信息、歌手资料、用户评价、播放量等多维度数据内容。针对采集获得的原始数据执行去重处理、缺失值填充、数据格式标准化等清洗工作,通过数据质量检测机制剔除异常记录,确保后续大数据分析处理的数据源质量与可靠性。
2、分布式数据存储架构:构建基于Hadoop HDFS的分布式文件系统存储海量音乐元数据,采用MySQL关系型数据库管理用户信息、推荐记录、交流内容等结构化业务数据。设计包含用户表、音乐表、评分表、推荐历史表等核心数据表结构,通过Flask-SQLAlchemy ORM框架实现应用层与数据库的高效交互,同时建立数据备份与恢复机制保障数据安全性。
3、大数据处理与推荐算法实现:基于Spark分布式计算引擎处理用户行为数据,实现用户-物品协同过滤推荐算法,通过计算用户相似度矩阵和物品相似度关系,生成个性化音乐推荐列表。结合用户听歌历史、收藏记录、评分行为等多重特征进行深度挖掘,构建用户画像模型,提升推荐准确性和覆盖率,有效解决冷启动和数据稀疏性问题。
4、多维度数据可视化分析:集成ECharts可视化组件构建音乐数据分析大屏,实时展示用户年龄分布、性别比例、热门歌手排行、音乐类型偏好等统计图表。通过动态数据更新机制呈现平台用户增长趋势、音乐播放热力图、推荐系统效果评估等关键业务指标,为运营决策和系统优化提供直观的数据洞察支持。
5、系统架构集成与性能优化:完成各功能模块开发后,采用模块化设计思想整合用户管理、推荐引擎、数据分析等核心组件,通过缓存机制和数据库连接池技术提升系统响应效率。配置负载均衡和异常处理机制确保系统稳定运行,并建立完整的测试体系验证系统功能完整性与性能指标达成情况。
3、音乐推荐系统-开发技术与环境
1、亮点(爬虫、大屏可视化)
2、技术分析:
- 开发语言:Python
- 后端框架:Flask
- 算法:协同过滤
- 前端:Vue
- 数据库:MySQL
3、开发工具:pycharm
4、音乐推荐系统-功能介绍
2个角色:用户/管理员(亮点:爬虫、大屏可视化、协同过滤推荐算法)
(1) 用户:登录注册、音乐推荐(协同过滤)、音乐交流、查看公告资讯
(2) 管理员:用户管理、音乐管理,音乐交流管理、系统管理、个人中心
(用户年龄统计、性别统计、作者作品统计、数据统计)
5、音乐推荐系统成果展示
5.1演示视频
【Hadoop+Spark+Hive】-基于大数据的音乐推荐与数据分析系统 音乐网站系统 网易云音乐网站
5.2演示图片
1、用户端页面:
☀️登录☀️
☀️音乐交流☀️
☀️音乐推荐☀️
☀️查看公告☀️
2、管理员端页面:
☀️大屏可视化☀️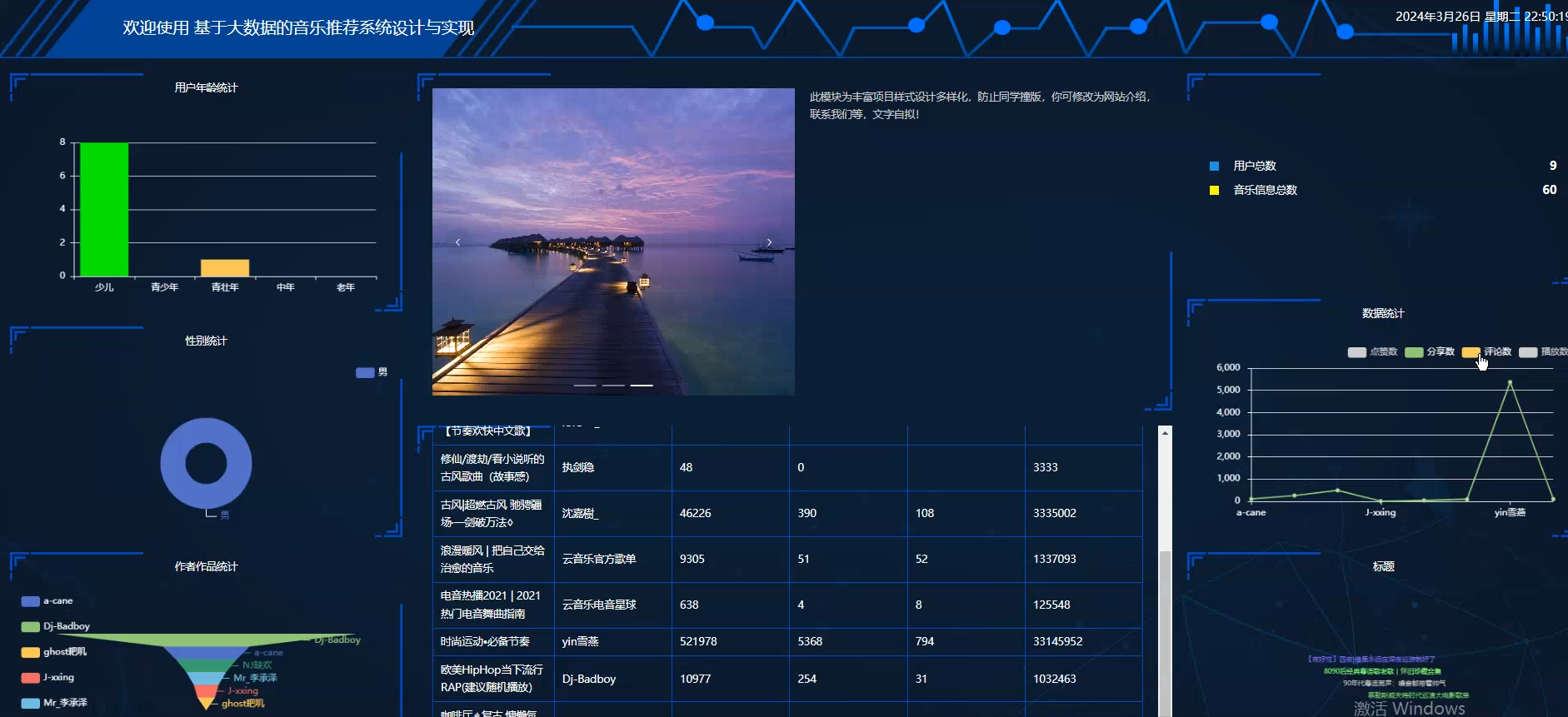
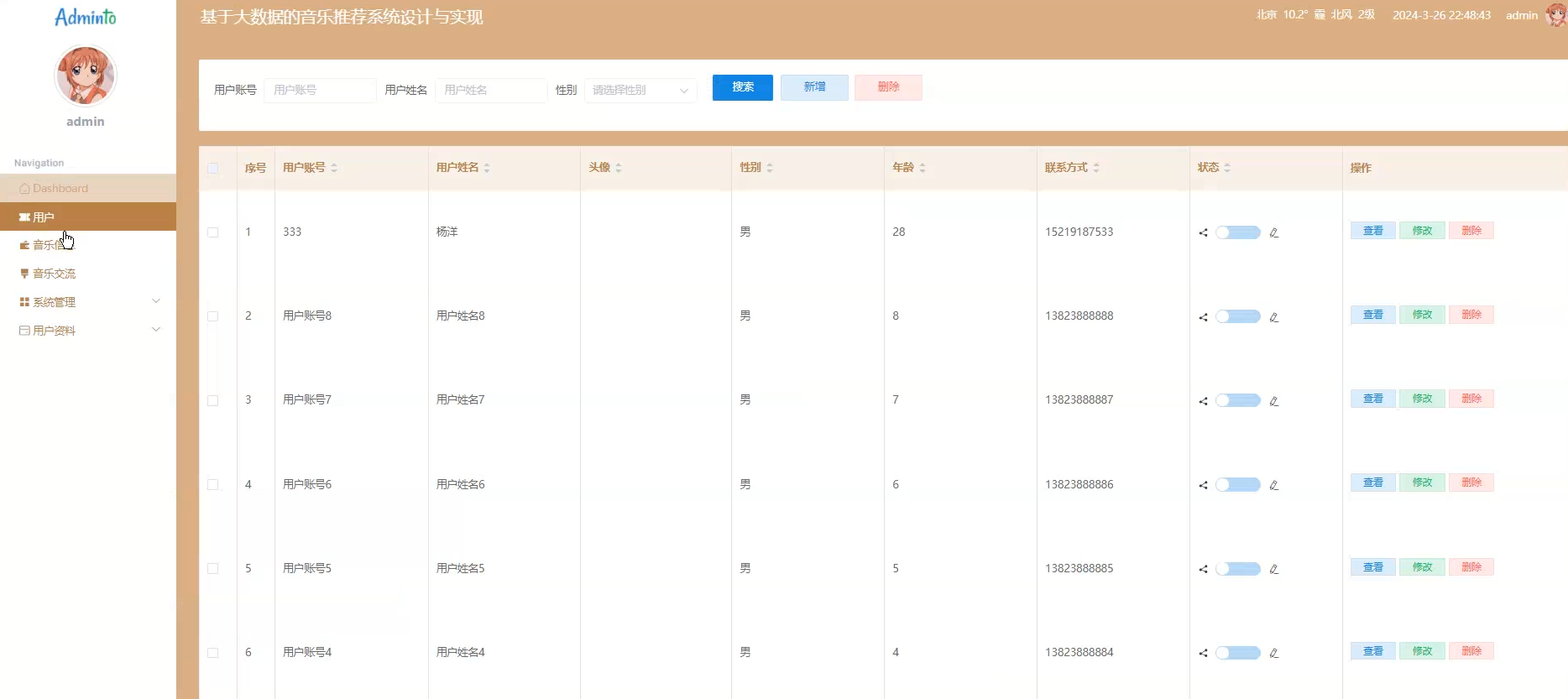
☀️用户管理☀️
☀️音乐管理☀️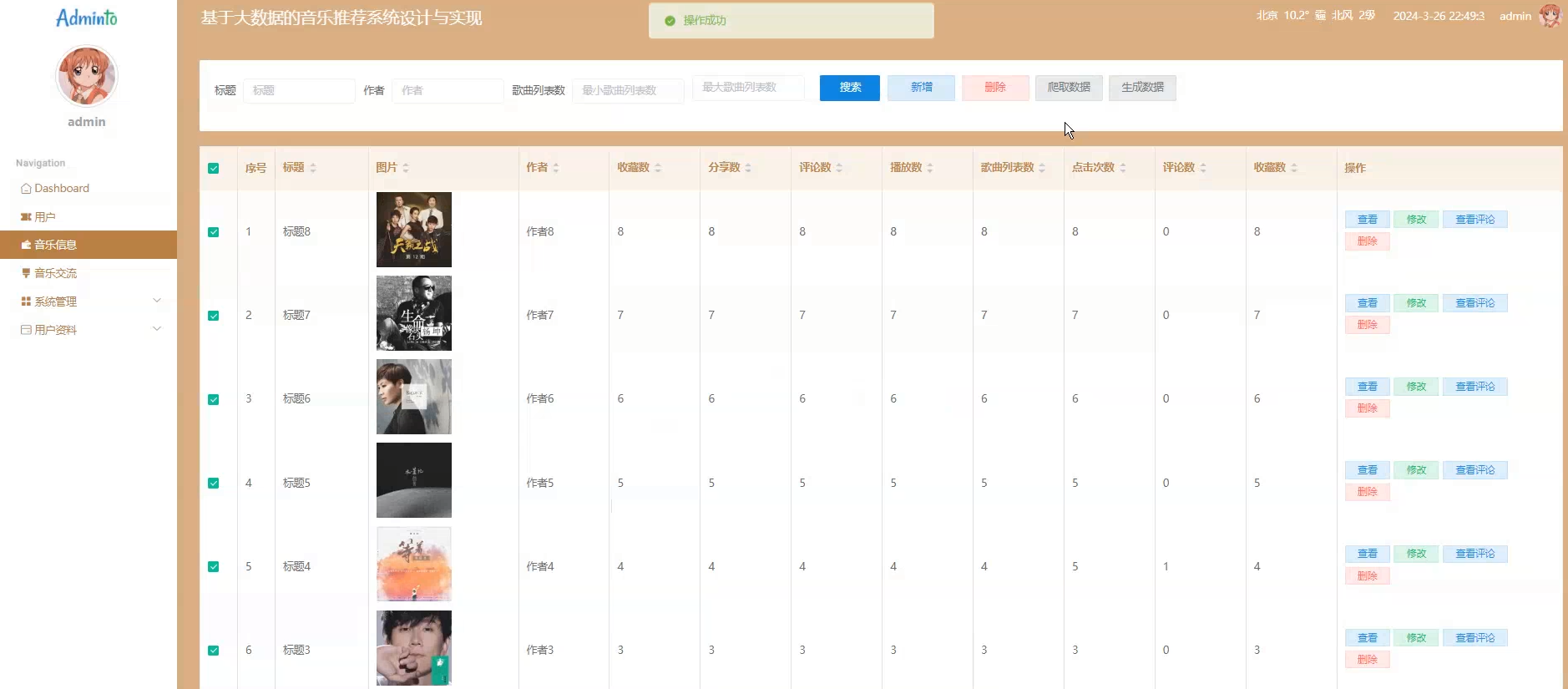
☀️音乐交流管理☀️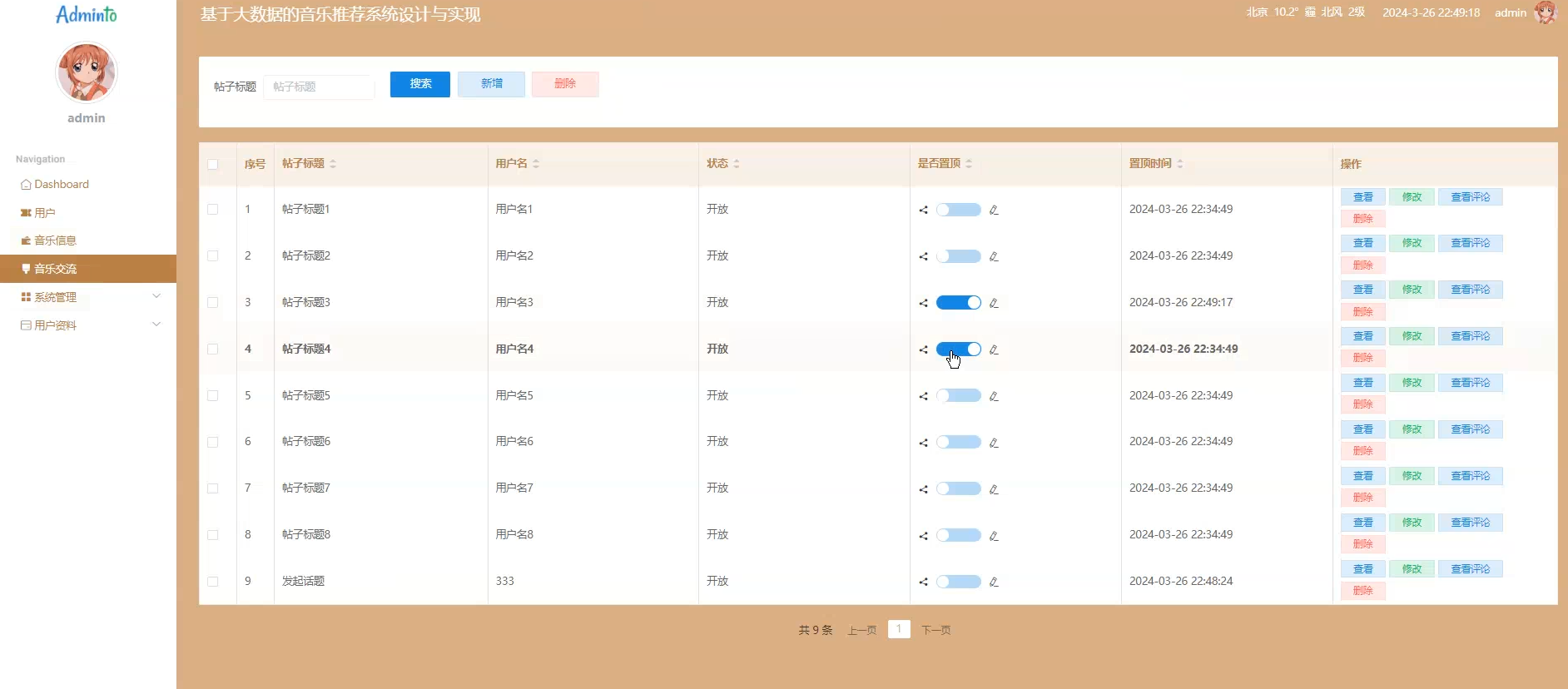
☀️系统管理☀️
音乐推荐系统-代码展示
1.数据爬虫【代码如下(示例):】
# 音乐信息
class MusicCrawler:
def __init__(self):
self.session = requests.Session()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
self.session.headers.update(self.headers)
# 数据库配置
self.db_config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'password',
'database': 'music_recommend',
'charset': 'utf8mb4'
}
def init_database(self):
"""初始化数据库连接"""
try:
self.conn = pymysql.connect(**self.db_config)
self.cursor = self.conn.cursor()
logger.info("数据库连接成功")
except Exception as e:
logger.error(f"数据库连接失败: {e}")
2.数据清洗【代码如下(示例):】
# 数据清洗
class MusicDataCleaner:
def __init__(self, db_config):
"""初始化数据清洗器"""
self.db_config = db_config
self.engine = create_engine(
f"mysql+pymysql://{db_config['user']}:{db_config['password']}@"
f"{db_config['host']}:{db_config['port']}/{db_config['database']}?charset=utf8mb4"
)
# 预定义的数据清洗规则
self.genre_mapping = {
'流行': '流行', 'pop': '流行', 'Pop': '流行',
'摇滚': '摇滚', 'rock': '摇滚', 'Rock': '摇滚',
'电子': '电子', 'electronic': '电子', 'Electronic': '电子',
'民谣': '民谣', 'folk': '民谣', 'Folk': '民谣',
'古典': '古典', 'classical': '古典', 'Classical': '古典',
'爵士': '爵士', 'jazz': '爵士', 'Jazz': '爵士',
'说唱': '说唱', 'rap': '说唱', 'hip-hop': '说唱', 'Hip-Hop': '说唱'
}
self.stop_words = ['的', '了', '和', '与', '及', '以及', '还有', '包括']
def load_raw_data(self, table_name='songs'):
"""从数据库加载原始数据"""
try:
query = f"SELECT * FROM {table_name}"
df = pd.read_sql(query, self.engine)
logger.info(f"成功加载 {len(df)} 条原始数据")
return df
except Exception as e:
logger.error(f"加载数据失败: {e}")
return pd.DataFrame()
音乐推荐系统-结语(文末获取源码)
💕💕
java精彩实战毕设项目案例
小程序精彩项目案例
Python精彩项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 54
54 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)