基于python的电影数据爬取与可视化分析系统
【代码】基于python的电影数据爬取与可视化分析系统。
·
技术栈设计
后端技术
- 语言: Python 3.8+
- 框架: Django/Flask(建议Django内置ORM和Admin)
- 爬虫库: Requests + BeautifulSoup4/Scrapy(动态内容用Selenium)
- 数据库: MySQL/PostgreSQL(关系型存储结构化数据)或MongoDB(非结构化数据)
- 数据处理: Pandas + NumPy
- 可视化: Matplotlib + Seaborn + Plotly(交互式图表)
前端技术
- 基础: HTML5 + CSS3 + JavaScript
- 可视化库: ECharts.js 或 D3.js(动态图表)
- 框架: Vue.js/React(可选,增强交互性)
其他工具
- 代理池: 解决反爬(如Scrapy-ProxyPool)
- 部署: Docker + Nginx
功能模块设计
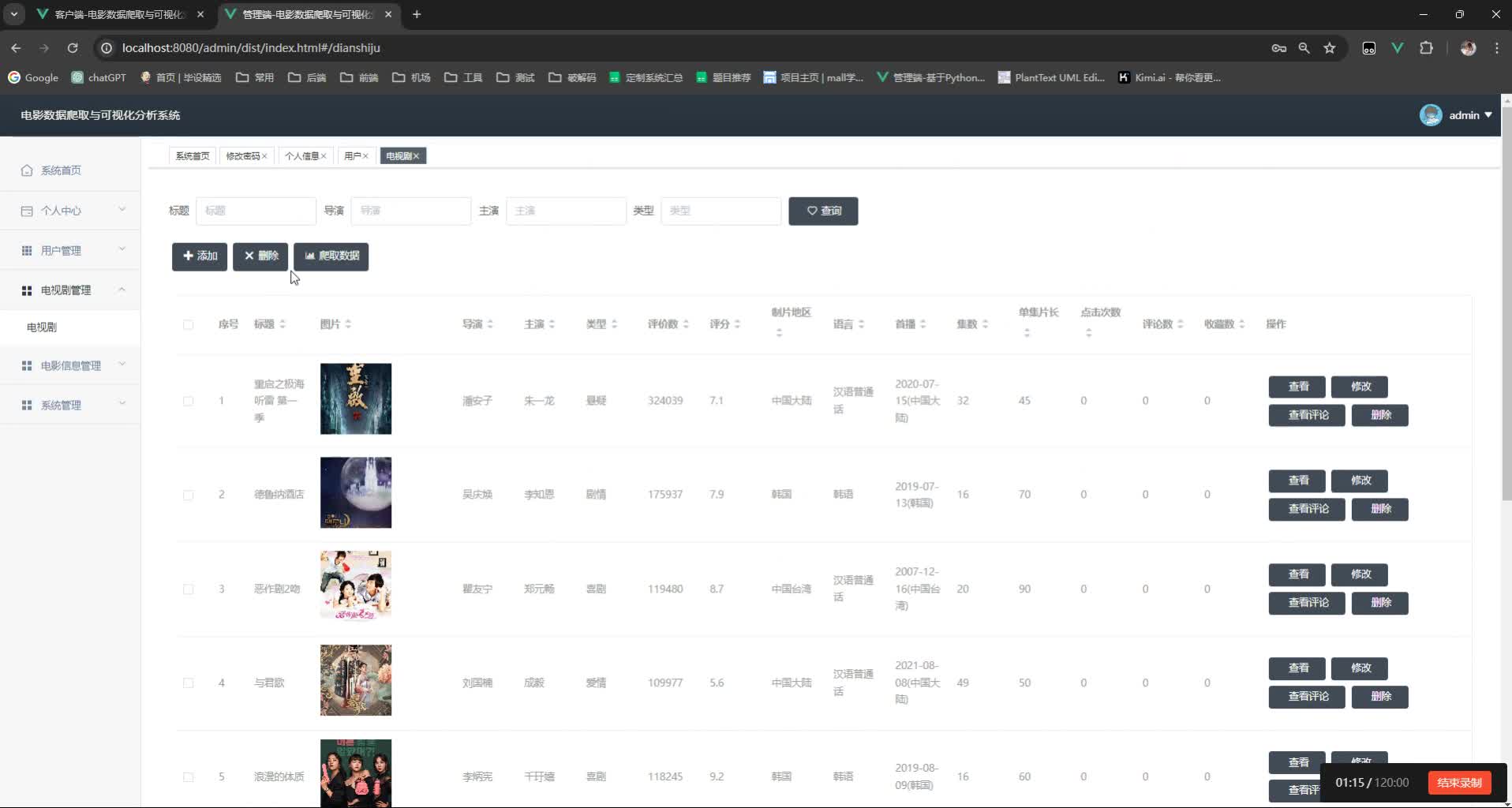
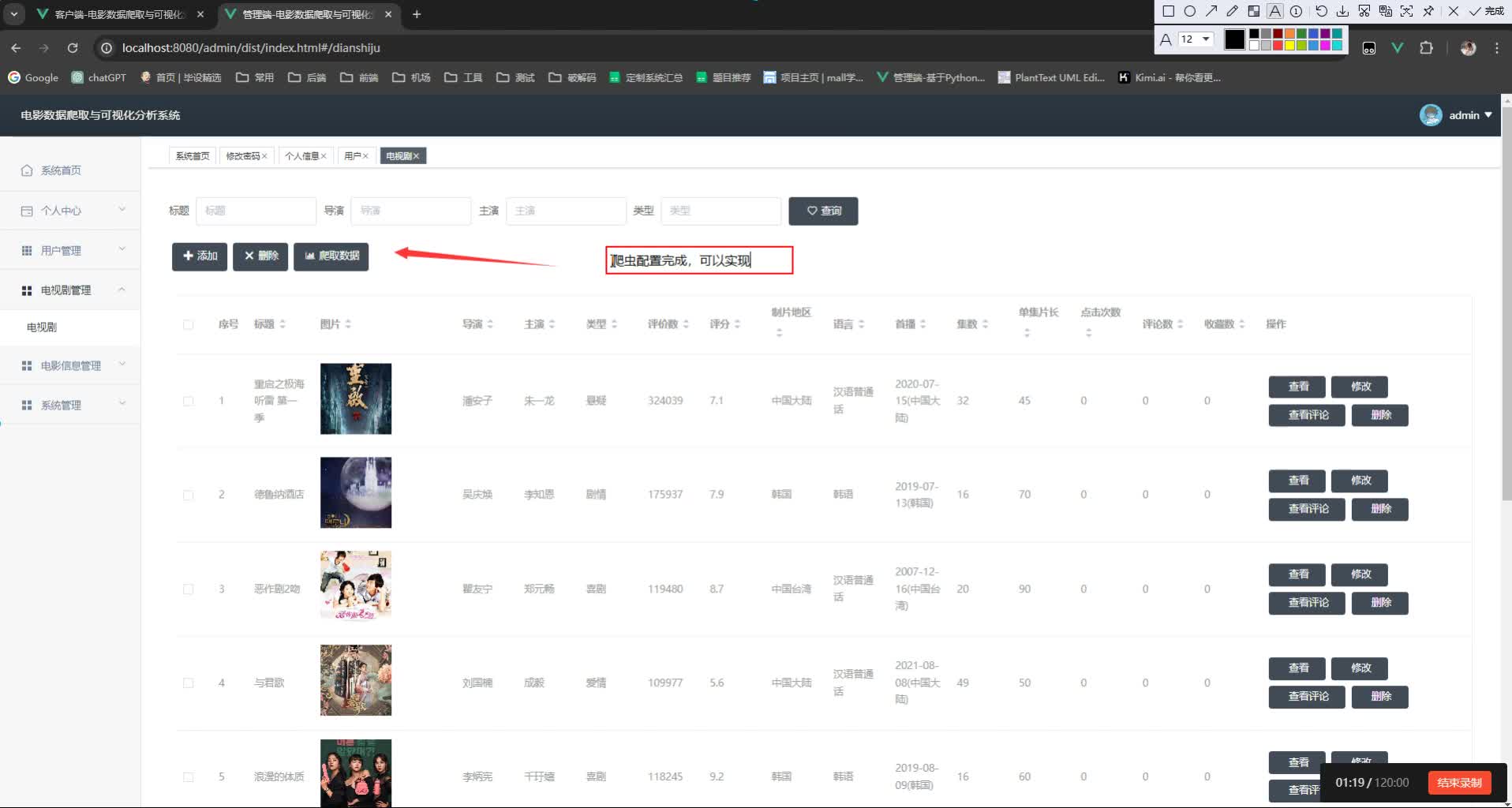
1. 数据爬取模块
- 目标网站: 豆瓣电影/IMDb等
- 字段设计:
class Movie(models.Model): # Django ORM示例 title = models.CharField(max_length=200) rating = models.FloatField() directors = models.CharField(max_length=100) actors = models.TextField() release_date = models.DateField() genres = models.CharField(max_length=100) crawl_time = models.DateTimeField(auto_now_add=True) - 反爬策略:
- 随机User-Agent(fake_useragent库)
- 请求间隔延迟(
time.sleep(random.uniform(1,3))) - IP轮换(付费代理服务)
2. 数据存储模块
- 数据库表设计:
- 电影基础表(主表)
- 演员/导演关联表(多对多关系)
- 用户评论表(可选)
- 索引优化: 对
title和genres字段建立索引
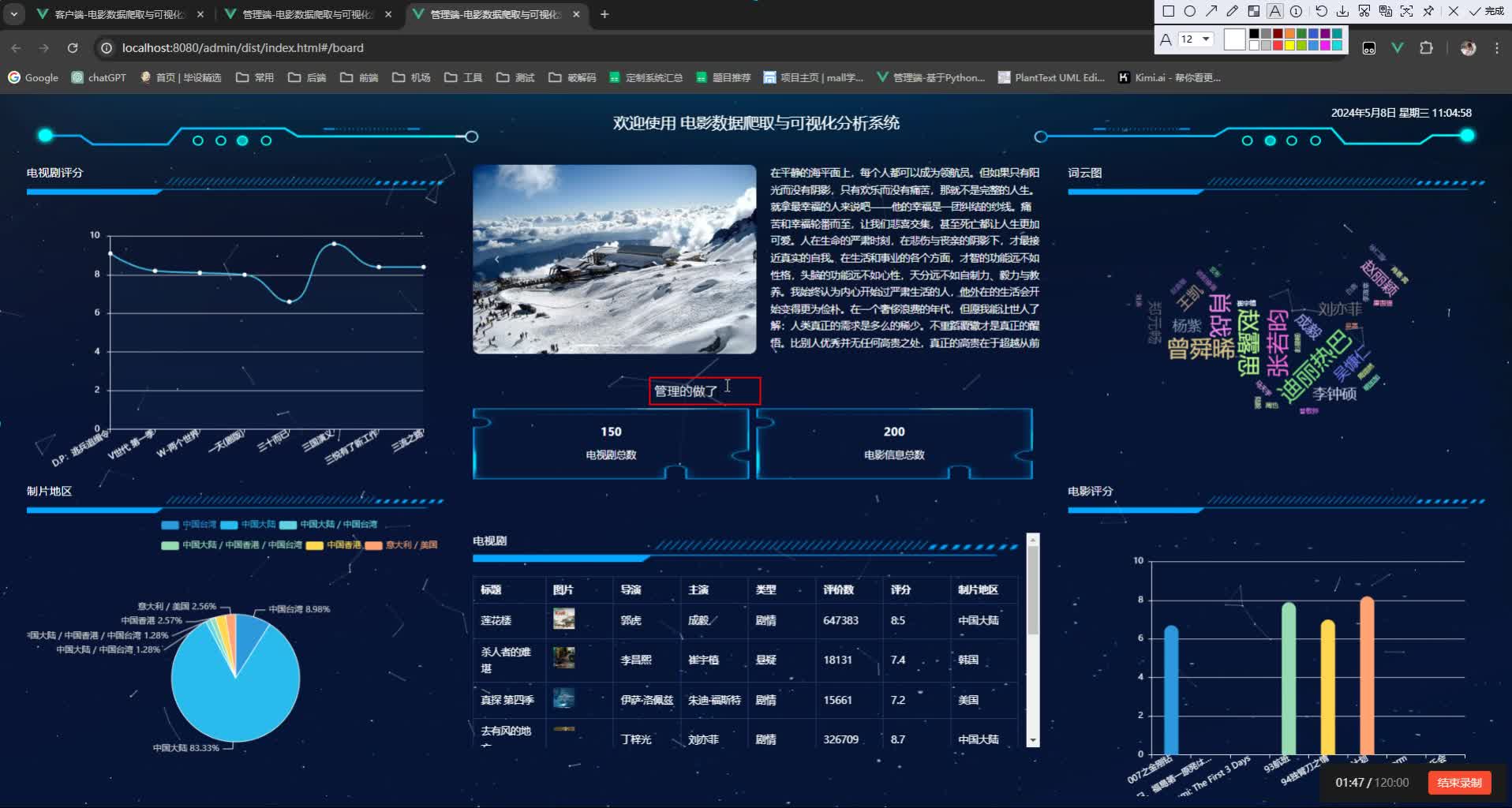
3. 可视化分析模块
- 分析维度:
- 评分分布直方图(Matplotlib)
- 类型占比饼图(Seaborn)
- 年度产量趋势线(Plotly动态图)
- 交互功能: 通过前端筛选条件(如时间范围、类型)动态更新图表
核心代码示例
爬虫片段(Scrapy)
import scrapy
from items import MovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
for movie in response.css('.item'):
item = MovieItem()
item['title'] = movie.css('.title::text').get()
item['rating'] = float(movie.css('.rating_num::text').get())
yield item
next_page = response.css('.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
可视化片段(Matplotlib)
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_sql("SELECT rating FROM movie", con=database_conn)
plt.hist(df['rating'], bins=10, edgecolor='black')
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Movie Rating Distribution')
plt.savefig('static/images/rating_dist.png') # 供前端调用
数据库设计(MySQL示例)
CREATE TABLE `movies` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(200) COLLATE utf8mb4_unicode_ci NOT NULL,
`rating` float DEFAULT NULL,
`release_year` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_rating` (`rating`) -- 加速查询
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
系统测试设计
1. 单元测试(PyTest)
- 爬虫测试: 模拟响应检查字段提取逻辑
def test_parse_movie_title(): html = "<div class='title'>Test Movie</div>" selector = scrapy.Selector(text=html) assert selector.css('.title::text').get() == "Test Movie"
2. 性能测试(Locust)
- 模拟并发用户请求API接口,监测响应时间
3. 可视化测试
- 手动验证图表数据与数据库是否一致
部署方案
-
容器化:
FROM python:3.8 WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt CMD ["gunicorn", "app:app", "--bind", "0.0.0.0:8000"] -
Nginx配置:
server { listen 80; location / { proxy_pass http://app:8000; } location /static { alias /app/static; } }

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)