基于Python的微博热点数据分析与可视化(源码+定制+开发)微博热点话题爬取与数据可视化分析系统 基于Python的社交平台热搜数据分析 微博热搜数据采集与可视化分析平台
【摘要】阿龙是一名资深Java全栈工程师,专注于大数据分析与可视化领域。作为CSDN特邀专家,他拥有10W+粉丝,为上千名学生提供过毕业设计辅导。本文详细介绍了他开发的微博热点分析系统,该系统采用Python爬虫采集数据,基于Hadoop+Spark大数据架构,结合Hive数据仓库进行分布式处理,并利用ECharts实现可视化展示。文章包含完整的技术栈解析(Python/Spark/Hadoop/
博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!

目录:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!
承诺所有开发的项目,全程售后陪伴!!!

2 相关工具及介绍
2.1 Python语言
Python 是由荷兰数学和计算机研究学会的吉多·范罗苏姆于20世纪90年代设计的一款高级编程语言。Python 优雅的语法、动态类型以及解释型语言的特点,使其成为数据分析、爬取、处理和可视化领域的首选语言。相比其他高级语言,Python 代码量少、风格简洁,拥有丰富的第三方库如 pandas、numpy、matplotlib 和 seaborn 等,极大方便了微博热点数据的抓取、清洗、分析与可视化。Python 也支持调用其他语言模块,故被称为“胶水语言”,非常适合本课题的数据处理需求。
2.2 Hive简介
Hive 是基于 Hadoop 的数据仓库工具,能够将存储于 HDFS 的结构化数据映射为表,支持类 SQL 查询。Hive 将 SQL 查询转化为 MapReduce 或其他引擎任务,简化大规模结构化数据的分析开发流程。
在本微博热点数据分析系统中,Hive 作为主要数据仓库,具备以下优势:
-
提供类 SQL 操作接口,方便快速构建数据分析流程;
-
相较传统关系型数据库,更适合大数据量的统计分析;
-
支持用户自定义函数,满足个性化热点分析算法需求;
-
基于 HDFS,具有良好的扩展性和可靠性;
-
支持替换底层计算引擎,提高执行效率。
考虑到 MapReduce 在迭代计算中的性能瓶颈,系统将 Hive 的计算引擎切换为 Tez,提高热点数据挖掘的效率。
2.3 Hadoop技术
Hadoop 是 Apache 软件基金会开源的分布式计算平台,核心组件包括分布式文件系统 HDFS 和 MapReduce 计算框架。Hadoop 为微博热点数据分析提供了可靠的海量数据存储和分布式计算能力。
Hadoop 主要优势:
-
高容错性:多副本机制保障节点故障时数据不丢失;
-
高扩展性:支持千级以上节点的集群任务调度和存储;
-
高效性:MapReduce 任务并行执行,加快处理速度。
HDFS 专为部署在廉价硬件设计,支持大规模数据流式访问,适合微博热点海量数据存储需求。鉴于 MapReduce 不适合迭代式数据流处理,Hadoop 主要承担数据存储职责。
2.4 数据采集
为了方便后续对微博热点数据的分析与处理,本系统采用爬虫技术采集微博文本、转发、评论等数据,并将爬取结果保存为 CSV 文件。CSV 格式轻量便捷,文件体积较小,便于网络传输和分享,且多种编程语言和大数据工具(如 Hadoop 生态中的 MapReduce)均能轻松解析,方便批量处理和热点数据分析。
2.5 Spark
Spark 是基于内存计算的快速大数据分析引擎,支持 DAG(有向无环图)计算模型。核心弹性分布式数据集(RDD)支持多次迭代计算,适合复杂的热点挖掘和机器学习算法。Spark 支持多种运行模式(Local、Standalone、Yarn、Mesos),其中 Yarn 模式在企业集群中应用广泛。
Spark 优势包括:
-
内存计算加快数据处理速度,支持缓存;
-
优化的 shuffle 机制降低中间文件读写;
-
高效的 DAG 调度和 RDD 计算,避免重复计算。
在本系统中,Spark 用于热点话题分析和模型训练,提升分析性能。
2.6 环境部署
本系统的软件开发及运行环境如下:
-
操作系统:Linux
-
JDK 版本:1.8.0_241
-
Hadoop 版本:3.3.5
-
虚拟机软件:VMware 16.0
-
数据库工具:MySQL 5.7.29、SQLyog 13.2.0
-
后端框架:Flask
-
可视化工具:ECharts
为实现基于大数据技术的微博热点数据分析,搭建了 Hadoop 集群以支持海量数据的分布式存储和计算。集群包含三台 Linux 虚拟机,分别配置 IP(192.168.144.131、192.168.144.132、192.168.144.133),实现免密码登录并安装 JDK 和 Hadoop。配置 Hadoop 环境变量及核心配置文件(hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml),通过命令 hadoop namenode -format 格式化 HDFS。集群启动后,可通过浏览器访问 http://192.168.144.131:9870 监控 HDFS 运行状态,确保系统稳定运行。
 系统实现界面展示:
系统实现界面展示:

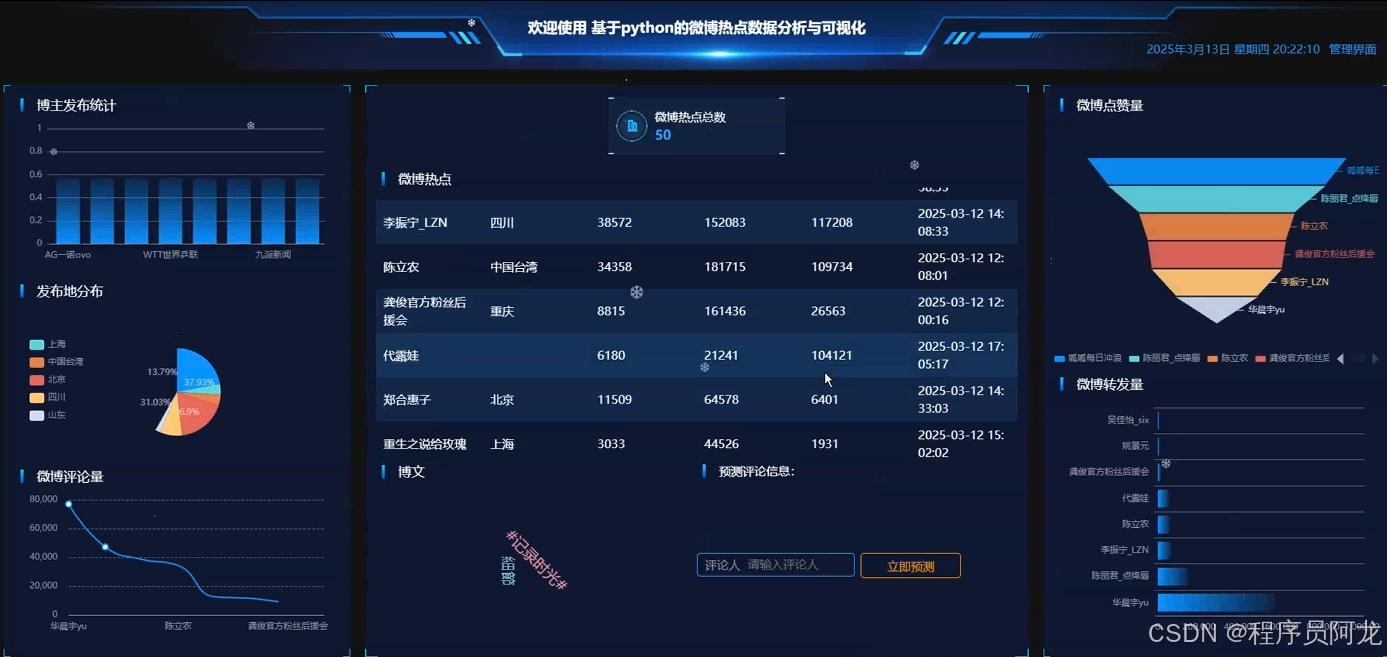
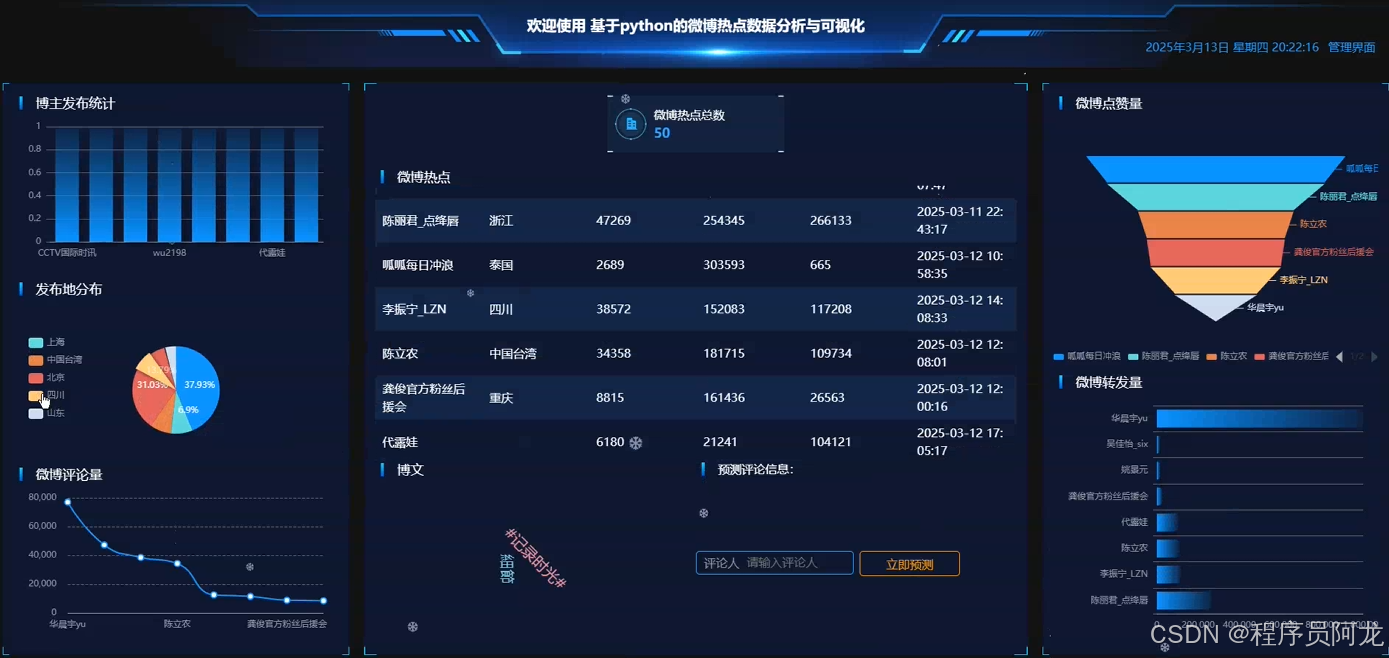
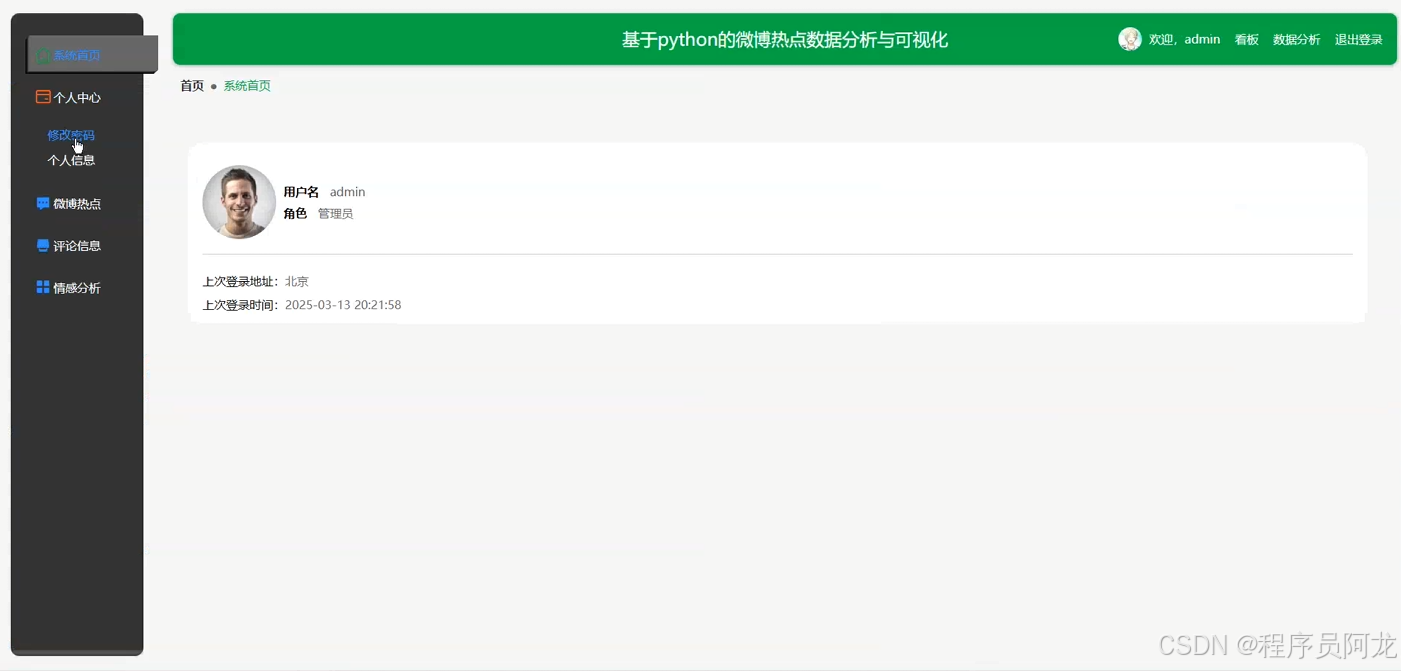
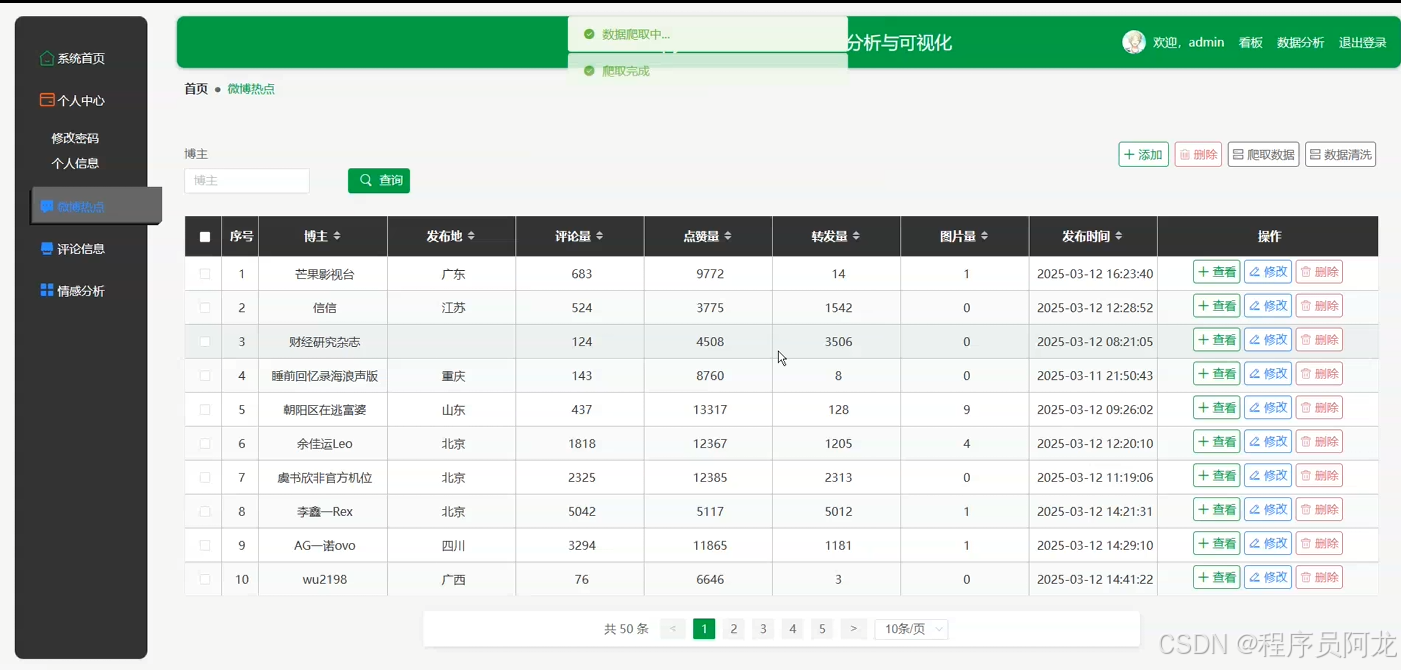
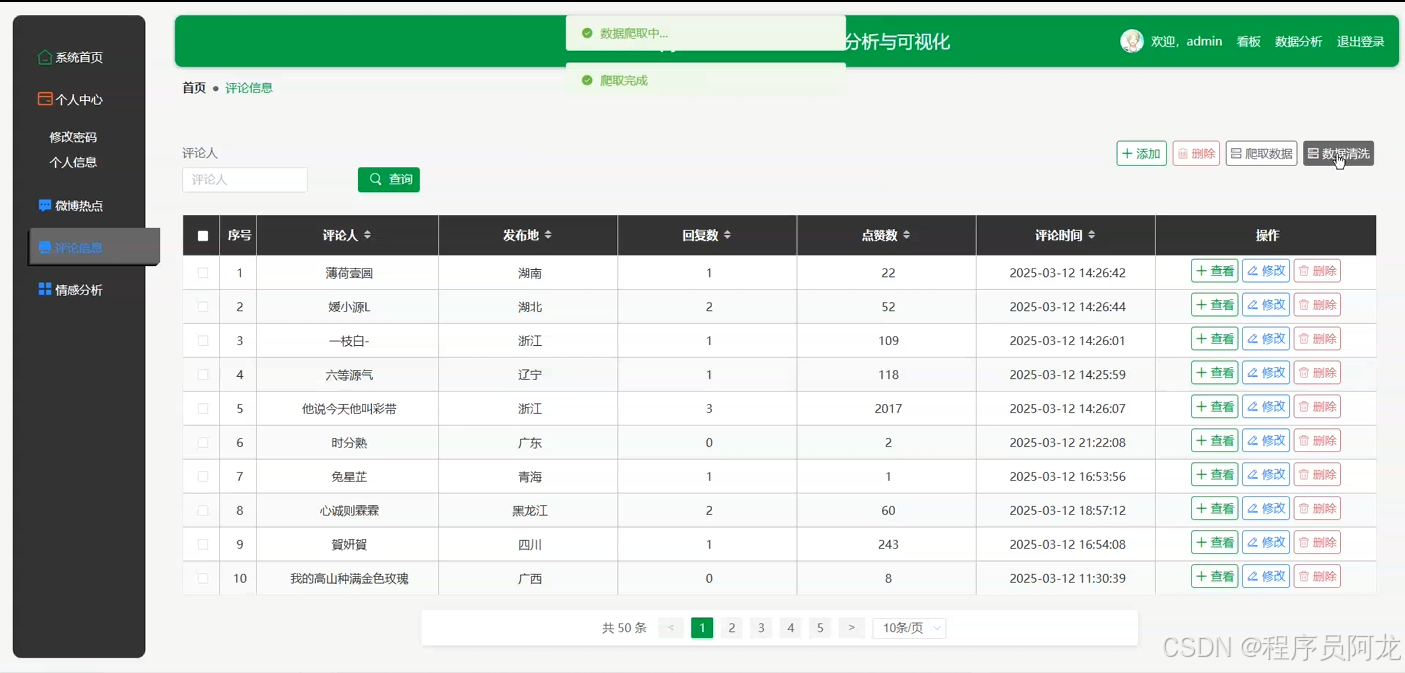
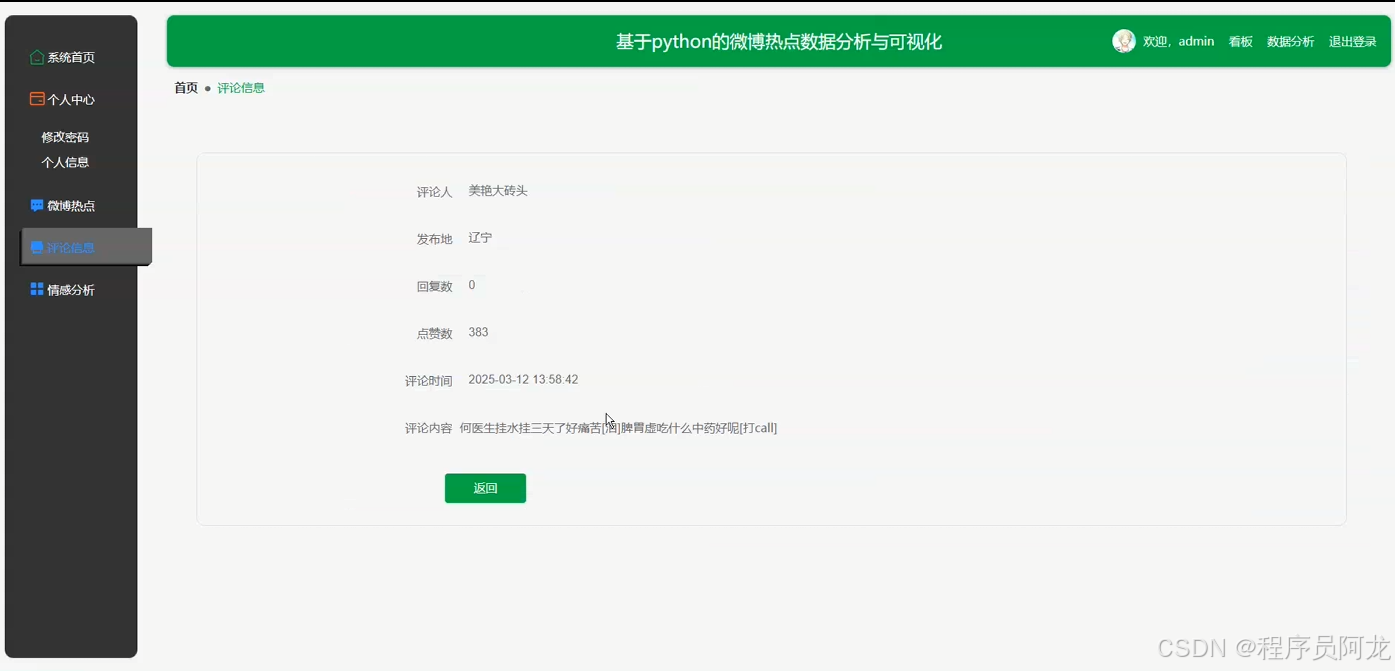
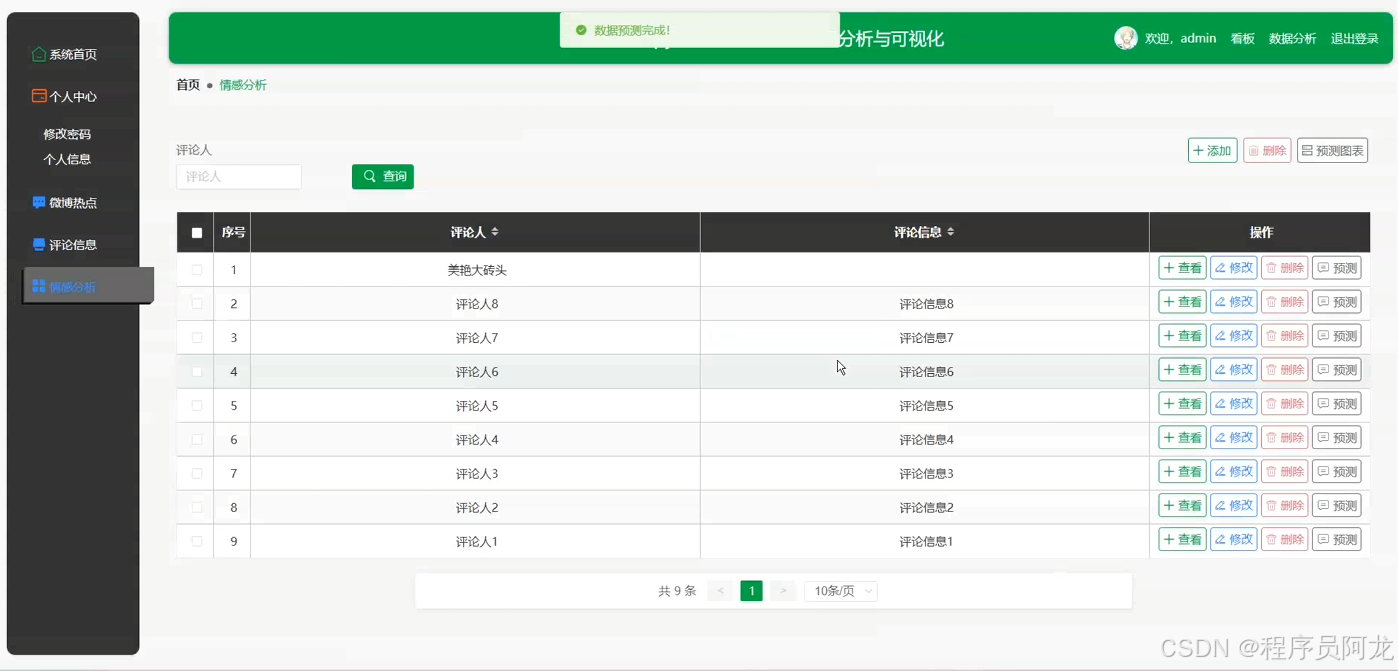
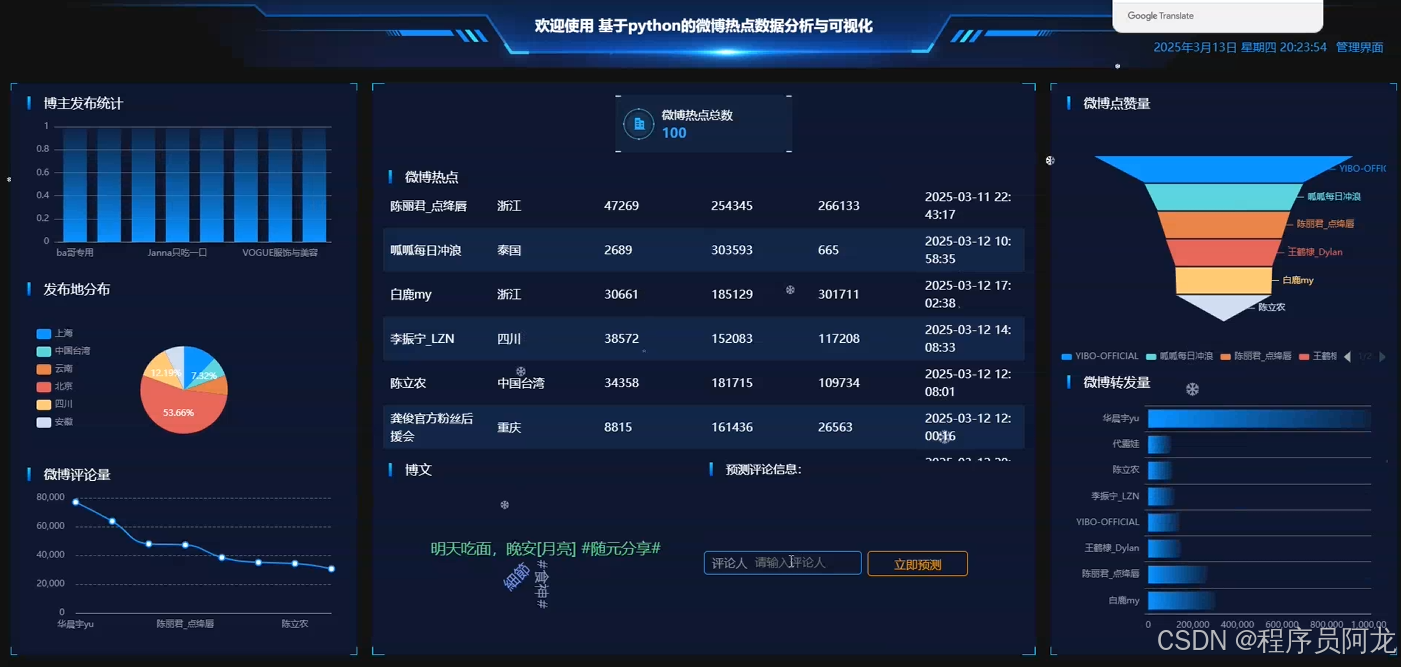
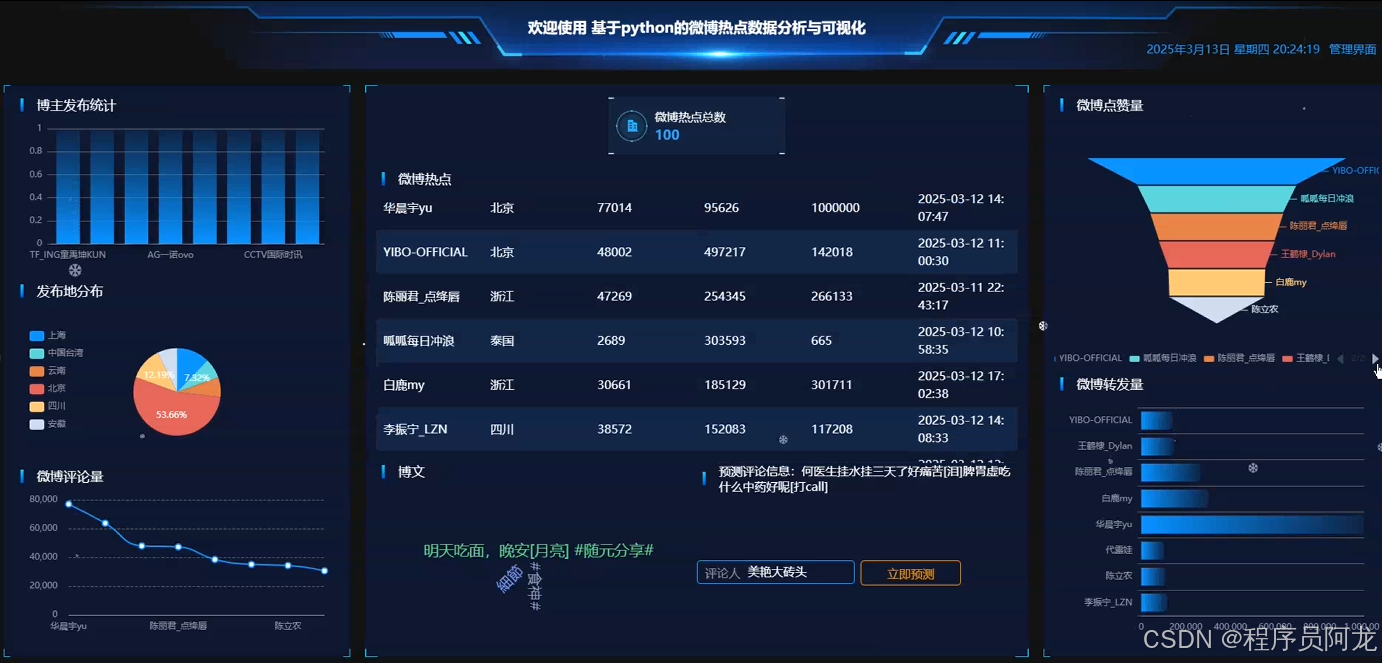
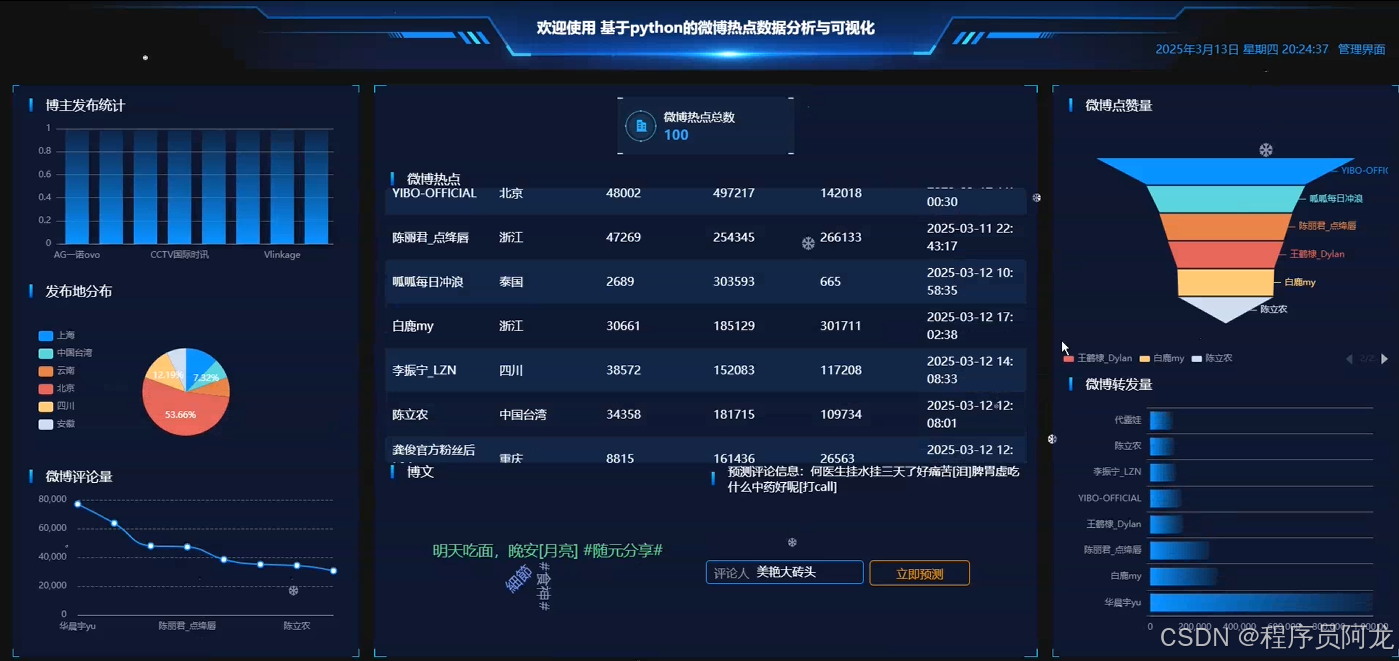
爬虫代码分析介绍:
# 微博热点
class WeibohotSpider(scrapy.Spider):
name = 'weibohotSpider'
spiderUrl = 'https://weibo.com/ajax/feed/hottimeline?since_id=0&refresh=1&group_id=1028038899&containerid=102803_ctg1_8899_-_ctg1_8899&extparam=discover%7Cnew_feed&max_id=0&count=10'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '28j17666_weibohot') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '28j17666_weibohot') == 1:
cursor.close()
connect.close()
self.temp_data()
return
data = json.loads(response.body)
try:
list = data["statuses"]
except:
pass
for item in list:
fields = WeibohotItem()
try:
fields["screenname"] = emoji.demojize(self.remove_html(str( item["user"]["screen_name"] )))
except:
pass
try:
fields["textraw"] = emoji.demojize(self.remove_html(str( item["text_raw"] )))
except:
pass
try:
fields["regionname"] = emoji.demojize(self.remove_html(str( item["region_name"].split()[1] )))
except:
pass
try:
fields["commentscount"] = int( item["comments_count"])
except:
pass
try:
fields["attitudescount"] = int( item["attitudes_count"])
except:
pass
try:
fields["repostscount"] = int( item["reposts_count"])
except:
pass
try:
fields["picnum"] = int( item["pic_num"])
except:
pass
try:
fields["fbtime"] = emoji.demojize(self.remove_html(str( item["created_at"] )))
except:
pass
try:
fields["gerenzy"] = emoji.demojize(self.remove_html(str('https://weibo.com/u/'+ item["user"]["idstr"] )))
except:
pass
yield fields
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
return fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spider28j17666?charset=UTF8MB4')
df = pd.read_sql('select * from weibohot limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8mb4')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
2.7 测试概述
系统测试就是对项目是否存在错误而运行程序的一种检测方式。系统测试对于一个软件来说极为重要,并且在开发过程中占有很大的比重。每一次功能的实现都伴随着很多次的测试。它是软件是否能用的检测环节,对于软件质量的评估有着重要影响。系统能否被验收成功是测试中最后一个至关重要的环节。
2.8软件测试原则
当进行软件测试时,有一些原则需要遵循,以确保测试的有效性和效率。
第一:测试应该尽早开始。在需求分析和系统设计阶段就应该进行测试准备,以便尽早发现系统的不足之处。这样可以降低修复成本,提高开发效率。测试人员应该在分析需求时就参与进来,确保需求具备可测试性和正确性。
第二:测试应该是全面的。测试应该覆盖软件的各个功能模块和不同的使用场景,以确保软件在各种情况下都能正常运行。测试还应该关注软件的性能、安全性和可用性等方面,以全面评估软件的质量。
随着软件开发的复杂性增加,手动测试已经无法满足需求。自动化测试可以提高测试的效率和准确性,减少人为错误。通过编写自动化测试脚本,可以快速执行大量的测试用例,并及时发现问题。软件的开发是一个迭代的过程,每个迭代都会引入新功能和修复旧问题。因此,测试也应该是一个持续的过程,与开发同步进行。持续集成和持续交付等技术可以帮助实现持续测试,确保软件在每个迭代中都能达到预期的质量标准。通过测试不仅仅是为了发现问题,更重要的是提供有价值的反馈给开发人员。测试人员应该及时向开发人员报告问题,并提供详细的复现步骤和环境信息,以便开发人员能够快速定位和解决问题。
2.9测试用例
(1)用户登陆测试用例
表 6-1 用户登录用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
||||
|
功能模块名 |
用户登陆模块 |
用例编号 |
xxxx |
|||
|
功能特性 |
用户身份验证 |
|||||
|
测试目的 |
验证是否输入合法的信息,允许合法登陆,阻止非法登陆 |
|||||
|
测试数据 |
用户名=1密码=a1身份= 非认证用户 |
|||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
状态 |
|
|
1 |
输入用户名和密码 |
用户名= 1密码=1 |
显示进入后的页面。 |
同期望结果。 |
正常 |
|
|
2 |
输入用户名和密码 |
用户名= 1密码=aaa |
显示警告信息“不存在该用户名或密码错误!” |
同期望结果。 |
正常 |
|
|
3 |
输入用户名和密码 |
用户名= aaa密码=1 |
显示警告信息“不存在该用户名或密码错误” |
同期望结果。 |
正常 |
|
|
4 |
输入用户名和密码 |
用户名=“” 密码=“” |
显示警告信息“用户名密码不能为空!” |
同期望结果。 |
正常 |
|
(2)用户注册测试用例
表 6-2 用户注册用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
|||||
|
功能模块名 |
用户注册模块 |
用例编号 |
xxxx |
||||
|
功能特性 |
用户注册 |
||||||
|
测试目的 |
验证私注册是否成功,注册数据是否合法 |
||||||
|
测试数据 |
用户名=aaa 密码=aaa电子邮件=dwa@qq.com |
||||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
测试状态 |
||
|
1 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:注册成功!转入用户主页 |
同期望结果。 |
正常 |
||
|
2 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:用户名已注册 |
同期望结果。 |
正常 |
||
|
3 |
输入注册数据 |
用户名= aaa密码=”” 电子邮件=dwa@qq.com |
提示:密码不能为空 |
同期望结果。 |
正常 |
||
|
4 |
输入注册数据 |
密码=aaa 电子邮件=dwa@qq.com |
提示:用户名为空 |
同期望结果。 |
正常 |
||



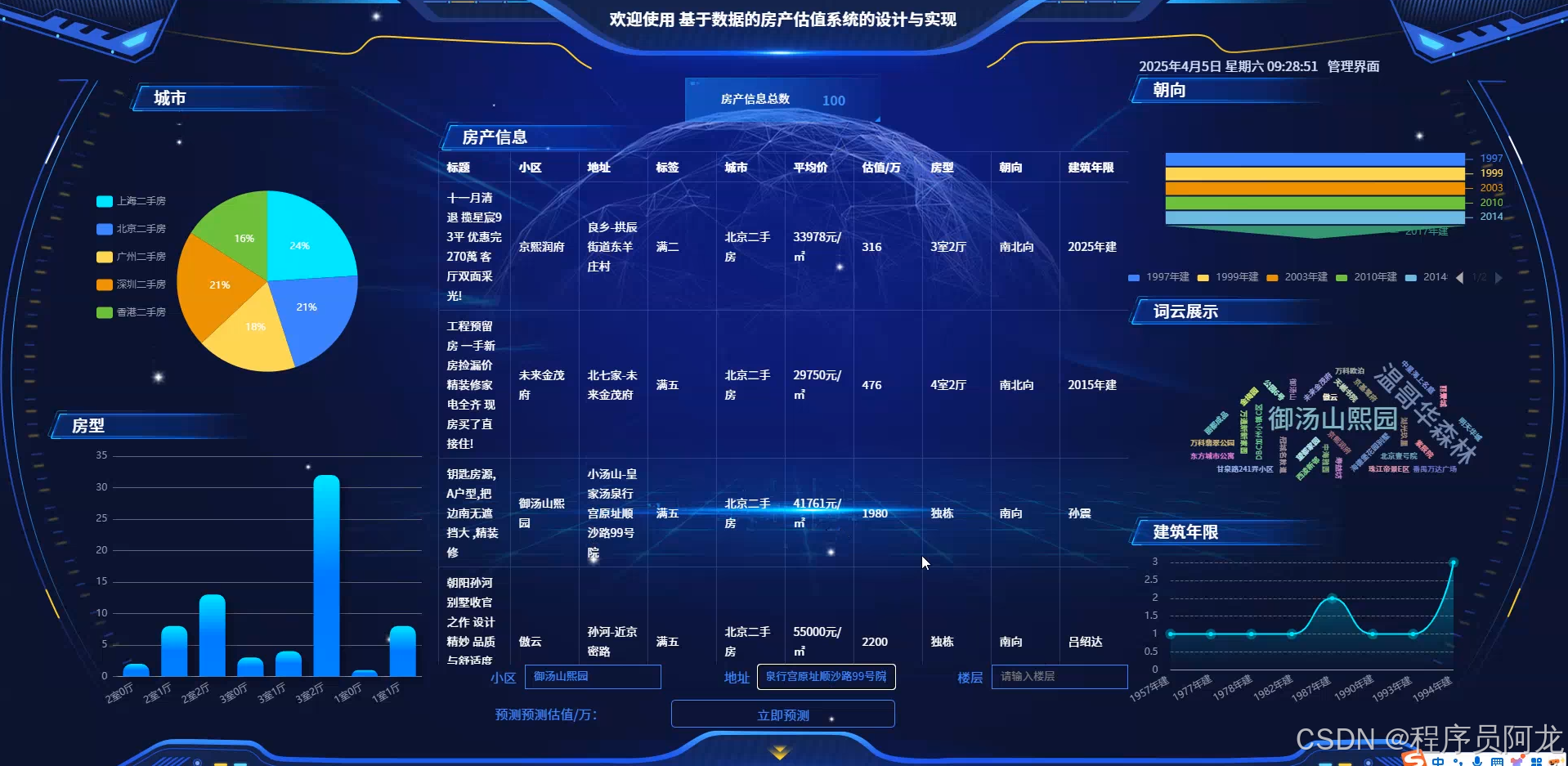 论文部分参考:
论文部分参考:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
我是程序员阿龙,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是CSDN特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。
已经为上百名同学获得优秀毕业生!
源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 31
31 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)