机器学习——线性回归(LinearRegression)实战案例:糖尿病数据预测分析
线性回归案例实战:糖尿病数据预测分析
线性回归是最基础也是最常用的回归算法之一,适用于预测连续变量,比如房价、血糖值、销售额等。本文通过糖尿病数据集,展示如何使用线性回归进行建模、训练与评估。
Diabetes Data![]() https://www4.stat.ncsu.edu/~boos/var.select/diabetes.html
https://www4.stat.ncsu.edu/~boos/var.select/diabetes.html

一、导入数据与库
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.model_selection import train_test_split
模块说明:
-
pandas:用于读取和处理数据 -
numpy:进行数值计算 -
LinearRegression:线性回归模型 -
train_test_split:划分训练集与测试集 -
mean_absolute_error,mean_squared_error:评估模型性能的指标
二、读取数据并划分特征与目标
data = pd.read_csv("糖尿病数据.csv")
X = data.drop('target', axis=1) # 特征变量
y = data[['target']] # 目标变量(如血糖值)
数据说明:
-
假设这是一个标准化后的糖尿病数据集,包含 10 个特征(如年龄、BMI、血压等)
-
target表示预测目标,例如糖尿病的指标值(数值型)
三、拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y)
将数据随机划分为:
-
X_train,y_train:训练集 -
X_test,y_test:测试集
默认比例为 75% 训练 + 25% 测试
四、训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
训练 LinearRegression 模型,找到最佳拟合的直线(或者超平面)来预测目标变量。
五、获取模型参数(系数与截距)
a = model.coef_
b = model.intercept_
print("自变量系数:", a)
print("截距:", b)
模型方程为:
y = a1*x1 + a2*x2 + ... + a10*x10 + b
参数解释:
-
系数(coef_) 表示每个变量对结果的影响方向与强度
-
正数:正相关
-
负数:负相关
-
-
截距(intercept_) 表示所有变量为 0 时的预测结果
六、评估模型性能
score = model.score(X_test, y_test)
print("R² 分数:", score)
R²(决定系数):
-
衡量模型对数据的解释能力
-
范围:[0, 1]
-
R² 越接近 1,说明模型拟合越好
-
R² = 0 表示模型无法解释数据变化
-
七、计算回归误差指标
print("MAE 平均绝对误差:", mean_absolute_error(y_test, model.predict(X_test)))
print("MSE 平均平方误差:", mean_squared_error(y_test, model.predict(X_test)))
print("RMSE 平方根误差:", np.sqrt(mean_squared_error(y_test, model.predict(X_test))))
在回归问题的模型评估中,MAE、MSE 和 RMSE 是常用的指标,用于衡量预测值与实际值之间的误差大小。以下是对它们的详细解释:
1. MAE(Mean Absolute Error,平均绝对误差)
定义
计算预测值与实际值之间绝对误差的平均值,公式为:
![]()
其中,yi 是实际值,y^i 是预测值,n 是样本数量。
特点
- 优点:计算简单,对异常值不敏感(因为绝对值不会放大极端误差),结果的单位与原数据一致,容易解释。
- 缺点:在误差较大的情况下,惩罚力度较弱,可能无法反映模型的真实偏差。
示例
若实际值为 [10, 20, 30],预测值为 [12, 18, 33],则:
绝对误差为 [2, 2, 3],MAE = (2+2+3)/3 ≈ 2.33。
2. MSE(Mean Squared Error,均方误差)
定义
计算预测值与实际值之间平方误差的平均值,公式为:
![]()
特点
- 优点:对误差较大的样本(异常值)惩罚更严厉(平方放大误差),能更敏感地反映模型的偏差。
- 缺点:结果的单位是原数据单位的平方(例如原数据单位为 “元”,MSE 单位为 “元 ²”),解释性稍弱。
示例
沿用上述数据,平方误差为 [4, 4, 9],MSE = (4+4+9)/3 ≈ 5.67。
3. RMSE(Root Mean Squared Error,均方根误差)
定义
MSE 的平方根,公式为:
![]()
特点
- 优点:继承了 MSE 对异常值敏感的特性,同时结果的单位与原数据一致(解决了 MSE 单位的问题),是最常用的指标之一。
- 缺点:仍受异常值影响较大,计算时需注意数据中是否存在极端值。
| 指标 | 含义 | 特点 |
|---|---|---|
| MAE | 平均预测误差 | 容易理解,易受异常值影响小 |
| MSE | 平方误差平均值 | 放大大误差的惩罚 |
| RMSE | MSE 开平方 | 单位与目标一致,更直观 |
八、模型预测使用示例(可扩展)
你可以使用模型预测新的数据样本,例如:
sample = [[-0.05, 0.12, 0.03, -0.01, 0.09, -0.02, 0.01, 0.04, -0.03, 0.02]]
result = model.predict(sample)
print("预测结果为:", result)
九、总结
通过本案例你学到了:
🔹 如何使用 LinearRegression 构建回归模型
🔹 如何提取模型的系数与截距,解释变量关系
🔹 如何使用 R²、MAE、MSE、RMSE 评估回归模型
🔹 模型如何应用于新样本预测
完整代码:
结果:
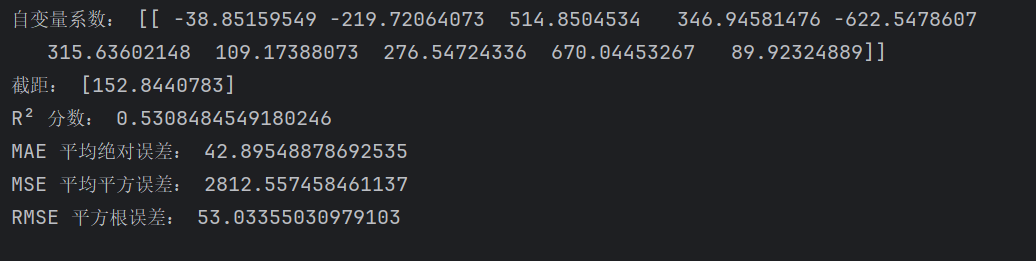
代码:
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.model_selection import train_test_split
data = pd.read_csv("糖尿病数据.csv")
X = data.drop('target',axis=1)
y = data[['target']]
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = LinearRegression()
model.fit(X_train,y_train)
# a:自变量系数
# b:截距
a = model.coef_
b = model.intercept_
print("自变量系数:",a)
print("截距:",b)
score = model.score(X_test,y_test)
print("R² 分数:", score)
y_pred = model.predict(X_test)
print("MAE 平均绝对误差:", mean_absolute_error(y_test, y_pred))
print("MSE 平均平方误差:", mean_squared_error(y_test, y_pred))
print("RMSE 平方根误差:", np.sqrt(mean_squared_error(y_test, y_pred)))

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 38
38 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)