python数据分析入门学习
目录
1. 为什么要学习数据分析
2. Numpy
3. Pandas
4. Pandas数据分析
5. 数据可视化
6. 实战练习
为什么要学习数据分析
Excel与Python对比
| 功能 | Excel | Python |
|---|---|---|
| 数据处理量 | 1万行以内 | 100万行以上 |
| 自动化 | 手动操作 | 代码自动化操作 |
数据分析使用python可自动化大量地处理数据
数据分析流程

Numpy高性能数值计算 Pandas表格数据处理 Matplotlib数据可视化
Anaconda
Anaconda下载: Anaconda
Anaconda是简化Python/R编程语言管理包和配置环境,开源的数据科学和机器学习的集成环境
Jupyter Notebook 与 Jupyter Lab区别
| 工具 | 适用场景 |
|---|---|
| Jupyter Notebook |
单文档,简单的交互任务 |
| Jupyter Lab |
多文档协做,复杂的开发工作流程,同时编写代码,运行终端 |
为什么使用Jupyter Notebook而不是使用python文件编写代码
Jupyter Notebook每个Cell的变量是全局变量 Markdown模型下 # 代表标题
Jupyter Notebook 可以跟代码进行交互,比python文件编写代码与数据交互更方便
Jupyter快捷键
| 命令 | 功能 |
|---|---|
| esc | 从输入模式推出到命令模式 |
| a | 在Cell上面再创建新的Cell |
| b | 在Cell下面再创建新的Cell |
| dd | 删除当前Cell |
| m | 切换到Markdown文本编辑模式 |
| y | 切换到code代码模式 |
| ctrl + 回车 | 运行Cell |
| shift + 回车 | 运行当前Cell并创建一个新Cell |
Numpy
概述 Numpy是Python科学计算与数值运行的基础包
ndarray多维
# 导包
import numpy as py
# 创建0为数组
arr = np.array(5)
# 创建1为数组
arr = np.array([1, 2, 3])
# 创建2为数组
arr = np.array([[1, 2],[3, 4]])当数组内数据是不同数据类型则转化为同类型 , 优先级(字符型>浮点型>整数型)
ndarray属性
# 创建3维数组
arr = np.array([ [[1, 2, 3],[4, 5, 6]], [[6, 5, 4],[3, 2, 1]] ])
# 输出数组形状
print(arr.shape)
# 输出数组维数
print(arr.ndim)
# 输出数组元素总个数
print(arr.size)
# 输出数组元素类型
print(arr.dtype)
# 输出数组的转置数组
print(arr.T)
# 输出数组单个元素内存
print(arr.itemsize)
# 输出数组总内存
print(arr.nbytes)
# 输出数组内存的存储方式
print(arr.flags)
# 执行以上代码,输出数组相关信息
(2, 2, 3) 3 12 int32 [ [[1, 6],[4, 3]], [[2, 5],[5,2]], [[3,4],[6 1]] ] 4 48
C_CONTIGUOUS : True F_CONTIGUOUS : False OWNDATA : True
WRITEABLE : True ALIGNED : True WRITEBACKIFCOPY : FalseALIGNED按硬件要求对齐 WRITEBACKIFCOPY延迟写回副本
OWNDATA表示拥有自己的数据内存 WRITEABLE表示允许修改元素值
C_CONTIGUOUS是C 风格连续存储行优先 F_CONTIGUOUS是Fortran 风格连续存储列优先
ndarray创建
基础创建
# 基础创建
list1 = [1, 2, 3]
# 创建一个数组
arr = np.array( list1 )
arr = np.array([1, 2, 3])
# 创建数组并定义数据类型
arr = np.array(list1, dtype=np.float64)数组复制
# 创建数组并复制赋值
arr1 = np.copy(arr)预定义形状
全0数组 全1数组 空值数组 填充数组
# 全0一维数组
arr = np.zeros(8, dtype=int)
# 全0二维数组
arr = np.zeros((2, 3),dtype=int)
# 全0复制格式数组
arr = np.zeros_like(arr)
# 全1一维数组
arr = np.ones(8, dtype=int)
# 全1二维数组
arr = np.ones((2, 3),dtype=int)
# 全1复制格式数组
arr = np.ones_like(arr)
# 空值一维数组
arr = np.empty(8, dtype=int)
# 空值二维数组
arr = np.empty((2, 3),dtype=int)
# 空值复制格式数组
arr = np.empty_like(arr)
# 填充一维数组
arr = np.full(8, 2025, dtype=int)
# 填充二维数组
arr = np.full((2, 3), 2025, dtype=int)
# 填充复制格式数组
arr = np.full_like(arr, 2026)empty函数不是生成随机数,,而是生成分配内存后保留在该内存原有的"垃圾值"
等差/线性/对数等分数列
# 等差间隔数列
# 参数类型 start,end+1,step 包左不包右
arr = np.arange(1, 10, 1)
# 输出
[1 2 3 4 5 6 7 8 9]
# 等间间隔数列
# 参数类型 start,end,step 包左包右
arr = np.linspace(0, 100, 5)
arr = np.arange(0, 101, 25)
# 输出
[ 0. 25. 50. 75. 100.]
[ 0 25 50 75 100]
# 对数间隔数列
# 参数类型 start,end,step 包左包右
arr = np.logspace(0,4,3,base=2)
# 输出
[ 1. 4. 16.]矩阵的创建
单位/对角矩阵
# 单位矩阵,3行3列
arr = np.eye(3, dtype=int)
arr = np.eye(3,3 dtype=int)
# 输出
[[1 0 0]
[0 1 0]
[0 0 1]]
# 单位矩阵,3行4列
arr = np.eye(3, 4, dtype=int)
# 输出
[[1 0 0]
[0 1 0]
[0 0 1]]
# 对角矩阵
arr = np.diag([1, 2, 3])
# 输出
[[1 0 0]
[0 2 0]
[0 0 3]]随机数值
均匀/正态分布/随机种子
# 随机[0,1)浮点数均匀分布,2行3列
arr = np.random.rand(2, 3)
# 随机指定[3,6)浮点数均匀分布,2行3列
arr = np.random.uniform(3, 6, (2, 3))
# 随机指定[3,6)整数均匀分布,2行3列
arr = np.random.randint(3, 6, (2, 3))
# 正态分布 (-3 3之间),2行3列
arr = np.random.randn(2, 3)
# 随机种子
np.random.seed(20)
arr = np.random.randint(1, 10, (2, 5))数据类型
布尔/整数/浮点/复数型
# 布尔型
arr = np.array([1, 0, 1],dtype='bool')
# 输出
[ True False True]
# 整数型
arr = np.array([1, 2, 3], dtype=np.int8)
# 输出
[1 2 3]
# 浮点型
arr = np.array([1, 2, 3], dtype=np.float64)
# 输出
[1. 2. 3.]
# 复数型
arr = np.array([1, 2, 3], dtype=np.complex128)
[1.+0.j 2.+0.j 3.+0.j]索引切片与运算
索引切片与slice函数运用
# 索引与切片,索引从0开始
# 创建一维随机数组
arr = np.random.randint(1, 100, 20)
# 取第11个元素
print(arr[:]) # 所有元素
print(arr[10]) # 第11个元素
print(arr[1:5]) # 1到4个元素 start:end+1 包左不包右
# 索引与切片,使用布尔索引
# 10以上的元素
print(arr[arr>10])
# 10到50的元素
print(arr[(arr>10) & (arr<50) ])
# 小于10或大于50的元素
print(arr[(arr<10) | (arr>50) ])
# slice切片函数
# start:end+1:step 起始,终点,步长 包左不包右
# 2到4的元素
print(arr[slice(2,5)])
# 2到9的元素,步长为2
print(arr[slice(2, 10, 2)])
print(arr[::-1]) # 反转
# 二维数组切片
arr = np.random.randint(1, 100, (4, 8))
# 切片二行3列数
print(arr[1, 2])
# 切片第二行2到4元素
print(arr[1,2:5])
# 大于50的数
print(arr[arr>50])
# 二行3到4列且大于50
print(arr[2,2:5][arr[2,2:5]>50])
# 二列3到4列且大于50
print(arr[2:3,2][arr[2:3,2]>50])矩阵运算
矩阵按位加减乘除,矩阵乘
# 同类型矩阵运算
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = np.array([[4, 5, 6], [7, 8, 9], [1, 2, 3]])
# 简单同位相加
print(a + b)
# 简单同位相减
print(a - b)
# 简单同位相乘
print(a * b)
# 简单同位相除
print(a / b)
# # 简单同位平方
print(a ** 2)
类型不同,若不可广播机制则报错
a = np.array([1, 2, 3]) # 1*3型
b = np.array([4], [5], [6]) # 3*1型
# 可广播相加
print(a+b)
[[5 6 7]
[6 7 8]
[7 8 9]]
# 可广播相乘
print(a*b)
[[ 4 8 12]
[ 5 10 15]
[ 6 12 18]]
# 矩阵乘@
print(a@b)Numpy常用函数
基本函数
平方sqrt 自然数指数exp 自然数对数log 三角sin cos 绝对值abs 指数power 取舍round
# 计算平方根,返回浮点数
list1 = np.array([1, 4, 9])
arr = np.sqrt(list1)
print(np.sqrt([1, 4, 9]))
# 计算自然数的指数
print(np.exp(1))
# 输出
2.718
# 计算自然对数
print(np.log(2.718))
# 输出
0.999896315728952
# 计算三角函数
print(np.sin(np.pi/2))
# 输出1.0
print(np.sin(1))
# 输出0.8414709848078965
print(np.cos(1))
# 输出0.5403023058681398
print(np.cos(np.pi))
# 输出-1.0
# 计算绝对值
print(np.abs(arr))
# 计算指数
print(np.power(arr,3))
# 四舍六入五凑偶
print(np.round([3.2, 4.5, 8.1]))
# 向上取整,向下取整
arr = np.array([1.6, 25.1, 81.7])
print(np.ceil(arr))
print(np.floor(arr))
# 检查缺失值
np.isnan([1, 2, np.nan, 3])统计函数
求和sum 计算平均值mean 计算中位数media 方差var 标准差std 最大值max 最小值min
最大值索引argmax 最小值索引argmin 计算分位数percentile 累积和cumsum 累积差cumprod
# 随机一维数组
arr = np.random.ranint(1, 20, 8)
# 求和
print(np.sum(arr))
# 平均值
print(np.mean(arr))
# 中位数 排序后奇数取中间,偶数取中间两个平均值 比较平均数和中位数
print(np.median(arr))
# 方差/标准差
print(np.var(arr))
print(np.std(arr))
# 最大值和最小值
print(np.max(arr), np.argmax(arr))
print(np.min(arr), np.argmin(arr))
# 分位数
print(np.percentile(arr,50))
44 47 64 67
# 百分之25
0.25*3=0.75
(47-44)*0.75+44=46.25
# 百分之80
3*0.8=2.4
(67-64)*0.4+64=65.2
# 累积和 累积积
arr = np.array([1, 2, 3])
print(np.cumsum(arr))
[1 3 6]
print(np.cumprod(arr))
[1 2 6]比较函数
大于greater 小于less 等于equal 与logical_and 或logical_or 非logical_not 至一真any 全真all
# 输出大于4的值
print(np.greater([3, 4, 5, 6, 7], 4))
# 输出小于4的值
print(np.less([3, 4, 5, 6, 7], 4))
# 输出等于4的值
print(np.equal([3, 4, 5, 6, 7], 4))
# 布尔值判断是否对等
print(np.equal([3, 4, 5, 6, 7], [4, 5, 6, 6, 8]))
# 逻辑并
print(np.logical_and([1, 0],[1, 1]))
# 逻辑或
print(np.logical_or([1, 0],[1, 1]))
# 逻辑非
print(np.logical_not([1, 0]))
# 检查元素是否至少有一个为True
print(np.any([0, 0, 0, 1]))
# 检查元素是否全为为True
print(np.all([0, 0, 0, 1]))自定义条件
自定义函数where 选择函数select
# 基础语法
print(np.where(条件,符合条件,不符合条件))
# 创建一维组
arr = np.array([1, 2, 3, 4, 5])
# arr大于3,输出arr,否则输出0
print(np.where(arr>3,arr,0))
[0 0 0 4 5]
# 创建一维组
arr = np.array([1,2,3,4,5])
# arr大于3,输出1,否则输出0
print(np.where(arr<3,1,0))
# 自定义函数
arr = np.random.randint(0, 101, 10)
print(np.where(score>=60,'及格','不及格'))
# 创建自定义函数,[0,60)不及格,[60,80)良好,[81,100]优秀
print(np.where(
score<60,'不及格',np.where(
score<80,'良好','优秀'
)
))
# select函数比where自定义函数简单
np.select(条件,返回结果)
print(np.select([score>80,(score>60)&(score<80),score<60,],['优秀', '良好', '不及格'],default=''未知))排序/去重/拼接/分割/调整函数
排序sort 去重unique 拼接concatenate 分割split 调整shape
# 创建一维数组
arr = np.random.randint(1,100,20)
# 直接打印并改变数值序列
arr.sort()
# print打印保留数值序列
print(np.sort(arr))
# 去重
print(np.unique(arr))
# 数组拼接
print(arr1+arr2)
print(np.concatenate((arr1,arr2)))
# 数组分割
# 能等分
print(np.split(arr,5))
# 不等分
print(np.split(arr,[6, 12, 18]))
# 调整形状
print(np.reshape(arr,[5,4]))NumPy科学计算综合练习
第一题 一周气温[ 28, 30, 29, 31, 32, 30, 29 ]分析
# 创建数组
temp = np.array([ 28, 30, 29, 31, 32, 30, 29 ])
# 最高气温
print(np.max(temp))
# 最低气温
print(np.min(temp))
# 平均气温,保留3位小数
print('%.3f'%np.mean(temp))
# 超30度气温
print(len(temp[temp>30]))
# 自定义条件判断
print(np.where(temp>30,1,0))
# 累加和
print(np.cumsum(np.where(temp>30,1,0))[-1])
# 非0计算
print(np.count_nonzeros(temps>30))第二题 学生成绩[ 85, 90, 78, 92, 88 ]分析
# 创建数组
score = np.array([ 85, 90, 78, 92, 88 ])
# 平均数
print(np.mean(score))
# 中位数
print(np.median(score))
# 标准差
print('%.3f'%np.std(score))
# 转为满分10分
print(score/10)第三题 A=[[1, 2], [3, 4]]和B=[[5, 6],[7, 8]]矩阵分析
# 创建矩阵
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6],[7, 8]])
# A + B
print(A+B)
# A * B
print(A*B)
# A@B
print(A@B)第四题 形状(3,4),范围[0,10)随机数组分析
# 随机种子创建随机数组
np.random.seed(0)
arr = np.random.randint(0, 10, (3, 4))
# 每列最大值,axis=0,轴为列
print(np.max(arr,axis=0))
# 每行最小值,axis=1,轴为行
print(np.min(arr,axis=1))
# 将奇数替换为-1
print(np.where(arr%2!=0,arr,-1))
# 布尔索引
arr[arr%2==1]=-1
print(arr)
第五题 数组变形
# 一维形状12数组,转为(3, 4)二维数组
arr = np.arange(1,13,1)
arr = np.reshape(arr, (3,4))
# 每行平均值
print(np.mean(arr,axis=1))
# 每行的和
print(np.sum(arr,axis=1))
# 每列平均值
print(np.mean(arr,axis=0))
# 转为一维数组
arr = np.reshape(arr, (12))
arr = np.reshape(arr, (arr.size))
arr = np.reshape(arr, (len(arr)))第六题 布尔索引
# 生成形状(5, 5),范围[0, 20)的随机数组
np.random.seed(0)
arr = np.random.randint(0, 20, (5, 5))
# 找出大于10的元素
arr[arr>10]
# 将大于10的替换为0
arr[arr>10]=0
print(np.where(arr > 10, arr, 0))第七题 统计函数应用
# 题目描述: 6个月销售额[120, 135, 110, 125, 130, 140]
# 生成数组
arr = np.array([120, 135, 110, 125, 130, 140])
# 总和
print(np.sum(arr))
# 均值
print("%.3f"%np.mean(arr))
# 方差
print("%.3f"%np.var(arr))
# 销售额最高月份
print(np.argmax(arr)+1)
# 销售额最第月份
print(np.argmin(arr)+1)第八题 数组拼接
# 题目描述: A = [1, 2, 3]和B = [4, 5, 6]
# 创建数组
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])
# A和B水平拼接
C = np.concatenate([A,B])
# A和B垂直拼接
print(np.reshapeC,(2,3))第九题 唯一值与排序
# 创建数组[2, 1, 2, 3, 1, 4, 3]
arr = np.array([2, 1, 2, 3, 1, 4, 3])
# 找出唯一值并排序
print(np.unique(arr))
# 计算每个唯一值出现次数
u_arr,counts = np.unique(arr, return_counts=True)
print(counts)
# for循环实现
counts = []
for i in range(len(u_arr)):
counts = counts + [len(arr[arr==u_arr[i]]))]第十题 综合应用
# 题目描述 5天销售额与成本为[20, 25, 22, 30, 28] [15, 18, 16, 22, 20]
# 创建数组
arr = np.array([20, 25, 22, 30, 28])
arr1 = np.array([15, 18, 16, 22, 20])
# 每天利润
arr2 = arr-arr1
# 利润平均值
np.mean(arr2)
# 利润标准差
np.std(arr2)
# 利润最高的天数
len(arr2[arr2==np.max(arr2)])
# 利润最高是第几天
for i in range(len(arr2)):
if arr2[i]==np.max(arr2):
print(i+1)Pandas
Pandas是数据读取,清洗,分析,统计,输出的高效工具,基于Numpy构建处理表格和混杂数据的python库.
Pandas简介
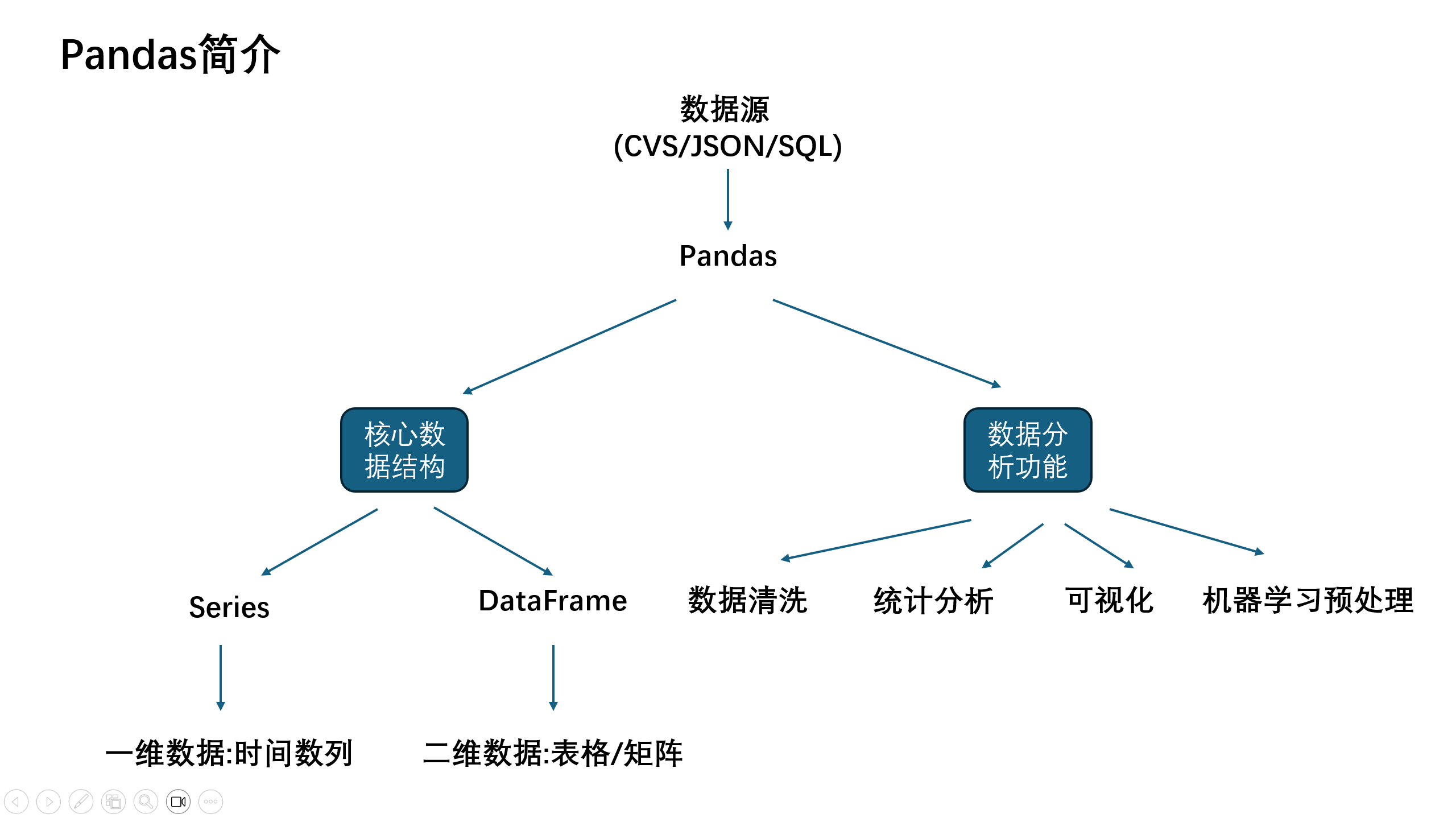
Series和DataFrame分析
| 数据类型 | Series | DataFrame |
|---|---|---|
| 维度 | 一维 | 二维 |
| 索引 | 单索引 | 行所以+列名 |
| 数据存储 | 同质化数据类型 | 各列可不同数据类型 |
| 类比 | Excel单列 | 整张Excel工作表 |
| 创建方法 | pd.Series([1, 2, 3]) | pd.DataFrame("列标签":{1, 2, 3}) |
Series
Series类似于Excel单列,有行索引,列标签
Series创建方法
自定义索引,标签创建Series
# 导入pandas包
import pandas as pd
# Series的创建
s = pd.Series([1,2,3,4,5])
0 1
1 2
2 3
3 4
4 5
# 自定义索引,定义标签name
s = pd.Series([1,2,3,4,5], index=['a','b','c','d','e'], name='月份')
a 1
b 2
c 3
d 4
e 5
Name: 月份, dtype: int64通过字典,Series创建Series
# 通过字典创建
s = pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5}, name='月份')
# 通过series创建
s = pd.Series(s, index=['a','b','c'])
a 1
b 2
c 3
Name: 月份, dtype: int64Series属性
index索引 values值 dtype/dtypes类型 shape形状 ndim维度 size个数 name标签
数组访问函数 loc[]显示索引 iloc[]隐式索引,位置访问 at[]索引访问 iat[]位置访问
s = pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5}, name='月份')
# 获取索引
print(s.index)
# 获取值
print(s.values)
# 获取数据类型
print(s.dtype)
# 获取标签
print(s.name)
# 获取形状
print(s.shape)
# 获取个数
print(s.size)
# 获取维度
print(s.ndim)
# 获取是否为空
print(s.empty)
# 访问数组函数
# 获取索引a值
print(s.loc['a'])
# 获取索引0值
print(s.iloc[0])
# 获取索引a到c
print(s.loc['a':'c'])
# 获取索引0到2
print(s.iloc[0:2])
# 获取索引a的值
print(s.at['a'])
# 获取索引0的值
print(s.iat[0])Series查看数据
s = pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5}, name='月份')
# 获取索引a的值
print(s['a'])
# 布尔索引
print(s[s<3])
# 获取前5行
print(s.head())
# 获取前3行
print(s.head(3))
# 获取后5行
print(s.tail())Series常用方法与统计
查看函数 head() tail() isin() isna()
统计函数 sum() mean() min() max() var() std() median() mode()众数
quantile()分位数 describe()显示常见统计信息(count mean std min 25% 50% 75% max)
排序于唯一值函数 value_counts()唯一值出现次数 count()非缺失值数量
nunique()唯一值个数 unique()去重后值的数组 drop_duplicates()去除重复项 sample()随机抽样 sort_index()索引排序 sort_values()值排序 replace()替换值 keys()返回索引
查看函数
import numpy as np
s = pd.Series({'a':1,'b':2,'c':np.nan,'d':None,'e':5}, name='月份')
# 查看函数
# 获取前3行
print(s.head(3))
# 获取后2行
print(s.tail(2))
# 描述
print(s.describe())
# 获取索引
print(s.keys())
# 获取索引
print(s.index)
# 判断值是否为空
print(s.isna())
# 判断值是否在列表中
print(s.isin([5,1,2]))统计函数
# 统计函数
s = pd.Series({'a':1,'b':2,'c':np.nan,'d':None,'e':5}, name='月份')
# 获取总和
print(s.sum())
# 获取平均值
print(s.mean())
# 获取中位数
print(s.median())
# 获取众数
print(s.mode())
# 获取标准差
print(s.std())
# 获取方差
print(s.var())
# 获取最小值
print(s.min())
# 获取最大值
print(s.max())
# 获取绝对值
print(s.abs())
# 获取乘积
print(s.prod())
# 获取累加
print(s.cumsum())
# 获取累乘
print(s.cumprod())
# 获取当前最大值
print(s.cummax())
# 获取当前最小值
print(s.cummin())
# 获取个数
print(s.count())
# 获取唯一值的个数
print(s.value_counts())
# 获取最小值和最小值索引
print(s.idxmax())
print(s.idxmin())
# 获取百分位数50%
print(s.quantile(0.5))
# 按值排序,不改变次序
print(s.rank())
# 获取唯一值个数
print(s.nunique())
# 获取唯一值,返回list
print(s.unique())
# 获取一个随机值
print(s.sample())
# 去重,返回Series
print(s.drop_duplicates())
# 按索引排序
prin(s.sort_index())
# 按值排序,改变次序
prin(s.sort_values())Series案例练习
第一题 学生成绩统计
# 题目描述 10人成绩[50,100]
# 创建Series数组
np.random.seed(42)
values = np.random.randint(0,101,10)
indexs = []
for i in range(1,11):
indexs.append('学生'+str(i))
scores = pd.Series(values, index=indexs)
# 平均分
print(scores.mean())
# 最高分
print(scores.max())
# 最低分
print(scores.min())
# 高于平均分人数
print(scores[scores>scores.mean()].count())
print(len(scores[scores>scores.mean()]))第二题 温度分析
# 题目描述 一周温度 [28, 31, 29, 32, 30, 27, 33]
# 创建Series数组
values = [28, 31, 29, 32, 30, 27, 33]
indexs = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']
temp = pd.Series(values, index=indexs, name='温度')
# 温度超过30度
print(temp[temp>30])
# 平均温度
print(temp.mean())
# 温度从高到低,升序False
print(temp.sort_values(ascending=False))
# 温度变化最大的两天
# diff前后两元素差
print(temp.diff().abs().nlargest(2))
# 或者
tem = temp.diff().abs()
print(tem.sort_values(ascending=False).keys()[:2].tolist())
print(tem.sort_values(ascending=False).index[:2].tolist())第三题 股票分析
# 题目描述 10个收盘价
# 创建Series数组
values = [102.3, 103.3, 105.2, 104.1, 106.5, 107.1, 106.3, 108.4, 109.4, 110.5]
indexs = pd.date_range('2023-01-01',periods=10)
prices = pd.Series(values, index=indexs, name='收盘价')
# 每日收益(当天/前天-1)
tem = prices.pct_change()
# 收益最高日期
print(tem.idmax())
# 收益最低日期
print(tem.idmin())
# 波动率收益标准差
print(tem.std())第四题 销售数据分析
# 题目描述 12个销售量
values = [120, 135, 145, 160, 155, 170, 180, 175, 190, 200, 210, 220]
indexs = pd.date_range('2025-01-01', periods=12, freq='ME')
sales = pd.Series(values, index=indexs, name='销售量')
# DE按天 WE按周 ME按月 QE按季 YE按年
# 季度平均销售
sales.resample('QS').mean() # Q按季重新采样,平均值
sales.resample('QS').sum() # Q按季重新采样,求和
# 销售最高月份
sales.idxmax()
# 月环比比上月增长量(同比比去年)
sales.pct_change()
# 连续增长超过两个月月份
tem = sales.pct_change()
tem[(tem>0).rolling(3).sum()==3].keys().tolist()第五题 每小时销售数据分析
# 题目描述 一天24小时销量额
# 创建Series数组
np.random.seed(42)
values = np.random.randint(0,100,24)
indexs = pd.date_range('2025-01-01', periods=24, freq='h')
h = pd.Series(values, index=indexs, name='销售额')
# 按天重采样,每日销售总额
d=h.resample('D').sum()
h.sum()
# 营业时间(8-22)和非营业时间销售额比
# 获取营业时间收益,三种方法
h.between_time('8:00','22:00').sum()
b = h[(h.index.hour>=8)&(h.index.hour<=22)]
mask = (h.index.hour>=8)&(h.index.hour<=22)
b = h[mask]
# 获取非营业时间收益,三种方法
nb = h.drop(b.index).sum()
nb = h[(h.index.hour<8)|(h.index.hour>22)].sum()
nb = h[~mask]
print(b.sum()/nb)
# 销售额最高的3销售
print(h.nlargest(3))
DataFrame
DataFrame类似于Excel整张工作表,有行索引和列名称索引
DataFrame创建方法
import numpy as np
import pandas as pd
# 通过Series创建DataFrame
s1 = pd.Series([1,2,3,4,5])
s2 = pd.Series([6, 7, 8, 9, 10])
df = pd.DataFrame({'第一列':s1, '第二列':s2})
# 通过字典创建
df = pd.DataFrame({ 'name':["tom", "jack","bob", "qia", "zul"],'age':[18,22,23,14,15],
'sex':['male', 'male', 'female', 'male', 'female']},
index=[1,2,3,4,5],columns=['name', 'sex', 'age'])
DataFrame属性
index values dtypes shape ndim size columns列标签 loc[] iloc[] at[] iat[] T转置
# 获取DataFrame信息
# 获取索引
print(df.index)
# 获取列标签
print(df.columns)
# 获取数据值
print(df.values)
# 获取行数和列数
print(df.shape)
# 获取数据类型
print(df.dtypes)
# 获取描述信息
print(df.describe())
# 获取转置
print(df.T)DataFram访问数据
# 获取单列数据
print(df.name)
print(df['name'])
print(df[['name', 'age']])
# 查看部分数据
df.head(3)
df.tail(3)
# 布尔索引
df[(df['age'] > 20) & (df.age < 30)]
# 数据采样
df.sample(3)
# 获取元素
# 通过索引获取行数据
print(df.loc[4]) # 获取key为4数据
print(df.iloc[3]) # 获取第4行数据
# 通过标签获取列数据
print(df.loc[:, 'name'])
print(df.iloc[:, 0])
# 获取单个数据
print(df.at[3, 'name'])
print(df.iat[2,0])
print(df.loc[3, 'name'])
print(df.iloc[2,0])
DataFrame常用方法与统计
isin() isna() mode() quantile() describe() drop_duplicates()去重 replace()替换值 sample() 随机采样 resample()重构 nlargest()返回最大n条数据 nsmallest 返回最小n条数据 duplicated()是否重复
# 默认显示前5行
df.head()
df.tail()
# 判断数据是否在集合中
df.isin(['jack',20])
# 检测数据是否为空
df.isna()
# 检测数据是否不为空
df.notna()
# 统计函数
# 求和
df.age.sum()
# 最大值
df['age'].max()
# 最小值
df['age'].min()
# 平均值
df.age.mean()
# 中位数
df.age.median()
# 标准差
df.age.std()
# 方差
df.age.var()
# 众数
df.age.mode()
# 50%分位数
df.age.quantile(0.5)
# 描述信息
df.describe()
# 每列个数
df.count()
# 每列的出现个数
df.value_counts()
# 每列的去重个数,DataFram
df.drop_duplicates()
# 检查是否重复
df.duplicated(subset='age')
# 替换
df.replace(15,16)
# 累加
df.cumsum()
# 累乘
df.age.cumprod()
# 累计最大
df.cummax()
# 每列的去重,list
df.age.unique()
# 每列的去重个数
df.age.nunique()
# 索引排序
df.age.sort_index()
# 值排序
df.sort_values(by=['name','age'],ascending=[True,False])
# 求最大值
df.nlargest(2,columns=['age'])DataFrame案列练习
第一题 学生成绩分析
# 题目描述 学生成绩数据
data = {'姓名':['张三','李四','王五','赵六', '钱七'],'数学':[85,95,88,78,95],'英语':[90,88,85,92,80],'物理':[75,80,88,85,90]}
# 创建DataFrame
df = pd.DataFrame(data)
# 每位学生总分
df['总分'] =df[['数学','英语','物理']].sum(axis=1)
# 每位学生平均分
df['平均分'] = df[['数学','英语','物理']].mean(axis=1)
# 数学高于90或英语高于85
df[(df['数学']>90)|(df['英语']>85)]
# 总分高到低的前三个
df.sort_values(by='总分',ascending=False).head(3)
df.nlargest(3,'总分')第二题 销售数据分析
# 题目描述: 销售数据
data = {'产品名称':['A','B','C','D'],'单价':[100,150,200,120],'销量':[50,30,20,40]}
# 创建DataFrame
df = pd.DataFrame(data)
# 每种产品销售额(销售额 = 单价 * 销量)
df['总销售额'] = df[['单价','销量']].prod(axis=1)
# 销售额最高产品
df.nlargest(1,'总销售额')
# 销售额从高到低
df.sort_values(by='总销售额',ascending=False)第三题 电商分析
# 题目描述 用户行为数据
data = {'用户ID':[101, 102, 103, 104, 105],'用户名':['Tom','Bob','Jack', 'Maike','Lucy'],'商品类别':['电子产品','服饰', '电子产品', '家居', '服饰'],'商品单价':[1200,300,800,150,200],'购买数量':[1,3,2,5,4]}
# 创建DataFrame
df = pd.DataFrame(data)
# 每位用户消费金额(消费金额 = 商品单价 * 购买数量)
df['消费金额'] = df[['商品单价','购买数量']].prod(axis=1)
# 输出消费金额最高用户
df.nlargest(1,'消费金额')
# 所有用户平均消费金额
print('%.2f'%df['消费金额'].mean())
# 电子产品总购买数量
df[df['商品类别']=='电子产品']['购买数量'].sum()Pandas数据分析
CSV和Excel区别
Excel:结构复杂, 以二进制(.xls)或 XML(.xlsx)格式存储
CSV: 结构简单,格式由逗号(制表符、分号)分隔的纯文本文件
数据导入/导出
CSV数据转成DataFrame导入导出
# CSV数据导入
import pandas as pd
# 将数据读入成DataFrame
df = pd.read_csv(r"data\employees.csv")
# CSV数据导出
df.to_csv(r"data\employees_out.csv", index=False)Json数据转成DataFrame导入导出
# 简单的json格式数据
df = pd.read_json(r"data\data1.json")
# 复杂的json格式数据
import json
with open(r"data\test.json", "r", encoding="utf-8") as f:
data = json.load(f)
df = pd.DataFrame(data['users'])数据处理
缺失值处理
缺失值查询
# 缺失值查询
import pandas as pd
import numpy as np
s = pd.Series([0, 1, np.nan, 3, 4, np.nan])
print(s.isna())
print(s.isnull())
print(s.isna().sum())
df = pd.DataFrame([[1,pd.NA,2],[2,np.nan,5],[None,4,6],[7,8,9]],columns=['第一列','第二列','第三列'])
print(df.isna())
print(df.isnull())
# 按行统计缺失值
print(df.isna().sum(axis=1))
# 按列统计缺失值
print(df.isna().sum(axis=0))缺失值类型 np.nan(不是一个值1除以0) None(空值) pd.NA(空值)
缺失值删除
# 删除缺失值
print(s.dropna())
# 删除含缺失值的一整行
print(df.dropna())
# 删除所有值都是缺失值的行
print(df.dropna(how="all"))
# 如果有n个数不是缺失值,就保留
print(df.dropna(thresh=2))
# 删除缺失值所在列
print(df.dropna(axis=1))
# 指定删除某列缺失值
print(df.dropna(subset=['第一列']))缺失值填充
# 填充缺失值
df = pd.read_csv(r"data\weather_withna.csv")
df.isna().sum(axis=0)
# 固定值填充,字典填充
print(df.fillna({'temp_max':20, 'wind':2.5}))
# 统计值填充
print(df.fillna(df[['temp_max','wind']].mean()))
# 前向front填充
print(df.ffill())
# 后向back填充
print(df.bfill())重复数据处理
查询/删除重复数据
# 查询/删除重复数据
data = {
'name':['Tom','张三','Jack','张三','张三'],
'age':[20,21,22,21,21],
'city':['上海','北京','广东','北京','北京']
}
df = pd.DataFrame(data)
# 一整行重复标记True
print(df.duplicated())
# 删除重复
print(df.drop_duplicates())
# 根据列去重
print(df.drop_duplicates(subset=['name']))
# 保留后面重复数据
print(df.drop_duplicates(subset=['name'],keep='last'))数据类型转换
# 数据类型转换
df['age'] = df['age'].astype('int16')
# 转为分类
df['gender'] = df['gender'].astype('category')
# map函数映射,转为布尔
df['is_male'] = df['gender'].map({'Male':True,'Female':False})数据变形
# 数据变形
data = {
"ID":[1,2],
"name":["张 三","王 五"],
'Math':[85,98],
'English':[92,86],
'Chinese':[83,99]
}
df = pd.DataFrame(data)
# 转置
df.T
# 宽表转长表
df = pd.melt(df,id_vars=['ID','name'],var_name='subject',value_name='score').sort_values('name')
# 长表转宽表
pd.pivot(df,index=['ID','name'],columns='subject',values='score')
# 分列
df[['姓','名']] = df['name'].str.split(" ",expand=True)
# 分裂,数据类型转换案例练习
df = pd.read_csv(r"data\sleep.csv")
df = df[['person_id','blood_pressure']]
df[['high','low',]] = df['blood_pressure'].str.split("/",expand=True)
df.info()
df['high'] = df['high'].astype('int64')
df['low'] = df['low'].astype('int64')
df.high.mean()
df.low.mean()数据分箱
# 数据分箱pd.cut(x,bins,labels)
import pandas as pd
df = pd.read_csv(r"data\employees.csv")
df = df.head(10)[['employee_id','salary']]
# 对salary分箱,bin表示多少个箱子
pd.cut(df['salary'],bins=2).value_counts()
# 自定义区间
df['收入范围'] = pd.cut(df['salary'],bins=[0,10000,20000,30000],labels=['低','中','高'])
# 等人数分箱
pd.qcut(df['salary'],q=3).value_counts()
分箱练习
# 统计练习
df = pd.read_csv(r"data\sleep.csv")
df = df.head(10)[['person_id','gender','sleep_quality']]
# 数值统计先分箱
df['睡眠质量'] =pd.cut(df['sleep_quality'],bins=3,labels=['差','中','好'])
df['睡眠质量'].value_counts()
# 字符串统计
df['gender'] = df['gender'].astype('category')
df['gender'].value_counts()
# 转换函数 rename() set_index() reset_index
df = pd.DataFrame({'name':['Tom','Jack','July'],'age':[20,21,22],'gender':['Male','Male','Female']})
# 设置索引
df.set_index('name',inplace=True)
# 重置索引
df.reset_index(inplace=True)
# 重命名列名与索引
df.rename(columns={'name':'姓名'},index={0:4},inplace=True)
df.index=[0,1,2]
df.columns = ['姓名','年龄','性别']时间数据处理
时间戳相关属性
# 时间戳
import pandas as pd
d = pd.Timestamp('2019-01-01 10:22')
# 获取时间戳信息
print(d.date)
# 获取时间戳的年月日时分秒
print(d.year)
print(d.month)
print(d.day)
print(d.hour)
print(d.minute)
print(d.second)
# 获取时间戳的季度
print(d.quarter)
# 获取时间戳的星期几
print(d.day_name())
# 判断时间戳是否是月初
print(d.is_month_start)
# 获取时间戳是否是月末
print(d.is_month_end)
# 转换为天数
print(d.to_period("D"))
# 转换为季度
print(d.to_period("Q"))转换时间戳数据类型
# 字符串转换为时间戳
d = pd.to_datetime('20250607220620')
# dataFrame转换为时间戳
df = pd.DataFrame({'sales':[10,20,30],'date':["20250607","20250608","20250609"]})
df['datetime']=pd.to_datetime(df['date'])
# 查看数据类型信息
print(df.info())
# dt列表的时间选择器
print(df['datetime'].dt.day_name())
# CSV日期转换
df = pd.read_csv(r"data\weather.csv",parse_dates=['date'])
# 方法一,parse_dates自动解析转换
df['date'].dt.day_name()
# 方法二,pd.to_datetime()类型转换
df['datetime'] = pd.to_datetime(df['date'])
df['datetime'].dt.day_name()时间戳索引并访问
# 日期数据作为索引
df.set_index('date',inplace=True)
df.loc["2012-01-01":"2012-01-05"]时间间隔delta
# 时间间隔
d1 = pd.Timestamp('2017-06-07')
d2 = pd.Timestamp('2023-06-07')
# 获取时间间隔
d3 = d2-d1
# 获取时间隔做索引访问
df["delta"] = df['date'] - df['date'][0]
df.set_index(["delta"], inplace=True)
print(df.loc['0 days':'9 days'])时间序列创建
# 创建时间序列
# 以频率freq从start到end创建
days = pd.date_range(start='2019-01-01',end='2019-01-31',freq='D')
# 以频率freq从start创建31个元素
days = pd.date_range('2019-01-01',periods=31,freq='D')
重采样
# 重采样
df = pd.read_csv(r"data\weather.csv",parse_dates=['date'])
df.set_index('date',inplace=True)
# 对temp_max和temp_min重采样,取平均
df[['temp_max','temp_min']].resample('YE').mean()分组聚合
# 分组聚合df.groupby('分组的字段')['聚合的字段'].聚合函数
df = pd.read_csv(r"data\employees.csv")
# 检查缺失值
print(df['department_id'].isna().sum())
# 删除缺失值
df.dropna(subset=['department_id'],inplace=True)
# id从float转为int
df['department_id']=df['department_id'].astype('int64')
# 不同部门平均工资
# 查看分组
df.groupby('department_id').groups
# 查看具体分组数据
df.groupby('department_id').get_group(10)
# 聚合
df = df.groupby('department_id')[['salary']].mean()
# 保留两位小数
df['salary'] = df['salary'].map('{:.2f}'.format)
df['salary'] = df['salary'].round(2)
df.reset_index(inplace=True)
# 排序输出
df.sort_values('salary',ascending=False,inplace=True)
# 分组聚合练习
df = pd.read_csv(r"data\employees.csv")
# 不同部门不同岗位平均薪资
df = df.groupby(['department_id','job_id'])[['salary']].mean().round(1).sort_values('salary',ascending=False).reset_index()数据分析案例练习
数据分析步骤 1.导包 2.数据导入 3.数据清洗 4.数据特征构造 5.数据分析 6.数据可视化
题目一 企鹅数据分析
# 1.导包
import pandas as pd
# 2.数据导入
df = pd.read_csv(r"data\penguins.csv")
df.head()
df.info()
# 3.数据清洗
# 缺失值检查
print(df.isna().sum())
df.dropna(inplace=True)
len(df)
# 4.数据特征构造
# 性别数据类型转换为类别
df['sex'] = df['sex'].astype('category')
# 喙的长宽比
df['bill_ratio'] = df['bill_length_mm']/df['bill_depth_mm']
# 5.数据分析
# 数据分箱,分为三个等级
df['mass_level'] = pd.cut(df['body_mass_g'],bins=3,labels=['低','中','高'])
# 体重各级数量
df['mass_level'].value_counts()
# 按岛屿,性别分组分析
df.groupby(['island','sex']).agg({'body_mass_g':['mean','count']})
第二题 睡眠质量分析
# 1.导包
import pandas as pd
# 2.数据导入
df = pd.read_csv(r"C:\Users\16774\Downloads\课件及代码\课件及代码\代码\data\sleep.csv")
df.head()
df.info()
df.describe()
# 3.数据清洗
# 缺失值检查
print(df.isna().sum())
df['sleep_disorder'].value_counts()
df.drop(columns='sleep_disorder',inplace=True)
# 4.数据特征构造
# 类型转换
df['gender'] = df['gender'].astype('category')
df['occupation'] = df['occupation'].astype('category')
df['bmi_category'] = df['bmi_category'].astype('category')
df[['high','low']] = df['blood_pressure'].str.split('/',expand=True)
# 睡眠质量分箱
df['quality_level'] = pd.cut(df['sleep_quality'],bins=3,labels=['差','中','优'])
# 年龄分箱
df['age_level'] = pd.cut(df['age'],bins=3,labels=['青少年','中年','老年'])
# 5.数据分析
# 查看bin类型数
print(df['bmi_category'].value_counts())
# 根据age_level,bim分组的睡眠质量
df.groupby(['age_level','bmi_category']).agg({'sleep_quality':['mean'],'stress_level':['mean']})数据可视化
可视化作用 分析趋势 发现错误 突出对比
绘图要素 标题 坐标轴 图形 图例 数据标签
可视化工具 Matplotib灵活基础 Seaborn美观繁琐 Pandas可视化-快捷样式简单
图形 折线图plot 柱状图bar 条形图barh 饼图pie 散点图scatter 箱型图boxplot
折线图-趋势
# 绘制折线图
# 导入matplotlib包
import matplotlib.pyplot as plt
# 导入字体rcParams包
from matplotlib import rcParams
# 设置字体
# 方法一
rcParams['font.family'] = 'SimHei'
# 方法二
rcParams['font.sans-serif'] = ['SimHei']
# 创建图标,设置大小
plt.figure(figsize=(10,5))
month = ['1月','2月','3月','4月','5月']
sales = [100,150,300,250,500]
# 绘制折线图
plt.plot(month,sales,label='产品A',color='blue',linewidth=2,linestyle='-',marker='o')
# 设置标题
plt.title('2025年销售趋势', fontsize=20, color='blue')
# 添加标签
plt.xlabel('月份', fontsize=15, color='black')
plt.ylabel('销售额(万元)', fontsize=15, color='black')
# 添加图例
plt.legend('销售额(万元)', loc='upper left')
plt.legend('销售额(万元)', loc='lower right')
# 添加网格
plt.grid(axis='y')
plt.grid(axis='x')
plt.grid(True,alpha=0.3,color='black',linestyle='--')
# 设置刻度字体大小,与旋转
plt.xticks(fontsize=15,rotation=0)
plt.yticks(fontsize=15,rotation=0)
# 设置y轴范围
plt.ylim(0,600)
# 每个数据点上显示数值
for x,y in zip(month,sales):
plt.text(x,y+10,str(y),ha='center',va='bottom',fontsize=15)
# 显示图形
plt.show()柱状图-对比
柱状图代码与折线图相似 width控制宽度,没有marker属性
# 绘制柱状图
plt.bar(subjects,scores,label='成绩',color='blue',width=0.6)条形图代码与柱状图相似 先传y轴,后传x轴,端点值显示注意yx顺序
# 绘制条形图
plt.barh(countries,gdp,label='GDP',color='blue')
# 每个数据点上显示数值,注意yx顺序
for y,x in zip(countries,gdp):
plt.text(x,y,f'{x}',ha='left',va='center',fontsize=15)
饼图-组成占比
数据准备
# 饼图
# 导入matplotlib包
import matplotlib.pyplot as plt
# 导入字体rcParams包
from matplotlib import rcParams
# 设置字体
# 方法一
rcParams['font.family'] = 'SimHei'
# 方法二
rcParams['font.sans-serif'] = ['SimHei']
# 创建图标,设置大小
plt.figure(figsize=(10,5))
things = ['学习', '睡觉', '工作', '娱乐', '运动']
times = [5, 8, 5, 2, 4]绘制饼图
# 绘制饼图
plt.pie(times,labels=things,autopct='%.1f%%',startangle=90,colors=['#66b3ff','#ff9999', '#99ff99', '#ff4499', '#c2c2f0']shadow=True)
绘制环形图
# 绘制环形图,wedgeprops占半径百分比,pctdistance占比数离原点距离
plt.pie(times,labels=things,autopct='%.1f%%',startangle=90,colors=['#66b3ff','#ff9999', '#99ff99', '#ff4499', '#c2c2f0'],wedgeprops={'width':0.5},pctdistance=0.6,shadow=True)标题/图例
# 设置标题
plt.title('一天时间分配', fontsize=20, color='blue')
# 添加图例,1.05超出右边界5%,1与上边界对齐
plt.legend(['学习', '睡觉', '工作', '娱乐', '运动'], bbox_to_anchor=(1.05, 1))散点图-相关性
# 绘制散点图
# 导入matplotlib包
import matplotlib.pyplot as plt
# 导入字体rcParams包
from matplotlib import rcParams
import random
# 设置字体
# 方法一
rcParams['font.family'] = 'SimHei'
# 方法二
rcParams['font.sans-serif'] = ['SimHei']
# 创建图标,设置大小
plt.figure(figsize=(10,6))
# 数据准备
x = []
y = []
for i in range(1000):
tmp = random.uniform(0,10)
x.append(tmp)
tmp2 = 2*tmp + random.gauss(0,2)
y.append(tmp2)
# 绘制散点图
plt.scatter(x,y,label='映射',color='blue',alpha=0.5,s=20)
# 设置标题
plt.title('x与y变量映射', fontsize=20, color='blue')
# 添加标签
plt.xlabel('x变量', fontsize=15, color='black')
plt.ylabel('y变量', fontsize=15, color='black')
# 添加图例
plt.legend('映射', loc='upper left')
plt.legend('映射', loc='lower right')
# 添加网格
plt.grid(axis='y')
plt.grid(axis='x')
plt.grid(True,alpha=0.3,color='black',linestyle='--')
# 设置刻度字体大小,与旋转
plt.xticks(fontsize=15,rotation=0)
plt.yticks(fontsize=15,rotation=0)
# 设置y轴范围
plt.ylim(0,30)
# 绘制直线两个横坐标[0,10],两个纵坐标[0,20]
plt.plot([0,10],[0,20],color='orange',linewidth=2)
# 每个数据点上显示数值
# for x,y in zip(x,y):
# plt.text(x,y,str(y),ha='center',va='bottom',fontsize=15)
# 显示图形
plt.show()箱线图-数据分布与异常
IQR=Q3-Q1 上边缘Q3+1.5*IQR 下边缘Q3-1.5*IQR 异常值,超出上边缘和下边缘
# 导包
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'SimHei'
# 数据准备
data = {
'语文': [80, 90, 85, 95, 80, 90, 85, 95, 72, 90, 85, 95],
'数学': [75, 85, 90, 80, 75, 85, 90, 80, 75, 85, 90, 80],
'英语': [90, 85, 95, 80, 90, 85, 95, 80, 90, 85, 95, 80],
}
# 准备画布
plt.figure(figsize=(10, 6))
# 绘图
plt.boxplot(data.values(),tick_labels=data.keys())
# 标题
plt.title("各科成绩")
# 坐标标签
plt.xlabel('分数')
plt.ylabel('科目')
# 网格
plt.grid(True,axis='y',alpha=0.3,color='black',linestyle='--')
# y范围
plt.ylim(70,100)
# 显示
plt.show()多个图的绘制方法
# 多个图的绘制方法
import matplotlib.pyplot as plt
month=['1','2','3','4']
sales=[100,150,80,130]
# 创建子图,行列索引
f1=plt.subplot(2,2,1)
f1.plot(month,sales)
f2=plt.subplot(222)
f2.bar(month,sales)
f3=plt.subplot(2,2,3)
f3.scatter(month, sales)
f4 = plt.subplot(2,2,4)
f4.barh(month, sales)绘图案例练习
# 绘图案例练习
# 题目 温度分析
import matplotlib.pyplot as plt
from matplotlib import rcParams
import pandas as pd
# 1.设置字体
rcParams['font.family'] = 'SimHei'
# 2.导入数据
df = pd.read_csv(r'C:\Users\16774\Downloads\课件及代码\课件及代码\代码\data\weather.csv')
df.head()
# 绘制气温的趋势变化图
df['date'] = pd.to_datetime(df['date'])
df = df[df['date'].dt.year == 2015]
df.info()
# 最高,最低气温的趋势变化图
plt.figure(figsize=(10,10))
plt.plot(df['date'],df['temp_max'],label='最高气温')
plt.plot(df['date'],df['temp_min'],label='最低气温')
plt.title('2015年气温变化趋势')
plt.xlabel('月份')
plt.ylabel('气温')
plt.legend()
# 绘制平均气温的趋势变化图
df['temp_mean'] = (df['temp_max'] + df['temp_min']) / 2
plt.figure(figsize=(10,10))
plt.plot(df['date'],df['temp_mean'],label='平均气温')
plt.title('2015年平均气温变化趋势')
plt.xlabel('月份')
plt.ylabel('气温')
plt.legend()
# 绘制降水量直方图
plt.figure(figsize=(10,10))
# 绘制直方图,分箱绘制
plt.hist(df['precipitation'],bins=5)
plt.title('2015年降水量直方图')
plt.xlabel('降水量')
plt.ylabel('频数')
plt.show()seaborn-各图形绘制
导包数据准备
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 设置字体
rcParams['font.family'] = 'SimHei'
penguins = pd.read_csv(r'C:\Users\16774\Downloads\课件及代码\课件及代码\代码\data\penguins.csv')
penguins.dropna(inplace=True)
penguins.info()
penguins.head()直方图 箱线图 散点图 点图 条形图 核密度估计图 估计图
# 直方图
sns.histplot(data=penguins,x='species')
# 绘制箱线图
sns.boxplot(data=penguins,x='species',y='flipper_length_mm')
# 散点图
sns.scatterplot(data=penguins,x='bill_length_mm',y='bill_depth_mm',hue='species')
# 绘制点图
sns.pointplot(data=penguins,x='species',y='flipper_length_mm')
# 绘制条形图
sns.barplot(data=penguins,x='species',y='flipper_length_mm')
# 核密度估计图
sns.kdeplot(data=penguins,x='flipper_length_mm')
# 估计图
sns.ecdfplot(data=penguins,x='flipper_length_mm')直方图+核密度估计图
# 直方图+核密度估计
sns.histplot(data=penguins,x='bill_length_mm', kde=True)计数图 蜂窝图 二维核密度估计图 成对关系图
# 计数图,适应不连续区间,与直方图类似
sns.countplot(data=penguins,x='island')
# 蜂窝图
sns.jointplot(data=penguins,x='body_mass_g',y='flipper_length_mm',kind='hex')
# 二维核密度估计图
sns.kdeplot(data=penguins,x='body_mass_g',y='flipper_length_mm')
# 成对关系图
sns.pairplot(data=penguins,hue='species')
实战练习
数据分析流程
采集数据->确定分析方向->导入数据->数据清洗->数据分析->数据可视化
一 数据类型
|
字段名 |
含义 |
说明 |
|
city |
城市 |
房屋所在的城市名称,例如“合肥”、“重庆”等。 |
|
address |
详细地址 |
房屋的具体位置,包含街道、交叉口等信息。 |
|
area |
面积 |
房屋的面积,单位为平方米(㎡)。 |
|
floor |
楼层 |
房屋所在的楼层信息,例如“中层(共18层)”。 |
|
name |
小区名称 |
房屋所在的小区或楼盘名称。 |
|
price |
价格 |
房屋的总价,单位为“万”或“元”。 |
|
province |
省份 |
房屋所在的省份或直辖市名称。 |
|
rooms |
户型 |
房屋的户型结构,例如“3室2厅”。 |
|
toward |
朝向 |
房屋的朝向,例如“南北向”、“南向”等。 |
|
unit |
单价 |
房屋的单价,单位为“元/㎡”。 |
|
year |
建造年份 |
房屋的建造年份,例如“2013年建”。 |
|
origin_url |
原始链接 |
房屋信息的来源网页链接。 |
二 分析方向
|
编号 |
问题 |
分析主题 |
分析目标 |
分组字段 |
指标/方法 |
|
A1 |
哪些变量最影响房价?面积、楼层、房间数哪个影响更大? |
特征相关性 |
了解房屋各特征对房价的线性影响 |
无 |
皮尔逊相关系数 |
|
A2 |
全国房价总体分布是怎样的?是否存在极端值? |
描述性统计 |
概览数值型字段的分布特征 |
无 |
平均数/中位数/四分位数/标准差 |
|
A3 |
哪些城市房价最高?直辖市与非直辖市差异如何? |
城市对比 |
比较不同城市房价水平 |
city |
均价/单价中位数/箱线图 |
|
A4 |
高价房在面积、楼层等方面有什么特征? |
价格分层 |
识别不同价位房屋特征差异 |
价格分段(低中高) |
列联表/卡方检验 |
|
A5 |
哪种户型最受欢迎?三室比两室贵多少? |
户型分析 |
分析不同户型的市场表现 |
rooms |
占比/平均单价/溢价率 |
|
A6 |
南北向是否真比单一朝向贵?贵多少? |
朝向溢价 |
评估不同朝向的价格差异 |
toward |
方差分析/多重比较 |
|
A7 |
新房比10年老房贵多少?折旧规律如何? |
楼龄效应 |
研究建筑年份对房价的影响 |
year分段(5年间隔) |
趋势线/回归分析 |
|
A8 |
哪些区域交易最活跃?新区和老城区哪个更贵? |
区域热度 |
识别各城市热门交易区域 |
address(提取区域关键词) |
交易量/价格增长率 |
|
A9 |
哪个面积段的性价比最高?超大户型有溢价吗? |
面积区间 |
分析不同面积段的价格特征 |
area分段(50㎡间隔) |
密度图/价格梯度 |
|
A10 |
中层真的比高层贵吗?差价是多少? |
楼层差异 |
比较不同楼层的价格表现 |
floor(高中低层) |
Kruskal-Wallis检验 |
|
A11 |
直辖市房价是否显著更高?单价和总价差异如何? |
直辖市vs非直辖市 |
对比直辖市与非直辖市的房价差异 |
province |
独立样本t检验/曼-惠特尼U检验 |
三 练习
1 导入库
# 1.导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rcParams
rcParams['font.sans-serif'] = ['SimHei']2 导入数据
# 导入数据
df = pd.read_csv(r"data\house_sales.csv")3 数据概览
# 数据概览
# 总记录数
print(len(df))
# 列数
print(len(df.columns))
# 数据信息
df.head()
df.info()4 数据清洗
缺失值 重复值 异常值
# 检查是否有缺失值
df.isna().sum()
df.dropna(inplace=True)
# 检查是否有缺失值
df.duplicated().sum()
df.drop_duplicates(inplace=True)
print(len(df))
# 面积数据类型转换
df['area'] = df['area'].str.replace('㎡', '').astype(float)
# 售价数据类型转换
df['price'] = df['price'].str.replace('万', '').astype(float)
# 朝向数据类型转换
df['toward'] = df['toward'].astype('category')
# 单价数据类型转换
df['unit'] = df['unit'].str.replace('元/㎡','').astype('float')
# 建造类型年数据类型转换
df['year'] = df['year'].str.replace('年建', '').astype('int')
# 异常值处理
# 房屋面积的异常处理
df = df[(df['area']<600)&(df['area']>20)]
# 售价的异常处理
Q1 = df['price'].quantile(0.25)
Q3 = df['price'].quantile(0.75)
IQR = Q3 - Q1
df = df[(df['price']>Q1-1.5*IQR)&(df['price']<Q3+1.5*IQR)]5 新数据特征构造
# 地区district
df['district'] = df['address'].str.split('-').str[0]
# 楼层的类型floor_type
# df['floor_type'] = df['floor'].str.split('(').str[0]
def fun1(str1):
if pd.isna(str1):
return '未知'
elif '低' in str1:
return '低楼层'
elif '中' in str1:
return '中楼层'
elif '高' in str1:
return '高楼层'
else:
return '未知'
df['floor_type2'] = df['floor'].apply(fun1).astype('category')
# 是否直辖市zxs
# def fun2(str2):
# return True if str2 in ['北京', '上海', '天津', '重庆'] else False
df['zxs'] = df['city'].apply(lambda x: 1 if x in ['北京', '上海', '天津', '重庆'] else 0)
# 卧室数量bedrooms
df['bedrooms'] = df['rooms'].str.split('室').str[0].astype(int)
# 客厅数量livingrooms
# df['livingrooms'] = df['room'].str.split('室').str[1].str.split('厅').str[0].astype(int)
# 正则表达式
df['livingrooms'] = df['rooms'].str.extract(r'(\d+)厅').astype(int)
# 楼龄building_age
df['building_age'] = 2025 - df['year']
# 价格分段price_labels
df['price_labels'] = pd.cut(df['price'], bins=4, labels=['低价', '中价', '高价', '豪华'])6 问题分析和可视化
问题A1 - 特质相关性 哪些变量最影响房价?面积、楼层、房间数哪个影响更大?
皮尔逊相关系数
# 选择数值型特征
# 数值间的相关性
a = df[['price', 'area', 'unit', 'building_age']].corr()
a['price'].sort_values(ascending=False)[1:]
# 绘制相关性矩阵
plt.figure(figsize=(10, 6))
sns.heatmap(a, annot=True, cmap='coolwarm')
plt.title('房屋特征相关性矩阵')
# 自适布局
plt.tight_layout()问题A2 - 描述性统计 全国房价总体分布是怎样的?是否存在极端值?
# 房价分布直方图
plt.figure(figsize=(10, 6))
# 方法一
plt.hist(df['price'], bins=6)
# 方法二
sns.histplot(df['price'], bins=6, kde=True)问题A6 - 朝向溢价 南北向是否真比单一朝向贵?贵多少?
# 数据准备
df['toward'].value_counts()
df.groupby('toward').agg({
'price': ['mean','median'],
'unit': 'median',
'building_age':'mean'
})
# 数据可视化
plt.figure(figsize=(10, 6))
sns.boxplot(x='toward', y='price', data=df)
plt.tight_layout()
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)