线程池多反应堆服务器webserver(c++)
爱编程的大丙。
线程池多反应堆服务器webserver
前言
参考:爱编程的大丙
一、项目框架
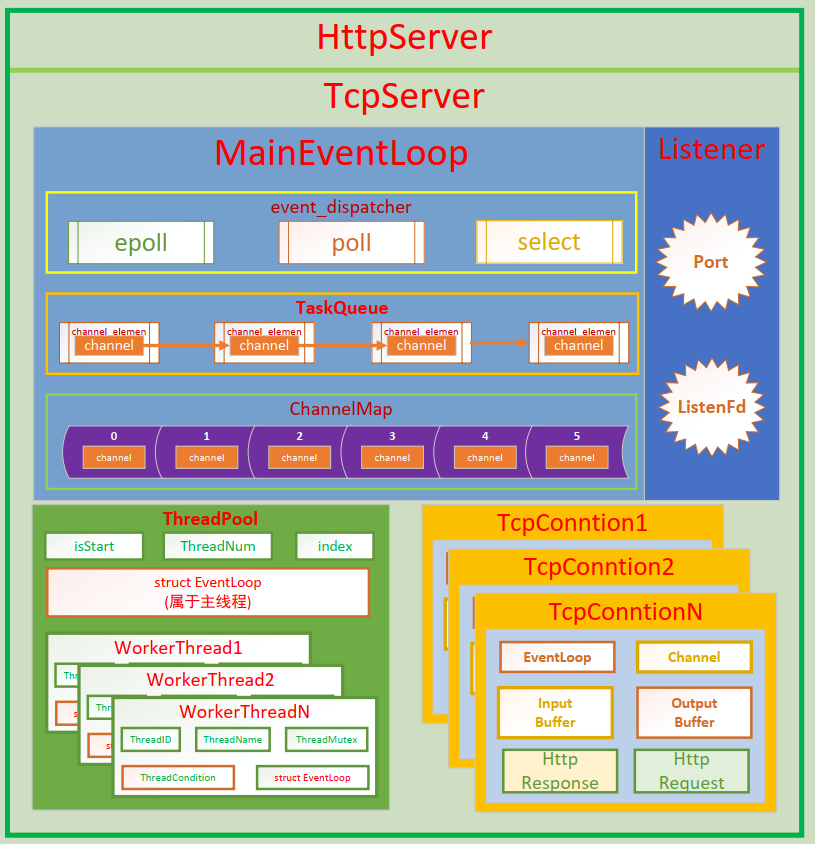
Dispatcher类
Dispatcher类:基类,接口类,同子类(select、poll、epoll)实现多态。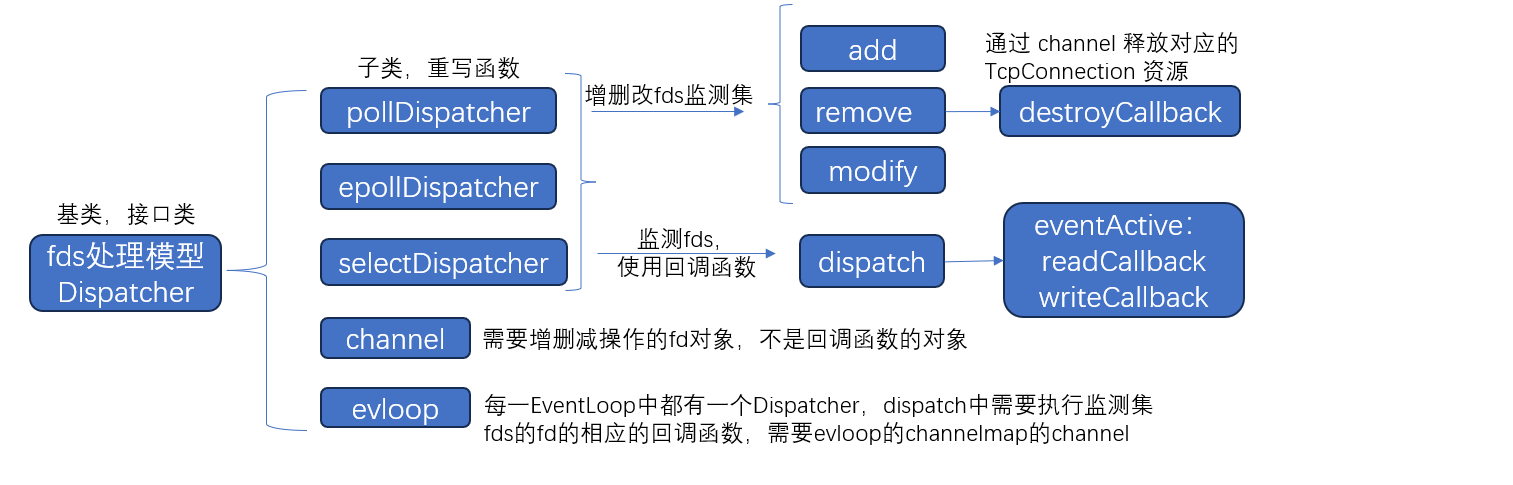
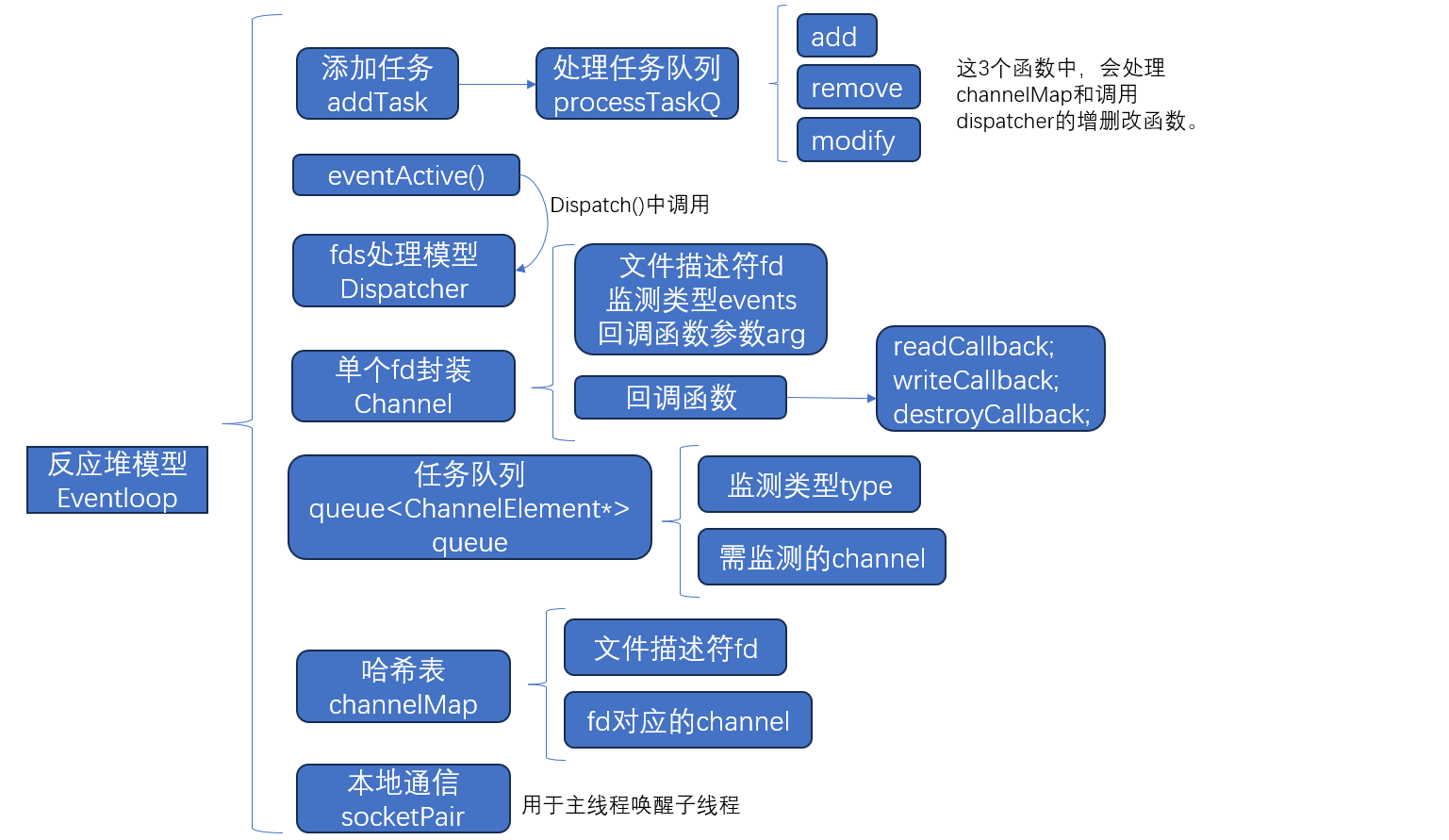
反应堆模型
反应堆模型:提供处理fd的方法。按理说,每个channel的回调函数可以不同,但是此项目只有两类fd:①lfd,监听fd,是tcp/httpServer的主线程使用,用于监听新的连接事件cfd,将cfd交给线程池的子线程处理;②cfd,socket通信fd,主要是线程池中的子线程处理http通信的分析和回应。
对于lfd(只有一个lfd),其只有readcallback,就是将新cfd交给线程池。
对于cfd,其有read、write、destroycallback,3个回调函数,虽然有多个cfd,每个cfd要处理的内容是一致的,即:
readcallback读取客户端http请求,并进行分析和组织回应,断开连接;
writecallback读取writebuffer中的http回应数据进行发送;
destroycallback删除对应的Tcpconnection对象。
所以每个cfd的3个回调函数其实都是一样的,所以在Tcpconnection中,只需要定义3个回调函数就行。
多线程/线程池
多线程/线程池:多线程使用eventloop,使得单反应堆模型变成多反应堆模型,因为不是所以的子线程共用一个任务队列,所以自主控制线程数量的操作还需分析。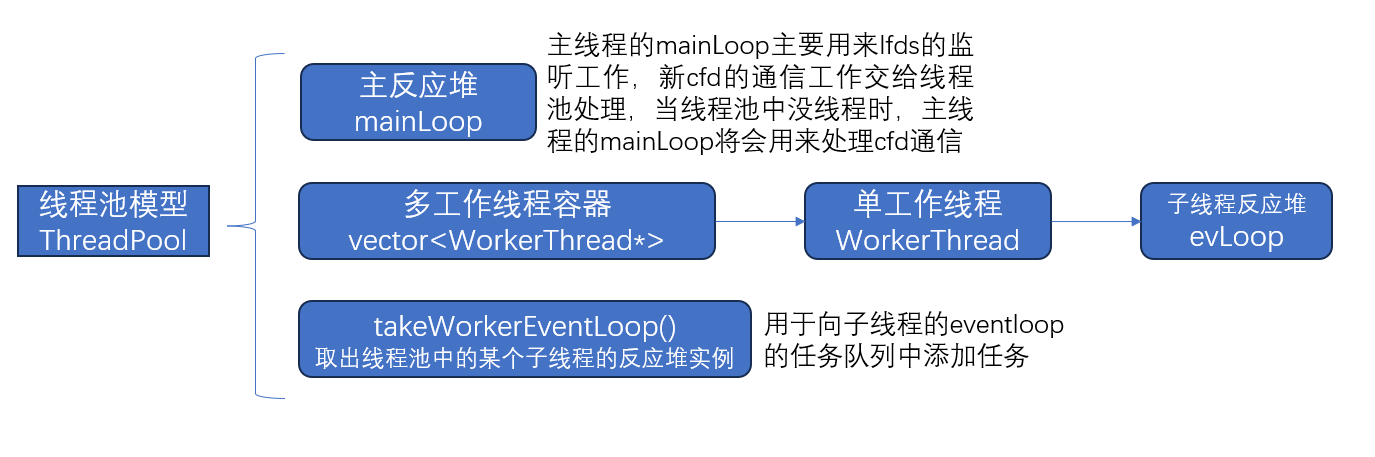
tcp服务器
tcp服务器:基础框架。http服务器就是在tcpServer的基础上使用了http通信协议。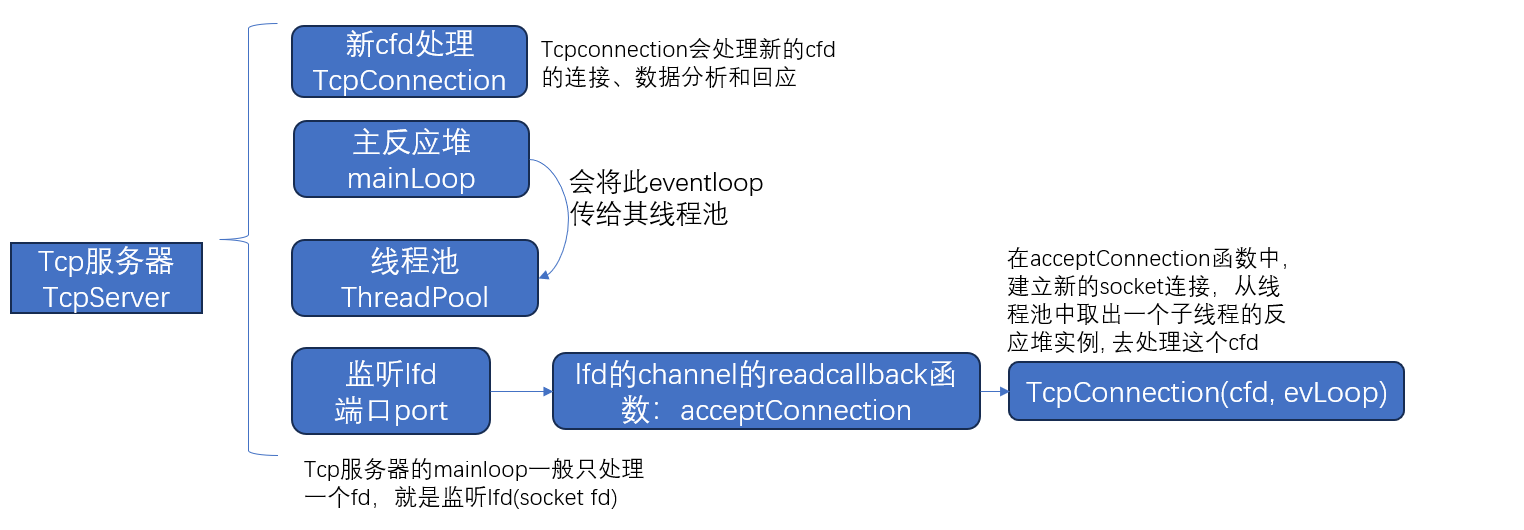
buffer
buffer:数据存储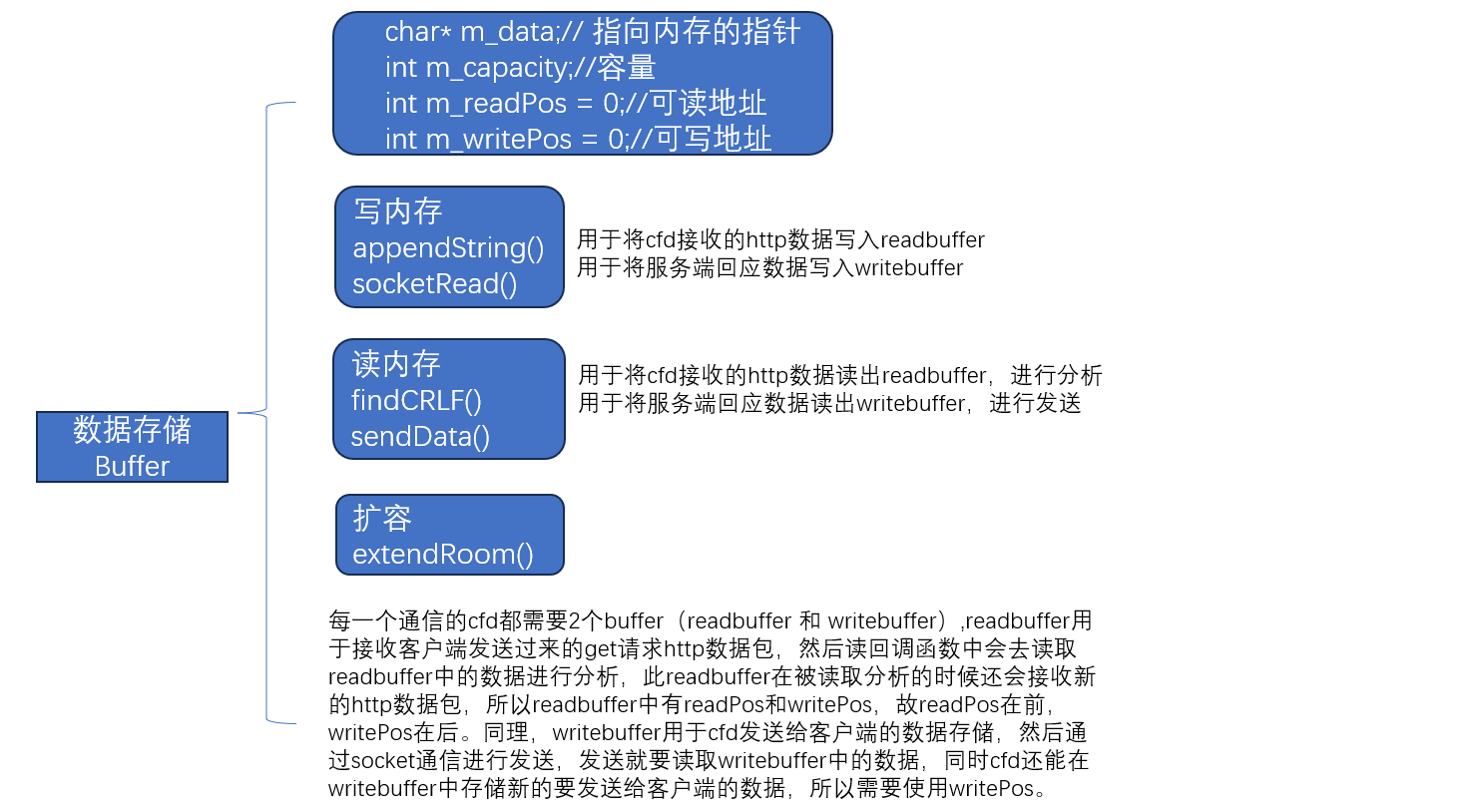
HttpRequest
HttpRequest:分析http请求,组织回应response
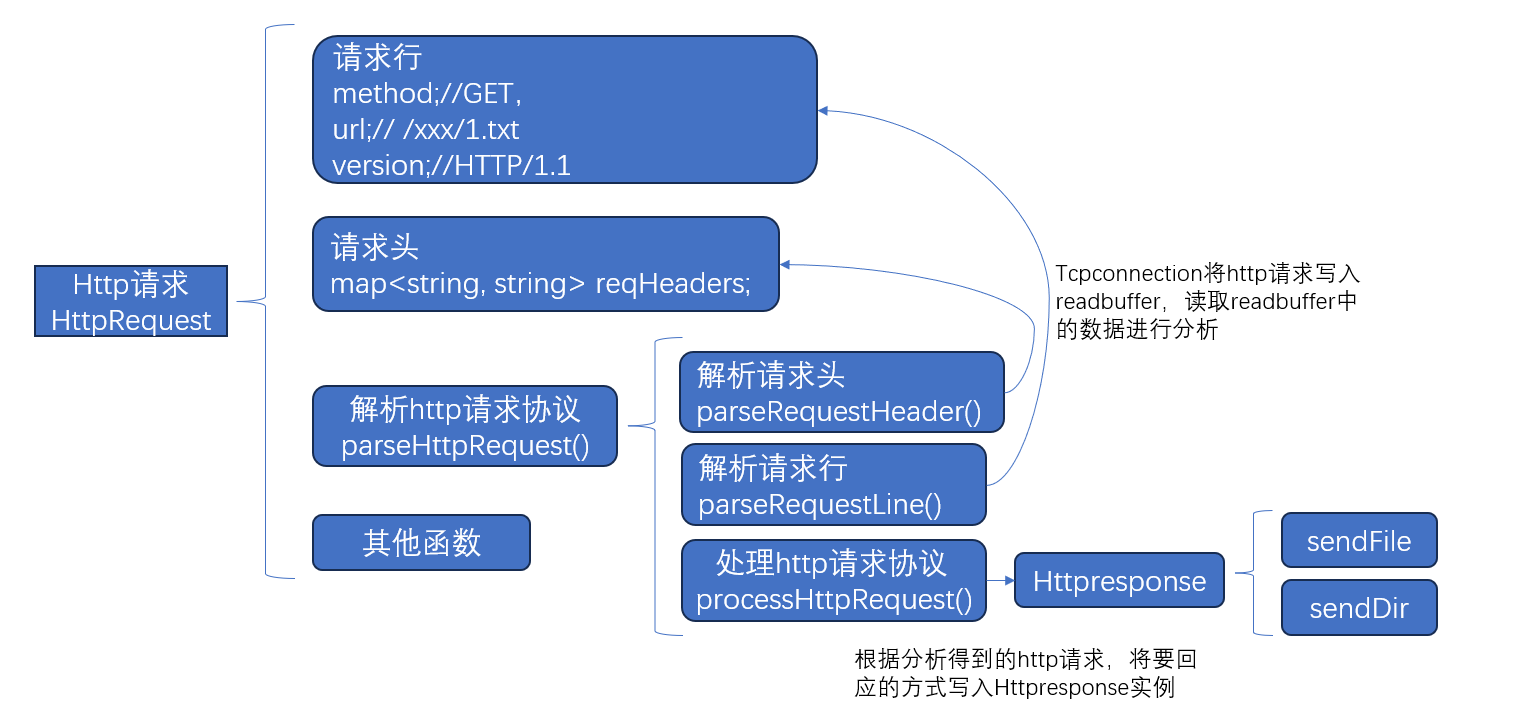
因为只考虑了“get” 请求,所以没有分析数据体的代码,后续可以添加对“post” 请求,需要读取数据体,这里有个一问题,就是readbuffer的大小受限,一旦“post” 传输的数据较大,webserver的内存不够,buffer扩容时会报错,所以需要限制“post” 请求发送的数据大小,使用分批发送。
HttpResponse
HttpResponse:根据httprequest分析得到的HttpResponse进行http回应数据的组织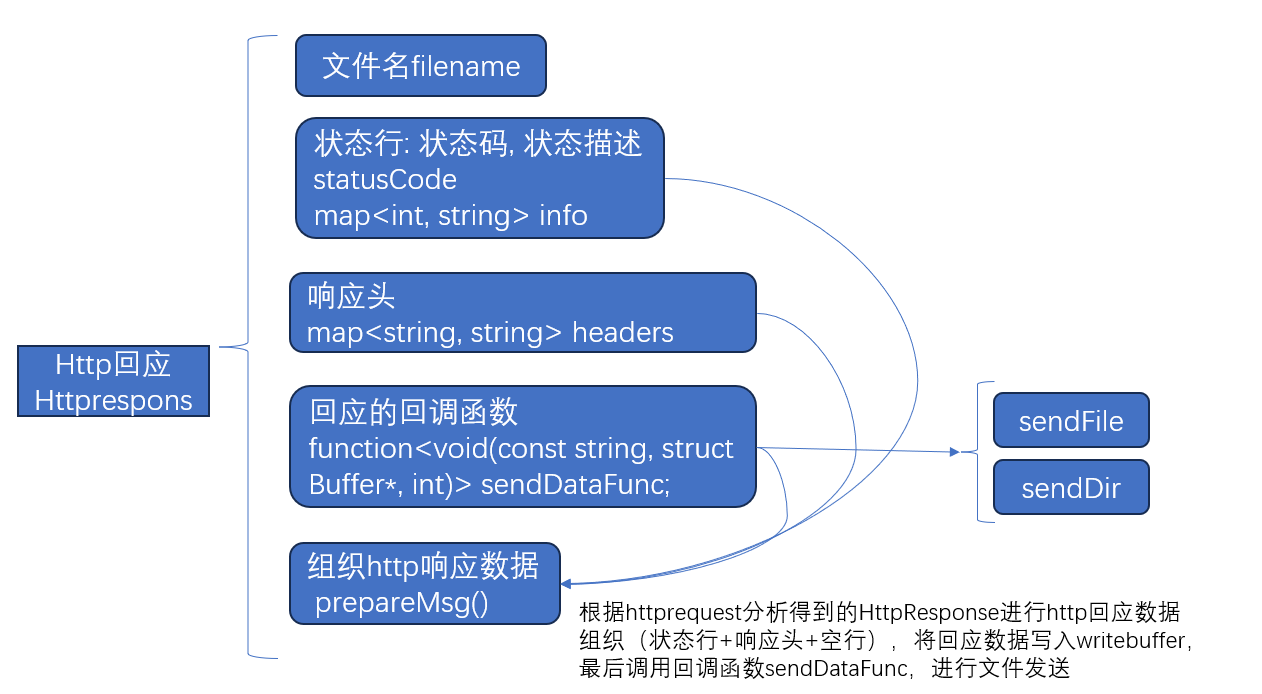
TcpConnection
TcpConnection:IO处理
每一个新的cfd 都会结合一个子线程,使用一个Tcpconnection,当此cfd断开连接,那就是 delet tcpconnection。Tcpconnection就是将一个cfd添加到子线程的evloop中,让此子线程处理此cfd。
二、 Dispatcher类
Dispatcher类:基类,接口类,同子类(select、poll、epoll)实现多态。
Dispatcher.h :
#pragma once
#include "Channel.h"
#include "EventLoop.h"
#include <string>
using namespace std;
class EventLoop;
//参数的优化:
//原本这些虚函数是有参数的,但是将这些参数作为该类Dispatcher的成员变量,就无需进行函数传参
//成员函数可以直接访问。对于class EventLoop* evLoop,每一EventLoop中都有一个Dispatcher,
//所以对于一个Dispatcher,其EventLoop是不变的,所以在构造函数中直接初始化即可,而对于
//class Channel* channel,其代表不同的fd,所以是可变的,所以需要相应的内联函数进行修改
class Dispatcher
{
public:
Dispatcher(EventLoop* evloop);
virtual ~Dispatcher();
// 添加add(class Channel* channel, class EventLoop* evLoop);
//virtual int add() = 0;写成纯虚函数也行,此时Dispatcher是抽象类,无法创建对象
virtual int add();
// 删除remove(class Channel* channel, class EventLoop* evLoop);
virtual int remove();
// 修改modify(class Channel* channel, class EventLoop* evLoop);
virtual int modify();
// 事件监测dispatch(class EventLoop* evLoop, int timeout); // 单位: s
virtual int dispatch(int timeout = 2); // 单位: s
inline void setChannel(Channel* channel)
{
m_channel = channel;
}
protected:
string m_name = string();//名字初始化为空字符串
Channel* m_channel;
EventLoop* m_evLoop; //dispatch中需要执行相应的回调函数,需要evloop的channelmap的channel
};
三、EventLoop反应堆模型
反应堆模型:提供处理fd的方法。按理说,每个channel的回调函数可以不同,但是此项目只有两类fd:①lfd,监听fd,是tcp/httpServer的主线程使用,用于监听新的连接事件cfd,将cfd交给线程池的子线程处理;②cfd,socket通信fd,主要是线程池中的子线程处理http通信的分析和回应。
对于lfd(只有一个lfd),其只有readcallback,就是将新cfd交给线程池。
对于cfd,其有read、write、destroycallback,3个回调函数,虽然有多个cfd,每个cfd要处理的内容是一致的,即:
readcallback读取客户端http请求,并进行分析和组织回应,断开连接;
writecallback读取writebuffer中的http回应数据进行发送;
destroycallback删除对应的Tcpconnection对象。
所以每个cfd的3个回调函数其实都是一样的,所以在Tcpconnection中,只需要定义3个回调函数就行。
EventLoop.h:
#pragma once
#include "Dispatcher.h"
#include "Channel.h"
#include <thread>
#include <queue>
#include <map>
#include <mutex>
using namespace std;
// 处理该节点中的channel的方式
enum class ElemType:char{ADD, DELETE, MODIFY};
// 定义任务队列的节点
struct ChannelElement
{
ElemType type; // 如何处理该节点中的channel
Channel* channel;
};
class Dispatcher;//Dispatcher和EventLoop相互包含,所以需要在类中定义之前进行类外定义
class EventLoop
{
public:
EventLoop();
EventLoop(const string threadName);
~EventLoop();//每个线程中都有一个evloop,线程结束,evloop结束,直接回收该线程的所有资源,故此析构函数无需执行什么。
// 启动反应堆模型,evloop创建者调用
int run();//启动了processTaskQ和dispather.dispath()
// 处理被激活的文件fd,调用read、write回调函数
int eventActive(int fd, int event);
// 添加任务到任务队列,主线程或子线程都会调用
int addTask(struct Channel* channel, ElemType type);
// 处理任务队列中的任务,应该只有本线程才会调用,可以是private
int processTaskQ();
// 处理dispatcher中的节点和channelMap
int add(Channel* channel);
int remove(Channel* channel);
int modify(Channel* channel);
// 释放channel
int freeChannel(Channel* channel);
int readMessage();//bind时使用,应该只有本线程才会调用,可以是private
// 返回线程ID
inline thread::id getThreadID()
{
return m_threadID;
}
inline string getThreadName()
{
return m_threadName;
}
static int readLocalMessage(void* arg);// 普通函数指针使用,应该只有本线程才会调用,可以是private
private:
void taskWakeup();
private:
bool m_isQuit;
// 该指针指向子类的实例 epoll, poll, select
Dispatcher* m_dispatcher;
// 任务队列
queue<ChannelElement*> m_taskQ; //如果是* 指针那就需要new
// map
map<int, Channel*> m_channelMap;
// 线程id, name, mutex
thread::id m_threadID;
string m_threadName;
mutex m_mutex;
int m_socketPair[2]; // 存储本地通信的fd 通过socketpair 初始化
};
在 int EventLoop::addTask(Channel* channel, ElemType type)函数中:
// 处理节点
/*
* 细节:
* 1. 对于链表节点的添加: 可能是当前线程也可能是其他线程(主线程)
* 1). 修改fd的事件, 当前子线程发起, 当前子线程处理
* 2). 添加新的fd, 添加任务节点的操作是由主线程发起的
* 2. 不能让主线程处理任务队列, 需要由当前的子线程取处理
*/
if (m_threadID == this_thread::get_id())
{
// 当前线程的eventloop执行addtask函数,由当前eventloop中的processTaskQ函数处理
//不使用taskWakeup()是因为不确定run函数是否运行,只有run()函数执行了,taskWakeup()函数才能调用
processTaskQ();
}
else
{
// 主线程 -- 告诉子线程处理任务队列中的任务
// 1. 子线程在工作 2. 子线程被阻塞了:select, poll, epoll
//主线程添加新的cfd,需要交给子线程的eventloop进行处理,无法直接调用子线程的processTaskQ()函数,只能强制“唤醒”
// 子线程,让子线程自动调用自己的processTaskQ()函数,(每个run函数中都会调用processTaskQ()函数)
taskWakeup();
}
四、多线程/线程池
多线程/线程池:多线程使用eventloop,使得单反应堆模型变成多反应堆模型,因为不是所以的子线程共用一个任务队列,所以自主控制线程数量的操作还需分析。
workerthread.h
#pragma once
#include <thread>
#include <mutex>
#include <condition_variable>
#include "EventLoop.h"
using namespace std;
// 定义子线程对应的结构体
class WorkerThread
{
public:
WorkerThread(int index);
~WorkerThread();
// 启动线程
void run();//启动了evloop.run()
inline EventLoop* getEventLoop()
{
return m_evLoop;
}
private:
void running();
private:
thread* m_thread; // 保存线程的实例
thread::id m_threadID; // ID
string m_name;
mutex m_mutex; // 互斥锁
condition_variable m_cond; // 条件变量
EventLoop* m_evLoop; // 反应堆模型
};
threadpool.h
#pragma once
#include "EventLoop.h"
#include <stdbool.h>
#include "WorkerThread.h"
#include <vector>
using namespace std;
// 定义线程池
class ThreadPool
{
public:
ThreadPool(EventLoop* mainLoop, int count);
~ThreadPool();
// 启动线程池
void run();//启动workerThread.run
// 取出线程池中的某个子线程的反应堆实例
EventLoop* takeWorkerEventLoop();
private:
// 主线程的反应堆模型,在takeWorkerEventLoop可被调用。
EventLoop* m_mainLoop;
bool m_isStart;
int m_threadNum;
vector<WorkerThread*> m_workerThreads;
int m_index;
};
五、tcp服务器
tcp服务器:基础框架。http服务器就是在tcpServer的基础上使用了http通信协议。
Tcpserver.h:
#pragma once
#include "EventLoop.h"
#include "ThreadPool.h"
class TcpServer
{
public:
TcpServer(unsigned short port, int threadNum);
// 初始化监听,初始化m_lfd和m_port
void setListen();
// 启动服务器
void run();
static int acceptConnection(void* arg);
private:
int m_threadNum;//threadPool中使用
EventLoop* m_mainLoop;//threadPool中也会使用
ThreadPool* m_threadPool;
int m_lfd;
unsigned short m_port;
};
六、buffer
buffer:数据存储
buffer.h
#pragma once
#include <string>
using namespace std;
//每一个通信的cfd都需要2个buffer(readbuffer 和 writebuffer),readbuffer用于接收客户端发送过来的get请求http数据包,
// 然后读回调函数中回去读取readbuffer中的数据进行分析,此readbuffer在被读取分析的时候还会接收新的http数据包,所以
// readbuffer中有readPos和writePos,故readPos在前,writePos在后。
// 同理,
// writebuffer用于cfd发送给客户端的数据存储,然后通过socket通信进行发送,发送就要读取writebuffer中的数据,同时cfd
// 还能在writebuffer中存储新的要发送给客户端的数据,所以需要使用writePos。
class Buffer
{
public:
Buffer(int size);
~Buffer();
// 扩容
void extendRoom(int size);
// 得到剩余的可写的内存容量
inline int writeableSize()
{
return m_capacity - m_writePos;
}
// 得到剩余的可读的内存容量
inline int readableSize()
{
return m_writePos - m_readPos;
}
// 写内存 1. 直接写 2. 接收套接字数据
int appendString(const char* data, int size);
int appendString(const char* data);
int appendString(const string data);
int socketRead(int fd);
// 根据\r\n取出一行, 找到其在数据块中的位置, 返回该位置
char* findCRLF();
// 发送数据
int sendData(int socket); // 指向内存的指针
// 得到读数据的起始位置
inline char* data()
{
return m_data + m_readPos;
}
inline int readPosIncrease(int count)
{
m_readPos += count;
return m_readPos;
}
private:
char* m_data;// 指向内存的指针
int m_capacity;
int m_readPos = 0;//相对data的起始地址而言,可读地址:data+readPos
int m_writePos = 0;//可写地址:data+writePos
};
在void Buffer::extendRoom(int size)函数中,有三种情况:
①剩余的内存够用 - 不需要扩容
②内存需要合并才够用 - 不需要扩容: 剩余的可写的内存 + 已读的内存 > size
③内存不够用 - 扩容,除了①②情况外就只有③了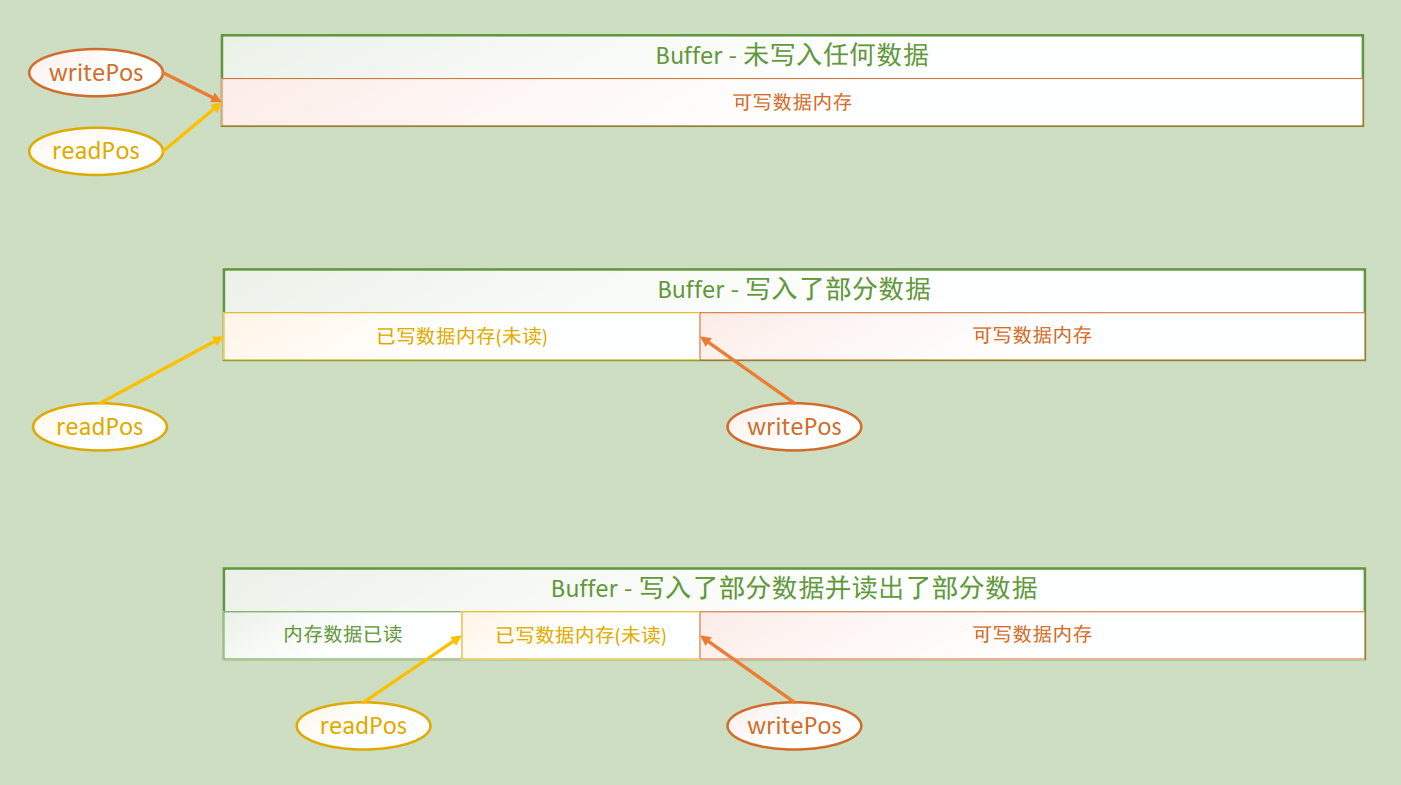
七、HttpRequest
HttpRequest:分析http请求,组织回应response
HttpRequest.h
#pragma once
#include "Buffer.h"
#include <stdbool.h>
#include "HttpResponse.h"
#include <map>
using namespace std;
// 当前的解析状态
enum class PrecessState:char
{
ParseReqLine, //请求行
ParseReqHeaders, //请求头
ParseReqBody, //请求数据块
ParseReqDone //完成
};
// 定义http请求结构体
class HttpRequest
{
public:
HttpRequest();
~HttpRequest();
// 重置
void reset();
// 添加请求头
void addHeader(const string key, const string value);
// 根据key得到请求头的value
string getHeader(const string key);
// 解析请求行
bool parseRequestLine(Buffer* readBuf);
// 解析请求头
bool parseRequestHeader(Buffer* readBuf);
// 解析http请求协议
bool parseHttpRequest(Buffer* readBuf, HttpResponse* response, Buffer* sendBuf, int socket);
// 处理http请求协议,判断客户端需要什么文件
bool processHttpRequest(HttpResponse* response);
// 解码字符串
string decodeMsg(string from);
const string getFileType(const string name);
static void sendDir(string dirName, Buffer* sendBuf, int cfd);
static void sendFile(string dirName, Buffer* sendBuf, int cfd);
inline void setMethod(string method)//function<void(string)>使用
{
m_method = method;
}
inline void seturl(string url)
{
m_url = url;
}
inline void setVersion(string version)//function<void(string)>使用
{
m_version = version;
}
// 获取处理状态
inline PrecessState getState()
{
return m_curState;
}
inline void setState(PrecessState state)//function<void(string)>使用
{
m_curState = state;
}
private:
char* splitRequestLine(const char* start, const char* end,
const char* sub, function<void(string)> callback);
int hexToDec(char c);
private:
// 请求行:GET /xxx/1.txt HTTP/1.1
string m_method;//GET
string m_url;// /xxx/1.txt
string m_version;//HTTP/1.1
map<string, string> m_reqHeaders;
PrecessState m_curState;
};
八、HttpResponse
HttpResponse:根据httprequest分析得到的HttpResponse进行http回应数据的组织
HttpResponse.h
#pragma once
#include "Buffer.h"
#include <map>
#include <functional>
using namespace std;
// 定义状态码枚举
enum class StatusCode
{
Unknown,
OK = 200,
MovedPermanently = 301,
MovedTemporarily = 302,
BadRequest = 400,
NotFound = 404
};
// 定义结构体
class HttpResponse
{
public:
HttpResponse();
~HttpResponse();
function<void(const string, struct Buffer*, int)> sendDataFunc;
// 添加响应头
void addHeader(const string key, const string value);
// 组织http响应数据
void prepareMsg(Buffer* sendBuf, int socket);
inline void setFileName(string name)
{
m_fileName = name;
}
inline void setStatusCode(StatusCode code)
{
m_statusCode = code;
}
private:
// 状态行: 状态码, 状态描述
StatusCode m_statusCode;
string m_fileName;
// 响应头 - 键值对
map<string, string> m_headers;
// 定义状态码和描述的对应关系
const map<int, string> m_info = {
{200, "OK"},
{301, "MovedPermanently"},
{302, "MovedTemporarily"},
{400, "BadRequest"},
{404, "NotFound"},
};
};
九、TcpConnection
TcpConnection:IO处理
TcpConnection.h
#pragma once
#include "EventLoop.h"
#include "Buffer.h"
#include "Channel.h"
#include "HttpRequest.h"
#include "HttpResponse.h"
//#define MSG_SEND_AUTO
class TcpConnection
{
public:
TcpConnection(int fd, EventLoop* evloop);
~TcpConnection();
static int processRead(void* arg);
static int processWrite(void* arg);
static int destroy(void* arg);
private:
string m_name;
EventLoop* m_evLoop;
Channel* m_channel;
Buffer* m_readBuf;
Buffer* m_writeBuf;
// http 协议
HttpRequest* m_request;
HttpResponse* m_response;
};
知识点
1、std::function
参考链接:https://blog.csdn.net/2301_76564925/article/details/147784710
操作模板
#include <functional>
function<return-type(arg1-type...)> fname = target
std::function是C++11标准库中引入的通用函数包装器模板,定义在<functional>头文件中。它可以存储、复制和调用任何可调用对象(如普通函数、lambda表达式、函数对象、成员函数指针等),并通过类型擦除机制提供统一的调用接口。
类型擦除
隐藏可调用对象的具体类型,仅保留函数签名(返回类型和参数列表),例如std::function<int(int, int)>可存储任何接受两个int参数并返回int的可调用对象。
支持的调用对象类型
①普通函数和函数指针:
int add(int a, int b) { return a + b; }
int main() {
// 存储普通函数
std::function<int(int, int)> func1 = add;
std::cout << func1(3, 5) << std::endl; // 输出: 8
}
②Lambda表达式(含捕获):
// 存储lambda表达式
std::function<int(int)> func2 = [](int x) { return x * x; };
std::cout << func2(4) << std::endl; // 输出: 16
③函数对象(重载operator()的类实例):这里的 Subtract 类就是一个函数对象,通过重载 () 运算符,使得它的对象 subtract_obj 可以像函数一样被调用。
#include <iostream>
#include <functional>
class Subtract {
public:
int operator()(int a, int b) {
return a - b;
}
};
int main() {
Subtract subtract_obj;
std::function<int(int, int)> func = subtract_obj;
int result = func(5, 3);
std::cout << "5 - 3 = " << result << std::endl;
return 0;
}
④成员函数与成员变量:无需bind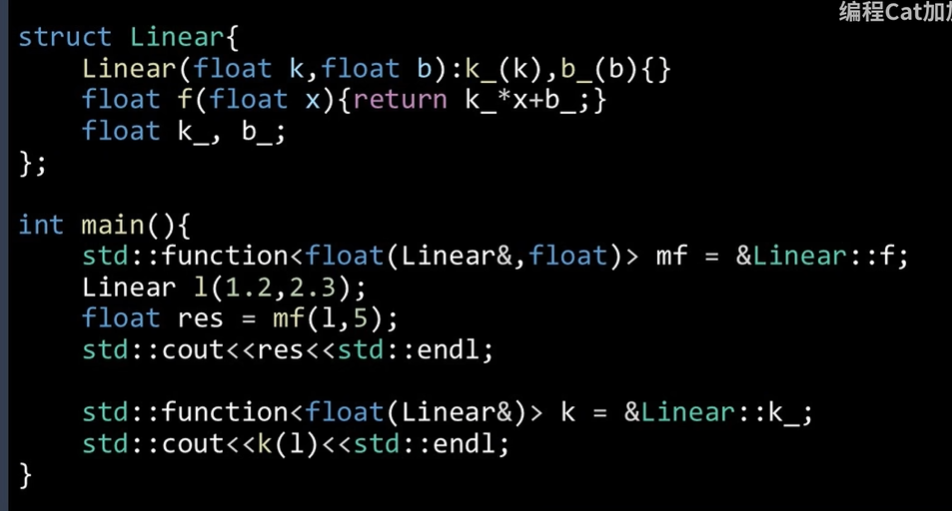
⑤作为函数参数和返回值
std::function 强大之处在于,它可以作为函数的参数和返回值,这为我们编写更加灵活和通用的代码提供了可能。
比如,我们可以定义一个 “运算调度器” 函数,它接受一个 std::function 对象作为参数,根据传入的不同可调用对象执行不同的运算:
#include <iostream>
#include <functional>
int operate(int a, int b, std::function<int(int, int)> operation) {
return operation(a, b);
}
int main() {
int num1 = 5, num2 = 3;
int add_result = operate(num1, num2, [](int a, int b) { return a + b; });
int subtract_result = operate(num1, num2, [](int a, int b) { return a - b; });
int multiply_result = operate(num1, num2, [](int a, int b) { return a * b; });
std::cout << num1 << " + " << num2 << " = " << add_result << std::endl;
std::cout << num1 << " - " << num2 << " = " << subtract_result << std::endl;
std::cout << num1 << " * " << num2 << " = " << multiply_result << std::endl;
return 0;
}
在这个例子中,operate 函数就像一个 “万能工人”,它不知道具体要执行什么运算,只知道按照传入的 “操作指南”(std::function 对象)来工作。我们可以根据需要传入不同的 lambda 表达式,实现不同的运算逻辑,这大大增强了代码的灵活性和可扩展性。
再比如,我们可以定义一个函数,它返回一个 std::function 对象,根据不同的条件返回不同的可调用对象:
#include <iostream>
#include <functional>
std::function<int(int, int)> get_operation(bool is_add) {
if (is_add) {
return [](int a, int b) { return a + b; };
} else {
return [](int a, int b) { return a - b; };
}
}
int main() {
int num1 = 8, num2 = 4;
std::function<int(int, int)> add_op = get_operation(true);
std::function<int(int, int)> subtract_op = get_operation(false);
std::cout << num1 << " + " << num2 << " = " << add_op(num1, num2) << std::endl;
std::cout << num1 << " - " << num2 << " = " << subtract_op(num1, num2) << std::endl;
return 0;
}
这里的 get_operation 函数就像一个 “工具发放员”,根据不同的条件(is_add 的值),发放不同的 “工具”(std::function 对象),让调用者可以根据拿到的工具进行相应的操作。
2、std::bind
std::bind 是 C++11 标准库中的函数适配器,用于将可调用对象(函数、成员函数、函数对象等)与参数绑定,生成新的可调用对象。
基本语法
#include <functional>
auto new_func = std::bind(original_func, arg1, arg2, ..., argN);
arg 类型:
具体值:绑定固定参数。
占位符(std::placeholders::_1等):表示调用时传入的参数位置。
参数绑定
固定部分参数值,生成参数更少的可调用对象。例如将二元函数绑定一个固定值后变为一元函数。
int add(int a, int b) { return a + b; }
auto add_five = std::bind(add, 5, std::placeholders::_1);
std::cout << add_five(3); // 输出 8(等价于 add(5, 3))
固定第一个参数为 5,第二个参数由调用时传入。
参数顺序调整
通过占位符(_1, _2等)重新排列参数顺序。
void print(int a, int b) { std::cout << a << ", " << b; }
auto reordered = std::bind(print, std::placeholders::_2, std::placeholders::_1);
reordered(10, 20); // 输出 "20, 10"
成员函数绑定
需显式指定对象指针或引用(如 &obj)
class Printer {
public:
void print(const std::string& msg) { std::cout << msg; }
};
Printer obj;
auto func = std::bind(&Printer::print, &obj, std::placeholders::_1);//需传递对象指针(&obj)和成员函数指针
func("Hello"); // 调用 obj.print("Hello")
成员函数参数中默认有一个this, '&obj’就是指定的实例对象this。
例如EventLoop中,有readMessage(),其是成员函数:int readMessage(this)。channel的回调函数类型是:handleFunc = std::function<int(void*)>
无法直接使用成员函数,需要bind进行绑定,bind中的‘this’就是readMessage中的‘this’,这里readMessage无其他参数,所以bind后无参数,但是这里的int EventLoop::readMessage() 类型似乎不匹配std::function<int(void*)>,但不影响使用。
int EventLoop::readMessage(){};
auto obj = bind(&EventLoop::readMessage, this);
Channel* channel = new Channel(m_socketPair[1], FDEvent::ReadEvent,
obj, nullptr, nullptr, this);
在httprequest.h的函数有:
char* HttpRequest::splitRequestLine(const char* start, const char* end, const char* sub, function<void(string)> callback)
成员函数HttpRequest::setMethod,此setMethod函数类型的符合 function<void(string)> callback的,但是成员函数有默认参数this,所以需要bind函数进行绑定。
inline void setMethod(string method)//function<void(string)>使用
{
m_method = method;
}
auto methodFunc = bind(&HttpRequest::setMethod, this, placeholders::_1);
start = splitRequestLine(start, end, " ", methodFunc);
3、malloc,realloc,calloc的区别
malloc, realloc, 和 calloc 是 C/C++ 中用于动态内存管理的核心函数,三者有明显区别:
①malloc - 基础内存分配
原型:
void* malloc(size_t size);
int* arr = (int*)malloc(5 * sizeof(int)); // 分配20字节(假设int为4字节)
功能:分配指定字节的未初始化内存块
特点:
分配内存内容为随机值(未初始化)
效率较高(无初始化开销)
② calloc - 初始化内存分配
原型:
void* calloc(size_t num, size_t size);
int* arr = (int*)calloc(5, sizeof(int));
// 等价于分配并清零20字节
功能:
分配 num 个大小为 size 的连续内存块,并初始化为0
特点:
内存内容强制清零(整数为0,指针为NULL)
适合需要安全初始化的场景(如数组)
③ realloc - 内存重分配
原型:
void* realloc(void* ptr, size_t new_size);
int* new_arr = (int*)realloc(arr, 10 * sizeof(int));
arr = new_arr //new_arr 不一定等于 arr,所以最好重写赋值
// 将原20字节扩展为40字节,前20字节数据保留
功能:
修改已分配内存块的大小(扩展/收缩)
特点:
保留原数据内容(新分配区域未初始化)
ptr 为 NULL 时等价于 malloc(new_size)
new_size 为 0 时等价于 free(ptr)
4、bzero
#include <string.h>
void bzero(void *s, size_t n);
参数:
s:指向待清零内存的指针。
n:需清零的字节数。
bzero 仅支持清零操作,而 memset 可设置任意值(如 memset(s, 0, n) 等效于 bzero(s, n))
5、readv
readv() 是 Linux/Unix 系统中的系统调用函数,用于实现分散读(Scatter Read)操作,允许从单个文件描述符(如文件、套接字)一次性将数据读取到多个非连续的缓冲区中。
函数原型与参数
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
fd:文件描述符(例如文件句柄或 Socket)。
iov:指向 iovec 结构体数组的指针,定义多个缓冲区地址和大小。
iovcnt:iovec 数组的元素个数。
返回值:成功时返回实际读取的总字节数;失败返回 -1,错误码存于 errno。
iovec 结构体定义:
struct iovec {
void *iov_base; // 缓冲区的起始地址
size_t iov_len; // 缓冲区的长度
};
例如buffer.h 的 int Buffer::socketRead(int fd)函数:
// read/recv/readv
struct iovec vec[2];
// 初始化数组元素
int writeable = writeableSize();
vec[0].iov_base = m_data + m_writePos;
vec[0].iov_len = writeable;
char* tmpbuf = (char*)malloc(40960);//buffer写满了,就用tmpbuf
vec[1].iov_base = tmpbuf;
vec[1].iov_len = 40960;
int result = readv(fd, vec, 2);
if (result == -1)//读取失败
{
return -1;
}
else if (result <= writeable)//使用buffer存取读取数据,没有用到tmpbuf
{
m_writePos += result;
}
else//用到tmpbuf
{
m_writePos = m_capacity;//更新buffer.writePos
appendString(tmpbuf, result - writeable);//将tmpbuf中的数据读入扩容后的buffer
}
free(tmpbuf);
6、enum class
C++中的强类型枚举(enum class)是C++11引入的特性,相比传统枚举有以下特点:
作用域限定
枚举值必须通过枚举类型名访问(MyEnum::Value)
不会污染外层命名空间
类型安全
不会隐式转换为整数
不同枚举类型不能直接比较
可指定底层类型
通过: type语法指定存储类型
如:enum class Color : uint8_t {…}
enum class Color { Red, Green, Blue };
enum class TrafficLight { Red, Yellow, Green }; // 不会与Color的Red冲突
enum class SmallEnum : uint8_t {//指定数据类型
Value1 = 1,
Value2 = 255 // 最大值由uint8_t决定
};
Color c = Color::Red;
// int i = c; // 错误:不能隐式转换
int i = static_cast<int>(c); // 需要显式转换
if (c == TrafficLight::Red) {} // 错误:类型不匹配
7、 Reactor & Proactor
参考链接:https://blog.csdn.net/qq_52313711/article/details/135585388
有两种高效的事件处理模式:
Reactor
Proactor
其中,同步I/O实现Reactor模式,异步I/O实现Proactor模式, 但同时,我们可以用同步I/O去模拟出Proactor处理模式.
Reactor
我们知道,服务器的内部有多个线程在工作,一般的结构是将服务器的线程分为主线程和工作线程,其中主线程一直处于激活状态,而工作线程则可能睡眠,也可能工作.
在Reactor模式中:
主线程:
一直在监听文件描述符上是否有事件发生,有就通知工作线程工作线程:
接受新的连接 读数据 处理客户请求 写数据
Proactor
Proactor则需要异步I/O模型,即Proactor模式下,所有的I/O操作将由内核来处理,工作线程只负责业务逻辑。
Proactor模式中:
主线程:
一直在监听socket上的事件 向内核注册socket读完成事件,告诉内核用户读缓冲区位置,读操作完成时该怎么通知应用程序内核
在读缓冲区上收到socket数据后,向程序发送一个信号通知,程序会根据信号处理函数选择工作线程进行处理 接受工作线程的写完成事件和写缓冲区位置 工作线程将写缓冲区的数据写入socket后,向程序发送一个信号通知,程序根据信号处理函数选择一个工作线程进行善后处理工作线程:
处理业务逻辑
模拟Proactor模式
通过观察我们发现,在Proactor模型中I/O交由内核处理,工作线程不需要进行数据的读写。因此,我们可以用主线程来完成一部分内核的功能来做到模拟Proactor模式。 即:主线程执行数据的读写操作,读写完成后,主线程向工作线程通知读写完成。这样从工作线程来看,就只需进行数据的逻辑操作了。
8、epollerr和epollhub
在 Linux 的 epoll 机制中,EPOLLERR(文件描述符错误)和 EPOLLHUP(文件描述符挂断)是无需主动设置监听标志即可被监听到的事件。无论是否在 epoll_ctl 中添加 EPOLLERR 或 EPOLLHUP 标志,内核始终会监控这两种事件。
EPOLLERR 在文件描述符发生底层错误(如非法操作、连接中断)时触发。
EPOLLHUP 在连接被对方关闭(如收到 FIN 包)或套接字异常断开时触发。
在dispatch()函数中,是直接跳过,等待下一次的通信。
int EpollDispatcher::dispatch(int timeout)
{
int count = epoll_wait(m_epfd, m_events, m_maxNode, timeout * 1000);
for (int i = 0; i < count; ++i)
{
int events = m_events[i].events;
int fd = m_events[i].data.fd;
if (events & EPOLLERR || events & EPOLLHUP)
{
// 对方断开了连接, 删除 fd
// epollRemove(Channel, evLoop);
continue;
}
if (events & EPOLLIN)//读事件
{
//需要channel中的回调函数,而channelmap在evloop中,所以eventActive是evloop的成员函数
m_evLoop->eventActive(fd, (int)FDEvent::ReadEvent);
}
if (events & EPOLLOUT)//写事件
{
m_evLoop->eventActive(fd, (int)FDEvent::WriteEvent);
}
}
return 0;
}
9、std::unique_lock<std::mutex>
std::unique_lock<std::mutex> 是 C++11 提供的互斥锁管理类,属于 RAII(资源获取即初始化)机制的实现,用于更灵活地管理 std::mutex 的生命周期和锁定行为。以下是其核心特性和用法:
-
核心功能
自动加锁/解锁:通过构造函数加锁,析构时自动解锁,避免忘记释放锁导致死锁。
灵活性:支持延迟加锁、手动解锁、尝试加锁等操作,比 std::lock_guard 更灵活。
条件变量支持:可与 std::condition_variable 配合使用,实现线程同步。 -
常用构造函数
std::mutex mtx;
std::unique_lock< std::mutex> lock1(mtx); // 立即加锁
std::unique_lock< std::mutex> lock2(mtx, std::defer_lock); // 延迟加锁
std::unique_lock< std::mutex> lock3(mtx, std::try_to_lock); // 尝试加锁
std::unique_lock< std::mutex> lock4(mtx, std::adopt_lock); // 接管已锁定的互斥量
-
关键成员函数
lock()/unlock():手动控制锁状态。
try_lock():非阻塞尝试加锁,返回成功与否。
owns_lock():检查当前是否持有锁。 -
典型应用场景
保护共享资源
std::mutex mtx;
int shared_data = 0;
void increment() {
std::unique_lock< std::mutex> lock(mtx);
shared_data++;
} // 自动解锁
条件变量同步
std::condition_variable cv;
bool ready = false;
void wait_thread() {
std::unique_lock< std::mutex> lock(mtx);
cv.wait(lock, []{ return ready; }); // 自动释放锁并等待通知
}
10、URL和URI
原文链接:https://blog.csdn.net/sc313121000/article/details/41279459
URL和URI定义:
1.URL(Uniform Resource Locator)是统一资源定位符的英文所写,您平时上网时在IE浏览器中输入的那个地址就是URL。比如:网易 http://www.163.com就是一个URL。
2.URI(Uniform Resource Identifier)是Web上可用的每种资源 - HTML文档、图像、视频片段、程序,由一个通用资源标志符(Universal Resource Identifier, 简称"URI")进行定位。
URL的格式由下列三部分组成: https://example.com/file
第一部分是协议(或称为服务方式);
第二部分是存有该资源的主机IP地址(有时也包括端口号);
第三部分是主机资源的具体地址。
URI一般由三部分组成: urn:issn:1535-313
访问资源的命名机制。
存放资源的主机名。
资源自身的名称,由路径表示。
URL和URI区别:
(a)URI是一个相对来说更广泛的概念,URL是URI的一种,是URI命名机制的一个子集,可以说URI是抽象的,而具体要使用URL来定位资源。
(b)Web上的每一种资源如:图片、文档、视频等,都是由URI定位的,这里所谓的定位指的是web上的资源相对于主机服务器来说,存放在服务器上的具体路径。
©URL是internet上用来描述信息资源文件的字符串,用在客户程序和服务器上,定位客户端连接服务器所需要的信息,它不仅定位了这个信息资源,而且定义了如何找到这个资源。
通俗理解 :
URI就是一种资源定位机制,它是比较笼统地定位了资源,并不局限于客户端和服务器,
而URL就定位了网上的一切资源,只要是网上的资源,都有唯一的URL.
11、惊群效应
Thundering Herd Problem)是多线程/多进程环境下的一种性能瓶颈现象,指多个等待同一资源的进程/线程同时被唤醒,但最终仅有一个能成功获取资源,导致大量无效上下文切换和CPU资源浪费。
触发条件
当多个进程/线程阻塞等待同一事件(如网络连接、锁释放)时,事件发生时所有等待者被内核同时唤醒,但仅第一个成功获取资源的进程/线程能处理事件,其余需重新阻塞。
典型场景
网络编程:多进程/线程同时监听同一socket,新连接到达时全部唤醒。
锁竞争:多个线程竞争同一互斥锁,锁释放时全部线程被唤醒。
任务队列:多个消费者线程监听同一队列,任务到达时所有线程被唤醒。
解决方案
Linux内核优化
内核2.6+通过WQ_FLAG_EXCLUSIVE标志仅唤醒单个进程
SO_REUSEPORT实现端口复用,隔离监听资源
应用层设计
单进程监听+线程池处理:如Nginx的accept_mutex机制
任务分片:避免多个线程处理同一资源
条件变量优化:使用std::condition_variable精准唤醒
12、分块传输编码
(Chunked Transfer Encoding)是HTTP/1.1协议中定义的关键数据传输机制,其核心作用与应用原理如下:
工作原理
当服务器无法预先确定响应体长度时,通过Transfer-Encoding: chunked头部启用分块传输。数据被分解为多个独立数据块(chunk)发送,每个块包含:
长度标识:十六进制字节数(如1F表示31字节)
数据内容:实际负载
终止符:CRLF(回车换行符)
5\r\n ← 第一块长度(5字节)
Hello\r\n ← 第一块数据
7\r\n ← 第二块长度
World!\r\n ← 第二块数据
0\r\n\r\n ← 终止块标记
传输终止
以长度标识为0的块作为结束符,后接可选的尾部头域(trailer)携带元数据
13、智能独占指针处理buffer类
①类中定义和初始化私有成员-独占指针
private:
// char* m_data;
int m_capacity;
int m_readPos = 0;
int m_writePos = 0;
unique_ptr<char[]> uptr;
// 连续内存块,可以使用memcpy
Buffer::Buffer(int size):m_capacity(size),uptr(std::make_unique<char[]>(size)){}
②uptr.get() 获取原始指针
因为需要对buffer进行调整(memcpy、memset)和扩容(realloc),所以需要原始指针,但是memcpy、realloc等函数是c库函数,和智能指针混合使用会出现一些问题,所以,建议使用c++的函数。
③std::copy 替换 memcpy
std::copy
template<class InputIt, class OutputIt>
OutputIt copy(InputIt first, InputIt last, OutputIt d_first);
参数:
first/last:源范围的起始和结束迭代器(左闭右开区间)。
d_first:目标范围的起始迭代器。
返回值:指向目标范围最后一个复制元素后一位置的迭代器
// 数据拷贝
将data中的size个char写入(起始位置)m_data + m_writePos
memcpy(m_data + m_writePos, data, size);
将[data, data + size)中的元素写入(起始位置)uptr.get() + m_writePos
std::copy(data, data + size, uptr.get() + m_writePos);
④std::move(new_ptr) 替换 realloc
realloc:
void* temp = realloc(m_data, m_capacity + size);
if (temp == NULL)
{
return; // 失败了
}
memset((char*)temp + m_capacity, 0, size);
// 更新数据
m_data = static_cast<char*>(temp);
m_capacity += size;
独占指针:
auto new_ptr = std::make_unique<char[]>(m_capacity + size); // 新内存
std::copy(uptr.get(), uptr.get() + m_capacity, new_ptr.get()); // 数据迁移
uptr = std::move(new_ptr); // 所有权转移, 更新数据
m_capacity += size;
总结
Http高并发服务器:http、reactor、IO多路复用、线程池、回调函数、智能指针、html。
网络协议:HTTP/1.1协议,实现GET/POST请求解析、文件传输,支持Chunked传输。
reactor反应堆:实现select/poll/epoll多态I/O复用,文件描述符的封装和任务队列的处理,通过socketpair实现线程唤醒。
线程池:多级任务队列设计,实现多反应堆模型,子线程的独立任务队列,能够减少竞争,处理高并发操作。
内存管理:双缓冲设计,input/output buffer分离,按需扩容,智能指针管理连接生命周期。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)