Transformer是一种基于自注意力机制(Self-Attention)的神经网络架构
Transformer是一种基于自注意力机制(Self-Attention)的神经网络架构,最早是在2017年由谷歌大脑团队Ashish Vaswani和多伦多大学的一个团队发表的一篇名为"Attention is All You Need"的论文中描述的。3.将Encoder输出的编码信息矩阵C传入Decoder中,Decoder会根据当前翻译过的单词 1 ~ i 翻译下一个单词 i + 1。1
Transformer是一种基于自注意力机制(Self-Attention)的神经网络架构,最早是在2017年由谷歌大脑团队Ashish Vaswani和多伦多大学的一个团队发表的一篇名为"Attention is All You Need"的论文中描述的。其革命性的自注意力机制彻底改变了序列建模的方法。与传统的循环神经网络(RNN)不同,Transformer能够并行处理序列中的所有位置,通过注意力权重矩阵捕获任意距离的依赖关系。这种架构设计不仅提高了训练效率,还显著增强了模型对长序列和复杂依赖关系的建模能力。
1 整体架构
Transformer采用编码器 - 解码器架构。编码器由多个相同层堆叠而成,每层包含多头自注意力机制和前馈神经网络,通过残差连接和层归一化稳定训练。解码器同样多层堆叠,在自注意力机制基础上增加了编码器 - 解码器注意力层,同样有残差连接与层归一化。位置编码注入序列位置信息,共同构成完整架。
2 工作原理
通俗地说、Transformer就是一个翻译器。在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出。
中间部分由编码器和解码器两部分组成。
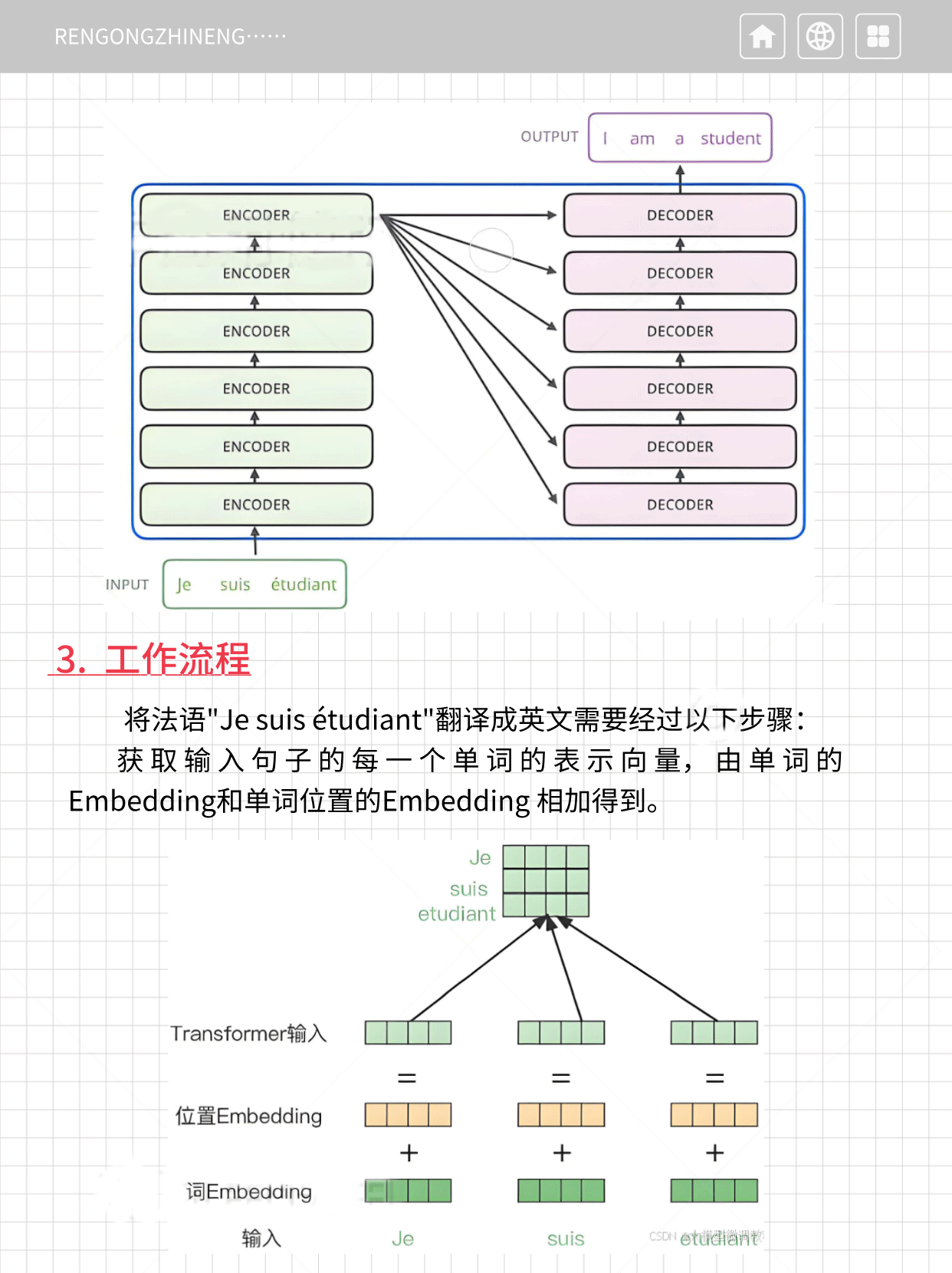
其中,编码组件由多层编码器(Encoder)组成(在论文中作者使用了 6 层编码器,在实际使用过程中你可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了 6 层)。
3 工作流程
将法语"Je suis étudiant"翻译成英文需要经过以下步骤:
1.获取输入句子的每一个单词的表示向量,由单词的Embedding和单词位置的Embedding 相加得到。
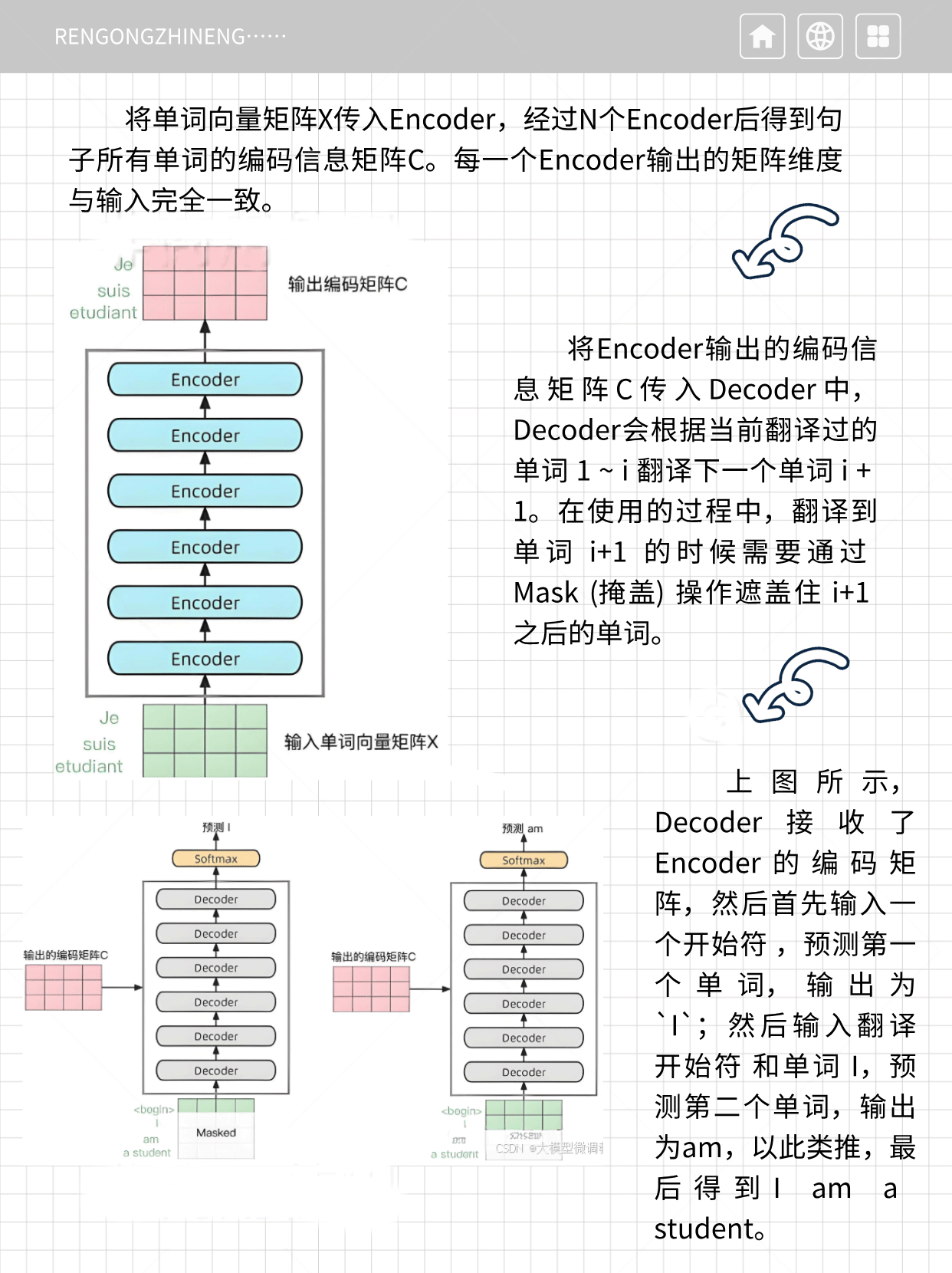
2.将单词向量矩阵X传入Encoder,经过N个Encoder后得到句子所有单词的编码信息矩阵C。每一个Encoder输出的矩阵维度与输入完全一致。
3.将Encoder输出的编码信息矩阵C传入Decoder中,Decoder会根据当前翻译过的单词 1 ~ i 翻译下一个单词 i + 1。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
Decoder接收了Encoder的编码矩阵,然后首先输入一个开始符 ,预测第一个单词,输出为`I`;然后输入翻译开始符 和单词 I,预测第二个单词,输出为am,以此类推,最后得到I a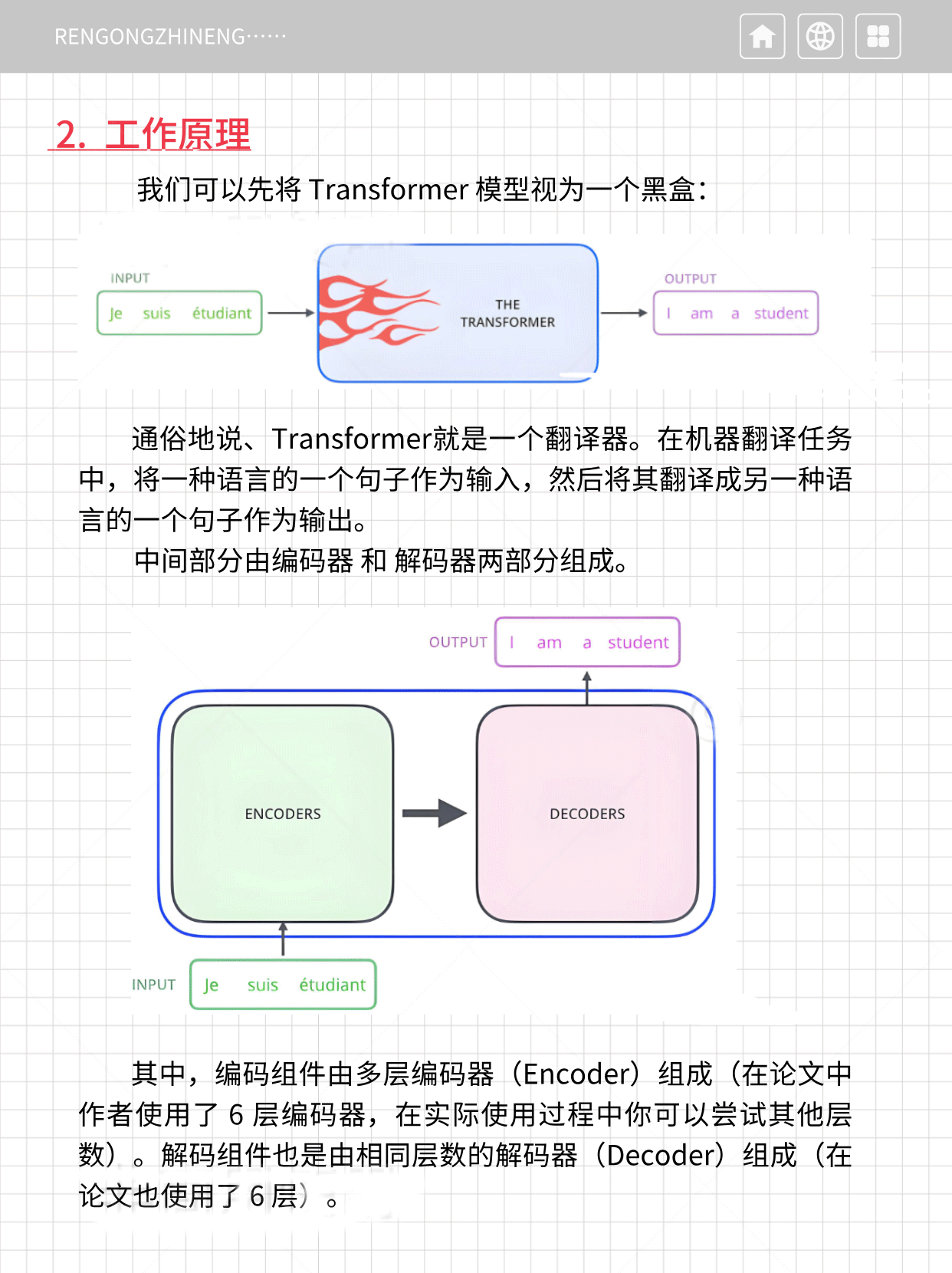 m a student。
m a student。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)