基于python+django的的旅游数据分析可视化系统的设计与实现大数据分析系统
旅游数据分析可视化系统的核心目标是通过大数据技术处理旅游相关数据,并借助可视化工具呈现分析结果。系统需包含数据采集、存储、处理、分析及可视化模块。Python+Django作为后端框架,结合前端可视化库(如ECharts、D3.js)实现交互式展示。该系统完整实现需要约15-20个核心Python文件,包含数据模型、视图逻辑、任务调度等模块。建议采用模块化开发,逐步迭代各个功能组件。
·
需求分析与系统设计
旅游数据分析可视化系统的核心目标是通过大数据技术处理旅游相关数据,并借助可视化工具呈现分析结果。系统需包含数据采集、存储、处理、分析及可视化模块。Python+Django作为后端框架,结合前端可视化库(如ECharts、D3.js)实现交互式展示。
关键功能模块:
- 数据采集:爬取旅游平台数据或接入公开API(如携程、飞猪)
- 数据存储:使用MySQL或MongoDB存储结构化/非结构化数据
- 数据处理:Pandas进行数据清洗,Spark处理大规模数据集
- 分析模型:基于用户行为、景点热度等维度构建分析模型
- 可视化展示:热力图、折线图、柱状图等多维度展示
技术栈选型
后端技术:
- Django框架:快速搭建RESTful API接口
- Django REST framework:构建数据分析API
- Celery:异步任务处理(如定时数据爬取)
- Pandas/Numpy:数据清洗与计算
- Scikit-learn:简单机器学习模型(如游客流量预测)
前端技术:
- ECharts/AntV:数据可视化渲染
- Vue.js/React:可选的前端框架
- Bootstrap:响应式页面布局
数据库:
- MySQL:存储结构化数据(用户信息、订单数据)
- MongoDB:存储非结构化数据(评论、日志)
- Redis:缓存热点数据
核心功能实现
数据采集模块示例(Scrapy爬虫):
import scrapy
class TravelSpider(scrapy.Spider):
name = 'trip'
def start_requests(self):
urls = ['https://www.ctrip.com/']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 解析景点数据
item = {
'scenic_name': response.css('h1::text').get(),
'comment_count': response.xpath('//span[@class="count"]/text()').get()
}
yield item
数据分析API示例(Django REST framework):
from rest_framework.views import APIView
from rest_framework.response import Response
import pandas as pd
class TourismAnalysis(APIView):
def get(self, request):
data = pd.read_csv('tourism.csv')
result = data.groupby('city')['visitors'].sum().to_dict()
return Response(result)
可视化实现方案
热力图生成示例(PyEcharts):
from pyecharts import options as opts
from pyecharts.charts import HeatMap
def heatmap_base() -> HeatMap:
data = [
[1, 1, 100], [2, 1, 200],
[1, 2, 300], [2, 2, 400]
]
c = (
HeatMap()
.add_xaxis(["北京", "上海"])
.add_yaxis("热度", ["冬季", "夏季"], data)
.set_global_opts(
title_opts=opts.TitleOpts(title="旅游热度分析"),
visualmap_opts=opts.VisualMapOpts()
)
)
return c
系统部署方案
推荐部署架构:
- Nginx:反向代理和负载均衡
- Gunicorn:Django应用服务器
- Supervisor:进程监控
- Docker:容器化部署
性能优化建议:
- 使用Django缓存框架缓存高频访问数据
- 对大数据分析任务采用异步队列处理
- 使用CDN加速静态资源访问
- 建立数据库读写分离架构
扩展功能建议
增强系统能力的可选模块:
- 实时数据处理:接入Kafka实现实时数据分析
- 预测模型:使用LSTM进行游客流量预测
- 个性化推荐:基于协同过滤算法实现景点推荐
- 舆情分析:NLP处理旅游评论情感分析
该系统完整实现需要约15-20个核心Python文件,包含数据模型、视图逻辑、任务调度等模块。建议采用模块化开发,逐步迭代各个功能组件。
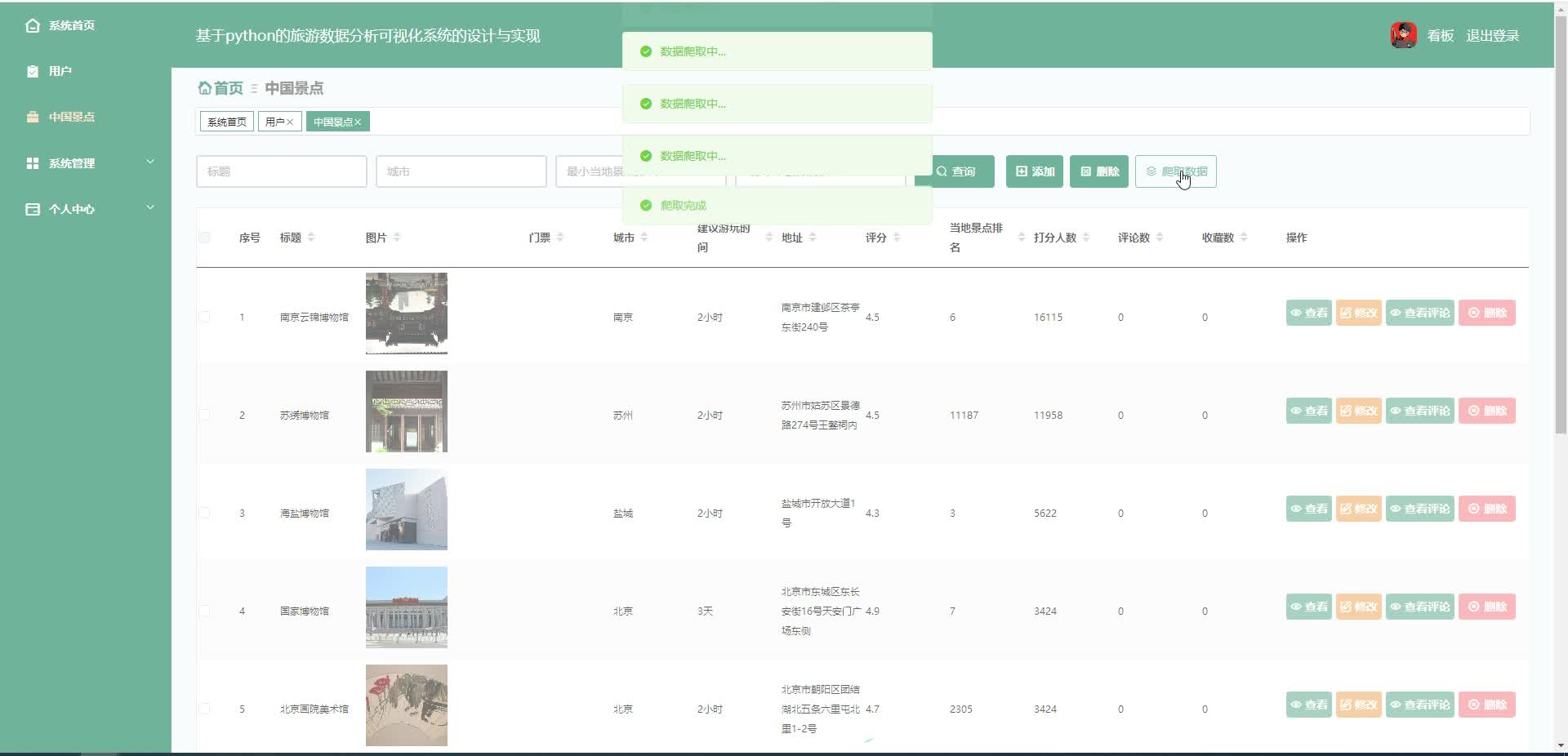
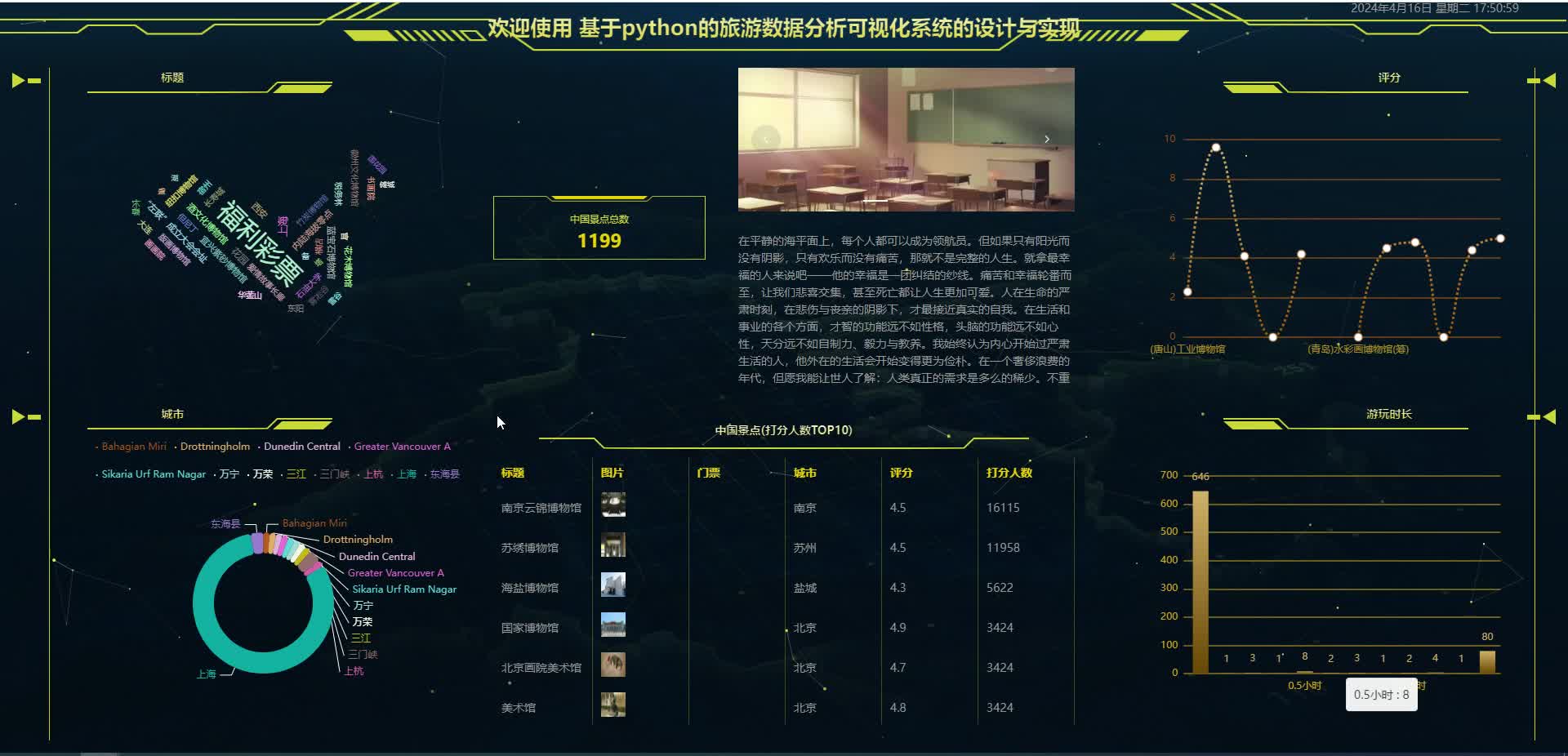

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)