基于python+django的大数据旅游景点数据分析及可视化的设计与实现
【代码】基于python+django的大数据旅游景点数据分析及可视化的设计与实现。
·
技术栈设计
后端框架
- 使用Python 3.8+作为开发语言,Django 3.2+作为后端框架,提供RESTful API接口。
- 数据库采用PostgreSQL 13+,支持JSON字段存储非结构化景点数据。
- 异步任务使用Celery + Redis,处理数据爬取和清洗任务。
数据分析与可视化
- 数据分析库:Pandas、NumPy进行数据清洗和统计分析。
- 机器学习库:Scikit-learn实现热门景点预测模型(如线性回归或随机森林)。
- 可视化工具:前端使用ECharts.js或D3.js,后端通过Matplotlib生成静态图表。
前端技术
- Vue.js 3.0或React 18构建响应式管理后台。
- Element UI或Ant Design提供UI组件支持。
数据采集
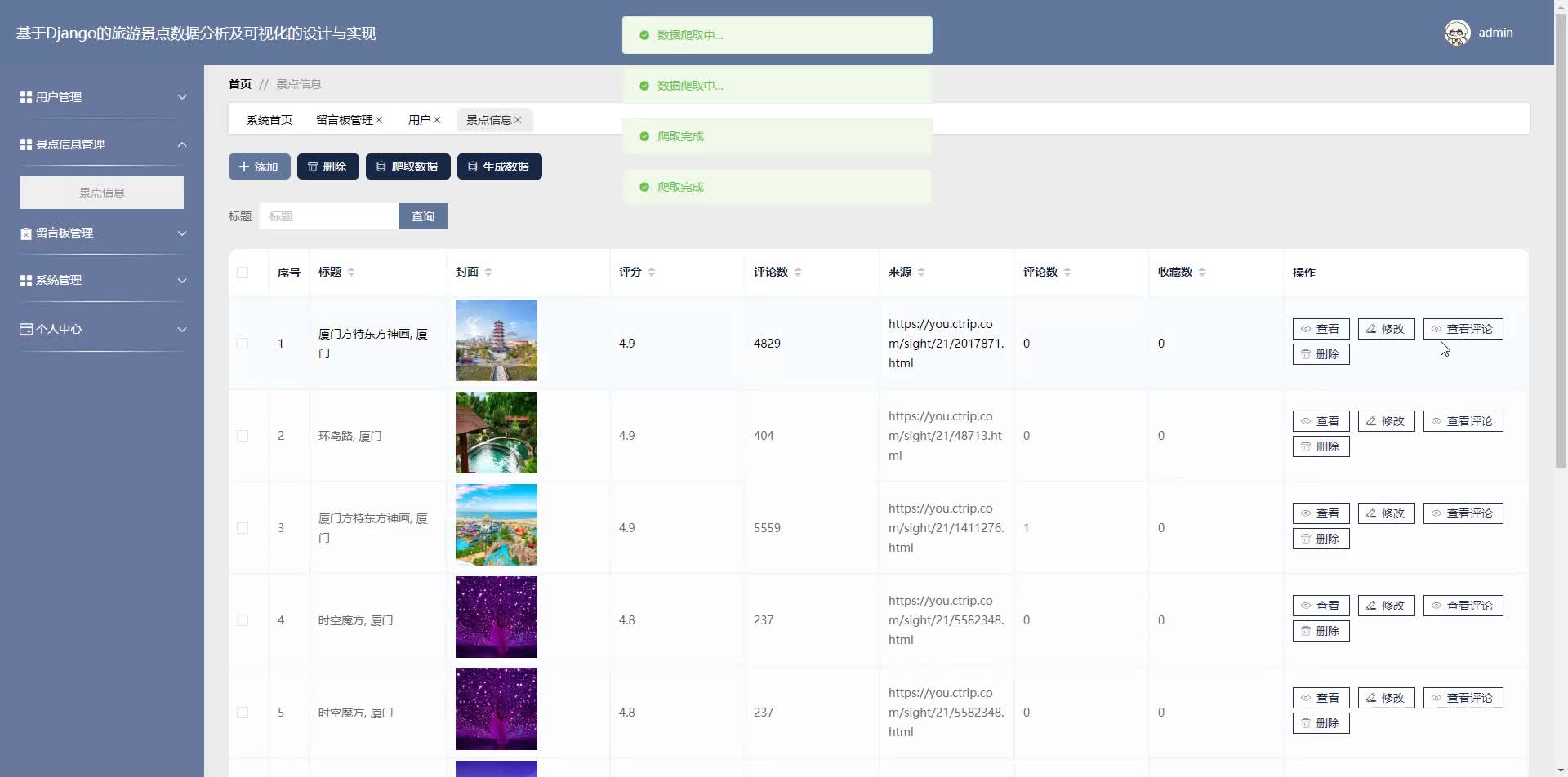
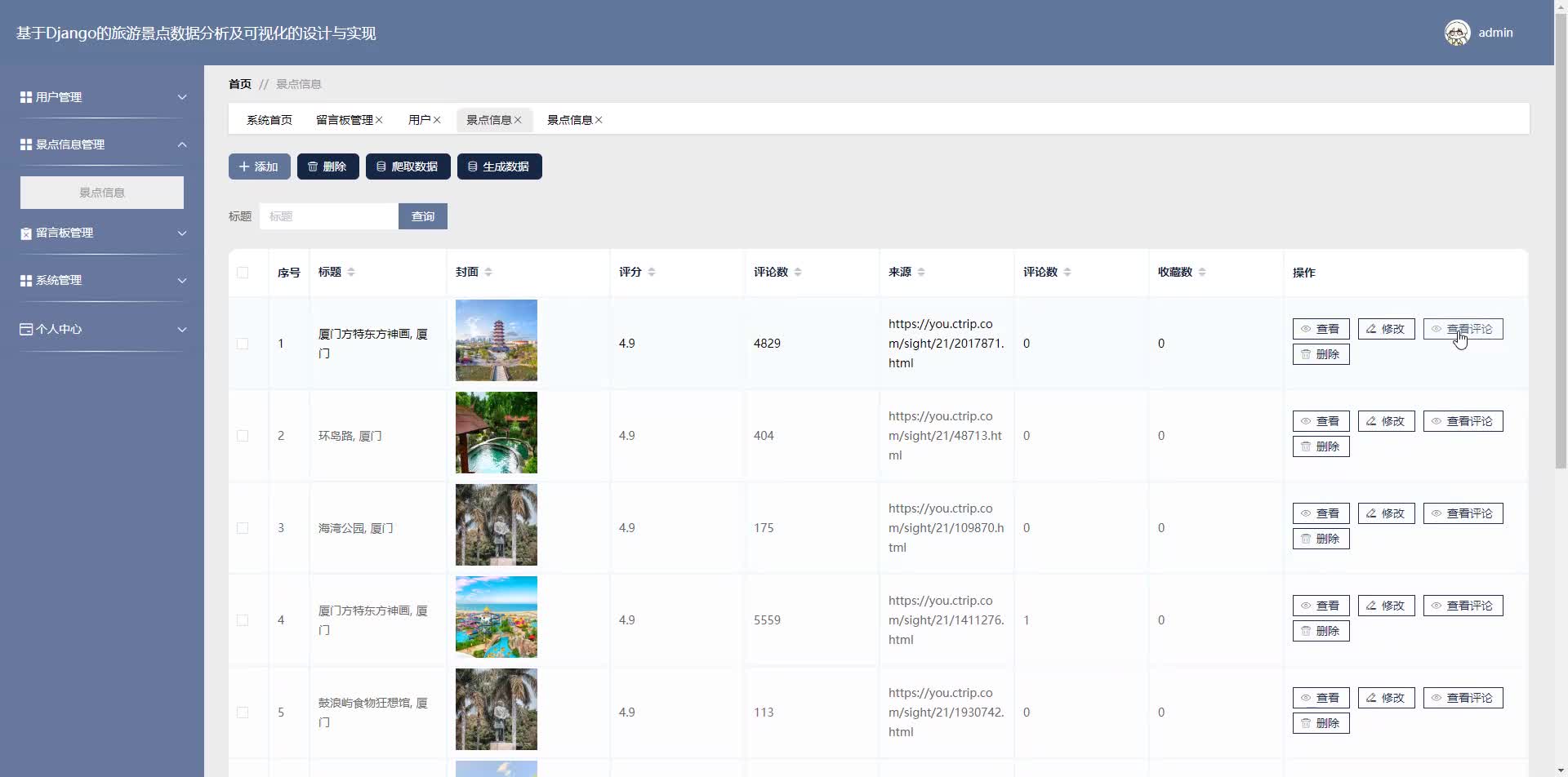
- Scrapy框架爬取公开旅游平台数据(如携程、TripAdvisor)。
- 数据字段包括景点评分、评论、地理位置、游客量等。
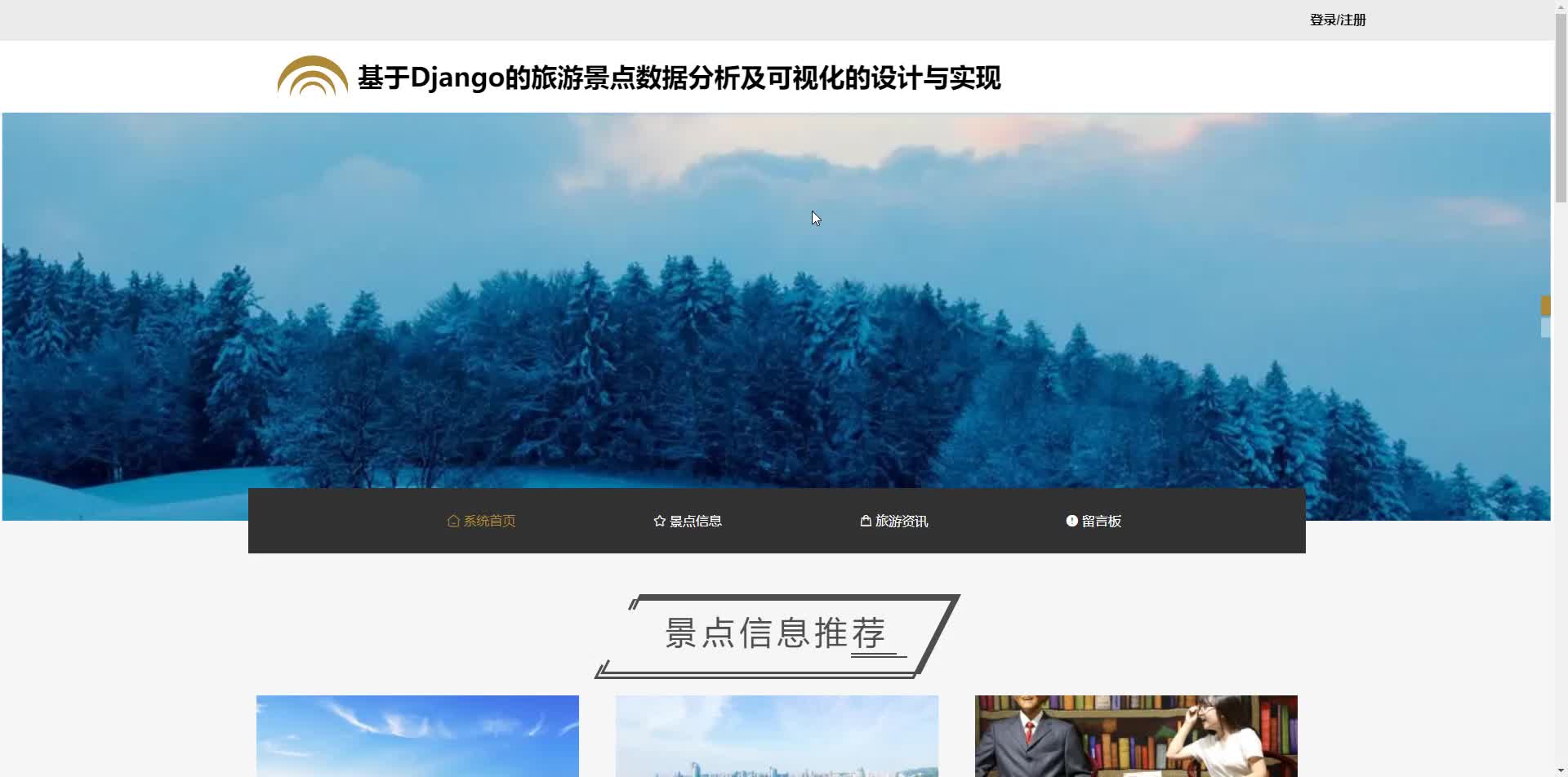
功能模块设计
数据管理模块
- 景点数据CRUD:支持管理员上传/编辑景点信息(名称、描述、坐标等)。
- 数据导入导出:通过Excel或CSV批量导入原始数据,导出分析结果。
分析模块
- 热度分析:基于历史访问量预测未来流量高峰时段。
- 情感分析:NLTK或TextBlob处理游客评论,生成情感极性分布。
- 关联分析:Apriori算法挖掘景点之间的游客访问关联规则。
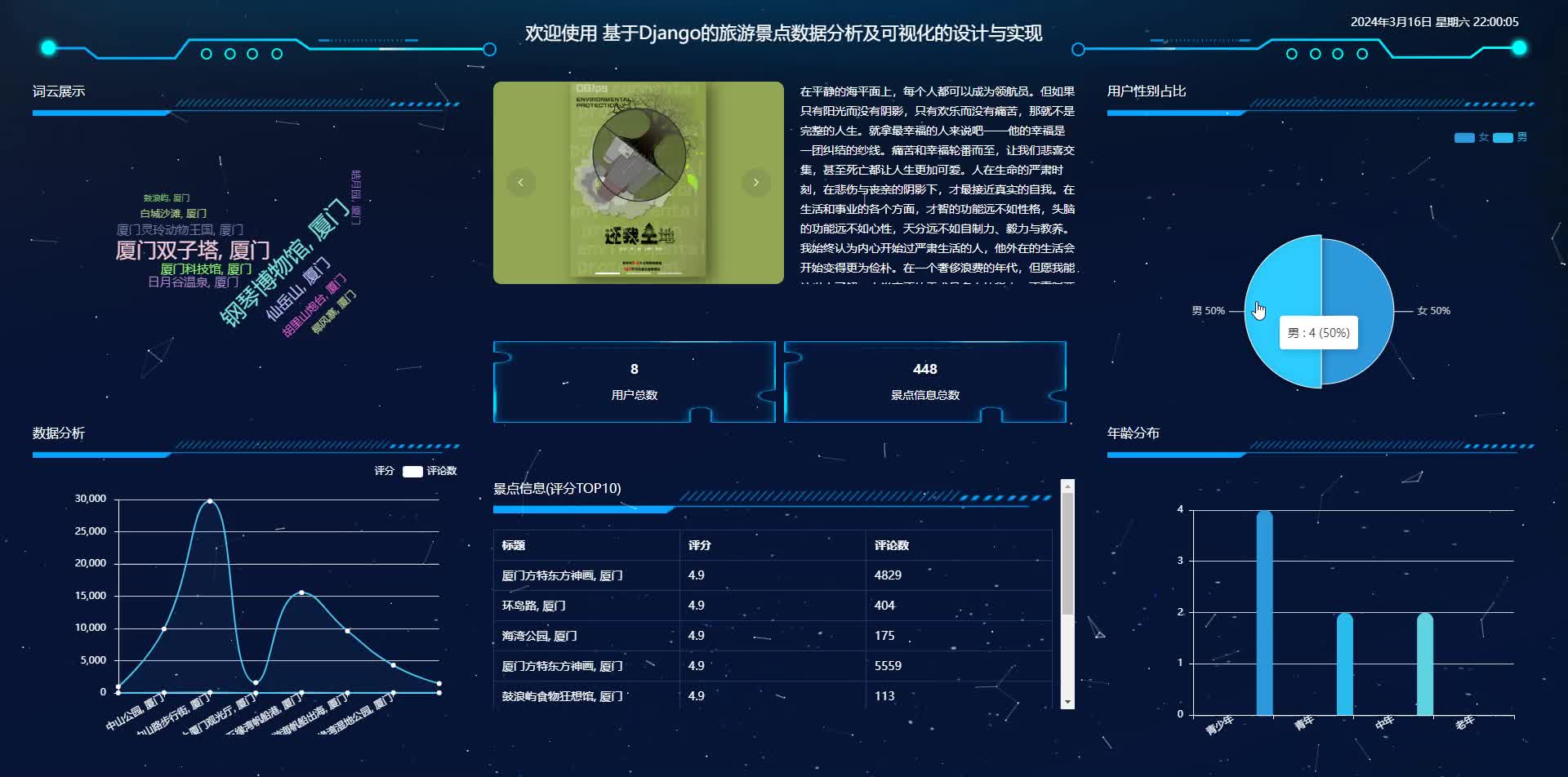
可视化模块
- 动态地图:集成Leaflet.js展示景点地理分布,热力图显示人流密度。
- 多维图表:柱状图对比评分趋势,折线图展示季节性游客量变化。
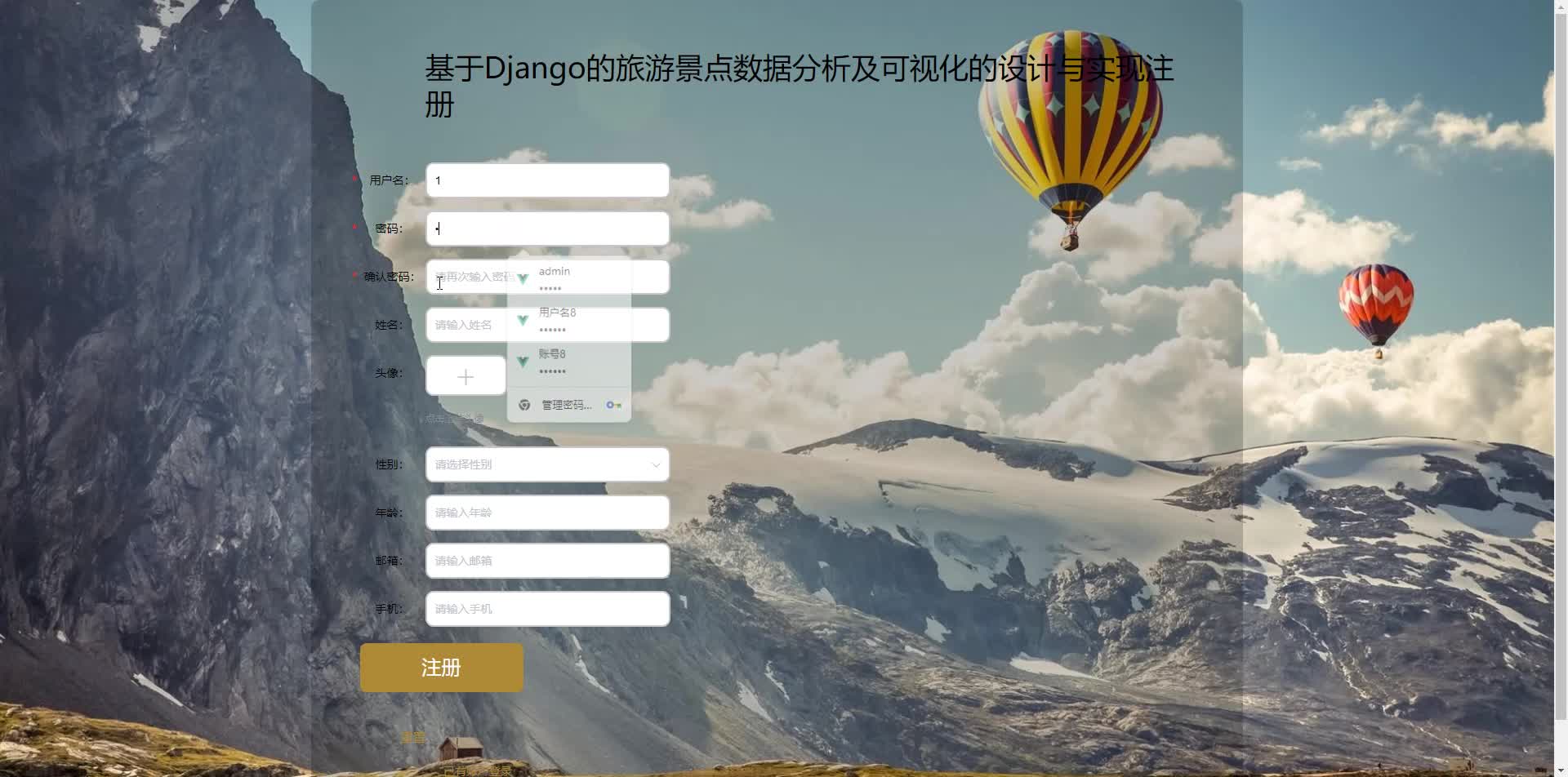
用户模块
- 权限控制:JWT实现管理员/普通用户角色分离。
- 个人看板:用户自定义保存常用分析视图。
数据库设计
核心表结构
-
景点表(scenic_spot):
CREATE TABLE scenic_spot ( id SERIAL PRIMARY KEY, name VARCHAR(255) NOT NULL, location GEOGRAPHY(POINT), description TEXT, average_rating FLOAT, visitor_count INT ); -
评论表(review):
CREATE TABLE review ( id SERIAL PRIMARY KEY, spot_id INT REFERENCES scenic_spot(id), content TEXT, sentiment_score FLOAT, created_at TIMESTAMP ); -
访问记录表(visitor_log):
CREATE TABLE visitor_log ( id SERIAL PRIMARY KEY, spot_id INT REFERENCES scenic_spot(id), date DATE, hour INT, count INT );
索引优化
- 为景点表的
location字段创建GIST索引加速空间查询。 - 评论表的
spot_id和created_at字段建立复合索引。
系统测试设计
单元测试
- 使用Django的
TestCase测试模型方法和API接口:class ScenicSpotTestCase(TestCase): def setUp(self): self.spot = ScenicSpot.objects.create(name="Test Spot", average_rating=4.5) def test_rating_threshold(self): self.assertTrue(self.spot.is_popular()) # 假设>4.0分为热门
集成测试
- Selenium模拟用户操作,测试前后端数据交互。
- Locust进行并发访问压力测试,确保API响应时间<500ms。
数据验证
- Great Expectations库检查数据质量:
expectation_suite = { "expectations": [ { "expectation_type": "expect_column_values_to_not_be_null", "kwargs": {"column": "visitor_count"} } ] }
源码结构示例
project/
├── core/ # Django核心设置
├── analytics/ # 数据分析模块
│ ├── models.py # 自定义分析模型
│ └── tasks.py # Celery异步任务
├── api/ # API接口
│ ├── serializers.py # DRF序列化器
│ └── views.py # 视图集
├── frontend/ # Vue/React源码
└── scripts/ # 数据爬取脚本
└── scraper.py # Scrapy爬虫
关键实现代码
热度预测模型(示例)
from sklearn.ensemble import RandomForestRegressor
def train_visitor_model(df):
X = df[['month', 'weekday', 'weather']]
y = df['visitor_count']
model = RandomForestRegressor()
model.fit(X, y)
return model
Django API视图
from rest_framework.views import APIView
class SpotAnalysisView(APIView):
def get(self, request, spot_id):
queryset = Review.objects.filter(spot_id=spot_id)
serializer = ReviewSerializer(queryset, many=True)
return Response(serializer.data)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)