【腾讯云智】C++后台开发(一面)面经
文章目录
- 1. 说一下堆区和栈区,为什么要划分出这两个区
- 2. 函数是如何调用的?
- 3. 介绍一下指针和引用,它们在作为参数类型时,如何传递参数?
- 4. 说一下MySql常用的索引
- 5. MySQL引擎有哪些,说一下 InnoDB 和 MyISAM 的区别
- 6. 说一下MySQL事务
- 7. 说一下 MVCC 机制,实现原理
- 8. 隔离级别有哪些?MVCC 机制用于哪些隔离级别?
- 9. MVCC 解决了哪些问题?
- 10. 索引如何优化?
- 11. 说一下 select、poll、epoll,以及它们的使用场景
- 12. 输入 URL 后发生的事情
- 13. HTTP 基于什么协议实现?
- 14. HTTP 和 HTTPS 的区别?
- 15. HTTPS 如何确保安全性?
- 16. 为什么不能只使用非对称加密?
- 17. 说一下 CA 证书
- 18. CA证书是由谁传输的?
- 19. 如何使用 CA 证书(CA 证书是如何保证安全的)?
- 20. 如果访问两个不同的网站,如何获取 CA 的公钥?
腾讯云智服是腾讯的一个子公司,内部员工都是正式员工。
腾讯云智服是腾讯推出的专业云客服SaaS系统,助力企业打造一流的服务体验。集合十年腾讯内部服务打磨的SaaS产品,输出海量用户经验
1. 说一下堆区和栈区,为什么要划分出这两个区
栈区(Stack)

堆区(Heap)

为什么要划分堆区和栈区?

2. 函数是如何调用的?
在C++中,函数调用涉及多个步骤,包括参数传递、函数执行、和返回值处理。
下面咱们来详细介绍函数调用的过程:
1. 函数调用步骤


2. 函数调用示例
以下是一个简单的示例,展示函数调用的过程:
#include <iostream>
// 函数声明
int add(int a, int b);
int main() {
int result = add(3, 4); // 调用 add 函数
std::cout << "Result: " << result << std::endl;
return 0;
}
// 函数定义
int add(int a, int b) {
return a + b;
}
上面这个调用的过程如下:
- 调用函数:在main函数中调用add(3, 4)。
- 参数传递:将3和4作为参数传递给add函数(值传递)。
- 压栈:压入返回地址、函数参数和必要的寄存器状态。
- 函数执行:执行add函数体中的代码return a + b;。
- 返回值处理:将返回值7存储在寄存器中。
- 弹栈:从栈中恢复调用现场,返回到main函数继续执行。
3. 函数调用约定(Calling Conventions)

3. 介绍一下指针和引用,它们在作为参数类型时,如何传递参数?
指针(Pointer)
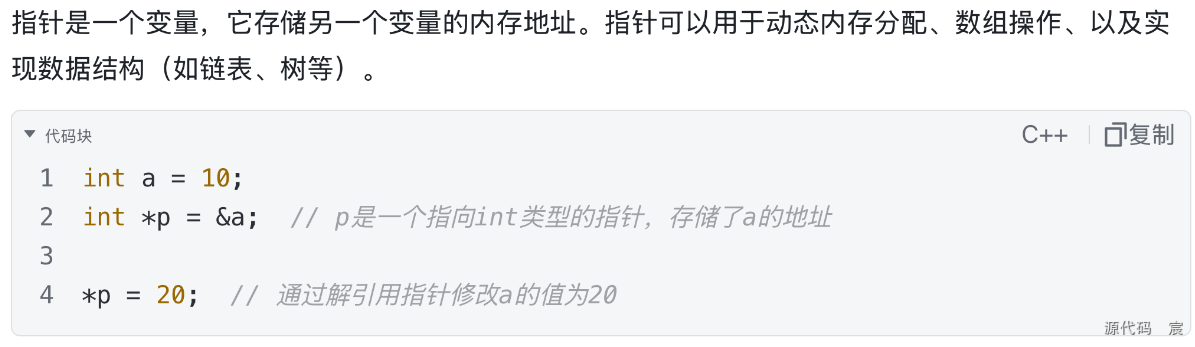
作为函数参数
当指针作为函数参数时,函数接收到的是指向实参的地址,这意味着可以在函数内部修改实参。
void modifyValue(int *p) {
*p = 100; // 修改指针所指向的变量的值
}
int main() {
int x = 10;
modifyValue(&x); // 传递x的地址
// 现在x的值变为100
return 0;
}
引用(Reference)
引用是一个变量的别名。它必须在声明时初始化,并且初始化后不能更改引用目标。 引用通常用于函数参数和返回类型,提供了一种比指针更简洁和安全的方式来访问变量。
int a = 10;
int &ref = a; // ref是a的引用
ref = 20; // 通过引用修改a的值为20
作为函数参数
当引用作为函数参数时,函数接收到的是实参的引用,这意味着可以在函数内部修改实参,而无需使用指针的解引用语法。
void modifyValue(int &ref) {
ref = 100; // 修改引用所指向的变量的值
}
int main() {
int x = 10;
modifyValue(x); // 传递x的引用
// 现在x的值变为100
return 0;
}
指针与引用的比较


4. 说一下MySql常用的索引
在MySQL中,索引是用于加速查询操作的数据结构。
4.1 常用索引类型
1. B+Tree索引:
- 默认索引类型,用于大多数情况。
- 支持精确匹配和范围查询。
- 适用于PRIMARY KEY、UNIQUE、INDEX、FULLTEXT等。
B+树动画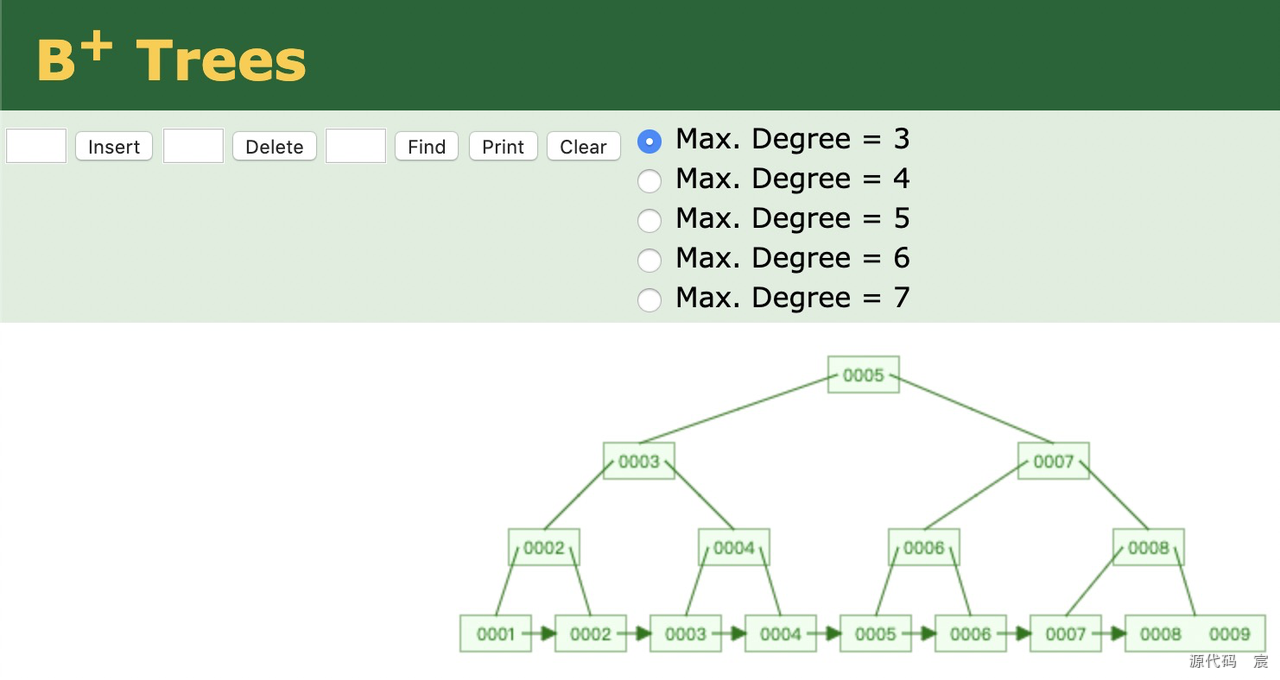
2. 哈希索引:

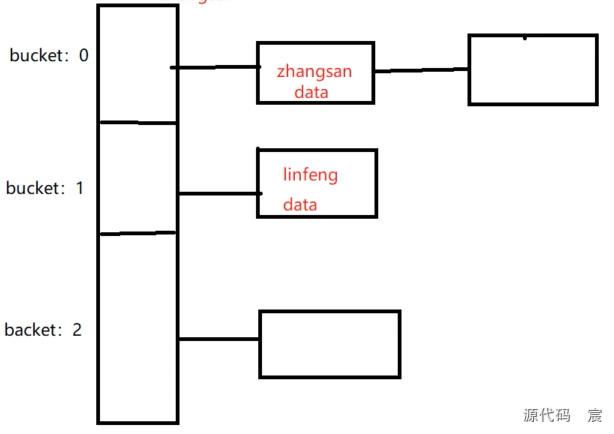
3. 全文索引(FULLTEXT):

4. 空间索引(SPATIAL):

4.2 创建索引的方法
1. 创建PRIMARY KEY:
- 每个表只能有一个PRIMARY KEY。
- 自动创建唯一索引。
CREATE TABLE my_table (
id INT NOT NULL,
name VARCHAR(50),
PRIMARY KEY (id)
);
2. 创建UNIQUE索引:
- 确保列中的值唯一。
CREATE TABLE my_table (
id INT NOT NULL,
name VARCHAR(50),
UNIQUE (name)
);
3. 创建普通索引:
- 用于加速查询。
CREATE INDEX index_name ON my_table (column_name);
- 或者在创建表时指定索引:
CREATE TABLE my_table (
id INT NOT NULL,
name VARCHAR(50),
INDEX (name)
);
4. 创建全文索引:
- 用于全文搜索。
CREATE FULLTEXT INDEX fulltext_index ON my_table (text_column);
5. 创建空间索引:
- 用于地理数据。
CREATE SPATIAL INDEX spatial_index ON my_table (geometry_column);
4.3 SQL定义示例
假设我们有一个表employees,需要为其不同的列创建索引:
CREATE TABLE employees (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
age INT,
department VARCHAR(50),
bio TEXT,
location POINT,
PRIMARY KEY (id),
UNIQUE INDEX unique_name (name),
INDEX age_index (age),
FULLTEXT INDEX bio_index (bio),
SPATIAL INDEX location_index (location)
);
CREATE TABLE employees
CREATE TABLE 是用来创建一个新表的 SQL 命令。这个命令后跟着表的名称,这里是 employees,表示创建一个名为 employees 的表。


location_index 是 空间索引(SPATIAL INDEX)的名称,它是为 location 列创建的索引,用于优化空间数据的查询。
5. MySQL引擎有哪些,说一下 InnoDB 和 MyISAM 的区别
5.1 常见MySQL引擎
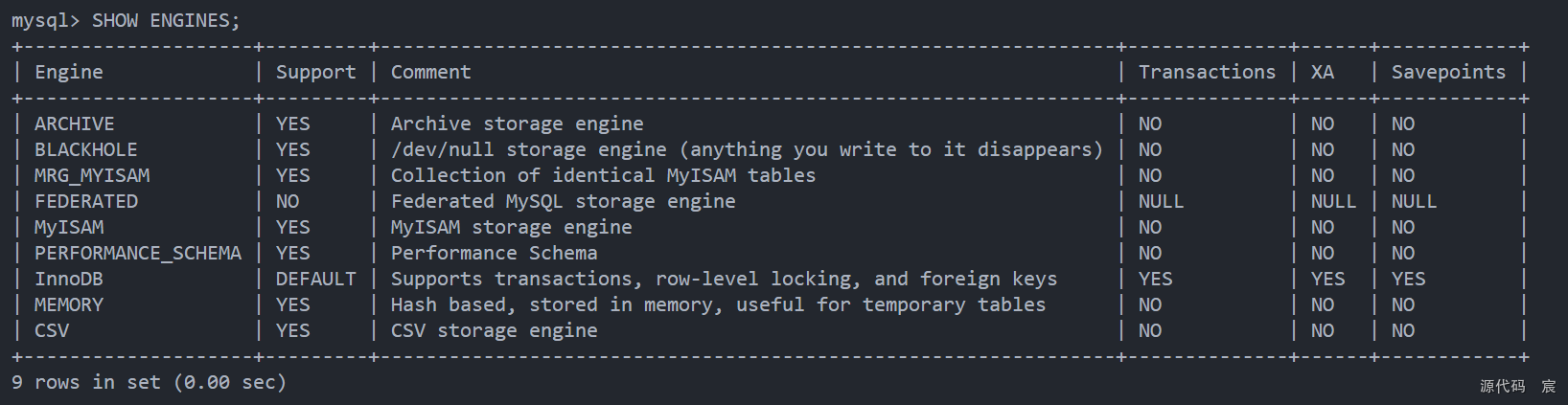
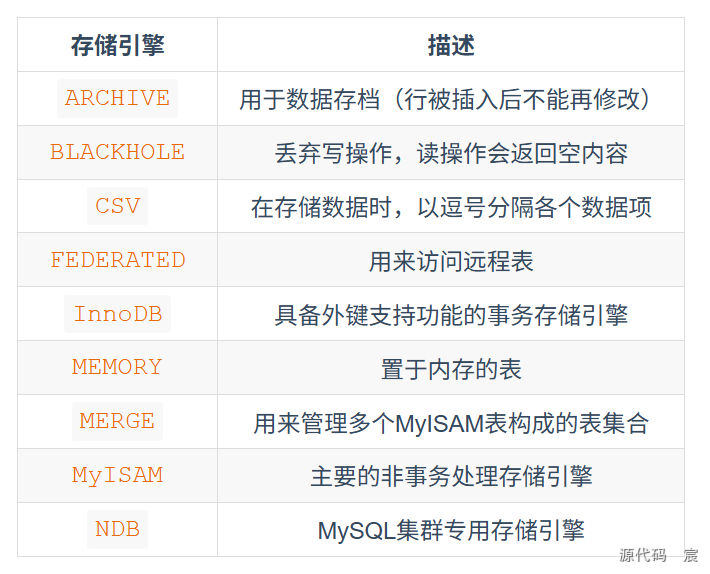


5.2 InnoDB 和 MyISAM 的区别
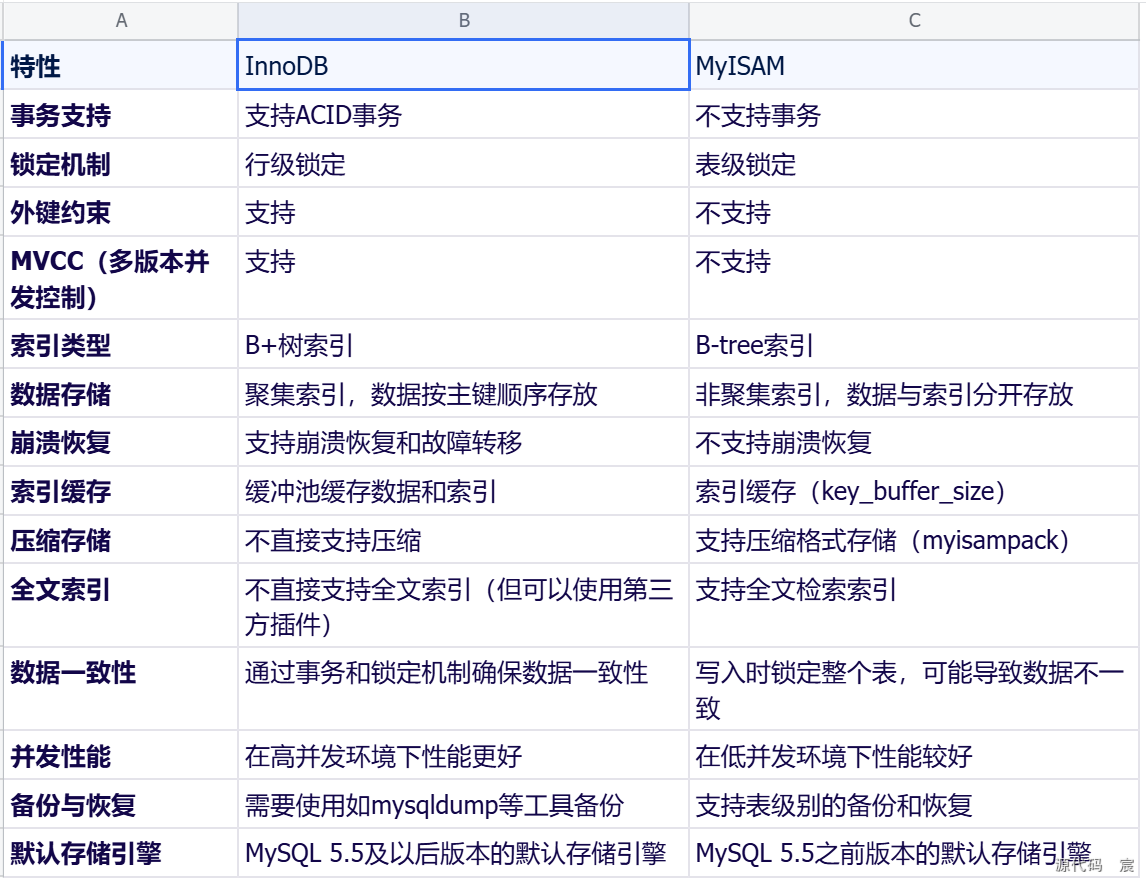
1. 事务支持

2. 外键支持

3. 锁机制

4. 存储结构

5. 崩溃恢复

6. 全文索引
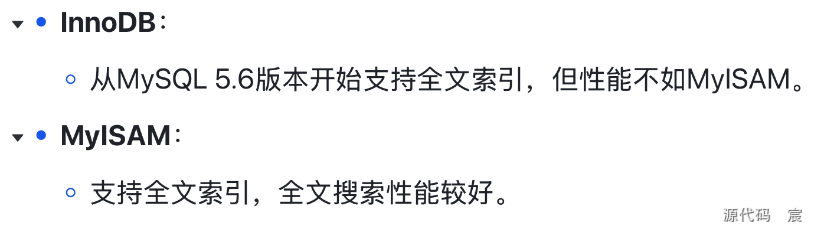
7. 表存储

总结
5.3 InnoDB 和 MyISAM 使用场景的区别
场景 1:高并发的Web应用

CREATE TABLE orders (
order_id INT NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
product_id INT NOT NULL,
order_date DATETIME,
status VARCHAR(20),
PRIMARY KEY (order_id),
FOREIGN KEY (user_id) REFERENCES users(user_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
) ENGINE=InnoDB;
场景 2:只读或读多写少的应用

CREATE TABLE blog_posts (
post_id INT NOT NULL AUTO_INCREMENT,
title VARCHAR(255),
content TEXT,
publish_date DATETIME,
PRIMARY KEY (post_id),
FULLTEXT (title, content)
) ENGINE=MyISAM;
场景 3:需要外键约束的应用

CREATE TABLE students (
student_id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100),
age INT,
PRIMARY KEY (student_id)
) ENGINE=InnoDB;
CREATE TABLE courses (
course_id INT NOT NULL AUTO_INCREMENT,
course_name VARCHAR(100),
PRIMARY KEY (course_id)
) ENGINE=InnoDB;
CREATE TABLE enrollments (
student_id INT,
course_id INT,
enrollment_date DATETIME,
PRIMARY KEY (student_id, course_id),
FOREIGN KEY (student_id) REFERENCES students(student_id),
FOREIGN KEY (course_id) REFERENCES courses(course_id)
) ENGINE=InnoDB;
场景 4:日志或审计数据存储

CREATE TABLE logs (
log_id INT NOT NULL AUTO_INCREMENT,
log_date DATETIME,
log_level VARCHAR(20),
message TEXT,
PRIMARY KEY (log_id)
) ENGINE=MyISAM;
6. 说一下MySQL事务



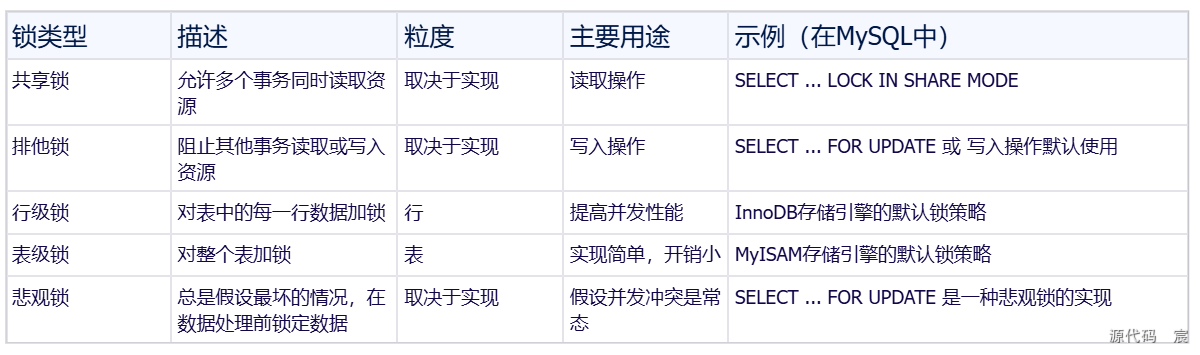
定义事务代码样例:
-- 开始一个事务
START TRANSACTION;
-- 检查A账户余额是否足够
DECLARE a_balance DECIMAL(10, 2);
SELECT money INTO a_balance FROM account WHERE name = 'A';
IF a_balance < 300 THEN
-- 如果A账户余额不足,则回滚事务并退出
ROLLBACK;
SELECT '转账失败:A账户余额不足';
EXIT;
END IF;
-- 从A账户扣款
UPDATE account SET money = money - 300 WHERE name = 'A';
-- 检查是否扣款成功(这里仅为演示,实际上扣款操作失败的可能性较小)
IF ROW_COUNT() != 1 THEN
-- 如果扣款失败,则回滚事务并退出
ROLLBACK;
SELECT '转账失败:扣款失败';
EXIT;
END IF;
-- 向B账户存款
UPDATE account SET money = money + 300 WHERE name = 'B';
-- 检查是否存款成功(这里仅为演示,实际上存款操作失败的可能性较小)
IF ROW_COUNT() != 1 THEN
-- 如果存款失败,则回滚事务并退出
ROLLBACK;
SELECT '转账失败:存款失败';
EXIT;
END IF;
-- 如果所有操作都成功,则提交事务
COMMIT;
SELECT '转账成功';
加锁代码样例:

START TRANSACTION;
-- 使用 FOR UPDATE 为要修改的行加上排他锁 这个查询是为了选择账户A的余额,同时为查询到的行加上排他锁(即 FOR UPDATE)。
-- FOR UPDATE 是一种行级锁,它会锁定查询返回的行,使得其他事务无法修改这些行,直到当前事务提交。这保证了在转账过程中,其他事务不能同时修改 A 账户的余额,避免了数据冲突和竞争条件。
SELECT money FROM account WHERE name = 'A' FOR UPDATE;
-- 检查A账户余额是否足够
DECLARE a_balance DECIMAL(10, 2);
SET a_balance = (SELECT money FROM account WHERE name = 'A' FOR UPDATE);
IF a_balance < 300 THEN
-- 如果A账户余额不足,则回滚事务
ROLLBACK;
SELECT '转账失败:A账户余额不足';
ELSE
-- 从A账户扣款
UPDATE account SET money = money - 300 WHERE name = 'A';
-- 假设这里没有错误处理,因为扣款通常不会失败
-- 向B账户存款
UPDATE account SET money = money + 300 WHERE name = 'B';
-- 如果所有操作都成功,则提交事务
COMMIT;
SELECT '转账成功';
END IF;
排他锁的作用是为了确保在事务过程中,数据不会被其他并发事务修改,保证数据的一致性和隔离性。它不阻止当前事务修改数据,而是防止其他事务在当前事务未完成时修改相同的数据。 在你的代码中,FOR UPDATE 确保了即使存在并发的其他事务,也不会在你检查余额和执行扣款之间修改 A 账户的余额。

7. 说一下 MVCC 机制,实现原理
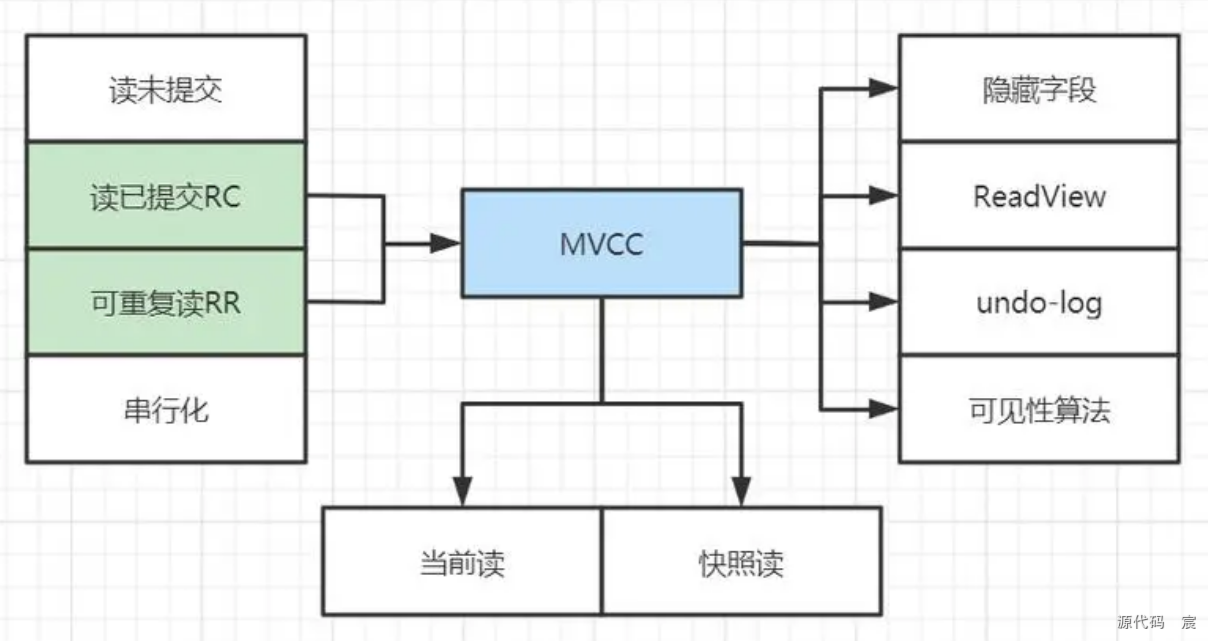
7.1 MVCC机制
MVCC(Multi-Version Concurrency Control,多版本并发控制)是数据库管理系统(DBMS)中用于解决读写冲突的一种并发控制机制,特别在MySQL的InnoDB存储引擎中被广泛采用。下面是对MVCC机制的分点说明和归纳:



7.2 实现原理
MVCC的实现原理主要体现在其InnoDB存储引擎中,旨在解决读-写并发冲突,避免在读写操作时加锁,从而实现非阻塞的读操作。
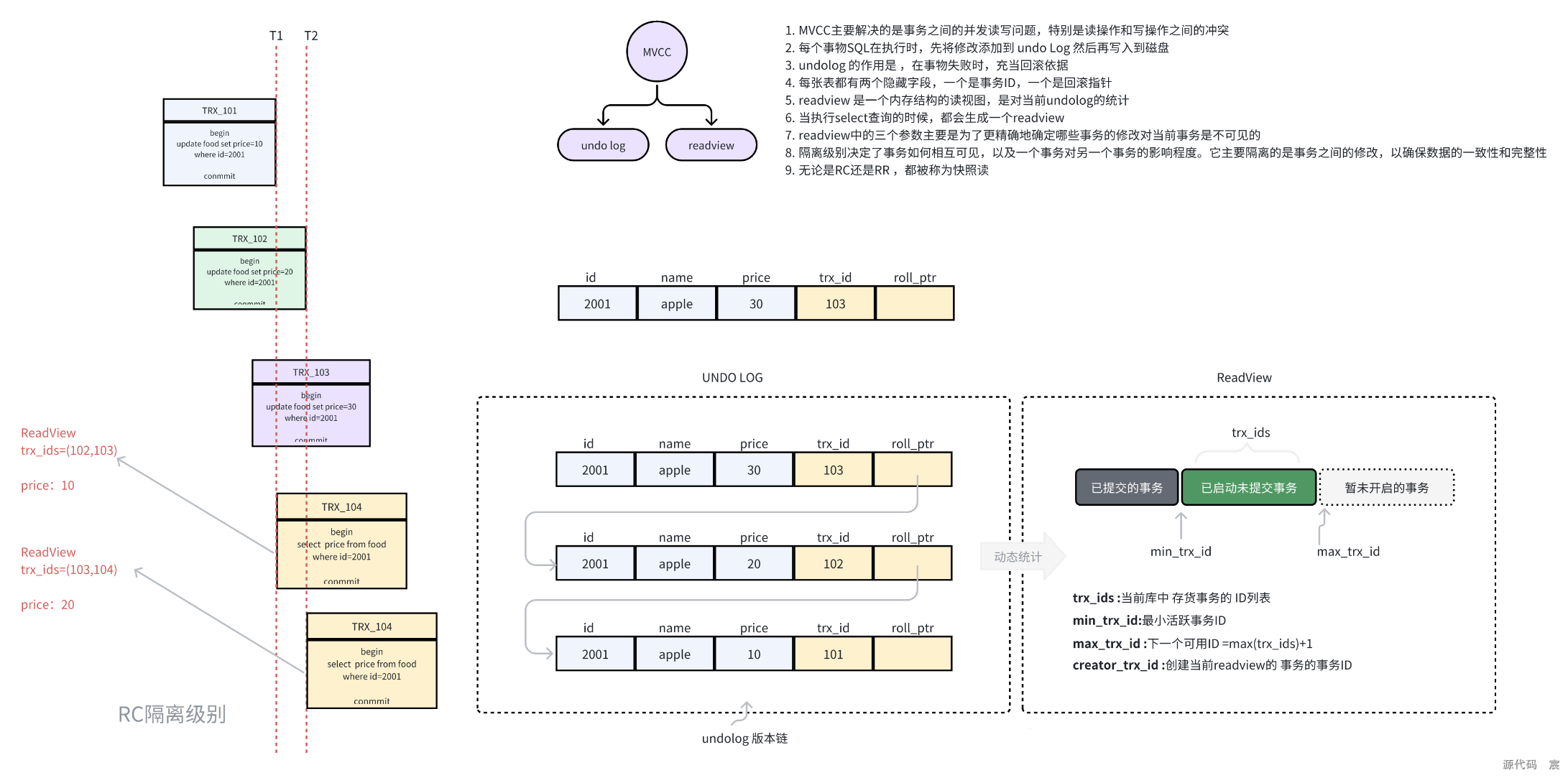

8. 隔离级别有哪些?MVCC 机制用于哪些隔离级别?
MySQL 的事务隔离级别定义了事务之间如何相互影响,以及一个事务可以看到其他事务所做的修改。
MySQL 支持以下四种事务隔离级别:
1. READ UNCOMMITTED(未提交读)

2. READ COMMITTED(提交读)RC

3. REPEATABLE READ(可重复读)RR

4. SERIALIZABLE(可串行化)


9. MVCC 解决了哪些问题?
MySQL 的 InnoDB 存储引擎通过实现多版本并发控制(MVCC, Multi-Version Concurrency Control)来解决了多个并发事务之间读取和写入操作的冲突问题,从而提高了数据库的并发性能。具体来说,MVCC 解决了以下几个主要问题:

需要注意的是,虽然 MVCC 带来了很多好处,但它也增加了一些开销,例如需要额外的存储空间来保存数据的多个版本,以及更复杂的并发控制逻辑。因此,在使用 MVCC 时需要根据具体的业务需求和系统环境进行权衡。
10. 索引如何优化?
针对MySQL的索引优化,我们可以从以下几个方面进行详细解释和样例展示:
1. 创建适当的索引:
- 选择性高的列:优先为选择性高的列(即列中不同值的比例高)创建索引。例如,一个只有几个不同值的列(如性别列)可能不是创建索引的好选择,因为索引可能不会显著提高查询性能。
- 经常用于查询的列:在WHERE子句、JOIN操作或ORDER BY子句中经常使用的列是创建索引的好候选。
示例:
CREATE INDEX idx_name ON your_table (column_name);
假设我们有一个名为 employees 的表,里面包含 id、name、department 等列。如果我们经常通过 name 字段来查找员工,可以创建如下的索引:
CREATE INDEX idx_employee_name ON employees (name);
2. 避免不必要的索引:
- 索引虽然能提升查询性能,但也会降低写操作的性能(如INSERT、UPDATE、DELETE),并占用额外的存储空间。因此,应避免在不需要的列上创建索引,特别是在经常更新的列上。
3. 使用复合索引:
- 当查询条件涉及多个列时,考虑使用复合索引(联合索引)。复合索引的列顺序很重要,应该基于列的选择性和查询中的列顺序来决定。
示例:
CREATE INDEX idx_name ON your_table (column1, column2);
假设我们有一个 employees 表,包含 first_name、last_name 和 department 三个字段,并且你经常需要查询姓氏和名字的组合,或者查询姓氏和部门的组合。你可以创建一个联合索引:
CREATE INDEX idx_name_dept ON employees (last_name, department);
这个索引会加速基于 last_name 和 department 列的查询。
通过 last_name 和 department 查询:
假设你经常查询员工姓氏为 “Smith” 并且部门为 “IT” 的员工,创建联合索引后,查询如下:
SELECT * FROM employees WHERE last_name = 'Smith' AND department = 'IT';
数据库会利用 idx_name_dept 联合索引快速定位匹配的行。
4. 使用覆盖索引:
- 覆盖索引是指索引包含了查询所需的所有列,而不需要回表检索数据。这可以显著提高查询性能。
示例:
CREATE INDEX idx_covering ON your_table (column1, column2);
- 对于查询SELECT column1, column2 FROM your_table WHERE column1 = ‘value’;,由于索引包含了所有需要的列,MySQL可以直接从索引中获取数据,而无需回表。
5. 考虑索引的选择性:
- 选择性是指索引列中不同值的比例。选择性越高,索引的效率通常也越高。
6. 使用前缀索引:
- 对于文本类的长字符串,可以考虑使用前缀索引来减少索引的大小。但需要注意,前缀长度应足够长以提供足够的选择性。
示例:
CREATE INDEX idx_prefix ON your_table (column_name(10));
7. 定期审查和维护索引:
- 随着数据的增长和变化,可能需要定期审查和调整索引策略。使用MySQL的EXPLAIN命令可以帮助你分析查询的执行计划,从而确定是否需要添加、删除或修改索引。
8. 选择合适的索引类型:
- MySQL支持多种索引类型,如B-Tree、Hash等。B-Tree索引适用于范围查询和排序操作,而Hash索引适用于等值查询。根据实际情况选择合适的索引类型非常重要。
11. 说一下 select、poll、epoll,以及它们的使用场景
在一个(或少量)线程里同时等待多个 IO 通道(socket/管道/文件描述符)变得可行的机制。它让你不用为每个连接开一个线程,而是用事件驱动方式在“谁准备好了我就处理谁”。
11.1 select
- 用途:select函数是一个监控函数,用于监控文件描述符(通常是套接字)的状态,包括可读、可写和异常状态。
- 优点:使用select函数可以实现非阻塞方式的程序,避免程序在I/O操作时被阻塞。
- 使用场景:适用于监控的文件描述符数量较少,且对性能要求不是特别高的场景。由于select函数通过线性表描述文件描述符集合,文件描述符有上限(一般是1024),并且每次调用select函数时都需要将文件描述符集合从用户空间拷贝到内核空间,因此在处理大量文件描述符时性能会下降。
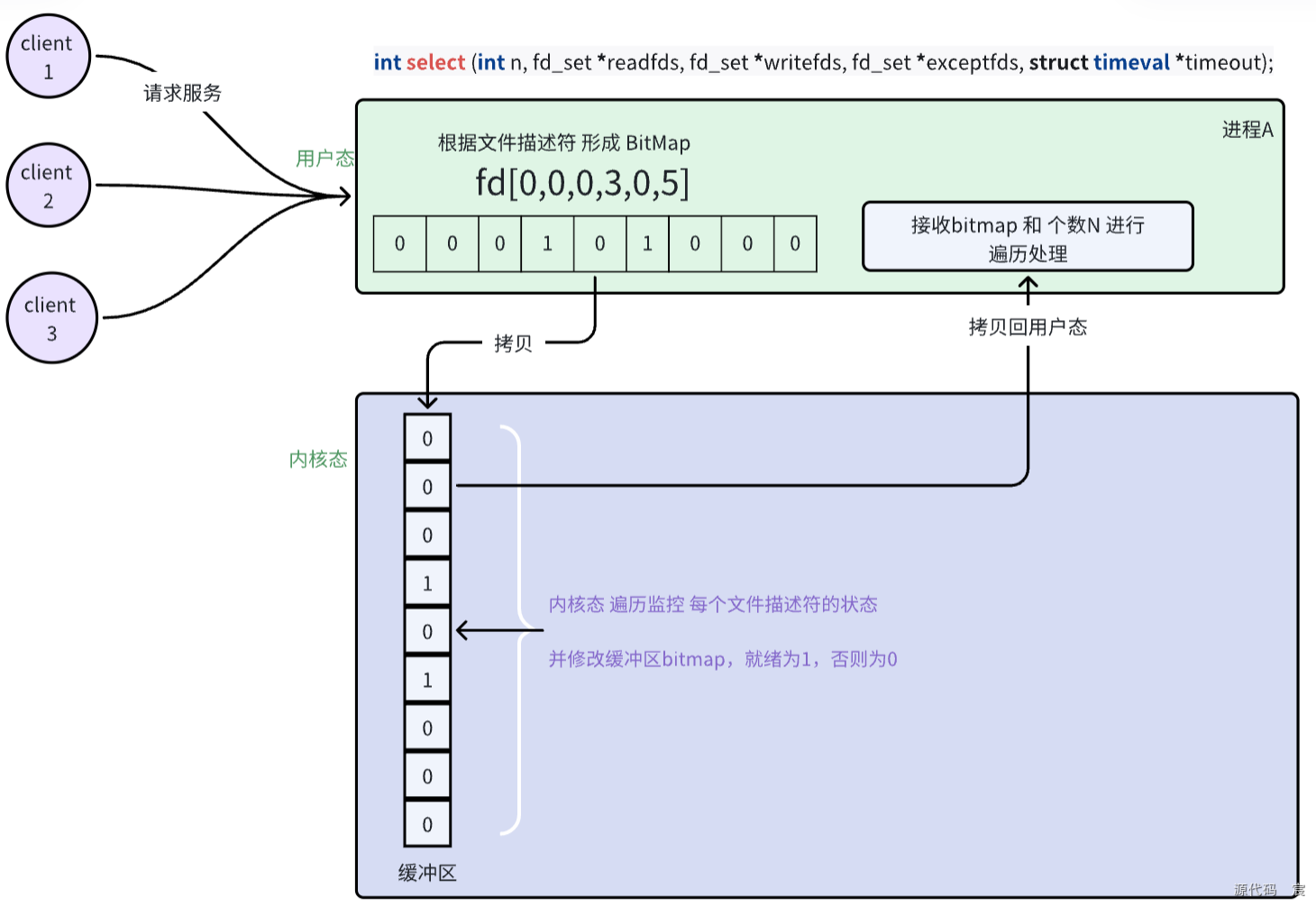


11.2 poll

11.3 epoll
- 特点:epoll是一组函数,包括epoll_create、epoll_ctl和epoll_wait等。epoll通过红黑树来描述文件描述符集合,并且使用事件驱动的方式,避免了每次调用时都进行文件描述符集合的拷贝。此外,epoll还支持ET(Edge Triggered)和LT(Level Triggered)两种触发模式,以及EPOLLONESHOT事件,进一步提高了性能。
- 使用场景:epoll适用于高性能、高并发的网络服务器场景,如游戏服务器、实时聊天应用等。在这些场景中,需要处理大量的并发连接和I/O操作,epoll能够显著提高服务器的处理能力和性能。
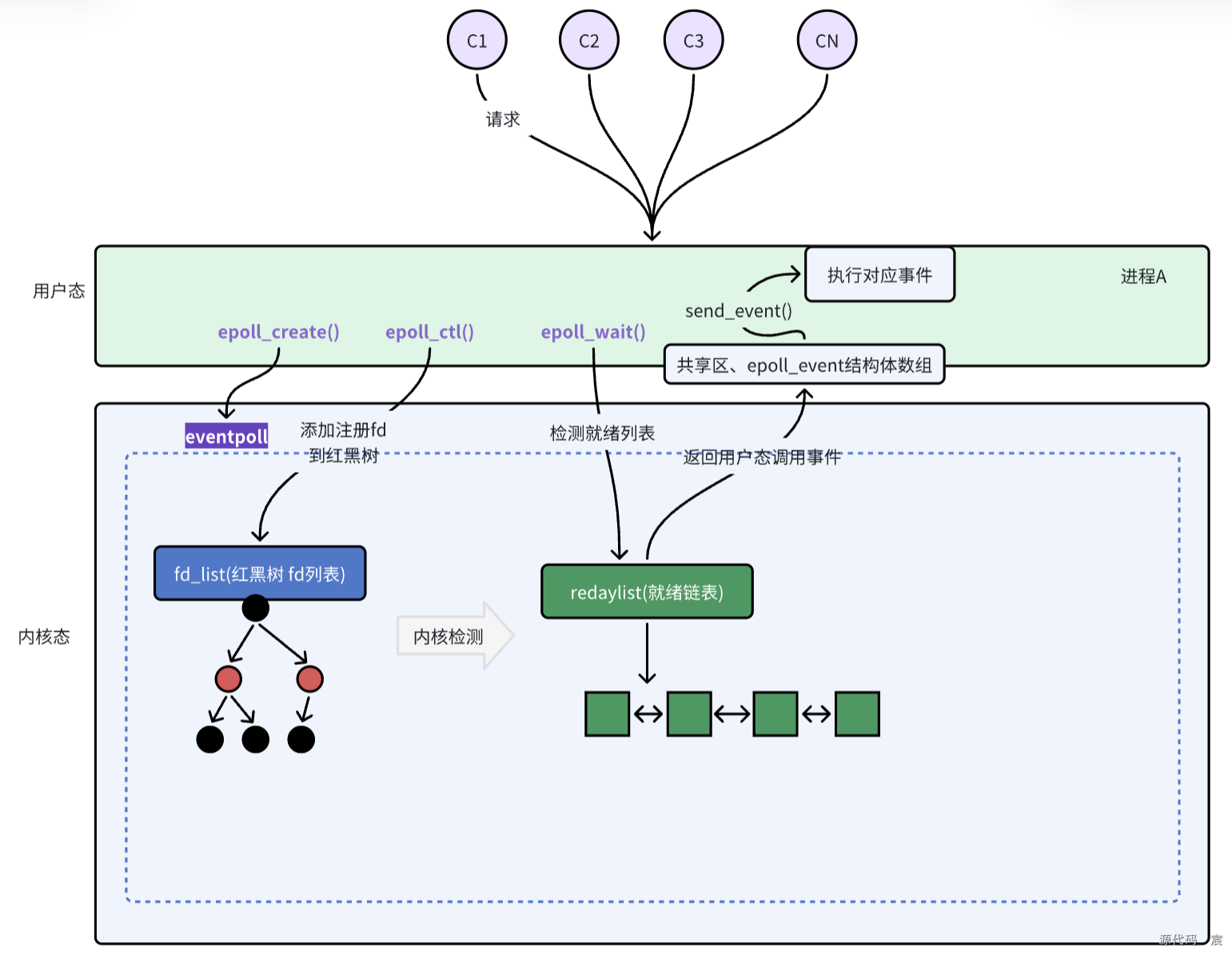

1. epoll 的核心概念
- 文件描述符(File Descriptor, FD):用于标识一个进程正在使用的文件、套接字等资源。
- 事件(Event):epoll 监听的文件描述符的状态变化,如可读、可写、错误等。
- epoll 文件描述符 :通过 epoll_create 创建,用于管理和监听多个文件描述符的状态变化。
2. epoll 的三个系统调用

3. epoll 的两种模式

4. epoll 的工作流程

5. epoll 的内部实现

LT:逻辑更简单;即使一次没读完/写完,稍后还会再收到事件。
ET:必须把 fd 设为非阻塞(O_NONBLOCK),并在回调里循环到 EAGAIN;否则可能永远收不到下一次事件(“饿死”)。
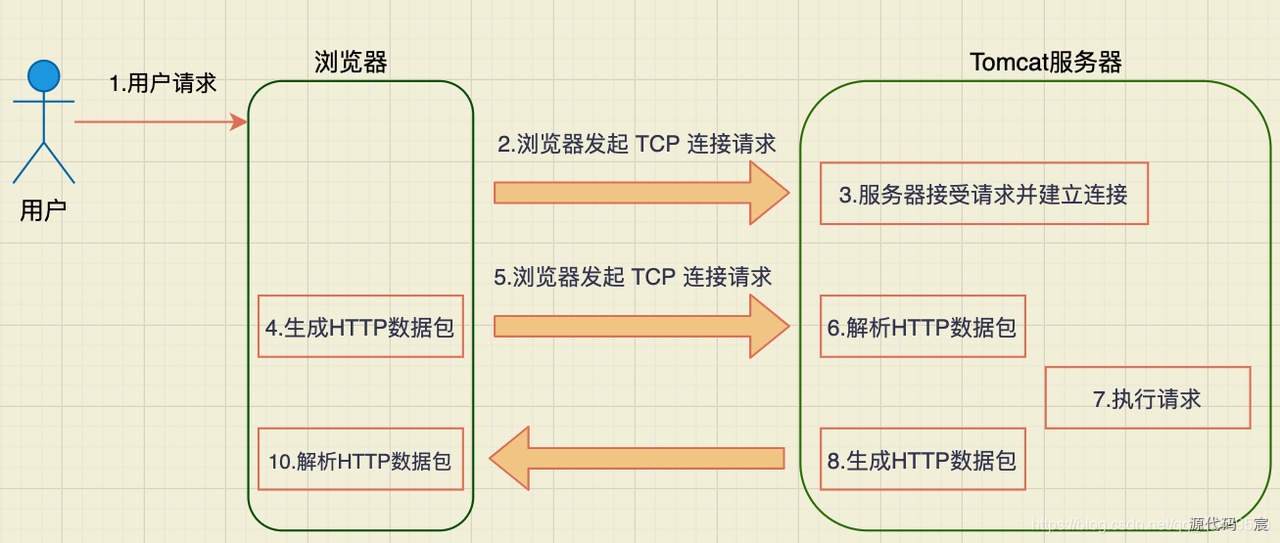
12. 输入 URL 后发生的事情
当用户在浏览器中输入一个URL(统一资源定位符)并按下回车键后,会发生一系列的事情来处理和加载该URL对应的网页。
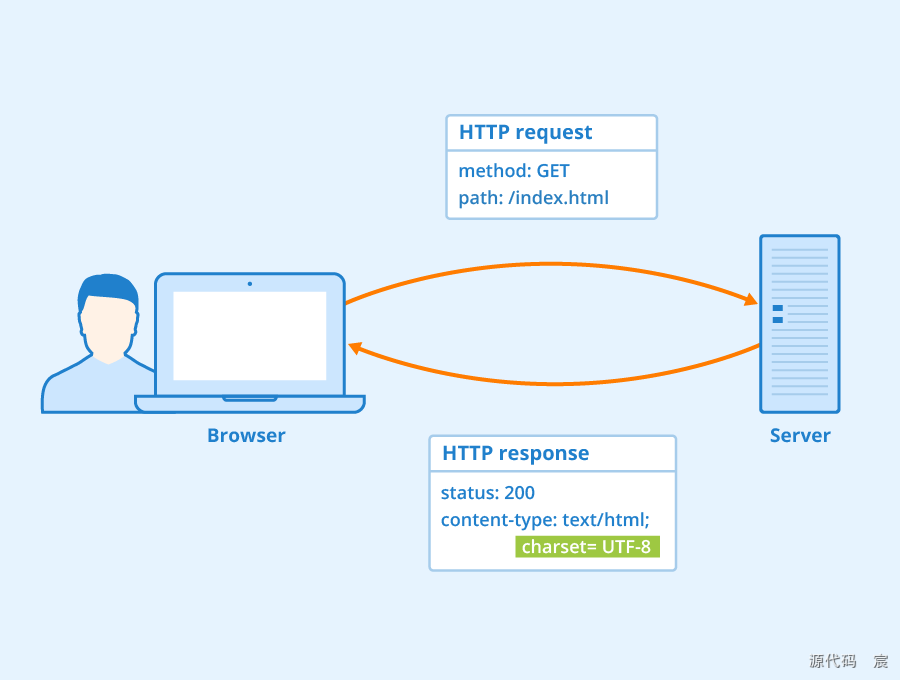

13. HTTP 基于什么协议实现?
HTTP(Hypertext Transfer Protocol,超文本传输协议)是基于TCP/IP协议实现的应用层协议。它定义了客户端和服务器之间传输超文本(如HTML文档)的规则和方式。具体来说,HTTP协议使用TCP协议来确保数据的可靠传输,因为TCP协议提供了数据包的确认、重传等机制,以确保数据在传输过程中不会被丢失或损坏。
在HTTP通信中,客户端(如Web浏览器)通过TCP连接向服务器发送HTTP请求,服务器接收到请求后,处理该请求并返回相应的HTTP响应。HTTP请求和响应都由一系列的文本行组成,这些文本行遵循特定的格式和规则,以便客户端和服务器能够正确地解析和处理它们。
需要注意的是,虽然HTTP协议本身并不直接依赖于IP协议,但它是通过TCP/IP协议栈中的TCP协议来传输数据的。因此,HTTP协议的实现离不开TCP/IP协议的支持。
14. HTTP 和 HTTPS 的区别?
HTTP(Hypertext Transfer Protocol,超文本传输协议)和HTTPS(Hypertext Transfer Protocol Secure,安全的超文本传输协议)在很多方面都是相似的,因为它们都用于在Web浏览器和服务器之间传输数据。然而,它们在安全性方面存在显著的区别。
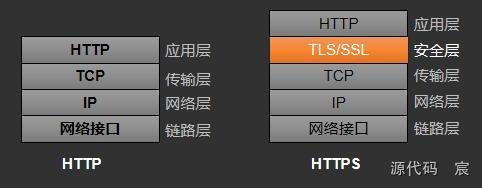
以下是HTTP和HTTPS的主要区别:

15. HTTPS 如何确保安全性?

SSL 和 TLS的区别是什么

16. 为什么不能只使用非对称加密?
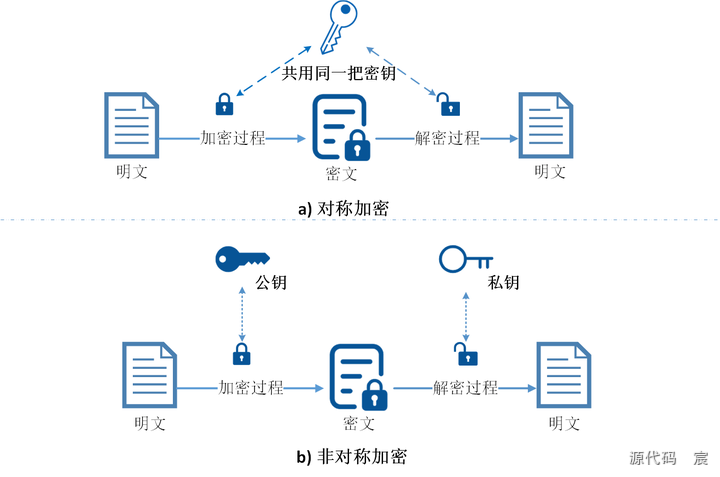
不能只使用非对称加密进行数据传输主要有以下几个原因:

17. 说一下 CA 证书
CA证书(Certificate Authority Certificate)是数字证书认证机构(Certification Authority, CA)颁发的用于确保网络通信安全的数字证书。以下是关于CA证书的详细解释:

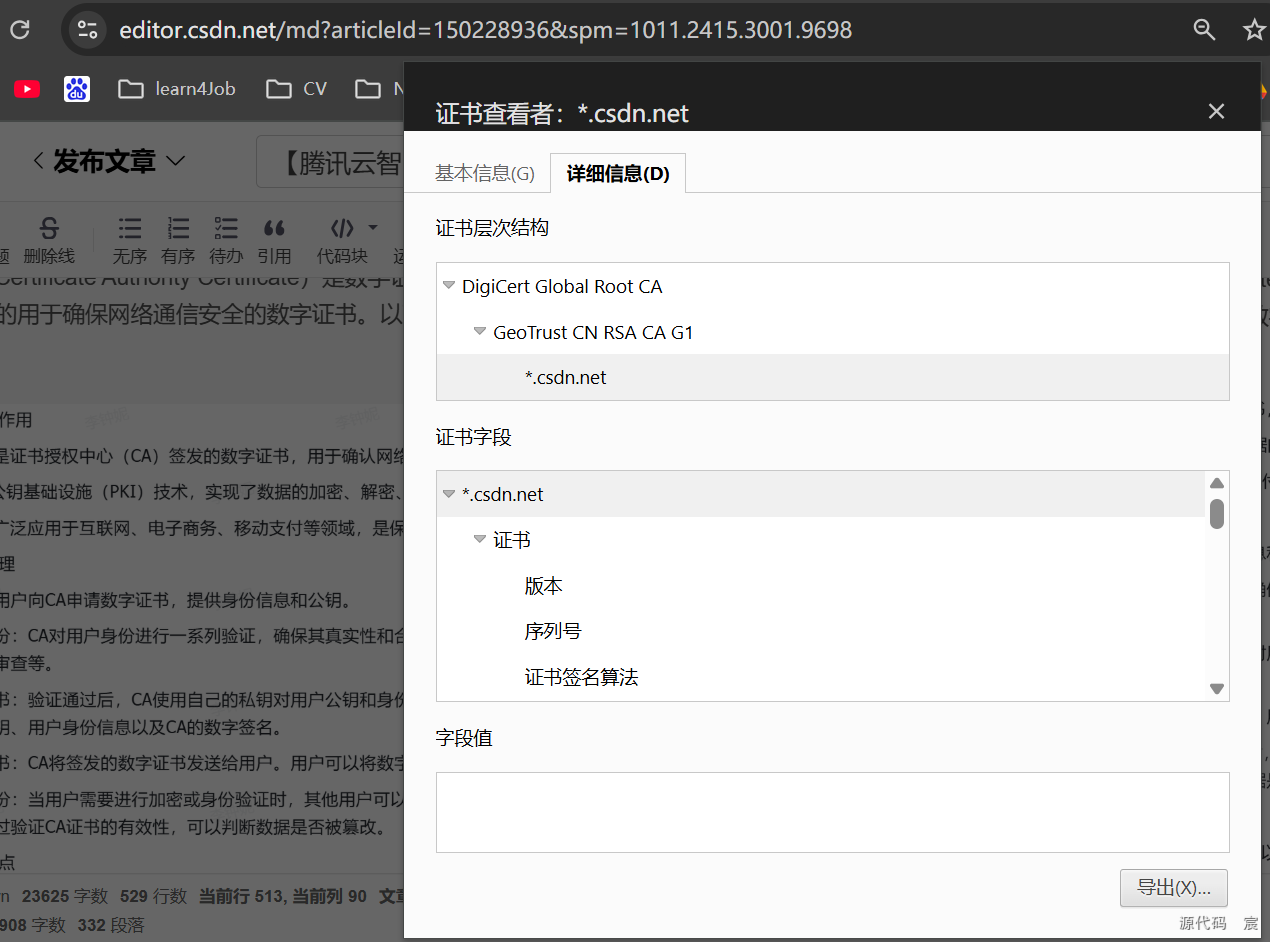
18. CA证书是由谁传输的?
CA证书(Certificate Authority Certificate)的传输通常涉及多个步骤和参与者,但主要来说,它是由证书颁发机构(Certificate Authority, CA)生成并传输给需要它的实体的。
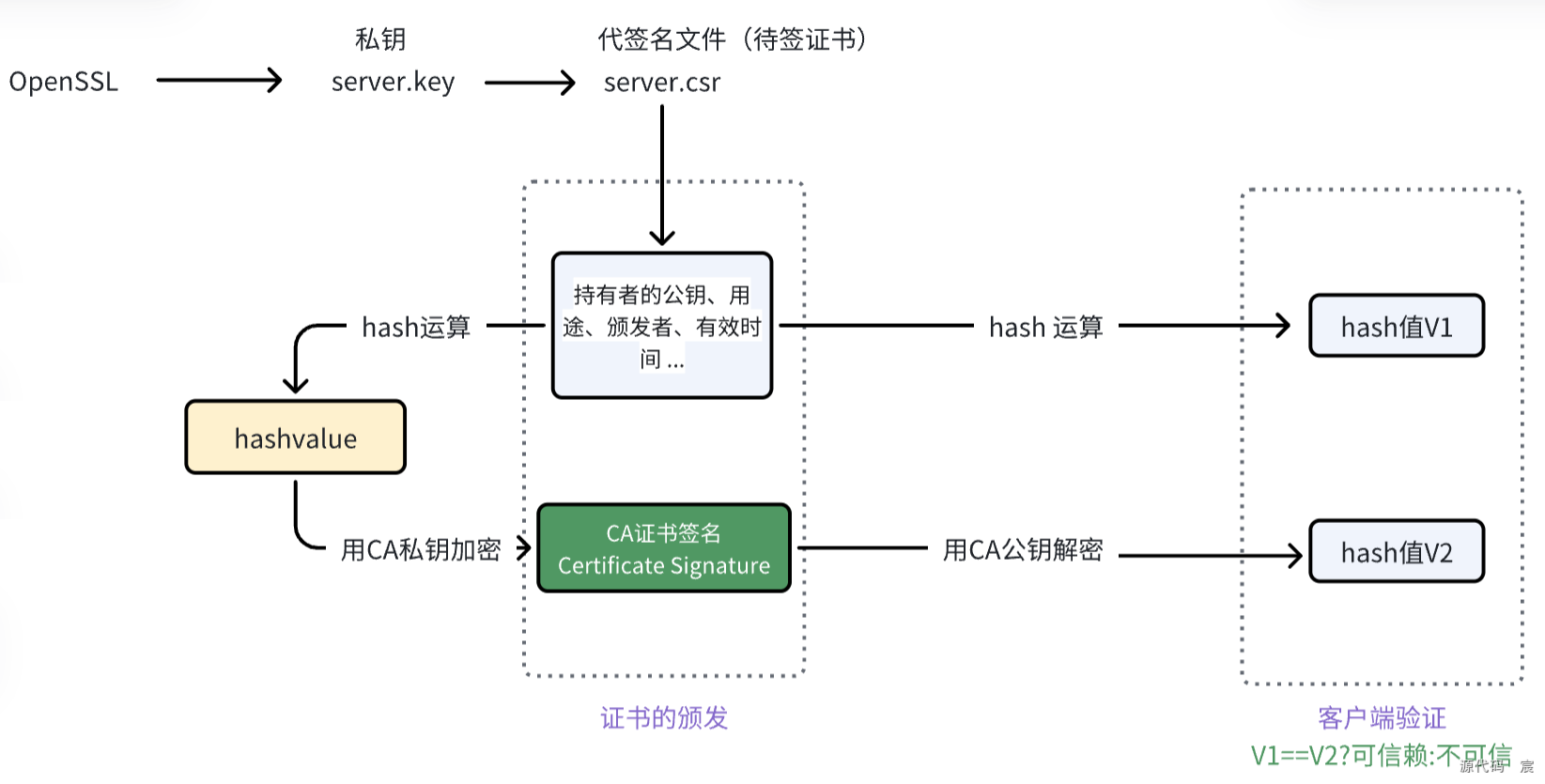
以下是CA证书传输的一般过程:

19. 如何使用 CA 证书(CA 证书是如何保证安全的)?

20. 如果访问两个不同的网站,如何获取 CA 的公钥?
当访问两个不同的网站时,获取CA(证书颁发机构)的公钥的过程主要依赖于HTTPS协议和浏览器的功能。
以下是获取CA公钥的步骤和解释:
步骤一:HTTPS握手
- 建立连接:当浏览器尝试通过HTTPS连接到网站时,会与网站的服务器建立TCP连接。
- SSL/TLS握手:在TCP连接建立后,浏览器和服务器会进行SSL/TLS握手,以协商安全参数并验证对方的身份。
步骤二:服务器发送证书链
- 证书链传输:在握手过程中,服务器会将其SSL/TLS证书(以及可能的证书链)发送给浏览器。证书链包括服务器的证书、中间证书(如果有的话)和根证书。
- 证书验证:浏览器会验证这个证书链的有效性,包括检查证书是否由受信任的CA签发、是否过期、域名是否匹配等。
步骤三:获取CA公钥
- 从证书链中提取:在验证证书链的过程中,浏览器会找到根证书。这个根证书是由受信任的CA签发的,并包含了CA的公钥。浏览器会从这个根证书中提取CA的公钥。
- 使用CA公钥:一旦获取了CA的公钥,浏览器就可以使用它来验证服务器证书的签名了。这是通过解密服务器证书上的数字签名并检查其内容是否与证书的其他部分相匹配来实现的。
答案归纳
- HTTPS握手:通过HTTPS协议建立与网站的连接,并进行SSL/TLS握手。
- 证书链传输:服务器发送其SSL/TLS证书链给浏览器。
- 证书验证:浏览器验证证书链的有效性,包括检查证书是否由受信任的CA签发。
- 获取CA公钥:从证书链中的根证书中提取CA的公钥,并使用它来验证服务器证书的签名。
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)