Python——一文读懂Pandas数据分析工具的实用技巧
在数据科学和数据分析的领域,Python 已经成为一种流行的编程语言,而 Pandas 库则是 Python 中最重要的数据分析工具之一。Pandas 提供了高效、灵活的数据结构和数据分析工具,使得处理和分析数据变得更加简单和直观。
目录
一、什么是Pandas?
Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)
Pandas 是 Python 数据科学领域中不可或缺的工具之一,它的灵活性和强大的功能使得数据处理和分析变得更加简单和高效。
Pandas 应用
- Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
- Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征
- Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
二、安装Pandas
Jupyter Notebook是有一个开源的交互式开发环境,可以实时查看的代码的运行效果
pip install pandas jupyter安装完成后,启动Jupyter Notebook
jupyter notebook启动后访问控制台输出的地址,就可以访问Jupyter了
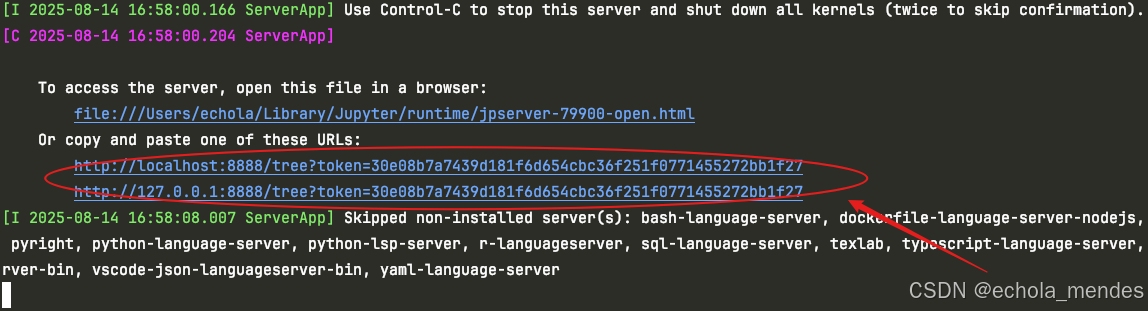
Jupyter:http://127.0.0.1:8888/tree,可以看到当前Python项目的目录了
如果退出Jupyter,请先保存后,再选择File-->Shut Down退出,或者在终端Ctrl+C后,输入y,即可退出
三、Pandas 功能
Pandas 是数据分析的利器,它不仅提供了高效、灵活的数据结构,还能帮助你以极低的成本完成复杂的数据操作和分析任务。
Pandas 提供了丰富的功能,包括:
- 数据清洗:处理缺失数据、重复数据等。
- 数据转换:改变数据的形状、结构或格式。
- 数据分析:进行统计分析、聚合、分组等。
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
1.数据结构
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据,类似于电子表格或 SQL 表)
Series
一维数组,支持存储不同数据类型的元素,可以通过列表和字典创建
创建一个简单的 Series 实例:
从列表创建
import pandas as pd
# 创建一个Series对象,指定名称为'A',值分别为1, 2, 3, 4
# 默认索引为0, 1, 2, 3
series = pd.Series([1, 2, 3, 4], name='A')
print(series)输出结果:
#索引 数据
0 1
1 2
2 3
3 4
Name: A, dtype: int64 从字典创建,字典的键会自动成为 Series 的索引名称
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
series = pd.Series(sites)
print(series)输出结果:
1 Google
2 Runoob
3 Wiki
dtype: object可以自定义索引名称,根据索引名称获取数据
Series的基本操作
索引访问 可以通过索引标签或位置访问数据。
s = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
print(s['a']) # 输出 10
print(s[0]) # 输出 10
切片操作 支持类似列表的切片操作
print(s[0:2]) # 输出前两个元素
print(s['a':'b']) # 输出索引 'a' 到 'b' 的元素
数学运算 Series 支持逐元素的数学运算
s1 = pd.Series([1, 2, 3])
s2 = pd.Series([4, 5, 6])
print(s1 + s2) # 输出 [5, 7, 9]
条件过滤 可以通过布尔条件过滤数据
s = pd.Series([10, 20, 30])
print(s[s > 15]) # 输出大于 15 的元素
Series 的常用方法
- s.head(n):返回前 n 行(默认 n=5)
- s.tail(n):返回后 n 行(默认 n=5)
- s.describe():生成描述性统计信息(如均值、标准差等)
- s.isnull():检查缺失值(返回布尔 Series)
- s.fillna(value):填充缺失值为指定值
DataFrame
DataFrame 是一种二维表格型数据结构,常用于数据处理和分析。它类似于电子表格或SQL表,包含行和列,每列可以是不同的数据类型(数值、字符串、布尔值等)
可以通过字典、列表、NumPy 数组或外部文件(如 CSV、Excel)创建
创建一个简单的 DataFrame:
import pandas as pd
# 创建一个简单的 DataFrame
data = {'Name': ['Google', 'Runoob', 'Taobao'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 查看 DataFrame
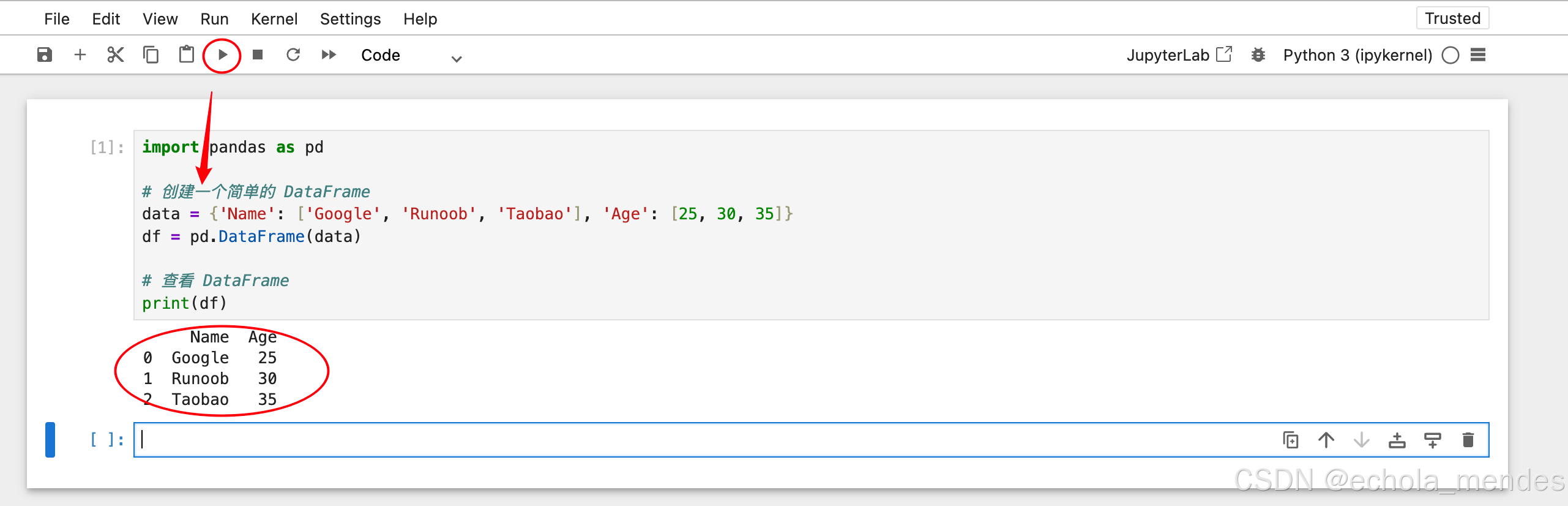
print(df)⚠️注意:文件名不能使用pandas会出现命名,pd 指向的是你本地项目中的 pandas 模块,而不是真正的pandas库,否则会报错module 'pandas' has no attribute 'Data'
输出以下格式,可以看出DataFrame是一个二维表格,类似于Excel或SQL中的表
Name Age
0 Google 25
1 Runoob 30
2 Taobao 35进入Jupyter后单击右键选择New Notebook后,再选择Python的版本

在notebook中运行上述代码,可以看出Jupyter可以即时预览运行效果
DataFrame基本操作
访问数据
# 获取列
df['Name']
# 获取行
df.loc[0] # 按标签
df.iloc[0] # 按位置
数据筛选
# 条件筛选
df[df['Age'] > 25]
修改数据
# 新增列
df['Salary'] = [50000, 60000,10000]
# 修改值
df.at[0, 'Age'] = 26
数据统计与聚合
# 描述性统计
df.describe()
# 分组聚合
df.groupby('Name')['Age'].mean()
2.数据读取与写入
读取
Pandas支持从多种文件格式中读取数据,如CSV、Excel、SQL数据库等。
| 函数 | 说明 |
|---|---|
| pd.read_csv(filename) | 读取 CSV 文件; |
| pd.read_excel(filename) | 读取 Excel 文件; |
| pd.read_sql(query, connection_object) | 从 SQL 数据库读取数据; |
| pd.read_json(json_string) | 从 JSON 字符串中读取数据; |
| pd.read_html(url) | 从 HTML 页面中读取数据。 |
读取CSV文件的示例:
import pandas as pd
df = pd.read_csv("./data/student.csv")
df可以看到以下输出结果,这里不使用print(df),是Jupyter Notebook 基于 IPython 内核,具有自动输出显示的功能。自动调用其 __repr__ 方法并显示结果,无需显式调用print(df),以下操作都在Jupyter中运行了,不再使用print()进行输出
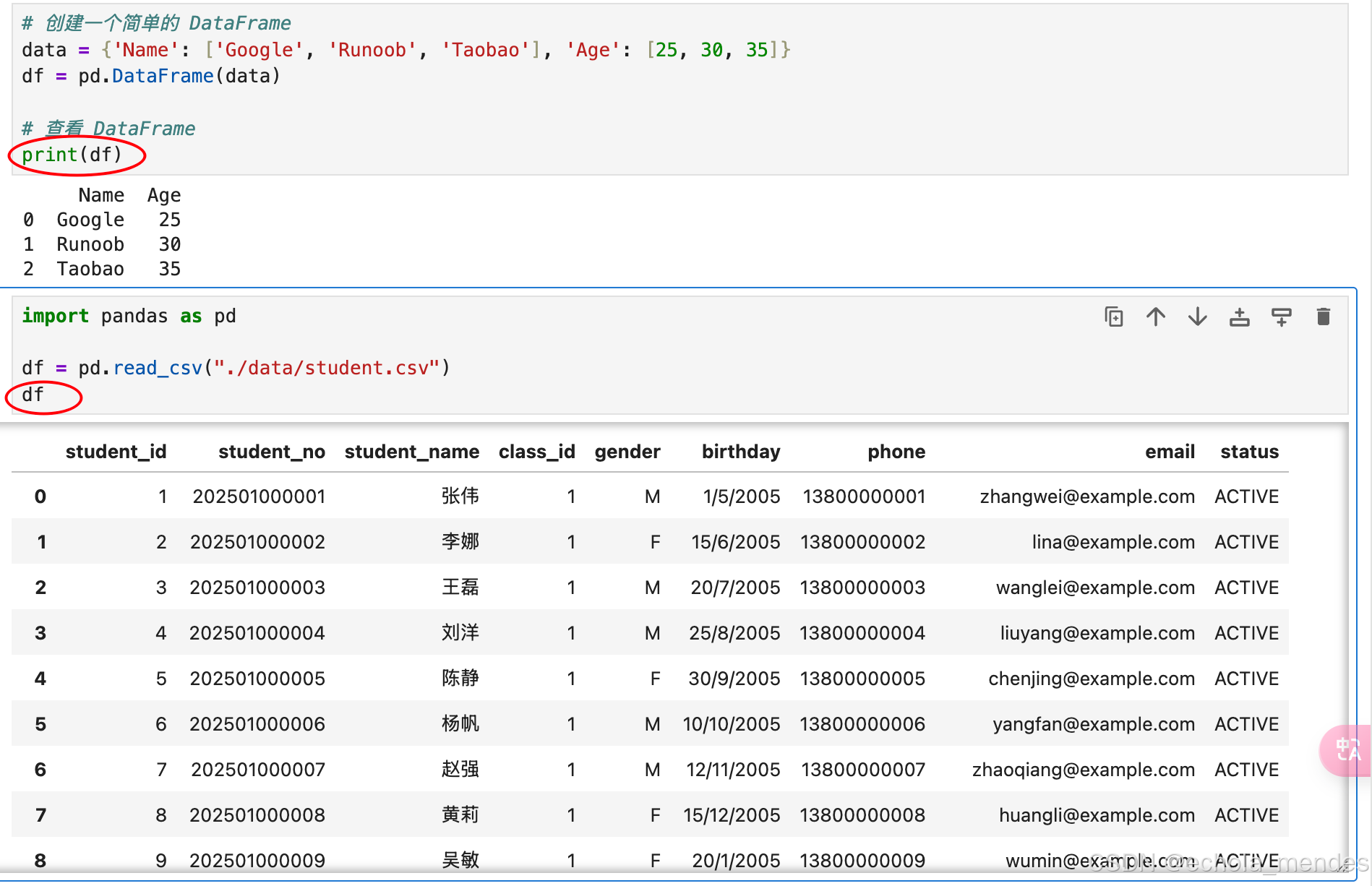
输出表格的前几行呢?
直接使用df.head(n)读取前面的 n 行,如果不填参数 n ,默认返回 5 行
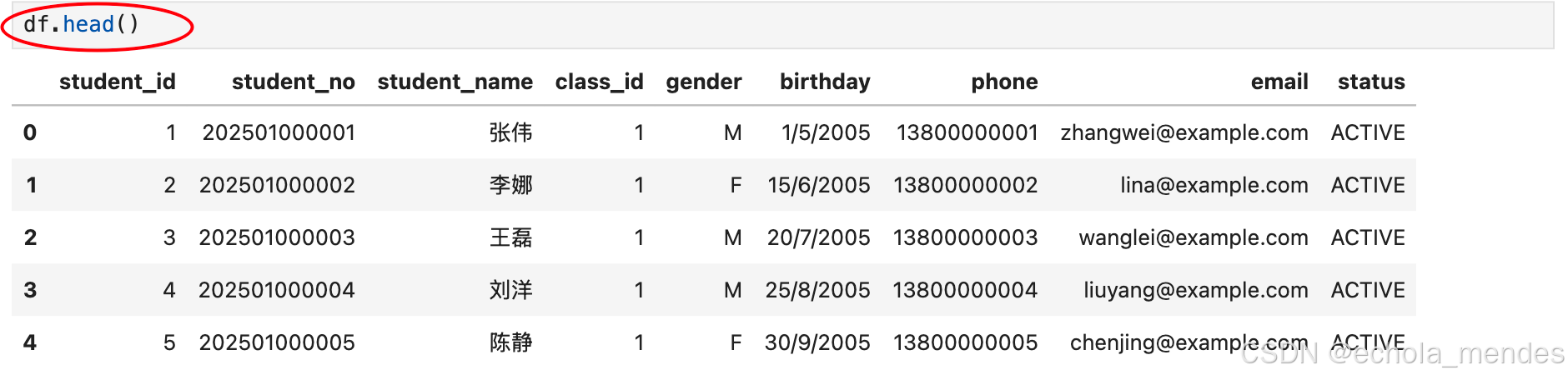
可以看到不需要再次读取csv文件,就可以输出结果,其代码执行单元(Cell)共享同一个内核进程。每次执行代码时,变量和对象会保留在内核的内存中,除非显式删除或重启内核
简单点说就是
- CSV 文件被加载到内存中,生成一个 DataFrame 对象
- 该对象被赋值给变量
df并存储在内核的命名空间中 - 即使不重新执行读取代码,
df变量依然有效
执行df.head()直接引用内存中已存在的 df 对象,不需要重新从磁盘读取文件
⚠️注意:
- 如果修改了原始 CSV 文件,需要重新执行
read_csv()才能获取最新数据- 使用
%reset或重启内核会清除所有变量- 大文件多次读取会浪费内存,建议保持单次读取
写入
将数据写入CSV文件的示例:
import pandas as pd
# 创建一个简单的 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 将DataFrame保存为CSV文件,设置index参数为False
df.to_csv('output.csv', index=False)运行后可以看到会在当前文件目录下生成outpur.csvshu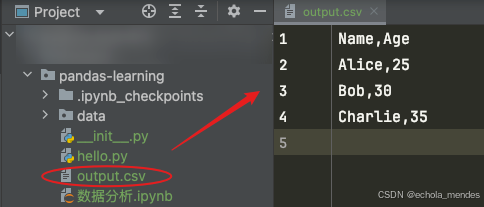
3.数据清洗与处理
数据清洗是对一些无用的数据进行处理的过程
在实际的数据分析过程中,数据往往会存在缺失值、异常值、重复、格式转换等等的问题,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理
常用方法
数据清洗与预处理的常见方法:
| 操作 | 方法/步骤 | 说明 | 常用函数/方法 |
|---|---|---|---|
| 缺失值处理 | 填充缺失值 | 使用指定的值(如均值、中位数、众数等)填充缺失值。 | df.fillna(value) |
| 删除缺失值 | 删除包含缺失值的行或列。 | df.dropna() |
|
| 重复数据处理 | 删除重复数据 | 删除 DataFrame 中的重复行。 | df.drop_duplicates() |
| 异常值处理 | 异常值检测(基于统计方法) | 通过 Z-score 或 IQR 方法识别并处理异常值。 | 自定义函数(如基于 Z-score 或 IQR) |
| 替换异常值 | 使用合适的值(如均值或中位数)替换异常值。 | 自定义函数(如替换异常值) | |
| 数据格式转换 | 转换数据类型 | 将数据类型从一个类型转换为另一个类型,如将字符串转换为日期。 | df.astype() |
| 日期时间格式转换 | 转换字符串或数字为日期时间类型。 | pd.to_datetime() |
|
| 标准化与归一化 | 标准化 | 将数据转换为均值为0,标准差为1的分布。 | StandardScaler() |
| 归一化 | 将数据缩放到指定的范围(如 [0, 1])。 | MinMaxScaler() |
|
| 类别数据编码 | 标签编码 | 将类别变量转换为整数形式。 | LabelEncoder() |
| 独热编码(One-Hot Encoding) | 将每个类别转换为一个新的二进制特征。 | pd.get_dummies() |
|
| 文本数据处理 | 去除停用词 | 从文本中去除无关紧要的词,如 "the" 、 "is" 等。 | 自定义函数(基于 nltk 或 spaCy) |
| 词干化与词形还原 | 提取词干或恢复单词的基本形式。 | nltk.stem.PorterStemmer() |
|
| 分词 | 将文本分割成单词或子词。 | nltk.word_tokenize() |
|
| 数据抽样 | 随机抽样 | 从数据中随机抽取一定比例的样本。 | df.sample() |
| 上采样与下采样 | 通过过采样(复制少数类样本)或欠采样(减少多数类样本)来平衡数据集中的类别分布。 | SMOTE()(上采样); RandomUnderSampler()(下采样) |
|
| 特征工程 | 特征选择 | 选择对目标变量有影响的特征,去除冗余或无关特征。 | SelectKBest() |
| 特征提取 | 从原始数据中创建新的特征,提升模型的预测能力。 | PolynomialFeatures() |
|
| 特征缩放 | 对数值特征进行缩放,使其具有相同的量级。 | MinMaxScaler() 、 StandardScaler() |
|
| 类别特征映射 | 特征映射 | 将类别变量映射为对应的数字编码。 | 自定义映射函数 |
| 数据合并与连接 | 合并数据 | 将多个 DataFrame 按照某些列合并在一起,支持内连接、外连接、左连接、右连接等。 | pd.merge() |
| 连接数据 | 将多个 DataFrame 进行行或列拼接。 | pd.concat() |
|
| 数据重塑 | 数据透视表 | 将数据根据某些维度进行分组并计算聚合结果。 | pd.pivot_table() |
| 数据变形 | 改变数据的形状,如从长格式转为宽格式或从宽格式转为长格式。 | df.melt() 、 df.pivot() |
|
| 数据类型转换与处理 | 字符串处理 | 对字符串数据进行处理,如去除空格、转换大小写等。 | str.replace() 、 str.upper() 等 |
| 分组计算 | 按照某个特征分组后进行聚合计算。 | df.groupby() |
|
| 缺失值预测填充 | 使用模型预测填充缺失值 | 使用机器学习模型(如回归模型)预测缺失值,并填充缺失数据。 | 自定义模型(如 sklearn.linear_model.LinearRegression) |
| 时间序列处理 | 时间序列缺失值填充 | 使用时间序列的方法(如前向填充、后向填充)填充缺失值。 | df.fillna(method='ffill') |
| 滚动窗口计算 | 使用滑动窗口进行时间序列数据的统计计算(如均值、标准差等)。 | df.rolling(window=5).mean() |
|
| 数据转换与映射 | 数据映射与替换 | 将数据中的某些值替换为其他值。 | df.replace() |
下面有测试数据,包含了四种数据n/a、NA、--、na
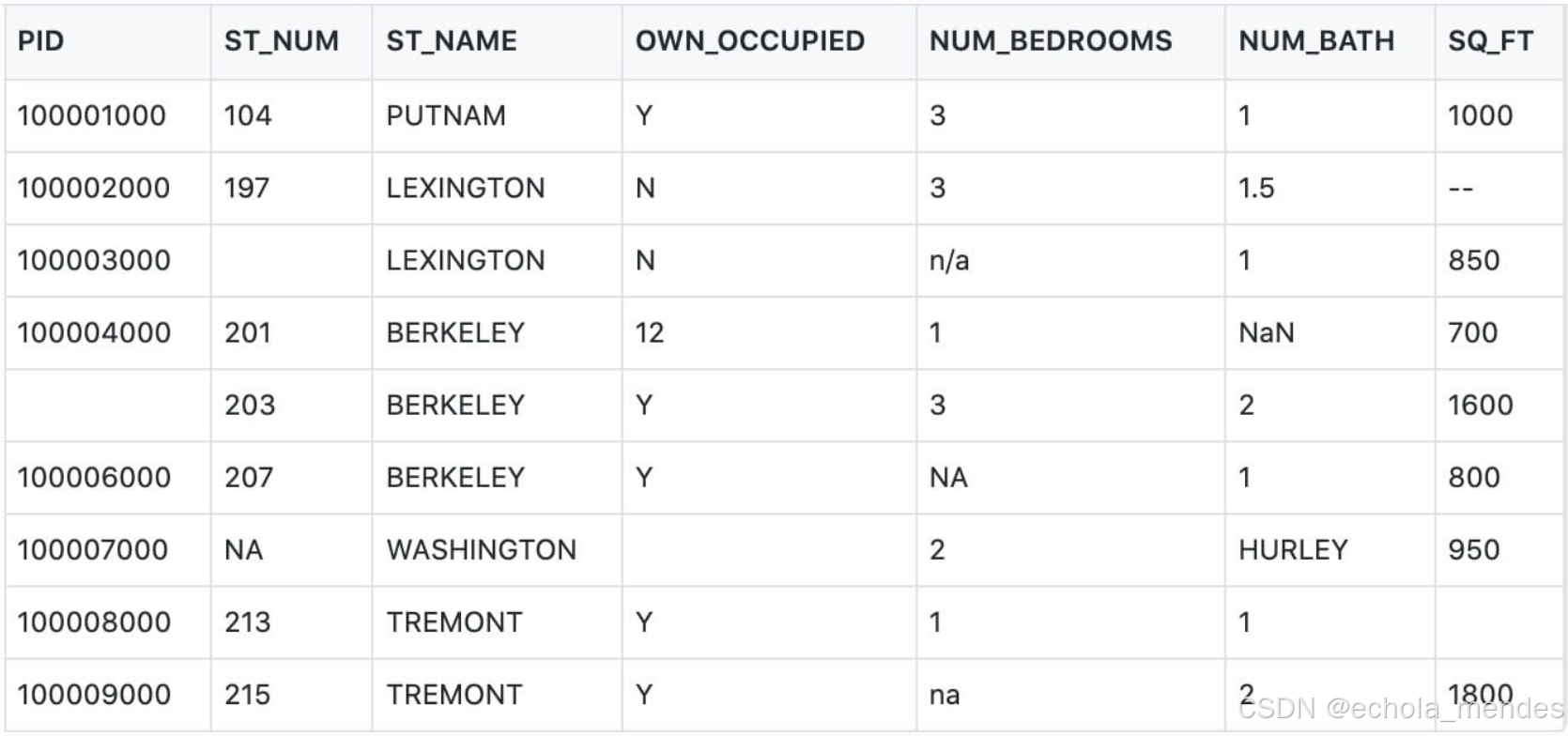
清洗空值
df['NUM_BEDROOMS'].isnull()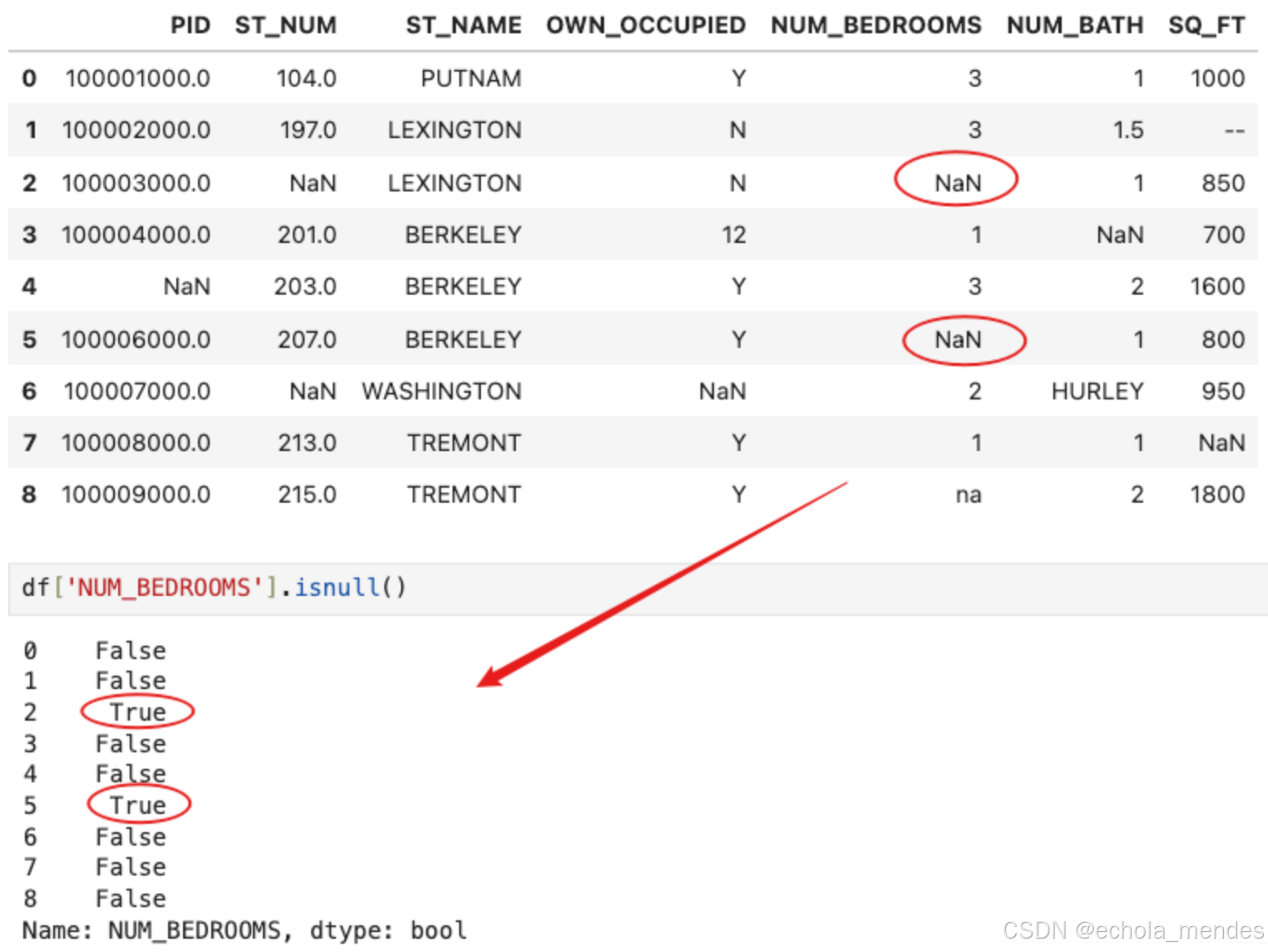
以上例子中我们看到 Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
missing_values = ["n/a", "na", "--"]
df = pd.read_csv("./data/property-data.csv", na_values = missing_values)
df['NUM_BEDROOMS'].isnull()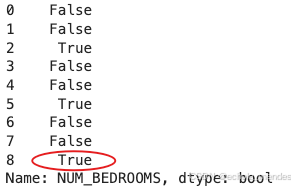
删除空值
那现在只是筛选出了空值,那从源文件中删除空值,使用dropna() ,默认情况下,dropna() 方法返回一个新的 DataFrame,不会修改源数据。
如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数
⚠️注意:只是修改Jupyter内存里的 DataFrame 对象df,不会把改动写回到硬盘上的原始文件(CSV、Excel、Parquet 等)。想持久化,必须再to_csv()
…
#移除所有有空值的行
df.dropna(inplace = True)
#移除指定列有空值的行
df.dropna(subset=['NUM_BEDROOMS'], inplace = True)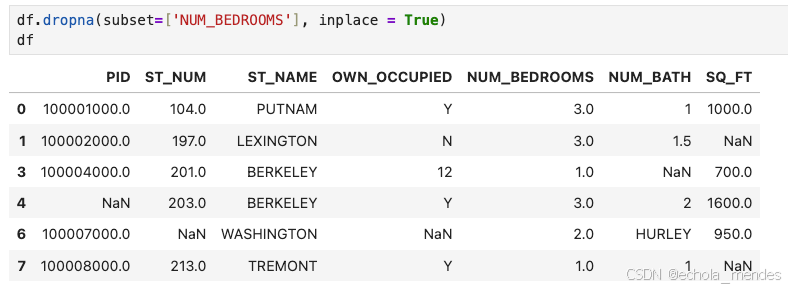
替换空值
可以使用 fillna() 方法来替换一些空字段,用某一个数,或者列的均值、中位数或者众数替换空值
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数
x = df["ST_NUM"].mean()
df["ST_NUM"] = df["ST_NUM"].fillna(x)
df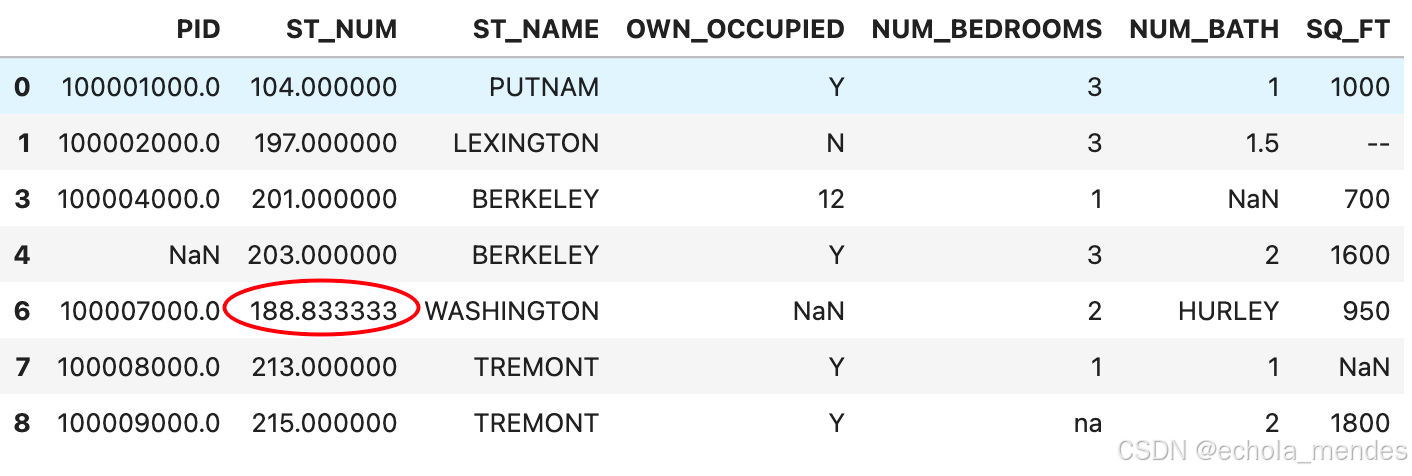
清洗错误格式
数据格式错误的单元格会使数据分析变得困难,甚至不可能,可以将列中的所有单元格转换为相同格式的数据
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data,index=["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'],format="mixed")
df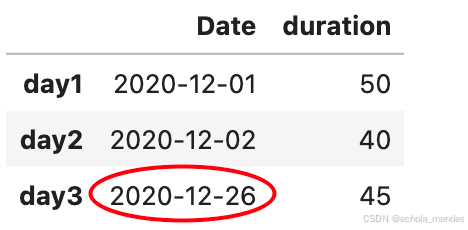
⚠️注意:此处必须指定format,否则会报错,原因是pandas 2.3.1 在 无显式 format 参数 时,内部会先尝试“推断”一个统一格式;由于前两行是 %Y/%m/%d,第三行是 %Y%m%d,推断失败,于是抛出:time data "20201226" doesn't match format "%Y/%m/%d"
如果所有日期格式统一,就不需要指定format
解决思路:告诉 pandas 不要强行用一个统一格式,而是逐条推断即可,也就是
df['Date'] = pd.to_datetime(df['Date'], format='mixed')或者
df['Date'] = pd.to_datetime(df['Date'], errors='coerce') # 先转成 NaT,再检查清除错误数据
对错误的数据进行替换或移除,就需要使用loc()和iloc(),可以来选择特定的行和列、切片操作、布尔索引、赋值操作
| 语法 | 依据什么取行/列 | 是否包含右端点 | 切片可否用布尔数组 |
|---|---|---|---|
.loc[...] |
标签(index/columns 的名字) | 包含 | 可以 |
.iloc[...] |
位置(第 0、1、2… 号) | 不包含 | 可以 |
简单用法:
# 选择单行单列
df.loc['Alice', 'Age'] # 输出: 25
# 选择从 'Alice' 到 'Bob' 的行(包含两端)
df.loc['Alice':'Bob', :]
# 选择第一行第二列(索引从0开始)
df.iloc[0, 1] # 输出: 25
# 选择前两行所有列
df.iloc[:2, :]补充一下Python中的切片用法:
切片(slice)
语法:start : stop : step
作用:从序列里按“左闭右开”区间取子序列。
例子:s = [0,1,2,3,4,5] s[1:4] # [1,2,3] s[::-1] # [5,4,3,2,1,0] 反转
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 350], # 350 年龄数据是错误
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
df.loc[2,'Age'] = 35 # 将第2行(索引2),Age列改为35
df清洗重复数据
如果要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法,如果对应的数据是重复的,就会返回True
persons = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(persons)
df.drop_duplicates(inplace = True)
df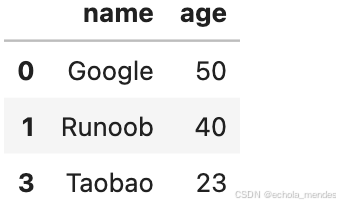
暂时列举这些数据清洗的用法
4.数据排序与聚合
常用方法
| 操作 | 方法 | 说明 | 常用函数/方法 |
|---|---|---|---|
| 排序 | sort_values(by, ascending) |
根据某列的值进行排序,ascending 控制升降序 |
df.sort_values(by='column') |
| 排序 | sort_index(axis) |
根据行或列的索引进行排序 | df.sort_index(axis=0) |
| 分组聚合 | groupby(by) |
按照某列进行分组后,应用聚合函数 | df.groupby('column') |
| 聚合函数 | agg() |
聚合函数,如 sum()、mean()、count() 等 |
df.groupby('column').agg({'value': 'sum'}) |
| 多重聚合 | agg([func1, func2]) |
对同一列应用多个聚合函数 | df.groupby('column').agg({'value': ['mean', 'sum']}) |
| 分组后排序 | apply(lambda x: x.sort_values(...)) |
在分组后进行排序 | df.groupby('column').apply(lambda x: x.sort_values(...)) |
| 透视表 | pivot_table() |
创建透视表,根据行、列进行数据汇总 |
数据排序
sort_values():根据列的值进行排序。sort_index():根据行或列的索引进行排序
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [45, 60, 35, 40],
'Salary': [50000, 60000, 70000, 80000]}
df = pd.DataFrame(data)
# 按照 "Age" 列的值进行降序排序
df_sorted = df.sort_values(by = 'Age',ascending = False)
df_sorted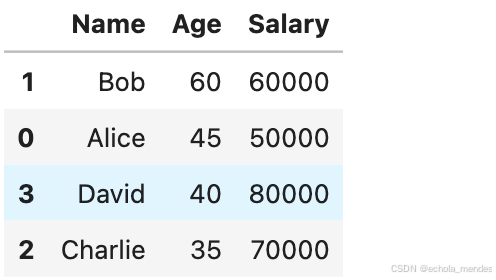
# 按照行索引进行排序 axis=0 按行/axis=1 按列
df_sorted_by_index = df.sort_index(axis=0)
df_sorted_by_index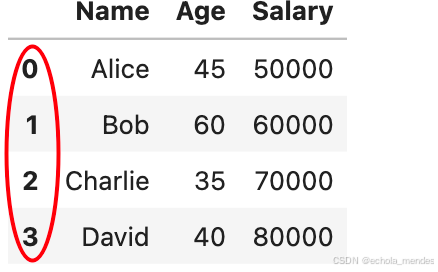
df_sorted_by_index = df.sort_index(axis=1)
df_sorted_by_index![]()
数据聚合
聚合是将数据按某些规则进行汇总,通常是对某些列的数据进行求和、求平均数、求最大值、求最小值等操作。Pandas 提供了groupby()方法来对数据进行分组,然后应用不同的聚合函数
groupby():按某些列分组。- 聚合函数:如
sum(),mean(),count(),min(),max(),std()等
data = {'Department': ['HR', 'Finance', 'HR', 'IT', 'IT'],
'Employee': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Salary': [50000, 60000, 55000, 70000, 75000]}
df = pd.DataFrame(data)
# 按照部门分组,并计算每个部门的平均薪资
grouped = df.groupby('Department')['Salary'].mean()
grouped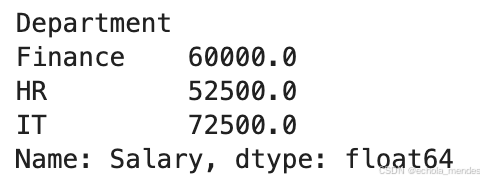
多重聚合函数应用:
# 按照部门分组,并计算每个部门的薪资的平均值和总和
grouped_multiple = df.groupby('Department').agg({'Salary': ['mean', 'sum']})
grouped_multiple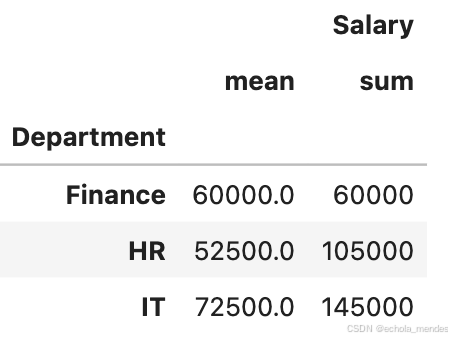
分组排序
聚合后的数据可以进一步按某列的值进行排序,这样可以找出特定组中最重要的值
# 按照部门分组后,按薪资降序排序
grouped_sorted = (
df.groupby('Department')
.apply(lambda x: x.sort_values('Salary', ascending=False),
include_groups=False)
)
grouped_sorted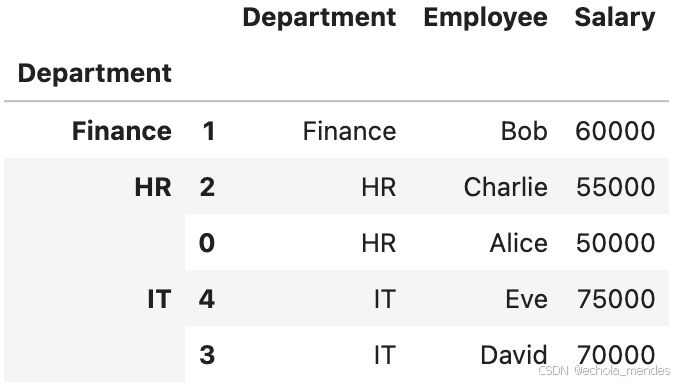
5.数据合并
常用方法
| 操作 | 方法 | 说明 | 常用函数/方法 |
|---|---|---|---|
| 纵向追加 | concat([objs], axis=0) | 把多张表按行“摞”在一起,列自动对齐 | pd.concat([df1, df2], ignore_index=True) |
| 横向拼接 | concat([objs], axis=1) | 把多张表按列并排拼接,索引自动对齐 | pd.concat([df1, df2], axis=1) |
| 键值连接 | merge(left, right, on, how) | 类似 SQL 的 JOIN,按指定列或索引对齐 | pd.merge(df1, df2, on=‘key’, how=‘inner’) |
| 索引连接 | join(other, how) | 快捷的索引对齐连接,默认左连接 | df1.join(df2, how=‘left’) |
| 分组后合并 | groupby + agg + merge | 先分组聚合,再把结果与原表合并 | df.merge(df.groupby(‘key’).agg({‘val’:‘sum’}), on=‘key’) |
| 去重合并 | drop_duplicates + concat | 纵向追加后去重,避免重复行 | pd.concat([df1, df2]).drop_duplicates() |
| 索引重置 | reset_index(drop=True) | 合并后重置索引,避免重复索引 | pd.concat([df1, df2]).reset_index(drop=True) |
在 pandas 里,“合并”可以指几种不同的操作:
- 纵向追加(append / concat)
- 横向对齐(merge / join)
- 按索引对齐(join)
- 按列名对齐(concat axis=1)
import pandas as pd
# 准备 3 张示例表
df1 = pd.DataFrame({'id': [1, 2], 'val': ['A', 'B']})
df2 = pd.DataFrame({'id': [3, 4], 'val': ['C', 'D']})
df3 = pd.DataFrame({'id': [1, 3], 'score': [90, 85]})
纵向追加
out1 = pd.concat([df1, df2], ignore_index=True)
out1
横向追加
left = pd.DataFrame({'A': [1, 2]}, index=['x', 'y'])
right = pd.DataFrame({'B': [3, 4]}, index=['x', 'y'])
out2 = pd.concat([left, right], axis=1)
out2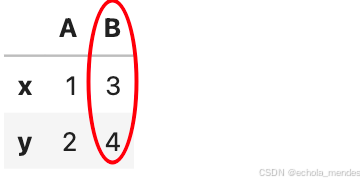
键值合并
out3 = pd.merge(df1, df3, on='id', how='inner')
out3how='inner' 表示取交集,因此 id = 3 这一行在结果里被过滤掉

索引连接
out4 = left.join(right, how='left')
out4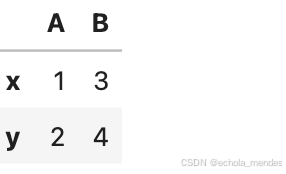
分组合并
agg = df3.groupby('id')['score'].sum().reset_index()
out5 = pd.merge(df1, agg, on='id', how='left')
out5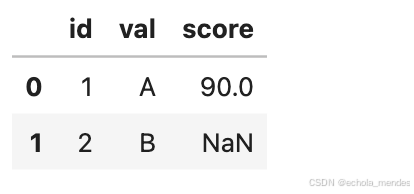
去重合并
out6 = pd.concat([df1, df1]).drop_duplicates().reset_index(drop=True)
out6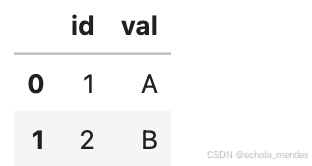
6.数据可视化
数据可视化是数据分析中的重要环节,它帮助我们更好地理解和解释数据的模式、趋势和关系。
通过图形、图表等形式,数据可视化将复杂的数字和统计信息转化为易于理解的图像,从而便于做出决策。
Pandas 提供了与 Matplotlib 和Seaborn等可视化库的集成,使得数据的可视化变得简单而高效。
在 Pandas 中,数据可视化功能主要通过DataFrame.plot() 和 Series.plot() 方法实现,这些方法实际上是对 Matplotlib 库的封装,简化了图表的绘制过程
常用方法
| 图表类型 | 描述 | 方法 |
|---|---|---|
| 折线图 | 展示数据随时间或其他连续变量的变化趋势 | df.plot(kind='line') |
| 柱状图 | 比较不同类别的数据 | df.plot(kind='bar') |
| 水平柱状图 | 比较不同类别的数据,但柱子水平排列 | df.plot(kind='barh') |
| 直方图 | 显示数据的分布 | df.plot(kind='hist') |
| 散点图 | 展示两个数值型变量之间的关系 | df.plot(kind='scatter', x='col1', y='col2') |
| 箱线图 | 显示数据分布,包括中位数、四分位数等 | df.plot(kind='box') |
| 密度图 | 展示数据的密度分布 | df.plot(kind='kde') |
| 饼图 | 显示不同部分在整体中的占比 | df.plot(kind='pie') |
| 区域图 | 展示数据的累计数值 | df.plot(kind='area') |
安装Matplotlib
pip install matplotlib折线图
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
data = {'Year': [2020, 2021, 2022, 2023, 2024, 2025],
'Sales': [150, 100, 180, 250, 500, 350]}
df = pd.DataFrame(data)
# 指定本地文件中的中文字体以防中文乱码
my_font = FontProperties(fname="./font/simsun.ttc", size=14)
# 绘制折线图
ax= df.plot(kind='line', x='Year', y='Sales', xlabel='Year', ylabel='Sales', figsize=(10, 6))
ax.set_title('历年销售数量',fontproperties = my_font)
plt.show()⚠️注意:plot的其他属性使用中文,也需要手动设置fontproperties属性
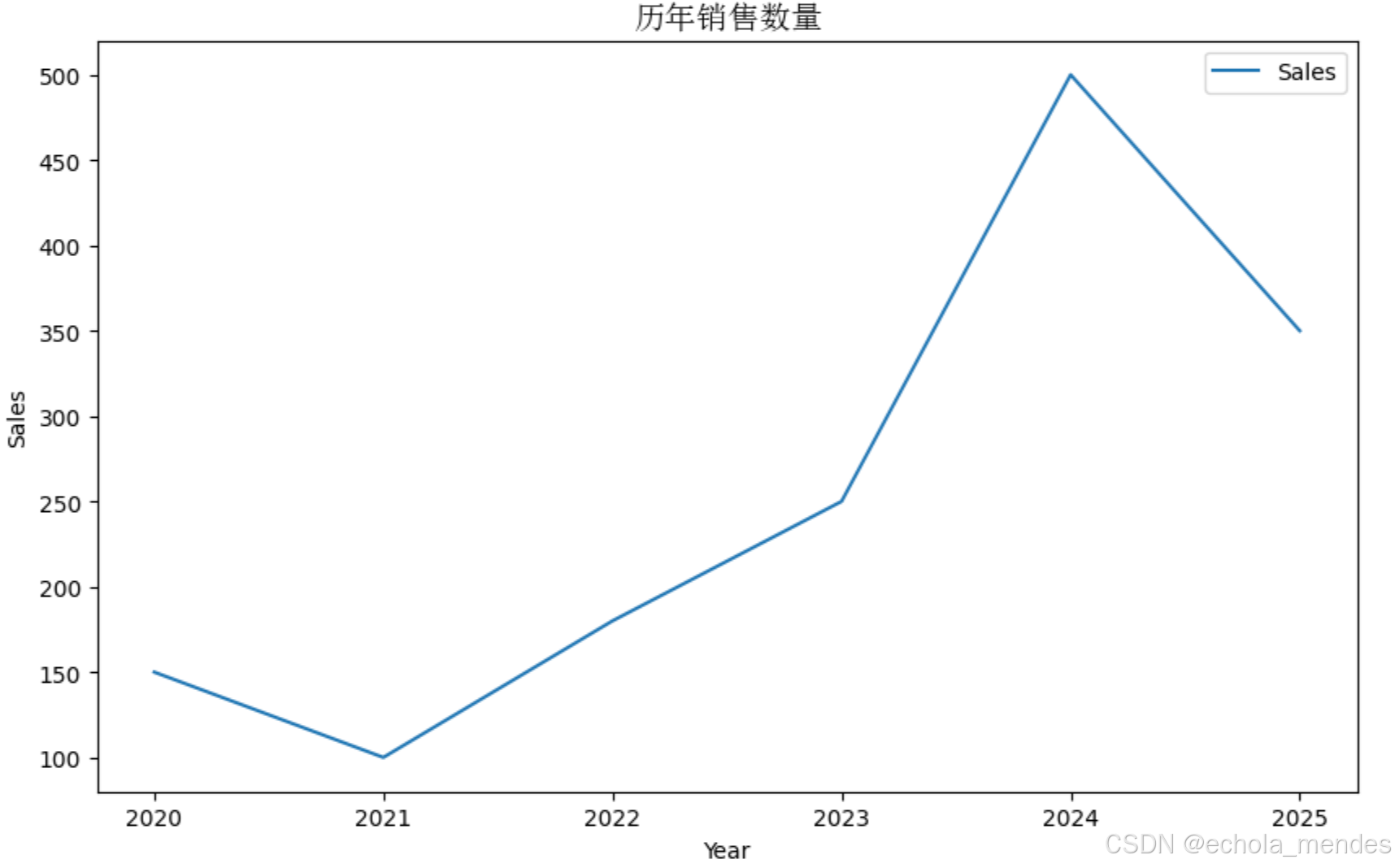 柱状图
柱状图
# 绘制折线图
ax= df.plot(kind='bar', x='Year', y='Sales', xlabel='Year', ylabel='Sales', figsize=(10, 6))
ax.set_title('历年销售数量',fontproperties = my_font)
plt.show()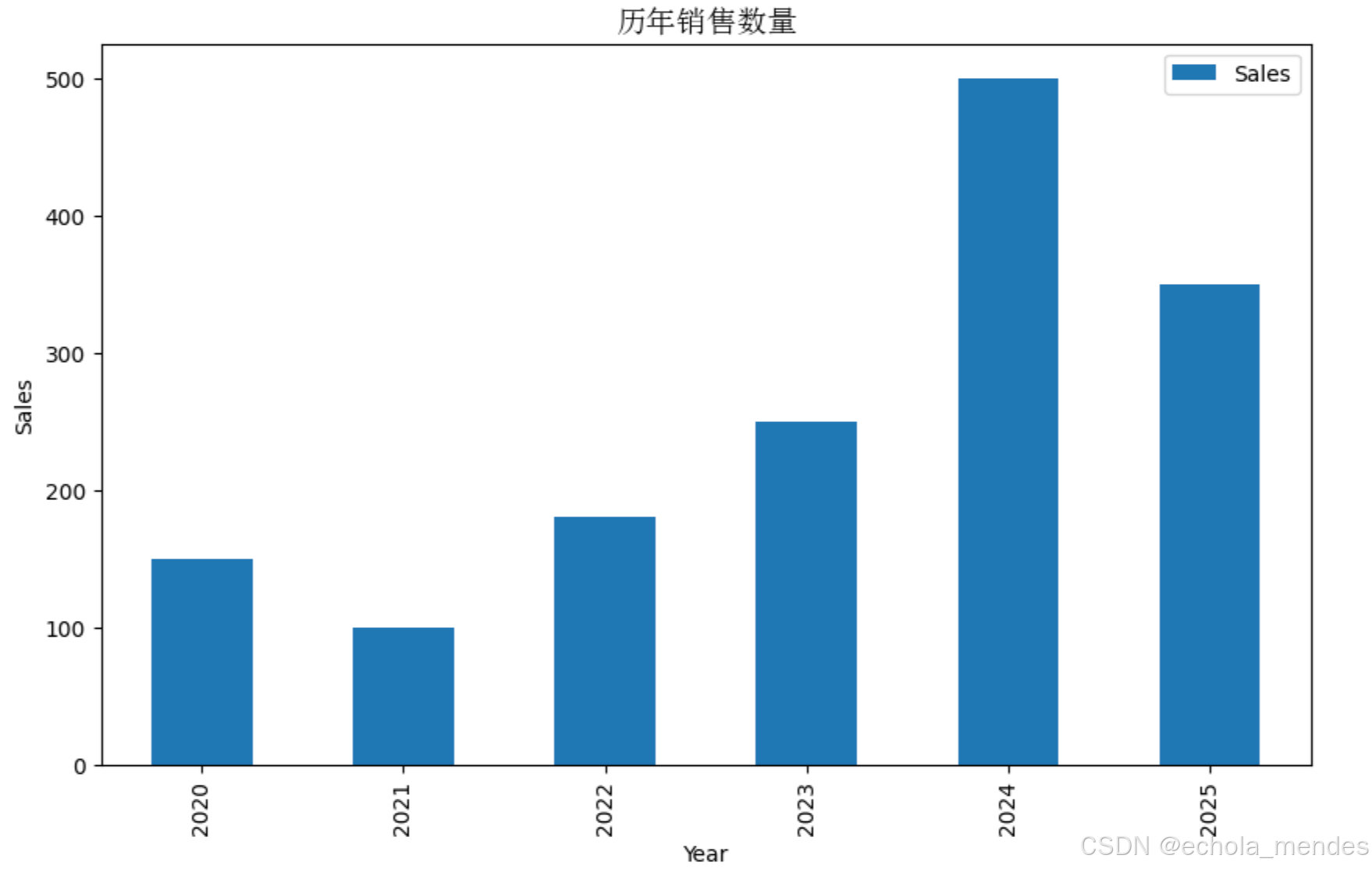
饼图
# 绘制饼图
ax= df.plot(kind='pie', y='Sales', labels=df['Year'], autopct='%1.1f%%', figsize=(10, 6))
ax.set_title('历年销售数量',fontproperties = my_font)
plt.show()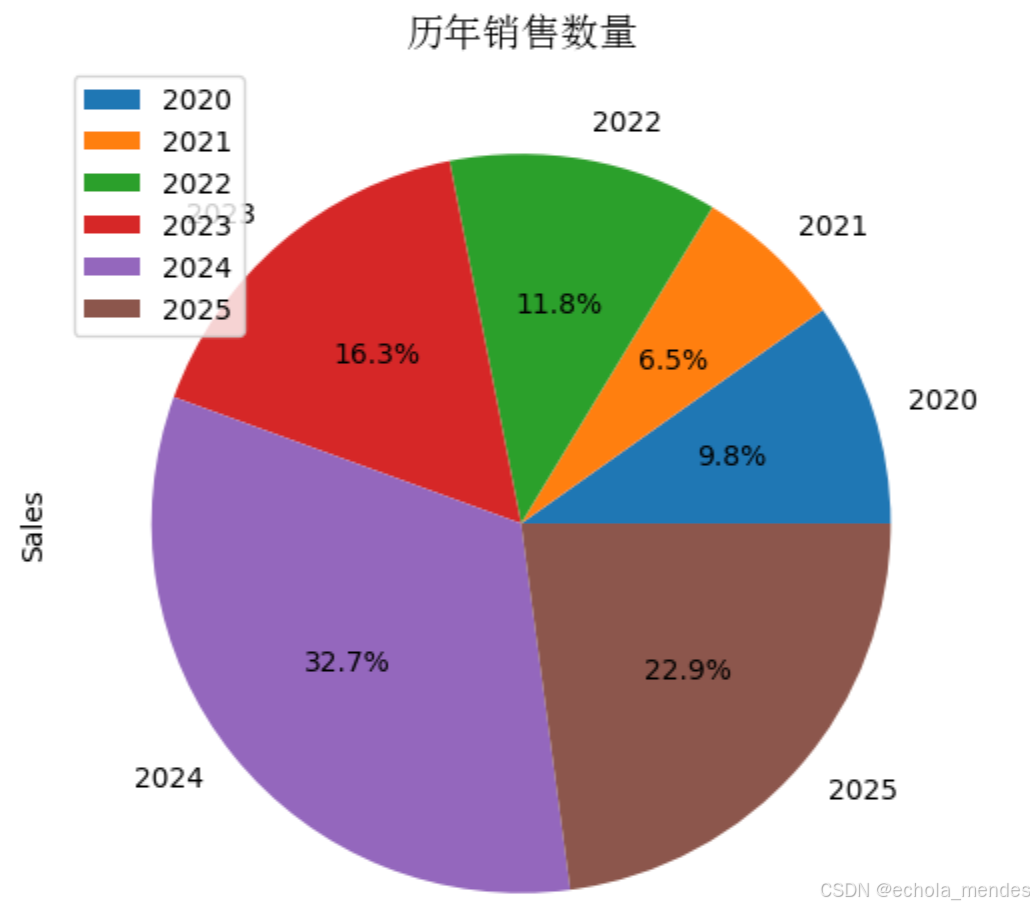
直方图
直方图用于显示数据的分布,特别是用于描述数据的频率分布
# 画直方图
df.plot(kind='hist', y='Sales', bins=6, edgecolor='black',
xlabel='Sales', ylabel='Frequency',
title='Sales Histogram (2020-2025)', figsize=(10, 6))
plt.show()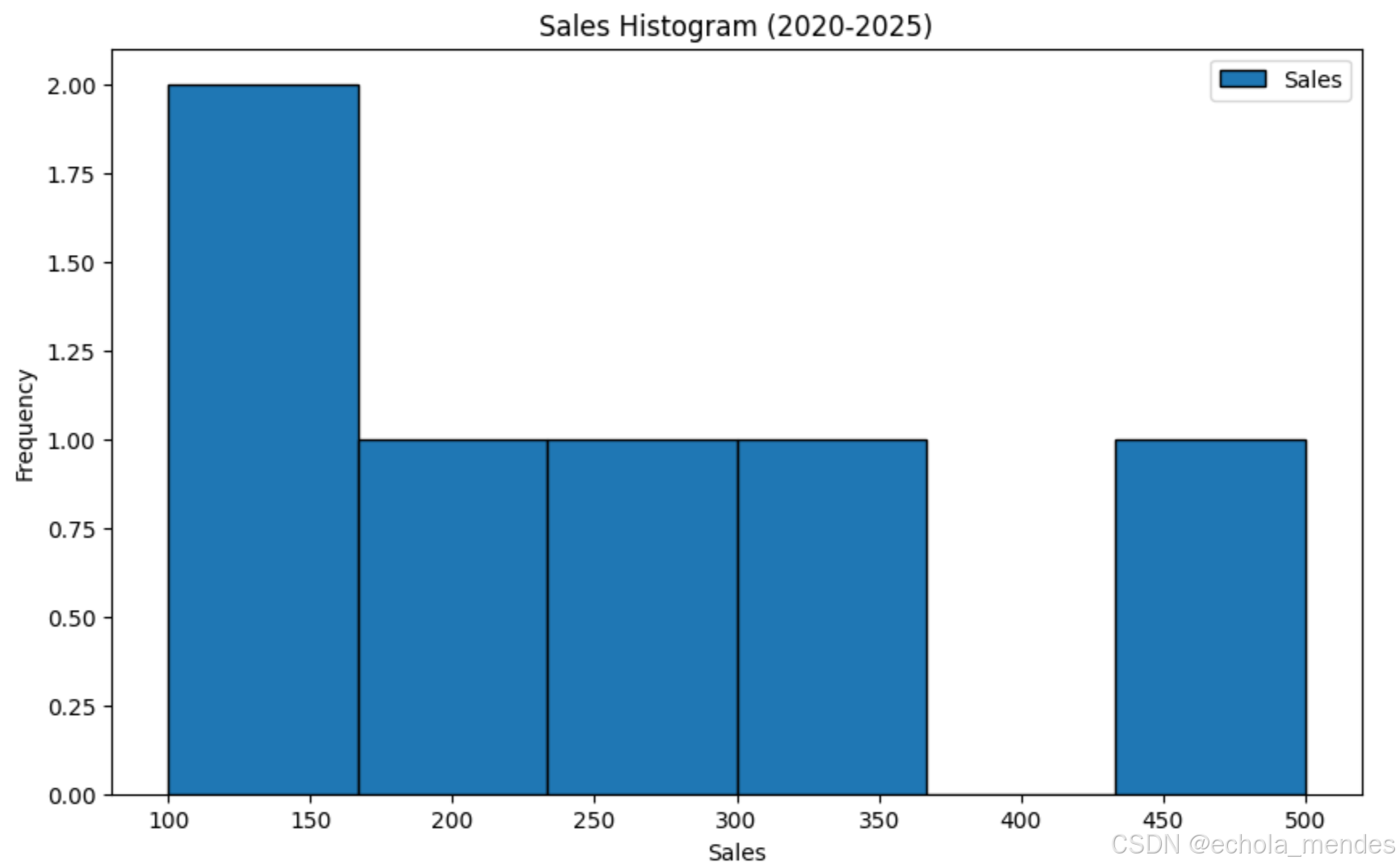
箱线图
箱线图用于展示数据的分布情况,包括中位数、四分位数以及异常值
df.plot(kind='box', y='Sales', figsize=(6, 6),
title='Sales Boxplot (2020-2025)')
plt.show()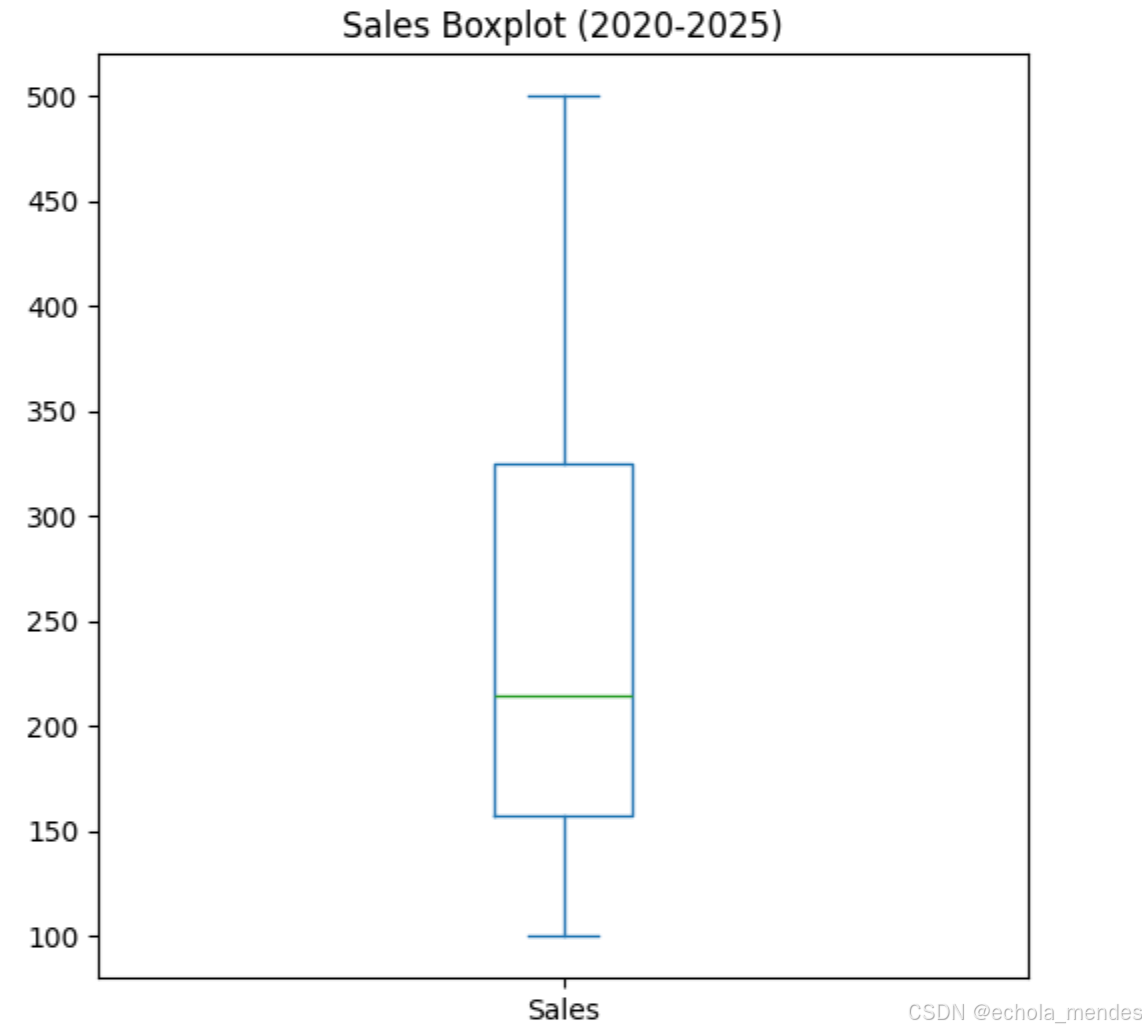
Matplotlib 高级自定义
除了使用 Pandas 提供的 plot() 方法外,Matplotlib 还可以提供更灵活的自定义功能,例如添加标题、标签、设置图表风格、调整坐标轴等
ax= df.plot(kind='line', x='Year', y='Sales', xlabel='Year', ylabel='Sales', figsize=(10, 6), marker='o')
ax.set_title('历年销售数量',fontproperties = my_font)
plt.grid(True)
plt.show()可以看到添加了 marker='o' ,折线图的每个数据点上会显示一个小圆点,便于直观看到每个年份对应的销量。
plt.grid(True) ,坐标系里会出现横纵网格线,方便读数
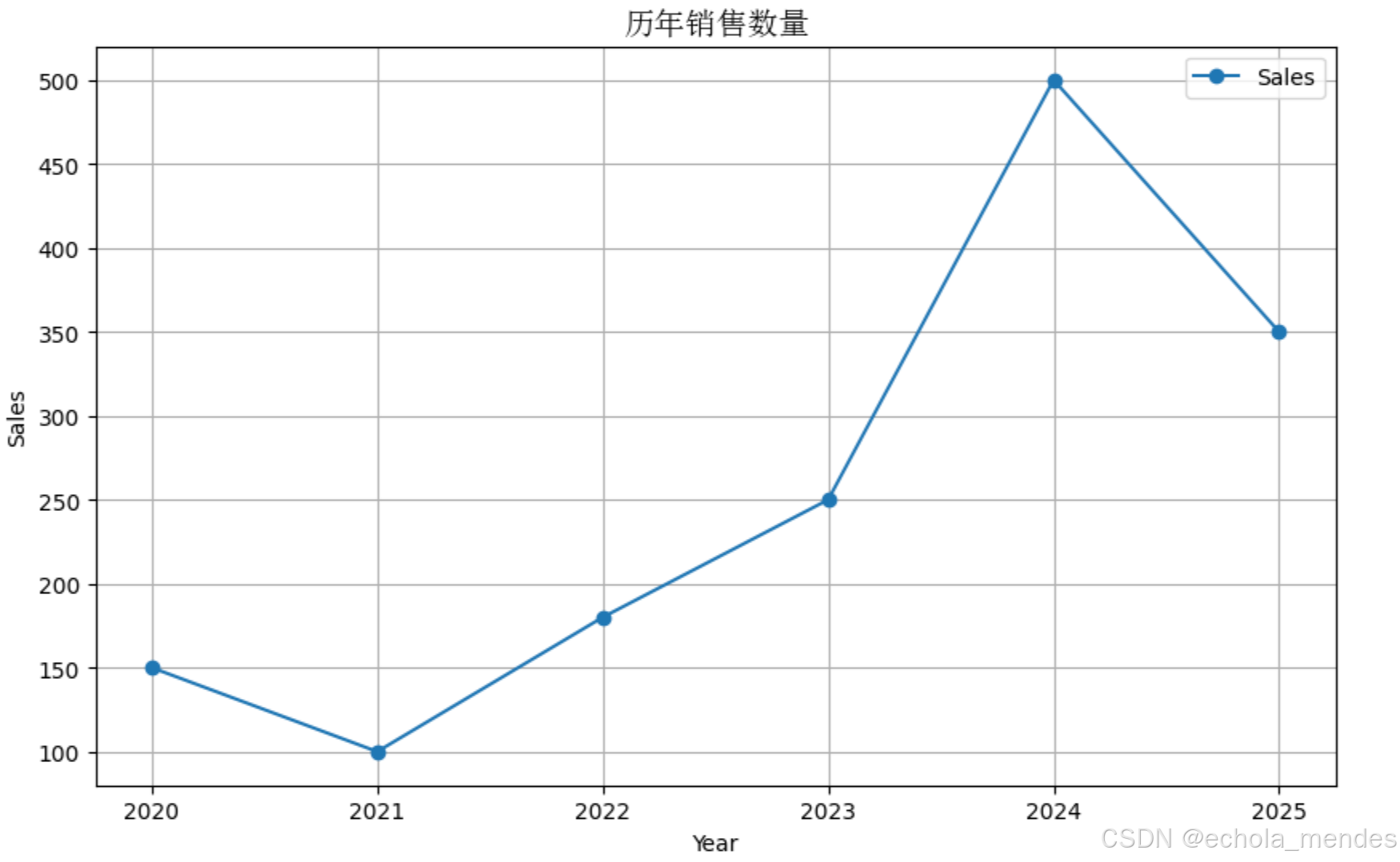
7.高级功能
时间序列化
Pandas 提供了强大的时间序列处理功能,包括日期解析、频率转换、日期范围生成、时间窗口操作等
import pandas as pd
# 生成时间序列
date_range = pd.date_range(start='2025-08-17', periods=5, freq='D')
date_range
#日期偏移
date = pd.to_datetime('2025-08-17')
new_date = date + pd.Timedelta(days=10)
new_date![]()
#滚动窗口,计算滚动平均值
df = pd.DataFrame({'Value': [10, 20, 30, 40, 50]})
# 计算 3 天滚动平均
df['Rolling_Mean'] = df['Value'].rolling(window=3).mean()
df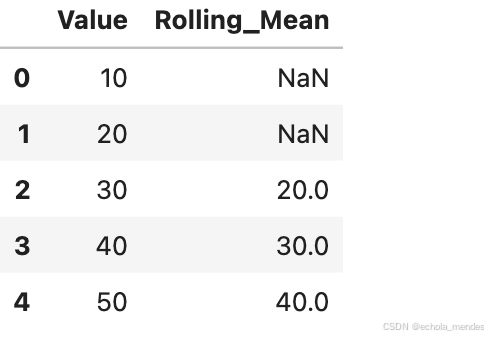
透视交叉
Pandas 提供了 pivot_table() 方法来创建透视表,和 crosstab() 方法来计算交叉表。透视表和交叉表都非常适合数据的汇总和重新排列
data = {'Date': ['2025-08-01', '2025-08-02', '2025-08-03', '2025-08-04'],
'Category': ['A', 'B', 'A', 'B'],
'Sales': [100, 150, 200, 250]}
df = pd.DataFrame(data)
# 创建透视表
pivot_table = pd.pivot_table(df, values='Sales', index='Date', columns='Category', aggfunc='sum', fill_value=0)
pivot_table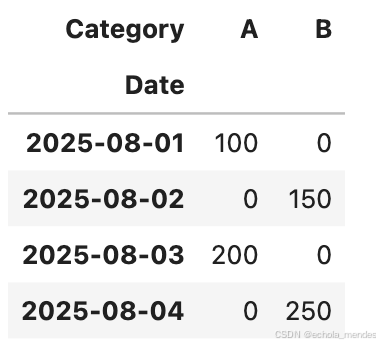
交叉表
# 示例数据
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Region': ['North', 'South', 'North', 'South', 'West', 'East']}
df = pd.DataFrame(data)
# 创建交叉表
cross_table = pd.crosstab(df['Category'], df['Region'])
cross_table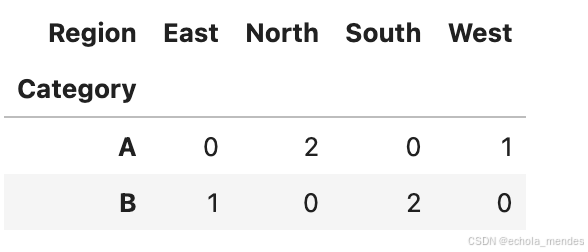
自定义函数
Pandas 提供了多种方法应用自定义函数,用于数据清洗和转换
apply() — 应用函数到 DataFrame 或 Series 上
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [10, 20, 30, 40]})
# 定义自定义函数
def custom_func(x):
return x * 2
# 在列上应用函数
df['A'] = df['A'].apply(custom_func)
df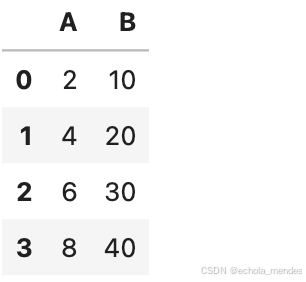
map() — 应用函数到 Series 上, 可以对 Series 中的每个元素应用一个函数或一个映射关系。
# 示例数据
df = pd.DataFrame({'A': ['cat', 'dog', 'rabbit']})
# 使用字典进行映射
df['A'] = df['A'].map({'cat': 'kitten', 'dog': 'puppy'})
df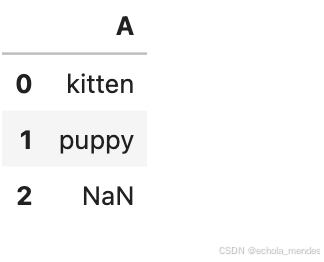
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 在 DataFrame 上应用自定义函数
df = df.map(lambda x: x ** 2)
df可以看到所有值均被平方,说明作用于整个DataFrame的每个元素,而非 Series。虽然语法类似 Series 的 map(),但行为有本质区别:Series 的 map() 通常用于元素级转换或映射字典/Series,而 DataFrame 的 map() 是纯粹的逐元素操作
DataFrame 的 map 方法已弃用(Deprecated),实际会调用 applymap 方法。
可以使用apply()进行替代
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 对每列应用平方函数(沿列方向)
df = df.apply(lambda x: x ** 2)
df四、总结
Pandas 是一个功能强大的 Python 库,专为数据分析和操作而设计。其核心数据结构包括 Series(一维数据)和 DataFrame(二维表格数据),支持从多种文件格式(如 CSV、Excel、SQL 等)读取和写入数据。Pandas 提供了丰富的数据处理功能,包括数据清洗、转换、分析和可视化,广泛应用于金融、学术和统计等领域。
学习建议
- 掌握基础数据结构(Series 和 DataFrame)的创建和操作。
- 熟悉常用数据清洗和分析方法。
- 结合实际项目练习,提升数据处理能力。
Pandas 是数据科学领域的核心工具之一,熟练掌握其功能将显著提升数据分析和处理的效率

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)