【机器学习&深度学习】OpenCompass 如何选择合适的开源数据集 & 自定义数据集
▲如果关注 数学 → GSM8K + MATH;▲如果关注 考试/知识 → MMLU、C-Eval、CMMLU;▲如果关注 常识与事实性 → ARC、Winogrande、TruthfulQA;▲如果关注 对话与指令 → MT-Bench、AlpacaEval;▲如果只想快速跑通 → demo 数据集;合理搭配数据集,才能全面、客观地评估你的模型。
目录

前言
在大模型的评测过程中,数据集的选择比分数更重要。同一个模型在不同任务上可能表现完全不同,因此,合理地挑选数据集,才能全面了解模型的能力。作为一个支持多模型、多任务评测的平台,OpenCompass 已经集成了大量开源数据集。但面对众多的选项,如何选择最合适的呢?本文将给出一个清晰的思路。
一、为什么数据集选择很重要?
模型评测的目标通常分为两类:
通用能力评测:例如数学计算、逻辑推理、常识问答、阅读理解等,适用于衡量模型的整体水平。
专项能力评测:例如法律问答、医疗咨询、代码生成等,往往用于特定领域的应用落地。
因此,数据集选择的核心就是 “评什么 → 选什么”。
二、OpenCompass 中的开源数据集类型
在 OpenCompass 的配置目录中(configs/datasets/),我们可以看到大量任务配置。大体上,这些数据集可以分为以下几类:
1.数学推理类
GSM8K:小学到初中水平的数学文字题,最经典 benchmark
MATH:更高难度,涵盖高中、大学数学
AQuA-RAT、SVAMP:偏向数值推理和应用题
2.知识与考试类
MMLU:57 门学科的多任务理解测试
CMMLU:中文版本的 MMLU
C-Eval:中文考试题,从初中到大学
AGIEval:中国高考、考研和职业资格考试题
3.常识与推理类
ARC (Easy/Challenge):科学常识推理
Winogrande:代词消解,测试常识理解
BoolQ:是/否问答理解
PIQA:物理常识推理
RACE:中英文阅读理解考试题目。
NaturalQuestions (NQ):Google 提供的真实问答数据。
4.事实性与忠实性
TruthfulQA:检测模型是否胡编乱造
HaluEval:中文幻觉检测
CNN/DailyMail、XSum:摘要数据,可测试信息完整性
5.对话与指令跟随类
MT-Bench:多维度评测聊天模型的对话能力
AlpacaEval:指令跟随能力评测
Chatbot Arena 数据(需单独获取)
6.多语言与跨语言类
WMT:翻译任务(英中、英德、英法等)
FLORES-200:200 种语言的翻译 benchmark
XCOPA:跨语言因果推理
7.专项能力
HumanEval:代码生成与正确率。
MBPP:编程题目。
MMLU:多学科知识问答(法律、医学、历史等)。
三、不同场景下的数据集选择策略
既然可选项这么多,那么不同的评测目标,应该选择哪些数据集呢?
1.想测试数学能力?
必备:
gsm8k(小学/初中水平)进阶:
math(高中/大学水平)如果模型能在 MATH 上有好成绩,说明数学推理能力很强。
2.想测试知识覆盖和考试能力?
英文:
mmlu(学科全面,覆盖面最广)中文:
ceval+cmmlu(专门针对中文考试场景)想更贴近中国语境:再加上
agieval
3.想测常识推理?
arc(科学常识)
winogrande(日常常识 + 代词消解)
piqa(物理常识)
4.担心模型胡编乱造(幻觉问题)?
英文:
truthfulqa中文:
halueval
5.关注对话与指令跟随?
mtbench(对话能力全方位测评)
alpacaeval(指令跟随测试)
6.跨语言任务?
翻译:
wmt、flores-200推理:
xcopa
小技巧:
-
如果目标是“通用模型评测”,可以选 GSM8K + MMLU + HumanEval,覆盖数学、知识、代码。
-
如果目标是“行业模型评测”,则要选择与领域更贴近的专项数据。
四、常见的“黄金组合”
在实际研究和工程项目中,通常不会只跑一个数据集,而是跑一个组合来全面评测模型。常见的组合有:
数学推理能力:
gsm8k+math知识考试能力:
mmlu+ceval+cmmlu常识推理能力:
arc+winogrande事实性与幻觉:
truthfulqa+halueval对话与指令跟随:
mtbench+alpacaeval
如果你只想做一个快速但相对全面的 benchmark(基准测试),推荐用:
👉 gsm8k + mmlu + truthfulqa + mtbench
这样能同时覆盖数学、知识、事实性和对话四大方面。
五、demo 数据集与真实数据集的区别
需要特别提醒的是,OpenCompass 里还提供了 demo/ 目录,比如:
demo_gsm8k_chat_gen
demo_math_chat_gen
这些只是几条小样例,主要用来验证环境配置,不能作为真实评测结果。真正的测试,一定要用正式数据集配置文件。
六、OpenCompass 自定义数据集
6.1 查看官方文档
官方文档查看地址:自定义数据集 — OpenCompass 0.4.2 文档

6.2 下载模型
#模型下载
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B', cache_dir='/root/A_mymodel/model')
print("模型已下载至:", model_dir)
【替换片段】
▲deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B:存放模型的文件夹路径;
▲/root/A_mymodel/model:模型所在总文件夹;
6.3 问答格式
格式1:.jsonl格式(推荐)
{"question": "752+361+181+933+235+986=", "answer": "3448"}
{"question": "712+165+223+711=", "answer": "1811"}
{"question": "921+975+888+539=", "answer": "3323"}
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}格式2:.csv 格式
question,answer
123+147+874+850+915+163+291+604=,3967
149+646+241+898+822+386=,3142
332+424+582+962+735+798+653+214=,4700
649+215+412+495+220+738+989+452=,41706.4 定义数据集配置
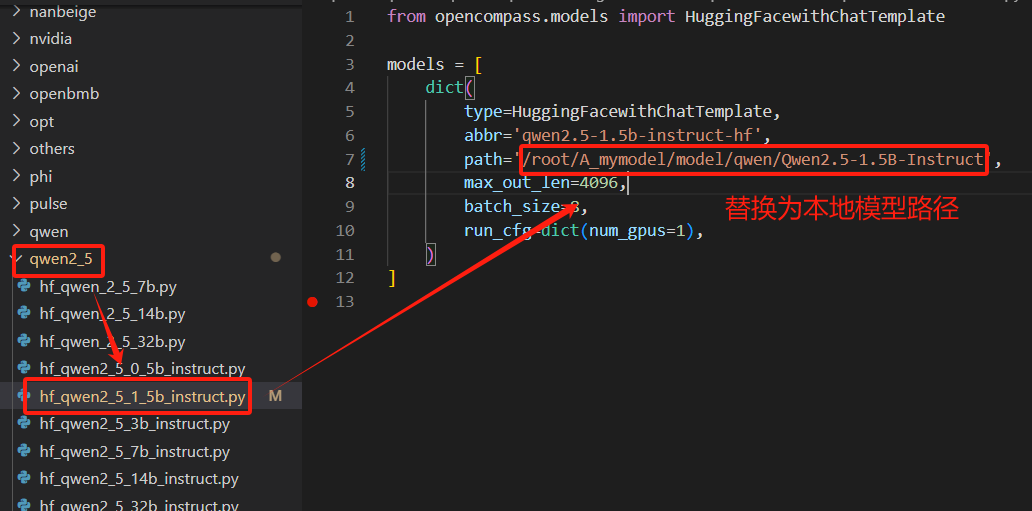
在 模型配置文件路径:~./opencompass/opencompass/configs/models/替换模型路径path:
【配置流程】
▲1、找到模型配置文件路径
~/opencompass/opencompass/configs/models/qwen2_5/hf_qwen2_5_1_5b_instruct.py;
红色区域路径为OpenCompass内置模型配置文件;
绿色区域路径根据下载的本地模型选择对应的配置文件,也可以任意选择一个hf格式的配置文件;
▲2、替换模型配置路径
#
6.4 运行评测
执行命令
命令格式会有点变化
jsonl格式(推荐)
python run.py \
--models hf_qwen2_5_1_5b_instruct \
--custom-dataset-path xxx/test_qa.jsonl \
--custom-dataset-data-type qa \
--custom-dataset-infer-method gen【命令说明】
▲models:指定要使用的模型
○hf_qwen2_5_1_5b_instruct:表示使用本地 HuggingFace 格式的 hf_qwen2_5_1_5b_instruct模型,模型配置文件路径:~./opencompass/opencompass/configs/models/;▲custom-dataset-path:指定自定义数据集路径
○xxx/test_qa.jsonl:本地自定义的数据集文件路径,格式为 JSONL;▲custom-dataset-data-type:指定数据类型
○qa:表示这是问答(Question-Answering)类型的数据集;▲custom-dataset-infer-method:指定推理方式
○gen:生成式推理(模型自由生成答案);
csv格式
python run.py \
--models hf_llama2_7b \
--custom-dataset-path xxx/test_mcq.csv \
--custom-dataset-data-type mcq \
--custom-dataset-infer-method ppl
七、总结
在 OpenCompass 中选择数据集,本质上是回答两个问题:
-
你想测模型的哪方面能力?
-
你能否获取到相应的开源/受限数据?
-
如果关注 数学 → GSM8K + MATH
-
如果关注 考试/知识 → MMLU、C-Eval、CMMLU
-
如果关注 常识与事实性 → ARC、Winogrande、TruthfulQA
-
如果关注 对话与指令 → MT-Bench、AlpacaEval
-
如果只想快速跑通 → demo 数据集
合理搭配数据集,才能全面、客观地评估你的模型。
👉 下次你在 OpenCompass 里运行时,不妨先想清楚:我要测的到底是数学?常识?对话?还是事实性? 然后再选择对应的数据集,这样得到的评测结果才真正有意义。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)