【语义分割】【深度学习】Ubuntu22.04下PointTransformerV1官方代码Pytorch实现
【语义分割】【深度学习】Ubuntu22.04下PointTransformerV1官方代码Pytorch实现
前言
PointTransformerV1是由牛津大学的Zhao, Hengshuang等人在《Point Transformer【CVPR-2021】》【论文地址】一文中提出了Point Transformer V1(简称PTv1)的模型,基于自注意力网络实现网络模型的构建。该方法设计了一个表达能力极强的 Point Transformer 层用于点云处理。该层具有置换不变性和基数不变性,适合点云处理。基于 Point Transformer 层构建了高性能的 Point Transformer 网络,可以作为 3D 场景理解的通用骨干网络,用于点云上的分类和密集预测任务。
在详细解析PointTransformerV1网络之前,首要任务是搭建PointTransformerV1【Pytorch-demo地址】所需的运行环境,并完成模型训练和测试工作,展开后续工作才有意义。
《Point Transformer》论文解读
环境搭建
官方推荐配置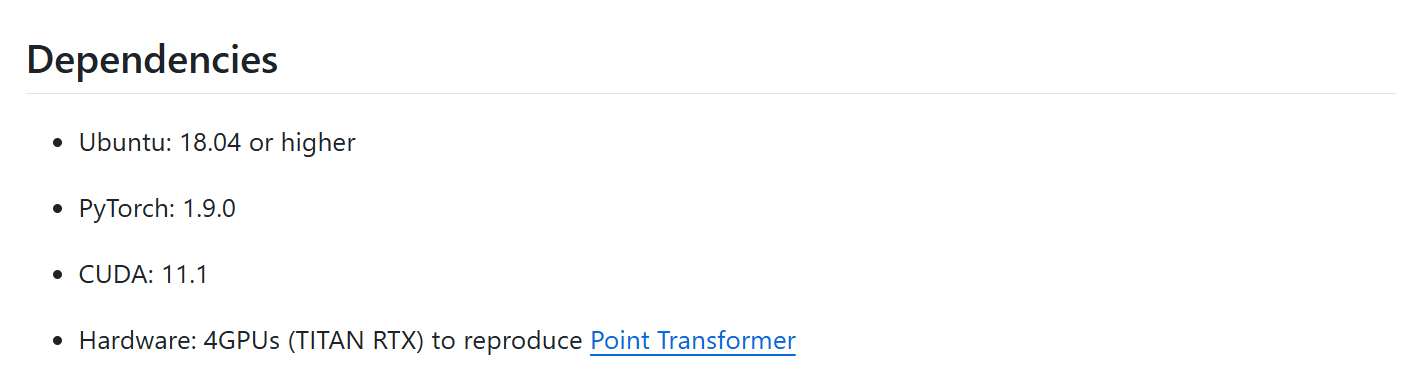
Ubuntu: 18.04 及以上版本;CUDA: 11.1 ;PyTorch: 1.9.0,需要4块TITAN RTX显卡。
博主这里是租的服务器【推荐服务商】
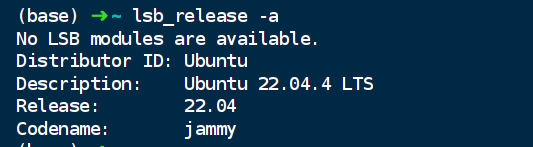
查看 Ubuntu 的版本信息
lsb_release -a
ubuntu环境下深度学习环境搭建
【参考安装anaconda环境】,方便搭建专用于PointTransformerV1模型的虚拟环境。
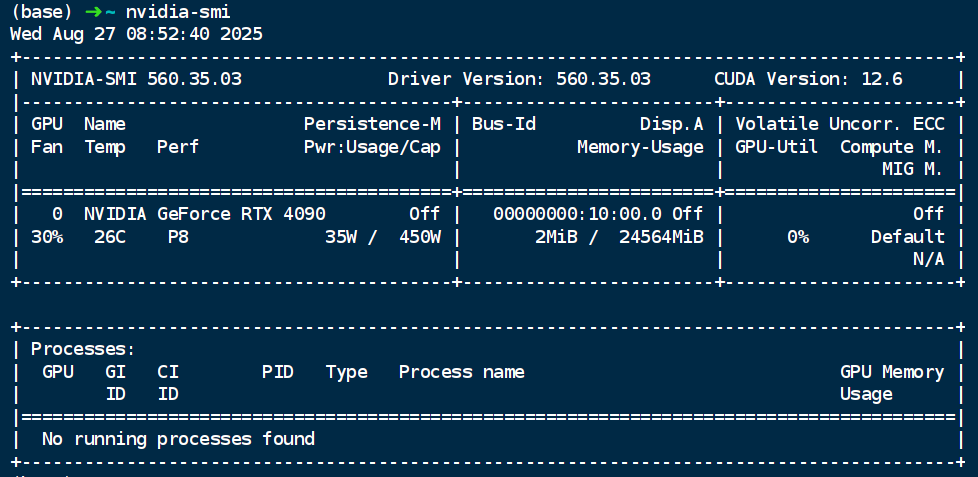
查看主机支持的cuda版本(最高)
# 查看 GPU 基本信息
nvidia-smi
查看主机安装的cuda版本
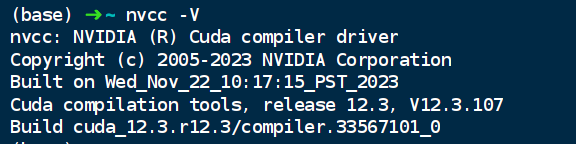
# 检查当前安装的 CUDA 开发环境
nvcc -V
安装GPU版本的torch【官网】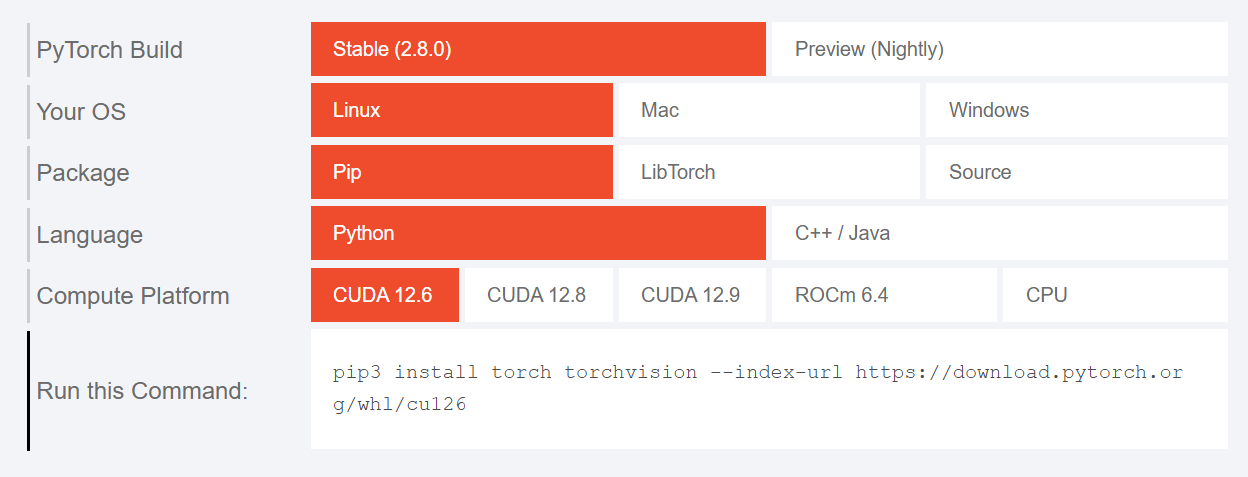
博主的cuda版本是12.1,在其他torch版本中【以前版本】找对应的安装命令。
这里按照的GPU版本的torch必须与主机安装的cuda版本版本一致,否则后续安装pointops包时候会出错。
博主的是 CUDA 12.3,但是PyTorch 官方目前没有发布专门针对 CUDA 12.3 的构建版本。不过 NVIDIA 的 CUDA 向后兼容性设计允许CUDA Toolkit 12.3 可以运行为 12.1 编译的程序。因此,使用 cu121 构建的 PyTorch 在 CUDA 12.3 环境下是完全兼容且推荐的做法。
博主安装环境参考
-
创建conda环境
# 下载githup源代码到合适文件夹,并cd到代码文件夹内(科学上网) git clone https://github.com/POSTECH-CVLab/point-transformer.git # 进入工程目录下 cd point-transformer # 创建虚拟环境 conda create -n PTv1 python=3.10 -y # 博主租用的服务器eg: # conda create --prefix /home/featurize/work/PTv1 python=3.10 -y # 查看新环境是否安装成功 conda env list # 激活环境 conda activate PTv1 # conda activate /home/featurize/work/PTv1 -
安装pytorch相关系列包
# 安装pytorch和torchvision pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121 -
安装环境所需的常规包
pip install h5py pyyaml tensorboardx sharedarray -
安装环境所需的第三方包(需要手动编译安装)
安装pointops包:cd lib/pointops conda activate PTv1 # conda activate /home/featurize/work/PTv1 python setup.py install代码引用了 PyTorch 旧版本(1.10 之前)的 THC 头文件,而新版本 PyTorch(1.10+)已经弃用并移除了 THC 库,改用 ATen 库。
// 旧代码 #include <THC/THC.h> // 新代码(使用 ATen 库) #include <ATen/ATen.h> #include <ATen/cuda/CUDAContext.h>
代码运行
数据集准备
下载 S3DIS 数据集【地址】。S3DIS dataset: 这是一个用于室内场景分割任务的数据集,包含多个房间的点云数据和对应的语义标签。
# 解压下载好的.tar.gz文件(-x:提取文件;-v:显示解压过程;-z:使用gzip解压缩;-f:指定文件名;-C:指定目标目录)
tar -xVzf s3dis.tar.gz -C /path/to/target/directory
# eg: tar -xVzf s3dis.tar.gz -C /home/featurize/work
# 在point-transformer目录下创建数据集存放目录
cd point-transformer
mkdir -p dataset
# 创建符号链接 -s 表示创建的是软链接
# /path_to_s3dis_dataset 需要替换为实际的 S3DIS 数据集所在的绝对路径
# dataset/s3dis: 符号链接的目标位置,即在 dataset 目录下创建一个名为 s3dis 的符号链接,指向 /path_to_s3dis_dataset。
ln -s /path_to_s3dis_dataset dataset/s3dis
# eg: ln -s /home/featurize/work/s3dis dataset/s3dis

模型训练
启动训练
train.sh是用于启动深度学习模型训练实验的自动化脚本。
sh tool/train.sh s3dis pointtransformer_repro
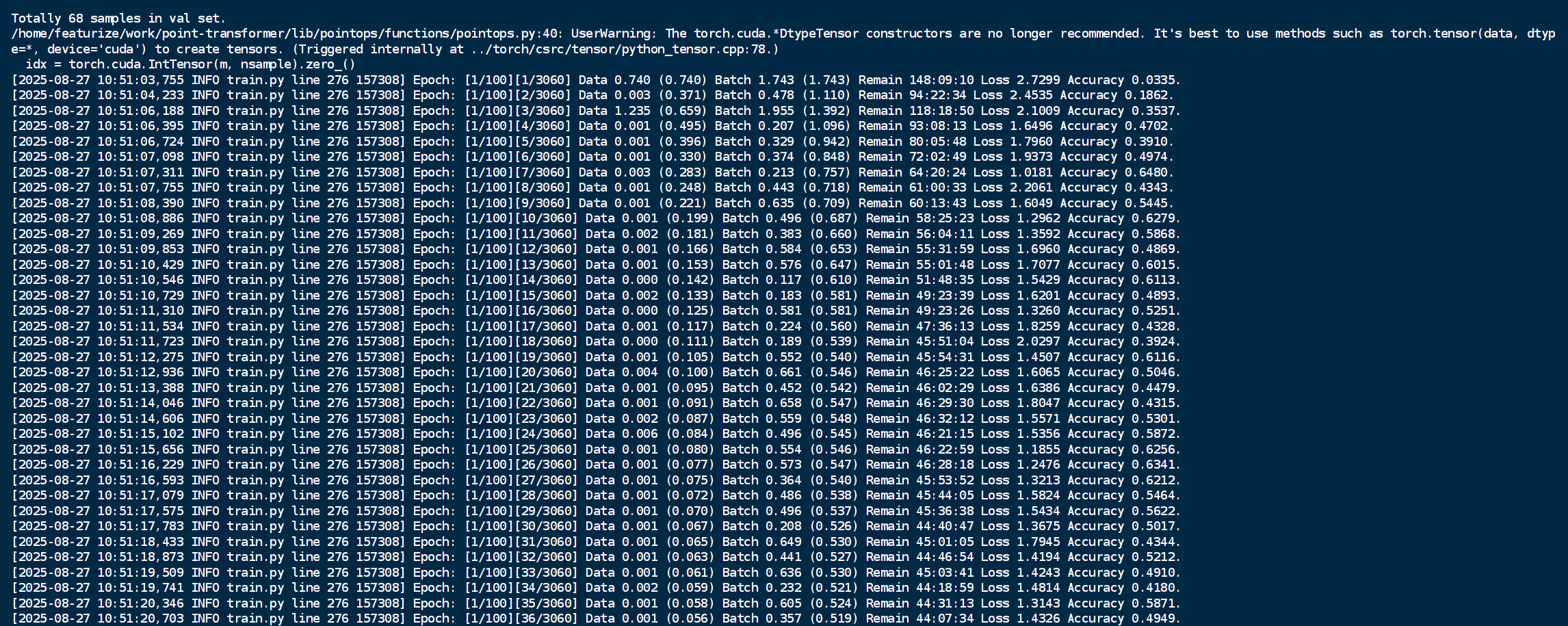
训练脚本train.sh解析
该脚本是一个工程化、可复现的深度学习训练启动器,通过自动配置环境、组织目录、备份代码和记录日志,极大提升了实验管理的效率与可靠性。
#!/bin/sh
# 指定脚本使用的解释器为sh(Bourne shell),确保在类 Unix 系统上正确执行.
# 将当前目录./添加到Python的模块搜索路径(PYTHONPATH)中,使得Python脚本可以导入当前目录下的自定义模块,而无需安装或复制到系统路径.
export PYTHONPATH=./
# 初始化Conda的shell钩子,使当前shell能识别并使用conda命令.
# 在非交互式shell(如脚本)中默认可能无法使用conda activate,需要先运行此命令激活Conda的环境管理功能.
eval "$(conda shell.bash hook)"
# 激活名为PTv1的Conda虚拟环境(这里黑丝博主自定义的,根据个人需求修改)
# 确保后续运行的Python脚本使用的是该环境中安装的Python解释器和依赖包
conda activate PTv1
# 定义一个变量PYTHON,值为python表示使用默认的Python解释器.
# 如果需要指定特定版本(如python3.8或虚拟环境中的路径),可在此处修改.
PYTHON=python
# 定义变量存储训练和测试脚本的文件名.
TRAIN_CODE=train.py
TEST_CODE=test.py
# 从命令行参数中获取第一个和第二个参数,分别赋值给dataset和exp_name.
dataset=$1 # $1:数据集名称(如s3dis,scannet).
exp_name=$2 # $2:实验名称(如pointnet,dgcnn).
# 构建一系列路径变量,用于组织实验文件结构.
exp_dir=exp/${dataset}/${exp_name} # 实验主目录,按“数据集+实验名”分类.
model_dir=${exp_dir}/model # 模型保存目录.
result_dir=${exp_dir}/result # 结果(测试结果,日志)保存目录.
config=config/${dataset}/${dataset}_${exp_name}.yaml # 配置文件(对应实验的YAML配置文件,包含超参数,网络结构等设置)路径.
# 创建所需目录(-p 表示递归创建,若已存在不报错).
mkdir -p ${model_dir} ${result_dir}
mkdir -p ${result_dir}/last
mkdir -p ${result_dir}/best
# 将关键脚本和配置文件复制到实验目录中,便于记录和复现实验.
cp tool/train.sh tool/${TRAIN_CODE} ${config} tool/test.sh tool/${TEST_CODE} ${exp_dir}
# 获取当前时间戳,格式为"年月日_时分秒".
# 用于命名日志文件,避免覆盖,方便追踪训练时间.
now=$(date +"%Y%m%d_%H%M%S")
# 执行训练命令:使用指定的Python解释器运行训练代码,传递配置文件路径和保存路径参数,同时输出到终端和日志文件
$PYTHON ${exp_dir}/${TRAIN_CODE} \
--config=${config} \
save_path ${exp_dir} \
2>&1 | tee ${exp_dir}/train-$now.log
结构示例
exp/
└── dataset/
└── exp_name/
├── model/ # 存放模型
└── result/ # 存放结果
├── last/ # 最新模型保存的输出结果(测试阶段保存)
└── best/ # 最佳模型保存的输出结果(测试阶段保存)
配置文件s3dis_pointtransformer_repro.yaml解析
该配置文件定义了一个使用 PointTransformer 架构在 S3DIS 数据集上进行 3D点云语义分割 任务的完整流程,包括数据预处理、模型训练、分布式设置和测试评估的所有关键参数。
DATA: # 数据配置:定义了与输入数据相关的所有参数
data_name: s3dis # 指定使用的数据集名称
data_root: dataset/s3dis/trainval_fullarea # 数据集在本地所在的根目录路径
test_area: 5 # 指定用于测试的区域编号,该数据集包含6个大型室内区域 Area 1-6,指定 Area 5 作为测试区域
classes: 13 # 数据集中包含的语义类别数量,13个类别:天花板、地板、墙、梁、柱子、窗户、门、桌子、椅子、沙发、书架、板障、杂物
fea_dim: 6 # 每个点的特征维度 6:表示(x, y, z, r, g, b),即三维坐标和 RGB 颜色信息
voxel_size: 0.04 # 体素化下采样的粒度:为了处理大规模点云,算法会先将空间划分为 0.04m x 0.04m x 0.04m 的小体素,然后从每个非空体素中采样一个点(取中心点或平均点),值越小保留的细节越多,但计算量也越大
voxel_max: 80000 # 训练时对每个点云块(patch)进行随机裁剪或采样后的最大点数(重要的内存控制参数):确保无论原始场景多大,输入到网络中的点数都是固定的,从而可以使用固定的批次大小
loop: 30 # 在每个训练周期 epoch 中对训练集进行采样的次数:由于训练时是从大面积场景中随机抽取小块, loop 参数决定了每个 epoch 会看到多少个小块
TRAIN: # 训练配置:定义了模型训练的超参数和设置
arch: pointtransformer_seg_repro # 指定要使用的模型架构:用于分割任务的 Point Transformer 网络的复现版本
use_xyz: True # 是否将点的坐标(x, y, z)作为输入特征的一部分,此参数通常控制是否在网络的某些层中显式地使用相对坐标信息进行计算(虽然fea_dim 已经包含了坐标)
sync_bn: False # 是否使用同步批归一化:在单机多卡训练时通常每个GPU独立计算批统计信息,同步BN会跨所有GPU计算全局的均值和方差,使得统计更准确,但会降低速度并增加通信开销
ignore_label: 255 # 在计算损失函数时会忽略带有此标签的点,常用于处理未标注或无效的点
train_gpu: [0, 1, 2, 3] # 指定用于训练的GPU设备ID:使用4块GPU 0, 1, 2, 3 号卡进行并行训练
workers: 16 # 数据加载器DataLoader使用的子进程数量:更多的数量可以加快数据预读取和预处理的速度,但会占用更多CPU和内存资源
batch_size: 16 # 每个GPU上的训练批次大小
batch_size_val: 4 # 在训练过程中进行验证时,每个GPU上的批次大小:验证通常需要更多的内存,因为要计算指标并可能保存结果,所以这个值会设得比batch_size小
base_lr: 0.5 # 初始学习率
epochs: 100 # 训练的总周期数
start_epoch: 0 # 开始训练的周期序号
step_epoch: 30 # 学习率衰减的步长:每过step_epoch个周期,学习率就会衰减一次
multiplier: 0.1 # 学习率衰减的乘数:每次衰减时,新的学习率 = 当前学习率 * multiplier
momentum: 0.9 # SGD优化器的动量参数
weight_decay: 0.0001 # 优化器的权重衰减系数用于防止过拟合
drop_rate: 0.5 # Dropout 层的丢弃率
manual_seed: 7777 # 随机数生成器的种子:设置固定的种子可以确保实验结果的可复现性
print_freq: 1 # 每隔多少个小批次(iteration)打印一次训练日志,如损失、准确率
save_freq: 1 # 每隔多少个训练周期(epoch)保存一次模型检查点
save_path: # 模型和日志的保存路径:这里为空,可能需要在实际运行时指定
weight: # 预训练权重的路径,用于加载并微调模型:为空表示从头开始训练
resume: # 之前训练中断的检查点路径,用于恢复训练:加载模型权重、优化器状态、学习率调度器状态和当前的epoch序号,为空表示不恢复
evaluate: True # 是否在每个训练阶段在验证集上评估模型性能
eval_freq: 1 # 评估的频率:1表示每个epoch都评估
Distributed: # 分布式配置
dist_url: tcp://localhost:8888 # 用于进程间通信的URL:localhost表示当前机器,8888是端口号
dist_backend: 'nccl' # 分布式后端的通信框架:NVIDIA GPU 通常使用 nccl,其效率最高
multiprocessing_distributed: True # 是否使用分布式训练
world_size: 1 # 进程总数:1表示只有一台机器
rank: 0 # 当前进程的优先级:0表示主进程
TEST: # 测试配置:定义了模型测试推理时的参数
test_list: dataset/s3dis/list/val5.txt # 包含测试文件列表的文本文件路径:即 Area 5 中的一些预处理后的点云块或文件列表
test_list_full: dataset/s3dis/list/val5_full.txt # 包含完整测试区域 Area 5 文件列表的文本文件路径:可能用于最终的全场景测试和指标计算
split: val # [train, val and test] 指定测试使用的数据分割:val表示使用验证集进行测试
test_gpu: [0] # 指定用于测试的 GPU 设备 ID
test_workers: 4 # 测试时数据加载器的子进程数量
batch_size_test: 4
model_path: # 测试模型权重文件路径
save_folder: # 测试结果的保存文件夹
names_path: data/s3dis/s3dis_names.txt # 包含类别名称的文本文件路径:用于使输出结果更可读
这里需要根据自己的运行主机的硬件条件进行修改配置,博主只有一张4090显卡,因此暂时修改以下部分:
train_gpu: [0]
batch_size: 2
batch_size_val: 2
multiprocessing_distributed: False
batch_size_test: 2
继续训练
修改s3dis_pointtransformer_repro.yaml配置文件的以下内容,添加此前已经中途训练产生的权重文件路径用于加载:
resume: point-transformer/exp/s3dis/pointtransformer_repro/model/model_best.pth
sh tool/train.sh s3dis pointtransformer_repro
模型测试
执行测试
test.sh是用于执行深度学习模型测试实验的自动化脚本。
sh tool/test.sh s3dis pointtransformer_repro
测试脚本test.sh解析
#!/bin/sh
# 将当前目录./添加到Python的模块搜索路径(PYTHONPATH)中,使得Python脚本可以导入当前目录下的自定义模块,而无需安装或复制到系统路径.
export PYTHONPATH=./
# 初始化Conda的shell钩子,使当前shell能识别并使用conda命令.
# 在非交互式shell(如脚本)中默认可能无法使用conda activate,需要先运行此命令激活Conda的环境管理功能.
eval "$(conda shell.bash hook)"
# 激活名为PTv1的Conda虚拟环境(这里黑丝博主自定义的,根据个人需求修改)
# 确保后续运行的Python脚本使用的是该环境中安装的Python解释器和依赖包
conda activate PTv1
# 定义一个变量PYTHON,值为python表示使用默认的Python解释器.
# 如果需要指定特定版本(如python3.8或虚拟环境中的路径),可在此处修改.
PYTHON=python
# 定义变量存储测试脚本的文件名.
TEST_CODE=test.py
# 从命令行参数中获取第一个和第二个参数,分别赋值给dataset和exp_name.
dataset=$1 # $1:数据集名称(如s3dis,scannet).
exp_name=$2 # $2:实验名称(如pointnet,dgcnn).
# 构建一系列路径变量,用于组织实验文件结构.
exp_dir=exp/${dataset}/${exp_name} # 实验主目录,按“数据集+实验名”分类.
model_dir=${exp_dir}/model # 模型保存目录.
result_dir=${exp_dir}/result # 结果(测试结果,日志)保存目录.
config=config/${dataset}/${dataset}_${exp_name}.yaml # 配置文件(对应实验的YAML配置文件,包含超参数,网络结构等设置)路径.
# 创建所需目录(-p 表示递归创建,若已存在不报错).
mkdir -p ${result_dir}/last
mkdir -p ${result_dir}/best
# 获取当前时间戳,格式为"年月日_时分秒".
# 用于命名日志文件,避免覆盖,方便追踪训练时间.
now=$(date +"%Y%m%d_%H%M%S")
# 将关键脚本和配置文件复制到实验目录中,便于记录和复现实验.
cp ${config} tool/test.sh tool/${TEST_CODE} ${exp_dir}
# 执行测试命令(最佳模型):使用指定的Python解释器运行测试代码,传递配置文件路径和保存路径参数,同时输出到终端和日志文件
# -u 参数确保Python输出无缓冲,实时显示
$PYTHON -u ${exp_dir}/${TEST_CODE} \
--config=${config} \
save_folder ${result_dir}/best \
model_path ${model_dir}/model_best.pth \
2>&1 | tee ${exp_dir}/test_best-$now.log
# 执行测试命令(最新模型):使用指定的Python解释器运行测试代码,传递配置文件路径和保存路径参数,同时输出到终端和日志文件
$PYTHON -u ${exp_dir}/${TEST_CODE} \
--config=${config} \
save_folder ${result_dir}/last \
model_path ${model_dir}/model_last.pth \
2>&1 | tee ${exp_dir}/test_last-$now.log
博主没有训练完100轮,只是为了方便演示。
最佳模型:
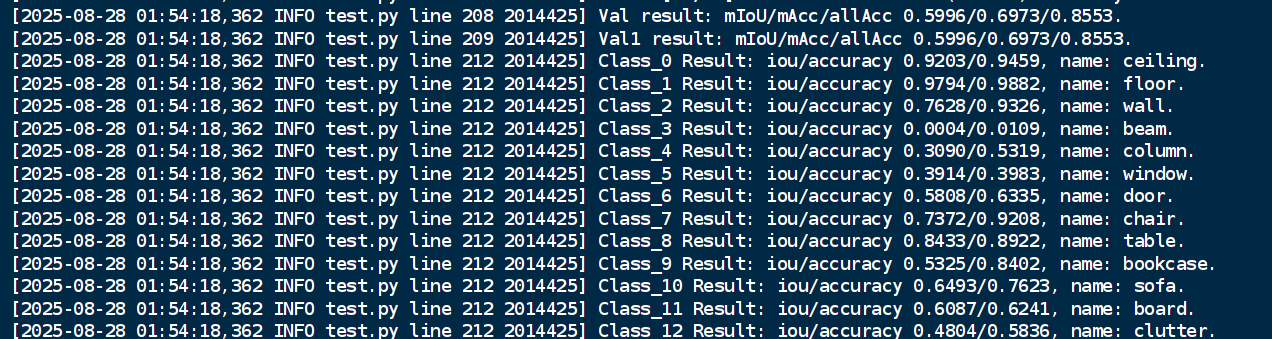
在point-transformer/exp/s3dis/pointtransformer_repro/result/best中,得到预测结果: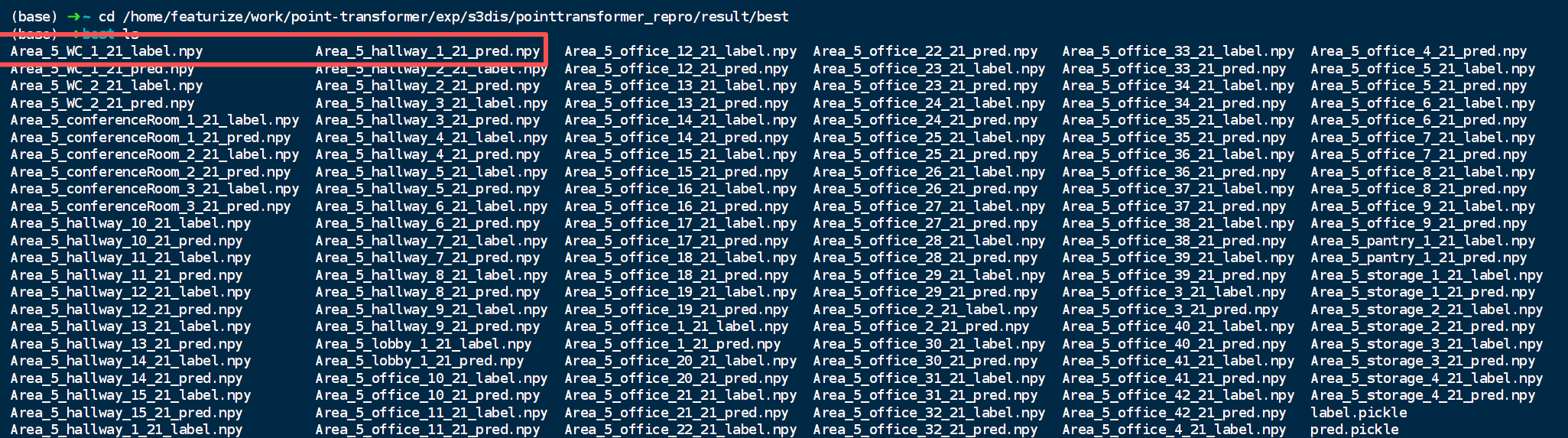
真实标签和预测标签作为一组对照出现。
最新模型: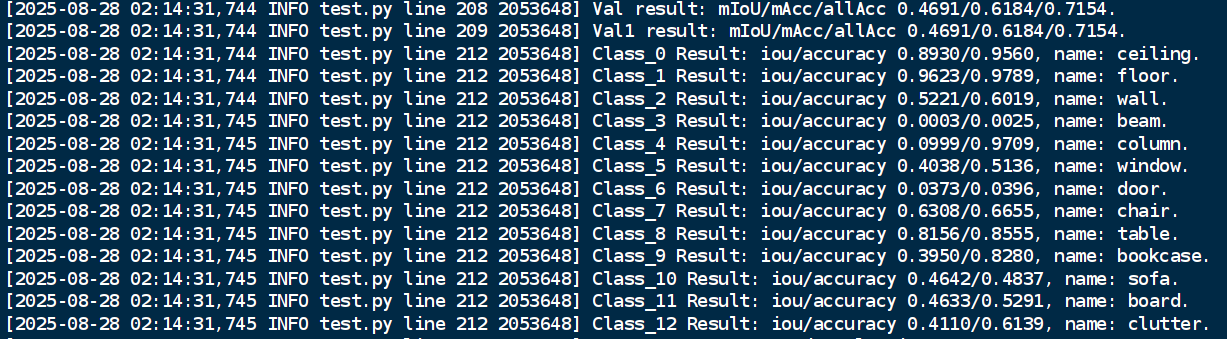
在point-transformer/exp/s3dis/pointtransformer_repro/result/last中,得到预测结果: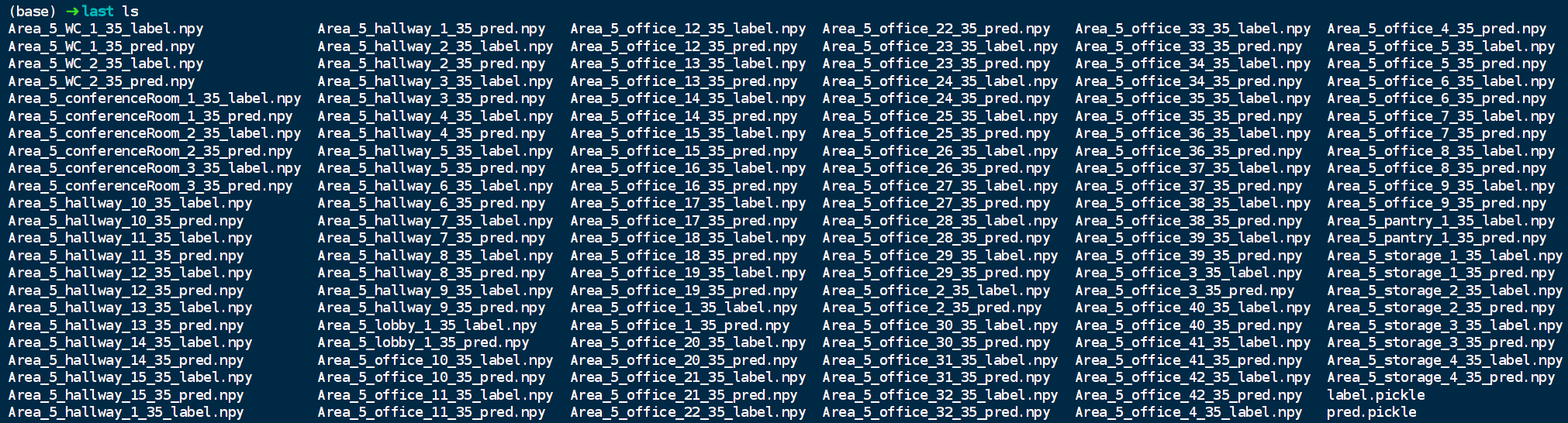
总结
尽可能简单、详细的介绍了PointTransformerV1的安装流程以及PointTransformerV1的使用方法。后续会根据自己学到的知识结合个人理解讲解PointTransformerV1的原理和代码。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)