2.1 强化学习基础(概念、流程、目标)
强化学习详解:从概念到应用
一、什么是强化学习?
强化学习(Reinforcement Learning, RL)是一种机器学习方法,它通过智能体(Agent)与环境(Environment)的交互来学习如何采取最优行为,从而最大化长期累积奖励。与有监督学习不同,强化学习不仅关注预测,还强调决策与反馈循环。
在一次交互中,流程如下:
- 感知(Perception):智能体观察当前的环境状态 sts_tst。
- 决策(Decision):智能体根据策略 π\piπ 选择一个动作 ata_tat。
- 反馈(Reward & Transition):环境根据动作给出奖励 rtr_trt 并转移到新状态 st+1s_{t+1}st+1。
- 目标(Objective):智能体的目标是最大化长期累积奖励的期望。
数学形式化
强化学习的目标可以用期望累积奖励来表示:
Gt=∑k=0∞γkrt+k G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k} Gt=k=0∑∞γkrt+k
其中:
- GtG_tGt 表示从时间 ttt 开始的累积奖励(Return)。
- γ∈[0,1]\gamma \in [0,1]γ∈[0,1] 是折扣因子(Discount factor),用于平衡短期和长期奖励。
- rt+kr_{t+k}rt+k 是第 t+kt+kt+k 步的即时奖励。
智能体的核心任务是找到一个最优策略 π∗\pi^*π∗,使得在任意状态下都能最大化期望累积奖励:
π∗=argmaxπE[Gt∣π] \pi^* = \arg\max_\pi \mathbb{E}[G_t | \pi] π∗=argπmaxE[Gt∣π]
强化学习的关键要素
1. 感知(Perception)
智能体需要感知环境的状态信息:
- 围棋 AI:感知棋盘上的布局。
- 无人车:感知道路、红绿灯、车辆和行人。
- 机器人狗:感知图像、地面摩擦和倾斜度。
这些状态信息通常记为 sts_tst。
2. 决策(Decision)
智能体根据策略(Policy)来选择动作:
- 围棋 AI:计算下一步落子的位置。
- 无人车:决定方向盘角度和油门、刹车力度。
- 机器人狗:计算四条腿的运动参数。
策略函数通常表示为:
π(a∣s)=P(At=a∣St=s) \pi(a|s) = P(A_t = a \mid S_t = s) π(a∣s)=P(At=a∣St=s)
即在状态 sss 下选择动作 aaa 的概率。
3. 奖励(Reward)
环境会返回一个标量信号 rtr_trt 作为反馈,用于衡量当前动作的好坏。
- 围棋:胜利奖励为 +1,失败为 -1。
- 无人车:安全且快速行驶获得正奖励,发生事故获得负奖励。
- 机器人狗:成功前进获得正奖励,摔倒获得负奖励。
奖励是智能体优化的核心目标。
强化学习与监督学习的区别
| 特点 | 强化学习(RL) | 监督学习(SL) |
|---|---|---|
| 任务类型 | 决策任务(多轮交互) | 预测任务(单轮) |
| 数据获取方式 | 与环境交互,试错学习 | 人工标注数据 |
| 反馈信号 | 延迟奖励,可能在很久之后才体现(游戏结束才能知道奖励) | 即时标签,立刻反馈 |
| 难点 | 平衡短期与长期奖励,探索与利用的权衡 | 模型泛化能力 |
一个关键区别是:决策可能带来长期后果。短期最优的选择并不一定是长期最优。例如:
- 在围棋中,眼前的吃子可能带来长期的失败。
- 在金融投资中,短期收益可能埋下长期风险。
强化学习解决的问题
强化学习主要解决序贯决策问题(Sequential Decision Making)。与人生选择类似,每一次决策都会影响未来的状态与选择。
二、强化学习的流程
智能体与环境的交互流程如下:
- 状态感知:智能体观察到环境的当前状态 sts_tst。
- 动作选择:根据策略 π\piπ,智能体选择一个动作 ata_tat。
- 环境响应:环境接收动作,生成即时奖励 rtr_trt,并转移到下一个状态 st+1s_{t+1}st+1。
- 策略更新:智能体利用奖励和新的状态更新自己的策略。
整个过程迭代进行,直到达到终止状态。例如,在围棋中,智能体每走一步棋(动作),棋盘布局(状态)会发生改变,比赛结果(奖励)则在终局时给出。
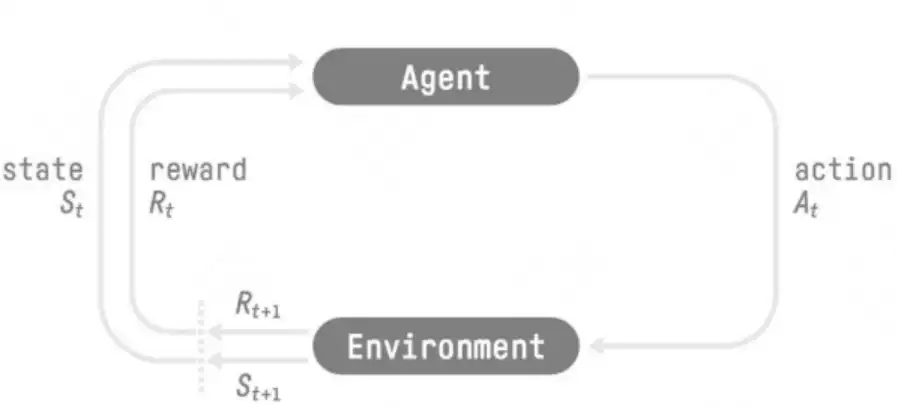
强化学习的环境
强化学习的环境通常用 随机过程(stochastic process) 来建模。环境的演变不仅取决于当前状态,还可能带有随机性。例如:
- 城市交通:红绿灯变化、车辆随机驶入道路。
- 足球比赛:即使战术相同,球员表现和偶然因素会导致不同结果。
- 布朗运动:水中微粒的运动轨迹是随机的。
状态转移公式
假设当前状态是 sts_tst,智能体采取的动作是 ata_tat,那么环境转移到下一状态 st+1s_{t+1}st+1 的概率由条件概率分布表示为:
P(st+1∣st,at) P(s_{t+1} \mid s_t, a_t) P(st+1∣st,at)
这里:
- sts_tst 表示当前状态;
- ata_tat 表示智能体采取的动作;
- P(st+1∣st,at)P(s_{t+1} \mid s_t, a_t)P(st+1∣st,at) 表示在给定状态和动作下,转移到下一状态的概率。
这意味着即使在相同的状态下采取相同的动作,下一状态也可能不同。例如,在赛车游戏中,同样踩油门,但由于赛道摩擦力、天气条件的随机变化,赛车的表现会有所差异。
强化学习的目标
在交互过程中,环境会给出即时奖励 rtr_trt,这些奖励的总和就是智能体的 回报(return):
Gt=∑k=0∞γkrt+k G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k} Gt=k=0∑∞γkrt+k
其中:
- GtG_tGt:从时刻 ttt 开始的回报;
- rt+kr_{t+k}rt+k:第 t+kt+kt+k 步的奖励;
- γ∈[0,1]\gamma \in [0,1]γ∈[0,1]:折扣因子(discount factor),用于平衡即时奖励与未来奖励的重要性。
折扣因子的引入保证了:
- 奖励不会无限累加(例如永远不结束的任务)。
- 更加重视近期奖励,而非遥远未来的奖励。
价值函数(Value Function)
强化学习的优化目标是找到一个策略 π\piπ,最大化回报的期望。为了形式化描述,引入 价值函数:
- 状态价值函数(State Value Function):
Vπ(s)=Eπ[Gt∣st=s] V^\pi(s) = \mathbb{E}_\pi \left[ G_t \mid s_t = s \right] Vπ(s)=Eπ[Gt∣st=s]
它表示:在状态 sss 下,按照策略 π\piπ 行动时,能获得的期望回报。(衡量状态的价值)
- 动作价值函数(Action Value Function):
Qπ(s,a)=Eπ[Gt∣st=s,at=a] Q^\pi(s,a) = \mathbb{E}_\pi \left[ G_t \mid s_t = s, a_t = a \right] Qπ(s,a)=Eπ[Gt∣st=s,at=a]
它表示:在状态 sss 下采取动作 aaa 后,按照策略 π\piπ 行动时,能获得的期望回报。(衡量这一步动作的价值)
实际案例:游戏中的分数优化
比如在 超级玛丽 游戏中:
- 每吃到金币获得 +10+10+10 分(即时奖励 rtr_trt);
- 每过关获得 +1000+1000+1000 分;
- 如果掉入陷阱则游戏结束(大的负奖励)。
智能体的目标是学习一个策略,使得它在长期游戏中 平均得分最高。这就对应最大化 期望回报 Vπ(s)V^\pi(s)Vπ(s)。
三、强化学习的独特性
在前面几节中,我们已经对强化学习的基本数学概念有了一定的了解。这一节将进一步回顾强化学习与有监督学习的区别,并从公式、数据来源、学习方式和反馈机制等多个角度进行深入讲解。
有监督学习的优化目标
在一般的有监督学习任务中,目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。假设训练数据满足独立同分布(i.i.d.)的条件,那么这个优化目标其实就是在最小化模型在整个数据分布上的泛化误差(generalization error)。
其核心公式为:
最优模型=argmin模型 E(特征,标签)∼数据分布[ 损失函数(标签,模型(特征)) ] \text{最优模型} = \arg \min_{\text{模型}} \; \mathbb{E}_{(\text{特征}, \text{标签}) \sim \text{数据分布}} \big[ \; \text{损失函数}(\text{标签}, \text{模型}(\text{特征})) \; \big] 最优模型=arg模型minE(特征,标签)∼数据分布[损失函数(标签,模型(特征))]
- 解释:
- 这里的 特征\text{特征}特征 表示输入(如图像的像素,或用户的一句话),
- 标签\text{标签}标签 表示真实的目标值(如分类任务中的类别标签)。
- 优化的过程,就是通过最小化预测结果与真实标签的差异,得到一个在数据分布上表现良好的模型。
案例:图像分类任务
例如,在 MNIST 手写数字分类中,特征\text{特征}特征 是 28×2828 \times 2828×28 的像素矩阵,标签\text{标签}标签 是数字类别(0–9)。模型通过最小化交叉熵损失函数,学习从图像到类别的映射。
强化学习的优化目标
相比之下,强化学习的目标是最大化智能体(agent)策略在与动态环境交互过程中的长期价值。
根据强化学习的理论,策略的价值可以等价转换为奖励函数在**策略的占用度量(occupancy measure)**上的期望。初学者在看这个定义时可能不好理解,但是这个公式可以帮忙理解。公式为:
最优策略=argmaxπ E(状态,动作)∼dπ[ r(状态,动作) ] \text{最优策略} = \arg \max_{\pi} \; \mathbb{E}_{(\text{状态}, \text{动作}) \sim d_\pi} \big[ \; r(\text{状态}, \text{动作}) \; \big] 最优策略=argπmaxE(状态,动作)∼dπ[r(状态,动作)]
- 解释:
- π\piπ 表示智能体的策略,即在每个状态下选择动作的概率分布;
- dπd_\pidπ 是该策略下的占用度量,即在环境交互中,状态–动作对 (s,a)(s,a)(s,a) 出现的概率分布;
- r(s,a)r(s,a)r(s,a) 是奖励函数,衡量状态 sss 下采取动作 aaa 的即时回报。
案例:自动驾驶
在自动驾驶任务中:
- 状态 sss 可能是车辆的传感器信息(如车速、路况、周围车辆位置);
- 动作 aaa 是驾驶决策(如转向、加速、刹车);
- 奖励 r(s,a)r(s,a)r(s,a) 可以设定为“保持车道 +1”、“安全超车 +5”、“发生碰撞 -100”。
强化学习的目标,就是通过不断试错与环境交互,学习出一套驾驶策略,使得长期总奖励最大化。
再次解析:策略的价值可以等价转换为奖励函数在**策略的占用度量(occupancy measure)**上的期望
- 策略的价值 (Value of a Policy)
通俗解释:如果智能体一直使用某个策略π,从开局到游戏结束,它平均能获得的总奖励是多少。这个值越高,说明策略越好。
- 策略的占用度量 (Occupancy Measure)
通俗解释:当智能体使用策略π玩这个游戏无数次时,它访问每一个“状态”并在该状态下执行每一个“动作”的频繁程度(概率分布)。
比如,在一个格子世界游戏中,一个策略如果倾向于“绕远路”,那么这个策略的占用度量就会在那些“远路”格子上有很高的概率值。一个倾向于“走捷径”的策略,则会在“近路”格子上有高概率值。
它捕获了策略π与环境交互所产生的数据分布。
- 奖励函数 (Reward Function) - r(状态, 动作)
通俗解释:环境给出的“打分器”。在某个状态下做了一个动作,环境会立即告诉你这个行为是好是坏(给你多少分)。比如吃豆人游戏中,吃到豆子+10分,碰到幽灵-100分。
- 期望 (Expectation)
通俗解释:加权平均。状态和动作的出现是有概率的(由占用度量决定)。(比如一个策略如果倾向于“绕远路”,那么这个策略的占用度量就会在那些“远路”格子上有很高的概率值。然后这条路路程偏远,但是比较通畅(这对应着奖励),最终可以根据期望获得策略的价值。同样一个倾向于“走捷径”的策略,则会在“近路”格子上有高概率值。然后这条路路程偏近,但是可能比较拥堵,最终也可以根据期望获得策略的价值。我们希望这个策略的价值尽可能高)
有监督学习与强化学习的核心区别
通过以上公式可以看出:
-
相似点
- 两者的优化目标都可以表述为“在一个数据分布下优化某个数值期望”。
- 有监督学习最小化损失期望;强化学习最大化奖励期望。
-
不同点
- 有监督学习:优化目标函数,但数据分布固定。
- 强化学习:改变数据分布(通过改变策略与环境交互),而奖励函数本身保持不变。 (通过强化学习不断试错,完成游戏的路径也会变化)
总结如下:
- 有监督学习:寻找一个模型,使其在给定的数据分布下,损失函数的期望最小;
- 强化学习:寻找一个策略,使其在与动态环境交互过程中,产生最优的数据分布,从而最大化奖励函数的期望。
数据层面的区别
有监督学习的数据来源
- 来自 预先标注好的数据集。
- 每个样本都有特征与对应的标签,数据分布是静态、固定的。
- 学习是一次性的,模型训练完成后数据分布不再变化。
例子:猫狗分类任务中,数据集已经包含了“猫图像 → 标签:猫”,“狗图像 → 标签:狗”,模型只需基于这些数据优化。
强化学习的数据来源
- 来自 智能体与环境的交互。
- 数据分布是动态的,由智能体的策略决定。不同策略会导致完全不同的训练数据。
- 学习是持续性的,需要通过“试错–反馈–更新”的循环过程进行。
例子:Atari 游戏学习。智能体起初可能随机按键,得到的经验是杂乱无章的;随着策略改进,它会越来越多地采样到“接近高分”的状态–动作对。
占用度量(Occupancy Measure)
强化学习中一个非常重要的概念是占用度量。
它描述了在策略 π\piπ 下,智能体和环境交互时采样到某个状态–动作对 (s,a)(s,a)(s,a) 的概率分布:
dπ(s,a)=Pr{在策略 π 下与环境交互时遇到状态 s 并采取动作 a} d_\pi(s,a) = \Pr\{ \text{在策略 $\pi$ 下与环境交互时遇到状态 $s$ 并采取动作 $a$} \} dπ(s,a)=Pr{在策略 π 下与环境交互时遇到状态 s 并采取动作 a}
关键性质:
- 给定两个策略 π1\pi_1π1 和 π2\pi_2π2,如果它们的占用度量 dπ1d_{\pi_1}dπ1 与 dπ2d_{\pi_2}dπ2 相同,那么这两个策略本质上是相同的。
- 因此,强化学习的本质就是在寻找一个最优的占用度量。
强化学习的难点
由于智能体的策略不断更新,其对应的占用度量(即数据分布)也会不断变化。因此,强化学习相比有监督学习存在额外的难点:
- 数据分布非静态:模型需要在不断变化的数据环境中进行学习;
- 延迟反馈:奖励往往不是即时的(例如,赢得一局围棋的奖励需要数百步后才体现);
- 探索与利用:智能体既要尝试新动作探索未知,也要利用已有知识获取奖励。
这也是为什么强化学习的训练过程通常比有监督学习更加复杂、耗时。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)