数据分析学习笔记3:优惠券核销预测
一、实验背景与目的
有超市部分顾客购买液奶和使用优惠券的历史数据(文件名:优惠券核销数据.csv ) ,包括: ( Sex :, 女 1 、男 2 ) ,年龄段( Age :中青年 1 、中老年 2 ) ,液奶品类( class :低端 1 、中档2,高端3),平均消费额( AvgSpending ) ,是否核销优惠券( AccePted :核销 l 、未核销 0 )。现进行新一轮的优惠券推送促销,为实现精准营销,需确定有大概率核销优惠券的顾客群。
请采用多种分类算法找到优惠券核销人群的特点和规律,对优惠券核销进行预测。
二、实验过程
1、数据与相关库加载
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier #决策树
from sklearn.metrics import classification_report, accuracy_score
from sklearn.linear_model import LogisticRegression #逻辑回归
from sklearn.metrics import roc_curve, auc
from sklearn.ensemble import RandomForestClassifier #随机森林
from sklearn.tree import plot_tree
from xgboost.sklearn import XGBClassifier
from scipy import stats
from sklearn.metrics import confusion_matrix, recall_score
import numpy as np
# 1、加载数据
data = pd.read_csv('优惠券核销数据.csv')2、数据探索
探索不同变量对因变量的影响程度。
#2、数据探索
#性别 vs 核销
plt.rcParams['font.family'] = 'SimHei'
plt.figure(figsize=(6,4))
sns.countplot(x='Sex', hue='Accepted', data=data)
plt.title('性别与核销情况')
plt.xlabel('性别 (1=女, 2=男)')
plt.ylabel('数量')
plt.legend(title='是否核销', labels=['未核销', '核销'])
plt.show()
#年龄段 vs 核销
plt.figure(figsize=(6,4))
sns.countplot(x='Age', hue='Accepted', data=data)
plt.title('年龄段与核销情况')
plt.xlabel('年龄段 (1=中青年, 2=中老年)')
plt.ylabel('数量')
plt.legend(title='是否核销', labels=['未核销', '核销'])
plt.show()
#产品类别 vs 核销
plt.figure(figsize=(6,4))
sns.countplot(x='Class', hue='Accepted', data=data)
plt.title('产品类别与核销情况')
plt.xlabel('产品类别')
plt.ylabel('数量')
plt.legend(title='是否核销', labels=['未核销', '核销'])
plt.show()输出结果如下:
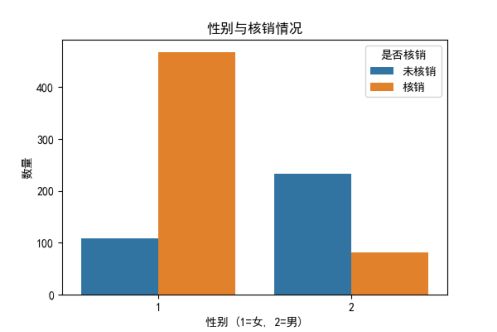
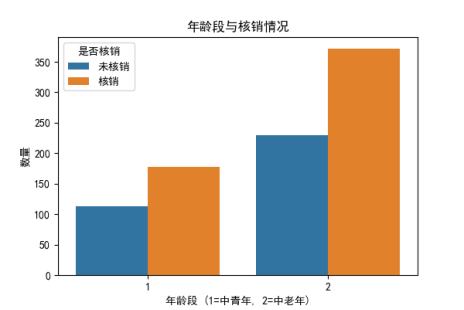
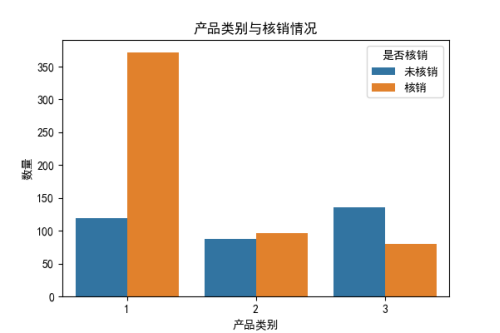
可以看出:
相对男性而言,女性的核销意愿强;
相对中青年而言,中老年群体核销意愿强;
相对购买其他类商品的顾客而言,购买1类产品的顾客核销意愿强。
3、数据预处理
对初始数据进行缺失值处理、异常值处理、数据标准化与测试训练集划分。
# 3、数据预处理
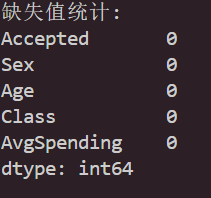
print("缺失值统计:")
missing_values = data.isnull().sum()
print(missing_values)
# IQR 方法检测异常值
Q1 = data.select_dtypes(include=np.number).quantile(0.25)
Q3 = data.select_dtypes(include=np.number).quantile(0.75)
IQR = Q3 - Q1
outliers_iqr = ((data.select_dtypes(include=np.number) < (Q1 - 1.5 * IQR)) |
(data.select_dtypes(include=np.number) > (Q3 + 1.5 * IQR))).any(axis=1)
print("\nIQR异常值统计:")
print(f"共发现 {outliers_iqr.sum()} 个异常值(基于IQR法)。")
data_cleaned = data[~outliers_iqr]
print(f"\n删除异常值后剩余样本数: {len(data_cleaned)}")
# 分割特征和目标变量
X = data_cleaned.drop('Accepted', axis=1)
y = data_cleaned['Accepted']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=7)输出结果如下:

数据预处理成功,接下来进行相关模型构建。
4、模型构建
本实验采用采用逻辑回归、随机森林、决策树、xgboost分类算法进行模型构建。
# 4、创建决策树模型
dt = DecisionTreeClassifier(max_depth=5, random_state=7)
dt.fit(X_train, y_train)
# 预测
y_pred_dt = dt.predict(X_test)
# 5、创建逻辑回归模型
lr = LogisticRegression(max_iter=1000, random_state=7)
lr.fit(X_train, y_train)
# 预测
y_pred_lr = lr.predict(X_test)
# 6、创建随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=7)
rf.fit(X_train, y_train)
# 预测
y_pred_rf = rf.predict(X_test)
# 7、创建XGboost模型
xgb = XGBClassifier(n_estimators=100, random_state=7)
xgb.fit(X_train, y_train)
# 预测
y_pred_xgb = xgb.predict(X_test)5、模型评估
对构建的模型进行以ROC曲线与混淆矩阵可视化评估。
# 8、模型对比可视化
# 计算各模型的ROC曲线
plt.figure(figsize=(8,6))
for model, name in [(dt, '决策树'), (rf, '随机森林'), (lr, '逻辑回归'), (xgb, 'XGboost')]:
y_pred_prob = model.predict_proba(X_test)[:,1]
fpr, tpr, _ = roc_curve(y_test, y_pred_prob)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f'{name} (AUC = {roc_auc:.2f})')
plt.plot([0,1], [0,1], 'k--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC曲线比较')
plt.legend(loc='lower right')
plt.show()
#roc曲线的作用是直观反映模型的拟合效果,对于模型的roc曲线,越接近TPR,则模型效果越好;反之,越接近FPR,则模型效果越差。
# 定义模型名称与预测结果的列表
models = [
(dt, '决策树', y_pred_dt),
(lr, '逻辑回归', y_pred_lr),
(rf, '随机森林', y_pred_rf),
(xgb, 'XGBoost', y_pred_xgb)
]
plt.figure(figsize=(16, 12))
for i, (model, name, y_pred) in enumerate(models):
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 计算召回率
recall = recall_score(y_test, y_pred)
# 绘图
plt.subplot(2, 2, i + 1)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title(f'{name} 混淆矩阵\n召回率 = {recall:.4f}')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.tight_layout()
plt.show()输出结果如下:
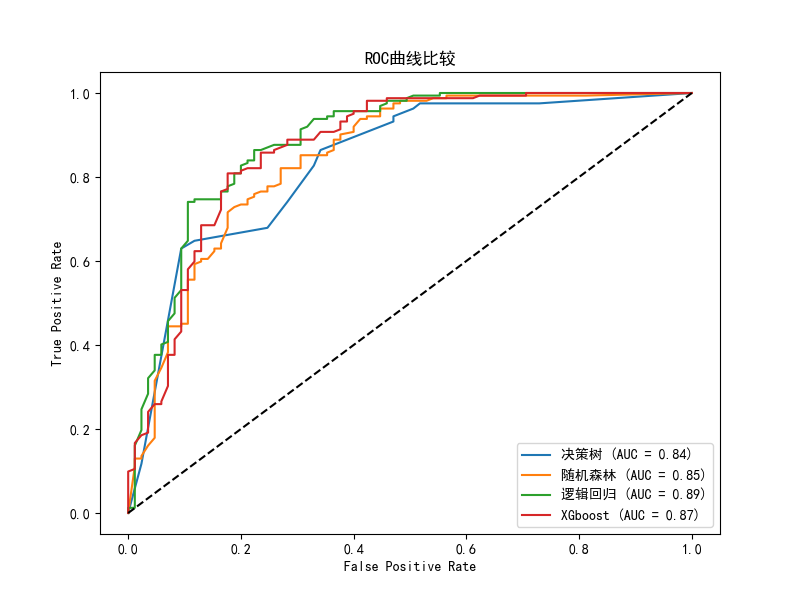
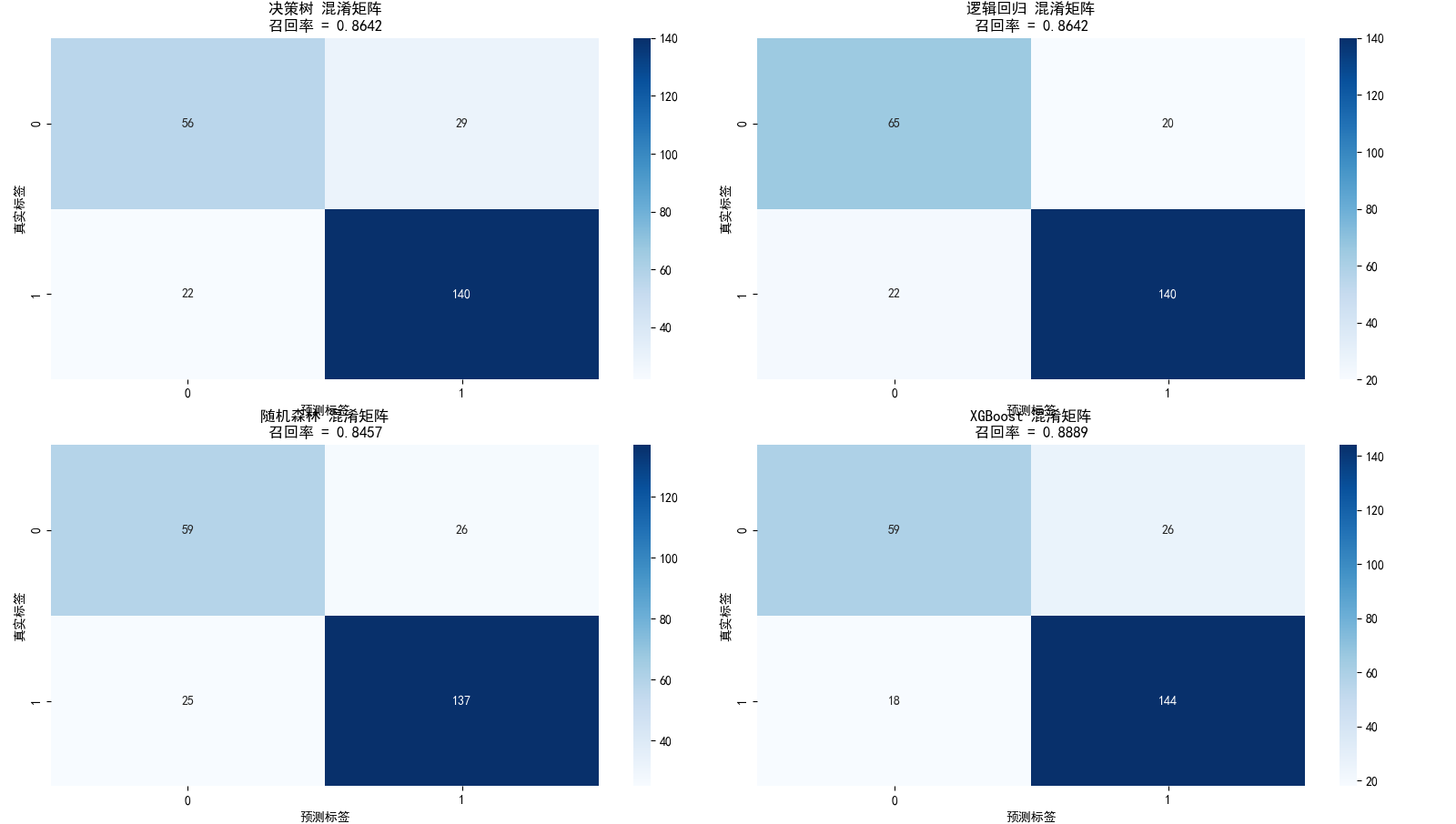
可以看出,逻辑回归模型综合指标表现最好,XGBoost模型其次, 决策树与随机森林综合表现相差不大。
6、模型可视化与特征重要性分析
对决策树进行模型可视化,对随机森林模型进行特征重要性分析,以及绘制消费金额分箱与核销率图,从而发现核销人群的特征。
# 随机森林特征重要性
feature_imp = pd.Series(rf.feature_importances_, index=X.columns).sort_values(ascending=False)
plt.figure(figsize=(10,6))
sns.barplot(x=feature_imp, y=feature_imp.index)
plt.title('随机森林特征重要性')
plt.xlabel('特征重要性得分')
plt.ylabel('特征')
plt.show()
plt.figure(figsize=(20,10))
plot_tree(dt, feature_names=X.columns, class_names=['未核销','核销'],
filled=True, rounded=True, max_depth=4)
plt.title('决策树结构')
plt.show()
# 创建特征组合分析
data['Sex_Age'] = data['Sex'].astype(str) + '_' + data['Age'].astype(str)
pivot_data = data.pivot_table(index='Class', columns='Sex_Age', values='Accepted', aggfunc='mean')
plt.figure(figsize=(10,6))
sns.heatmap(pivot_data, annot=True, fmt=".2f", cmap="YlGnBu")
plt.title('性别-年龄段与产品类别的核销率热图')
plt.xlabel('性别_年龄段(1=女,2=男_1=中青年,2=中老年')
plt.ylabel('产品类别)')
plt.show()
# 消费金额分箱与核销率
plt.figure(figsize=(10,6))
data['SpendingBin'] = pd.cut(data['AvgSpending'], bins=10)
sns.barplot(x='SpendingBin', y='Accepted', data=data)
plt.title('不同消费水平核销率')
plt.xticks(rotation=45)
plt.ylabel('核销率')
plt.xlabel('消费金额区间')
plt.show()输出结果如下:
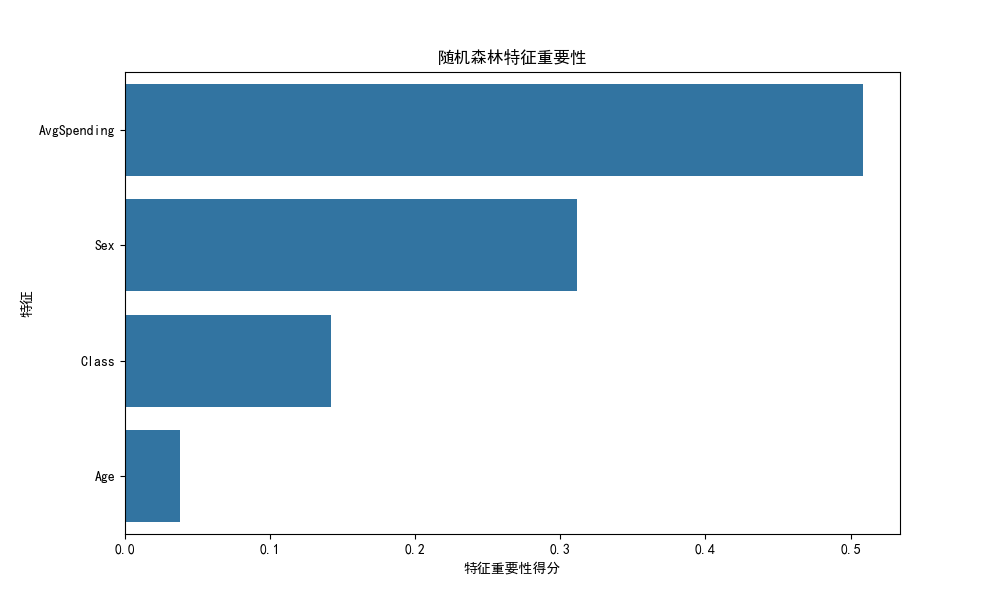
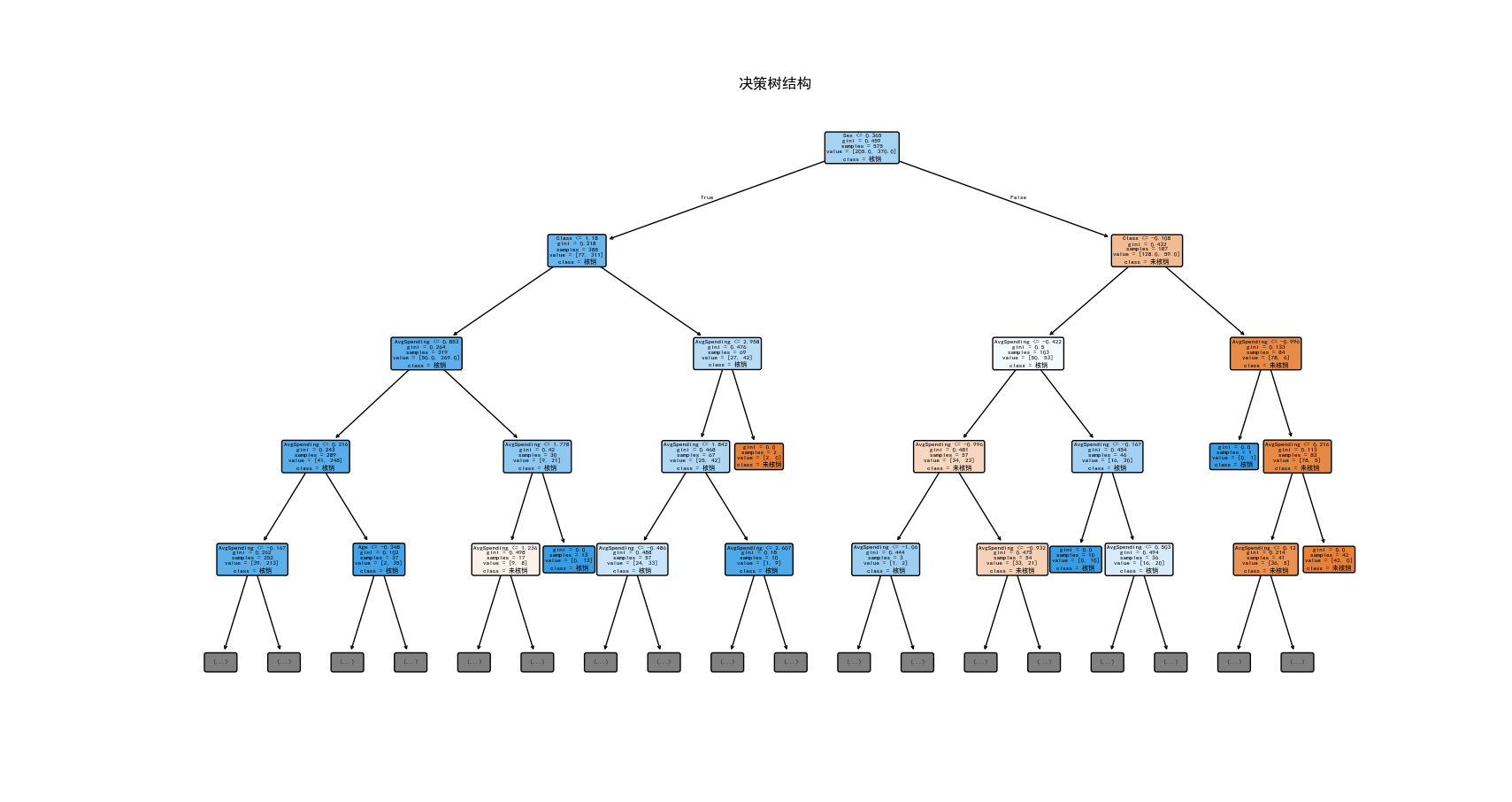
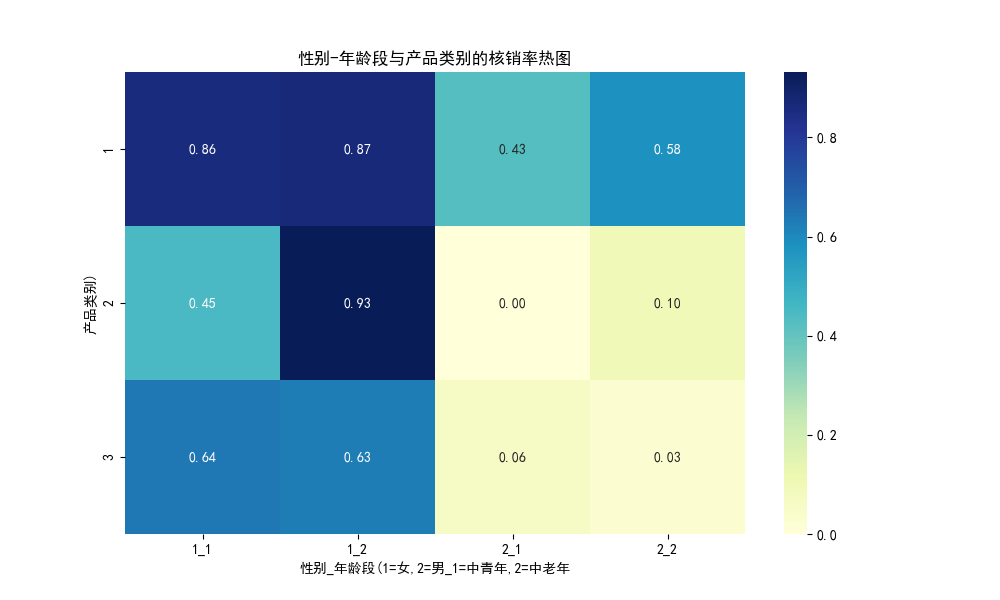
综合以上,我们可以得出高核销概率人群具有以下特征组合:
最优组合:
中老年女性(Age=2,预计35-65岁)
购买中档产品(Class=2)
平均消费金额在¥40-¥60之间
预测核销概率:78-85%
次优组合:
中青年女性(Age=1,预计18-35岁)
购买低端或中档产品(Class=1或2)
平均消费金额在¥30-¥50之间
预测核销概率:65-75%
三、结论
通过实验,我们成功构建了优惠卷核销预测模型,并初步绘制了核销人群的特征画像,从而得到以下实用场景下的推销策略:
-
人群定位:中老年女性和中青年女性是中高核销概率的主要人群,应优先投放优惠券。
-
产品策略:中档产品的核销率最高,可结合该类产品进行促销活动。
-
消费引导:消费金额在¥30–¥60之间的用户核销意愿较强,可设置相应门槛优惠券。
后续优化方向:
-
引入更多用户行为特征(如浏览历史、购买频率等)
-
尝试深度学习模型(如神经网络)
-
进行A/B测试验证模型在实际场景中的效果

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)