神经网络入门:前馈神经网络(超详细+实战讲解)
前馈神经网络是最基础的神经网络类型,信息单向流动(输入层→隐藏层→输出层),通过多层非线性变换实现端到端学习。文章详细介绍了神经网络的结构、激活函数(如Sigmoid、ReLU)、初始化方法(Xavier、He)、损失函数(交叉熵、均方误差)、优化算法(SGD、Adam)以及正则化技术(Dropout、L2正则化)。通过三个实践任务(XOR分类、MNIST手写数字识别、CIFAR10图像分类)展示
引言
- 神经网络与深度神经网络:
在人工智能领域,有一个方法叫机器学习。在机器学习这个方法里,有一类算法叫神经网络。神经网络如下图所示:
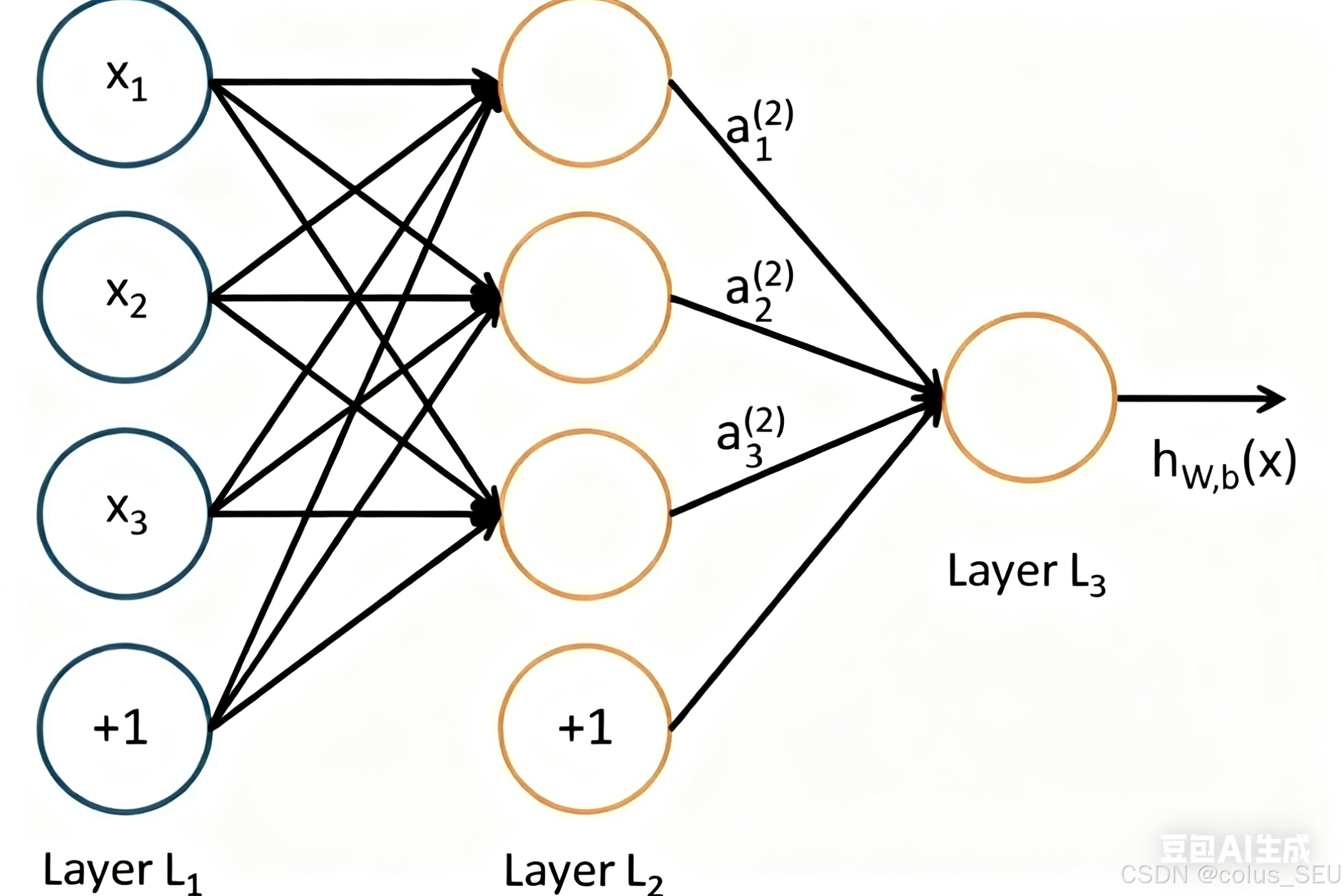
上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的神经元没有连接。最左边的层叫做输入层,负责接收输入数据;最右边的层叫输出层,从这层获取神经网络输出数据。输入层和输出层之间的叫隐藏层。
隐藏层大于二的神经网络叫做深度神经网络。而深度学习,就是使用深层架构(比如,深度神经网络)的机器学习方法。
深层网络表达力更强。事实上,一个仅有一个隐藏层的神经网络就能拟合任何一个函数,但是它需要很多很多的神经元。而深层网络用少得多的神经元就能拟合同样的函数。也就是为了拟合一个函数,要么使用一个浅而宽的网络,要么使用一个深而窄的网络。而后者往往更节约资源。唯一缺点就是深层网络不太容易训练。
-
前馈神经网络的定义:前馈神经网络是一种最简单的人工神经网络,其信息流动方向是单向的(从输入层→隐藏层→输出层),不存在循环或反馈连接,是深度学习的基础模型。
-
前馈神经网络的核心思想:通过多层非线性变换拟合输入与输出之间的映射关系,实现从数据到目标的端到端学习。
前馈神经网络作为最简单的神经网络,非常适合深度学习领域入门者进行学习。本文从理论和实践的角度全面介绍了前馈神经网络,为读者提供完善的入门指引😄
长文预警!
不愿看长文的读者可以根据需要直接跳转以下链接👇👇👇
🎉 🎉 🎉 我的前馈神经网络系列文章如下,便于读者成体系学习:🎉 🎉 🎉
1、🕸 网络结构
1.1 神经元
受生物神经元的启发,人工神经元接收来自其他神经元或外部源的输入,每个输入都有一个相关的权值,它是根据该输入对当前神经元的重要性来确定的,对该输入加权并与其他输入求和后,经过一个激活函数,计算得到该神经元的输出。也可以说,一个神经元的功能是求得输入向量与权向量的内积后,经一个非线性传递函数(激活函数)得到一个标量结果。一个简单的神经元结构如下图所示:
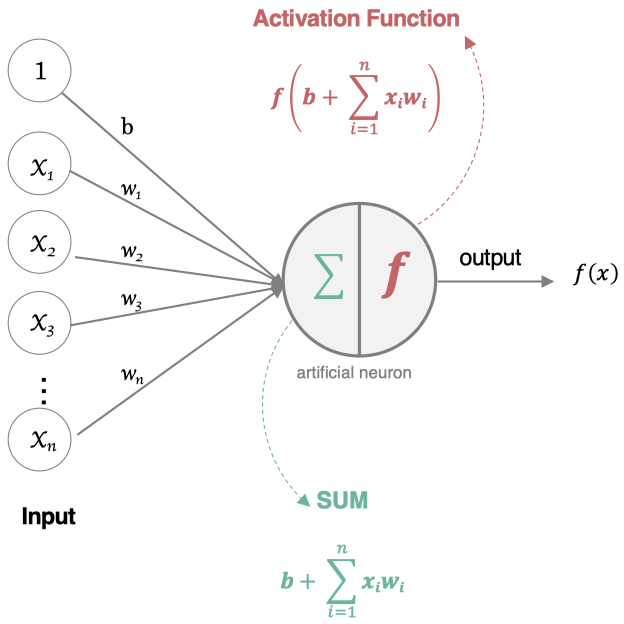
为输入
为偏置项
为输入对应的权值
即为对输入加权并与其他输入求和
为激活函数
1943 年,McCulloch 和 Pitts 将上述情形抽象为上图所示的简单模型,这就是一直沿用至今的 M-P 神经元模型。把许多这样的神经元按照一定的层次结构连接起来,就得到了神经网络。
1.2 感知机(PLA,Perceptron Learning Algorithm):
1.2.1 感知机模型
感知机由两层神经网络组成,输入层接收外界输入信号后传递给输出层,输出层是 M-P 神经元,这两层共同组成了一个简单的神经元,即单个神经元模型,是较大神经网络的前身。它是一个线性的二分类器,但它对非线性的数据并不能进行有效的分类。因此我们可以加深这个神经元的网络层次,理论上来说,多层网络可以模拟任何复杂的函数。以下是感知机的概念公式:
其中 为激活函数。
为了方便理解感知机的作用,我们举个例子:
例子:用感知机实现 and 函数
我们设计一个感知机,让它来实现 and 运算。and 的真值表:
x_1 x_2 y 0 0 0 0 1 0 1 0 0 1 1 1 如果令 w_1 = 0.5; w_2 = 0.5; b = -0.8,激活函数取阶跃函数:
通过验算易知,这时感知机就相当于 and 函数。
1.2.2 感知机的训练
权重项和偏置项的值是如何获得的呢?这就要用到感知器训练算法:将权重项和偏置项初始化为0,然后,利用下面的感知器规则迭代的修改 w_i 和 b,直到训练完成。
其中:
是与输入
对应的权重项,
是偏置项。事实上,可以把
看作是值永远为1的输入
所对应的权重。t 是训练样本的实际值,一般称之为label。而 y 是感知器的输出值,根据感知机的概念公式计算得出。
是一个称为学习率的常数,其作用是控制每一步调整权的幅度。
每次从训练数据中取出一个样本的输入向量 x,使用感知器计算其输出 y,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
1.2.3 感知机作用
感知机是一个线性的二分类器,它对非线性的数据并不能进行有效的分类,这也是为什么感知器不能实现异或运算,异或运算不是线性的,无法用一条直线把分类0和分类1分开。因此我们可以加深这个神经元的网络层次变为多层感知机,理论上来说,多层网络可以模拟任何复杂的函数。
1.3 多层感知机(MLP,Multi-Layer Perceptron):
-
概念:由感知机推广而来,它最主要的特点就是有多个神经元层,因此 MLP 也被称为人工神经网络(Artificial Neural Network,ANN)。MLP 是一种特定类型的人工神经网络,它由多个神经元组成,通常包括一个输入层、一个或多个隐藏层以及一个输出层。相对而言,ANN 是一个更广泛的术语,它包括了所有由神经元组成的网络,而 MLP 则是 ANN 中的一个特例,指代具有多个层的前馈神经网络。所以在讨论上,MLP 和 ANN 可以互换使用。
-
全连接层:从结构图中我们可以看出,多层感知机这三类给定层(输入、中间、输出层)中的每个节点都会连接到相邻层中的每个节点(全连接),所以这里有一个MLP中最重要的一个组成就是Dense Layer(全连接层/线性层/稠密层,在本文中我称之为全连接层),它在MLP中发挥的是什么样的作用呢?全连接层中有一个可以学习的参数 W(
维矩阵,n:输入特征的维度,m:输出的向量的长度),还有一个参数 b(偏置项,长为 m),所以在这一层我们会对输入的数据 x 进行下面的公式计算,得到输出 y 。
写成向量形式:
那么之前我们所了解到的线性回归,本质上就可以认为是一个全连接层,但是只有一个输出,即
-
非线性结构的由来:如何将线性结构变为多层感知机呢?——重点就是:全连接(Dense) + 激活函数(引入非线性)。 将全连接层简单的叠加在一起还是线性的,所以要加入非线性的东西在里面,也就是激活函数(比如sigmoid、Relu等),才能实现非线性(可以去拟合各种各样的函数,更具现实意义)。
2、📈 激活函数
2.1 激活函数的作用
-
增加模型的非线性分割能力
| 图1 | 图2 |
|---|---|
 |
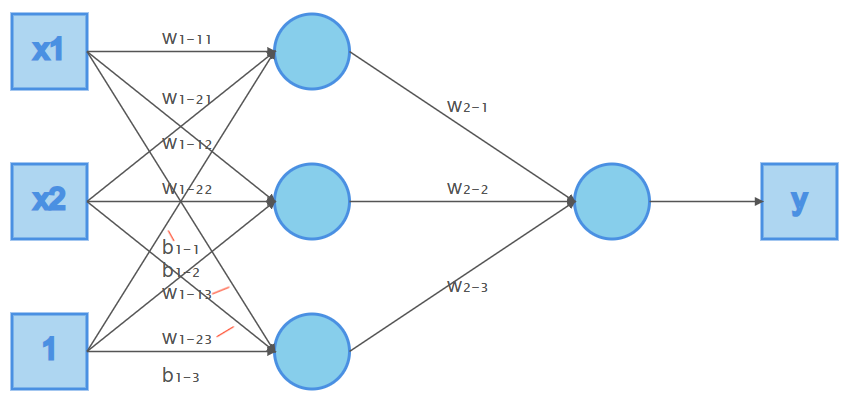 |
在神经元中引入激活函数的本质是向神经网络中引入非线性因素,通过激活函数,神经网络就可以拟合各种曲线。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合
如图2,在图1基础上增加了一层隐藏层
输出由
变为了
但仍然为线性,没有任何改进
引入非线性函数作为激活函数,那输出不再是输入的线性组合,可以逼近任意函数。
-
提高模型鲁棒性
-
缓解梯度消失问题
-
加速模型收敛等
2.2 激活函数的种类
2.2.1 Sigmoid 函数
-
数学公式
-
函数及其导数图像
Sigmoid 函数 Sigmoid 导数 
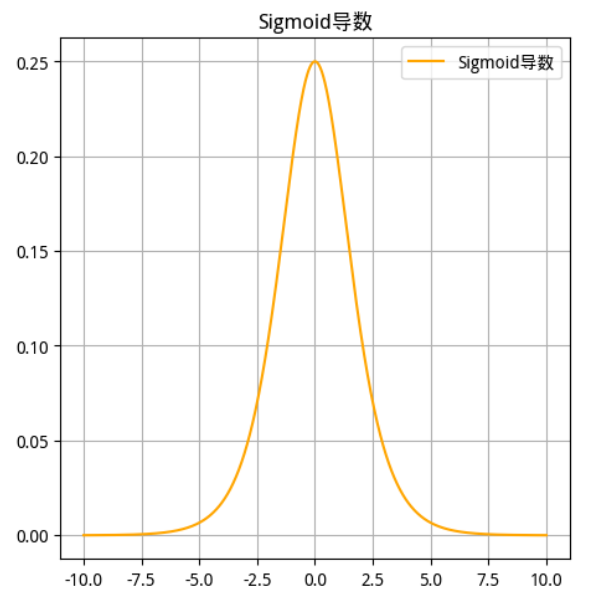
-
使用场景
-
sigmoid 在定义域内处处可导,且两侧导数逐渐趋近于0。如果 x 的值很大或者很小的时候,那么函数的梯度(函数的斜率)会非常小,在反向传播的过程中,导致了向低层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失 。一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的(是以 0.5 为中心的),所以在实践中这种激活函数使用的很少。
-
sigmoid函数将输入映射到 (0, 1) 区间,一般只用于二分类的输出层
-
-
实现代码
import torch import torch.nn as nn import torch.nn.functional as F # 方法1:使用类(作为网络层) sigmoid_layer = nn.Sigmoid() # 方法2:使用函数式接口 x = torch.tensor([-2.0, 0.0, 2.0]) output1 = sigmoid_layer(x) # 类调用 output2 = F.sigmoid(x) # 函数调用 print("Sigmoid输出:", output1) # 输出:tensor([0.1192, 0.5000, 0.8808])
2.2.2 Tanh函数
-
数学公式
-
函数及其导数图像
Tanh 函数 Tanh 导数 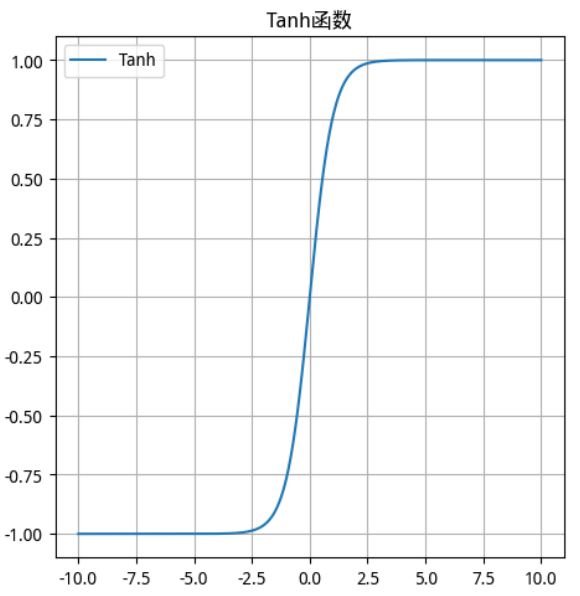
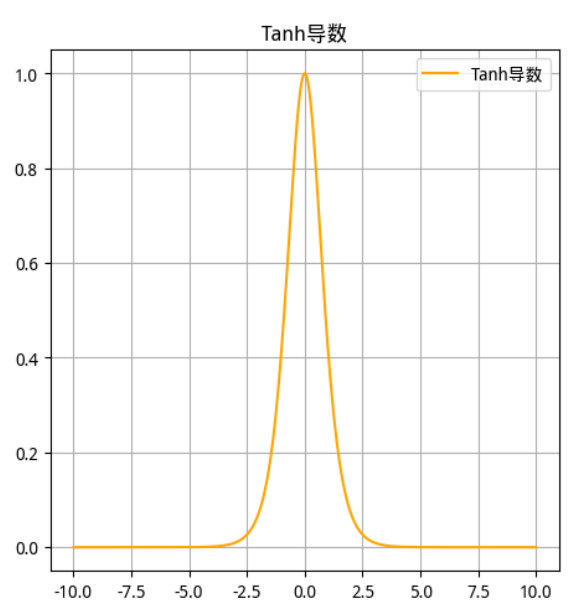
-
使用场景
tanh 也是一种非常常见的激活函数。与 sigmoid 相比,它是以 0 为中心的,使得其收敛速度要比 sigmoid 快(相比之下,tanh 曲线更为陡峭一些),减少迭代次数。然而,从图中可以看出,tanh 两侧的导数也为 0,同样会造成梯度消失。
若使用时可在隐藏层使用 tanh 函数,在输出层使用 sigmoid 函数。
-
实现代码
import torch import torch.nn as nn import torch.nn.functional as F # 方法1:使用类 tanh_layer = nn.Tanh() # 方法2:使用函数式接口 x = torch.tensor([-1.0, 0.0, 1.0]) output1 = tanh_layer(x) # 类调用 output2 = F.tanh(x) # 函数调用 print("Tanh输出:", output1) # 输出:tensor([-0.7616, 0.0000, 0.7616])
2.2.3 ReLU函数
-
数学公式
-
函数及其导数图像
ReLU 函数 ReLU 导数 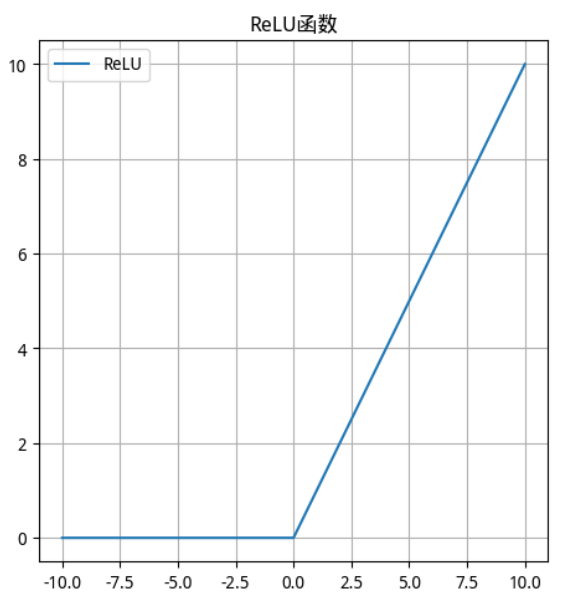
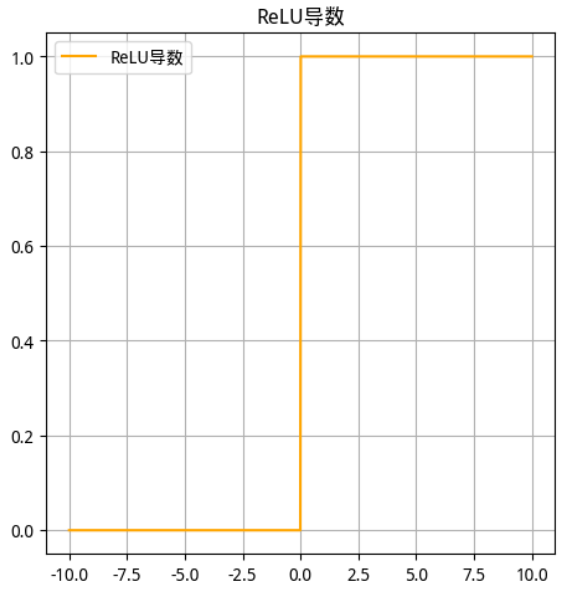
-
使用场景
-
ReLU是目前最常用的激活函数。 从图中可以看到,当 x<0 时,ReLU导数为0,而当 x>0 时,则不存在饱和问题。所以,ReLU 能够在 x>0 时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新。这种现象被称为“神经元死亡”。
-
Relu是输入只能大于0,如果你输入含有负数,Relu就不适合,如果你的输入是图片格式,Relu就挺常用的,因为图片的像素值作为输入时取值为[0,255]。
-
与sigmoid相比,RELU的优势是:
-
采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
-
sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
-
Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题。
-
-
-
实现代码
import torch import torch.nn as nn import torch.nn.functional as F # 方法1:使用类 relu_layer = nn.ReLU() # 方法2:使用函数式接口 x = torch.tensor([-1.0, 0.0, 1.0]) output1 = relu_layer(x) # 类调用 output2 = F.relu(x) # 函数调用 # 类接口(如nn.ReLU): # 适合在__init__中定义为网络的固定层,参数可通过model.parameters()管理(如 Swish 的\(\beta\)) # 函数接口(如F.relu): # 适合在forward中灵活调用,无需在__init__中预先定义 print("ReLU输出:", output1) # 输出:tensor([0., 0., 1.])
2.2.4 Leaky ReLU 函数
-
数学公式(一般取
)
-
函数及其导数图像
Leaky ReLU 函数 Leaky ReLU 导数 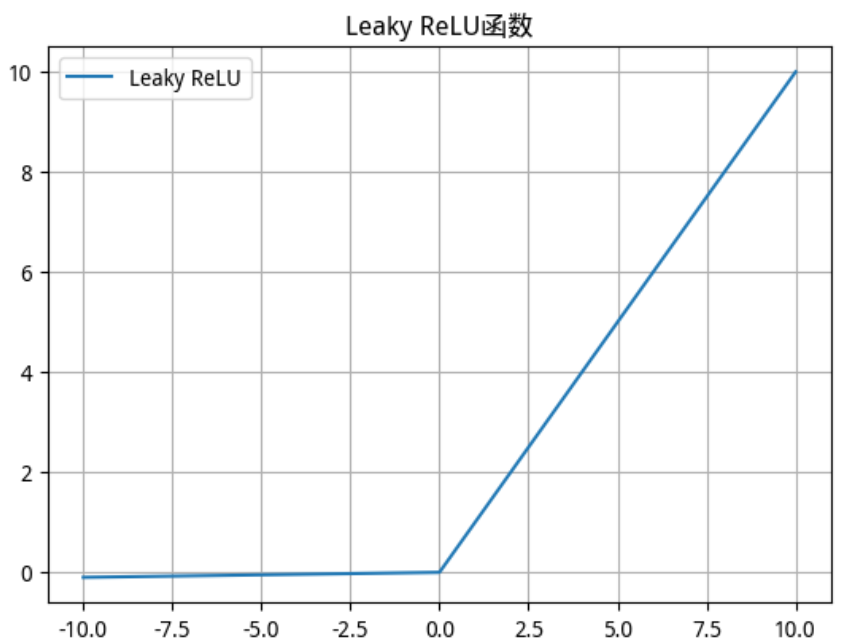
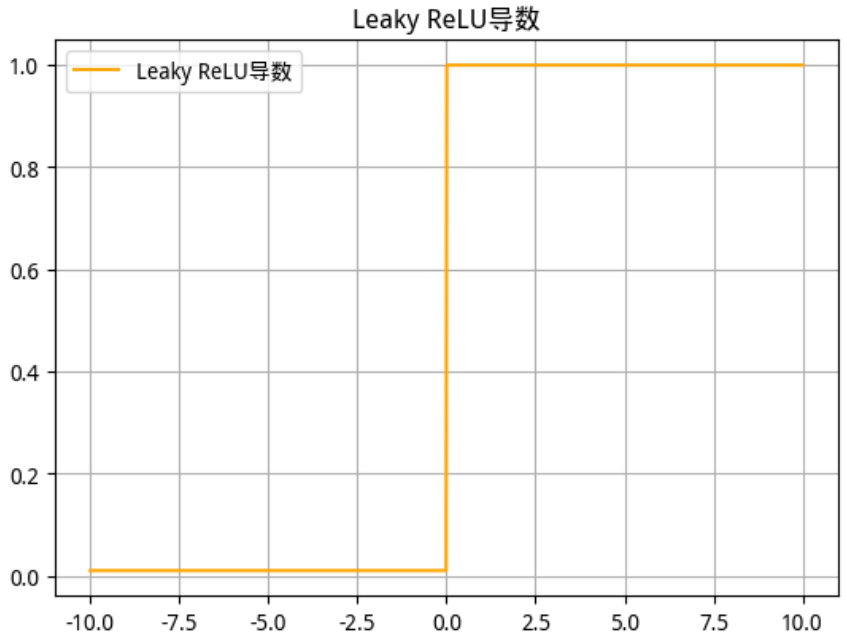
-
使用场景
该激活函数是对RELU的改进,一定程度上缓解了神经元死亡问题
-
实现代码
import torch import torch.nn as nn import torch.nn.functional as F # 方法1:使用类(可指定alpha) leaky_relu_layer = nn.LeakyReLU(negative_slope=0.01) # negative_slope即alpha # 方法2:使用函数式接口 x = torch.tensor([-1.0, 0.0, 1.0]) output1 = leaky_relu_layer(x) # 类调用 output2 = F.leaky_relu(x, negative_slope=0.01) # 函数调用 print("Leaky ReLU输出:", output1) # 输出:tensor([-0.0100, 0.0000, 1.0000])
2.2.5 ELU(Exponential Linear Unit)函数
-
数学公式
-
函数及其导数图像
ELU 函数 ELU 导数 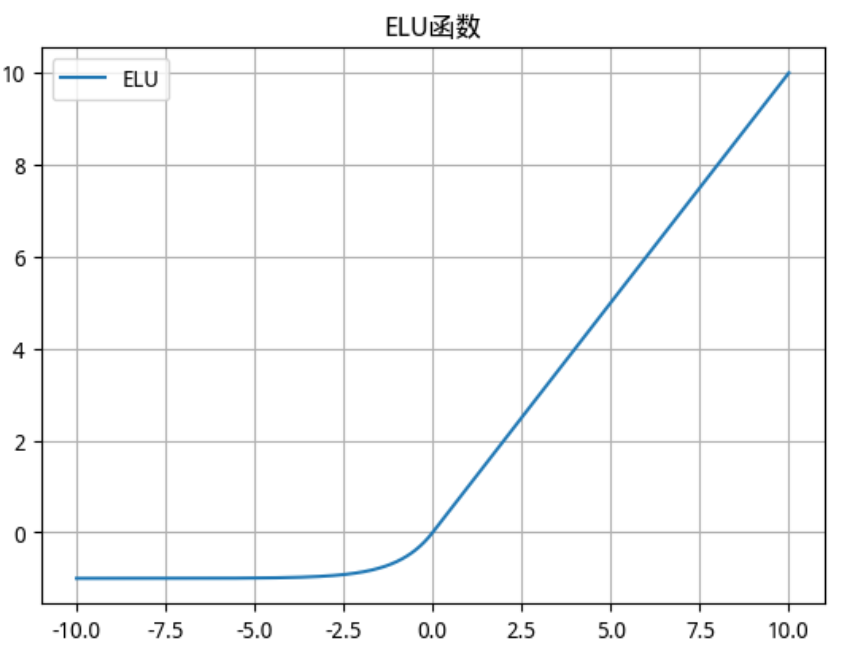
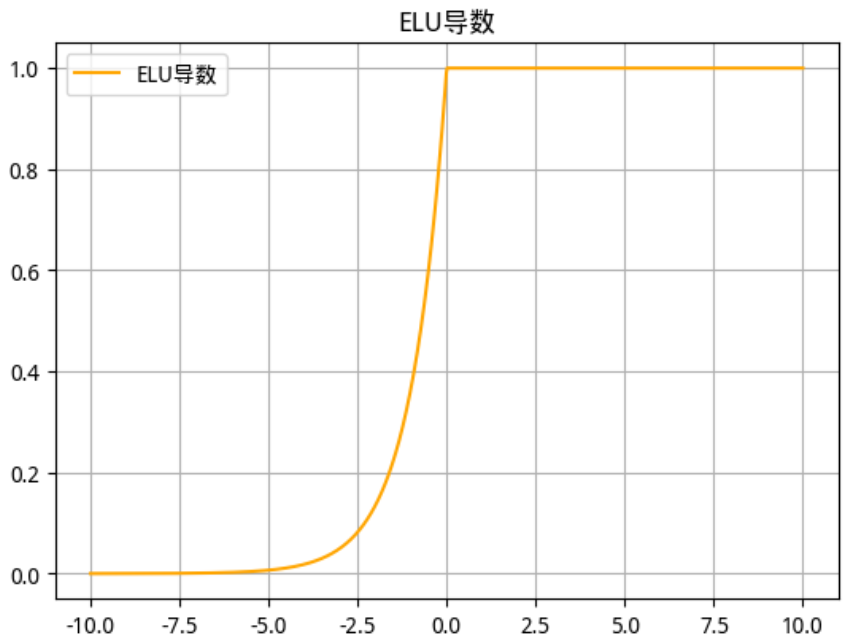
-
使用场景
ELU激活函数是一种改进的激活函数,它在处理负值时具有独特的优势。ELU函数通过引入指数函数来处理负输入,从而在理论上可以提供更好的性能。因此,ELU激活函数适用于需要处理大量负值输入的各种深度学习任务。
-
实现代码
import torch import torch.nn as nn import torch.nn.functional as F # 方法1:使用类(可指定alpha) elu_layer = nn.ELU(alpha=1.0) # 方法2:使用函数式接口 x = torch.tensor([-1.0, 0.0, 1.0]) output1 = elu_layer(x) # 类调用 output2 = F.elu(x, alpha=1.0) # 函数调用 print("ELU输出:", output1) # 输出:tensor([-0.6321, 0.0000, 1.0000])
2.2.6 Softmax函数
-
数学公式
-
使用场景
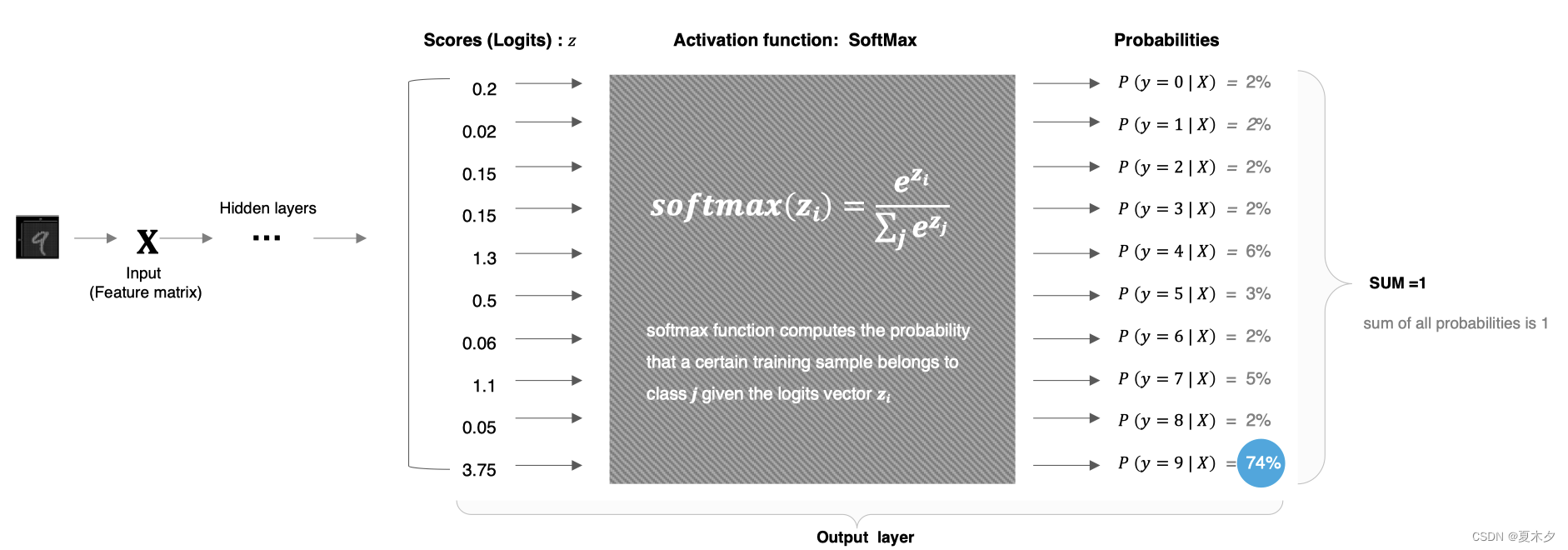
softmax用于多分类过程中,它是二分类函数 sigmoid 在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
softmax 直白来说就是将网络输出的 logits 通过softmax函数,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们将它理解成概率,选取概率最大(也就是值对应最大的)接点,作为我们的预测目标类别。
-
实现代码
import torch import torch.nn as nn import torch.nn.functional as F # 方法1:使用类(dim参数指定计算维度,通常为-1表示最后一维) softmax_layer = nn.Softmax(dim=-1) # 方法2:使用函数式接口 x = torch.tensor([[1.0, 2.0, 3.0]]) # 假设是批次中的一个样本(形状:[1, 3]) output1 = softmax_layer(x) # 类调用 output2 = F.softmax(x, dim=-1) # 函数调用 print("Softmax输出:", output1) # 输出:tensor([[0.0900, 0.2447, 0.6652]]) print("概率和:", output1.sum()) # 输出:tensor(1.0)(满足概率分布性质)
2.3 激活函数的选择
-
隐藏层
-
优先选择RELU激活函数
-
如果ReLu效果不好,那么尝试其他激活,如Leaky ReLu等
-
如果使用了Relu, 需要注意避免出现大的梯度从而导致过多的神经元死亡
-
不要使用sigmoid激活函数,可以尝试使用tanh激活函数
-
-
输出层
-
二分类问题选择sigmoid激活函数
-
多分类问题选择softmax激活函数
-
3、🔰 初始化方法
在神经网络中,权重初始化是训练过程中至关重要的环节。合适的初始化可以避免梯度消失 / 爆炸问题,加速模型收敛;而不当的初始化可能导致训练停滞。以下是常用的初始化方法介绍。
3.1 随机初始化(Random Initialization)
定义:
随机初始化是最基础的方法,通过从特定分布中随机采样来初始化权重。早期常用均匀分布或正态分布,但需要手动调整分布范围。
-
均匀分布:权重从区间 [-a, a] 中随机采样,其中 a 是超参数(通常取较小值,如 0.01):
-
正态分布:权重从均值为 0、方差为 (
) 的正态分布中采样,(
) 通常取 0.01:
适用场景:
适用于简单网络或作为其他复杂初始化的基础,但需要谨慎调整范围(过大会导致激活值饱和,过小会导致梯度消失)。
import torch
import torch.nn as nn
# 定义一个线性层(输入维度10,输出维度5)
linear = nn.Linear(10, 5)
# 均匀分布初始化(范围[-0.01, 0.01])
nn.init.uniform_(linear.weight, a=-0.01, b=0.01)
# 正态分布初始化(均值0,方差0.0001即σ=0.01)
nn.init.normal_(linear.weight, mean=0.0, std=0.01)3.2 Xavier 初始化(Glorot 初始化)
定义:
Xavier 初始化(由 Glorot 等人提出)针对 sigmoid、tanh 等对称激活函数设计,核心思想是使前向传播的输入信号方差和反向传播的梯度方差在层间保持一致。
假设第 层有
个输入神经元和
个输出神经元:
-
均匀分布版本:
推导:
为了满足方差一致性条件,需要:
(推导略)
均匀分布
的方差为:
因此,
-
正态分布版本:
适用场景:
适用于激活函数为 sigmoid、tanh 的网络(这些函数在 0 附近近似线性,且对称)
import torch
import torch.nn as nn
# Xavier均匀分布初始化
nn.init.xavier_uniform_(linear.weight, gain=1.0) # gain为缩放因子,默认1.0
# Xavier正态分布初始化
nn.init.xavier_normal_(linear.weight, gain=1.0)3.3 He 初始化(Kaiming 初始化)
He 初始化(由 Kaiming He 等人提出)针对 ReLU 及其变种(如 Leaky ReLU)设计。由于 ReLU 会将负数输入置零(约 50% 的神经元可能不激活),He 初始化通过调整方差补偿这种信息损失。
定义:
仅考虑输入神经元数量 (不考虑输出):
-
均匀分布版本:
-
正态分布版本:
适用场景:
适用于激活函数为 ReLU、Leaky ReLU 的网络(当前深度学习中最常用的初始化方法之一)。
import torch
import torch.nn as nn
# He均匀分布初始化
nn.init.kaiming_uniform_(linear.weight, mode='fan_in', nonlinearity='relu')
# He正态分布初始化
nn.init.kaiming_normal_(linear.weight, mode='fan_in', nonlinearity='relu')
# mode='fan_in':仅考虑输入神经元数量(默认,更安全)
# mode='fan_out':考虑输出神经元数量
# nonlinearity:指定激活函数(如 relu、leaky_relu)3.4 常数初始化(Constant Initialization)
将权重初始化为固定常数(如 0 或 1),但实际中很少单独使用。
-
全零初始化会导致 “对称权重问题”:所有神经元学习到相同的特征,网络等效于单个神经元,失去表达能力。
-
通常仅用于偏置项(bias)初始化(如偏置初始化为 0)
import torch
import torch.nn as nn
# 权重初始化为1.0
nn.init.constant_(linear.weight, val=1.0)
# 偏置初始化为0(PyTorch线性层默认偏置为0)
nn.init.constant_(linear.bias, val=0.0)3.5 正交初始化(Orthogonal Initialization)
将权重矩阵初始化为正交矩阵(满足 ),目的是保持输入信号的范数在层间传递时不变,减少梯度爆炸风险。
数学原理:
通过对随机矩阵进行 SVD 分解,取左奇异矩阵作为权重(确保正交性)。
适用场景:
常用于循环神经网络(RNN、LSTM、GRU),缓解其训练中的梯度不稳定问题。
import torch
import torch.nn as nn
# 正交初始化(gain为缩放因子,对ReLU通常设为√2)
nn.init.orthogonal_(linear.weight, gain=1.0) # 对ReLU: gain=math.sqrt(2)总结
| 初始化方法 | 核心思想 | 适用激活函数 | 典型场景 |
|---|---|---|---|
| 随机初始化 | 简单随机采样 | 通用(需调参) | 简单网络 |
| Xavier 初始化 | 保持信号和梯度方差一致 | sigmoid、tanh | 传统深度网络 |
| He 初始化 | 补偿 ReLU 的信息损失 | ReLU、Leaky ReLU | 现代 CNN、Transformer |
| 常数初始化 | 固定值(如 0) | 仅偏置项 | 偏置初始化 |
| 正交初始化 | 保持信号范数不变 | 任意(尤其 RNN) | 循环神经网络 |
实际应用中,He 初始化(配合 ReLU)是最常用的选择,PyTorch 等框架的默认初始化也常基于此设计。
4、⬇️ 损失函数
4.1 损失函数的概念
4.1.1 定义
损失函数(Loss Function),也称为成本函数(Cost Function)或目标函数(Objective Function),是衡量模型预测值 \hat{y} 与真实标签 y 之间差异的量化指标。它输出一个标量值(损失值),损失值越小表示模型预测效果越好,反之则越差。
4.1.2 核心作用
-
量化模型性能:提供客观指标评估模型在训练或验证过程中的表现
-
指导参数优化:通过计算损失函数对模型参数(权重和偏置)的梯度,为优化器(如 SGD、Adam)提供参数更新方向,是反向传播算法的基础
4.2 PyTorch 中损失函数的通用使用方式
在 PyTorch 中,所有损失函数都封装在torch.nn模块中,使用流程统一:
import torch
import torch.nn as nn
# 1. 实例化损失函数
loss_fn = nn.损失函数类(参数)
# 2. 计算损失(需要模型输出和真实标签)
y_pred = model(inputs) # 模型预测值
loss = loss_fn(y_pred, y_true) # 计算损失
# 3. 反向传播(清空梯度→计算梯度→更新参数)
optimizer.zero_grad() # 清空历史梯度
loss.backward() # 反向传播计算梯度
optimizer.step() # 优化器更新参数4.3 回归问题中的损失函数
4.3.1 均方误差(Mean Squared Error, MSE)
PyTorch 实现:nn.MSELoss
# 实例化MSE损失(默认计算均值)
mse_loss = nn.MSELoss(reduction='mean')
# 示例数据(batch_size=2, 输出维度=3)
y_true = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
y_pred = torch.tensor([[1.5, 2.5, 3.5], [4.5, 5.5, 6.5]])
# 计算损失
loss = mse_loss(y_pred, y_true)
print(loss) # 输出: tensor(0.2500)
# 计算过程:每个元素误差平方的均值 → ((0.5²×3) + (0.5²×3)) / (2×3) = 0.25-
对大误差(异常值)敏感(平方放大效应)
-
适用于大多数回归任务(如房价预测、数值预测)
-
数学性质好(连续可导,梯度计算简单)
4.3.2 平均绝对误差(Mean Absolute Error, MAE)
PyTorch 实现:nn.L1Loss
# 实例化L1损失(MAE)
l1_loss = nn.L1Loss(reduction='mean')
# 使用和之前MSE相同的示例数据
loss = l1_loss(y_pred, y_true)
print(loss) # 输出: tensor(0.5000)-
对异常值不敏感(绝对值特性)
-
梯度在零点不可导(可能影响优化效率)
-
适用于存在较多异常值的回归任务
4.3.3 平滑 L1 损失(Smooth L1 Loss)
其中
PyTorch实现:nn.SmoothL1Loss
# 实例化平滑L1损失
smooth_l1 = nn.SmoothL1Loss(reduction='mean', beta=1.0)
# 示例:包含大误差的情况
y_true = torch.tensor([[1.0], [2.0]])
y_pred = torch.tensor([[3.0], [5.0]]) # 误差分别为2.0和3.0
loss = smooth_l1(y_pred, y_true)
print(loss)
# 计算过程:( (2-0.5) + (3-0.5) ) / 2 = (1.5 + 2.5)/2 = 2.0-
beta:控制平滑区域的阈值(默认1.0),值越大平滑区域越大 -
结合MSE和MAE优点:小误差时用MSE(平滑可导),大误差时用MAE(抗异常值)
-
广泛用于目标检测边框回归(如Faster R-CNN、YOLO)
4.4 分类问题中的损失函数
4.4.1 二元交叉熵(Binary Cross-Entropy, BCE)
-
PyTorch实现1:
nn.BCELoss(需手动加sigmoid)
# 1. 定义模型输出层(无激活函数)
model_output = torch.tensor([[0.8], [0.3], [0.6]]) # logits
# 2. 手动应用sigmoid得到概率
y_pred = torch.sigmoid(model_output) # 输出: tensor([[0.6890], [0.5744], [0.6457]])
# 3. 真实标签(二分类标签为0或1)
y_true = torch.tensor([[1.0], [0.0], [1.0]])
# 4. 计算BCE损失
bce_loss = nn.BCELoss(reduction='mean')
loss = bce_loss(y_pred, y_true)
print(loss) # 输出: 约0.4545-
PyTorch实现2:
nn.BCEWithLogitsLoss(推荐)
内置sigmoid激活,数值稳定性更好(避免单独计算sigmoid可能的数值溢出):
# 直接使用模型输出的logits,无需手动sigmoid
bce_with_logits = nn.BCEWithLogitsLoss(reduction='mean')
loss = bce_with_logits(model_output, y_true) # 与上面结果一致-
适用场景
-
适用于二分类任务(输出为0或1,如垃圾邮件检测、疾病诊断),输出需经过sigmoid激活(确保输出在[0,1]区间表示概率)
-
多标签分类(如一张图片同时包含猫和狗,每个标签独立预测)
-
4.4.2 多分类交叉熵(Categorical Cross-Entropy)
-
PyTorch实现1:
nn.CrossEntropyLoss(推荐)
内置LogSoftmax操作,直接接收模型输出的logits,标签为类别索引(无需one-hot)
# 模型输出:(batch_size, num_classes),未经过softmax
logits = torch.tensor([[2.0, 1.0, 0.1], # 样本1
[0.5, 2.0, 0.3]]) # 样本2
# 真实标签:(batch_size,),每个元素是类别索引(0,1,2)
y_true = torch.tensor([0, 1])
# 计算交叉熵损失
ce_loss = nn.CrossEntropyLoss()
loss = ce_loss(logits, y_true)
print(loss) # 输出: 约0.4171-
PyTorch实现2:
nn.NLLLoss(需配合LogSoftmax)
# 1. 对模型输出应用LogSoftmax
log_softmax = nn.LogSoftmax(dim=1)
log_probs = log_softmax(logits) # 形状: (2,3)
# 2. 计算NLLLoss(负对数似然损失)
nll_loss = nn.NLLLoss()
loss = nll_loss(log_probs, y_true) # 与CrossEntropyLoss结果一致-
适用场景:适用于多分类任务(类别互斥,如MNIST手写数字识别、ImageNet图像分类),C 为类别数,y 通常为one-hot编码(仅一个类别为1,其余为0)
4.5 PyTorch损失函数使用技巧
4.5.1 优先使用内置 "带激活" 的损失函数(数值稳定性)
单独用sigmoid/softmax + 基础损失函数可能导致数值溢出(尤其是输入值过大时),内置组合损失函数用数学优化避免了这个问题
import torch
import torch.nn as nn
# 二分类任务:推荐用BCEWithLogitsLoss替代sigmoid+BCE
# 反例:不稳定的实现方式
def unstable_way():
logits = torch.tensor([100.0, -50.0]) # 大数值输入
y_pred = torch.sigmoid(logits) # 可能出现数值溢出
y_true = torch.tensor([1.0, 0.0])
loss_fn = nn.BCELoss()
return loss_fn(y_pred, y_true) # 可能返回nan或不准确值
# 正例:稳定的实现方式
def stable_way():
logits = torch.tensor([100.0, -50.0])
y_true = torch.tensor([1.0, 0.0])
loss_fn = nn.BCEWithLogitsLoss() # 内置sigmoid,数值更稳定
return loss_fn(logits, y_true) # 正确计算损失
print("不稳定方式:", unstable_way()) # 可能出错
print("稳定方式:", stable_way()) # 正常输出损失-
二分类:用
BCEWithLogitsLoss替代BCELoss -
多分类:用
CrossEntropyLoss替代LogSoftmax + NLLLoss
4.5.2 类别不平衡处理(权重调整)
当数据集中不同类别的样本数量差异大(如 1:100),模型会倾向于预测多数类,需要通过权重调整平衡损失。
# 假设3个类别,样本比例为 [100, 500, 2000](第0类最稀少)
# 计算权重:总样本数 / (类别数 × 该类样本数) → 使稀少类别权重更高
total_samples = 100 + 500 + 2000
class_weights = torch.tensor([
total_samples/(3*100), # 2600/(3*100) ≈ 8.67
total_samples/(3*500), # 2600/(3*500) ≈ 1.73
total_samples/(3*2000) # 2600/(3*2000) ≈ 0.43
])
# 多分类场景:在CrossEntropyLoss中应用权重
loss_fn = nn.CrossEntropyLoss(weight=class_weights)
# 测试数据
logits = torch.randn(4, 3) # 4个样本,3类输出
labels = torch.tensor([0, 0, 1, 2]) # 包含稀少类别0
loss = loss_fn(logits, labels)
print("加权损失:", loss)二分类可用 pos_weight
# 正样本权重设为5.0(适用于正样本少的场景)
loss_fn = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([5.0]))4.5.3 灵活使用 reduction 参数(损失聚合方式)
默认的reduction='mean'在某些场景下不适用(如需要对不同样本赋予不同权重,或分析单样本损失)
# 1. 查看每个样本的损失(用于分析错误样本)
loss_fn = nn.CrossEntropyLoss(reduction='none')
logits = torch.randn(3, 5) # 3个样本,5类
labels = torch.tensor([2, 0, 3])
sample_losses = loss_fn(logits, labels)
print("单样本损失:", sample_losses) # 输出形状: [3]
# 2. 自定义样本权重(如对重要样本加大权重)
sample_weights = torch.tensor([2.0, 1.0, 3.0]) # 样本权重
weighted_loss = (sample_losses * sample_weights).mean()
print("加权后总损失:", weighted_loss)
# 3. 仅求和(用于需要手动控制归一化的场景)
loss_fn_sum = nn.MSELoss(reduction='sum')-
reduction='none':获取单样本损失,用于难例挖掘、可视化错误分布 -
结合样本权重:实现对特定样本(如标注可靠的样本)的侧重
4.5.4 标签平滑(Label Smoothing)提升泛化能力
硬标签(one-hot 编码)可能导致模型过拟合(过度自信),标签平滑通过软化标签缓解这个问题。
# 多分类标签平滑(PyTorch 1.10+支持)
loss_fn = nn.CrossEntropyLoss(label_smoothing=0.1) # 平滑系数ε=0.1
# 原理:将真实标签从1.0软化到1-ε,其他类别分配ε/(C-1)
# 例如3分类中,真实标签1会变成 [0.05, 0.9, 0.05](ε=0.1)
# 测试
logits = torch.randn(2, 3)
labels = torch.tensor([1, 0]) # 原始硬标签
loss = loss_fn(logits, labels)
print("标签平滑后的损失:", loss)-
图像分类(如 ResNet 训练常用 \epsilon=0.1)
-
样本量有限、容易过拟合的任务
-
不适用:需要精确预测概率的场景(如风险评估)
5、🔔 参数优化方法
参数优化是神经网络训练的核心环节,其目标是通过调整网络参数(权重(W)和偏置(b))最小化损失函数(L)。梯度下降法是最基础的优化框架,而其变体及高级优化器则通过改进收敛速度、稳定性和泛化能力解决实际问题。以下详细介绍各类参数优化方法:
5.1 梯度下降法(Gradient Descent, GD)
详见我的这篇文章:【机器学习】——回归1:线性回归_机器学习线性回归-CSDN博客
5.2 改进的优化器(解决 SGD 的缺陷)
SGD 存在收敛慢、对学习率敏感、易在鞍点或局部最优停滞等问题。以下优化器通过引入动量、自适应学习率等机制改进:
5.2.1 动量法(Momentum)
-
核心思想:模拟物理中的 “惯性”,累积历史梯度的 “动量”,加速收敛并减少震荡。
例如:小球下坡时,不仅受当前坡度(梯度)影响,还受之前的运动趋势(动量)影响。
-
公式:
是待优化参数
是损失函数对待优化参数的梯度,
(或写成
) 是当前批次的梯度
是
时刻的动量(速度)
是动量因子(通常取 0.9,控制历史梯度的衰减)
是学习率(步长),控制参数更新的幅度
-
优点:加速收敛(沿正确方向累积动量);减少震荡(抑制垂直于收敛方向的噪声)
-
缺点:
和
需手动调参
5.2.2 牛顿动量(Nesterov Momentum)
-
改进点:Momentum 先更新动量再计算梯度,而 Nesterov 先 “预判” 下一步位置,再基于新位置计算梯度,增强收敛的前瞻性。
-
公式:
-
优点:在梯度方向变化较大时,能更快调整方向,收敛更稳定。
5.2.3 Adagrad(自适应梯度算法)
-
核心思想:为不同参数分配不同的学习率—— 频繁更新的参数(如高频特征)用较小的学习率,稀疏更新的参数(如低频特征)用较大的学习率,适合稀疏数据(如文本)。
-
公式:
(累积梯度平方和)
其中:
是参数梯度平方的累积和
是小常数(如
),避免分母为 0
-
优点:无需手动调整学习率;适合稀疏数据(如自然语言处理)。
-
缺点:
随迭代累积逐渐增大,导致学习率不断减小,最终可能趋于 0,训练提前停滞。
5.2.4 RMSprop(Root Mean Square Propagation)
-
核心思想:改进 Adagrad 的 “学习率衰减过快” 问题,用指数移动平均替代梯度平方的累积和,使学习率更稳定。
-
公式:
(指数移动平均)
(0.9 和 0.1 是经验系数,控制历史梯度的权重)
-
优点:避免学习率过快衰减,收敛更稳定;适合非平稳目标(如递归神经网络)。
5.2.5 Adam(Adaptive Moment Estimation)
-
核心思想:结合 Momentum(动量)和 RMSprop(自适应学习率)的优点,是目前最常用的优化器之一。
-
公式:
默认超参数:(动量因子),
(二阶动量因子),
-
计算一阶动量(动量项,类似 Momentum):
-
计算二阶动量(自适应学习率项,类似 RMSprop):
3. 偏差修正(解决初始时刻 ,
接近 0 的问题):
4. 参数更新:
-
优点:收敛快,稳定性好;对超参数(学习率)不敏感,无需精细调参;适用于大多数场景(图像、文本、语音等)。
-
缺点:在某些任务(如生成对抗网络)中,可能不如 SGD 泛化能力强。
5.2.6 其他优化器
-
Adadelta:Adagrad 的变体,无需手动设置学习率,通过历史更新幅度自适应调整,适合长周期训练。
-
Nadam:结合 Nesterov 动量和 Adam,增强对梯度变化的敏感性,收敛更快。
-
RAdam:解决 Adam 在训练初期因二阶动量估计不准确导致的波动问题,稳定性更好。
5.3 优化器对比与选择建议
| 优化器 | 核心特点 | 适用场景 | 调参难度 | 收敛速度 | 泛化能力 |
|---|---|---|---|---|---|
| SGD | 基础方法,无自适应机制 | 数据量大、需要精细调优的场景(如 CNN) | 高(需调学习率 + 动量) | 慢 | 较好 |
| Momentum | 引入惯性,减少震荡 | 替代 SGD,加速收敛 | 中(调 |
中 | 较好 |
| Adagrad | 自适应学习率,适合稀疏数据 | 文本分类、推荐系统(稀疏特征) | 低 | 中 | 一般 |
| RMSprop | 改进 Adagrad,学习率更稳定 | RNN、LSTM 等时序模型 | 低 | 中快 | 一般 |
| Adam | 结合动量与自适应学习率 | 绝大多数场景(默认选择) | 低 | 快 | 中 |
选择建议:
-
新手入门:优先使用 Adam(无需复杂调参,效果稳定)。
-
追求泛化能力:尝试 SGD+Momentum(配合学习率衰减策略,如余弦退火)。
-
稀疏数据场景:Adagrad 或 RMSprop。
-
精细调优:对比 Adam 和 SGD,根据验证集性能选择。
5.4 学习率调度(Learning Rate Scheduling)
学习率()是最重要的超参数之一,固定学习率可能导致收敛慢或过冲。常用调度策略:
-
分段衰减:训练到一定 epoch 后按比例减小学习率(如每 10 轮乘以 0.1)。
-
指数衰减:(
)((
-
余弦退火:学习率随 epoch 按余弦函数周期性变化,避免陷入局部最优。
-
自适应调度(如 ReduceLROnPlateau):当验证集损失停滞时自动减小学习率。
总结:参数优化的核心是 “高效利用梯度信息”,从基础的梯度下降到高级的 Adam,优化器的发展趋势是自适应化、稳定化和快速收敛。实际应用中需结合数据特点、模型结构和任务需求选择合适的优化器及超参数。
6、🔎 正则化方法
在神经网络训练中,过拟合是常见的挑战 。正则化(Regularization) 是一类通过限制模型复杂度、引导模型学习更稳健模式来缓解过拟合的技术。以下是神经网络中常用的正则化方法:
6.1 L1/L2 正则化(权重正则化)
L1 和 L2 正则化是最经典的正则化方法,通过在损失函数中添加权重参数的惩罚项,限制权重的绝对值或平方和,避免模型过度依赖某些特征。
6.1.1 L2 正则化(权重衰减,Weight Decay)
-
定义:在损失函数中加入权重参数平方和的惩罚项,是实践中最常用的正则化方法。
-
原理:
-
原始损失函数为
(
为模型参数,如权重 W 和偏置 b)
-
L2 正则化后的损失为:
其中
为正则化系数(超参数,需调优),控制惩罚强度。
-
L2 会 “压制” 权重的绝对值,使权重分布更均匀(避免某些权重过大),模型更倾向于学习简单的、泛化性强的模式。
-
-
PyTorch 实现: PyTorch 中通过优化器的
weight_decay参数直接支持 L2 正则化(无需手动修改损失函数),默认对所有可学习参数(权重和偏置)生效(通常偏置不正则化,可手动排除)。import torch import torch.nn as nn import torch.optim as optim # 定义简单模型 class SimpleModel(nn.Module): def __init__(self): super().__init__() self.fc = nn.Linear(10, 2) # 输入10维,输出2维 def forward(self, x): return self.fc(x) model = SimpleModel() criterion = nn.CrossEntropyLoss() # 分类损失 # 优化器设置weight_decay(L2正则化系数) optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4) # λ=1e-4 # 训练过程(简化) x = torch.randn(32, 10) # 32个样本,10维特征 y = torch.randint(0, 2, (32,)) # 标签 pred = model(x) loss = criterion(pred, y) # 原始损失 optimizer.zero_grad() loss.backward() # 自动包含L2惩罚的梯度 optimizer.step() -
适用场景:几乎所有神经网络(全连接、卷积、Transformer 等),尤其当模型参数较多、易过拟合时。
6.1.2 L1 正则化
定义:在损失函数中加入权重参数绝对值之和的惩罚项。
-
原理:
-
正则化后的损失为:
-
L1 会使部分权重变为 0(稀疏性),相当于自动 “剔除” 不重要的特征,实现特征选择。
-
-
PyTorch 实现: PyTorch 优化器不直接支持 L1 正则化,需手动在损失中添加惩罚项:
# 定义L1惩罚项(仅对权重,忽略偏置) def l1_regularization(model, lambda_l1=1e-4): l1_loss = 0.0 for param in model.parameters(): if param.dim() > 1: # 假设权重是2D及以上,偏置是1D l1_loss += torch.norm(param, 1) # L1范数 return lambda_l1 * l1_loss # 训练时的总损失 pred = model(x) ce_loss = criterion(pred, y) # 交叉熵损失 l1_loss = l1_regularization(model) # L1惩罚 total_loss = ce_loss + l1_loss # 总损失 optimizer.zero_grad() total_loss.backward() optimizer.step() -
适用场景:需要特征选择的任务(如高维输入数据),但优化难度高于 L2(L1 损失在 0 点不可导),实际中不如 L2 常用。
6.2 Dropout
Dropout 是 Hinton 团队提出的针对神经网络的专用正则化方法,通过随机丢弃部分神经元,强制模型学习更鲁棒的特征(不依赖特定神经元)。
-
原理
-
训练阶段:对某一层的神经元,以概率 p(通常 0.5)随机将其输出设为 0(“丢弃”),其余神经元输出乘以 1/(1-p)(保持期望不变)。 例如:若某层有 4 个神经元,输出为 ([a, b, c, d]),Dropout 概率 (p=0.5),可能随机丢弃第 2 和第 4 个神经元,输出变为 ([2a, 0, 2c, 0])(乘以 (1/(1-0.5)=2))。
-
验证阶段:不丢弃神经元,所有神经元正常输出(无需缩放,因训练时已通过缩放保持期望)。
直观来说,Dropout 使模型在训练时 “随机瘦身”,避免对特定神经元的依赖,相当于同时训练多个子模型,最终集成它们的效果。
-
-
PyTorch 实现
通过 nn.Dropout 层实现,注意训练和验证时的模式切换(model.train() 和 model.eval()):
class DropoutModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 100)
self.dropout = nn.Dropout(p=0.5) # 丢弃概率50%
self.fc2 = nn.Linear(100, 2)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.dropout(x) # 训练时生效,推理时关闭
x = self.fc2(x)
return x
model = DropoutModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模式(开启Dropout)
model.train()
x_train = torch.randn(32, 10)
y_train = torch.randint(0, 2, (32,))
pred = model(x_train)
loss = criterion(pred, y_train)
loss.backward()
optimizer.step()
# 推理模式(关闭Dropout)
model.eval()
with torch.no_grad(): # 关闭梯度计算
x_test = torch.randn(10, 10)
pred_test = model(x_test) # 无丢弃-
适用场景
-
全连接层(效果显著)、卷积层(可使用,但需较小的丢弃概率,如 0.1-0.3)。
-
不建议用于循环神经网络(RNN),可改用专门的
nn.Dropout2d(空间维度丢弃)或nn.AlphaDropout(保持均值和方差,适合自归一化网络)。
-
6.3 早停(Early Stopping)
早停是一种 “朴素” 但高效的正则化方法,通过监控验证集性能,在模型开始过拟合前停止训练,避免模型过度学习训练数据的噪声。
-
原理
-
训练过程中,模型在训练集上的损失会持续下降,但验证集损失会先下降后上升(过拟合的标志)。
-
早停的核心是:当验证集损失连续若干个 epoch(如 5-10 次)不再下降时,停止训练,并保存此时的模型参数(验证集性能最优的状态)。
-
-
PyTorch 实现
需手动记录验证集损失,判断是否停止:
model = SimpleModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 早停参数
patience = 5 # 最多容忍5个epoch无改进
best_val_loss = float('inf')
counter = 0 # 记录无改进的epoch数
# 假设已划分训练集和验证集
for epoch in range(100):
# 训练
model.train()
train_pred = model(train_x)
train_loss = criterion(train_pred, train_y)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
# 验证
model.eval()
with torch.no_grad():
val_pred = model(val_x)
val_loss = criterion(val_pred, val_y)
# 早停判断
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model.state_dict() # 保存最优模型
counter = 0 # 重置计数器
else:
counter += 1
if counter >= patience:
print(f"早停于第{epoch}轮")
break
# 加载最优模型
model.load_state_dict(best_model)-
适用场景
所有神经网络训练,尤其当训练数据有限、模型复杂度高时(如深层 CNN、Transformer)。需注意:验证集的划分需合理(与训练集独立同分布),否则可能导致早停失效。
6.4 数据增强(Data Augmentation)
数据增强是从数据层面缓解过拟合的方法,通过对训练数据进行随机变换(如旋转、裁剪、加噪等),生成 “新样本”,扩大训练集规模,迫使模型学习更通用的特征。
-
原理
-
变换后的样本保留原始数据的核心特征(如猫的图像旋转后仍是猫),但细节不同(如角度、位置)。
-
模型在多样化的样本上训练,能减少对特定细节(如训练集中猫的位置)的依赖,提高泛化能力。
-
-
PyTorch 实现
通过 torchvision.transforms 实现(以图像为例):
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
# 定义数据增强变换(仅用于训练集)
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪并缩放至224x224
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转
transforms.RandomRotation(15), # 随机旋转±15度
transforms.ColorJitter(brightness=0.2), # 随机调整亮度
transforms.ToTensor(), # 转为Tensor
])
# 验证集不增强(保持原始分布)
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
# 自定义数据集(假设已实现)
train_dataset = CustomDataset(data_dir, transform=train_transform)
val_dataset = CustomDataset(data_dir, transform=val_transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)-
适用场景
-
图像任务(最常用):通过裁剪、翻转、色彩变换等增强。
-
文本任务:通过同义词替换、随机插入 / 删除单词、回译等增强。
-
语音任务:通过加噪、语速调整、音调变换等增强。 数据增强的关键是变换需保留标签信息(如猫的图像旋转后标签仍是 “猫”)。
-
6.5 批量归一化(Batch Normalization, BN)
BN 主要用于加速神经网络训练(缓解梯度消失 / 爆炸),但同时具有一定正则化效果,可辅助缓解过拟合。
-
原理
-
训练时,对每一层的输入按批次标准化(减去均值、除以标准差),并引入可学习的缩放和平移参数。
-
正则化效果来源:批次内的随机噪声(不同批次的均值 / 标准差不同)会给模型带来微小扰动,类似 Dropout 的 “随机性”,迫使模型更稳健。
-
-
PyTorch 实现
class BNModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 100)
self.bn = nn.BatchNorm1d(100) # 对100维特征做BN
self.fc2 = nn.Linear(100, 2)
def forward(self, x):
x = self.fc1(x)
x = self.bn(x) # 应用BN
x = torch.relu(x)
x = self.fc2(x)
return x-
适用场景
几乎所有深度神经网络(CNN、全连接网络等),尤其深层模型。注意:BN 的正则化效果较弱,通常需与 Dropout、早停等配合使用。
6.6 其他正则化方法
-
标签平滑(Label Smoothing): 软化分类任务的 one-hot 标签(如将标签 “1” 改为 “0.9”,其他类别改为 “0.1/(C-1)”,C 为类别数),避免模型对预测过于自信,减少过拟合。 PyTorch 实现:
nn.CrossEntropyLoss(label_smoothing=0.1)(PyTorch 1.10 + 支持)。 -
模型集成(Ensemble): 训练多个不同的模型(如不同初始化、不同架构),通过投票或平均输出得到最终结果。集成方法能显著提高泛化能力,但计算成本高。 示例:训练 3 个不同的 CNN,推理时取预测概率的平均值。
-
权重剪枝(Weight Pruning): 移除神经网络中绝对值较小的权重(认为其对模型贡献小),简化模型结构,减少过拟合。PyTorch 可通过
torch.nn.utils.prune模块实现。
总结
正则化方法的核心是 “限制模型复杂度” 或 “增加数据多样性”,实际应用中通常组合多种方法(如 L2 正则化 + Dropout + 早停 + 数据增强)以达到最佳效果。选择时需结合任务类型(分类 / 回归)、数据规模(小数据更依赖数据增强和早停)、模型结构(深层模型需更多正则化)等因素综合考虑。
7、↩️ BP(Back Propagation)神经网络
7.1 BP神经网络的结构
BP神经网络同样使用基础神经网络架构(感知机或多层感知机),用梯度下降法更新参数并运用反向传播方法。其核心流程如下:
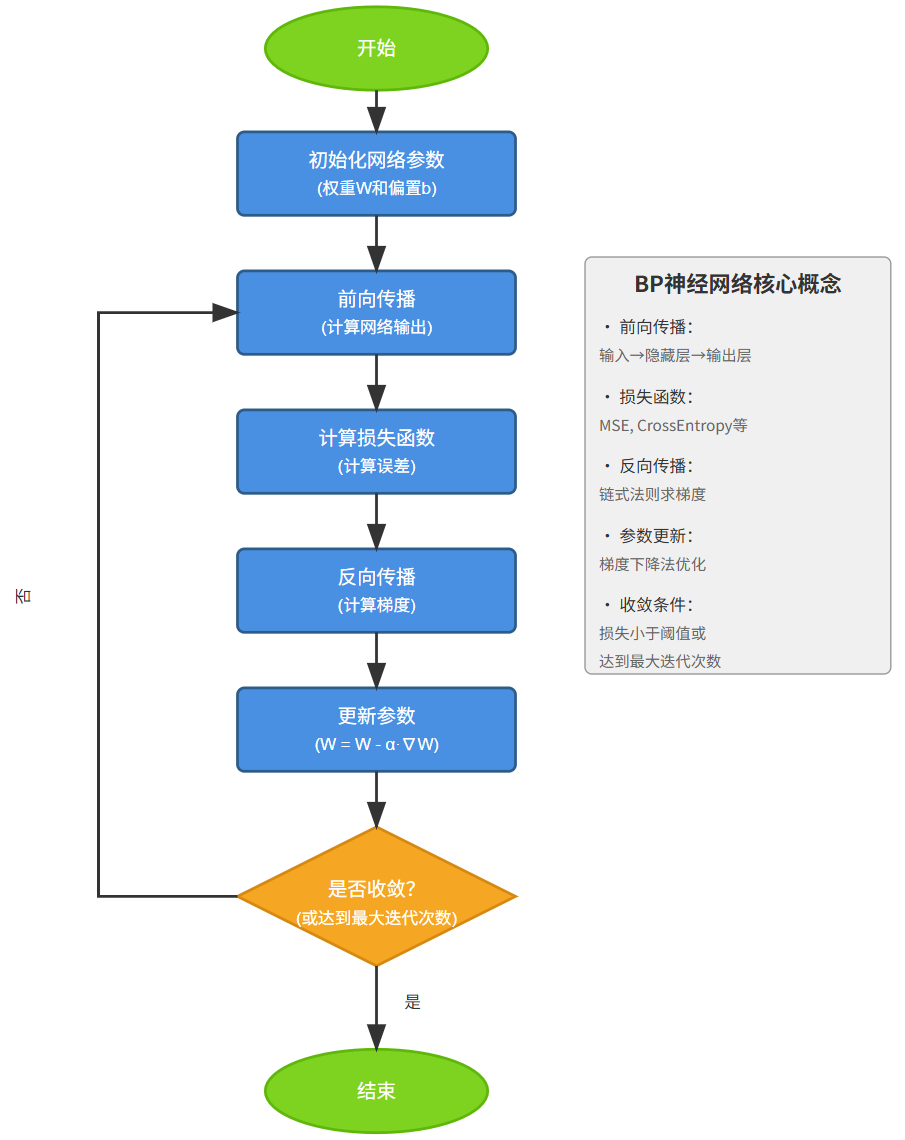
7.2 反向传播算法的推导
反向传播算法其实就是链式求导法则的应用。
我们先确定神经网络的目标函数,然后用随机梯度下降优化算法去求目标函数最小值时的参数值。
取网络所有输出层节点的误差平方和作为目标函数:
其中, 表示是样本
的误差。
是输出向量
的一个元素。
然后,我们用随机梯度下降算法对目标函数进行优化:
随机梯度下降算法也就是需要求出误差 对于每个权重
的偏导数(也就是梯度),怎么求呢?
观察上图,我们发现权重 仅能通过影响节点
的输入值影响网络的其它部分,设
是节点
的加权输入,即
是
的函数,而
是
的函数。根据链式求导法则,可以得到:
上式中, 是节点 i 传递给节点 j 的输入值,也就是节点 i 的输出值。
对于 的推导,需要区分输出层和隐藏层两种情况。
输出层权值训练
对于输出层来说, 仅能通过节点 j 的输出值
(由于是输出层,所以不是向量) 来影响网络其它部分,也就是说
是
的函数,而
是
的函数,其中
。所以我们可以再次使用链式求导法则:
上式第一项:
上式第二项:(涉及到sigmoid函数求导,这里直接用结论)
将第一项和第二项带入,得到:
如果令 ,也就是一个节点的误差项
是网络误差对这个节点输入的偏导数的相反数。带入上式,得到:
将上述推导带入随机梯度下降公式,得到:
隐藏层权值训练(通过下一层的误差反向传播)
现在我们要推导出隐藏层的 。
首先,我们需要定义节点 j 的所有直接下游节点的集合 。
只能通过影响
再影响
。设
是节点 j 的下游节点的输入,则
是
的函数,而
是
的函数。因为
有多个,
。 我们应用全导数公式,可以做出如下推导:
因为 ,带入上式得到:
8、📉 RBF神经网络
8.1 RBF神经网络的原理
8.1.1 RBF函数
径向基函数(RBF)是一类以输入向量与中心点之间的距离为变量的函数。常用的RBF函数包括:
-
高斯函数(Gaussian Function)
其中,
是输入向量
与中心点
之间的欧几里得距离,
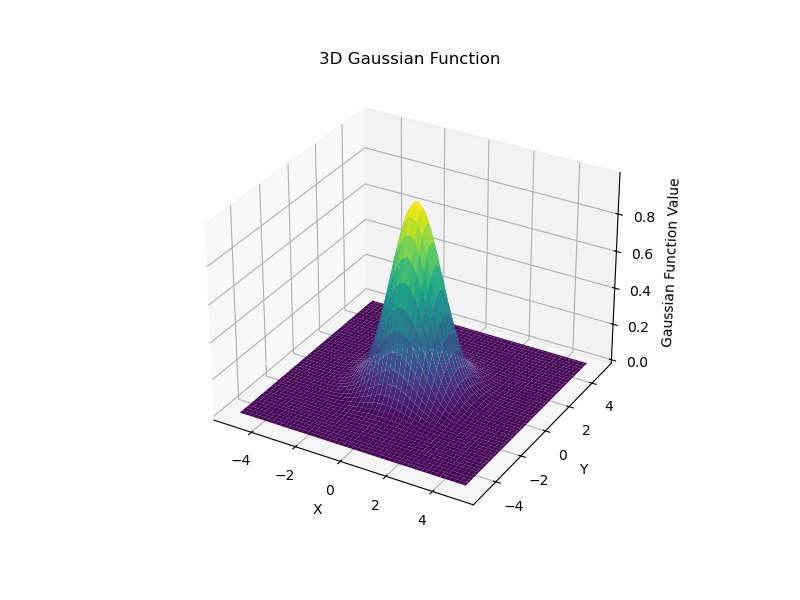
-
多项式函数(Polynomial Function)
其中, d 是多项式的次数,
-
薄板样条函数(Thin Plate Spline Function)
适用于二维和三维数据的插值。
-
逆多二次函数(Inverse Multiquadric Function)
其中,
-
多二次函数(Multiquadric Function)
其中,
8.1.2 RBF神经网络拟合原理
RBF神经网络是一种以RBF为激活函数的神经网络,可用于回归问题,即数值预测。
RBF神经网络解决回归问题的思路如下:
由于RBF函数只对其中心部分有较大影响,而不怎么影响其它地方,RBF神经网络利用RFB函数的这种局部性,在每个局部都用一个RBF去拟合目标。最终凑合多个RBF函数,就可得到一条可以拟合全局所有样本数据点的平滑曲线:
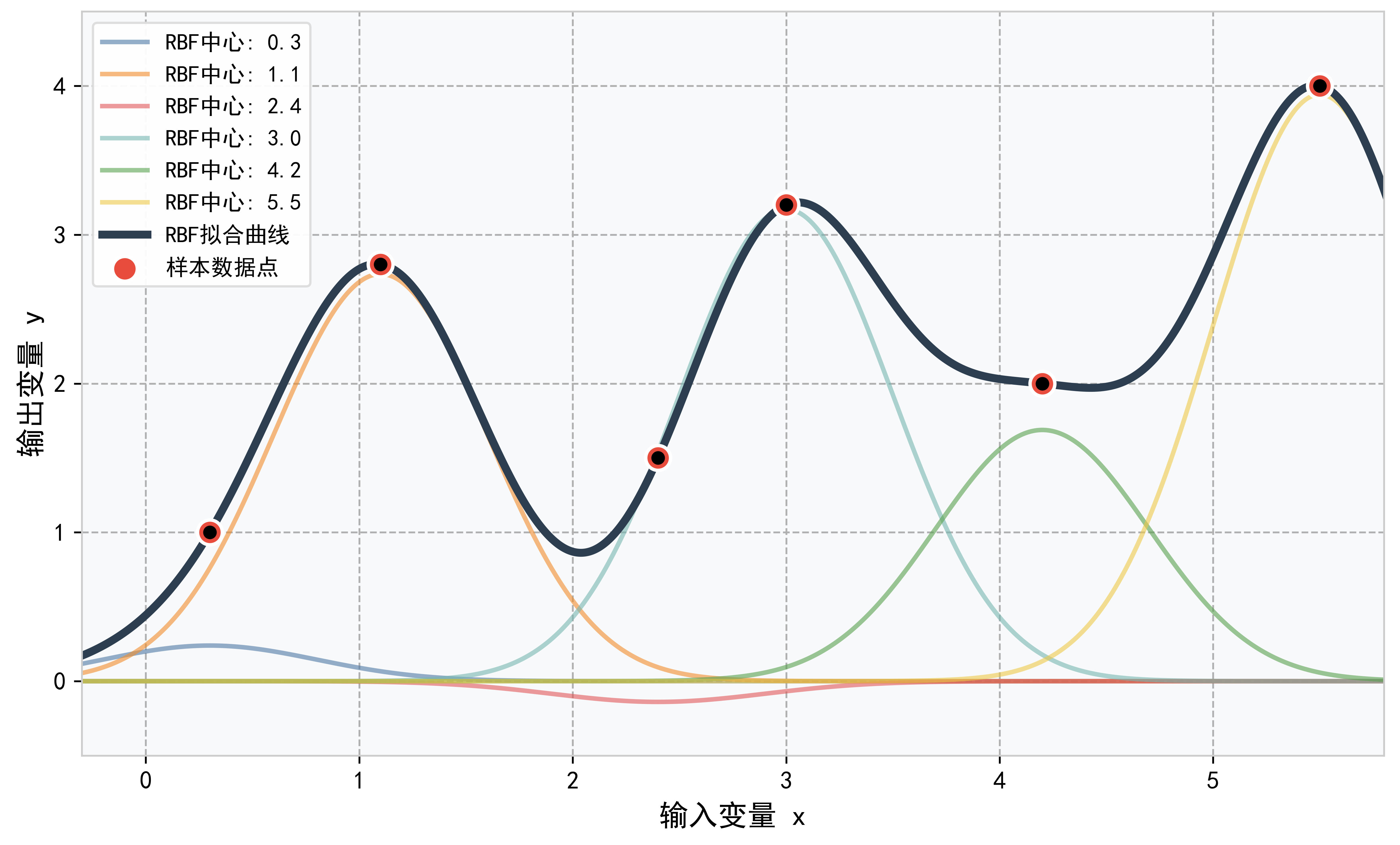
如图所示,RBF神经网络以各个样本数据点为中心,来生成多个RFB径向基曲线。然后通过叠加所有RBF曲线,就可得到一条能够光滑拟合各个样本数据点的曲线。总的来说,RBF神经网络的原理就是每个局部都用一个RBF函数去拟合,最终达到全局拟合。
8.2 RBF神经网络的模型结构与表达式
以一个2输入、3个隐节点、1个输出的RBF神经网络为例:
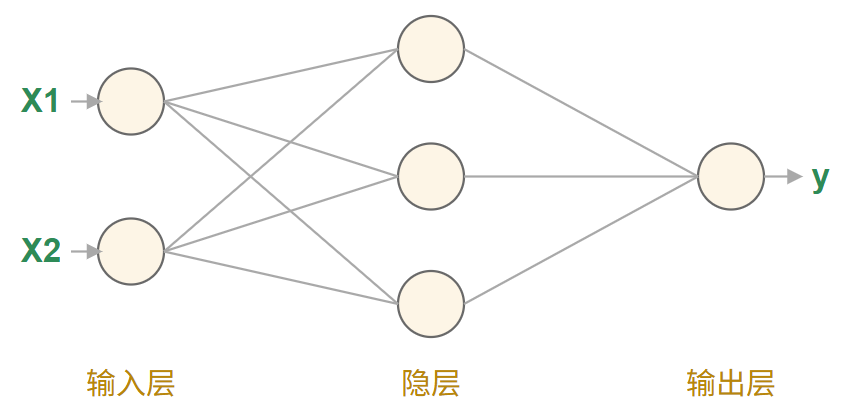
结构说明:
-
输入层:2个节点
-
隐层:3个径向基函数节点
-
输出层:1个线性组合节点
-
连接:
-
输入层到隐层:全连接(每个输入连接到所有隐节点)
-
隐层到输出层:全连接(每个隐节点连接到输出节点)
-
RBF网络的输出由隐层激活函数的线性组合构成:
其中:
-
:输入向量
-
:第 i 个隐节点的径向基函数(通常为高斯函数)
-
-
:隐节点 i 到输出的权重
高斯径向基函数表达式:
其中:
-
:第 i 个隐节点的中心向量
-
:第 i 个隐节点的宽度参数
-
:欧氏距离平方
完整输出公式展开
-
输入传播:输入向量
传递到所有隐节点
-
隐层激活:每个隐节点计算输入与中心的距离,并通过高斯函数输出激活值
-
输出计算:隐层输出加权求和(含偏置)得到最终输出
注:实际应用中,中心
和宽度
8.3 RBF神经网络训练与实现
RBF神经网络的训练就是求解 w 和 b,使得最终模型的输出与真实 y 值一致。
| 方法 | 中心选择策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 插值求解 | 所有训练样本 | 精确拟合训练数据 | 易过拟合,计算量大 | 小规模数据,精确插值 |
| OLS求解法 | 逐步选择重要样本 | 自动选择中心,避免过拟合 | 计算复杂度高 | 中等规模数据,泛化要求高 |
| K-means聚类法 | 聚类中心 | 计算效率高,适合大数据 | 中心选择可能不够精确 | 大规模数据,实时应用 |
import numpy as np
import matplotlib.pyplot as plt
from scipy.linalg import pinv
from sklearn.cluster import KMeans
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 生成数据集
def generate_data(n_samples=200, noise=0.1):
np.random.seed(42)
x1 = np.linspace(0, 2*np.pi, n_samples)
x2 = np.random.uniform(0, 1, n_samples)
X = np.column_stack((x1, x2))
y = np.sin(x1) + 0.1*x2 + np.random.normal(0, noise, n_samples)
return X, y
# 高斯径向基函数
def gaussian_rbf(x, center, sigma):
return np.exp(-np.linalg.norm(x - center)**2 / (2 * sigma**2))
# 方法1: 插值求解 (对应MATLAB的newrbe)
class RBF_Interpolation:
def __init__(self):
self.centers = None
self.sigma = None
self.weights = None
def fit(self, X, y):
# 使用所有训练样本作为中心
self.centers = X.copy()
n_samples = X.shape[0]
# 计算全局宽度 (平均距离的倍数)
dists = []
for i in range(n_samples):
for j in range(i+1, n_samples):
dists.append(np.linalg.norm(X[i] - X[j]))
self.sigma = np.mean(dists) * 1.0
# 构建设计矩阵
G = np.zeros((n_samples, n_samples))
for i in range(n_samples):
for j in range(n_samples):
G[i, j] = gaussian_rbf(X[i], self.centers[j], self.sigma)
# 添加偏置项
G = np.column_stack([G, np.ones(n_samples)])
# 求解权重 (使用伪逆避免奇异矩阵)
self.weights = pinv(G) @ y
def predict(self, X):
n_samples = X.shape[0]
n_centers = self.centers.shape[0]
G = np.zeros((n_samples, n_centers))
for i in range(n_samples):
for j in range(n_centers):
G[i, j] = gaussian_rbf(X[i], self.centers[j], self.sigma)
# 添加偏置项
G = np.column_stack([G, np.ones(n_samples)])
return G @ self.weights
# 方法2: OLS求解法 (对应MATLAB的newrb)
class RBF_OLS:
def __init__(self, max_centers=20, tolerance=0.01):
self.max_centers = max_centers
self.tolerance = tolerance
self.centers = None
self.sigmas = None
self.weights = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.centers = []
self.sigmas = []
# 初始误差
error = y.copy()
selected_indices = []
# 逐步选择中心
for _ in range(self.max_centers):
# 计算所有候选中心的误差减少量
errors_reduction = []
for i in range(n_samples):
if i in selected_indices:
errors_reduction.append(-np.inf)
continue
# 计算当前候选中心对所有样本的RBF输出
rbf_output = np.array([gaussian_rbf(X[j], X[i], 1.0) for j in range(n_samples)])
# 计算误差减少量 (投影误差)
reduction = np.dot(rbf_output, error)**2 / np.dot(rbf_output, rbf_output)
errors_reduction.append(reduction)
# 选择误差减少量最大的中心
best_idx = np.argmax(errors_reduction)
best_reduction = errors_reduction[best_idx]
# 如果误差减少量小于容忍度,停止
if best_reduction < self.tolerance:
break
selected_indices.append(best_idx)
self.centers.append(X[best_idx])
# 计算当前中心对所有样本的RBF输出
rbf_output = np.array([gaussian_rbf(X[j], X[best_idx], 1.0) for j in range(n_samples)])
# 更新误差 (正交化)
error = error - (np.dot(rbf_output, error) / np.dot(rbf_output, rbf_output)) * rbf_output
# 转换为numpy数组
self.centers = np.array(self.centers)
n_centers = len(self.centers)
# 计算每个中心的宽度 (最近邻距离的平均值)
for i in range(n_centers):
dists = [np.linalg.norm(self.centers[i] - self.centers[j])
for j in range(n_centers) if i != j]
self.sigmas.append(np.mean(dists) * 1.0)
self.sigmas = np.array(self.sigmas)
# 构建设计矩阵
G = np.zeros((n_samples, n_centers))
for i in range(n_samples):
for j in range(n_centers):
G[i, j] = gaussian_rbf(X[i], self.centers[j], self.sigmas[j])
# 添加偏置项
G = np.column_stack([G, np.ones(n_samples)])
# 求解权重
self.weights = pinv(G) @ y
def predict(self, X):
n_samples = X.shape[0]
n_centers = len(self.centers)
G = np.zeros((n_samples, n_centers))
for i in range(n_samples):
for j in range(n_centers):
G[i, j] = gaussian_rbf(X[i], self.centers[j], self.sigmas[j])
# 添加偏置项
G = np.column_stack([G, np.ones(n_samples)])
return G @ self.weights
# 方法3: K-means聚类法
class RBF_KMeans:
def __init__(self, n_centers=10):
self.n_centers = n_centers
self.centers = None
self.sigmas = None
self.weights = None
def fit(self, X, y):
# 使用K-means聚类确定中心
kmeans = KMeans(n_clusters=self.n_centers, random_state=42)
kmeans.fit(X)
self.centers = kmeans.cluster_centers_
# 计算每个中心的宽度 (簇内样本到中心的平均距离)
self.sigmas = np.zeros(self.n_centers)
for i in range(self.n_centers):
cluster_points = X[kmeans.labels_ == i]
if len(cluster_points) > 0:
dists = [np.linalg.norm(p - self.centers[i]) for p in cluster_points]
self.sigmas[i] = np.mean(dists) * 1.0
else:
self.sigmas[i] = 1.0 # 默认值
# 构建设计矩阵
n_samples = X.shape[0]
G = np.zeros((n_samples, self.n_centers))
for i in range(n_samples):
for j in range(self.n_centers):
G[i, j] = gaussian_rbf(X[i], self.centers[j], self.sigmas[j])
# 添加偏置项
G = np.column_stack([G, np.ones(n_samples)])
# 求解权重
self.weights = pinv(G) @ y
def predict(self, X):
n_samples = X.shape[0]
G = np.zeros((n_samples, self.n_centers))
for i in range(n_samples):
for j in range(self.n_centers):
G[i, j] = gaussian_rbf(X[i], self.centers[j], self.sigmas[j])
# 添加偏置项
G = np.column_stack([G, np.ones(n_samples)])
return G @ self.weights
# 主程序
if __name__ == "__main__":
# 生成数据
X, y = generate_data(n_samples=200, noise=0.1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 方法1: 插值求解
rbf_interp = RBF_Interpolation()
rbf_interp.fit(X_train, y_train)
y_pred_interp = rbf_interp.predict(X_test)
mse_interp = mean_squared_error(y_test, y_pred_interp)
# 方法2: OLS求解法
rbf_ols = RBF_OLS(max_centers=20, tolerance=0.01)
rbf_ols.fit(X_train, y_train)
y_pred_ols = rbf_ols.predict(X_test)
mse_ols = mean_squared_error(y_test, y_pred_ols)
# 方法3: K-means聚类法
rbf_kmeans = RBF_KMeans(n_centers=10)
rbf_kmeans.fit(X_train, y_train)
y_pred_kmeans = rbf_kmeans.predict(X_test)
mse_kmeans = mean_squared_error(y_test, y_pred_kmeans)
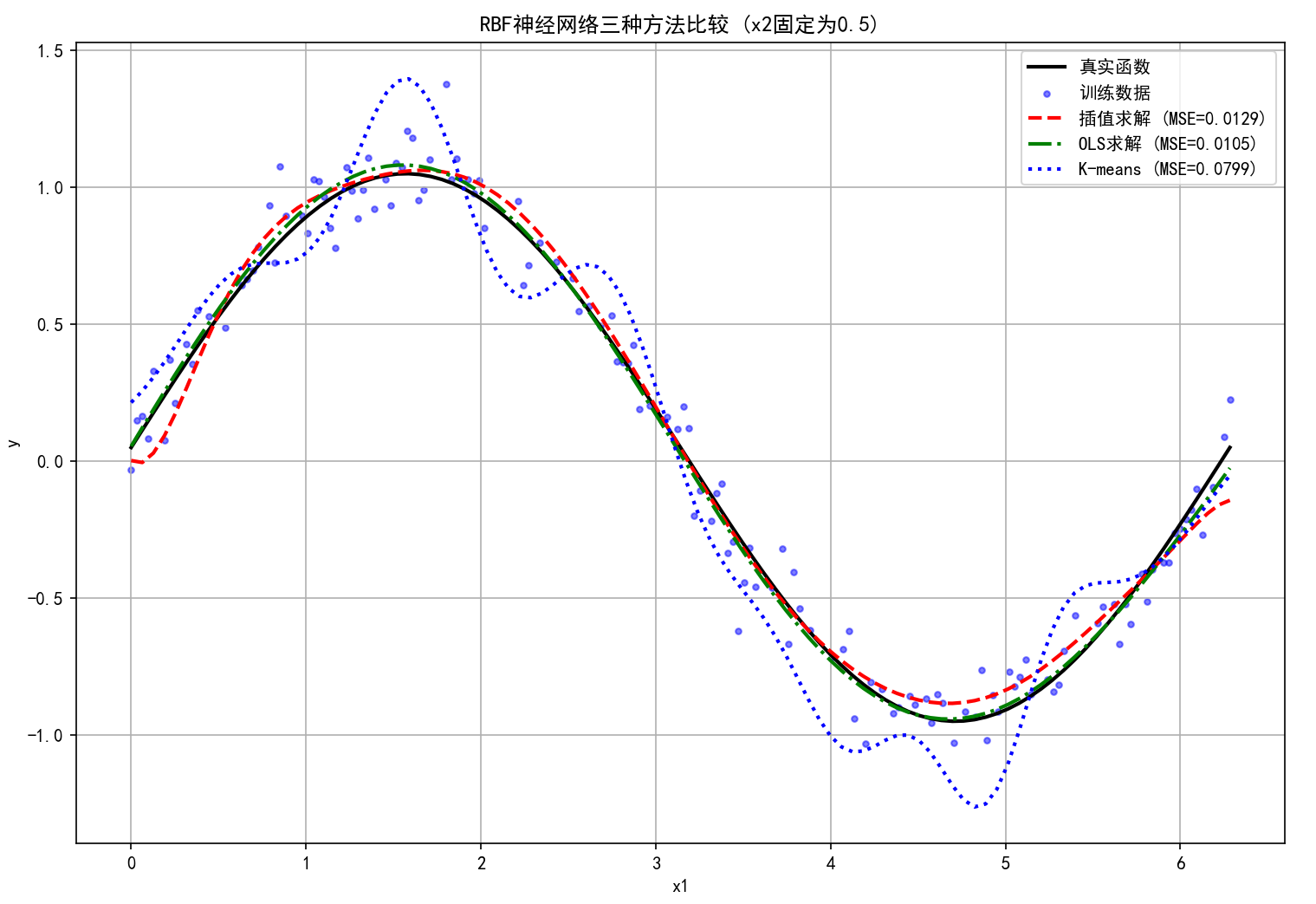
# 可视化结果 (固定x2=0.5,只变化x1)
x1_test = np.linspace(0, 2*np.pi, 100)
x2_test = np.full_like(x1_test, 0.5)
X_vis = np.column_stack((x1_test, x2_test))
y_true = np.sin(x1_test) + 0.1*x2_test
y_vis_interp = rbf_interp.predict(X_vis)
y_vis_ols = rbf_ols.predict(X_vis)
y_vis_kmeans = rbf_kmeans.predict(X_vis)
plt.figure(figsize=(12, 8))
plt.plot(x1_test, y_true, 'k-', linewidth=2, label='真实函数')
plt.scatter(X_train[:,0], y_train, c='blue', s=10, alpha=0.5, label='训练数据')
plt.plot(x1_test, y_vis_interp, 'r--', linewidth=2, label=f'插值求解 (MSE={mse_interp:.4f})')
plt.plot(x1_test, y_vis_ols, 'g-.', linewidth=2, label=f'OLS求解 (MSE={mse_ols:.4f})')
plt.plot(x1_test, y_vis_kmeans, 'b:', linewidth=2, label=f'K-means (MSE={mse_kmeans:.4f})')
plt.xlabel('x1')
plt.ylabel('y')
plt.title('RBF神经网络三种方法比较 (x2固定为0.5)')
plt.legend()
plt.grid(True)
plt.show()代码说明
-
数据生成
-
生成二维输入数据:x_1∈[0,2π],x_2∈[0,1]
-
目标函数:
,其中
是高斯噪声
-
数据集划分为训练集(70%)和测试集(30%)
-
三种RBF求解方法实现
-
方法1: 插值求解 (对应MATLAB的newrbe)
-
使用所有训练样本作为RBF中心
-
宽度
-
通过求解线性方程组
得到权重
-
特点:精确拟合训练数据,但可能过拟合
-
-
方法2: OLS求解法 (对应MATLAB的newrb)
-
使用正交最小二乘法(OLS)逐步选择中心
-
每次选择使误差减少最多的样本作为新中心
-
当误差减少量小于容忍度或达到最大中心数时停止
-
特点:自动选择重要中心,避免过拟合
-
-
方法3: K-means聚类法
-
使用K-means聚类确定RBF中心
-
宽度
-
通过最小二乘法求解权重
-
特点:计算效率高,适合大规模数据
-
-
评估与可视化
-
计算三种方法在测试集上的均方误差(MSE)
-
可视化比较:固定 x_2=0.5,变化 x_1,观察拟合效果
9、📌 任务一
用纯 NumPy 手写 3 层 MLP(2-4-1)解决 XOR 问题
📍9.1 XOR问题简介
XOR问题是一个经典的小数据集,用来说明单层感知机无法解决非线性分类,必须通过至少一层隐藏层才能学会。
XOR 问题是神经网络的“Hello World”,能学会 XOR,就证明你的网络具备非线性表达能力。
✔️9.2 具体定义
| 输入 A | 输入 B | 输出 (A ⊕ B) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
-
逻辑:当且仅当两个输入不相等时输出 1。
-
本质:这是一个非线性可分的二分类问题。
🚫 9.3 为什么单层感知机做不到?
-
单层感知机只能画一条直线把数据分开。
-
但 XOR 的 4 个点在二维坐标上呈 “×” 形分布:
(0,1)● ●(1,1) ╲ ╱ ╲╱ ╱╲ ╱ ╲ (0,0)● ●(1,0)
不存在一条直线能把 0 和 1 完全分开。
✅ 9.4 解决方式:多层感知机(MLP)
-
加一层隐藏层即可把输入空间映射到更高维,用两条直线围成的区域实现非线性划分。
-
这就是为什么我们刚才用 2-4-1 网络 去训练 XOR:
-
输入层 2 个神经元(对应 A、B)
-
隐藏层 4 个神经元(学习非线性特征)
-
输出层 1 个神经元(预测 0 或 1)
-
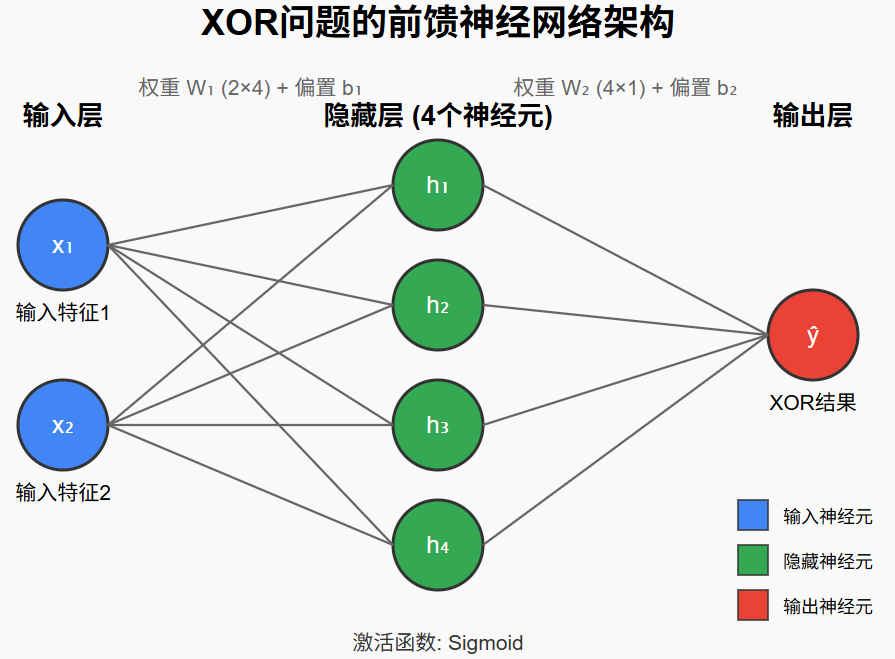
import numpy as np
# 1️⃣ 准备XOR问题的训练数据
print("准备XOR问题的训练数据...")
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]], dtype=float)
y = np.array([[0],
[1],
[1],
[0]], dtype=float)
print("输入特征X:")
print(X)
print("\n目标输出y (XOR结果):")
print(y)
# 2️⃣ 初始化神经网络参数
def xavier(fan_in, fan_out):
"""Xavier初始化方法,有助于神经网络训练"""
lim = np.sqrt(6 / (fan_in + fan_out))
return np.random.uniform(-lim, lim, (fan_in, fan_out))
# 隐藏层有4个神经元
W1 = xavier(2, 4) # 输入层到隐藏层的权重 (2×4)
b1 = np.zeros((1, 4))# 隐藏层偏置 (1×4)
W2 = xavier(4, 1) # 隐藏层到输出层的权重 (4×1)
b2 = np.zeros((1, 1))# 输出层偏置 (1×1)
print("\n初始化神经网络参数完成")
# 定义激活函数及其导数
sigmoid = lambda z: 1 / (1 + np.exp(-z))
sigmoid_grad = lambda a: a * (1 - a)
# 训练参数
learning_rate = 0.5
epochs = 10000
print(f"\n开始训练神经网络 (共{epochs}轮)...")
# 训练过程
for epoch in range(epochs):
# 3️⃣ 前向传播
z1 = X @ W1 + b1 # 隐藏层加权输入 (4×4)
a1 = sigmoid(z1) # 隐藏层输出 (4×4)
z2 = a1 @ W2 + b2 # 输出层加权输入 (4×1)
y_hat = sigmoid(z2) # 网络预测输出 (4×1)
# 4️⃣ 反向传播计算梯度
error = y_hat - y # 输出误差 (4×1)
delta2 = error * sigmoid_grad(y_hat) # 输出层 delta (4×1)
grad_W2 = a1.T @ delta2 # W2的梯度 (4×1)
grad_b2 = delta2.sum(axis=0, keepdims=True) # b2的梯度 (1×1)
e1 = delta2 @ W2.T # 隐藏层误差 (4×4)
delta1 = e1 * sigmoid_grad(a1) # 隐藏层 delta (4×4)
grad_W1 = X.T @ delta1 # W1的梯度 (2×4)
grad_b1 = delta1.sum(axis=0, keepdims=True) # b1的梯度 (1×4)
# 5️⃣ 更新参数
W2 -= learning_rate * grad_W2
b2 -= learning_rate * grad_b2
W1 -= learning_rate * grad_W1
b1 -= learning_rate * grad_b1
# 定期输出训练进度
if epoch % 2000 == 0:
mse_loss = np.mean(error**2)
print(f"训练轮次 {epoch:>5}/{epochs} | 均方误差: {mse_loss:.6f}")
# 6️⃣ 训练结果验证
print("\n" + "="*50)
print("训练完成!最终结果:")
print("="*50)
# 格式化输出预测结果
print("\n输入 | 实际XOR结果 | 网络预测 | 预测类别")
print("-"*40)
for i in range(len(X)):
# 将预测值转换为类别(0或1),以0.5为阈值
predicted_class = 1 if y_hat[i][0] >= 0.5 else 0
print(f" {X[i]} | {y[i][0]} | {y_hat[i][0]:.4f} | {predicted_class}")
# 计算并输出准确率
predicted_classes = (y_hat >= 0.5).astype(int)
accuracy = np.mean(predicted_classes == y) * 100
print(f"\n模型准确率: {accuracy:.2f}%") 控制台输出:
准备XOR问题的训练数据...
输入特征X:
[[0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]
目标输出y (XOR结果):
[[0.]
[1.]
[1.]
[0.]]
初始化神经网络参数完成
开始训练神经网络 (共10000轮)...
训练轮次 0/10000 | 均方误差: 0.274570
训练轮次 2000/10000 | 均方误差: 0.003462
训练轮次 4000/10000 | 均方误差: 0.000944
训练轮次 6000/10000 | 均方误差: 0.000522
训练轮次 8000/10000 | 均方误差: 0.000356
==================================================
训练完成!最终结果:
==================================================
输入 | 实际XOR结果 | 网络预测 | 预测类别
----------------------------------------
[0. 0.] | 0.0 | 0.0197 | 0
[0. 1.] | 1.0 | 0.9848 | 1
[1. 0.] | 1.0 | 0.9847 | 1
[1. 1.] | 0.0 | 0.0149 | 0
模型准确率: 100.00%代码解释:
-
前向传播(神经网络结构与变量定义)
-
输入层:2 个神经元(输入特征
,4 个样本,每个样本 2 维)
-
隐藏层:4 个神经元,加权输入
,激活输出
-
输出层:1 个神经元,加权输入
,激活输出
-
参数:
(输入→隐藏权重),
(隐藏层偏置),
(隐藏→输出权重),
(输出层偏置)。
-
损失函数:均方误差(MSE):
-
-
反向传播
反向传播的目标是计算损失
对每个参数
的偏导数,即
。计算顺序是从输出层到输入层(反向),利用链式法则逐层传递误差。
-
步骤 1:计算输出层误差与梯度
-
输出层误差项
误差项
定义为:
(损失对输出层加权输入的偏导数),由链式法则:
-
第一项
:损失对预测值的偏导数。
因损失是 MSE:
,故
。
代码中简化为
error = y_hat - y(省略了系数,不影响梯度方向,可通过学习率调整幅度)。
-
第二项
:sigmoid 激活函数的导数。
sigmoid 函数为
,其导数为
。
因
,故
,即代码中的
sigmoid_grad(y_hat)。
对应代码:
delta2 = error * sigmoid_grad(y_hat) -
-
的梯度
到输出层加权输入
的权重,即
根据链式法则,损失对
(推导:
,矩阵乘法需转置保证维度匹配)
对应代码:
grad_W2 = a1.T @ delta2 # a1.T是4×4,delta2是4×1,结果为4×1(与W2维度一致) -
的梯度
偏置
。
根据链式法则:
(对所有样本的
对应代码:
grad_b2 = delta2.sum(axis=0, keepdims=True) # 沿样本轴(axis=0)求和,保持维度1×1(与b2一致)
-
-
步骤 2:计算隐藏层误差与梯度
-
隐藏层误差项
误差项
定义为:
(损失对隐藏层加权输入的偏导数),根据链式法则:
-
第一项
:输出层误差反向传播到隐藏层输出
-
因
,因此损失对
-
代码中记为
e1 = delta2 @ W2.T。
-
-
第二项
:隐藏层 sigmoid 激活函数的导数。
-
因
,故导数为
,即代码中的
sigmoid_grad(a1)
-
因此,
对应代码:
e1 = delta2 @ W2.T # 隐藏层误差 (4×4) delta1 = e1 * sigmoid_grad(a1) # 隐藏层 delta (4×4) -
-
的梯度
的权重,即
根据链式法则,损失对
(推导:
)
对应代码:
grad_W1 = X.T @ delta1 # W1的梯度 (2×4) -
的梯度
偏置
。
根据链式法则:
(对所有样本的
对应代码
grad_b1 = delta1.sum(axis=0, keepdims=True) # b1的梯度 (1×4)
-
-
10、📌 任务二
用torch.nn搭建MLP,在MNIST上训练到98%准确率
MNIST数据集介绍:
MNIST 数据集(Modified National Institute of Standards and Technology database)是机器学习和计算机视觉领域最经典、最常用的入门级数据集之一,主要用于手写数字识别任务。下面从几个维度为你做一个系统介绍。
1. 数据概况
项目 数值 类别数 10(数字 0–9) 训练集 60,000 张 28×28 灰度图像 测试集 10,000 张 28×28 灰度图像 像素范围 0–255(通常归一化到 0–1 或 −1–1) 文件格式 原始二进制 idx3/idx1 格式,或 CSV
2. 数据来源与制作
原始素材:来自 NIST 的两份手写数字数据集(SD-3 为政府雇员书写,SD-7 为高中生书写)。
修改过程:
将黑白图像转为灰度并统一尺寸为 28×28。
对字符进行抗锯齿、居中处理,简化背景。
重新划分训练/测试,保证两份子集写入者群体不重叠,避免分布偏差。
3. 数据结构
MNIST 包含 4 个文件(官方二进制版本):
文件名 内容 大小 train-images-idx3-ubyte 训练图像 47,040,016 字节 train-labels-idx1-ubyte 训练标签 60,008 字节 t10k-images-idx3-ubyte 测试图像 7,840,016 字节 t10k-labels-idx1-ubyte 测试标签 10,008 字节
图像文件:前 16 字节为 magic number 和维度信息,后续为像素字节流。
标签文件:前 8 字节为头部,后续为 0–9 的整数标签。
4. 典型基准结果
模型/方法 测试误差率 线性分类器 (1-layer softmax) 7.6 % 2 层全连接神经网络 2.4 % CNN (LeNet-5) 0.8 % CNN + Dropout + BatchNorm 0.3 % 人类表现 ≈ 0.2 %
5. 使用示例(PyTorch)
from torchvision import datasets, transforms from torch.utils.data import DataLoader transform = transforms.Compose([ transforms.ToTensor(), # [0,255]->[0,1] transforms.Normalize((0.1307,), (0.3081,)) ]) train_ds = datasets.MNIST(root='./data', train=True, download=True, transform=transform) test_ds = datasets.MNIST(root='./data', train=False, download=True, transform=transform) train_loader = DataLoader(train_ds, batch_size=64, shuffle=True) test_loader = DataLoader(test_ds, batch_size=1000, shuffle=False)
6. 常见扩展与衍生
KMNIST:日本片假名字符(平假名),与 MNIST 同尺寸格式。
Fashion-MNIST:10 类服饰商品图像,形状、纹理更复杂,作为 MNIST 替代品。
EMNIST:包含大写/小写字母与数字,共 62 类 + 10 类数字。
QMNIST:NIST 原始扫描重新处理,含额外 50,000 张“丢失”样本。
7. 局限性与注意事项
过于简单:现代 CNN 轻松达到 99%+ 准确率,无法充分评估复杂模型。
灰度、单通道:缺少彩色、纹理、背景干扰,与现实场景差距大。
已过度拟合:公开测试集被反复使用,可能导致“隐式过拟合”。
8. 获取方式
官方:
http://yann.lecun.com/exdb/mnist/镜像:
https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz框架内置:PyTorch、TensorFlow、Keras、MXNet 均支持一行代码下载。
总结:MNIST 以“小而精”著称,是入门深度学习、算法原型验证、教学演示的“Hello World”。
但在当前研究或工业落地中,通常会选择更复杂的数据集(如 CIFAR-10/100、ImageNet、COCO 等)。
框架选择
-
激活函数:ReLU
-
初始化方法:Xavier初始化
-
损失函数:多分类交叉熵损失
-
参数优化方法:SGD (lr=0.01, momentum=0.9)
-
正则化方法:Dropout(0.5)
import torch
# PyTorch 核心库
import torch.nn as nn
# 包含所有构建神经网络所需的模块,如线性层、激活函数、损失函数等
import torch.optim as optim
# 包含各种优化算法,如 SGD, Adam 等
import torch.nn.functional as F
# 包含一系列函数式接口,如激活函数 (relu) 和损失函数 (nll_loss)
from torchvision import datasets, transforms
# PyTorch 的视觉库,包含了常用的数据集(如 MNIST)、模型架构和图像变换
from torch.utils.data import DataLoader
# 一个非常重要和方便的工具,用于加载数据,并支持批量处理、打乱数据和并行加载
import time # 用于计算代码运行时间
import numpy as np # 用于科学计算,这里主要用来计算最终结果的平均值和标准差
from tqdm import tqdm # 一个快速、可扩展的 Python 进度条库,用于在训练循环中显示进度
# 定义MLP模型
class MLP(nn.Module): # 定义一个名为 MLP (多层感知机) 的类,它继承自 PyTorch 的基础神经网络模块 nn.Module
def __init__(self): # 类的构造函数
super().__init__() # 调用父类 nn.Module 的构造函数,这是必须的步骤
self.fc1 = nn.Linear(784, 256)
# 定义第一个全连接层 (fully connected layer)
# 输入特征数为 784 (MNIST 图像 28x28 像素展开),输出特征数为 256
self.fc2 = nn.Linear(256, 10)
# 定义第二个全连接层,输入为上一层的 256,输出为 10,对应 10 个数字类别 (0-9)
self.dropout = nn.Dropout(0.5)
# 定义一个 Dropout 层,在训练时会以 50% 的概率随机将一些神经元的输出置为零
# 这是一种有效的正则化手段,可以防止过拟合
self.init_weights() # 调用一个自定义的权重初始化方法
def init_weights(self): # 自定义的权重初始化函数
# Xavier初始化
nn.init.xavier_uniform_(self.fc1.weight)
# 使用 Xavier 均匀分布来初始化全连接层的权重(weight)。这是一种常用的权重初始化方法,有助于防止梯度消失或爆炸
nn.init.zeros_(self.fc1.bias)
# 初始化偏置为0,这是常见的做法
nn.init.xavier_uniform_(self.fc2.weight)
nn.init.zeros_(self.fc2.bias)
def forward(self, x): # 定义模型的前向传播逻辑
x = x.view(-1, 784)
# 将输入的图像张量 x (通常形状为 [batch_size, 1, 28, 28]) 展平为 [batch_size, 784] 的二维张量
# -1 表示该维度的大小由 PyTorch 自动推断
x = F.relu(self.fc1(x))
# 将数据传入第一个全连接层 self.fc1,然后使用 ReLU (Rectified Linear Unit) 作为激活函数
x = self.dropout(x)
# 将 Dropout 应用于激活后的输出
x = self.fc2(x)
# 将 Dropout 应用于激活后的输出
return x
# 直接返回原始输出 (logits)。log_softmax 将由 CrossEntropyLoss 处理
# 训练函数
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train()
# 将模型设置为训练模式,这会启用 Dropout 等只在训练时使用的层
train_loss = 0
# 初始化训练损失
for batch_idx, (data, target) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch}")):
# 循环遍历 train_loader 中的所有数据批次,并使用 tqdm 显示一个带有描述的进度条
data, target = data.to(device), target.to(device)
# 将输入数据 data 和标签 target 移动到指定的计算设备(CPU 或 GPU)
optimizer.zero_grad()
# 在计算新梯度之前,清除之前计算的梯度
output = model(data)
# 执行模型的前向传播,得到预测结果
loss = criterion(output, target)
# 使用传入的 criterion 计算损失
loss.backward()
# 执行反向传播,计算损失函数相对于模型所有参数的梯度
optimizer.step()
# 根据计算出的梯度,使用优化器(如 SGD)更新模型的参数
train_loss += loss.item()
# 累加每个批次的损失值。.item() 用于从只有一个元素的张量中获取其 Python 数值
return train_loss / len(train_loader)
# 返回该 epoch 的平均训练损失
# 测试函数
def test(model, device, test_loader, criterion):
model.eval()
# 将模型设置为评估模式,这会禁用 Dropout 等层
test_loss = 0
correct = 0
# 初始化测试损失和准确率
with torch.no_grad():
# 一个上下文管理器,在其作用域内禁用梯度计算。这在测试阶段是必须的,可以显著提高计算速度并减少内存占用
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
# 用传入的 criterion 计算损失,累加整个测试集的总损失
# criterion 默认 reduction='mean',所以直接 .item()
# 可以得到更精确的全局平均损失
pred = output.argmax(dim=1, keepdim=True)
# 找到 log_softmax 输出中概率最大的那个类别的索引,作为模型的预测结果
# dim=1 表示在类别维度上操作
correct += pred.eq(target.view_as(pred)).sum().item()
# 将预测结果 pred 和真实标签 target 进行比较
# .eq() 返回一个布尔张量,
# .sum() 计算其中 True 的数量(即预测正确的样本数)
# .item() 将其转换为 Python 数字并累加
# [OPTIMIZATION] 由于criterion默认计算的是批次的平均损失,这里我们对所有批次的平均损失再取平均
test_loss /= len(test_loader) # 计算整个测试集的平均损失
accuracy = 100. * correct / len(test_loader.dataset) # 计算分类准确率
return test_loss, accuracy
# 运行实验函数
def run(seed, epochs=20):
torch.manual_seed(seed)
np.random.seed(seed)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
model = MLP().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
criterion = nn.CrossEntropyLoss()
# 损失函数使用 nn.CrossEntropyLoss,它结合了 log_softmax 和 nll_loss
train_losses, test_losses, test_accuracies = [], [], []
start_time = time.time()
print(f"\n{'=' * 50}")
print(f"RUNNING WITH SEED {seed} ON DEVICE {device}")
print(f"Optimizer: SGD, Init: Xavier, Regularization: Dropout(0.5)")
print('=' * 50)
for epoch in range(1, epochs + 1):
train_loss = train(model, device, train_loader, optimizer, criterion, epoch)
test_loss, accuracy = test(model, device, test_loader, criterion)
train_losses.append(train_loss)
test_losses.append(test_loss)
test_accuracies.append(accuracy)
print(f"Epoch {epoch:02d}: Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%")
training_time = time.time() - start_time
final_accuracy = test_accuracies[-1]
print(f"\nFinal Accuracy: {final_accuracy:.2f}%")
print(f"Training Time: {training_time:.2f} seconds")
return {
'seed': seed,
'final_accuracy': final_accuracy,
'training_time': training_time
}
# --- 主执行块 ---
if __name__ == '__main__':
seeds = [42, 123, 456]
results = []
for seed in seeds:
result = run(seed, epochs=20)
results.append(result)
avg_accuracy = np.mean([r['final_accuracy'] for r in results])
std_accuracy = np.std([r['final_accuracy'] for r in results])
avg_time = np.mean([r['training_time'] for r in results])
std_time = np.std([r['training_time'] for r in results])
print("\n" + "=" * 70)
print("FINAL RESULTS SUMMARY (Best Combination: SGD + Xavier + Dropout(0.5))")
print("=" * 70)
for i, result in enumerate(results):
print(f"\nRun {i + 1} (Seed={result['seed']}):")
print(f" Final Accuracy: {result['final_accuracy']:.2f}%")
print(f" Training Time: {result['training_time']:.2f} seconds")
print("\n" + "-" * 70)
print("AVERAGE RESULTS ACROSS ALL RUNS:")
print(f" Average Accuracy: {avg_accuracy:.2f}% ± {std_accuracy:.2f}%")
print(f" Average Training Time: {avg_time:.2f} ± {std_time:.2f} seconds")
print("-" * 70) 控制台关键输出:
==================================================
RUNNING WITH SEED 42 ON DEVICE cuda
Optimizer: SGD, Init: Xavier, Regularization: Dropout(0.5)
==================================================
此处省略进度条等。。。
======================================================================
FINAL RESULTS SUMMARY (Best Combination: SGD + Xavier + Dropout(0.5))
======================================================================
Run 1 (Seed=42):
Final Accuracy: 98.20%
Training Time: 378.30 seconds
Run 2 (Seed=123):
Final Accuracy: 98.27%
Training Time: 194.02 seconds
Run 3 (Seed=456):
Final Accuracy: 98.14%
Training Time: 214.97 seconds
----------------------------------------------------------------------
AVERAGE RESULTS ACROSS ALL RUNS:
Average Accuracy: 98.20% ± 0.05%
Average Training Time: 262.43 ± 82.38 seconds
----------------------------------------------------------------------11、📌 任务三
用torch.nn搭建MLP,在CIFAR10上训练,并设计实验探究优化器、初始化、正则化对 MLP 性能的影响
数据集介绍:CIFAR-10
CIFAR-10 是一个广泛用于计算机视觉研究的经典数据集。
内容:它包含了 60,000 张 32x32 像素的彩色图像。
类别:这些图像被分为 10 个互斥的类别,每个类别有 6,000 张图像。这 10 个类别是:飞机(airplane)、汽车(automobile)、鸟(bird)、猫(cat)、鹿(deer)、狗(dog)、青蛙(frog)、马(horse)、船(ship)和卡车(truck)。
数据划分:数据集被标准地划分为 50,000 张训练图像和 10,000 张测试图像。
与 MNIST 的区别和挑战:
彩色 vs. 灰度:CIFAR-10 是三通道(RGB)的彩色图像,而 MNIST 是单通道的灰度图像。这意味着对于同样尺寸的图像,MLP的输入层需要处理的数据量是 MNIST 的三倍。
复杂性:CIFAR-10 的图像内容是真实世界的物体,具有复杂的背景、不同的光照、视角和形态变化。相比之下,MNIST 的手写数字通常是居中的,背景简单。
对模型的要求:由于其复杂性,CIFAR-10 对模型的特征提取能力要求更高。一个简单的 MLP 在 CIFAR-10 上的性能通常远不如在 MNIST 上,并且非常容易过拟合。这使得它成为一个很好的“试验场”,来检验各种优化和正则化技术的效果。
11.1 📊 实验设计
目标:系统地比较优化器、初始化、正则化对 MLP 性能的影响
控制变量法:建立一个基准(Baseline)模型,然后一次只改变一个因素进行比较
基准模型 (Baseline)
-
架构: 一个简单的 MLP,结构为 输入层 -> 隐藏层1(512) -> ReLU -> 隐藏层2(256) -> ReLU -> 输出层(10)。
-
优化器: SGD (随机梯度下降) with momentum=0.9, lr=0.01。这是一个非常经典和稳健的基准。
-
初始化: Kaiming (He) 初始化。由于我们使用 ReLU 激活函数,Kaiming 初始化是理论上和实践上都非常合适的选择。
-
正则化: 无。基准模型不使用任何正则化,以便后续观察添加正则化后的效果。
实验A:比较优化器 (Optimizer)
-
固定项: Kaiming 初始化,无正则化。
-
可变项:
-
SGD with Momentum (基准)
-
Adam: 一种自适应学习率优化器,通常收敛速度更快。
-
Adagrad: 另一种自适应学习率优化器,适合处理稀疏数据。
-
实验B:比较初始化方法 (Initialization)
-
固定项: 使用实验A中表现最好的优化器(预计是 Adam),无正则化。
-
可变项:
-
Kaiming (He) 初始化 (基准)
-
Xavier (Glorot) 初始化: 专为 tanh 或 sigmoid 等饱和激活函数设计,但也常被使用。
-
标准正态分布初始化: 一种朴素的初始化方法,用于对比现代初始化技术的重要性。
-
实验C:比较正则化技术 (Regularization)
-
固定项: 使用实验A和B中表现最好的优化器和初始化方法。
-
可变项:
-
无正则化 (基une)
-
Dropout: 以 50% 的概率在前向传播中随机丢弃神经元,是防止过拟合的强力工具。
-
L2 正则化 (Weight Decay): 在损失函数中加入权重的 L2 范数惩罚项,抑制权重变得过大。
-
每个实验,我们都将记录其在 15-20 个 epoch 内的训练损失、测试损失和测试准确率,并特别关注最终的测试准确率和训练所需时间。
11.2 📆 实验代码与运行结果
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import time
import numpy as np
from tqdm import tqdm
# --- 1. 模型定义 ---
class MLP_CIFAR(nn.Module):
def __init__(self, regularization=None, dropout_rate=0.5):
super().__init__()
self.regularization = regularization
# 定义网络层
self.fc1 = nn.Linear(32 * 32 * 3, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
if self.regularization == 'dropout':
self.dropout = nn.Dropout(dropout_rate)
def init_weights(self, method='kaiming'):
"""根据指定方法初始化权重"""
for m in self.modules():
if isinstance(m, nn.Linear):
if method == 'kaiming':
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
elif method == 'xavier':
nn.init.xavier_uniform_(m.weight)
elif method == 'normal':
nn.init.normal_(m.weight, mean=0, std=0.01)
else:
# 默认使用 Kaiming
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
nn.init.zeros_(m.bias)
def forward(self, x):
# 将输入的 32x32x3 图像展平
x = x.view(-1, 32 * 32 * 3)
x = torch.relu(self.fc1(x))
if self.regularization == 'dropout' and self.training:
x = self.dropout(x)
x = torch.relu(self.fc2(x))
if self.regularization == 'dropout' and self.training:
x = self.dropout(x)
x = self.fc3(x)
return x
# --- 2. 训练与测试函数 ---
def train(model, device, train_loader, optimizer, criterion):
model.train()
total_loss = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)
def test(model, device, test_loader, criterion):
model.eval()
total_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
total_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
avg_loss = total_loss / len(test_loader)
accuracy = 100. * correct / len(test_loader.dataset)
return avg_loss, accuracy
# --- 3. 实验运行主函数 ---
def run_experiment(config):
"""根据配置运行一次完整的实验"""
print("\n" + "=" * 50)
print(f"Running Config: Optimizer={config['optimizer']}, Init={config['init']}, Reg={config['reg']}")
print("=" * 50)
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据预处理与加载
# CIFAR-10 标准的均值和标准差
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
train_dataset = datasets.CIFAR10('./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False)
# 模型初始化
model = MLP_CIFAR(regularization=config['reg']).to(device)
model.init_weights(method=config['init'])
# 优化器选择
lr = config.get('lr', 0.01)
weight_decay = config['weight_decay'] if config['reg'] == 'l2' else 0
if config['optimizer'] == 'sgd':
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=0.9, weight_decay=weight_decay)
elif config['optimizer'] == 'adam':
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
elif config['optimizer'] == 'adagrad':
optimizer = optim.Adagrad(model.parameters(), lr=lr, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
# 训练循环
start_time = time.time()
for epoch in tqdm(range(1, config['epochs'] + 1), desc="Training Progress"):
train_loss = train(model, device, train_loader, optimizer, criterion)
test_loss, test_accuracy = test(model, device, test_loader, criterion)
if epoch % 5 == 0 or epoch == config['epochs']: # 每5轮打印一次结果
print(
f"Epoch {epoch:02d} | Train Loss: {train_loss:.4f} | Test Loss: {test_loss:.4f} | Test Acc: {test_accuracy:.2f}%")
end_time = time.time()
final_loss, final_accuracy = test(model, device, test_loader, criterion)
print(f"\nFinal Test Accuracy: {final_accuracy:.2f}%")
print(f"Total Training Time: {end_time - start_time:.2f} seconds")
return final_accuracy, end_time - start_time
# --- 4. 主执行块 ---
if __name__ == '__main__':
# 定义所有实验配置
experiments = {
"A: Optimizers": [
{'name': 'SGD', 'optimizer': 'sgd', 'init': 'kaiming', 'reg': None, 'epochs': 15},
{'name': 'Adam', 'optimizer': 'adam', 'init': 'kaiming', 'reg': None, 'epochs': 15, 'lr': 0.001},
# Adam通常需要更小的学习率
{'name': 'Adagrad', 'optimizer': 'adagrad', 'init': 'kaiming', 'reg': None, 'epochs': 15},
],
"B: Initializations": [
{'name': 'Kaiming', 'optimizer': 'adam', 'init': 'kaiming', 'reg': None, 'epochs': 15, 'lr': 0.001},
{'name': 'Xavier', 'optimizer': 'adam', 'init': 'xavier', 'reg': None, 'epochs': 15, 'lr': 0.001},
{'name': 'Normal', 'optimizer': 'adam', 'init': 'normal', 'reg': None, 'epochs': 15, 'lr': 0.001},
],
"C: Regularizations": [
{'name': 'None', 'optimizer': 'adam', 'init': 'kaiming', 'reg': None, 'epochs': 20, 'lr': 0.001},
{'name': 'Dropout', 'optimizer': 'adam', 'init': 'kaiming', 'reg': 'dropout', 'epochs': 20, 'lr': 0.001},
{'name': 'L2 (WeightDecay)', 'optimizer': 'adam', 'init': 'kaiming', 'reg': 'l2', 'weight_decay': 1e-4,
'epochs': 20, 'lr': 0.001},
]
}
# 运行所有实验并收集结果
results = {}
for group_name, configs in experiments.items():
print("\n" + "#" * 70)
print(f"# EXPERIMENT GROUP: {group_name}")
print("#" * 70)
group_results = {}
for config in configs:
acc, train_time = run_experiment(config)
group_results[config['name']] = {'accuracy': acc, 'time': train_time}
results[group_name] = group_results
# 打印最终总结
print("\n\n" + "*" * 70)
print("*" + " " * 25 + "FINAL RESULTS SUMMARY" + " " * 24 + "*")
print("*" * 70)
for group_name, group_results in results.items():
print(f"\n--- {group_name} ---")
for name, res in group_results.items():
print(f" - {name:<20}: Accuracy = {res['accuracy']:.2f}%, Time = {res['time']:.2f}s")控制台输出:
之前省略。。。
**********************************************************************
* FINAL RESULTS SUMMARY *
**********************************************************************
--- A: Optimizers ---
- SGD : Accuracy = 51.52%, Time = 328.79s
- Adam : Accuracy = 51.11%, Time = 595.79s
- Adagrad : Accuracy = 52.23%, Time = 584.58s
--- B: Initializations ---
- Kaiming : Accuracy = 51.40%, Time = 165.01s
- Xavier : Accuracy = 52.28%, Time = 275.64s
- Normal : Accuracy = 52.77%, Time = 164.00s
--- C: Regularizations ---
- None : Accuracy = 50.95%, Time = 217.71s
- Dropout : Accuracy = 46.91%, Time = 219.02s
- L2 (WeightDecay) : Accuracy = 50.86%, Time = 207.37s实验结果表明,在简单网络结构(MLP)下,使用不同优化器,初始化方法,正则化方法并没有显著影响。模型是基础: 所有优化策略都建立在模型结构之上。如果模型结构本身不适合解决问题(如此处的 MLP 用于图像识别),那么再多的调优也只是杯水车薪,甚至可能因为错误的假设(如误认为模型是过拟合而使用强正则化)而得到更差的结果。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 59
59 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)