python实现BSM1仿真中运行代码的详解
🌞欢迎来到人工智能的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2025年8月24日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

稳态运行阶段
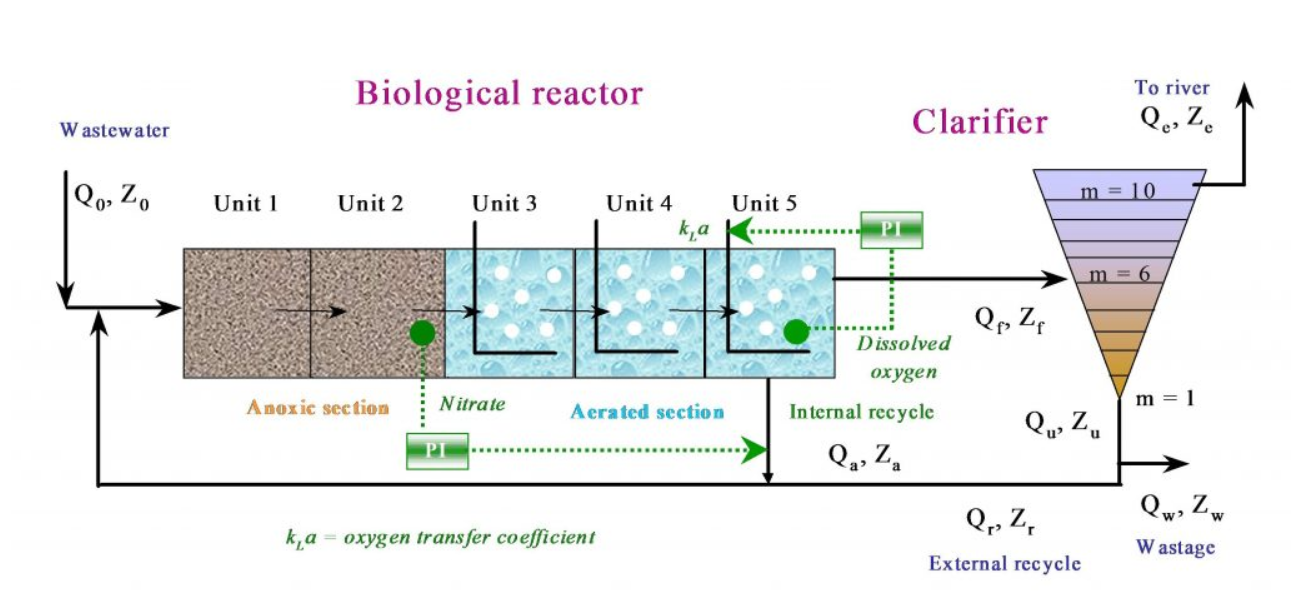
1️⃣构建组件
创造反应器
reactor1 = asm1.ASM1reactor(
asm1init.KLa1, # 反应器1的KLa
asm1init.VOL1, # 体积
asm1init.yinit1, # 初始状态(21维组分 + 扩展项)
asm1init.PAR1, # ASM1参数(动/静力学、半饱和常数等)
asm1init.carb1, # 外加碳源流量
asm1init.carbonsourceconc, # 碳源浓度
tempmodel, # 是否做温度平衡
activate # 是否启用虚拟变量
)
调用asm1.py中ASM1reactor函数完成翻译器的定义,反应器中的参数使用asm1init这个文件
中的设定的参数里面的参数如下:
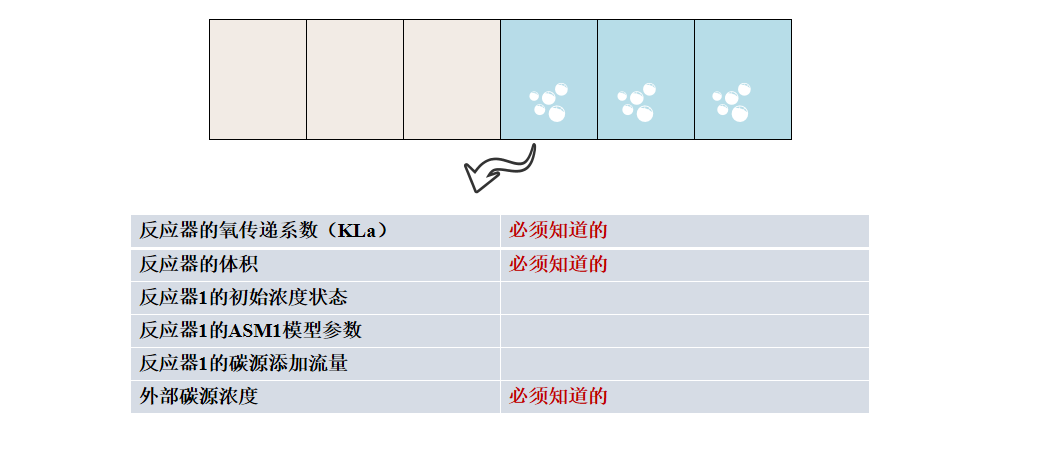
创造沉淀池
# 创建沉淀池(一维模型)
settler = settler1d_asm1.Settler(
settler1dinit_asm1.DIM, # 沉淀池尺寸参数
settler1dinit_asm1.LAYER, # 沉淀池分层数量
asm1init.Qr, # 回流污泥流量
asm1init.Qw, # 剩余污泥流量
settler1dinit_asm1.settlerinit, # 沉淀池初始状态
settler1dinit_asm1.SETTLERPAR, # 沉淀池参数(如沉淀速度等)
asm1init.PAR1, # ASM1模型共享参数
tempmodel # 温度模型开关
)调用settler1d_asm1文件的Settler类,初始化参数通过settler1dinit_asm1文件和asm1init实现
创造曝气系统
aerationcontrol3 = aerationcontrol.PIaeration(
aerationcontrolinit.KLa3_min, # KLa最小值(控制下限)
aerationcontrolinit.KLa3_max, # KLa最大值(控制上限)
aerationcontrolinit.KSO3, # 比例系数(PI控制器参数)
aerationcontrolinit.TiSO3, # 积分时间(PI控制器参数)
aerationcontrolinit.TtSO3, # 控制采样时间
aerationcontrolinit.SO3ref, # 溶解氧设定值(控制目标)
aerationcontrolinit.KLa3offset, # KLa偏移量(基础值调整)
aerationcontrolinit.SO3intstate, # 积分项初始状态
aerationcontrolinit.SO3awstate, # 控制器报警状态
aerationcontrolinit.kla3_lim, # 3号反应器受限制的KLa值
aerationcontrolinit.kla3_calc # 3号反应器计算的KLa值
)2️⃣设置仿真基础和初始化变量
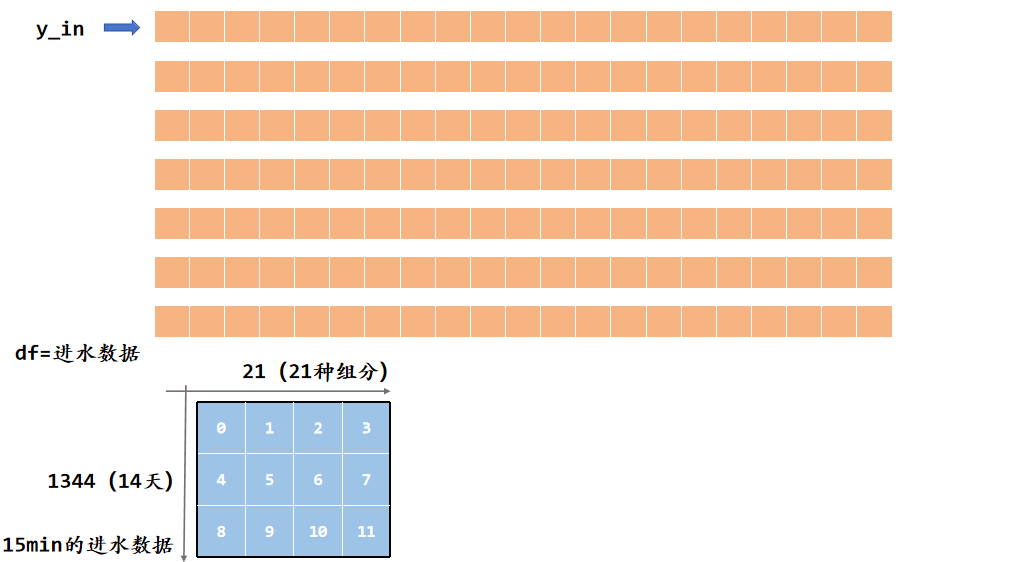
# 进水数据(恒定进水,符合BSM1标准,共21个组分)
# 组分定义:[SI, SS, XI, XS, XBH, XBA, XP, SO, SNO, SNH, SND, XND, SALK, TSS, Q, TEMP, SD1, SD2, SD3, XD4, XD5]
y_in = np.array(
[30, 69.5000000000000, 51.2000000000000, 202.320000000000, 28.1700000000000, 0, 0, 0, 0, 31.5600000000000,
6.95000000000000, 10.5900000000000, 7, 211.267500000000, 18446, 15, 0, 0, 0, 0, 0])# 仿真时间参数设置(单位:天)
timestep = 1 / (60 * 24) # 积分步长:1分钟(转换为天)
endtime = 200 # 仿真总时长:200天(确保系统达到稳态)
simtime = np.arange(0, endtime, timestep) # 生成仿真时间序列# 初始化变量(存储反应器和沉淀池的状态参数)
y_out5 = np.zeros(21) # 反应器5的出水浓度(21个组分)
ys_out = np.zeros(21) # 沉淀池的回流污泥浓度
ys_in = np.zeros(21) # 进入沉淀池的混合液浓度
Qintr = 0 # 内回流流量(稳态仿真中设为0)
# 初始化3、4、5号反应器的KLa值(从初始参数文件读取)
kla3 = asm1init.KLa3
kla4 = asm1init.KLa4
kla5 = asm1init.KLa53️⃣稳态仿真
计算考虑内回流和外回流的进水(y_in1)
将当前计算的KLa值应用到3、4、5号反应器
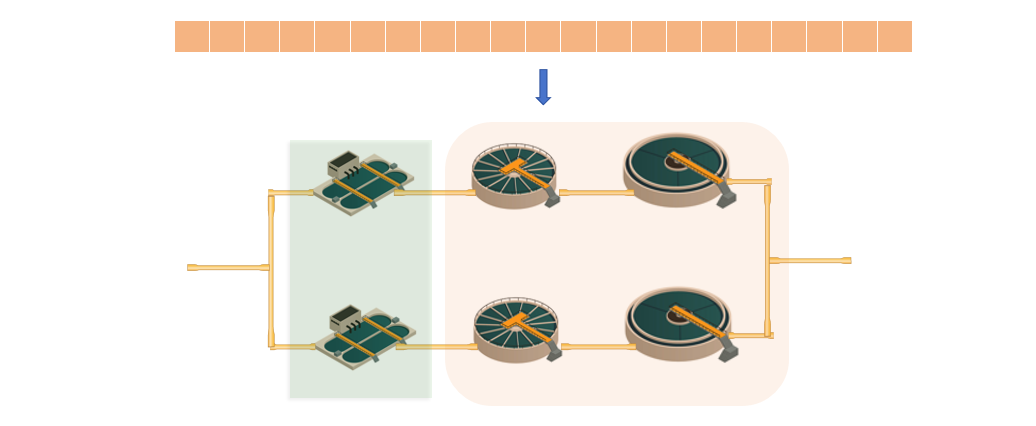
依次运行5个串联反应器(前一个反应器的出水作为下一个的进水)
基于反应器出水的溶解氧浓度(第7个参数)进行反馈调节
准备进入沉淀池的混合液(反应器5的出水减去内回流)
运行沉淀池模型(泥水分离,输出回流污泥和最终出水)
4️⃣保存稳态仿真结果到文件
前6行一共有21个数据,代表水质情况,第7行有25个数据,多的4个数据分别代表凯氏氮、总氮、COD、BOD。

保存3、4、5号反应器曝气控制系统的稳态参数, 3行(反应器)×5列(控制参数)

28天的仿真阶段
1️⃣从稳态仿真结果读初始数据
2️⃣构建组件和设置曝气系统
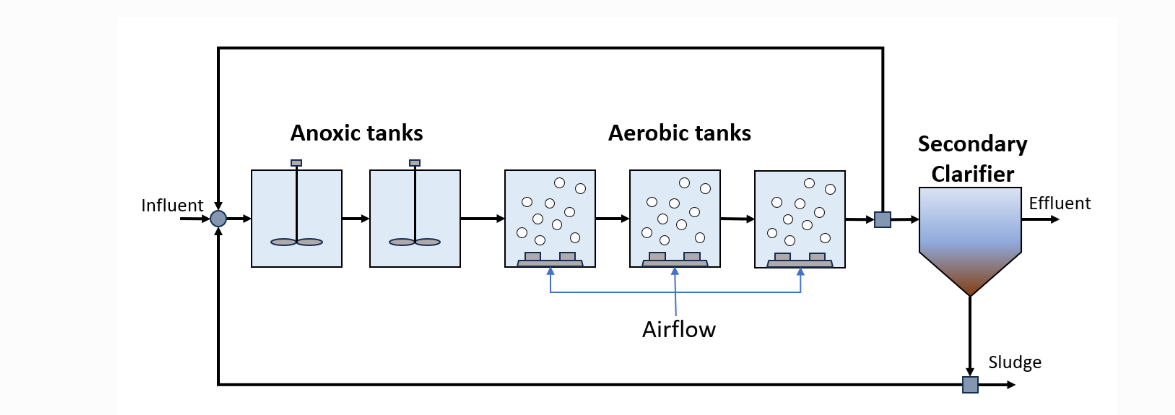
3️⃣读取进水数据和噪声数据
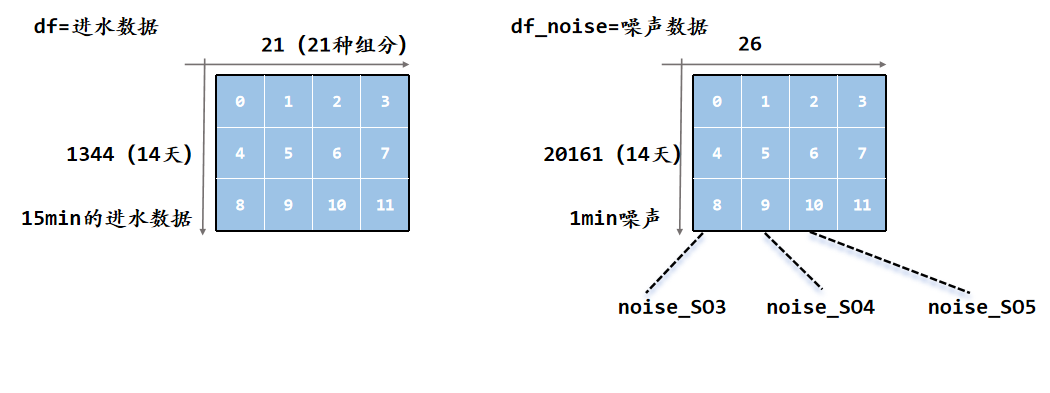
4️⃣仿真的参数设置
control (曝气控制步长)
这是曝气控制系统(PI控制器和执行器)更新指令的频率。在每个0.5分钟的control步长,控
制系统会读取溶解氧传感器的测量值,计算所需的K_La,并将其发送给执行器。由于control步长
等于integration步长,这意味着控制系统可以以最高的频率进行调整,以保持对溶解氧的实时控
制。
transferfunction (传递函数区间)
溶解氧传感器测量的并非瞬时浓度,而是过去一段时间内浓度的加权平均。transferfunction
参数定义了这个“过去一段时间”的长度。同样,执行器输出的实际K_La值也取决于其过去15分钟内
的指令序列。

5️⃣数据存储数组
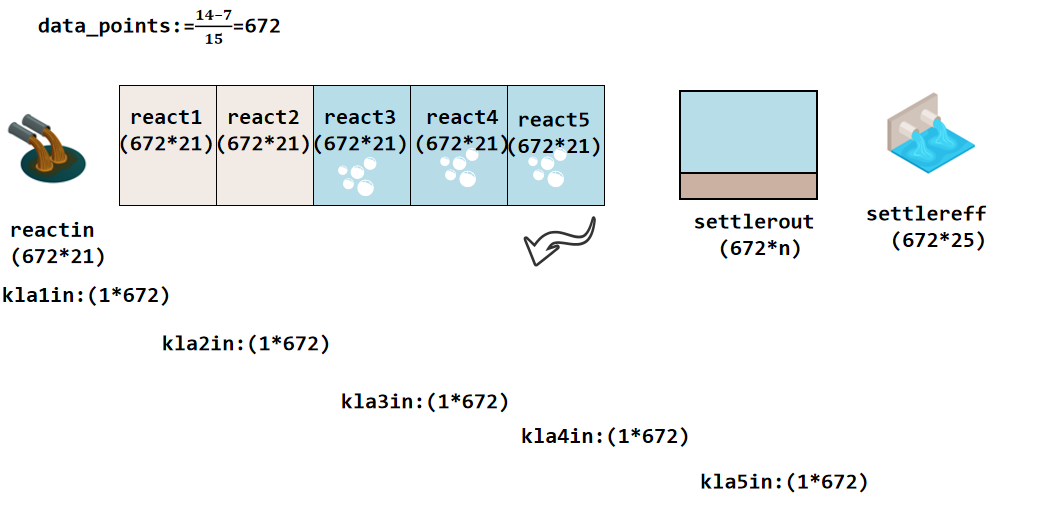
曝气控制相关变量初始化
初始值来自稳态数据

溶解氧和KLa的滑动窗口(长度=传递函数区间/控制步长 + 1,用于动态响应计算)
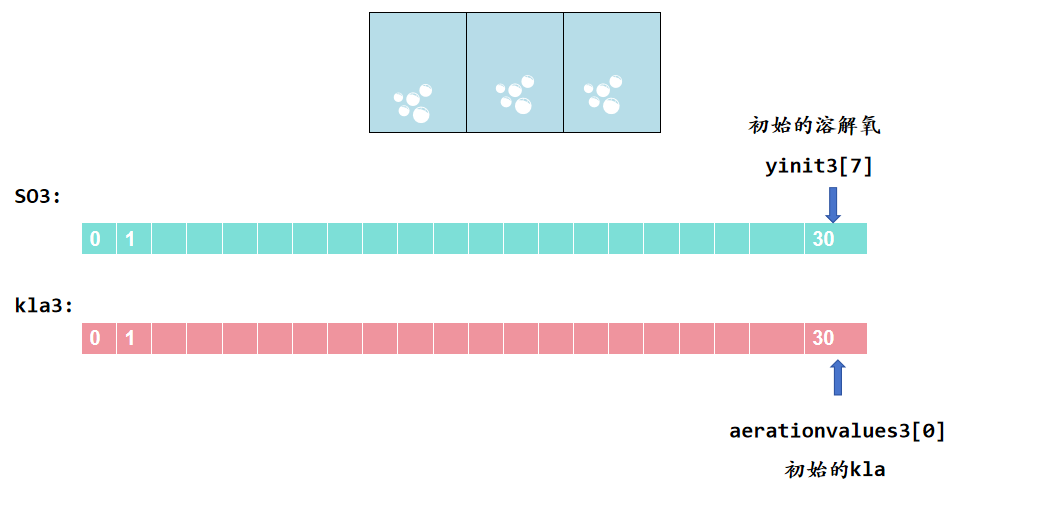
6️⃣14天预热仿真详解
这个阶段不保存任何评估数据,其核心目的是让整个污水处理厂的系统(包括反应器、沉淀池
和曝气控制)在动态变化的进水和控制策略下,从稳态初始数据平稳过渡到有代表性的动态平衡状
态。这可以消除初始数据对最终性能评估的影响。
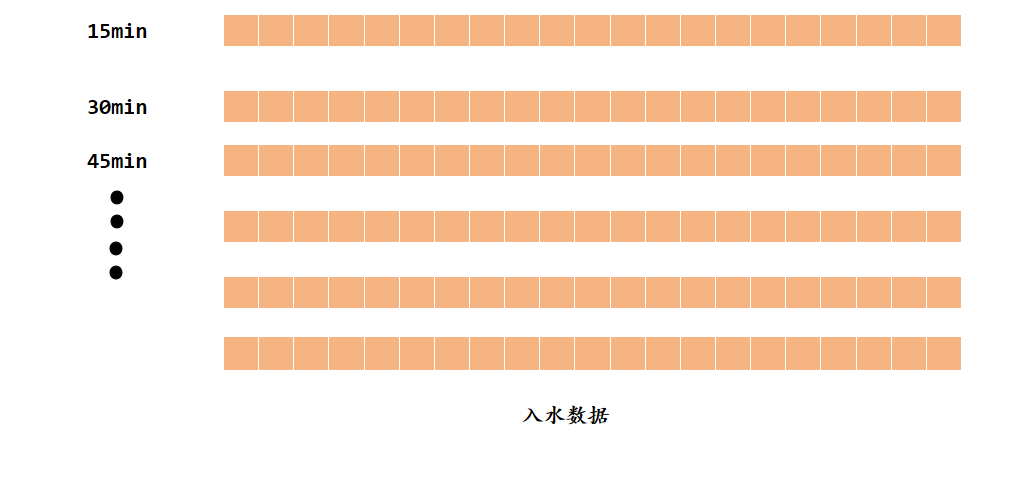
每30个积分步长,就需要读取一次新的进水数据(15min)
sample / integration=30
计算考虑内回流和外回流的进水(y_in1)
将当前计算的KLa值应用到3、4、5号反应器
依次运行5个串联反应器(前一个反应器的出水作为下一个的进水)
基于反应器出水的溶解氧浓度(第7个参数)进行反馈调节
准备进入沉淀池的混合液(反应器5的出水减去内回流)
运行沉淀池模型(泥水分离,输出回流污泥和最终出水)
重点在于kla计算的不同
control / integration=1
每1个积分步长,就需要进行kla的控制
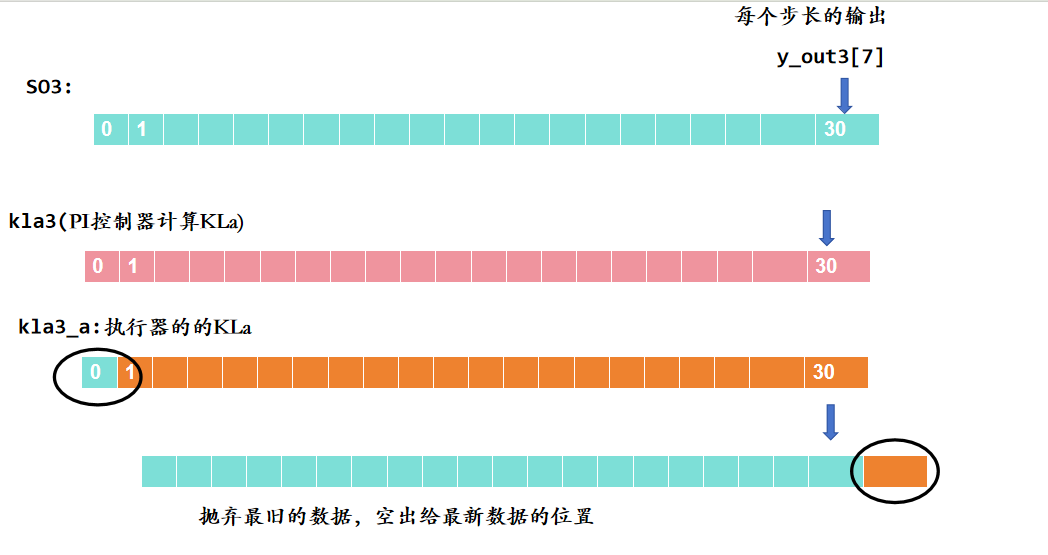
SO3[0:30] = SO3[1:31]
将 SO3 数组中索引1到30的所有值向左移动一位,覆盖了原先索引0到29的值。
7️⃣第二阶段的仿真
SO3[int(transferfunction / control) - 1] = y_out3[7] # 初始溶解氧(当前值) kla3[int(transferfunction / control) - 1] = kla3_a # 初始KLa(当前值)
系统状态(如反应器浓度和曝气控制的实际KLa)会从第一阶段的结束状态延续到第二阶段,
但像数据存储索引 (number, row)、步数计数器 (numberstep) 和控制相关的滑动窗口 (SO3, kla3 等)
都被重新初始化。
小总结
稳态仿真(第一段):建立一个可靠的初始状态,排除启动过程的干扰,确保后续仿真的准确性。
动态仿真(第二段):基于这个可靠的初始状态,引入真实的动态变化和控制策略,来模拟和评估
系统的真实性能。(完成曝气的调节)

使用ASM完成实际的应用
下面仅仅是我个人的看法,不一定正确,首先,我们实际的工厂数据是:
上面的仿真的第一步的目的是为了得到,每个池子的初始浓度,这里我们也可以根据最近一次
的平均入水,得到每个池子的初始数据。(个人也觉得可以直接从工厂中要过来)
这个是AI给的,个人不太相信:
虽然传感器能提供实时数据,但它们反映的是瞬时状态和实际运行中的波动,无法提供一个理想的、可重复的基准。稳态仿真正是为了填补这个空白而存在的。
你可以将稳态仿真看作是校准和验证模型的第一道关卡。只有当模型在稳态条件下表现良好时,我们才能相信它在模拟真实世界的复杂动态时也能给出可靠的预测。因此,在实际的工程应用中,稳态仿真是一个必不可少的步骤,它是动态分析和高级控制的基础。
我的想法是:
根据过去14天的数据,(1344条数据),计算平均入水水质。然后进行,仿真200天。获得几个池子的浓度和曝气系统的参数。
然后对过去的1344条数据进行14天的仿真,使得系统适应这种状态。获得kla和SO,然后再进行单点的时间序列预测。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 33
33 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)