深度学习入门之Torch(一)
PyTorch是主流的深度学习框架,由Facebook开发,广泛应用于计算机视觉、自然语言处理等领域。其核心数据结构是张量(Tensor),支持动态计算图、GPU加速和自动微分。文章详细介绍了张量的概念、创建方法(包括随机张量)、常见属性(如数据类型、形状)及设备切换(CPU/GPU)。此外,还讲解了张量与NumPy数组的转换(区分内存共享与不共享)、常见运算(元素级运算、矩阵乘法)以及类型转换等
一、认识Torch
PyTorch,简称Torch,是主流的经典的深度学习框架
PyTorch提供了一种灵活、高效、易于学习的方式来实现深度学习模型。PyTorch最初由Facebook开发,被广泛应用于计算机视觉、自然语言处理、语音识别等领域。
PyTorch使用张量(tensor)来表示数据,可以轻松地处理大规模数据集,且可以在GPU上加速。
PyTorch提供了许多高级功能,如自动微分(automatic differentiation)、自动求导(automatic gradients)等,这些功能可以帮助我们更好地理解模型的训练过程,并提高模型训练效率。
二、Tensor概述
PyTorch会将数据封装成张量(Tensor)进行计算。
张量可以在 GPU 上加速运行。
1.张量的概念
可以把张量(Tensor) 理解为一个多维数组。它是标量、向量、矩阵在高维空间上的推广。
| 名称 | 维度 (Dimension / Rank) | 例子 (形状) |
|---|---|---|
| 标量 (Scalar) | 0维 张量 | [ ] |
| 向量 (Vector) | 1维 张量 | [3] |
| 矩阵 (Matrix) | 2维 张量 | [2, 3] |
| 3维张量 | 3维 张量 | [2, 3, 4] |
| 更高维张量 | N维 张量 | [batch, channel, height, width] |
代码表示:
-
标量 是 0 维张量,如
a = torch.tensor(5) -
向量 是 1 维张量,如
b = torch.tensor([1, 2, 3]) -
矩阵 是 2 维张量,如
c = torch.tensor([[1, 2], [3, 4]]) -
更高维度的张量,如3维、4维等,通常用于表示图像、视频数据等复杂结构。
2.特点
-
动态计算图:PyTorch 支持动态计算图,这意味着在每一次前向传播时,计算图是即时创建的。
-
GPU 支持:PyTorch 张量可以通过
.to('cuda')移动到 GPU 上进行加速计算。import torch device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') a = torch.tensor([1, 2, 3]) print(a) a = a.to(device) print(a)
-
自动微分:通过
autograd模块,PyTorch 可以自动计算张量运算的梯度,这对深度学习中的反向传播算法非常重要。
3. 数据类型
浮点类型
-
torch.float32 或 torch.float:32位浮点数,是默认的浮点类型。
-
torch.float64 或 torch.double:64位浮点数,精度更高。
-
torch.float16 或 torch.half:16位浮点数,适用于半精度计算,常用于 GPU 加速。
整数类型
-
torch.int8:8位有符号整数。
-
torch.uint8:8位无符号整数。
-
torch.int16:16位有符号整数。
-
torch.int32:32位有符号整数。
-
torch.int64:64位有符号整数。
为什么要分为8位、16位、32位、64位呢?
场景不同,对数据的精度和速度要求不同。通常,移动或嵌入式设备追求速度,对精度要求相对低一些。精度越高,往往效果也越好,自然硬件开销就比较高。
三、tensor的创建
1.基本创建方法
1.1 torch.tensor
import torch
import numpy as np
def test001():
# 1. 用标量创建张量
tensor = torch.tensor(5)
print(tensor.shape)
# 2. 使用numpy随机一个数组创建张量
tensor = torch.tensor(np.random.randn(3, 5))
print(tensor)
print(tensor.shape)
# 3. 根据list创建tensor
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(tensor)
print(tensor.shape)
print(tensor.dtype)
if __name__ == '__main__':
test001()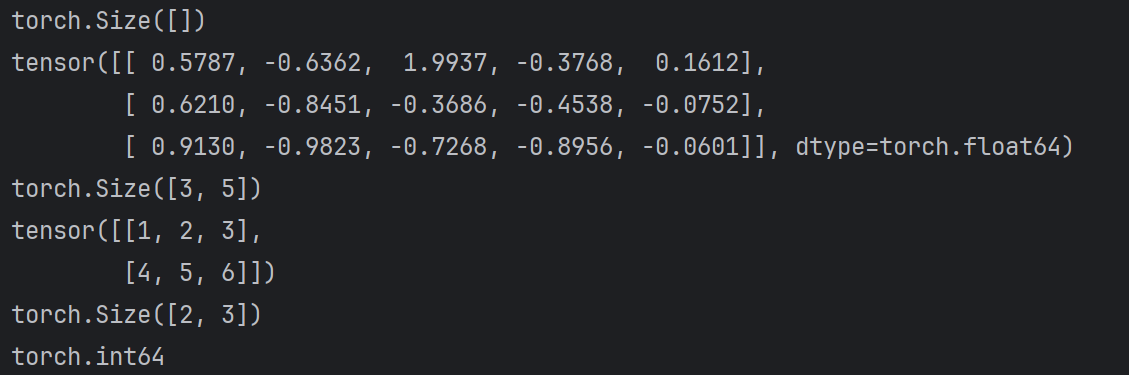
注意区分大小写,tensor和Tensor是两种不同的方法
2. torch.Tensor
import torch
import numpy as np
def test002():
# 1. 根据形状创建张量
tensor1 = torch.Tensor(2, 3)
print(tensor1)
# 2. 也可以是具体的值
tensor2 = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(tensor2, tensor2.shape, tensor2.dtype)
tensor3 = torch.Tensor([10])
print(tensor3, tensor3.shape, tensor3.dtype)
# 指定tensor数据类型
tensor1 = torch.Tensor([1,2,3]).short()
print(tensor1)
tensor1 = torch.Tensor([1,2,3]).int()
print(tensor1)
tensor1 = torch.Tensor([1,2,3]).float()
print(tensor1)
tensor1 = torch.Tensor([1,2,3]).double()
print(tensor1)
if __name__ == "__main__":
test002()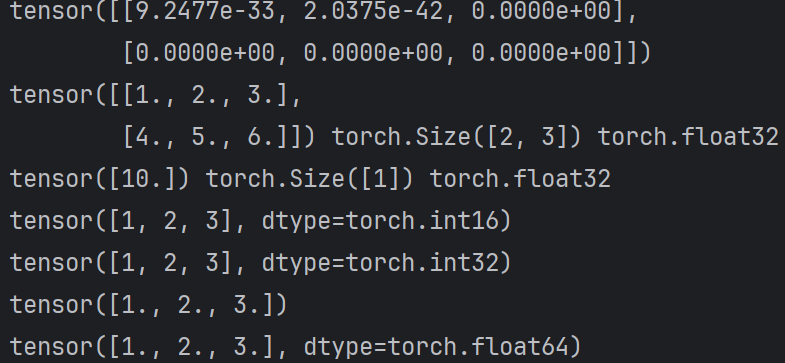
tensor和Tensor区别
| 特性 | torch.Tensor() |
torch.tensor() |
|---|---|---|
| 数据类型推断 | 强制转为 torch.float32 |
根据输入数据自动推断(如整数→int64) |
显式指定 dtype |
不支持 | 支持(如 dtype=torch.float64) |
| 设备指定 | 不支持 | 支持(如 device='cuda') |
| 输入为张量时的行为 | 创建新副本(不继承原属性) | 默认共享数据(除非 copy=True) |
| 推荐使用场景 | 需要快速创建浮点张量 | 需要精确控制数据类型或设备 |
torch.Tensor()指定dtype和device会报错
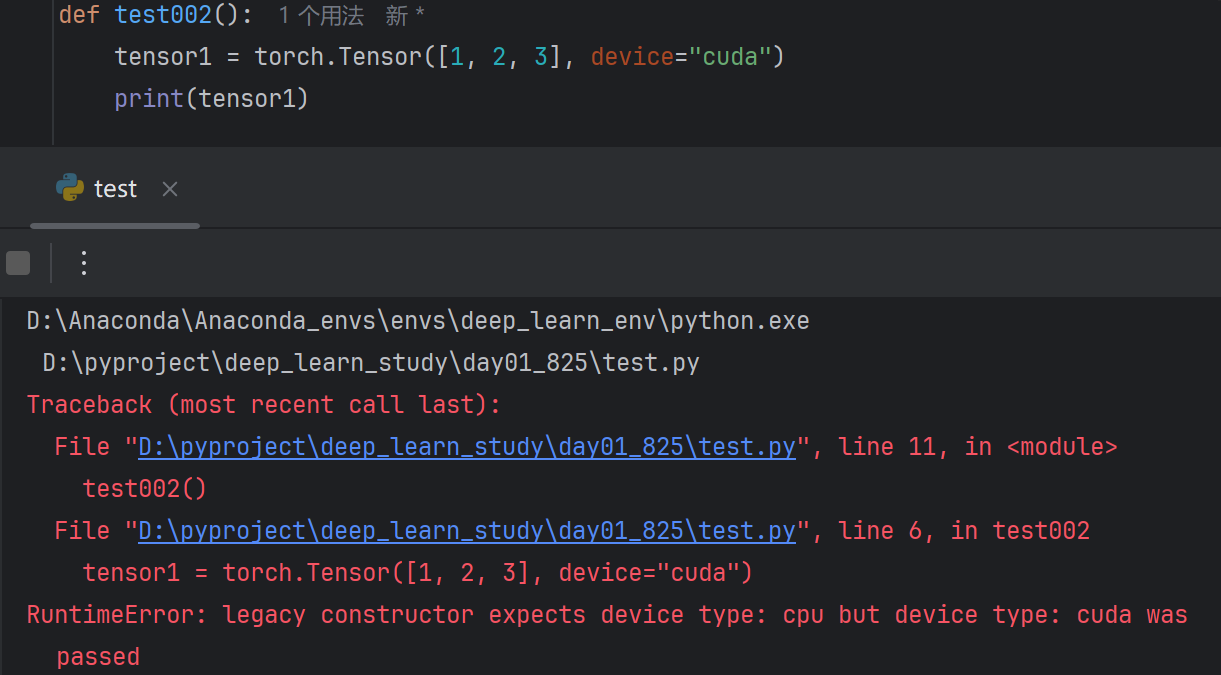
一般torch.tensor()方法使用更多
3.torch.IntTensor
用于创建指定类型的张量,还有诸如Torch.FloatTensor、 torch.DoubleTensor、 torch.LongTensor......等。
如果数据类型不匹配,那么在创建的过程中会进行类型转换,要尽可能避免,防止数据丢失。
import torch
def test003():
# 1. 创建指定形状的张量
tt1 = torch.IntTensor(2, 3)
print(tt1)
tt2 = torch.FloatTensor(3, 3)
print(tt2, tt2.dtype)
tt3 = torch.DoubleTensor(3, 3)
print(tt3, tt3.dtype)
tt4 = torch.LongTensor(3, 3)
print(tt4, tt4.dtype)
tt5 = torch.ShortTensor(3, 3)
print(tt5, tt5.dtype)
if __name__ == "__main__":
test003()
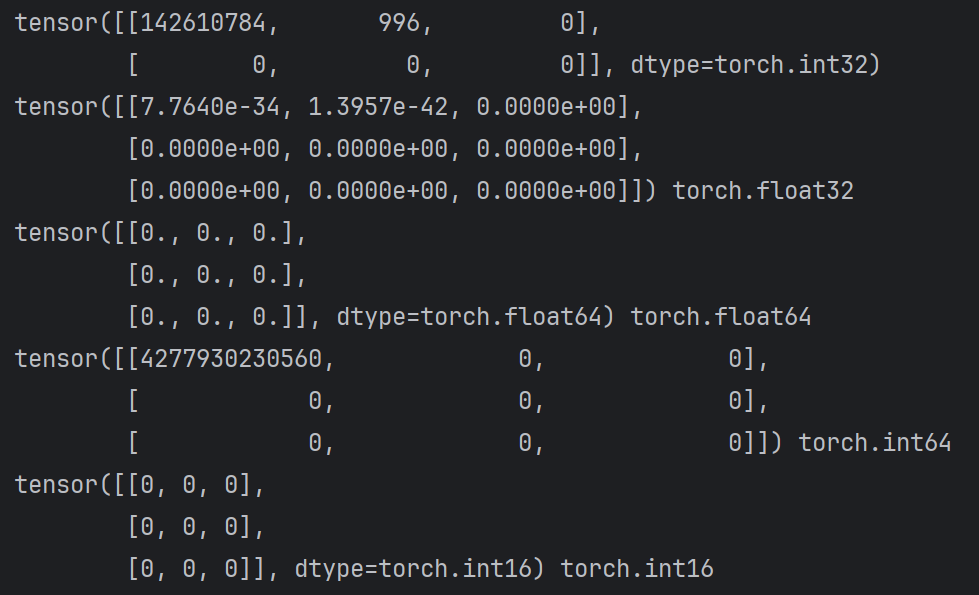
2.创建线性和随机张量
2.1 创建线性张量
使用torch.arange 和 torch.linspace 创建线性张量:
import torch
import numpy as np
# 不用科学计数法打印
torch.set_printoptions(sci_mode=False)
def test004():
# 1. 创建线性张量
r1 = torch.arange(0, 10, 2)
print(r1)
# 2. 在指定空间按照元素个数生成张量:等差
r2 = torch.linspace(3, 10, 10)
print(r2)
r2 = torch.linspace(3, 10000000, 10)
print(r2)
if __name__ == "__main__":
test004()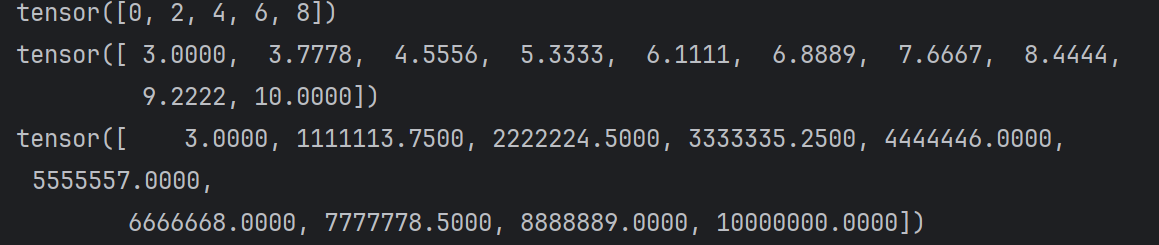
torch.arange(0, 10, 2)效果等同于range()
torch.set_printoptions(sci_mode=False)表明不使用科学计数法显示结果,去掉的话,打印结果会显示为

这样的数据会变得难以直接观察
2.2 随机张量
使用torch.randn 创建随机张量。
2.2.1 随机数种子
随机数种子(Random Seed)是一个用于初始化随机数生成器的数值。随机数生成器是一种算法,用于生成一个看似随机的数列,但如果使用相同的种子进行初始化,生成器将产生相同的数列。
随机数种子的设置和获取:
import torch
def test001():
# 设置随机数种子
torch.manual_seed(123)
# 获取随机数种子
print(torch.initial_seed())
if __name__ == "__main__":
test001()2.2.2 随机张量
在 PyTorch 中,种子影响所有与随机性相关的操作,包括张量的随机初始化、数据的随机打乱、模型的参数初始化等。通过设置随机数种子,可以做到模型训练和实验结果在不同的运行中进行复现。
import torch
def test001():
# 1. 设置随机数种子
torch.manual_seed(123)
# 2. 获取随机数种子,需要查看种子时调用
print(torch.initial_seed())
# 3. 生成随机张量,均匀分布(范围 [0, 1))
# 创建2个样本,每个样本3个特征
print(torch.rand(2, 3))
# 4. 生成随机张量:标准正态分布(均值 0,标准差 1)
print(torch.randn(2, 3))
# 5. 原生服从正态分布:均值为2, 方差为3,形状为1*4的正态分布
print(torch.normal(mean=2, std=3, size=(1, 4)))
if __name__ == "__main__":
test001()

注:不设置随机种子时,每次打印的结果不一样。
四、Tensor常见属性
张量有device、dtype、shape等常见属性
1. 获取属性
import torch
def test001():
data = torch.tensor([1, 2, 3])
print(data.dtype, data.device, data.shape)
if __name__ == "__main__":
test001()2. 切换设备
默认在cpu上运行,可以显式的切换到GPU:不同设备上的数据是不能相互运算的。
import torch
def test001():
data = torch.tensor([1, 2, 3])
print(data.dtype, data.device, data.shape)
# 把数据切换到GPU进行运算
device = "cuda" if torch.cuda.is_available() else "cpu"
data = data.to(device)
print(data.device)
if __name__ == "__main__":
test001() 
或者使用cuda进行切换:
data = data.cuda()当然也可以直接创建在GPU上:
# 直接在GPU上创建张量
data = torch.tensor([1, 2, 3], device='cuda')
print(data.device)3. 类型转换
在训练模型或推理时,类型转换也是张量的基本操作,是需要掌握的。
import torch
def test001():
data = torch.tensor([1, 2, 3])
print(data.dtype) # torch.int64
# 1. 使用type进行类型转换
data = data.type(torch.float32)
print(data.dtype) # float32
data = data.type(torch.float16)
print(data.dtype) # float16
# 2. 使用类型方法
data = data.float()
print(data.dtype) # float32
# 16 位浮点数,torch.float16,即半精度
data = data.half()
print(data.dtype) # float16
data = data.double()
print(data.dtype) # float64
data = data.long()
print(data.dtype) # int64
data = data.int()
print(data.dtype) # int32
# 使用dtype属性
data = torch.tensor([1, 2, 3], dtype=torch.half)
print(data.dtype)
if __name__ == "__main__":
test001()五、Tensor数据转换
1 张量转Numpy
此时分内存共享和内存不共享
1.1 浅拷贝
调用numpy()方法可以把Tensor转换为Numpy,此时内存是共享的。
import torch
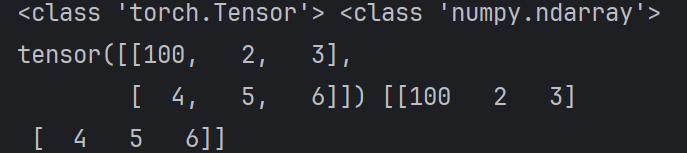
def test003():
# 1. 张量转numpy
data_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
data_numpy = data_tensor.numpy()
print(type(data_tensor), type(data_numpy))
# 2. 他们内存是共享的
data_numpy[0, 0] = 100
print(data_tensor, data_numpy)
if __name__ == "__main__":
test003()
1.2 深拷贝
使用copy()方法可以避免内存共享:
import torch
def test003():
# 1. 张量转numpy
data_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])
# 2. 使用copy()避免内存共享
data_numpy = data_tensor.numpy().copy()
print(type(data_tensor), type(data_numpy))
# 3. 此时他们内存是不共享的
data_numpy[0, 0] = 100
print(data_tensor, data_numpy)
if __name__ == "__main__":
test003()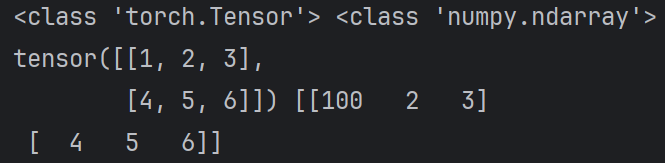
2 Numpy转张量
也可以分为内存共享和不共享
1.2.1 浅拷贝
from_numpy方法转Tensor默认是内存共享的
import numpy as np
import torch
def test006():
# 1. numpy转张量
data_numpy = np.array([[1, 2, 3], [4, 5, 6]])
data_tensor = torch.from_numpy(data_numpy)
print(type(data_tensor), type(data_numpy))
# 2. 他们内存是共享的
data_tensor[0, 0] = 100
print(data_tensor, data_numpy)
if __name__ == "__main__":
test006()
1.2.2 深拷贝
使用传统的torch.tensor()则内存是不共享的
import numpy as np
import torch
def test006():
# 1. numpy转张量
data_numpy = np.array([[1, 2, 3], [4, 5, 6]])
data_tensor = torch.tensor(data_numpy)
print(type(data_tensor), type(data_numpy))
# 2. 内存是不共享的
data_tensor[0, 0] = 100
print(data_tensor, data_numpy)
if __name__ == "__main__":
test006()
六、Tensor常见操作
在深度学习中,Tensor是一种多维数组,用于存储和操作数据,我们需要掌握张量各种运算。
1. 获取元素值
我们可以把单个元素tensor转换为Python数值,这是非常常用的操作
import torch
def test002():
data = torch.tensor([18])
print(data.item())
pass
if __name__ == "__main__":
test002()注意:
-
和Tensor的维度没有关系,都可以取出来!
-
如果有多个元素则报错;
-
仅适用于CPU张量,如果张量在GPU上,需先移动到CPU(标准的操作)
-
gpu_tensor = torch.tensor([1.0], device='cuda') value = gpu_tensor.cpu().item() # 先转CPU再提取
2. 元素值运算
常见的加减乘除次方取反开方等各种操作,带有_的方法则会替换原始值。
import torch
def test001():
# 生成范围 [0, 10) 的 2x3 随机整数张量
data = torch.randint(0, 10, (2, 3))
print(data)
# 元素级别的加减乘除:不修改原始值
print(data.add(1))
print(data.sub(1))
print(data.mul(2))
print(data.div(3))
print(data.pow(2))
# 元素级别的加减乘除:修改原始值
data = data.float()
data.add_(1)
data.sub_(1)
data.mul_(2)
data.div_(3.0)
data.pow_(2)
print(data)
if __name__ == "__main__":
test001()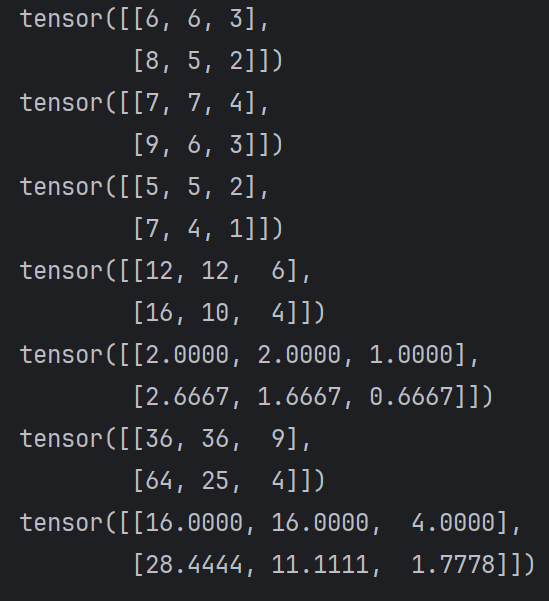
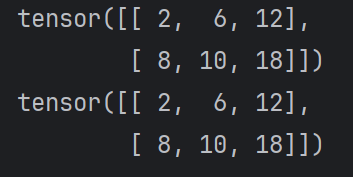
3. 阿达玛积
阿达玛积是指两个形状相同的矩阵或张量对应位置的元素相乘。它与矩阵乘法不同,矩阵乘法是线性代数中的标准乘法,而阿达玛积是逐元素操作。假设有两个形状相同的矩阵 A和 B,它们的阿达玛积 C=A∘B定义为:
其中:
-
Cij 是结果矩阵 C的第 i行第 j列的元素。
-
Aij和 Bij分别是矩阵 A和 B的第 i行第 j 列的元素。
在 PyTorch 中,可以使用mul函数或者*来实现;
import torch
def test001():
data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])
data2 = torch.tensor([[2, 3, 4], [2, 2, 3]])
print(data1 * data2)
def test002():
data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])
data2 = torch.tensor([[2, 3, 4], [2, 2, 3]])
print(data1.mul(data2))
if __name__ == "__main__":
test001()
test002()
4. Tensor相乘
矩阵乘法是线性代数中的一种基本运算,用于将两个矩阵相乘,生成一个新的矩阵。
假设有两个矩阵:
-
矩阵 A的形状为 m×n(m行 n列)。
-
矩阵 B的形状为 n×p(n行 p列)。
矩阵相乘要求第一个矩阵的列必须和第二个矩阵的行相等
矩阵 A和 B的乘积 C=A×B是一个形状为 m×p的矩阵,其中 C的每个元素 Cij,计算 A的第 i行与 B的第 j列的点积。计算公式为:
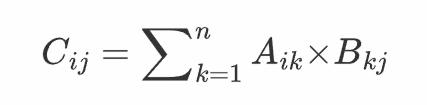
矩阵乘法运算要求如果第一个矩阵的shape是 (N, M),那么第二个矩阵 shape必须是 (M, P),最后两个矩阵点积运算的shape为 (N, P)。
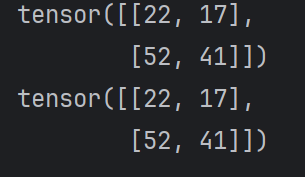
在 PyTorch 中,使用@或者matmul完成Tensor的乘法。
import torch
def test006():
data1 = torch.tensor([
[1, 2, 3],
[4, 5, 6]
])
data2 = torch.tensor([
[3, 2],
[2, 3],
[5, 3]
])
print(data1 @ data2)
print(torch.matmul(data1,data2))
# 也可以写成print(data1.matmul(data2))
if __name__ == "__main__":
test006()
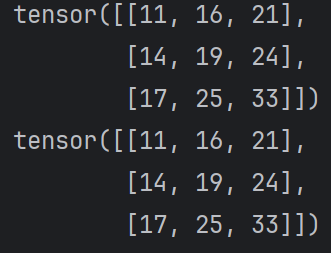
注意使用@或者matmul时,矩阵的顺序会改变运算的结果,如果调换上面的data1和data2的顺序,那么结果是3 X 2的矩阵与2 X 3的两个矩阵进行矩阵相乘,得到的结果为一个3 X 3的矩阵
技术分享是一个相互学习的过程。关于本文的主题,如果你有不同的见解、发现了文中的错误,或者有任何不清楚的地方,都请毫不犹豫地在评论区留言。我很期待能和大家一起讨论,共同补充更多细节。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)