国产化数据库怎么选?4 大维度 + 主流产品对比,小白也能懂
随着信创产业加速推进,国产化数据库从 “可用” 向 “好用” 快速迈进,市场上涌现出达梦、人大金仓、巨杉、华为高斯等数十款产品。但 “乱花渐欲迷人眼”,不少企业在选型时陷入 “跟着名气走”“只看参数表” 的误区,最终导致数据库与业务需求不匹配,反而增加运维成本。本文将从 “明确需求 — 对标技术 — 匹配产品 — 规避误区” 四个维度,教你找到最适合自己的国产化数据库。希望可以帮助到大家
第一步:先搞清楚 “我需要什么”—— 需求分析是核心
选型的本质是 “让数据库适配业务”,而非 “让业务迁就数据库”。在看产品前,必须先梳理清楚自身的核心需求,避免盲目跟风。可以从以下 4 个维度拆解:
1. 业务场景:确定数据库的 “核心使命”
不同业务场景对数据库的要求天差地别,这是选型的第一准则。比如:
交易类场景(如金融支付、电商下单):核心需求是 “强一致性” 和 “高并发”,需优先选择支持 ACID 特性、能承载每秒数千至数万笔交易的数据库,比如达梦 DM8、华为高斯 DB (for MySQL);
分析类场景(如企业报表、数据大屏):重点是 “海量数据处理” 和 “复杂查询效率”,列存数据库或 MPP 架构的产品更合适,比如人大金仓 KingbaseES Analytics、星环 Transwarp ArgoDB;
混合负载场景(如新零售的实时库存 + 销售分析):需要兼顾交易与分析,可考虑支持 HTAP(混合事务 / 分析处理)架构的数据库,比如巨杉 SequoiaDB、阿里云 AnalyticDB;
边缘场景(如工业设备数据采集):对 “轻量化” 和 “低资源占用” 要求高,可选择嵌入式数据库,比如华易达 HBaseEdge、航天科工智慧海派 EdgeDB。
2. 数据特征:明确数据库的 “承载对象”
数据的类型、量级、增长速度,直接决定数据库的存储架构和性能设计:
数据量级:若单表数据量在 1000 万以内,常规关系型数据库(如达梦、人大金仓)即可满足;若达到亿级甚至十亿级,需考虑分布式数据库(如巨杉、腾讯 TDSQL);
数据类型:如果以结构化数据(表格数据)为主,优先选关系型数据库;若包含大量非结构化数据(图片、文档)或半结构化数据(JSON、XML),文档型数据库(如阿里云 Lindorm、华为 GaussDB NoSQL)更适配;
增长速度:若数据日均增长 GB 级,需关注数据库的 “水平扩展能力”,避免后续扩容困难。
3. 合规要求:守住 “底线标准”
国产化数据库选型必须符合行业合规要求,这是不可逾越的红线:
政务、国企场景:需满足《数据安全法》《网络安全法》要求,优先选择通过 “等保三级及以上”“自主可控测评” 的产品,比如达梦 DM8、人大金仓 KingbaseES(均通过等保四级);
金融场景:除等保外,还需符合银保监会 “核心系统国产化替代” 相关要求,部分场景需通过 “金融行业专项测试”,比如华为高斯 DB、腾讯 TDSQL 已在多家银行核心系统落地;
敏感行业(如军工、能源):需选择 “全自主研发”“无外部开源依赖” 的产品,避免潜在安全风险。
4. 成本预算:平衡 “短期投入” 与 “长期运维”
成本不仅包括采购费用,还包括后续的部署、运维、培训成本:
小型企业 / 初创公司:若预算有限,可优先选择开源衍生的国产化数据库(如阿里云 PolarDB、腾讯 TDSQL),初期可按需付费,降低门槛;
中大型企业:若业务核心且对稳定性要求高,建议选择商业版数据库(如达梦、人大金仓),虽然采购成本较高,但能获得原厂的一对一技术支持,减少运维风险;
长期成本:需关注数据库的 “运维便捷性”,比如是否有可视化管理工具、是否支持自动化备份恢复,避免后续投入过多人力成本。
第二步:对标技术指标 —— 避开 “参数陷阱”
明确需求后,就需要通过技术指标筛选产品。但要注意:参数表上的 “最高值” 不等于实际使用中的 “有效值”,需结合业务场景看核心指标:
- 兼容性:降低 “迁移成本” 的关键
如果是从 Oracle、MySQL 等国外数据库迁移,“兼容性” 直接决定迁移难度:
语法兼容:优先选择支持 Oracle PL/SQL、MySQL SQL 语法的产品,比如达梦 DM8 兼容 Oracle 语法,华为高斯 DB (for MySQL) 兼容 MySQL 语法,可减少代码改写量;
工具兼容:看是否支持常用的 ETL 工具(如 DataX、Kettle)、BI 工具(如 FineBI、Tableau),避免迁移后工具无法使用。 - 高可用:保障业务 “不中断”
数据库故障可能导致业务停摆,高可用能力必须重点关注:
部署架构:支持主从复制、集群架构是基础,比如人大金仓 KingbaseES 支持 “一主多从”,巨杉 SequoiaDB 支持 “分片集群”,可实现故障自动切换;
恢复能力:看是否支持 “时间点恢复(PITR)”,比如阿里云 PolarDB 可恢复到任意时间点,避免数据丢失后无法挽回。 - 安全性:筑牢 “数据防线”
数据安全是国产化的核心诉求之一,需关注以下能力:
基础安全:支持数据加密(存储加密、传输加密)、身份认证(多因素认证)、权限控制(细粒度权限),比如达梦 DM8 支持国密算法 SM4 加密;
审计能力:能记录数据库操作日志,支持审计报表生成,满足合规审计要求,比如人大金仓 KingbaseES 的审计模块可追溯所有操作。 - 性能:匹配业务 “负载峰值”
性能测试不能只看 “TPC-C/TPC-H 跑分”,需结合自身业务场景做压力测试:
交易场景:关注 “每秒事务数(TPS)” 和 “响应时间”,比如在 1000 并发下,目标数据库的 TPS 是否能达到业务峰值需求,响应时间是否控制在 100ms 以内;
分析场景:关注 “复杂查询耗时”,比如跑一个包含多表关联、聚合计算的报表,耗时是否在可接受范围内(如 5 秒内)。
第三步:主流国产化数据库对比 —— 找到 “适配款”
目前国产化数据库市场主要分为 “关系型”“分布式”“NoSQL” 三大类,不同类别下的主流产品各有侧重,可根据需求对号入座: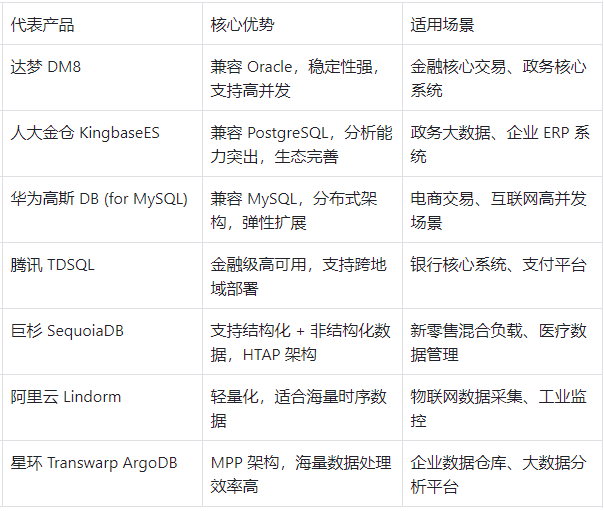
举个例子:如果是政务部门的核心业务系统,需要兼容 Oracle、满足等保四级,达梦 DM8 或人大金仓 KingbaseES 是优先选项;如果是互联网公司的电商业务,需要高并发、弹性扩展,华为高斯 DB (for MySQL) 或腾讯 TDSQL 更合适。
第四步:选型四步法 —— 落地 “不踩坑”
明确需求、对标指标、对比产品后,还需要通过实际操作验证,确保选型落地:
1. 小范围测试:用 “真实数据” 验证
不要直接上线核心业务,先搭建测试环境,用真实业务数据做验证:
迁移部分非核心数据到目标数据库,运行日常业务 SQL,观察兼容性和性能;
模拟故障场景(如主库宕机、网络中断),测试高可用切换是否正常,数据是否丢失。
2. 评估生态:看 “长期支持”
数据库不是孤立的产品,生态成熟度决定后续使用体验:
原厂支持:了解厂商的技术支持能力,比如是否有 7×24 小时服务、是否有本地化服务团队,避免出现问题后无人响应;
社区活力:如果选择开源衍生产品,关注社区活跃度(如 GitHub 星数、issue 解决速度),确保后续能获得持续的版本更新。
3. 制定迁移计划:分 “阶段落地”
如果是从国外数据库迁移,建议分阶段进行:
第一阶段:非核心业务迁移(如报表系统),积累经验;
第二阶段:核心业务灰度迁移(如部分用户的交易业务),观察稳定性;
第三阶段:全量迁移,完成替代。
4. 团队培训:让 “人” 适配新工具
数据库选型后,需对技术团队进行培训:
厂商提供的产品培训(如语法、运维工具使用);
实际操作演练(如备份恢复、故障处理),确保团队能独立运维。
第五步:避开常见误区 —— 少走 “弯路”
最后,总结几个选型中常见的误区,帮你规避风险:
误区一:只看 “名气” 不看 “适配”
有些企业盲目选择市场占有率高的产品,但忽略自身业务场景。比如用分析型数据库做交易业务,导致性能不足。记住:没有 “最好” 的数据库,只有 “更适合” 的数据库。
误区二:忽视 “生态” 只看 “产品”
有些产品参数优秀,但生态不完善(如工具少、文档缺、支持弱),后续运维中会遇到大量问题。比如某小众数据库,虽然性能达标,但不支持常用的 BI 工具,最终只能放弃。
误区三:追求 “一步到位”
有些企业希望一次选型解决所有问题,但业务是动态变化的。建议按需选型,预留扩展空间,比如选择支持分布式架构的产品,后续数据量增长时可随时扩容。
总结
国产化数据库选型不是 “拍脑袋” 的决策,而是 “需求 — 技术 — 产品 — 落地” 的系统性工程。关键在于:先明确自身业务场景、数据特征、合规要求,再对标核心技术指标,通过小范围测试验证,最后分阶段落地。只要遵循这个逻辑,就能找到最适合自己的国产化数据库,为业务发展筑牢数据基石。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)