【基础篇】数据分析与建模新手小白自学全流程完整指南!!
设计“教师教学能力问卷”,通过专家评审确保题项覆盖“备课能力”“课堂管理”等内容(内容效度),通过因子分析验证题项是否分成“专业能力”和“沟通能力”两个维度(结构效度),并与“学生成绩提升率”(效标)关联,验证问卷有效性。对“客户满意度”的10个题项(如“产品质量”“物流速度”“客服态度”等)进行因子分析,提取出2个潜在因子:“产品体验因子”(与质量、价格相关)和“服务体验因子”(与物流、客服相关
目录
什么是数据分析与建模?
数据分析是指对数据到的原始数据进行清洗、转换、统计与分析。数学建模是用数学式子或者算法等构建能够反映数据内在关系的模型。
一、数据分析的步骤?
1、数据收集
第一步数据收集。根据想要分析的目的,用合适的方法收集相关的数据。
2、数据预处理
第二步数据预处理。对数据进行清洗,常见的有重复值,缺失值,异常值,数据平衡,数据变换等。
3、选择合适的统计分析
第三步选择合适的统计分析,完成数据清洗后,选择合适的统计方法分析。
二、常见的统计分析方法
1、描述统计分析
用统计量或者可视化图表概括数据特征。
数据特征通常指的是集中趋势、离散程度、分布形态。
例如:用均值来看每日锻炼的平均时长,用条形图来统计一周内每天销售衣服的数量。
2、推断统计分析
基于样本的数据推断总体的规律,利用假设检验来验证关系。
(1)参数估计用样本数据估计总体的未知参数。
例子:用1000用户的满意度来估计整体用户的满意度。
(2)假设检验验证关于总体的假设是否成立。有参数检验与非参数检验。
这里我们讨论的是参数检验。参数检验与非参数检验区别在于数据是否要满足某种特定的分布形式。
(一)T检验
T检验通常包单样本t检验、独立样本t检验、配对样本t检验。
01、单样本t检验
1.适用场景:检验单个样本的均值是否与某个已知的总体均值存在显著差异。
2.前提:样本数据需要近似服从正态性分布。
3.例子:某班级学生的数学平均分(样本)是否与全国中学生的数学平均分(总体已知值)有显著不同。
02、两独立样本t检验
1.适用场景:比较两个独立分组的总体均值是否存在显著差异(两组数据来自不同的样本,彼此无关)。
2.前提:两组数据需满足正态分布、方差齐性(若方差不齐,改用Welcht检验)。
3.例子:比较A品牌和B品牌手机的平均续航时间(两组用户分别使用不同品牌,相互独立)。
03、配对样本t检验
1.适用场景:比较同一组样本在两种不同条件下的均值差异(需要注意的是:两组数据来自同一批样本,存在配对关系)。
2.前提:两组配对样本均服从正态性分布。
3.例子:同一批患者在服药前和服药后的血压均值差异;
(二)方差分析
方差分析通常有重复测量方差分析与多因素方差分析
01、单因素方差分析
1.适用场景:比较三个及以上独立分组的总体均值是否存在显著差异
2.前提:各组数据近似服从正态分布;各组数据的总体方差齐性(可通过Levene检验验证);观测值相互独立(各组样本无重叠,组内数据无关联)。
3.例子:比较A、B、C三个品牌饮料的平均甜度是否存在显著差异(自变量为“品牌”,分3组)。
02、多因素方差分析
1.适用场景:分析两个及以上自变量对因变量的影响以及自变量之间的交互作用
2.前提:满足单因素方差分析的所有前提(正态性、方差齐性、独立性);各因素的水平组合下样本量可相等或不等。
3.例子:分析“促销方式(买一送一/满减)”和“城市级别(一线/二线)”对产品销量的影响,同时判断“促销方式的效果是否因城市级别不同而变化”(交互作用)。
03、重复测量方差分析
1.适用场景:比较同一组样本在不同时间点或不同条件下的因变量均值差异(自变量为“时间”或“重复测量的条件”,样本存在重复测量关系)。
2.前提:每个时间点/条件下的测量数据近似服从正态分布;满足“sphericity(球形假设)”(即不同时间点之间的差异方差相等,可通过Mauchly检验验证,不满足时需校正);样本内的重复测量数据相关,样本间相互独立。
3.例子:跟踪同一批患者在服药1周、2周、4周后的血压值,分析不同时间点的血压均值是否存在显著差异。
(三)卡方检验
卡方检验是一种基于卡方统计量的非参数检验方法
1.适用场景:用于分析分类数据之间的关联性或独立性,判断实际观测结果与理论预期结果是否存在显著差异。常见于两个或多个分类变量的关系检验。
2.前提:数据为分类数据;样本量足够大;观测值相互独立。
01、卡方独立性检验
1.核心目的:检验两个分类变量是否独立(即一个变量的取值不影响另一个变量的分布)。
2.例子:分析“性别(男/女)”与“购物偏好(线上/线下)”是否独立,即不同性别的用户在购物渠道选择上是否存在显著差异。
02、卡方拟合优度检验
1.核心目的:检验某个分类变量的实际观测频数分布是否与理论预期分布一致(如是否符合均匀分布、已知比例分布等)。
2.例子:某品牌声称其产品的三个口味(A/B/C)销量占比为3:3:4,通过收集实际销量数据,检验观测到的销量比例是否与声称的比例一致。
03、卡方同质性检验
1.核心目的:检验多个独立样本的分类变量分布是否一致(即不同群体在某个分类特征上的分布是否存在差异)。
2.例子:比较来自三个不同地区(A/B/C)的消费者对某产品的“好评/中评/差评”分布是否存在显著差异,判断地区是否影响评价分布。
(四)相关分析与回归分析
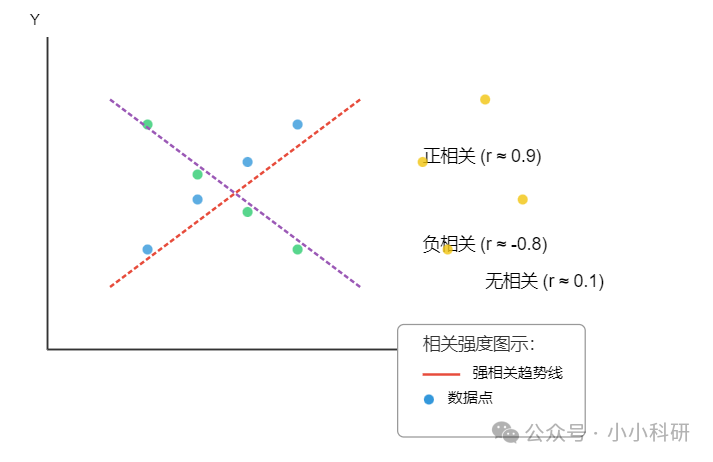
01、相关分析
相关分析用相关系数衡量两个变量的关联程度
例子:用皮尔逊相关系数衡量广告投入与销售额之间的关系。
02、回归分析
回归分析建立自变量对因变量的数学关系。常见线性回归与逻辑回归。
例子:用一元线性回归探究住房面积与房子的价格之间的关系。

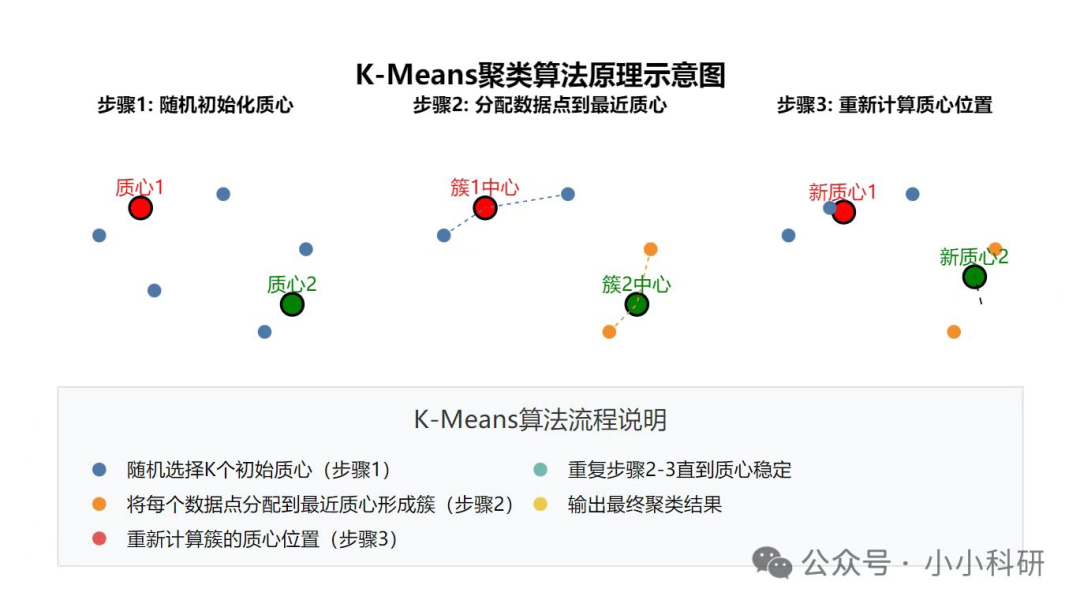
(五)聚类分析
聚类分析是属于无监督学习。事先不知道数据的类别,通过算法自动将数据按相似度(如距离、相关性)分组,让组内数据差异小、组间差异大。
1.本质:“探索性分类”,从数据中发现潜在的类别结构。
2.常用算法:
K-means聚类(指定聚类数量,快速分组)
层次聚类(生成树状图,展示类别间的层次关系)
DBSCAN(基于密度,能识别任意形状的簇)
往期回顾:
关注【小小科研】公众号,了解更多详细内容!
高斯混合聚类
3.例子:
对客户消费数据聚类,发现“高消费高频”“低消费低频”等潜在客户群体;
(六)判别分析
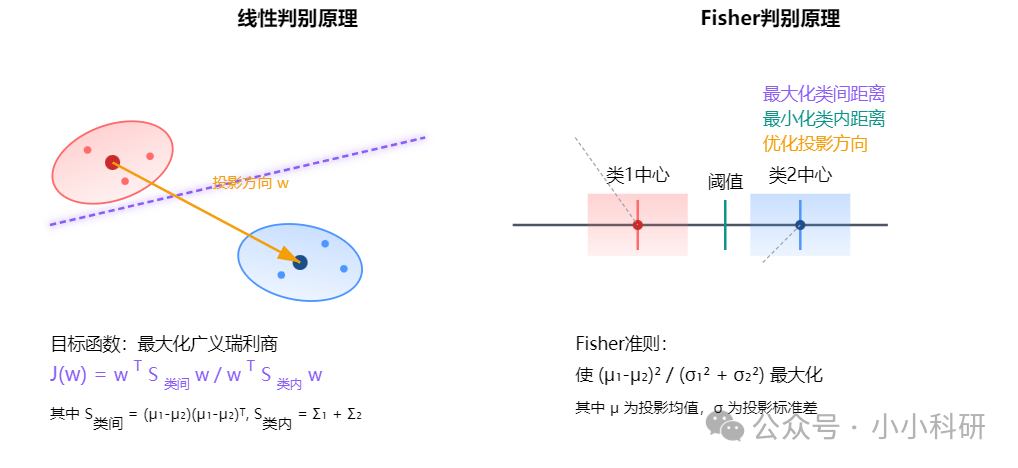
判别分析是属于监督学习。已知数据的类别标签,通过建立数学模型(判别函数),学习类别与特征间的关系,用于对新样本进行分类预测。
1.本质:“验证性分类”,基于已知类别训练模型,实现对未知样本的归类。
2.常用方法:
①Fisher判别分析(找到最优分类线,使组内差异最小、组间差异最大)
②贝叶斯判别分析(基于概率,计算新样本属于各类别的后验概率,选择概率最大的类别)
③逐步判别分析
3.例子:已知一批客户的“流失/未流失”标签,用其消费、活跃度等特征建立判别模型,预测新客户是否会流失。基于患者的症状数据(已知“患病类型”),建立模型判断新患者的患病类型。
(七)其他统计分析
三、信度与效度分析
1、信度分析
检验衡量测量工具的稳定性和一致性,用于测量结果是否可信
1.适用场景:问卷、量表类数据的质量评估
2.常用方法:内部一致性信度:最常用,检验同一量表内多个题项是否测量同一概念,常用指标:
①Cronbach'sα系数:适用于Likert量表(如“非常同意-非常不同意”),α值越高(通常≥0.7),内部一致性越好;若α值过低,需删除相关性低的题项。
②分半信度:将量表题项随机分为两半,计算两半得分的相关系数,反映两半题项的一致性。
3.例子:一份“员工敬业度量表”包含8个题项,通过计算Cronbach'sα系数为0.85,说明题项内部一致性良好,测量结果可靠。
2、效度分析
衡量测量工具是否准确测量了其预期要测量的概念,确保测量工具的有效性。
1.适用场景:评估新量表/问卷的有效性
2.常用的效度类型:
①内容效度:主观评估量表题项是否全面覆盖了目标概念的所有方面,通常通过专家评审或预调查验证。
②结构效度:检验测量结果是否符合理论预期的“结构”。常用:
探索性因子分析(EFA):通过降维提取潜在因子,检验题项是否按理论预期聚类。
验证性因子分析(CFA):用结构方程模型验证观测数据是否符合预设的理论结构。
3.例子:设计“教师教学能力问卷”,通过专家评审确保题项覆盖“备课能力”“课堂管理”等内容(内容效度),通过因子分析验证题项是否分成“专业能力”和“沟通能力”两个维度(结构效度),并与“学生成绩提升率”(效标)关联,验证问卷有效性。
四、主成分分析与因子分析
主成分分析与因子分析两者均为多元统计方法,用于处理多变量数据的降维和潜在关系探索,是数据简化和结构分析的重要工具。
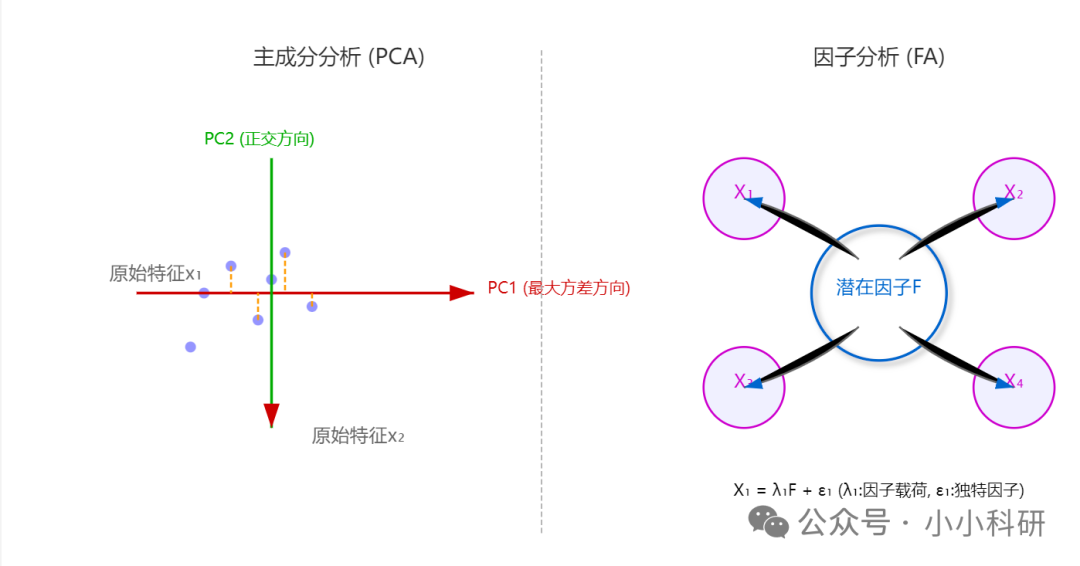
1、主成分分析(PCA)
1.定义:将多个相关的原始变量转换为少数几个不相关的综合变量(称为“主成分”),这些主成分尽可能保留原始变量的信息(即方差)。
2.核心目的:降维,用较少的主成分代替多个原始变量,减少数据复杂度。
3.原理:通过线性变换,找到原始变量空间中方差最大的方向(第一主成分),再在与第一主成分垂直的方向上找方差次大的方向(第二主成分),依次类推,直到主成分包含足够多的原始信息(如累计方差贡献率≥85%)。
4.适用场景:变量数量多且相关性高时;消除变量间的多重共线性.
5.例子:学生成绩包含语文、数学、英语、物理、化学5科,用PCA提取2个主成分,其中第一主成分可能代表“理科能力”(数学、物理、化学权重高),第二主成分代表“文科能力”(语文、英语权重高),用这2个主成分概括学生的整体学习水平。
2、因子分析
1.定义:假设存在一些不可直接观测的潜在因子,原始变量的变异由这些潜在因子和变量自身的独特因子共同解释,目的是提取这些潜在因子并解释变量间的相关性。
2.核心目的:探索数据背后的潜在结构或共同驱动因素,解释“变量为何相关”。
3.原理:通过估计因子载荷,确定每个变量受哪些潜在因子影响,进而命名因子。
4.适用场景:探索变量间的潜在机制;检验量表的结构效度。
5.例子:对“客户满意度”的10个题项(如“产品质量”“物流速度”“客服态度”等)进行因子分析,提取出2个潜在因子:“产品体验因子”(与质量、价格相关)和“服务体验因子”(与物流、客服相关),解释客户满意度的核心驱动因素。
五、时间序列分析
用于分析按时间顺序排列的数据,揭示其变化规律并预测未来趋势。
1.核心:描述时间序列的特征,识别数据背后的变化规律,基于历史数据预测未来值。
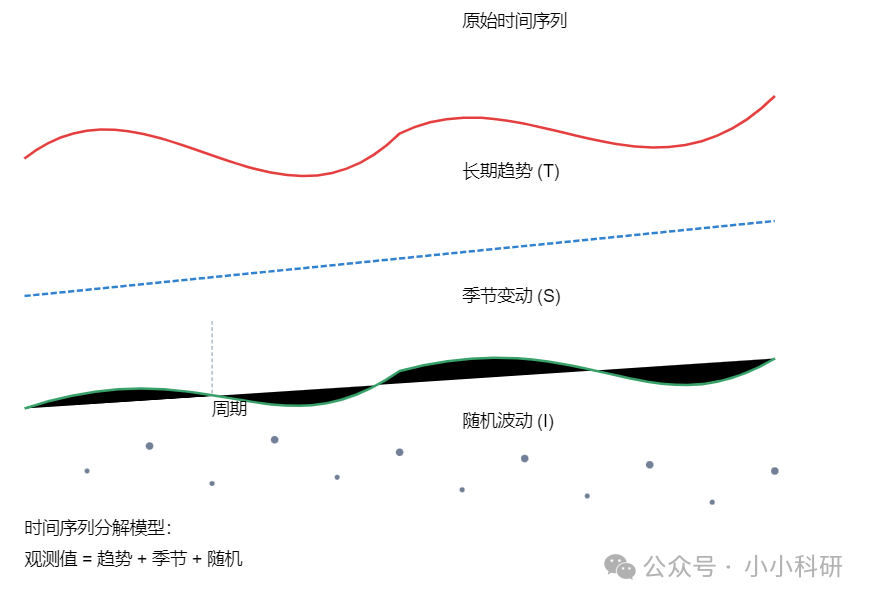
2.时间序列的基本组成成分:
①趋势:数据在长期内的整体变化方向。
②季节性:数据在固定周期内(如每年、每月、每周)重复出现的波动。
③周期性:数据在非固定周期内的波动。
④随机波动:无法预测的、偶然的短期波动。
3.适用场景:预测:如股票价格、电力负荷、商品销量、疾病发病率等。
监控:如检测工业生产中的异常波动。
1、常用分析方法
(一)描述性分析:
①可视化:用折线图展示数据随时间的变化,直观观察趋势和波动。
②平滑处理:通过移动平均消除短期随机波动,突出趋势。
(二)平稳性检验:
许多时间序列模型要求数据“平稳”(即均值和方差不随时间变化),常用ADF检验 验证平稳性;若不平稳,需通过“差分”处理为平稳序列。
(三)建模与预测方法:
传统时间序列模型:ARIMAProphet
机器学习算法:随机森林Lstm
往期回顾:
关注【小小科研】公众号,了解更多详细内容!
4.例子:分析某超市过去3年的月度销量数据,发现存在“每年12月销量高峰”(季节性)和“整体逐年增长”(趋势),用ARIMA(1,1,1)模型预测未来6个月的销量。
六、生存分析
生存分析是一种专门用于研究事件发生时间的统计方法,核心是分析“从某个起始点到特定事件发生所经历的时间”及其影响因素。
1.适用场景:分析“事件发生时间”数据,关注事件何时发生及影响因素(如产品失效时间、患者存活时间、用户流失时间)。
2.常用方法:
①Kaplan-Meier曲线(绘制生存概率随时间的变化,比较不同组的生存差异);
②Cox比例风险模型(分析多个自变量对事件发生风险的影响,如年龄、治疗方式对患者死亡风险的影响)。
3.前提:数据包含“事件是否发生”和“发生时间”(若事件未发生则为“缺失数据”),且满足Cox模型的“比例风险假设”(风险比不随时间变化)。
4.例子:用Kaplan-Meier曲线比较两种癌症治疗方案的患者1年、3年生存率差异;
往期回顾:
三分钟讲透一个模型——生存分析模型三分钟讲透一个模型——生存分析模型![]() https://mp.weixin.qq.com/s/o4ZdI9E6UOOPzeVcg4kQLg
https://mp.weixin.qq.com/s/o4ZdI9E6UOOPzeVcg4kQLg
关注【小小科研】公众号,后台回复,可获取电子讲义哦!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 34
34 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)