【深度学习|学习笔记】Adam 和 SGD 是深度学习里最常用的两类优化器,详解它们的使用场景和效果差别?
·
【深度学习|学习笔记】Adam 和 SGD 是深度学习里最常用的两类优化器,详解它们的使用场景和效果差别?
【深度学习|学习笔记】Adam 和 SGD 是深度学习里最常用的两类优化器,详解它们的使用场景和效果差别?
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/148877490
1. SGD(随机梯度下降)
特点
- 更新公式(带 Momentum):
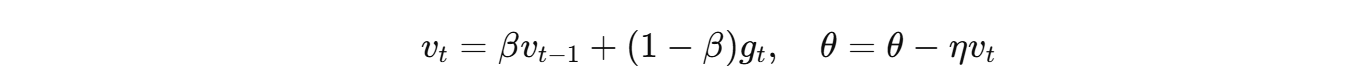
- 每个参数的学习率相同,依赖手工调整。
- 更容易获得好的泛化性能,常用于大规模任务(如 ImageNet 训练)。
- 收敛速度相对慢,尤其是在高维或稀疏梯度情况下。
适用场景
- 大规模计算机视觉任务(CNN 在图像分类、目标检测)。
- 当你更关心最终泛化性能而不是快速收敛。
- 当有较大的数据集,调参资源足够时。
2. Adam(Adaptive Moment Estimation)
特点
- 更新公式带自适应学习率:
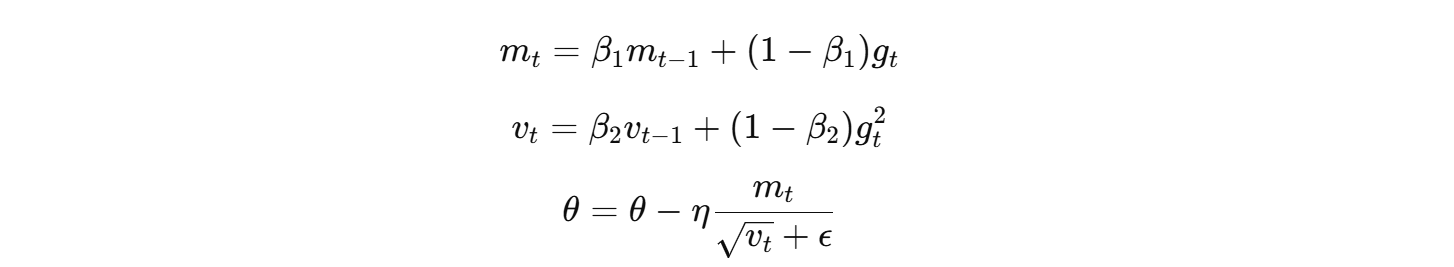
- 每个参数都有独立的自适应学习率。
- 收敛快,对稀疏梯度和非平稳目标特别友好。
- 有时泛化性能不如 SGD。
适用场景
- NLP(Transformer、BERT、GPT 等模型)
- 小数据集或稀疏特征场景
- 希望模型快速收敛,调参资源有限
- 初始训练阶段用 Adam,后期可切换到 SGD 微调
3. 代码演示(PyTorch)
- 我们在同一个简单神经网络上对比 Adam 和 SGD 的使用:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 简单的MLP网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 数据
transform = transforms.ToTensor()
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('.', train=True, download=True, transform=transform),
batch_size=64, shuffle=True
)
# 初始化网络
model_sgd = SimpleNN()
model_adam = SimpleNN()
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer_sgd = optim.SGD(model_sgd.parameters(), lr=0.01, momentum=0.9)
optimizer_adam = optim.Adam(model_adam.parameters(), lr=0.001)
# 训练循环对比
for epoch in range(3):
for (data, target) in train_loader:
# SGD
optimizer_sgd.zero_grad()
output_sgd = model_sgd(data)
loss_sgd = criterion(output_sgd, target)
loss_sgd.backward()
optimizer_sgd.step()
# Adam
optimizer_adam.zero_grad()
output_adam = model_adam(data)
loss_adam = criterion(output_adam, target)
loss_adam.backward()
optimizer_adam.step()
4. 什么时候用 Adam,什么时候用 SGD?
- 快速原型/调试:Adam(收敛快,鲁棒)
- NLP/Transformer:Adam(稀疏梯度,自适应学习率很关键)
- 大规模图像任务:SGD + Momentum(泛化性能更好)
- 训练策略:先用 Adam 训练收敛 → 再切换 SGD 微调,可以兼顾速度和泛化
✅ 总结:
- Adam:快,适合稀疏梯度,适合 NLP、小数据。
- SGD:稳,泛化好,适合 CV、大数据。
- 组合策略:Adam 起步,SGD 收尾。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)