吊打传统算法!卡尔曼滤波+强化学习,目标跟踪精度暴增50%!
强化学习与卡尔曼滤波的交叉研究成为2025年前沿热点。最新研究表明,将卡尔曼滤波层嵌入强化学习框架能有效处理部分可观测环境下的不确定性,在非线性系统中显著优于传统方法。两大突破性成果显示:1)独立卡尔曼滤波层可实现端到端训练,在混沌系统中降低预测误差达30%;2)深度强化学习框架在非高斯数据处理上超越传统EnKF算法。该方向已形成三大技术路线:粒子融合、鲁棒建模和不确定性蒸馏,相关代码和论文资源已
强化学习×卡尔曼滤波,2025最硬核的交叉风口已经炸场!
强化学习能够根据环境反馈动态调整策略,而卡尔曼滤波则擅长处理噪声数据和状态估计,两者的结合让模型在处理复杂动态系统时更加高效和精准。
想抢下一篇顶会?锁定这三大黄金赛道:①非线性观测下的粒子RL-KF融合,②运动扰动中的鲁棒KF奖励建模,③端到端KF策略正则化与不确定性蒸馏。
我熬夜整理了10篇相关的前沿论文,顶会/顶刊论文+部分官方代码打包免费送,全部论文PDF版+开源代码,工种号 沃的顶会 扫码回复 “强化卡尔曼” 领取。
Uncertainty Representations in State-Space Layers for Deep Reinforcement Learning under Partial Observability
文章解析
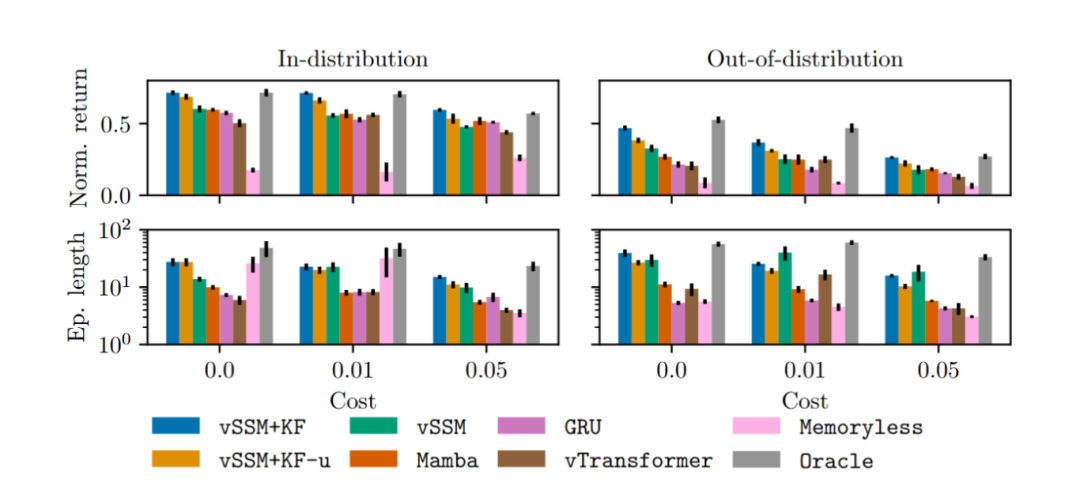
本文提出了一种独立的卡尔曼滤波层,该层在模型无关的架构中进行端到端训练,以处理部分可观测环境下的不确定性。该层能够进行显式的概率过滤,处理隐状态的不确定性,并在需要不确定性推理的任务中表现出色。
创新点
提出了一种独立的卡尔曼滤波层,可以在模型无关的强化学习架构中进行端到端训练。
卡尔曼滤波层可以作为其他循环层的直接替代品,同时包含显式的概率过滤机制。
实验表明,卡尔曼滤波层在需要不确定性推理的任务中显著优于确定性的状态模型。
研究方法
设计了一个独立的卡尔曼滤波层,用于线性状态空间模型中的高斯推断。
将卡尔曼滤波层嵌入到模型无关的强化学习架构中,与策略优化器结合使用。
通过并行扫描处理序列数据,使得计算复杂度对序列长度呈对数增长。
在多种部分可观测任务中进行了实验验证,评估了卡尔曼滤波层的性能。
研究结论
卡尔曼滤波层在需要不确定性推理的任务中表现优异,显著优于其他确定性的状态模型。
卡尔曼滤波层可以作为标准循环层的直接替代品,且易于与其他组件结合使用。
显式的概率推断机制为部分可观测环境下的决策提供了有效的支持。
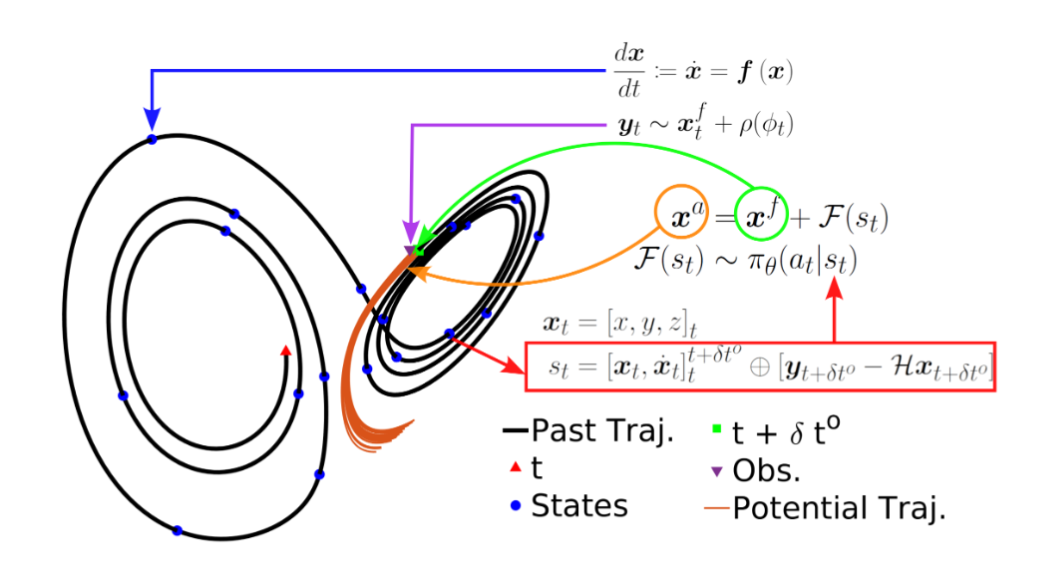
Data Assimilation in Chaotic Systems Using Deep Reinforcement Learning
文章解析
本文提出了一种新的数据同化策略,利用深度强化学习(RL)对混沌系统进行状态修正。通过在Lorenz'63系统上的实验,证明了该方法能够有效减少观测值与预测状态之间的均方根误差,并且在非高斯数据同化方面表现优于传统的集合卡尔曼滤波器(EnKF)。
创新点
引入深度强化学习(RL)进行数据同化,提高了型在未训练场景中的适应能力。
提出了基于随机行动策略的蒙特卡洛数据同化框架,生成集成同化实现。
展示了RL算法在处理非高斯数据方面的优势,解决了EnKF的一个重要局限。
研究方法
利用深度强化学习(RL)对混沌系统的状态变量进行全或部分观测,以最小化观测值与预测状态之间的均方根误差。
通过在Lorenz'63系统上的实验,验证了RL代理在不同场景下的性能。
采用随机行动策略,通过随机采样生成集成同化实现,形成蒙特卡洛数据同化框架。
研究结论
提出的RL算法在性能上优于传统的EnKF,特别是在处理非高斯数据时。
RL提供了一个新的框架,用于基于观测数据对预测进行非线性修正,增强了模型的预测能力。
研究结果表明,RL代理能够有效地应对未训练场景,提高了数据同化的鲁棒性和适应性。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)