基于深度学习的模板匹配技术:理论、方法与实现
摘要:本文系统探讨了深度学习在计算机视觉模板匹配任务中的应用。首先分析了传统模板匹配方法的局限性,然后详细介绍了基于卷积神经网络、孪生网络和注意力机制的深度学习方法,包括SiameseFC、SiamRPN等典型算法。文章提供了完整的PyTorch实现代码,涵盖数据预处理、网络架构设计、损失函数选择及训练流程,并通过实验验证了深度学习模板匹配的高精度和强鲁棒性。最后讨论了该技术在工业检测、安防监控等
摘要
模板匹配作为计算机视觉领域的基础任务之一,旨在从图像中定位与给定模板相似的区域。传统方法在面对光照变化、尺度变换、旋转干扰等复杂场景时表现受限。近年来,随着深度学习技术的快速发展,基于深度神经网络的模板匹配方法在精度和鲁棒性上取得了显著突破。本文系统阐述了深度学习在模板匹配任务中的应用,详细介绍了基于卷积神经网络、孪生网络、注意力机制等的模板匹配方法,分析了各方法的原理、优势及局限性,并通过完整代码实现验证了典型方法的有效性。本文旨在为相关研究人员和工程实践者提供全面的技术参考,推动深度学习在模板匹配领域的进一步发展与应用。
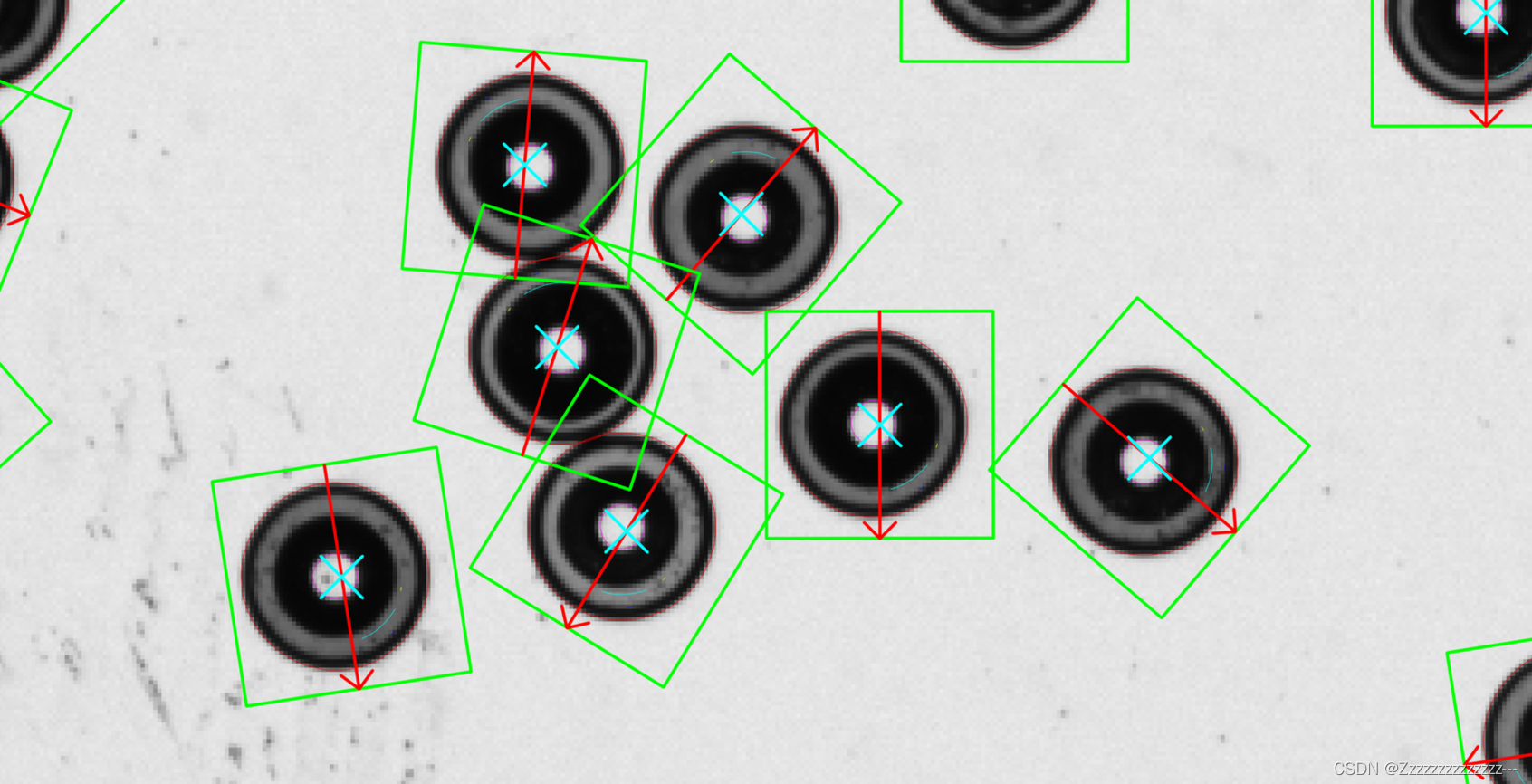
关键词:模板匹配;深度学习;卷积神经网络;孪生网络;计算机视觉
1. 引言
1.1 模板匹配的定义与意义
模板匹配是计算机视觉中最基础且应用广泛的任务之一,其核心目标是在源图像(待检测图像)中寻找与模板图像(已知目标图像)最相似的区域。从本质上讲,模板匹配属于模式识别的范畴,通过度量图像间的相似性来实现目标定位。
在实际应用中,模板匹配技术具有重要价值:
- 工业检测:电子元件定位、产品缺陷检测、装配精度验证
- 安防监控:特定目标追踪、异常行为检测
- 医学影像:病灶识别、器官定位、影像配准
- 机器人视觉:目标抓取、场景导航、物体识别
- 遥感图像:地物识别、变化检测、目标定位
随着应用场景的复杂化,对模板匹配技术的鲁棒性、精度和效率提出了更高要求,传统方法逐渐暴露出局限性,为深度学习方法的应用提供了契机。
1.2 传统模板匹配方法的局限性
传统模板匹配方法主要基于像素级的相似性度量,通过滑动窗口在源图像上移动,计算每个窗口与模板的相似度得分,最终选取得分最高的区域作为匹配结果。常见的传统方法包括:
-
基于灰度的方法:
- 平方差匹配(SSD):计算模板与窗口区域像素灰度值差的平方和
- 归一化平方差匹配(NSSD):对 SSD 进行归一化处理
- 交叉相关匹配(CC):计算模板与窗口区域的互相关
- 归一化交叉相关匹配(NCC):对 CC 进行归一化处理
-
基于特征的方法:
- SIFT(尺度不变特征变换)匹配
- SURF(加速稳健特征)匹配
- ORB(定向快速旋转 brief)匹配
传统方法存在显著局限性:
- 对光照变化、噪声干扰敏感
- 难以处理目标的尺度变化和旋转变形
- 特征表达能力有限,复杂场景下匹配精度低
- 计算效率不高,难以满足实时性要求
这些局限性促使研究人员探索更强大的模板匹配方法,而深度学习技术的兴起为解决这些问题提供了新的思路。
1.3 深度学习在模板匹配中的优势
深度学习通过多层非线性变换自动学习图像的抽象特征,相比传统方法具有显著优势:
- 强大的特征学习能力:能够自动学习从低级到高级的层次化特征,捕捉图像的语义信息
- 更好的鲁棒性:对光照、尺度、旋转等变换具有更强的适应能力
- 端到端学习:可以直接从数据中学习匹配模式,无需人工设计特征
- 泛化能力强:在大规模数据集上训练的模型可以较好地迁移到新场景
基于这些优势,深度学习方法在模板匹配任务中取得了突破性进展,成为当前研究的热点方向。
1.4 本文结构
本文余下部分安排如下:第 2 章介绍基于深度学习的模板匹配基础理论;第 3 章详细阐述各类深度学习模板匹配方法;第 4 章给出完整的代码实现与实验分析;第 5 章探讨深度学习模板匹配的应用场景;第 6 章分析当前研究面临的挑战与未来发展方向;最后是结论部分。
2. 深度学习模板匹配基础理论
2.1 卷积神经网络基础
卷积神经网络(CNN)是深度学习在计算机视觉领域取得成功的基础,其特殊的网络结构使其能够有效捕捉图像的空间特征。
2.1.1 卷积操作
卷积操作是 CNN 的核心,通过滑动卷积核对输入图像进行局部特征提取:
其中,I 是输入图像,K 是卷积核,M 和 N 是卷积核的大小。
2.1.2 池化操作
池化操作用于降低特征图维度,减少计算量,同时提供一定的平移不变性:
- 最大池化(Max Pooling):选取局部区域的最大值
- 平均池化(Average Pooling):计算局部区域的平均值
2.1.3 经典 CNN 架构
- LeNet-5:早期用于手写数字识别的 CNN 架构
- AlexNet:2012 年在 ImageNet 竞赛中夺冠,推动了深度学习的发展
- VGG:采用多个 3×3 卷积核堆叠,加深网络深度
- ResNet:引入残差连接,解决深层网络训练难题
- DenseNet:通过密集连接充分利用特征,提升模型性能
这些经典架构为模板匹配任务中的特征提取提供了有力工具。
2.2 相似性度量学习
模板匹配本质上是一种相似性度量任务,深度学习方法通过学习有效的相似性度量函数来提升匹配性能。
2.2.1 距离度量
常用的距离度量方式包括:
- 欧氏距离(Euclidean Distance):
- 曼哈顿距离(Manhattan Distance):
- 余弦距离(Cosine Distance):
2.2.2 损失函数
在深度学习中,通常通过损失函数来指导模型学习有效的相似性度量:
-
对比损失(Contrastive Loss):
其中,Y 表示样本对是否匹配(1 表示匹配,0 表示不匹配),D 是特征向量距离,m 是边际参数。
-
三元组损失(Triplet Loss):
其中,a 是锚点样本,p 是与a匹配的正样本,n 是与a不匹配的负样本,\(\alpha\) 是边际参数,目标是使a与p的距离小于a与n的距离至少
。
-
三元组中心损失(Triplet Center Loss): 在三元组损失基础上引入类中心,增强类内聚集性和类间分离性。
这些损失函数为训练模板匹配模型提供了优化目标。
2.3 孪生网络架构
孪生网络(Siamese Network)是模板匹配任务中应用最广泛的深度学习架构之一,由两个结构相同、参数共享的子网络组成,分别处理模板图像和待检测图像,通过度量两个子网络输出特征的相似度来实现匹配。
2.3.1 基本结构
孪生网络的基本结构包括:
- 特征提取子网络(通常为 CNN):对输入图像进行特征编码
- 相似度度量模块:计算两个特征向量的相似度
- 损失函数:指导网络学习有效的特征表示和相似度度量
2.3.2 变种结构
- 双联网络(Pseudo-Siamese Network):两个子网络结构相同但参数不共享
- 三联网络(Triplet Network):包含三个子网络,分别处理锚点、正样本和负样本
- 多尺度孪生网络:融合不同尺度的特征,提升对尺度变化的鲁棒性
孪生网络通过共享参数有效减少了模型参数数量,同时强制网络学习具有判别性的特征表示,非常适合模板匹配任务。
3. 深度学习模板匹配方法
3.1 基于卷积神经网络的模板匹配
早期将深度学习应用于模板匹配的方法主要是利用 CNN 进行特征提取,然后结合传统相似性度量进行匹配。
3.1.1 端到端回归方法
该方法将模板匹配视为回归问题,直接预测目标在源图像中的位置坐标。
基本流程:
- 将模板图像和源图像输入 CNN
- 网络输出目标区域的边界框坐标(x1, y1, x2, y2)
- 使用平滑 L1 损失等边界框回归损失进行训练
优势:直接输出目标位置,端到端训练 局限性:需要大量标注数据,对模板与目标的尺度差异敏感
3.1.2 滑动窗口分类方法
该方法将模板匹配视为分类问题,通过滑动窗口判断每个窗口是否包含目标。
基本流程:
- 预训练 CNN 分类模型
- 将模板图像作为正样本,背景区域作为负样本
- 在源图像上滑动窗口,使用 CNN 判断每个窗口是否与模板匹配
- 对分类得分进行非极大值抑制,得到最终匹配结果
优势:可以利用预训练模型,减少数据需求 局限性:计算量大,检测速度慢
3.2 基于孪生网络的模板匹配
孪生网络通过学习图像对的相似性,在模板匹配任务中表现出色,成为研究热点。
3.2.1 SiameseFC 方法
SiameseFC(Siamese Fully Convolutional Networks)是首个将全卷积网络与孪生网络结合的模板匹配方法,实现了实时目标跟踪与匹配。
核心思想:
- 使用全卷积网络作为特征提取器,保证输入输出的空间对应关系
- 通过互相关操作计算模板特征与搜索区域特征的相似度
- 输出响应图,响应值最高的位置即为匹配结果
网络结构:
- 特征提取网络:采用 AlexNet 的前几层,去除全连接层,保留卷积层
- 互相关层:计算模板特征与搜索区域特征的相似度
- 输出层:生成响应图
优势:
- 全卷积结构支持任意尺寸输入
- 前向传播速度快,可实现实时匹配(约 100fps)
- 对平移变化具有良好的鲁棒性
局限性:
- 对尺度变化和剧烈外观变化鲁棒性不足
- 特征表达能力有限
3.2.2 SiamRPN 方法
SiamRPN(Siamese Region Proposal Network)引入区域建议网络(RPN)到孪生网络中,提升了对尺度和比例变化的适应能力。
核心改进:
- 在孪生网络特征提取基础上,引入 RPN 分支
- RPN 同时预测目标边界框和分类得分
- 通过 anchor 机制处理不同尺度和比例的目标
优势:
- 同时处理分类和回归任务
- 对尺度和比例变化的鲁棒性显著提升
- 匹配精度高于 SiameseFC
局限性:
- 模型复杂度增加,计算量增大
- 对严重遮挡的处理能力有限
3.2.3 SiamMask 方法
SiamMask 在 SiamRPN 基础上增加了掩码分支,不仅可以定位目标,还能生成目标的像素级掩码,进一步提升匹配精度。
创新点:
- 引入掩码分支,输出目标的二值掩码
- 采用空间注意力机制增强特征表示
- 多任务联合训练(分类、回归、掩码)
优势:
- 提供更精细的目标轮廓信息
- 对部分遮挡具有更好的鲁棒性
- 匹配精度进一步提升
局限性:
- 计算复杂度更高,对硬件要求提升
- 掩码生成增加了训练难度
3.3 基于注意力机制的模板匹配
注意力机制能够使模型关注关键区域,提升特征表示的判别性,在模板匹配中得到广泛应用。
3.3.1 空间注意力
空间注意力机制通过学习空间权重图,使模型关注图像中对匹配更重要的区域。
实现方式:
- 对特征图进行全局平均池化和全局最大池化
- 将两种池化结果拼接,通过卷积层生成空间注意力图
- 将注意力图与原特征图相乘,增强关键区域特征
优势:突出目标区域,抑制背景干扰 应用:SiamAttn、AttentionSiamese 等方法
3.3.2 通道注意力
通道注意力机制通过学习通道权重,增强对匹配更重要的特征通道。
实现方式:
- 对特征图进行全局平均池化和全局最大池化
- 通过 MLP 学习通道权重
- 将权重与原特征图相乘,增强关键通道特征
优势:自动选择有判别性的特征通道 应用:SiamCA、ChannelAttentionSiamese 等方法
3.3.3 自注意力机制
自注意力机制(Self-Attention)能够捕捉图像中长距离依赖关系,提升特征的全局一致性。
实现方式:
- 计算查询(Query)、键(Key)和值(Value)矩阵
- 通过缩放点积计算注意力权重:
- 将注意力结果与原特征融合
优势:捕捉全局上下文信息,增强特征的语义一致性 应用:Transformer-Siamese 等最新方法
3.4 基于 Transformer 的模板匹配
Transformer 凭借其强大的全局建模能力,在计算机视觉领域取得突破,也被应用于模板匹配任务。
3.4.1 Vision Transformer 基础
Vision Transformer(ViT)将图像分割为 patches,通过自注意力机制捕捉全局特征:
- 将图像分割为固定大小的 patches
- 对每个 patch 进行线性嵌入
- 添加位置编码,保留空间信息
- 通过多个 Transformer 编码器层进行特征学习
3.4.2 Transformer 在模板匹配中的应用
基于 Transformer 的模板匹配方法主要有两种思路:
-
Transformer 增强的孪生网络:
- 保留孪生网络结构
- 在特征提取后加入 Transformer 编码器
- 利用自注意力和交叉注意力增强模板与搜索区域的特征交互
-
纯 Transformer 匹配模型:
- 去除 CNN 特征提取器,直接使用 ViT 处理图像
- 通过交叉注意力计算模板与搜索区域的相似度
- 端到端学习匹配模式
优势:
- 强大的全局依赖建模能力
- 对复杂背景和遮挡的鲁棒性强
- 特征表示更具语义性
局限性:
- 计算复杂度高,训练和推理成本大
- 需要更多的训练数据
- 对小目标匹配精度有待提升
3.5 多模态模板匹配
多模态模板匹配结合多种类型的图像数据(如 RGB、红外、深度等),提升复杂场景下的匹配鲁棒性。
3.5.1 模态融合策略
- 早期融合:在输入层融合多模态数据,共同进行特征提取
- 中期融合:在特征提取过程中融合不同模态的特征
- 晚期融合:对不同模态的匹配结果进行融合
3.5.2 深度学习实现方法
- 多分支网络:为每种模态设计专门的特征提取分支
- 跨模态注意力:学习模态间的关联,增强互补信息
- 模态转换网络:将一种模态转换为另一种模态,解决模态差异问题
优势:利用多模态数据的互补性,提升复杂环境下的匹配可靠性 应用场景:夜间监控、恶劣天气下的目标检测、医疗影像分析
4. 代码实现与实验分析
4.1 基于孪生网络的模板匹配实现
下面我们实现一个基于孪生网络的模板匹配模型,使用 PyTorch 框架,采用 ResNet 作为特征提取器,结合对比损失进行训练。
4.1.1 环境配置
首先确保安装必要的库:
- Python 3.8+
- PyTorch 1.7+
- torchvision 0.8+
- OpenCV 4.5+
- NumPy 1.19+
- Matplotlib 3.3+
4.1.2 数据集准备
我们使用自定义数据集进行训练,数据集包含模板图像和对应的源图像对,分为匹配对和非匹配对。
数据集结构:
dataset/
├── train/
│ ├── positive/ # 匹配对
│ │ ├── template_0001.jpg
│ │ ├── image_0001.jpg
│ │ ├── ...
│ ├── negative/ # 非匹配对
│ │ ├── template_0001.jpg
│ │ ├── image_0001.jpg
│ │ ├── ...
├── val/
│ ├── positive/
│ ├── negative/datasets.py:
# 定义数据集类
class TemplateMatchingDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.positive_pairs = []
self.negative_pairs = []
# 加载正样本对
positive_dir = os.path.join(root_dir, 'positive')
if os.path.exists(positive_dir):
template_files = [f for f in os.listdir(positive_dir) if f.startswith('template')]
for template_file in template_files:
idx = template_file.split('_')[1].split('.')[0]
image_file = f'image_{idx}.jpg'
if image_file in os.listdir(positive_dir):
template_path = os.path.join(positive_dir, template_file)
image_path = os.path.join(positive_dir, image_file)
self.positive_pairs.append((template_path, image_path, 1))
# 加载负样本对
negative_dir = os.path.join(root_dir, 'negative')
if os.path.exists(negative_dir):
template_files = [f for f in os.listdir(negative_dir) if f.startswith('template')]
for template_file in template_files:
idx = template_file.split('_')[1].split('.')[0]
image_file = f'image_{idx}.jpg'
if image_file in os.listdir(negative_dir):
template_path = os.path.join(negative_dir, template_file)
image_path = os.path.join(negative_dir, image_file)
self.negative_pairs.append((template_path, image_path, 0))
# 合并正负样本
self.data = self.positive_pairs + self.negative_pairs
print(f"Loaded {len(self.positive_pairs)} positive pairs and {len(self.negative_pairs)} negative pairs")
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
template_path, image_path, label = self.data[idx]
# 读取图像
template = cv2.imread(template_path)
image = cv2.imread(image_path)
# 转换为RGB格式
template = cv2.cvtColor(template, cv2.COLOR_BGR2RGB)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 调整大小
template = cv2.resize(template, (128, 128))
image = cv2.resize(image, (128, 128))
# 应用变换
if self.transform:
template = self.transform(template)
image = self.transform(image)
return template, image, torch.tensor(label, dtype=torch.float32)
network.py:
import torch
import torch.nn as nn
import torchvision.models as models
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import cv2
import numpy as np
import os
from tqdm import tqdm
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, roc_auc_score
# 定义特征提取网络
class FeatureExtractor(nn.Module):
def __init__(self, embedding_dim=128):
super(FeatureExtractor, self).__init__()
# 使用预训练的ResNet18作为基础模型
self.resnet = models.resnet18(pretrained=True)
# 移除最后一个全连接层
self.features = nn.Sequential(*list(self.resnet.children())[:-1])
# 添加自定义全连接层,输出指定维度的特征向量
self.fc = nn.Linear(self.resnet.fc.in_features, embedding_dim)
def forward(self, x):
# 特征提取
x = self.features(x)
# 展平特征图
x = x.view(x.size(0), -1)
# 输出特征向量
x = self.fc(x)
# L2归一化
x = F.normalize(x, p=2, dim=1)
return x
# 定义孪生网络
class SiameseNetwork(nn.Module):
def __init__(self, embedding_dim=128):
super(SiameseNetwork, self).__init__()
# 共享特征提取器
self.feature_extractor = FeatureExtractor(embedding_dim)
def forward(self, template, image):
# 提取模板特征
template_embedding = self.feature_extractor(template)
# 提取图像特征
image_embedding = self.feature_extractor(image)
return template_embedding, image_embedding
# 定义对比损失
class ContrastiveLoss(nn.Module):
def __init__(self, margin=1.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
# 计算欧氏距离
euclidean_distance = F.pairwise_distance(output1, output2)
# 计算对比损失
loss_contrastive = torch.mean((1 - label) * torch.pow(euclidean_distance, 2) +
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
train.py:
# 训练函数
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs=20, device='cuda'):
# 记录训练过程
train_losses = []
val_losses = []
train_accuracies = []
val_accuracies = []
val_aucs = []
# 移动模型到设备
model.to(device)
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
train_preds = []
train_labels = []
# 训练循环
for templates, images, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs} - Training"):
# 移动数据到设备
templates = templates.to(device)
images = images.to(device)
labels = labels.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
template_embeddings, image_embeddings = model(templates, images)
# 计算损失
loss = criterion(template_embeddings, image_embeddings, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
# 累计损失
train_loss += loss.item() * templates.size(0)
# 计算预测结果(距离小于0.5视为匹配)
distances = F.pairwise_distance(template_embeddings, image_embeddings)
preds = (distances < 0.5).float()
# 保存预测结果和标签
train_preds.extend(preds.cpu().numpy())
train_labels.extend(labels.cpu().numpy())
# 计算平均训练损失和准确率
epoch_train_loss = train_loss / len(train_loader.dataset)
train_accuracy = accuracy_score(train_labels, train_preds)
# 验证
model.eval()
val_loss = 0.0
val_preds = []
val_labels = []
val_distances = []
with torch.no_grad():
for templates, images, labels in tqdm(val_loader, desc=f"Epoch {epoch+1}/{num_epochs} - Validation"):
# 移动数据到设备
templates = templates.to(device)
images = images.to(device)
labels = labels.to(device)
# 前向传播
template_embeddings, image_embeddings = model(templates, images)
# 计算损失
loss = criterion(template_embeddings, image_embeddings, labels)
val_loss += loss.item() * templates.size(0)
# 计算距离和预测结果
distances = F.pairwise_distance(template_embeddings, image_embeddings)
preds = (distances < 0.5).float()
# 保存结果
val_preds.extend(preds.cpu().numpy())
val_labels.extend(labels.cpu().numpy())
val_distances.extend(distances.cpu().numpy())
# 计算平均验证损失、准确率和AUC
epoch_val_loss = val_loss / len(val_loader.dataset)
val_accuracy = accuracy_score(val_labels, val_preds)
val_auc = roc_auc_score(val_labels, 1 - np.array(val_distances)) # 1 - 距离作为相似度
# 保存指标
train_losses.append(epoch_train_loss)
val_losses.append(epoch_val_loss)
train_accuracies.append(train_accuracy)
val_accuracies.append(val_accuracy)
val_aucs.append(val_auc)
# 打印 epoch 结果
print(f"Epoch {epoch+1}/{num_epochs}")
print(f"Train Loss: {epoch_train_loss:.4f} | Train Acc: {train_accuracy:.4f}")
print(f"Val Loss: {epoch_val_loss:.4f} | Val Acc: {val_accuracy:.4f} | Val AUC: {val_auc:.4f}")
print("-" * 50)
# 保存模型
torch.save(model.state_dict(), 'siamese_template_matching.pth')
print("Model saved as 'siamese_template_matching.pth'")
return {
'train_losses': train_losses,
'val_losses': val_losses,
'train_accuracies': train_accuracies,
'val_accuracies': val_accuracies,
'val_aucs': val_aucs
}
infer.py:
# 模板匹配推理函数
def template_matching(model, template_path, image_path, transform, device='cuda'):
# 加载图像
template = cv2.imread(template_path)
image = cv2.imread(image_path)
if template is None or image is None:
raise ValueError("Could not read template or image file")
# 转换为RGB格式
template_rgb = cv2.cvtColor(template, cv2.COLOR_BGR2RGB)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 保存原始图像用于可视化
original_template = template.copy()
original_image = image.copy()
# 预处理
template_resized = cv2.resize(template_rgb, (128, 128))
image_resized = cv2.resize(image_rgb, (128, 128))
# 应用变换
template_tensor = transform(template_resized).unsqueeze(0)
image_tensor = transform(image_resized).unsqueeze(0)
# 模型推理
model.eval()
with torch.no_grad():
template_tensor = template_tensor.to(device)
image_tensor = image_tensor.to(device)
template_embedding, image_embedding = model(template_tensor, image_tensor)
# 计算相似度
distance = F.pairwise_distance(template_embedding, image_embedding).item()
similarity = 1 - distance # 转换为相似度(0-1之间)
return original_template, original_image, similarity
# 滑动窗口匹配函数,用于在大图中寻找匹配区域
def sliding_window_matching(model, template_path, image_path, transform,
window_size=(128, 128), step_size=32, device='cuda'):
# 加载图像
template = cv2.imread(template_path)
image = cv2.imread(image_path)
if template is None or image is None:
raise ValueError("Could not read template or image file")
# 转换为RGB格式
template_rgb = cv2.cvtColor(template, cv2.COLOR_BGR2RGB)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 调整模板大小
template_resized = cv2.resize(template_rgb, window_size)
template_tensor = transform(template_resized).unsqueeze(0).to(device)
# 获取图像尺寸
img_height, img_width = image_rgb.shape[:2]
window_height, window_width = window_size
# 初始化相似度图
similarity_map = np.zeros((
(img_height - window_height) // step_size + 1,
(img_width - window_width) // step_size + 1
))
model.eval()
with torch.no_grad():
# 提取模板特征
template_embedding = model.feature_extractor(template_tensor)
# 滑动窗口
for i, y in enumerate(range(0, img_height - window_height + 1, step_size)):
for j, x in enumerate(range(0, img_width - window_width + 1, step_size)):
# 提取窗口区域
window = image_rgb[y:y+window_height, x:x+window_width]
# 预处理
window_tensor = transform(window).unsqueeze(0).to(device)
# 提取窗口特征
window_embedding = model.feature_extractor(window_tensor)
# 计算相似度
distance = F.pairwise_distance(template_embedding, window_embedding).item()
similarity = 1 - distance
# 保存相似度
similarity_map[i, j] = similarity
# 找到最大相似度位置
max_i, max_j = np.unravel_index(np.argmax(similarity_map), similarity_map.shape)
best_y = max_i * step_size
best_x = max_j * step_size
best_similarity = similarity_map[max_i, max_j]
# 绘制最佳匹配区域
result_image = image.copy()
cv2.rectangle(result_image, (best_x, best_y),
(best_x + window_width, best_y + window_height),
(0, 255, 0), 2)
cv2.putText(result_image, f"Similarity: {best_similarity:.2f}",
(best_x, best_y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return template, result_image, similarity_map, best_similarity
# 可视化训练结果
def plot_training_results(results):
plt.figure(figsize=(15, 10))
# 绘制损失曲线
plt.subplot(2, 2, 1)
plt.plot(results['train_losses'], label='Train Loss')
plt.plot(results['val_losses'], label='Validation Loss')
plt.title('Loss Curves')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 绘制准确率曲线
plt.subplot(2, 2, 2)
plt.plot(results['train_accuracies'], label='Train Accuracy')
plt.plot(results['val_accuracies'], label='Validation Accuracy')
plt.title('Accuracy Curves')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
# 绘制AUC曲线
plt.subplot(2, 2, 3)
plt.plot(results['val_aucs'], label='Validation AUC')
plt.title('Validation AUC Curve')
plt.xlabel('Epoch')
plt.ylabel('AUC')
plt.legend()
plt.tight_layout()
plt.savefig('training_results.png')
plt.show()
# 主函数
def main():
import torchvision.transforms as transforms
# 配置参数
embedding_dim = 128
margin = 1.0
batch_size = 32
learning_rate = 1e-4
num_epochs = 20
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
# 数据变换
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集
train_dataset = TemplateMatchingDataset('dataset/train', transform=transform)
val_dataset = TemplateMatchingDataset('dataset/val', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
# 初始化模型、损失函数和优化器
model = SiameseNetwork(embedding_dim)
criterion = ContrastiveLoss(margin)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
results = train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs, device)
# 可视化训练结果
plot_training_results(results)
# 示例推理
template_path = 'dataset/val/positive/template_0001.jpg'
image_path = 'dataset/val/positive/image_0001.jpg'
# 单对图像匹配
template, image, similarity = template_matching(model, template_path, image_path, transform, device)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(template, cv2.COLOR_BGR2RGB))
plt.title('Template')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title(f'Image (Similarity: {similarity:.2f})')
plt.axis('off')
plt.tight_layout()
plt.savefig('single_matching_result.png')
plt.show()
# 滑动窗口匹配示例
large_image_path = 'test_large_image.jpg' # 替换为实际的大图路径
if os.path.exists(large_image_path):
template, result_image, similarity_map, best_similarity = sliding_window_matching(
model, template_path, large_image_path, transform, device=device
)
plt.figure(figsize=(15, 10))
plt.subplot(1, 3, 1)
plt.imshow(cv2.cvtColor(template, cv2.COLOR_BGR2RGB))
plt.title('Template')
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(cv2.cvtColor(result_image, cv2.COLOR_BGR2RGB))
plt.title(f'Matching Result (Similarity: {best_similarity:.2f})')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(similarity_map, cmap='jet')
plt.title('Similarity Map')
plt.colorbar()
plt.axis('off')
plt.tight_layout()
plt.savefig('sliding_window_result.png')
plt.show()
if __name__ == "__main__":
main()

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)